[ भाग 1 | भाग 2 | भाग 3 | भाग 4 ]
इस श्रृंखला के भाग 3 में, मैंने IDENTITY . को चौड़ा करने से बचने के लिए दो समाधान दिखाए कॉलम - एक जो आपको केवल समय देता है, और दूसरा जो IDENTITY . को छोड़ देता है पूरी तरह से। पूर्व आपको बाहरी निर्भरताओं जैसे कि विदेशी कुंजी से निपटने से रोकता है, लेकिन बाद वाला अभी भी उस मुद्दे को संबोधित नहीं करता है। इस पोस्ट में, मैं उस दृष्टिकोण के बारे में विस्तार से बताना चाहता था जो मैं लेता अगर मुझे बिल्कुल bigint पर जाने की आवश्यकता होती , डाउनटाइम को कम करने के लिए आवश्यक था, और योजना बनाने के लिए बहुत समय था।
सभी संभावित अवरोधकों और न्यूनतम व्यवधान की आवश्यकता के कारण, दृष्टिकोण को थोड़ा जटिल के रूप में देखा जा सकता है, और यह केवल तभी अधिक हो जाता है जब अतिरिक्त विदेशी सुविधाओं का उपयोग किया जा रहा हो (जैसे, विभाजन, इन-मेमोरी ओएलटीपी, या प्रतिकृति) .
बहुत उच्च स्तर पर, दृष्टिकोण छाया तालिकाओं का एक सेट बनाना है, जहां सभी आवेषण तालिका की एक नई प्रतिलिपि (बड़े डेटा प्रकार के साथ) पर निर्देशित होते हैं, और तालिकाओं के दो सेटों का अस्तित्व उतना ही पारदर्शी होता है एप्लिकेशन और उसके उपयोगकर्ताओं के लिए जितना संभव हो सके।
अधिक बारीक स्तर पर, चरणों का सेट इस प्रकार होगा:
- सही डेटा प्रकारों के साथ तालिकाओं की छाया प्रतियां बनाएं।
- पैरामीटर के लिए बिगिंट का उपयोग करने के लिए संग्रहीत कार्यविधियों (या तदर्थ कोड) को बदलें। (इसके लिए पैरामीटर सूची से परे संशोधन की आवश्यकता हो सकती है, जैसे कि स्थानीय चर, अस्थायी तालिकाएँ, आदि, लेकिन यहाँ ऐसा नहीं है।)
- पुरानी तालिकाओं का नाम बदलें, और उन नामों के साथ दृश्य बनाएं जो पुरानी और नई तालिकाओं को मिलाते हैं।
- उन दृश्यों में ट्रिगर के बजाय डीएमएल संचालन को उचित तालिका (तालिकाओं) में उचित रूप से निर्देशित करने के लिए होगा, ताकि माइग्रेशन के दौरान डेटा को अभी भी संशोधित किया जा सके।
- इसके लिए SCHEMABINDING को किसी भी अनुक्रमित दृश्य से हटा दिया जाना चाहिए, मौजूदा विचारों को नई और पुरानी तालिकाओं के बीच संघ बनाने के लिए, और SCOPE_IDENTITY() पर निर्भर प्रक्रियाओं को संशोधित करने की आवश्यकता है।
- पुराने डेटा को टुकड़ों में नई टेबल में माइग्रेट करें।
- साफ़ करें, जिसमें शामिल हैं:
- अस्थायी दृश्यों को छोड़ना (जो INSTEAD OF ट्रिगर्स को छोड़ देगा)।
- नई तालिकाओं का नाम बदलकर मूल नाम करना।
- SCOPE_IDENTITY() पर वापस जाने के लिए संग्रहीत कार्यविधियों को ठीक करना।
- पुरानी, अब-खाली तालिकाओं को छोड़ना।
- SCHEMABINDING को इंडेक्स किए गए व्यू पर वापस लाना और क्लस्टर्ड इंडेक्स को फिर से बनाना।
यदि आप संग्रहीत कार्यविधियों के माध्यम से सभी डेटा एक्सेस को नियंत्रित कर सकते हैं, तो आप शायद अधिकांश विचारों और ट्रिगर से बच सकते हैं, लेकिन चूंकि वह परिदृश्य दुर्लभ है (और 100% पर भरोसा करना असंभव है), मैं कठिन मार्ग दिखाने जा रहा हूं।
