जीवन बीमा एक ऐसी चीज है जिसकी हम सभी आशा करते हैं कि हमें इसकी आवश्यकता नहीं होगी, लेकिन जैसा कि हम जानते हैं, जीवन अप्रत्याशित है। इस लेख में, हम एक डेटा मॉडल तैयार करने पर ध्यान केंद्रित करेंगे जिसका उपयोग एक जीवन बीमा कंपनी अपनी जानकारी संग्रहीत करने के लिए कर सकती है।
जीवन बीमा एक अवधारणा के रूप में
जीवन बीमा कंपनी के लिए वास्तविक डेटा मॉडल पर चर्चा शुरू करने से पहले, हम संक्षेप में खुद को याद दिलाएंगे कि बीमा क्या है और यह कैसे काम करता है, इसलिए हमें इस बात का बेहतर अंदाजा है कि हम किसके साथ काम कर रहे हैं।
बीमा काफी पुरानी अवधारणा है जो मध्य युग से भी पहले की है, जब कई गिल्ड अप्रत्याशित परिस्थितियों में अपने सदस्यों की सुरक्षा के लिए नीतियों की पेशकश करते थे। यहां तक कि प्रसिद्ध खगोलशास्त्री, गणितज्ञ, वैज्ञानिक और आविष्कारक एडमंड हैली ने भी बीमा में काम किया, आंकड़ों और मृत्यु दर पर काम किया, जिसने आधुनिक बीमा मॉडल की रीढ़ बनाई।
आपको बीमा के लिए भुगतान क्यों करना चाहिए? यह विचार काफी सरल है - आप बीमा कंपनी की गारंटी के बदले में एक निश्चित राशि (प्रीमियम) का भुगतान करते हैं कि अगर आपको या आपकी संपत्ति के साथ कुछ अप्रत्याशित होता है तो आपको या आपके परिवार को आर्थिक रूप से मुआवजा दिया जाएगा। जीवन बीमा पॉलिसी के मामले में, आप एक लाभार्थी को नामित करते हैं जो आपकी मृत्यु की स्थिति में एक राशि (लाभ) प्राप्त करेगा। विचार यह है कि यह पैसा उन्हें अपने नुकसान से उबरने में मदद करेगा, खासकर अगर आपकी मृत्यु से कोई वित्तीय समस्या पैदा होती है।
बेशक, बीमा कंपनियां आम तौर पर प्रीमियम और शेयर बाजार में आपके पैसे का निवेश करने से होने वाले लाभों की तुलना में बहुत कम भुगतान करती हैं। अन्यथा, वे दिवालिया हो जाएंगे, और पूरी व्यवस्था चरमरा जाएगी!
यह काफी हद तक इसका सार है। अब जबकि हमें यह सब मिल गया है, आइए आगे बढ़ते हैं और एक सामान्य जीवन बीमा कंपनी के डेटा मॉडल पर एक नज़र डालते हैं।
डेटा मॉडल:अवलोकन
हम जिस डेटा मॉडल के साथ काम कर रहे हैं, उसमें पांच विषय क्षेत्र शामिल हैं:
- कर्मचारी
- उत्पाद
- ग्राहक
- ऑफ़र
- भुगतान
हम इनमें से प्रत्येक अनुभाग को ऊपर सूचीबद्ध किए गए क्रम में अधिक विस्तार से कवर करेंगे।
विषय क्षेत्र #1:कर्मचारी
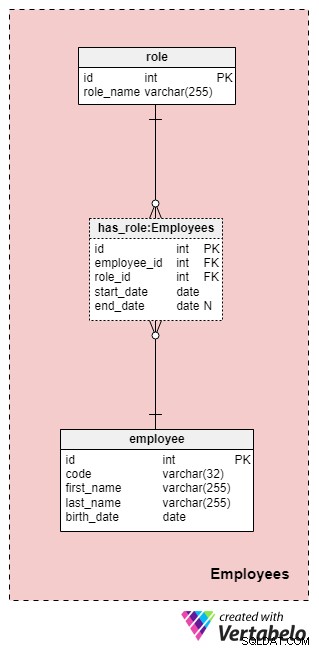
यह क्षेत्र आवश्यक रूप से इस डेटा मॉडल के लिए विशिष्ट नहीं है, लेकिन अभी भी बहुत महत्वपूर्ण है क्योंकि इसमें शामिल तालिकाओं को अन्य विषय क्षेत्रों द्वारा संदर्भित किया जाएगा। हमारे बीमा कंपनी डेटा मॉडल के प्रयोजनों के लिए, हमें निश्चित रूप से यह जानना होगा कि किसने क्या कार्रवाई की (उदाहरण के लिए, ग्राहक/ग्राहक के साथ काम करते समय हमारी कंपनी का प्रतिनिधित्व किसने किया, पॉलिसी पर हस्ताक्षर करने वाले, और इसी तरह)।
