SQL यूनियन के साथ कठिन समय हो रहा है? ऐसा तब होता है जब आपके द्वारा संयुक्त किए गए परिणाम आपके SQL सर्वर को एक ठहराव में डाल देते हैं। या एक रिपोर्ट जो लाल X आइकन के साथ एक बॉक्स पॉप अप करने से पहले काम कर रही है। UNION के साथ एक लाइन की ओर इशारा करते हुए "ऑपरेंड टाइप क्लैश" त्रुटि उत्पन्न होती है। "आग" शुरू होती है। परिचित लगता है?
चाहे आप कुछ समय के लिए SQL UNION का उपयोग कर रहे हों या बस इसे शुरू कर दें, एक चीट शीट या नोट्स के संक्षिप्त सेट से कोई नुकसान नहीं होगा। आज आपको इस पोस्ट में यही मिलने वाला है। यह सूची नौसिखियों और दिग्गजों दोनों के लिए 10 उपयोगी टिप्स प्रदान करती है। साथ ही, उदाहरण और कुछ उन्नत चर्चाएँ भी होंगी।

[sendpulse-form id="11900″]
लेकिन इससे पहले कि हम पहले बिंदु पर जाएं, आइए शर्तों को स्पष्ट करें।
UNION SQL में सेट ऑपरेटरों में से एक है जो 2 या अधिक परिणाम सेट को जोड़ता है। यह तब काम आ सकता है जब आपको विभिन्न स्रोतों से नाम, मासिक आँकड़े और बहुत कुछ संयोजित करने की आवश्यकता हो। और चाहे आप SQL सर्वर, MySQL, या Oracle का उपयोग करें, उद्देश्य, व्यवहार और सिंटैक्स बहुत समान होंगे। लेकिन यह कैसे काम करता है?
1. अद्वितीय को संयोजित करने के लिए SQL UNION का उपयोग करें रिकॉर्ड्स
परिणाम सेट को संयोजित करने के लिए UNION का उपयोग करना डुप्लिकेट को हटा देता है।
यह महत्वपूर्ण क्यों है?
अधिकांश समय, आप डुप्लीकेट के साथ परिणाम नहीं चाहते हैं। डुप्लिकेट लाइनों वाली रिपोर्ट हार्डकॉपी में स्याही और कागज को बर्बाद कर देती है। और इससे आपके उपयोगकर्ता नाराज़ होंगे।
इसका उपयोग कैसे करें
आप बीच में UNION के साथ SELECT स्टेटमेंट के परिणामों को जोड़ते हैं।
उदाहरण के साथ शुरू करने से पहले, आइए अपना नमूना डेटा तैयार करें।
USE AdventureWorks
GO
IF OBJECT_ID ('dbo.Customer1', 'U') IS NOT NULL
DROP TABLE dbo.Customer1;
GO
IF OBJECT_ID ('dbo.Customer2', 'U') IS NOT NULL
DROP TABLE dbo.Customer2;
GO
IF OBJECT_ID ('dbo.Customer3', 'U') IS NOT NULL
DROP TABLE dbo.Customer3;
GO
-- Get 3 customer names with Andersen lastname
SELECT TOP 3
p.LastName
, p.FirstName
, c.AccountNumber
INTO dbo.Customer1
FROM Person.Person AS p
INNER JOIN Sales.Customer c
ON c.PersonID = p.BusinessEntityID
WHERE p.LastName = 'Andersen';
-- Make sure we have a duplicate in another table
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
INTO dbo.Customer2
FROM Customer1 c
-- Seems it's not enough. Let's have a 3rd copy
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
INTO dbo.Customer3
FROM Customer1 c
हम उपरोक्त कोड द्वारा उत्पन्न डेटा का उपयोग तीसरे टिप तक करेंगे। अब जब हम तैयार हैं, तो नीचे उदाहरण दिया गया है:
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
FROM dbo.Customer1 c
UNION
SELECT
c2.LastName
,c2.FirstName
,c2.AccountNumber
FROM dbo.Customer2 c2
UNION
SELECT
c3.LastName
,c3.FirstName
,c3.AccountNumber
FROM dbo.Customer3 c3
हमारे पास समान ग्राहकों के नाम की 3 प्रतियां हैं और हम उम्मीद करते हैं कि अद्वितीय रिकॉर्ड गायब हो जाएंगे। परिणाम देखें:
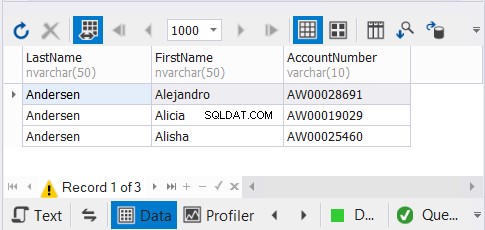
SQL सर्वर समाधान के लिए dbForge Studio हम अपने उदाहरणों के लिए उपयोग करते हैं केवल 3 रिकॉर्ड दिखाते हैं। यह 9 हो सकता था। UNION लागू करके, हमने डुप्लिकेट हटा दिए।
यह कैसे काम करता है?