प्रारंभिक स्कीमा
इस दृष्टिकोण को यथासंभव सरल रखने के प्रयास में, श्रृंखला में पहले उल्लेख किए गए कई अवरोधकों को संबोधित करते हुए, मान लें कि हमारे पास यह स्कीमा है:
CREATE TABLE dbo.Employees
(
EmployeeID int IDENTITY(1,1) PRIMARY KEY,
Name nvarchar(64) NOT NULL,
LunchGroup AS (CONVERT(tinyint, EmployeeID % 5))
);
GO
CREATE INDEX EmployeeName ON dbo.Employees(Name);
GO
CREATE VIEW dbo.LunchGroupCount
WITH SCHEMABINDING
AS
SELECT LunchGroup, MemberCount = COUNT_BIG(*)
FROM dbo.Employees
GROUP BY LunchGroup;
GO
CREATE UNIQUE CLUSTERED INDEX LGC ON dbo.LunchGroupCount(LunchGroup);
GO
CREATE TABLE dbo.EmployeeFile
(
EmployeeID int NOT NULL PRIMARY KEY
FOREIGN KEY REFERENCES dbo.Employees(EmployeeID),
Notes nvarchar(max) NULL
);
GO तो एक साधारण कार्मिक तालिका, एक संकुल पहचान स्तंभ के साथ, एक गैर-संकुल सूचकांक, पहचान स्तंभ के आधार पर एक गणना स्तंभ, एक अनुक्रमित दृश्य, और एक अलग एचआर / गंदगी तालिका जिसमें कार्मिक तालिका में एक विदेशी कुंजी है (I जरूरी नहीं कि मैं उस डिजाइन को प्रोत्साहित कर रहा हूं, बस इस उदाहरण के लिए इसका इस्तेमाल कर रहा हूं)। ये सभी चीजें हैं जो इस समस्या को और अधिक जटिल बनाती हैं यदि हमारे पास एक स्टैंडअलोन, स्वतंत्र तालिका होती।
उस स्कीमा के साथ, हमारे पास शायद कुछ संग्रहीत प्रक्रियाएं हैं जो सीआरयूडी जैसी चीजें करती हैं। ये किसी भी चीज़ से अधिक दस्तावेज़ीकरण के लिए हैं; मैं अंतर्निहित स्कीमा में परिवर्तन करने जा रहा हूँ जैसे कि इन प्रक्रियाओं को बदलना न्यूनतम होना चाहिए। यह इस तथ्य का अनुकरण करने के लिए है कि आपके अनुप्रयोगों से तदर्थ SQL को बदलना संभव नहीं हो सकता है, और आवश्यक नहीं भी हो सकता है (ठीक है, जब तक आप एक ORM का उपयोग नहीं कर रहे हैं जो तालिका बनाम दृश्य का पता लगा सकता है)।
CREATE PROCEDURE dbo.Employee_Add
@Name nvarchar(64),
@Notes nvarchar(max) = NULL
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.Employees(Name)
VALUES(@Name);
INSERT dbo.EmployeeFile(EmployeeID, Notes)
VALUES(SCOPE_IDENTITY(),@Notes);
END
GO
CREATE PROCEDURE dbo.Employee_Update
@EmployeeID int,
@Name nvarchar(64),
@Notes nvarchar(max)
AS
BEGIN
SET NOCOUNT ON;
UPDATE dbo.Employees
SET Name = @Name
WHERE EmployeeID = @EmployeeID;
UPDATE dbo.EmployeeFile
SET Notes = @Notes
WHERE EmployeeID = @EmployeeID;
END
GO
CREATE PROCEDURE dbo.Employee_Get
@EmployeeID int
AS
BEGIN
SET NOCOUNT ON;
SELECT e.EmployeeID, e.Name, e.LunchGroup, ed.Notes
FROM dbo.Employees AS e
INNER JOIN dbo.EmployeeFile AS ed
ON e.EmployeeID = ed.EmployeeID