कंपनी के सभी कर्मचारियों की सूची employee टेबल। प्रत्येक कर्मचारी के लिए, हम निम्नलिखित जानकारी संग्रहीत करेंगे:
code- एक अनूठी कुंजी जो एक कर्मचारी की पहचान करती है। चूंकि कोड का उपयोग अन्य तालिकाओं में एक विशेषता के रूप में किया जाएगा, यह इस तालिका में एक वैकल्पिक कुंजी के रूप में काम करेगा।first_nameऔरlast_name— कर्मचारी के प्रथम और अंतिम नाम, क्रमशः।birth_date— कर्मचारी की जन्म तिथि।
बेशक, हम निश्चित रूप से इस तालिका में कई अन्य कर्मचारी-संबंधित विशेषताओं को शामिल कर सकते हैं, लेकिन ये चार अभी के लिए पर्याप्त से अधिक हैं। हम पूरे लेख में इस पैटर्न का पालन करेंगे और चीजों को यथासंभव सरल रखने की कोशिश करेंगे, लेकिन ध्यान दें कि आप अतिरिक्त जानकारी शामिल करने के लिए निश्चित रूप से इस डेटा मॉडल का विस्तार कर सकते हैं।
चूंकि कर्मचारी किसी भी समय हमारी कंपनी में अपनी भूमिकाएं बदल सकते हैं, हमें कंपनी की भूमिकाओं का प्रतिनिधित्व करने के लिए एक शब्दकोश तालिका और मूल्यों को संग्रहीत करने के लिए एक तालिका की आवश्यकता होगी। हमारी जीवन बीमा कंपनी में कर्मचारियों द्वारा ग्रहण की जा सकने वाली सभी संभावित भूमिकाओं की सूची role शब्दकोश। इसमें केवल एक विशेषता है जिसका नाम role_name . है जिसमें विशिष्ट रूप से पहचान करने वाले मान शामिल हैं।
हम has_role टेबल। विदेशी कुंजियों के अलावा employee_id और role_id , हम दो मान संग्रहीत करेंगे:start_date और end_date . ये दो मान उस सीमा को दर्शाते हैं जिसमें किसी विशेष कर्मचारी के लिए यह कंपनी की भूमिका सक्रिय थी। end_date इस कर्मचारी की भूमिका के लिए अंतिम तिथि निर्धारित होने तक शून्य का मान होगा। इस तालिका के लिए वैकल्पिक कुंजी employee_id . का संयोजन है , role_id , और start_date . एक ही कर्मचारी के लिए एक ही भूमिका की नकल से बचने के लिए, जब भी हम तालिका में एक नया रिकॉर्ड जोड़ते हैं या किसी मौजूदा को अपडेट करते हैं, तो हमें किसी भी ओवरलैप के लिए प्रोग्रामेटिक रूप से जांच करनी होगी।
विषय क्षेत्र #2:उत्पाद
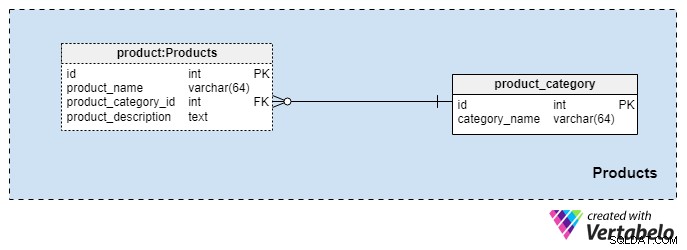
यह विषय क्षेत्र काफी छोटा है और इसमें केवल दो टेबल हैं। इन तालिकाओं के मान हमारे अन्य विषय क्षेत्रों के लिए पूर्वापेक्षाएँ हैं, इसलिए हम इन पर संक्षेप में चर्चा करेंगे।