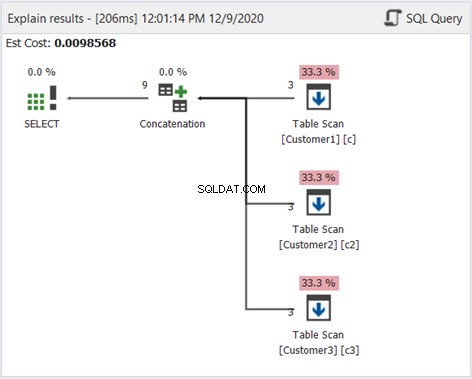
डीबीफोर्ज स्टूडियो में योजना आरेख से पता चलता है कि SQL सर्वर चित्र 1 में दिखाए गए परिणाम कैसे उत्पन्न करता है:एक नज़र डालें:
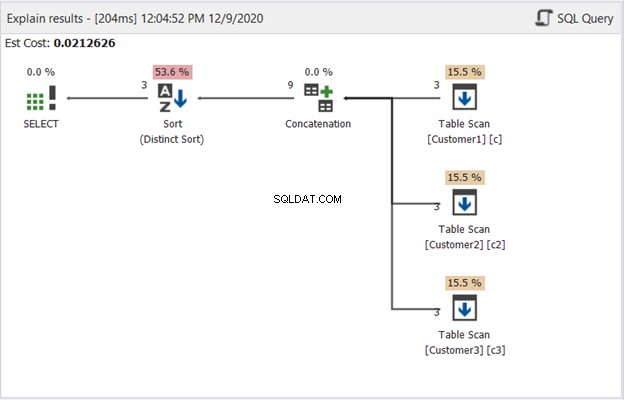
चित्र 2 की व्याख्या करने के लिए, दाएं से बाएं शुरू करें:
- हमने प्रत्येक टेबल स्कैन ऑपरेटर से 3 रिकॉर्ड प्राप्त किए। वे ऊपर दिए गए उदाहरण से 3 SELECT स्टेटमेंट हैं। इसमें से निकलने वाली प्रत्येक पंक्ति में '3' का अर्थ है प्रत्येक में 3 रिकॉर्ड।
- संयोजन ऑपरेटर परिणामों का संयोजन करता है। इससे बाहर जाने वाली रेखा '9' दिखाती है - परिणामों के संयोजन से 9 रिकॉर्ड का आउटपुट।
- डिस्टिक्ट सॉर्ट ऑपरेटर अंतिम आउटपुट होने के लिए अद्वितीय रिकॉर्ड सुनिश्चित करता है। इससे निकलने वाली रेखा '3' दिखाती है, जो चित्र 1 में रिकॉर्ड की संख्या के अनुरूप है।
उपरोक्त आरेख दिखाता है कि SQL सर्वर द्वारा UNION को कैसे संसाधित किया जाता है। उपयोग किए गए ऑपरेटरों की संख्या और प्रकार क्वेरी और अंतर्निहित डेटा स्रोत के आधार पर भिन्न हो सकते हैं। लेकिन संक्षेप में, एक यूनियन इस प्रकार काम करता है:
- प्रत्येक चयन कथन के परिणाम प्राप्त करें।
- परिणामों को एक संयोजन ऑपरेटर के साथ संयोजित करें।
- यदि संयुक्त परिणाम अद्वितीय नहीं हैं, तो SQL सर्वर डुप्लिकेट को फ़िल्टर कर देगा।
यूनियन के साथ सभी सफल उदाहरण इन बुनियादी चरणों का पालन करते हैं।
2. डुप्लिकेट के साथ रिकॉर्ड को संयोजित करने के लिए SQL UNION ALL का उपयोग करें
UNION ALL का उपयोग करना परिणाम सेट को डुप्लीकेट के साथ संयोजित करता है।
यह महत्वपूर्ण क्यों है?
आप परिणाम सेट को संयोजित करना चाहते हैं और फिर बाद में प्रसंस्करण के लिए डुप्लिकेट के साथ रिकॉर्ड प्राप्त कर सकते हैं। यह कार्य आपके डेटा को साफ करने के लिए उपयोगी है।
इसका उपयोग कैसे करें
आप सेलेक्ट स्टेटमेंट के परिणामों को UNION ALL के बीच में जोड़ते हैं। उदाहरण पर एक नज़र डालें:
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
FROM dbo.Customer1 c
UNION ALL
SELECT
c2.LastName
,c2.FirstName
,c2.AccountNumber
FROM dbo.Customer2 c2
UNION ALL
SELECT
c3.LastName
,c3.FirstName
,c3.AccountNumber
FROM dbo.Customer3 c3
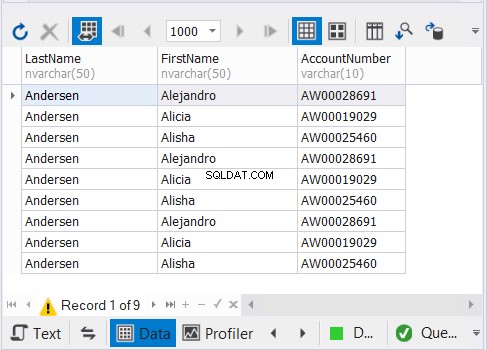
उपरोक्त कोड 9 रिकॉर्ड आउटपुट करता है जैसा कि चित्र 3 में दिखाया गया है:
यह कैसे काम करता है?