WHERE e.EmployeeID = @EmployeeID;
END
GO
CREATE PROCEDURE dbo.Employee_Delete
@EmployeeID int
AS
BEGIN
SET NOCOUNT ON;
DELETE dbo.EmployeeFile WHERE EmployeeID = @EmployeeID;
DELETE dbo.Employees WHERE EmployeeID = @EmployeeID;
END
GO अब, मूल तालिकाओं में डेटा की 5 पंक्तियाँ जोड़ें:
EXEC dbo.Employee_Add @Name = N'Employee1', @Notes = 'Employee #1 is the best'; EXEC dbo.Employee_Add @Name = N'Employee2', @Notes = 'Fewer people like Employee #2'; EXEC dbo.Employee_Add @Name = N'Employee3', @Notes = 'Jury on Employee #3 is out'; EXEC dbo.Employee_Add @Name = N'Employee4', @Notes = '#4 is moving on'; EXEC dbo.Employee_Add @Name = N'Employee5', @Notes = 'I like #5';
चरण 1 - नई तालिकाएं
यहां हम टेबल की एक नई जोड़ी बनाएंगे, जिसमें कर्मचारी आईडी कॉलम के डेटा प्रकार, पहचान कॉलम के लिए प्रारंभिक बीज और नामों पर एक अस्थायी प्रत्यय को छोड़कर मूल को प्रतिबिंबित किया जाएगा:
CREATE TABLE dbo.Employees_New
(
EmployeeID bigint IDENTITY(2147483648,1) PRIMARY KEY,
Name nvarchar(64) NOT NULL,
LunchGroup AS (CONVERT(tinyint, EmployeeID % 5))
);
GO
CREATE INDEX EmployeeName_New ON dbo.Employees_New(Name);
GO
CREATE TABLE dbo.EmployeeFile_New
(
EmployeeID bigint NOT NULL PRIMARY KEY
FOREIGN KEY REFERENCES dbo.Employees_New(EmployeeID),
Notes nvarchar(max) NULL
); चरण 2 - प्रक्रिया पैरामीटर ठीक करें
यहां प्रक्रियाएं (और संभावित रूप से आपका तदर्थ कोड, जब तक कि यह पहले से ही बड़े पूर्णांक प्रकार का उपयोग नहीं कर रहा है) को एक बहुत ही मामूली बदलाव की आवश्यकता होगी ताकि भविष्य में वे एक पूर्णांक की ऊपरी सीमा से परे कर्मचारी आईडी मान स्वीकार कर सकें। जबकि आप तर्क दे सकते हैं कि यदि आप इन प्रक्रियाओं को बदलने जा रहे हैं, तो आप उन्हें नई तालिकाओं पर इंगित कर सकते हैं, मैं यह मामला बनाने की कोशिश कर रहा हूं कि आप मौजूदा, स्थायी में * न्यूनतम * घुसपैठ के साथ अंतिम लक्ष्य प्राप्त कर सकते हैं कोड।
ALTER PROCEDURE dbo.Employee_Update
@EmployeeID bigint, -- only change
@Name nvarchar(64),
@Notes nvarchar(max)
AS
BEGIN
SET NOCOUNT ON;
UPDATE dbo.Employees
SET Name = @Name
WHERE EmployeeID = @EmployeeID;
UPDATE dbo.EmployeeFile
SET Notes = @Notes
WHERE EmployeeID = @EmployeeID;
END
GO
ALTER PROCEDURE dbo.Employee_Get
@EmployeeID bigint -- only change
AS
BEGIN
SET NOCOUNT ON;
SELECT e.EmployeeID, e.Name, e.LunchGroup, ed.Notes
FROM dbo.Employees AS e
INNER JOIN dbo.EmployeeFile AS ed
ON e.EmployeeID = ed.EmployeeID
WHERE e.EmployeeID = @EmployeeID;
END
GO
ALTER PROCEDURE dbo.Employee_Delete
@EmployeeID bigint -- only change
