सबसे अच्छा परिदृश्य यह है कि, डेटाबेस विफलता के मामले में, आपके पास एक अच्छी आपदा रिकवरी योजना (डीआरपी) और एक स्वचालित विफलता प्रक्रिया के साथ एक अत्यधिक उपलब्ध वातावरण है, लेकिन ... यदि यह विफल हो जाता है तो क्या होता है कुछ अप्रत्याशित कारण? क्या होगा यदि आपको मैन्युअल फ़ेलओवर करने की आवश्यकता है? इस ब्लॉग में, यदि आप अपने डेटाबेस को विफल करना चाहते हैं तो हम कुछ अनुशंसाओं का पालन करेंगे।
सत्यापन जांच
कोई भी परिवर्तन करने से पहले, आपको कुछ बुनियादी बातों को सत्यापित करना होगा ताकि विफलता प्रक्रिया के बाद नई समस्याओं से बचा जा सके।
प्रतिकृति स्थिति
यह संभव हो सकता है कि, विफलता के समय, नेटवर्क विफलता, उच्च लोड, या किसी अन्य समस्या के कारण स्लेव नोड अप-टू-डेट न हो, इसलिए आपको यह सुनिश्चित करने की आवश्यकता है कि आपका दास के पास सभी (या लगभग सभी) जानकारी है। यदि आपके पास एक से अधिक स्लेव नोड हैं, तो आपको यह भी जांचना चाहिए कि कौन सा सबसे उन्नत नोड है और इसे फ़ेलओवर के लिए चुनें।
उदाहरण:आइए मारियाडीबी सर्वर में प्रतिकृति स्थिति की जांच करें।
MariaDB [(none)]> SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.100.110
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000014
Read_Master_Log_Pos: 339
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 635
Relay_Master_Log_File: binlog.000014
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Last_Errno: 0
Skip_Counter: 0
Exec_Master_Log_Pos: 339
Relay_Log_Space: 938
Until_Condition: None
Until_Log_Pos: 0
Master_SSL_Allowed: No
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_SQL_Errno: 0
Replicate_Ignore_Server_Ids:
Master_Server_Id: 3001
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 0-3001-20
Parallel_Mode: conservative
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it
Slave_DDL_Groups: 0
Slave_Non_Transactional_Groups: 0
Slave_Transactional_Groups: 0
1 row in set (0.000 sec)PostgreSQL के मामले में, यह थोड़ा अलग है क्योंकि आपको WAL की स्थिति की जांच करने और लागू की गई तुलना की तुलना करने की आवश्यकता होती है।
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn()=pg_last_wal_replay_lsn()
postgres-# THEN 0
postgres-# ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
postgres-# END AS log_delay;
log_delay
-----------