पहले की तरह, हम यह जानने के लिए योजना आरेख का उपयोग करते हैं कि यह कैसे काम करता है:
चित्र 2 में सॉर्ट डिस्टिंक्ट को छोड़कर, ऊपर दिया गया चित्र समान है। यह सही है क्योंकि हम डुप्लिकेट को फ़िल्टर नहीं करना चाहते हैं।
उपरोक्त आरेख दिखाता है कि UNION ALL कैसे काम करता है। संक्षेप में, ये वे चरण हैं जिनका SQL सर्वर अनुसरण करेगा:
- प्रत्येक चयन कथन के परिणाम प्राप्त करें।
- फिर, परिणामों को एक संयोजन ऑपरेटर के साथ संयोजित करें।
UNION ALL के सफल उदाहरण इस पैटर्न का अनुसरण करते हैं।
3. आप SQL UNION और UNION सभी को मिला सकते हैं लेकिन उन्हें कोष्ठक के साथ समूहित कर सकते हैं
आप कम से कम तीन SELECT स्टेटमेंट में UNION और UNION ALL के उपयोग को मिला सकते हैं।
इसका उपयोग कैसे करें?
आप चयन कथन के परिणामों को यूनियन या यूनियन सभी के बीच में जोड़ते हैं। कोष्ठक एक साथ आने वाले परिणामों को समूहित करते हैं। आइए अगले उदाहरण के लिए उसी डेटा का उपयोग करें:
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
FROM dbo.Customer1 c
UNION ALL
(
SELECT
c2.LastName
,c2.FirstName
,c2.AccountNumber
FROM dbo.Customer2 c2
UNION
SELECT
c3.LastName
,c3.FirstName
,c3.AccountNumber
FROM dbo.Customer3 c3
)
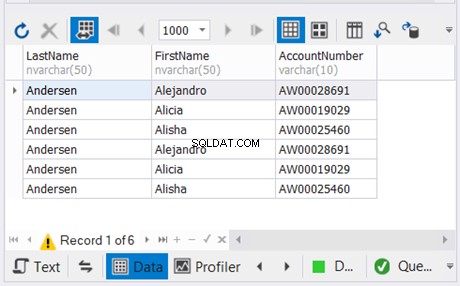
उपरोक्त उदाहरण डुप्लिकेट के बिना अंतिम दो SELECT स्टेटमेंट के परिणामों को जोड़ता है। फिर, यह इसे पहले SELECT स्टेटमेंट के परिणाम के साथ जोड़ता है। परिणाम नीचे चित्र 5 में है:
4. प्रत्येक चयन कथन के कॉलम में संगत डेटा प्रकार होने चाहिए
UNION का उपयोग करने वाले प्रत्येक SELECT स्टेटमेंट के कॉलम में अलग-अलग डेटा प्रकार हो सकते हैं। यह तब तक स्वीकार्य है जब तक वे संगत हैं और उन पर निहित रूपांतरण की अनुमति देते हैं। संयुक्त परिणामों का अंतिम डेटा प्रकार उच्चतम प्राथमिकता वाले डेटा प्रकार का उपयोग करेगा। साथ ही, अंतिम डेटा आकार का आधार सबसे बड़े आकार वाला डेटा होता है। स्ट्रिंग्स के मामले में, यह सबसे अधिक वर्णों वाले डेटा का उपयोग करेगा।
यह महत्वपूर्ण क्यों है?
यदि आपको किसी तालिका में यूनियनों के परिणाम डालने की आवश्यकता है, तो अंतिम डेटा प्रकार और आकार यह निर्धारित करेगा कि यह लक्ष्य तालिका कॉलम पर फिट बैठता है या नहीं। यदि नहीं, तो त्रुटि होगी। उदाहरण के लिए, यूनियन में कॉलम में से एक में अंतिम प्रकार का NVARCHAR (50) है। यदि लक्ष्य तालिका स्तंभ VARCHAR(50) है, तो आप इसे तालिका में सम्मिलित नहीं कर सकते।
यह कैसे काम करता है?