AS
BEGIN
SET NOCOUNT ON;
DELETE dbo.EmployeeFile WHERE EmployeeID = @EmployeeID;
DELETE dbo.Employees WHERE EmployeeID = @EmployeeID;
END
GO चरण 3 - दृश्य और ट्रिगर
दुर्भाग्य से, यह *सब* चुपचाप नहीं किया जा सकता। हम अधिकांश संचालन समानांतर में और समवर्ती उपयोग को प्रभावित किए बिना कर सकते हैं, लेकिन SCHEMABINDING के कारण, अनुक्रमित दृश्य को बदलना पड़ता है और बाद में अनुक्रमणिका को फिर से बनाया जाता है।
यह किसी भी अन्य ऑब्जेक्ट के लिए सही है जो SCHEMABINDING का उपयोग करता है और हमारी किसी भी तालिका का संदर्भ देता है। मैं इसे ऑपरेशन की शुरुआत में एक गैर-अनुक्रमित दृश्य के रूप में बदलने की सलाह देता हूं, और प्रक्रिया में कई बार के बजाय सभी डेटा को माइग्रेट करने के बाद इंडेक्स का पुनर्निर्माण करना (क्योंकि तालिकाओं का कई बार नाम बदला जाएगा)। वास्तव में मैं जो करने जा रहा हूं वह प्रक्रिया की अवधि के लिए कर्मचारी तालिका के नए और पुराने संस्करणों को मिलाने के लिए दृश्य को बदलना है।
एक और चीज़ जो हमें करने की ज़रूरत है वह है SCOPE_IDENTITY() के बजाय अस्थायी रूप से @@ पहचान का उपयोग करने के लिए Employee_Add संग्रहीत कार्यविधि को बदलना। ऐसा इसलिए है क्योंकि INSTEAD OF ट्रिगर जो "कर्मचारियों" के लिए नए अपडेट को हैंडल करेगा, उसमें SCOPE_IDENTITY() मान की दृश्यता नहीं होगी। यह, निश्चित रूप से, मानता है कि टेबल में ट्रिगर्स के बाद नहीं है जो @@ पहचान को प्रभावित करेगा। उम्मीद है कि आप या तो इन प्रश्नों को एक संग्रहित प्रक्रिया के अंदर बदल सकते हैं (जहां आप केवल नई तालिका में INSERT को इंगित कर सकते हैं), या आपके एप्लिकेशन कोड को पहले स्थान पर SCOPE_IDENTITY() पर भरोसा करने की आवश्यकता नहीं है।
हम इसे SERIALIZABLE के तहत करने जा रहे हैं ताकि वस्तुओं के प्रवाह में होने पर कोई भी लेन-देन घुसने की कोशिश न करे। यह बड़े पैमाने पर केवल-मेटाडेटा संचालन का एक सेट है, इसलिए इसे त्वरित होना चाहिए।
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN TRANSACTION;
GO
-- first, remove schemabinding from the view so we can change the base table
ALTER VIEW dbo.LunchGroupCount
--WITH SCHEMABINDING -- this will silently drop the index
-- and will temp. affect performance
AS
SELECT LunchGroup, MemberCount = COUNT_BIG(*)
FROM dbo.Employees
GROUP BY LunchGroup;
GO
-- rename the tables
EXEC sys.sp_rename N'dbo.Employees', N'Employees_Old', N'OBJECT';
EXEC sys.sp_rename N'dbo.EmployeeFile', N'EmployeeFile_Old', N'OBJECT';
GO
-- the view above will be broken for about a millisecond
-- until the following union view is created:
CREATE VIEW dbo.Employees
WITH SCHEMABINDING
AS
SELECT EmployeeID = CONVERT(bigint, EmployeeID), Name, LunchGroup