product_category शब्दकोश उत्पादों की सबसे सामान्य श्रेणियों को संग्रहीत करता है जिन्हें हम अपने ग्राहकों को पेश करने की योजना बनाते हैं। इस तालिका में हम जो एकमात्र मूल्य संग्रहीत करेंगे, वह है अद्वितीय category_name हमारे द्वारा प्रदान किए जाने वाले बीमा के प्रकार को दर्शाने के लिए, जो व्यक्तिगत जीवन बीमा, पारिवारिक जीवन बीमा आदि हो सकता है।
हम product टेबल। यह तालिका हमारे द्वारा बेचे जाने वाले वास्तविक उत्पादों का प्रतिनिधित्व करती है न कि उनकी श्रेणियों को। जैसा कि आप कल्पना कर सकते हैं, हम उत्पादों को अवधि के अनुसार समूहित कर सकते हैं (जैसे, 10 या 20 वर्ष, या यहां तक कि जीवन भर)। अगर हम ऐसा करना चुनते हैं, तो हमारे पास समान product_category_id वाले उत्पाद होने की संभावना है लेकिन अलग-अलग नाम और विवरण। प्रत्येक उत्पाद के लिए, हम निम्नलिखित मूलभूत जानकारी संग्रहीत करेंगे:
product_name- इस उत्पाद का नाम। यहproduct_category_id. के संयोजन में इस तालिका के लिए वैकल्पिक कुंजी के रूप में उपयोग किया जाता है गुण। यह संभावना नहीं है कि हमारे पास एक ही नाम के दो उत्पाद होंगे जो विभिन्न श्रेणियों से संबंधित हैं, लेकिन फिर भी यह एक संभावना है।product_category_id— उस श्रेणी की पहचान करता है जिससे यह उत्पाद संबंधित है।product_description— इस उत्पाद का पाठ्य विवरण।
विषय क्षेत्र #3:ग्राहक
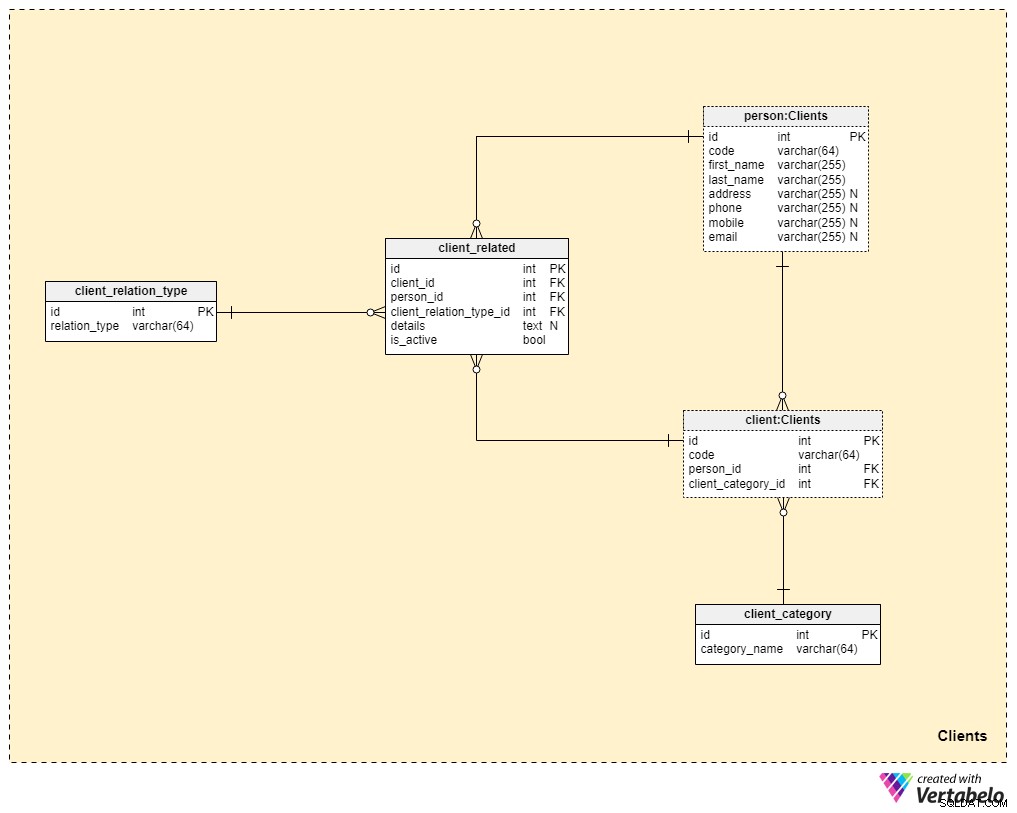
अब हम अपने डेटा मॉडल के मूल के बहुत करीब पहुंच रहे हैं, लेकिन हम अभी तक काफी नहीं हैं। जीवन बीमा अद्वितीय है क्योंकि एक पॉलिसी परिवार के किसी सदस्य या किसी और को हस्तांतरित की जा सकती है, जबकि बीमा के अन्य रूपों (जैसे स्वास्थ्य बीमा या कार बीमा) के लिए नीतियां एक ही ग्राहक से संबंधित होती हैं और उन्हें स्थानांतरित नहीं किया जा सकता है। इस कारण से, हमें न केवल उस ग्राहक के बारे में जानकारी संग्रहीत करने की आवश्यकता होगी जिससे पॉलिसी संबंधित है बल्कि किसी भी संबंधित लोगों और क्लाइंट से उनके संबंधों के बारे में भी जानकारी संग्रहीत करनी होगी।
हम client टेबल। प्रत्येक क्लाइंट के लिए, हम उस क्लाइंट के लिए बनाए गए या मैन्युअल रूप से डाले गए अद्वितीय कोड को स्टोर करेंगे, साथ ही तालिका को संदर्भित करने वाली विदेशी कुंजियों को उनके व्यक्तिगत डेटा (person_id) के साथ संग्रहीत करेंगे। ) और हमारे आंतरिक वर्गीकरण वाली तालिका (client_category_id )