इसे एक उदाहरण से समझाने का कोई बेहतर तरीका नहीं है:
SELECT N'김지수' AS FullName
UNION
SELECT N'김제니' AS KoreanName
UNION
SELECT N'박채영' AS KoreanName
UNION
SELECT N'ลลิษา มโนบาล' AS ThaiName
UNION
SELECT 'Kim Ji-soo' AS EnglishName
UNION
SELECT 'Jennie Kim' AS EnglishName
UNION
SELECT 'Roseanne Park' AS EnglishName
UNION
SELECT 'Lalisa Manoban' AS EnglishName
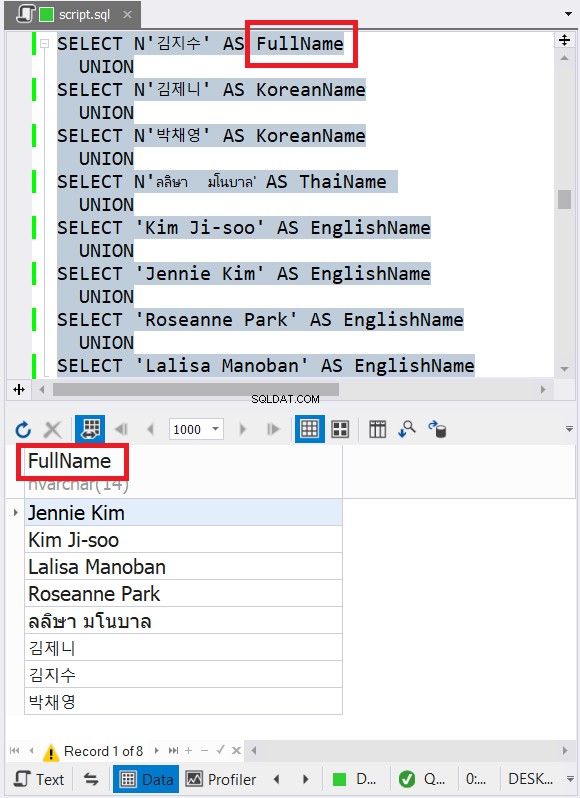
ऊपर दिए गए नमूने में अंग्रेज़ी, कोरियाई और थाई वर्ण नामों वाला डेटा है। थाई और कोरियाई यूनिकोड वर्ण हैं। अंग्रेजी अक्षर नहीं हैं। तो, आपको क्या लगता है कि अंतिम डेटा प्रकार और आकार क्या होगा? dbForge Studio इसे परिणाम सेट में दिखाता है:
क्या आपने चित्र 6 में अंतिम डेटा प्रकार देखा? यूनिकोड वर्णों के कारण यह VARCHAR नहीं हो सकता। तो, यह NVARCHAR होना चाहिए। इस बीच, आकार 14 से कम नहीं हो सकता क्योंकि सबसे अधिक वर्णों वाले डेटा में 14 वर्ण होते हैं। चित्र 6 में लाल रंग में कैप्शन देखें। dbForge Studio में कॉलम हेडर में डेटा प्रकार और आकार शामिल करना अच्छा है।
यह केवल स्ट्रिंग डेटा प्रकारों के मामले में नहीं है। यह संख्याओं और तिथियों पर भी लागू होता है। इस बीच, यदि आप डेटा को असंगत डेटा प्रकारों के साथ संयोजित करने का प्रयास करते हैं, तो एक त्रुटि उत्पन्न होगी। नीचे दिया गया उदाहरण देखें:
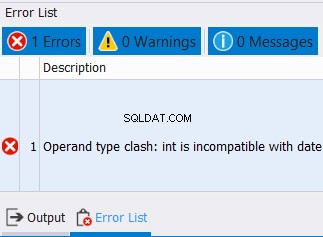
SELECT CAST('12/25/2020' AS DATE) AS col1
UNION
SELECT CAST('10' AS INT) AS col1
हम दिनांक और पूर्णांकों को एक कॉलम में संयोजित नहीं कर सकते। तो, नीचे दी गई त्रुटि की तरह उम्मीद करें:
5. संयुक्त परिणामों के कॉलम नाम पहले चयन विवरण के कॉलम नामों का उपयोग करेंगे
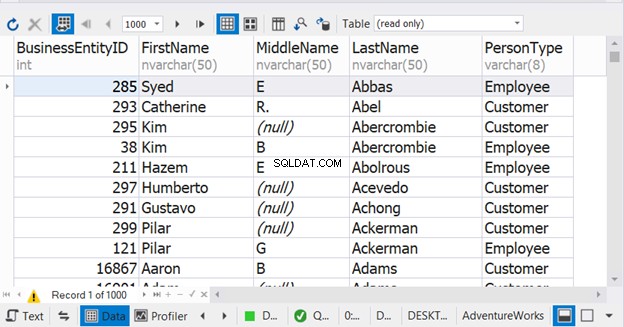
यह मुद्दा पिछले टिप से संबंधित है। टिप #4 में कोड में कॉलम नामों पर ध्यान दें। प्रत्येक सेलेक्ट स्टेटमेंट में अलग-अलग कॉलम नाम होते हैं। हालांकि, हमने पहले चित्रा 6 में संयुक्त परिणाम में अंतिम कॉलम नाम देखा था। इस प्रकार, आधार पहले SELECT स्टेटमेंट का कॉलम नाम है।
यह महत्वपूर्ण क्यों है?
यह तब आसान हो सकता है जब आपको यूनियन के परिणाम को अस्थायी तालिका में डंप करने की आवश्यकता हो। यदि आपको बाद के कथनों में इसके कॉलम नामों का उल्लेख करने की आवश्यकता है, तो आपको नामों के बारे में निश्चित होना चाहिए। जब तक आप IntelliSense के साथ एक उन्नत कोड संपादक का उपयोग नहीं कर रहे हैं, आप अपने T-SQL कोड में एक और त्रुटि के लिए तैयार हैं।
यह कैसे काम करता है?
dbForge Studio का उपयोग करने के स्पष्ट परिणामों के लिए चित्र 8 देखें:
6. परिणामों को क्रमबद्ध करने के लिए SQL UNION के साथ अंतिम चयन कथन में ORDER BY जोड़ें
आपको संयुक्त परिणामों को क्रमबद्ध करने की आवश्यकता है। बीच में UNION के साथ SELECT स्टेटमेंट की एक श्रृंखला में, आप इसे अंतिम SELECT स्टेटमेंट में ORDER BY क्लॉज के साथ कर सकते हैं।
यह महत्वपूर्ण क्यों है?