FROM dbo.Employees_Old
UNION ALL
SELECT EmployeeID, Name, LunchGroup
FROM dbo.Employees_New;
GO
-- now the view will work again (but it will be slower)
CREATE VIEW dbo.EmployeeFile
WITH SCHEMABINDING
AS
SELECT EmployeeID = CONVERT(bigint, EmployeeID), Notes
FROM dbo.EmployeeFile_Old
UNION ALL
SELECT EmployeeID, Notes
FROM dbo.EmployeeFile_New;
GO
CREATE TRIGGER dbo.Employees_InsteadOfInsert
ON dbo.Employees
INSTEAD OF INSERT
AS
BEGIN
SET NOCOUNT ON;
-- just needs to insert the row(s) into the new copy of the table
INSERT dbo.Employees_New(Name) SELECT Name FROM inserted;
END
GO
CREATE TRIGGER dbo.Employees_InsteadOfUpdate
ON dbo.Employees
INSTEAD OF UPDATE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
-- need to cover multi-row updates, and the possibility
-- that any row may have been migrated already
UPDATE o SET Name = i.Name
FROM dbo.Employees_Old AS o
INNER JOIN inserted AS i
ON o.EmployeeID = i.EmployeeID;
UPDATE n SET Name = i.Name
FROM dbo.Employees_New AS n
INNER JOIN inserted AS i
ON n.EmployeeID = i.EmployeeID;
COMMIT TRANSACTION;
END
GO
CREATE TRIGGER dbo.Employees_InsteadOfDelete
ON dbo.Employees
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
-- a row may have been migrated already, maybe not
DELETE o FROM dbo.Employees_Old AS o
INNER JOIN deleted AS d
ON o.EmployeeID = d.EmployeeID;
DELETE n FROM dbo.Employees_New AS n
INNER JOIN deleted AS d
ON n.EmployeeID = d.EmployeeID;
COMMIT TRANSACTION;
END
GO
CREATE TRIGGER dbo.EmployeeFile_InsteadOfInsert
ON dbo.EmployeeFile
INSTEAD OF INSERT
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.EmployeeFile_New(EmployeeID, Notes)
SELECT EmployeeID, Notes FROM inserted;
END
GO
CREATE TRIGGER dbo.EmployeeFile_InsteadOfUpdate
ON dbo.EmployeeFile
INSTEAD OF UPDATE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
UPDATE o SET Notes = i.Notes
FROM dbo.EmployeeFile_Old AS o
INNER JOIN inserted AS i
ON o.EmployeeID = i.EmployeeID;
UPDATE n SET Notes = i.Notes
FROM dbo.EmployeeFile_New AS n
INNER JOIN inserted AS i
ON n.EmployeeID = i.EmployeeID;
COMMIT TRANSACTION;
END
GO
CREATE TRIGGER dbo.EmployeeFile_InsteadOfDelete
ON dbo.EmployeeFile
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
DELETE o FROM dbo.EmployeeFile_Old AS o
INNER JOIN deleted AS d
ON o.EmployeeID = d.EmployeeID;
DELETE n FROM dbo.EmployeeFile_New AS n
INNER JOIN deleted AS d
ON n.EmployeeID = d.EmployeeID;
COMMIT TRANSACTION;
END
GO