0
(1 row)क्रेडेंशियल्स
फेलओवर चलाने से पहले, आपको यह जांचना होगा कि क्या आपका एप्लिकेशन/उपयोगकर्ता मौजूदा क्रेडेंशियल के साथ आपके नए मास्टर तक पहुंचने में सक्षम होंगे। यदि आप अपने डेटाबेस उपयोगकर्ताओं की नकल नहीं कर रहे हैं, तो हो सकता है कि क्रेडेंशियल बदल दिए गए हों, इसलिए किसी भी बदलाव से पहले आपको उन्हें स्लेव नोड्स में अपडेट करना होगा।
उदा:आप एक मारियाडीबी/MySQL सर्वर में उपयोगकर्ता क्रेडेंशियल्स की जांच करने के लिए mysql डेटाबेस में उपयोगकर्ता तालिका को क्वेरी कर सकते हैं:
MariaDB [(none)]> SELECT Host,User,Password FROM mysql.user;
+-----------------+--------------+-------------------------------------------+
| Host | User | Password |
+-----------------+--------------+-------------------------------------------+
| localhost | root | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| localhost | mysql | invalid |
| 127.0.0.1 | backupuser | *AC01ED53FA8443BFD3FC7C448F78A6F2C26C3C38 |
| 192.168.100.100 | cmon | *F80B5EE41D1FB1FA67D83E96FCB1638ABCFB86E2 |
| 127.0.0.1 | root | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| ::1 | root | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| localhost | backupuser | *AC01ED53FA8443BFD3FC7C448F78A6F2C26C3C38 |
| 192.168.100.112 | user1 | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| localhost | cmonexporter | *0F7AD3EAF21E28201D311384753810C5066B0964 |
| 127.0.0.1 | cmonexporter | *0F7AD3EAF21E28201D311384753810C5066B0964 |
| ::1 | cmonexporter | *0F7AD3EAF21E28201D311384753810C5066B0964 |
| 192.168.100.110 | rpl_user | *EEA7B018B16E0201270B3CDC0AF8FC335048DC63 |
+-----------------+--------------+-------------------------------------------+
12 rows in set (0.001 sec)पोस्टग्रेएसक्यूएल के मामले में, आप भूमिकाओं को जानने के लिए '\du' कमांड का उपयोग कर सकते हैं, और आपको उपयोगकर्ता पहुंच (क्रेडेंशियल नहीं) को प्रबंधित करने के लिए pg_hba.conf कॉन्फ़िगरेशन फ़ाइल को भी देखना होगा। तो:
postgres=# \du
List of roles
Role name | Attributes | Member of
------------------+------------------------------------------------------------+-----------
admindb | Superuser, Create role, Create DB | {}
cmon_replication | Replication | {}