उपयोगकर्ता डेटा को उसी तरह क्रमबद्ध करना चाहते हैं जैसे वे ऐप्स, वेब पेज, रिपोर्ट, स्प्रेडशीट आदि में पसंद करते हैं।
इसका उपयोग कैसे करें
अंतिम चयन कथन में ORDER BY का उपयोग करें। यहां एक उदाहरण दिया गया है:
SELECT
e.BusinessEntityID
,p.FirstName
,p.MiddleName
,p.LastName
,'Employee' AS PersonType
FROM HumanResources.Employee e
INNER JOIN Person.Person p ON e.BusinessEntityID = p.BusinessEntityID
UNION
SELECT
c.PersonID
,p.FirstName
,p.MiddleName
,p.LastName
,'Customer' AS PersonType
FROM Sales.Customer c
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
ORDER BY p.LastName, p.FirstName
ऊपर दिया गया नमूना ऐसा लगता है कि छँटाई केवल अंतिम चयन कथन में होती है। लेकिन ऐसा नहीं है। यह संयुक्त परिणाम के लिए काम करेगा। यदि आप इसे प्रत्येक SELECT स्टेटमेंट में रखते हैं तो आपको परेशानी होगी। परिणाम देखें:
ORDER BY के बिना, परिणाम सेट में सभी कर्मचारी होंगे PersonType पहले सभी ग्राहक के बाद व्यक्ति प्रकार . हालांकि, चित्र 9 दर्शाता है कि नाम संयुक्त परिणाम का क्रमबद्ध क्रम बन जाते हैं।
अगर आप क्रम से लगाने के लिए हर SELECT स्टेटमेंट में ORDER BY डालने की कोशिश करते हैं, तो यहां बताया गया है कि क्या होगा:
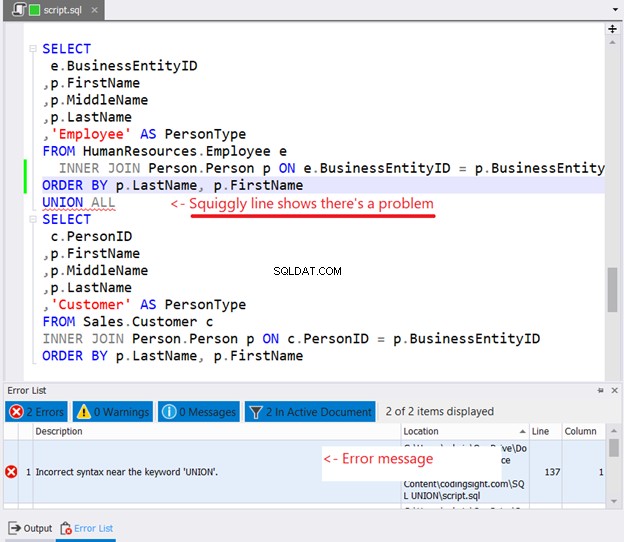
क्या आपने चित्र 10 में स्क्विगली लाइन देखी? यह एक चेतावनी है। यदि आपने इस पर ध्यान नहीं दिया और आगे बढ़ गए, तो dbForge Studio की त्रुटि सूची विंडो में एक त्रुटि दिखाई देगी।
7. SQL UNION के साथ प्रत्येक SELECT स्टेटमेंट में WHERE और GROUP BY क्लॉज़ का उपयोग किया जा सकता है
बीच में यूनियन के साथ प्रत्येक चयन कथन में खंड द्वारा आदेश काम नहीं करता है। हालांकि, WHERE और GROUP BY क्लॉज काम करते हैं।
यह महत्वपूर्ण क्यों है?