-- the insert stored procedure also has to be updated, temporarily
ALTER PROCEDURE dbo.Employee_Add
@Name nvarchar(64),
@Notes nvarchar(max) = NULL
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.Employees(Name)
VALUES(@Name);
INSERT dbo.EmployeeFile(EmployeeID, Notes)
VALUES(@@IDENTITY, @Notes);
-------^^^^^^^^^^------ change here
END
GO
COMMIT TRANSACTION; चरण 4 - पुराने डेटा को नई तालिका में माइग्रेट करें
हम संगामिति और लेन-देन लॉग दोनों पर प्रभाव को कम करने के लिए डेटा को टुकड़ों में माइग्रेट करने जा रहे हैं, मेरी एक पुरानी पोस्ट से बुनियादी तकनीक उधार लेते हुए, "बड़े डिलीट ऑपरेशन को टुकड़ों में तोड़ दें।" हम इन बैचों को SERIALIZABLE में भी निष्पादित करने जा रहे हैं, जिसका अर्थ है कि आप बैच आकार से सावधान रहना चाहेंगे, और मैंने संक्षिप्तता के लिए त्रुटि प्रबंधन को छोड़ दिया है।
CREATE TABLE #batches(EmployeeID int);
DECLARE @BatchSize int = 1; -- for this demo only
-- your optimal batch size will hopefully be larger
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
WHILE 1 = 1
BEGIN
INSERT #batches(EmployeeID)
SELECT TOP (@BatchSize) EmployeeID
FROM dbo.Employees_Old
WHERE EmployeeID NOT IN (SELECT EmployeeID FROM dbo.Employees_New)
ORDER BY EmployeeID;
IF @@ROWCOUNT = 0
BREAK;
BEGIN TRANSACTION;
SET IDENTITY_INSERT dbo.Employees_New ON;
INSERT dbo.Employees_New(EmployeeID, Name)
SELECT o.EmployeeID, o.Name
FROM #batches AS b
INNER JOIN dbo.Employees_Old AS o
ON b.EmployeeID = o.EmployeeID;
SET IDENTITY_INSERT dbo.Employees_New OFF;
INSERT dbo.EmployeeFile_New(EmployeeID, Notes)
SELECT o.EmployeeID, o.Notes
FROM #batches AS b
INNER JOIN dbo.EmployeeFile_Old AS o
ON b.EmployeeID = o.EmployeeID;
DELETE o FROM dbo.EmployeeFile_Old AS o
INNER JOIN #batches AS b
ON b.EmployeeID = o.EmployeeID;
DELETE o FROM dbo.Employees_Old AS o
INNER JOIN #batches AS b
ON b.EmployeeID = o.EmployeeID;
COMMIT TRANSACTION;
TRUNCATE TABLE #batches;
-- monitor progress
SELECT total = (SELECT COUNT(*) FROM dbo.Employees),
original = (SELECT COUNT(*) FROM dbo.Employees_Old),
new = (SELECT COUNT(*) FROM dbo.Employees_New);
-- checkpoint / backup log etc.
END
DROP TABLE #batches; परिणाम:
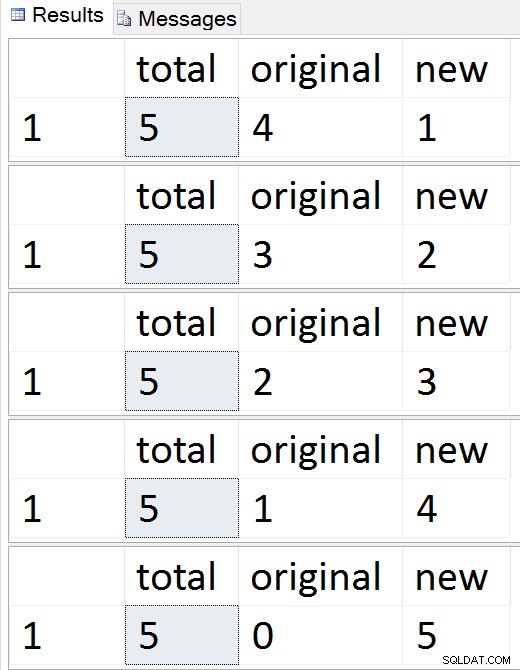 पंक्तियों को एक-एक करके माइग्रेट होते देखें
पंक्तियों को एक-एक करके माइग्रेट होते देखें
उस क्रम के दौरान किसी भी समय, आप इंसर्ट, अपडेट और डिलीट का परीक्षण कर सकते हैं, और उन्हें उचित तरीके से हैंडल किया जाना चाहिए। एक बार माइग्रेशन पूरा हो जाने पर, आप शेष प्रक्रिया पर आगे बढ़ सकते हैं।
चरण 5 - साफ़ करें