client_category शब्दकोश हमें ग्राहकों को उनकी जनसांख्यिकी और वित्तीय विवरण के आधार पर समूहबद्ध करने की अनुमति देता है। ग्राहक श्रेणियों का उपयोग उस बीमा पॉलिसी को निर्धारित करने के लिए किया जाएगा जिसे हम किसी विशेष ग्राहक को देने के लिए तैयार हैं। यहां, हम केवल उन अद्वितीय मानों की एक सूची संग्रहीत करेंगे, जिन्हें हम ग्राहकों को सौंपेंगे।
चूंकि हम जीवन बीमा के बारे में बात कर रहे हैं, इसलिए हम मान लेंगे कि ग्राहक एक अकेला व्यक्ति है। हालाँकि, जैसा कि हमने पहले उल्लेख किया है, ग्राहक से संबंधित अन्य लोग भी हो सकते हैं जिन्हें पॉलिसी हस्तांतरित की जा सकती है या ग्राहक की मृत्यु पर पॉलिसी लाभ प्राप्त कर सकते हैं। इस कारण से, हमने एक अलग person टेबल। इस तालिका में प्रत्येक रिकॉर्ड के लिए, हम निम्नलिखित जानकारी संग्रहीत करेंगे:
code- स्वचालित रूप से उत्पन्न या मैन्युअल रूप से डाला गया मान संबंधित व्यक्ति को विशिष्ट रूप से पहचानने के लिए उपयोग किया जाता है।first_nameऔरlast_name— व्यक्ति के प्रथम और अंतिम नाम, क्रमशः।address,phone,mobileऔरemail— इस व्यक्ति के संपर्क विवरण, जिनमें सभी मनमाने मूल्य हैं।
क्लाइंट और अन्य लोगों के बीच संबंधों की प्रकृति का वर्णन करने के लिए इस विषय क्षेत्र में शेष दो तालिकाओं की आवश्यकता है।
सभी संभावित संबंध प्रकारों की सूची client_relation_type शब्दकोश। अन्य शब्दकोशों की तरह, इसमें विशिष्ट नामों की एक सूची होगी जिसका उपयोग हम बाद में किसी विशेष ग्राहक और किसी अन्य व्यक्ति के बीच संबंध का वर्णन करते समय करेंगे।
वास्तविक संबंध डेटा client_related टेबल। इस तालिका में प्रत्येक रिकॉर्ड के लिए, हम क्लाइंट के संदर्भ संग्रहीत करेंगे (client_id ), संबंधित व्यक्ति (person_id ), उस संबंध की प्रकृति (client_relation_type_id ), सभी अतिरिक्त विवरण (details ), यदि कोई हो, और एक ध्वज जो दर्शाता है कि संबंध वर्तमान में सक्रिय है (is_active ) इस तालिका में वैकल्पिक कुंजी client_id . के संयोजन द्वारा परिभाषित की गई है , person_id , और client_relation_type_id ।
विषय क्षेत्र #4:ऑफ़र
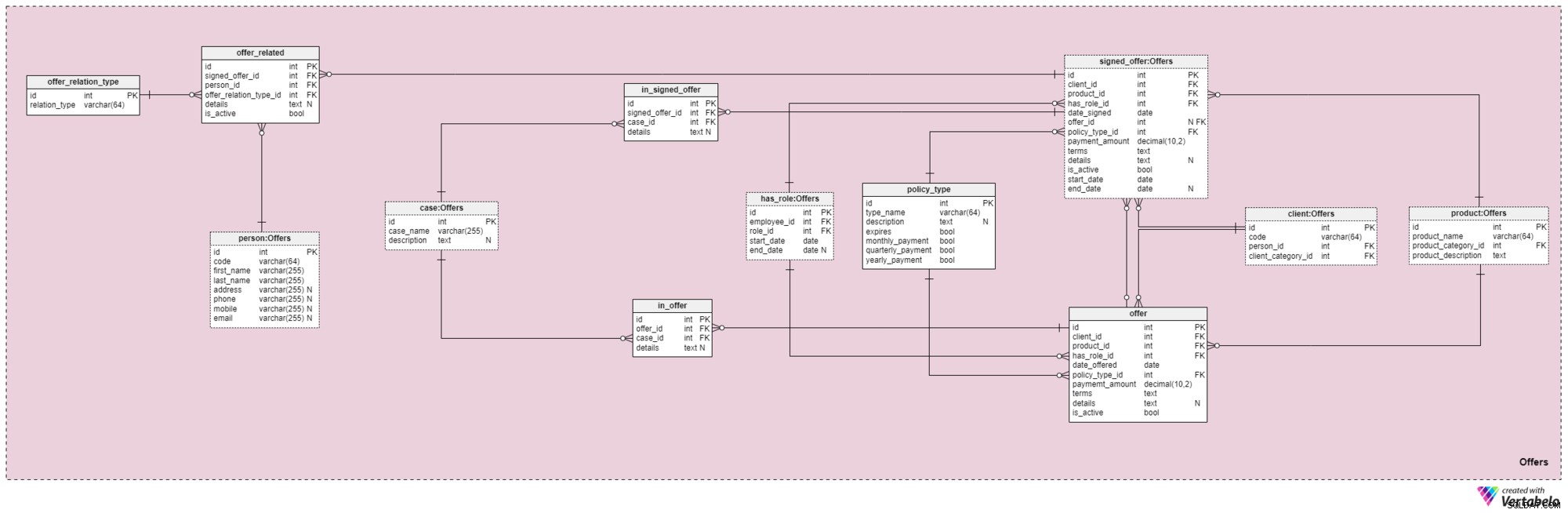
यह विषय क्षेत्र और इसके बाद आने वाला क्षेत्र इस डेटा मॉडल के केंद्र में है। वे ऑफ़र और हस्ताक्षरित नीतियों के साथ-साथ ऑफ़र से संबंधित भुगतानों को भी कवर करते हैं। सबसे पहले, हम ऑफ़र विषय क्षेत्र का वर्णन करेंगे। यह जटिल लग सकता है क्योंकि इसमें 12 टेबल हैं। हालांकि, इन 12 में से चार (has_role , product , client , और person ) का वर्णन पिछले विषय क्षेत्रों में किया गया था, इसलिए हम अपनी चर्चा को यहां नहीं दोहराएंगे।