आप अलग-अलग क्वेरी के परिणामों को संयोजित करना चाह सकते हैं जो डेटा को फ़िल्टर, गिनते या सारांशित करते हैं। उदाहरण के लिए, आप जनवरी 2012 के लिए कुल बिक्री आदेश प्राप्त करने के लिए ऐसा कर सकते हैं और इसकी तुलना जनवरी 2013, जनवरी 2014 आदि से कर सकते हैं।
इसका उपयोग कैसे करें
प्रत्येक सेलेक्ट स्टेटमेंट में WHERE और/या GROUP BY क्लॉज रखें। नीचे दिया गया उदाहरण देखें:
USE AdventureWorks
GO
-- Get the number of orders for January 2012, 2013, 2014 for comparison
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '01/31/2012'
GROUP BY YEAR(soh.OrderDate)
UNION
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2013' AND '01/31/2013'
GROUP BY YEAR(soh.OrderDate)
UNION
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2014' AND '01/31/2014'
GROUP BY YEAR(soh.OrderDate)
उपरोक्त कोड लगातार तीन वर्षों के लिए जनवरी के आदेशों की संख्या को जोड़ता है। अब, आउटपुट जांचें:
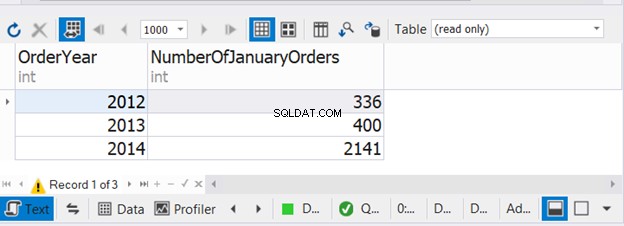
यह उदाहरण दिखाता है कि यूनियन के साथ तीन सेलेक्ट स्टेटमेंट में से प्रत्येक में WHERE और GROUP BY का उपयोग करना संभव है।
8. SQL UNION के साथ काम करता है में चुनें
जब आपको SQL UNION के साथ किसी क्वेरी के परिणामों को तालिका में सम्मिलित करने की आवश्यकता होती है, तो आप SELECT INTO का उपयोग करके ऐसा कर सकते हैं।
यह महत्वपूर्ण क्यों है?
ऐसे समय होंगे जब आपको आगे की प्रक्रिया के लिए UNION के साथ एक क्वेरी के परिणामों को तालिका में रखने की आवश्यकता होगी।
इसका उपयोग कैसे करें
INTO क्लॉज को पहले SELECT स्टेटमेंट में रखें। यहां एक उदाहरण दिया गया है:
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
INTO JanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '01/31/2012'
GROUP BY YEAR(soh.OrderDate)
UNION
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2013' AND '01/31/2013'
GROUP BY YEAR(soh.OrderDate)
UNION
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2014' AND '01/31/2014'
GROUP BY YEAR(soh.OrderDate)
पहले सेलेक्ट स्टेटमेंट में केवल एक INTO क्लॉज रखना याद रखें।
यह कैसे काम करता है
SQL सर्वर UNION को संसाधित करने के पैटर्न का अनुसरण करता है। फिर, यह INTO क्लॉज में निर्दिष्ट तालिका में परिणाम सम्मिलित करता है।
9. SQL UNION को SQL JOIN से अलग करें
SQL UNION और SQL JOIN दोनों टेबल डेटा को मिलाते हैं, लेकिन सिंटैक्स और परिणामों में अंतर रात और दिन जैसा होता है।
यह महत्वपूर्ण क्यों है?
अगर आपकी रिपोर्ट या किसी आवश्यकता को जॉइन की आवश्यकता है लेकिन आपने यूनियन किया है, तो आउटपुट गलत होगा।
SQL UNION और SQL JOIN का उपयोग कैसे किया जाता है
यह SQL यूनियन बनाम जॉइन है। SQL UNION के बारे में सीखते समय यह संबंधित खोज प्रश्नों और प्रश्नों में से एक है जो Google में एक नौसिखिया करता है। यहां अंतर की तालिका दी गई है:
| एसक्यूएल यूनियन | एसक्यूएल जॉइन | |
| क्या मिला हुआ है | पंक्तियाँ | कॉलम (कुंजी का उपयोग करके) |
| प्रति तालिका स्तंभों की संख्या | सभी तालिकाओं के लिए समान | परिवर्तनीय (सभी स्तंभों/तालिकाओं के लिए शून्य) |
मैं जिन सभी प्रोजेक्ट्स के साथ रहा हूं, उनमें ज्यादातर समय SQL JOIN लागू होता है। मेरे पास केवल कुछ मामले थे जो SQL यूनियन का उपयोग करते थे। लेकिन जैसा कि आपने अब तक देखा है, SQL UNION बेकार से बहुत दूर है।
<एच2>10. SQL UNION ALL, UNION से तेज़ हैपहले चित्र 2 और चित्र 4 में योजना आरेखों से पता चलता है कि अद्वितीय परिणाम सुनिश्चित करने के लिए UNION को एक अतिरिक्त ऑपरेटर की आवश्यकता है। इसलिए UNION ALL तेज है।
यह महत्वपूर्ण क्यों है?