अस्थायी रूप से बनाई गई वस्तुओं को साफ करने और कर्मचारियों / कर्मचारी फ़ाइल को उचित, प्रथम श्रेणी के नागरिकों के रूप में बहाल करने के लिए चरणों की एक श्रृंखला की आवश्यकता होती है। इनमें से अधिकतर आदेश केवल मेटाडेटा संचालन हैं - अनुक्रमित दृश्य पर संकुल अनुक्रमणिका बनाने के अपवाद के साथ, वे सभी तात्कालिक होने चाहिए।
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN TRANSACTION;
-- drop views and restore name of new tables
DROP VIEW dbo.EmployeeFile; --v
DROP VIEW dbo.Employees; -- this will drop the instead of triggers
EXEC sys.sp_rename N'dbo.Employees_New', N'Employees', N'OBJECT';
EXEC sys.sp_rename N'dbo.EmployeeFile_New', N'EmployeeFile', N'OBJECT';
GO
-- put schemabinding back on the view, and remove the union
ALTER VIEW dbo.LunchGroupCount
WITH SCHEMABINDING
AS
SELECT LunchGroup, MemberCount = COUNT_BIG(*)
FROM dbo.Employees
GROUP BY LunchGroup;
GO
-- change the procedure back to SCOPE_IDENTITY()
ALTER PROCEDURE dbo.Employee_Add
@Name nvarchar(64),
@Notes nvarchar(max) = NULL
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.Employees(Name)
VALUES(@Name);
INSERT dbo.EmployeeFile(EmployeeID, Notes)
VALUES(SCOPE_IDENTITY(), @Notes);
END
GO
COMMIT TRANSACTION;
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
-- drop the old (now empty) tables
-- and create the index on the view
-- outside the transaction
DROP TABLE dbo.EmployeeFile_Old;
DROP TABLE dbo.Employees_Old;
GO
-- only portion that is absolutely not online
CREATE UNIQUE CLUSTERED INDEX LGC ON dbo.LunchGroupCount(LunchGroup);
GO . पर इस बिंदु पर, सब कुछ सामान्य संचालन पर वापस आ जाना चाहिए, हालांकि आप प्रमुख स्कीमा परिवर्तनों के बाद विशिष्ट रखरखाव गतिविधियों पर विचार करना चाह सकते हैं, जैसे कि आंकड़े अपडेट करना, अनुक्रमणिका का पुनर्निर्माण करना, या कैश से योजनाओं को निकालना।
निष्कर्ष
एक साधारण समस्या क्या होनी चाहिए, यह एक बहुत ही जटिल समाधान है। मुझे आशा है कि किसी बिंदु पर SQL सर्वर पहचान संपत्ति को जोड़ने/निकालने, नए लक्ष्य डेटा प्रकारों के साथ अनुक्रमणिका को पुनर्निर्माण करने और रिश्ते को त्यागने के बिना रिश्ते के दोनों किनारों पर कॉलम बदलने जैसी चीजें करना संभव बनाता है। इस बीच, मुझे यह जानने में दिलचस्पी होगी कि क्या यह समाधान आपकी मदद करता है, या यदि आपके पास कोई अलग दृष्टिकोण है।
मेरे दृष्टिकोण की जांच में विवेक की मदद करने के लिए जेम्स लुपोल्ट (@jlupoltsql) के लिए बड़ा चिल्लाहट, और इसे अपने स्वयं के वास्तविक तालिकाओं में से एक पर अंतिम परीक्षण में डाल दिया। (यह अच्छा रहा। धन्यवाद जेम्स!)
—
[ भाग 1 | भाग 2 | भाग 3 | भाग 4 ]