offer और signed_offer तालिकाओं में समान संरचनाएं होती हैं क्योंकि उनका उपयोग हमारे मॉडल में बहुत समान डेटा संग्रहीत करने के लिए किया जाएगा। हालांकि, जबकि offer मुख्य रूप से किसी भी नीति (और उनके विवरण) को संग्रहीत करने के लिए उपयोग किया जाएगा जो हमने अपने ग्राहकों को दिया है, signed_offer तालिका का उपयोग उन ग्राहकों के बारे में जानकारी संग्रहीत करने के लिए सख्ती से किया जाएगा, जिन्होंने वास्तव में हमारी कंपनी के साथ नीतियों पर हस्ताक्षर किए हैं। हम इन तालिकाओं को एक साथ कवर करेंगे, किसी भी अंतर को ध्यान में रखते हुए जहां वे दिखाई देते हैं। इन दो तालिकाओं में विशेषताएँ इस प्रकार हैं:
client_id— किसी विशेष ऑफ़र पर हस्ताक्षर करने वाले क्लाइंट के लिए विशिष्ट पहचानकर्ता का संदर्भ।product_id— उस उत्पाद के विशिष्ट पहचानकर्ता का संदर्भ जो हस्ताक्षरित ऑफ़र में शामिल था।has_role_id- कर्मचारी की आईडी और प्रस्ताव प्रस्तुत/हस्ताक्षरित होने के समय उनकी भूमिका का संदर्भ।date_offeredऔरdate_signed— वास्तविक तिथियां यह दर्शाती हैं कि यह ऑफ़र क्लाइंट को कब प्रस्तुत किया गया था और जब इस पर हस्ताक्षर किए गए थे, क्रमशः।offer_id— इस क्लाइंट के लिए पिछले ऑफ़र का संदर्भ। इसमें शून्य का मान हो सकता है क्योंकि ग्राहक कंपनी से किसी भी पिछले प्रस्ताव के बिना पॉलिसी पर हस्ताक्षर कर सकता था, जैसे कि उन्होंने हमसे स्वयं संपर्क किया। यह विशेषता सख्ती सेsigned_offerटेबल.policy_type_id— पॉलिसी टाइप डिक्शनरी के संदर्भ में जो पॉलिसी के प्रकार को दर्शाता है जिसे हमने क्लाइंट को पेश किया था या उस पर हस्ताक्षर किए थे।payment_amount— वह राशि जो ग्राहक को पॉलिसी के लिए नियमित रूप से चुकानी होगी।terms- समझौते की सभी शर्तें, टेक्स्ट (एक्सएमएल) प्रारूप में। विचार इस विशेषता में पॉलिसी के वित्तीय भाग से संबंधित सभी महत्वपूर्ण विवरणों को संग्रहीत करना है। टेक्स्ट के उदाहरण जिन्हें हम स्टोर कर सकते हैं, वे हैं कुल पॉलिसी राशि, क्लाइंट द्वारा किए जाने वाले भुगतानों की संख्या, और इसी तरह।details— कोई अतिरिक्त विवरण, पाठ्य प्रारूप में।is_active— झंडा यह दर्शाता है कि रिकॉर्ड अभी भी सक्रिय है या नहीं।start_dateऔरend_date- उस समय सीमा को निरूपित करें जिसमें यह नीति सक्रिय है/थी। यदि पॉलिसी को जीवन भर के लिए हस्ताक्षरित किया गया था, तो end_date में शून्य का मान होगा।