आप, आपके उपयोगकर्ता, आपके ग्राहक, आपके बॉस, सभी त्वरित परिणाम चाहते हैं। यह जानकर कि UNION ALL, UNION से तेज़ है, आपको आश्चर्य होता है कि यदि आपको अद्वितीय संयुक्त परिणामों की आवश्यकता है तो क्या करें। इसका एक उपाय है, जैसा कि आप बाद में देखेंगे।
एसक्यूएल यूनियन ऑल बनाम यूनियन परफॉर्मेंस
चित्र 2 और चित्र 4 ने आपको पहले से ही एक विचार दिया है कि कौन सा तेज़ है। लेकिन उपयोग किए गए कोड नमूने एक छोटे से परिणाम सेट के साथ सरल हैं। आइए इसे आकर्षक बनाने के लिए लाखों रिकॉर्ड का उपयोग करके कुछ और तुलनाएं जोड़ें।
आरंभ करने के लिए, आइए डेटा तैयार करें:
SELECT TOP (2000000)
val = ROW_NUMBER() OVER (ORDER BY sod.SalesOrderDetailID)
INTO dbo.TestNumbers
FROM AdventureWorks.Sales.SalesOrderDetail sod
CROSS JOIN AdventureWorks.Sales.SalesOrderDetail sod2
यह 2 मिलियन रिकॉर्ड है। मुझे आशा है कि यह काफी सम्मोहक है। अब, अगले दो प्रश्न नीचे दिए गए हैं।
-- Using UNION ALL
SELECT
val
FROM TestNumbers tn
UNION ALL
SELECT
val
FROM TestNumbers tn
-- Using UNION
SELECT
val
FROM TestNumbers tn
UNION
SELECT
val
FROM TestNumbers tn
आइए इन प्रश्नों में शामिल प्रक्रियाओं की जांच तेजी से शुरू करें।
योजना आरेख विश्लेषण
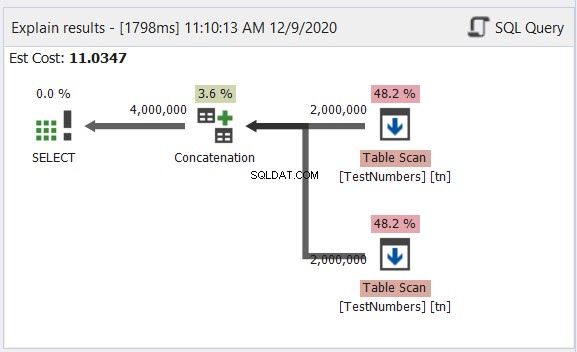
चित्र 12 में आरेख एक UNION ALL प्रक्रिया की तरह दिखता है। हालांकि, परिणाम 4 मिलियन संयुक्त परिणाम है। Concatenation ऑपरेटर से बाहर जाने वाला तीर देखें। फिर भी, यह आम तौर पर इसलिए होता है क्योंकि यह डुप्लिकेट के साथ डील नहीं करता है।
अब, चित्र 13 में UNION क्वेरी का आरेख देखें:
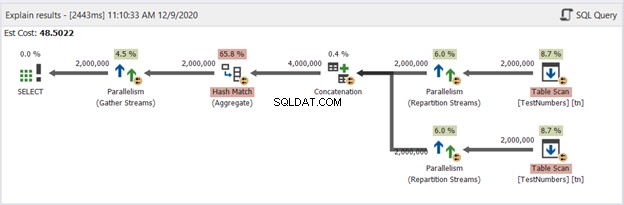
यह अब विशिष्ट नहीं है। चार मिलियन पंक्तियों में डुप्लिकेट को हटाने से निपटने के लिए योजना समानांतर क्वेरी योजना बन जाती है। समानांतर क्वेरी योजना का अर्थ है कि SQL सर्वर को प्रक्रिया को उसके लिए उपलब्ध प्रोसेसर कोर की संख्या से विभाजित करने की आवश्यकता है।
आइए इसकी व्याख्या करें, बाईं ओर जाने वाले दाएं ऑपरेटरों से शुरू होकर:
- चूंकि हम एक तालिका को स्वयं से जोड़ रहे हैं, SQL सर्वर को इसे दो बार पुनर्प्राप्त करने की आवश्यकता है। दो टेबल स्कैन देखें जिनमें से प्रत्येक में दो मिलियन रिकॉर्ड हैं।
- रिपार्टिशन स्ट्रीम ऑपरेटर अगले उपलब्ध थ्रेड में प्रत्येक पंक्ति के वितरण को नियंत्रित करेंगे।
- संयोजन परिणाम को दोगुना कर चार मिलियन कर देता है। यह अभी भी प्रोसेसर कोर की संख्या पर विचार कर रहा है।
- डुप्लिकेट को हटाने के लिए हैश मैच लागू होता है। यह 65.8% ऑपरेटर लागत के साथ एक महंगी प्रक्रिया है। परिणामस्वरूप, दो मिलियन रिकॉर्ड खारिज हो गए।
- गेदर स्ट्रीम प्रत्येक प्रोसेसर कोर या थ्रेड में किए गए परिणामों को एक में पुनः संयोजित करता है।
प्रक्रिया कई थ्रेड्स में विभाजित होने के बावजूद यह बहुत अधिक काम है। इसलिए, आप यह निष्कर्ष निकालेंगे कि यह धीमी गति से चलेगी। लेकिन क्या होगा यदि UNION ALL के साथ अद्वितीय रिकॉर्ड प्राप्त करने का कोई समाधान हो लेकिन इससे तेज़ हो?
अद्वितीय परिणाम लेकिन UNION ALL के साथ तेज़ सुधार - कैसे?