cmonexporter | | {}
postgres | Superuser, Create role, Create DB, Replication, Bypass RLS | {}
s9smysqlchk | Superuser, Create role, Create DB | {}और pg_hba.conf:
# TYPE DATABASE USER ADDRESS METHOD
host replication cmon_replication localhost md5
host replication cmon_replication 127.0.0.1/32 md5
host all s9smysqlchk localhost md5
host all s9smysqlchk 127.0.0.1/32 md5
local all all trust
host all all 127.0.0.1/32 trustनेटवर्क/फ़ायरवॉल एक्सेस
आपके नए मास्टर तक पहुंचने के लिए केवल क्रेडेंशियल ही संभावित समस्या नहीं है। यदि नोड किसी अन्य डेटासेंटर में है, या आपके पास ट्रैफ़िक फ़िल्टर करने के लिए एक स्थानीय फ़ायरवॉल है, तो आपको यह जांचना होगा कि क्या आपको इसे एक्सेस करने की अनुमति है या यहां तक कि यदि आपके पास नए मास्टर नोड तक पहुंचने के लिए नेटवर्क मार्ग है।
उदा:iptables. आइए नेटवर्क से ट्रैफ़िक को 167.124.57.0/24 पर आने दें और इसे जोड़ने के बाद वर्तमान नियमों की जाँच करें:
$ iptables -A INPUT -s 167.124.57.0/24 -m state --state NEW -j ACCEPT
$ iptables -L -n
Chain INPUT (policy ACCEPT)
target prot opt source destination
ACCEPT all -- 167.124.57.0/24 0.0.0.0/0 state NEW
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destinationउदा:मार्ग। मान लें कि आपका नया मास्टर नोड नेटवर्क 10.0.0.0/24 में है, आपका एप्लिकेशन सर्वर 192.168.100.0/24 में है, और आप 192.168.100.100 का उपयोग करके दूरस्थ नेटवर्क तक पहुंच सकते हैं, इसलिए अपने एप्लिकेशन सर्वर में, संबंधित मार्ग जोड़ें:
$ route add -net 10.0.0.0/24 gw 192.168.100.100
$ route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.100.1 0.0.0.0 UG 0 0 0 eth0
10.0.0.0 192.168.100.100 255.255.255.0 UG 0 0 0 eth0
169.254.0.0 0.0.0.0 255.255.0.0 U 1027 0 0 eth0
192.168.100.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0कार्रवाई के बिंदु
सभी उल्लिखित बिंदुओं की जांच करने के बाद, आपको अपने डेटाबेस को विफल करने के लिए कार्रवाई करने के लिए तैयार रहना चाहिए।
नया आईपी पता
जैसे ही आप स्लेव नोड को बढ़ावा देंगे, मास्टर आईपी पता बदल जाएगा, इसलिए आपको इसे अपने एप्लिकेशन या क्लाइंट एक्सेस में बदलना होगा।
लोड बैलेंसर का उपयोग करना इस समस्या/परिवर्तन से बचने का एक शानदार तरीका है। फ़ेलओवर प्रक्रिया के बाद, लोड बैलेंसर पुराने मास्टर को ऑफ़लाइन के रूप में पहचान लेगा और (कॉन्फ़िगरेशन पर निर्भर करता है) उस पर लिखने के लिए नए को ट्रैफ़िक भेज देगा, इसलिए आपको अपने आवेदन में कुछ भी बदलने की आवश्यकता नहीं है।