policy_type शब्दकोश जिसका हमने पहले संक्षेप में उल्लेख किया था। उम्र, स्वास्थ्य, वैवाहिक स्थिति, क्रेडिट जोखिम आदि जैसे कारकों के आधार पर हमें अलग-अलग ग्राहकों को एक ही उत्पाद की पेशकश करने में कुछ हद तक लचीलेपन की आवश्यकता होती है। प्रत्येक नीति प्रकार के लिए, हम एक type_name संग्रहित करेंगे पहचानकर्ता, एक अतिरिक्त पाठ्य details , नाम का एक फ़्लैग यह दर्शाता है कि पॉलिसी समाप्त हो सकती है या नहीं, और दूसरा फ़्लैग यह दर्शाता है कि इस पॉलिसी प्रकार के प्रीमियमों का मासिक, त्रैमासिक या वार्षिक भुगतान करने की आवश्यकता है या नहीं। कुछ अपेक्षित पॉलिसी प्रकार हैं:टर्म लाइफ, होल लाइफ, यूनिवर्सल लाइफ, गारंटीड यूनिवर्सल लाइफ, वैरिएबल लाइफ, वैरिएबल यूनिवर्सल लाइफ और रिटायरमेंट के बाद का लाइफ इंश्योरेंस।
आगे बढ़ते हुए, अब हमें उन सभी मामलों और स्थितियों को परिभाषित करने की आवश्यकता है जिन्हें एक विशेष नीति कवर कर सकती है। हमें इन मामलों को विशिष्ट प्रस्तावों और हस्ताक्षरित प्रस्तावों से जोड़ने की आवश्यकता है।
हमारी नीतियों के सभी संभावित मामलों की सूची case शब्दकोश। इस तालिका के प्रत्येक रिकॉर्ड को उसके case_name . द्वारा विशिष्ट रूप से पहचाना जा सकता है और एक अतिरिक्त details है , अगर एक की जरूरत है।
in_offer और in_signed_offer तालिकाएँ समान संरचना साझा करती हैं क्योंकि वे समान डेटा संग्रहीत करती हैं। दोनों के बीच एकमात्र अंतर यह है कि पहला पॉलिसी में कवर किए गए मामलों को स्टोर करता है जो केवल क्लाइंट को पेश किए जाते हैं, जबकि दूसरा क्लाइंट द्वारा हस्ताक्षरित पॉलिसी में मामलों को स्टोर करता है। इन दो तालिकाओं में प्रत्येक रिकॉर्ड के लिए, हम offer_id . की अनूठी जोड़ी संग्रहित करेंगे /signed_offer_id और case_id , जिनमें से उत्तरार्द्ध पॉलिसी द्वारा कवर किए गए मामले या घटना को दर्शाता है। अन्य सभी विवरण, यदि आवश्यक हो, एक पाठ्य विशेषता में संग्रहीत किए जाएंगे।
जैसा कि हमने पहले बताया, जीवन बीमा पॉलिसियां लगभग हमेशा ग्राहकों से ही नहीं बल्कि उनके परिवार के सदस्यों या रिश्तेदारों से भी जुड़ी होती हैं। हमें इन संबंधों को इस क्षेत्र में भी संग्रहित करने की आवश्यकता है। पॉलिसी पर हस्ताक्षर के समय उन्हें परिभाषित किया जाएगा, लेकिन उन्हें पॉलिसी की पूरी अवधि में बदला भी जा सकता है।
पहली चीज़ जो हमें करने की ज़रूरत है वह एक ऐसा शब्दकोश बनाना है जिसमें सभी संभावित मान हों जो किसी संबंध को असाइन किए जा सकें। हमारे मॉडल में, यह offer_relation_type शब्दकोश। प्राथमिक कुंजी के अलावा, इस तालिका में केवल एक विशेषता है—relation_type - जिसमें केवल अद्वितीय मान हो सकते हैं।