मैं तुम्हें प्रतीक्षा नहीं करवाऊंगा। यह रहा कोड:
SELECT DISTINCT
val
FROM
(
SELECT
val
FROM TestNumbers tn
UNION ALL
SELECT
val
FROM TestNumbers tn
) AS uniqtn
यह एक लंगड़ा समाधान हो सकता है। लेकिन चित्र 14 में इसका योजना आरेख देखें:
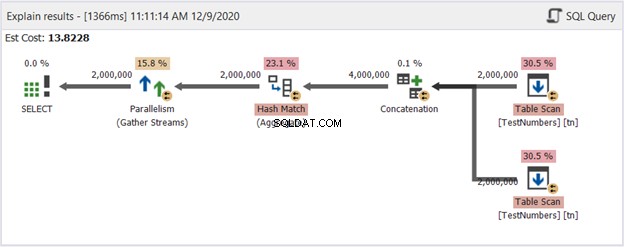
तो, क्या इसे बेहतर बना दिया? यदि आप इसकी तुलना चित्र 13 से करते हैं, तो आप देखते हैं कि पुनर्विभाजन स्ट्रीम संचालक चले गए हैं। हालाँकि, यह अभी भी काम पूरा करने के लिए कई थ्रेड्स का उपयोग करता है। दूसरी ओर, इसका तात्पर्य है कि क्वेरी ऑप्टिमाइज़र UNION का उपयोग करने वाली क्वेरी की तुलना में इस प्रक्रिया को करना आसान मानता है।
क्या हम सुरक्षित रूप से यह निष्कर्ष निकाल सकते हैं कि हमें यूनियन का उपयोग करने से बचना चाहिए और इसके बजाय इस दृष्टिकोण का उपयोग करना चाहिए? बिल्कुल भी नहीं! हमेशा निष्पादन योजना आरेख की जांच करें! यह हमेशा इस बात पर निर्भर करता है कि आप SQL सर्वर को आपको क्या देना चाहते हैं। यह केवल यह दर्शाता है कि यदि आप एक प्रदर्शन दीवार से टकराते हैं, तो आपको अपना क्वेरी दृष्टिकोण बदलने की आवश्यकता है।
I/O सांख्यिकी के बारे में कैसे?
SQL सर्वर को हमारे क्वेरी उदाहरणों को संसाधित करने के लिए कितने संसाधनों की आवश्यकता है, हम इसे खारिज नहीं कर सकते। इसलिए हमें उनके आँकड़ों की जाँच करने की भी आवश्यकता है। उपरोक्त तीन प्रश्नों की तुलना करने पर, हमें नीचे तार्किक पठन मिलता है:
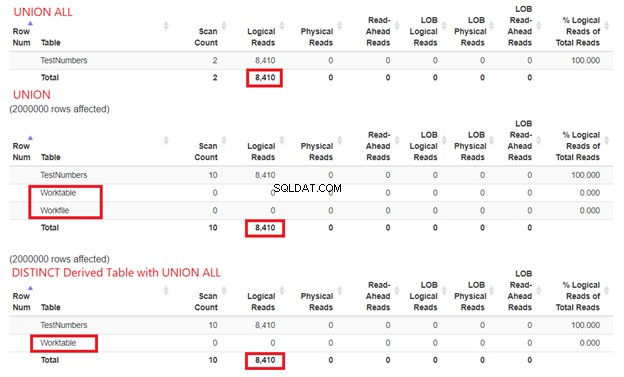
चित्र 15 से, हम अभी भी यह निष्कर्ष निकाल सकते हैं कि UNION ALL, UNION से तेज़ है, हालाँकि तार्किक पठन समान हैं। कार्यस्थल . की उपस्थिति और कार्यफ़ाइल tempdb . का उपयोग करके दिखाता है काम पूरा करने के लिए। इस बीच, जब हम UNION ALL के साथ व्युत्पन्न तालिका से SELECT DISTINCT का उपयोग करते हैं, तो tempdb UNION की तुलना में उपयोग कम है। यह आगे पुन:पुष्टि करता है कि योजना आरेखों से पहले का हमारा विश्लेषण सही है।
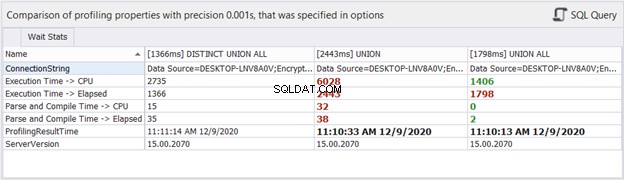
समय सांख्यिकी के बारे में कैसे?
हालांकि बीता हुआ समय हमारे द्वारा समान प्रश्नों के लिए किए जाने वाले प्रत्येक निष्पादन में बदल सकता है, यह हमें कुछ विचार दे सकता है और हमारे विश्लेषण में और सबूत जोड़ सकता है। dbForge Studio उपरोक्त तीन प्रश्नों के समय के अंतर को प्रदर्शित करता है। यह तुलना हमारे द्वारा किए गए पिछले विश्लेषण के अनुरूप है।
निष्कर्ष
SQL UNION और UNION ALL का उपयोग करने के लिए आपको जो चाहिए वह प्रदान करने के लिए हमने बहुत सारी पृष्ठभूमि को कवर किया। हो सकता है कि इस पोस्ट को पढ़ने के बाद आपको सब कुछ याद न हो, इसलिए इस पेज को बुकमार्क करना न भूलें।
अगर आपको पोस्ट पसंद आए तो इसे सोशल मीडिया पर शेयर करने में संकोच न करें।