उदा:आइए एक HAProxy कॉन्फ़िगरेशन के लिए एक उदाहरण देखें:
listen haproxy_5433
bind *:5433
mode tcp
timeout client 10800s
timeout server 10800s
balance leastconn
option tcp-check
server 192.168.100.119 192.168.100.119:5432 check
server 192.168.100.120 192.168.100.120:5432 checkइस मामले में, यदि एक नोड बंद है, तो HAProxy वहां ट्रैफ़िक नहीं भेजेगा और केवल उपलब्ध नोड को ट्रैफ़िक भेजेगा।
स्लेव नोड्स को फिर से कॉन्फ़िगर करें
यदि आपके पास एक से अधिक दास नोड हैं, तो उनमें से एक को बढ़ावा देने के बाद, आपको नए मास्टर से जुड़ने के लिए शेष दासों को फिर से कॉन्फ़िगर करना होगा। नोड्स की संख्या के आधार पर यह एक समय लेने वाला कार्य हो सकता है।
बैकअप सत्यापित और कॉन्फ़िगर करें
आपके पास सब कुछ होने के बाद (नए मास्टर पदोन्नत, दास पुन:कॉन्फ़िगर किए गए, नए मास्टर में आवेदन लेखन), एक नई समस्या को रोकने के लिए आवश्यक कार्रवाई करना महत्वपूर्ण है, इसलिए बैकअप आवश्यक हैं यह कदम। संभवत:घटना से पहले आपके पास बैकअप नीति चल रही थी (यदि नहीं, तो आपको इसे सुनिश्चित करने की आवश्यकता है), इसलिए आपको यह जांचना होगा कि बैकअप अभी भी चल रहे हैं या वे नई टोपोलॉजी में करेंगे। यह संभव हो सकता है कि आपके पास पुराने मास्टर पर चल रहे बैकअप थे, या स्लेव नोड का उपयोग कर रहे थे जो अभी मास्टर है, इसलिए आपको यह सुनिश्चित करने के लिए इसे जांचना होगा कि आपकी बैकअप नीति परिवर्तनों के बाद भी काम करेगी।
डेटाबेस निगरानी
जब आप एक विफलता प्रक्रिया करते हैं, तो प्रक्रिया के पहले, दौरान और बाद में निगरानी आवश्यक है। इसके साथ, आप किसी समस्या के बिगड़ने से पहले उसे रोक सकते हैं, फ़ेलओवर के दौरान किसी अनपेक्षित समस्या का पता लगा सकते हैं, या यह भी जान सकते हैं कि उसके बाद कुछ गलत हुआ है या नहीं। उदाहरण के लिए, आपको सक्रिय कनेक्शनों की संख्या की जांच करके निगरानी करनी चाहिए कि क्या आपका एप्लिकेशन आपके नए मास्टर तक पहुंच सकता है।
मॉनिटर करने के लिए प्रमुख मीट्रिक
आइए देखते हैं कुछ सबसे महत्वपूर्ण मीट्रिक जिन्हें ध्यान में रखा जाना चाहिए:
- प्रतिकृति अंतराल
- प्रतिकृति स्थिति
- कनेक्शन की संख्या
- नेटवर्क उपयोग/त्रुटियां
- सर्वर लोड (CPU, मेमोरी, डिस्क)
- डेटाबेस और सिस्टम लॉग
रोलबैक