हम बस पहुँच गए! इस विषय क्षेत्र में अंतिम तालिका का शीर्षक है offer_related . यह किसी ऐसे व्यक्ति से हस्ताक्षरित प्रस्ताव से संबंधित है जो ग्राहक से संबंधित है। इसलिए, हमें हस्ताक्षरित नीति के संदर्भ संग्रहीत करने होंगे (signed_offer_id ) और संबंधित व्यक्ति (person_id .) ) और उस संबंध की प्रकृति भी निर्दिष्ट करें (offer_relation_type_id ) इसके अतिरिक्त, हमें details स्टोर करने की आवश्यकता होगी इस रिकॉर्ड से संबंधित और यह जांचने के लिए एक ध्वज बनाएं कि क्या यह अभी भी हमारे सिस्टम में मान्य है।
विषय क्षेत्र #5:भुगतान
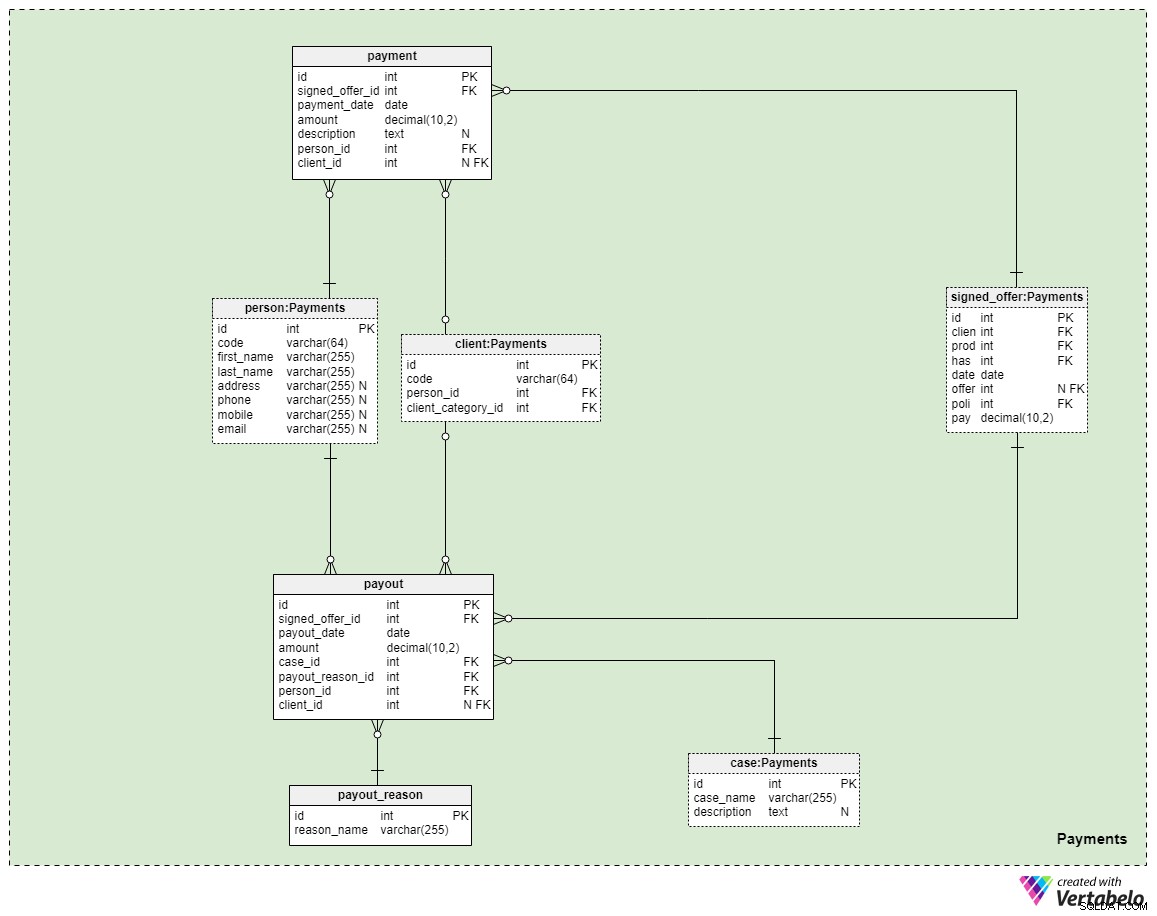
हमारे मॉडल में अंतिम विषय क्षेत्र भुगतान से संबंधित है। यहां, हम केवल तीन नई तालिकाएं प्रस्तुत कर रहे हैं:payment , payout_reason , और payout ।
नीतियों से संबंधित सभी भुगतान payment टेबल। हमने यहां केवल सबसे महत्वपूर्ण विशेषताओं को शामिल किया है:
signed_offer_id— हस्ताक्षरित ऑफ़र (नीति) के विशिष्ट पहचानकर्ता का संदर्भ।payment_date— वह तारीख जब यह भुगतान किया गया था।amount— भुगतान की गई वास्तविक राशि।details— भुगतान का एक वैकल्पिक विवरण, पाठ्य प्रारूप में।person_id- भुगतान करने वाले व्यक्ति के विशिष्ट पहचानकर्ता का संदर्भ। ध्यान दें कि प्रस्ताव पर हस्ताक्षर करने वाला ग्राहक ही भुगतान करने वाला एकमात्र व्यक्ति नहीं है।client_id— भुगतान करने वाले ग्राहक के विशिष्ट पहचानकर्ता का संदर्भ। इस विशेषता में केवल तभी मूल्य होगा जब ग्राहक ने स्वयं भुगतान किया हो।
शेष दो टेबल शायद सबसे महत्वपूर्ण कारण का प्रतिनिधित्व करते हैं कि हम जीवन बीमा के लिए भुगतान क्यों करते हैं- कि अगर हमें कुछ होता है, तो हमारे परिवार के सदस्यों या जीवन/व्यावसायिक भागीदारों को भुगतान किया जाएगा। यह कैसे होता है यह सब आपकी स्थिति और आपके द्वारा हस्ताक्षरित विशिष्ट नीति की शर्तों पर निर्भर करता है। हम इन मामलों को कवर करने के लिए दो सरल तालिकाओं का उपयोग करेंगे।
पहला एक शब्दकोश है जिसका शीर्षक है payout_reason और एक क्लासिक शब्दकोश संरचना पेश करता है। प्राथमिक कुंजी विशेषता के अलावा, हमारे पास केवल एक विशेषता है - reason_name - जो यह दर्शाता है कि यह भुगतान क्यों किया गया था, अद्वितीय मूल्यों की एक सूची संग्रहीत करेगा।
मॉडल में अंतिम तालिका payout टेबल। यह बहुत हद तक payment तालिका, लेकिन सबसे महत्वपूर्ण अंतर नीचे दिए गए हैं:
payout_date— वह तारीख जब भुगतान किया गया था।case_id- भुगतान को ट्रिगर करने वाले संबंधित मामले या घटना के विशिष्ट पहचानकर्ता का संदर्भ। यह नीति में शामिल किसी एक आईडी से मेल खाना चाहिए।payout_reason_id— उस शब्दकोश का संदर्भ जो भुगतान के कारण का अधिक विस्तार से वर्णन करता है। जबकि पेआउट मामला छोटा और अधिक सामान्य है, पेआउट कारण क्या हुआ इसके बारे में अधिक विशिष्ट विवरण प्रदान करेगा।person_idऔरclient_id— क्रमशः पेआउट से संबंधित व्यक्ति और क्लाइंट का संदर्भ देता है।