बेशक, अगर कुछ गलत हुआ, तो आपको वापस रोल करने में सक्षम होना चाहिए। पुराने नोड पर यातायात को अवरुद्ध करना और इसे यथासंभव अलग रखना इसके लिए एक अच्छी रणनीति हो सकती है, इसलिए यदि आपको रोलबैक करने की आवश्यकता है, तो आपके पास पुराना नोड उपलब्ध होगा। यदि रोलबैक कुछ मिनटों के बाद होता है, तो ट्रैफ़िक के आधार पर, आपको संभवतः इन मिनटों का डेटा पुराने मास्टर में डालने की आवश्यकता होगी, इसलिए सुनिश्चित करें कि आपके पास अपना अस्थायी मास्टर नोड भी उपलब्ध है और इस जानकारी को लेने और इसे वापस लागू करने के लिए अलग है। ।
ClusterControl के साथ स्वचालित विफलता प्रक्रिया
एक फ़ेलओवर करने के लिए इन सभी आवश्यक कार्यों को देखते हुए, शायद आप इसे स्वचालित करना चाहते हैं और इस सभी मैन्युअल कार्य से बचना चाहते हैं। इसके लिए, आप कुछ सुविधाओं का लाभ उठा सकते हैं जो क्लस्टरकंट्रोल आपको विभिन्न डेटाबेस तकनीकों के लिए पेश कर सकता है, जैसे ऑटो-रिकवरी, बैकअप, उपयोगकर्ता प्रबंधन, निगरानी, अन्य सुविधाओं के बीच, सभी एक ही सिस्टम से।
ClusterControl से आप प्रतिकृति स्थिति और उसके अंतराल को सत्यापित कर सकते हैं, क्रेडेंशियल बना या संशोधित कर सकते हैं, नेटवर्क और होस्ट की स्थिति जान सकते हैं, और और भी अधिक सत्यापन कर सकते हैं।
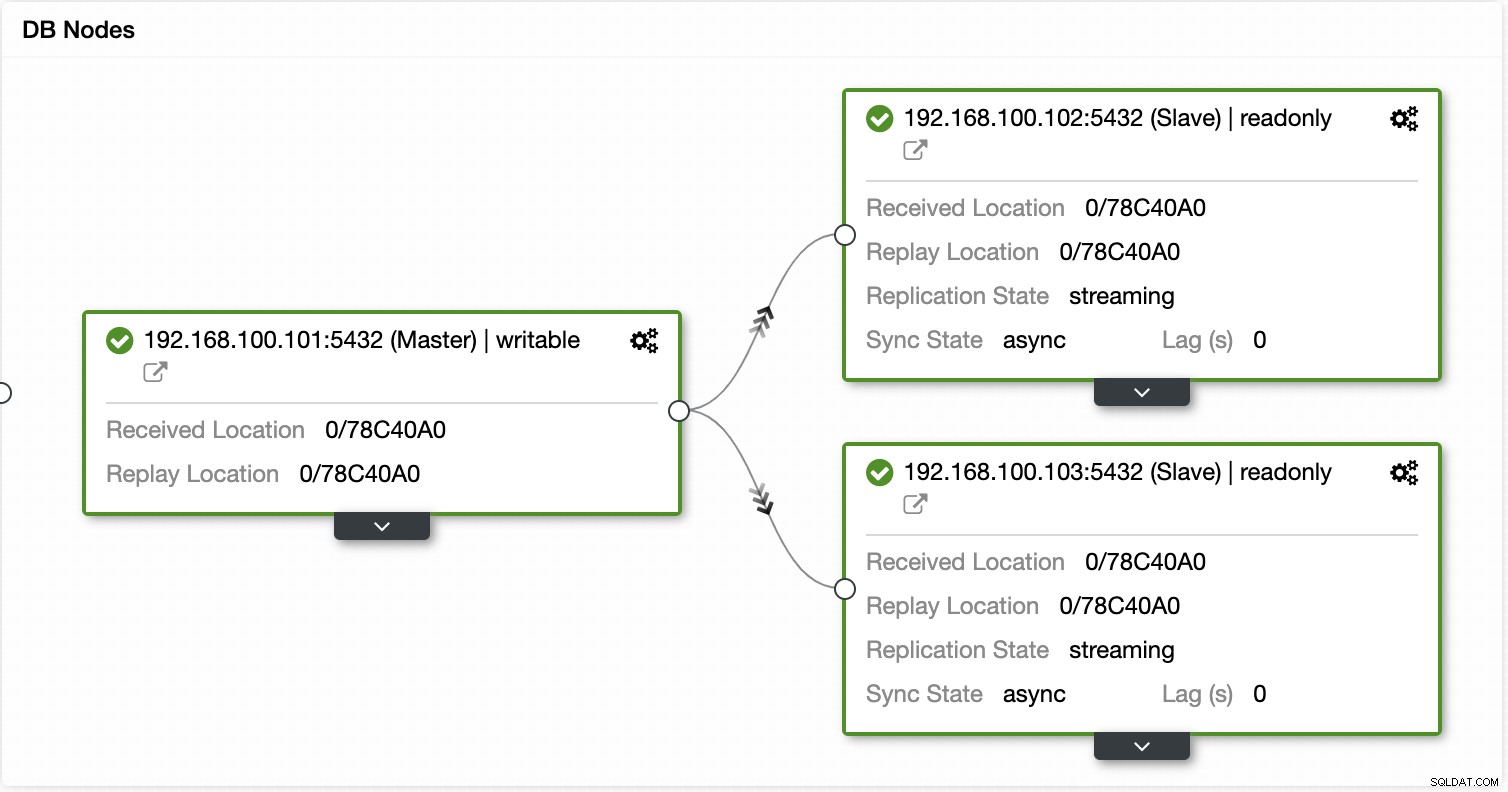
ClusterControl का उपयोग करके आप विभिन्न क्लस्टर और नोड क्रियाएं भी कर सकते हैं, जैसे स्लेव को बढ़ावा देना , डेटाबेस और सर्वर को पुनरारंभ करें, डेटाबेस नोड्स जोड़ें या निकालें, लोड बैलेंसर नोड्स जोड़ें या निकालें, एक प्रतिकृति दास का पुनर्निर्माण करें, और बहुत कुछ।
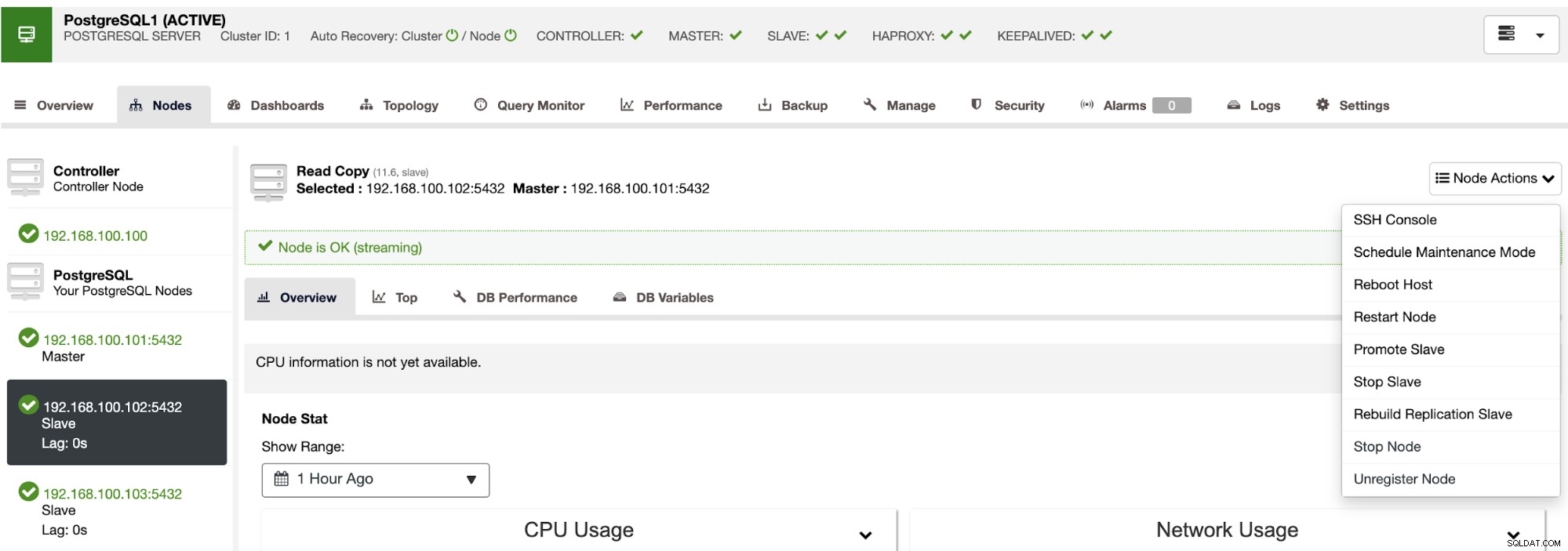
इन कार्रवाइयों का उपयोग करके, यदि आवश्यक हो, तो पुनर्निर्माण और प्रचार करके आप अपने फ़ेलओवर को रोलबैक भी कर सकते हैं पिछला मास्टर।
ClusterControl में निगरानी और अलर्ट करने वाली सेवाएं हैं जो आपको यह जानने में मदद करती हैं कि क्या हो रहा है या यहां तक कि अगर पहले कुछ हुआ था।
आप अधिक उपयोगकर्ता-अनुकूल दृश्य के लिए डैशबोर्ड अनुभाग का भी उपयोग कर सकते हैं आपके सिस्टम की स्थिति के बारे में।
निष्कर्ष
एक मास्टर डेटाबेस विफलता के मामले में, आप ASAP आवश्यक कार्रवाई करने के लिए सभी जानकारी रखना चाहेंगे। एक अच्छा डीआरपी होना आपके सिस्टम को हर समय (या लगभग सभी) चालू रखने की कुंजी है। इस डीआरपी में कंपनी के लिए एक स्वीकार्य आरटीओ (रिकवरी टाइम ऑब्जेक्टिव) होने के लिए एक अच्छी तरह से प्रलेखित विफलता प्रक्रिया शामिल होनी चाहिए।