सारांश
विस्मयकारी! हमने अपना जीवन बीमा डेटा मॉडल सफलतापूर्वक बनाया है। इससे पहले कि हम अपनी चर्चा को समाप्त करें, यह ध्यान देने योग्य है कि इस मॉडल में और भी बहुत कुछ शामिल किया जा सकता है। इस लेख में, हम मुख्य रूप से मॉडल की मूल बातें कवर करना चाहते थे ताकि आपको यह पता चल सके कि यह कैसा दिखता है और कार्य करता है। यहां कुछ और विवरण दिए गए हैं जिन्हें इस तरह के डेटा मॉडल में शामिल किया जा सकता है:
- अतिरिक्त नीति उन्नयन हमारे वर्तमान मॉडल में शामिल नहीं हैं (उदाहरण के लिए, यदि आप मौजूदा नीतियों के लिए वार्षिक ऑफ़र करना चाहते हैं, तो आप इसे इस संरचना के साथ नहीं कर पाएंगे)। प्रस्तुत/हस्ताक्षरित ऑफ़र के लिए सभी नीतिगत परिवर्तनों को संग्रहीत करने के लिए हमें कुछ और तालिकाएँ जोड़नी चाहिए।
- सारी कागजी कार्रवाई जानबूझकर छोड़ी गई है। बेशक, किसी विशेष जीवन बीमा पॉलिसी से जुड़ी बहुत सारी कागजी कार्रवाई होगी, विशेष रूप से हस्ताक्षर प्रक्रिया और भुगतान के लिए। हम ऐसे दस्तावेज़ संलग्न कर सकते हैं जो पॉलिसी पर हस्ताक्षर किए जाने के समय ग्राहक की स्थिति और रास्ते में किसी भी बदलाव के साथ-साथ पेआउट से संबंधित किसी भी दस्तावेज़ का वर्णन करते हों।
- इस मॉडल में पॉलिसी जोखिम गणना के लिए आवश्यक संरचना शामिल नहीं है। हमारे पास वे सभी पैरामीटर होने चाहिए जिनका हमें परीक्षण करने की आवश्यकता है और कोई भी श्रेणी जो यह निर्धारित करती है कि ग्राहक का मूल्य समग्र गणना को कैसे प्रभावित करता है। इन गणनाओं के परिणामों को प्रत्येक ऑफ़र और हस्ताक्षरित नीति के लिए संग्रहीत करने की आवश्यकता होगी।
- इनवॉइस संरचना वास्तव में भुगतान विषय क्षेत्र में हमारे द्वारा कवर की गई संरचना से कहीं अधिक जटिल है। हमने अपने मॉडल में कहीं भी वित्तीय खातों का उल्लेख नहीं किया है।
जाहिर है, बीमा कारोबार काफी जटिल है। हमने इस लेख में केवल जीवन बीमा के लिए एक डेटा मॉडल पर चर्चा की है - क्या आप कल्पना कर सकते हैं कि यह डेटा मॉडल कैसे विकसित होगा यदि हम एक ऐसी कंपनी चलाते हैं जो कई अलग-अलग प्रकार के बीमा प्रदान करती है? ऐसी कंपनी के लिए एक संगठित डेटा मॉडल पेश करने के लिए निश्चित रूप से बहुत सारी योजना और विचार करना होगा।
यदि हमारे डेटा मॉडल में सुधार के लिए आपके पास कोई सुझाव या विचार हैं, तो बेझिझक हमें नीचे टिप्पणी में बताएं!