XQuery का उपयोग करके XML से डेटा पार्स करना एक नियमित अभ्यास है। इसे सबसे प्रभावी ढंग से करने के लिए, थोड़े प्रयास की आवश्यकता है।
मान लीजिए कि हमें निम्न संरचना के साथ डिस्क फ़ाइल से डेटा पार्स करने की आवश्यकता है:
<tables> <table name="Accounting" schema="Production" object="Accounting"> <column name="Date" order="3" visible="1" /> <column name="DateFrom" order="5" visible="1" /> <column name="DateTo" order="6" visible="1" /> <column name="Description" order="4" visible="1" /> <column name="DocumentUID" order="1" visible="0" /> <column name="Number" order="2" visible="1" /> <column name="Warehouse" order="7" visible="1" /> </table> </tables>
यदि आप किसी फ़ाइल से डेटा पढ़ना चाहते हैं, तो बल्क इंसर्ट का उपयोग करें:
SELECT BulkColumn FROM OPENROWSET(BULK 'D:\data.xml', SINGLE_BLOB) x sample xml file
एक नमूना xml फ़ाइल यहाँ है।
हालांकि, एक खास बात का ध्यान रखें... डेटा को सीधे पढ़ने की कोशिश न करें:
;WITH cte AS
(
SELECT x = CAST(BulkColumn AS XML)
FROM OPENROWSET(BULK 'D:\data.xml', SINGLE_BLOB) x
)
SELECT t.c.value('@name', 'VARCHAR(100)')
FROM cte
CROSS APPLY x.nodes('tables/table') t(c) एक चर के लिए डेटा असाइन करें। इस तरह आप एक अधिक कुशल निष्पादन योजना प्राप्त कर सकते हैं:
DECLARE @xml XML
SELECT @xml = BulkColumn
FROM OPENROWSET(BULK 'D:\data.xml', SINGLE_BLOB) x
SELECT t.c.value('@name', 'VARCHAR(100)')
FROM @xml.nodes('tables/table') t(c) परिणामों की तुलना करें:
Table 'Worktable'. Scan count 0, logical reads 729, physical reads 0, read-ahead reads 0, lob logical reads 62655,... SQL Server Execution Times: CPU time = 1203 ms, elapsed time = 1214 ms. Table 'Worktable'. Scan count 0, logical reads 7, physical reads 0, read-ahead reads 0, lob logical reads 202,.... SQL Server Execution Times: CPU time = 16 ms, elapsed time = 4 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 3 ms.
जैसा कि आप देख सकते हैं, दूसरा विकल्प काफी तेज है।
XQuery के साथ काम करते समय SQL सर्वर की एक अन्य महत्वपूर्ण विशेषता यह है कि मूल तत्व को पढ़ने से खराब प्रदर्शन हो सकता है। निम्नलिखित उदाहरण पर विचार करें:
SET STATISTICS PROFILE OFF
DECLARE @xml XML
SELECT @xml = BulkColumn
FROM OPENROWSET(BULK 'D:\data.xml', SINGLE_BLOB) x
SET STATISTICS PROFILE ON
SELECT
t.c.value('@name', 'SYSNAME')
, t.c.value('@order', 'INT')
, t.c.value('@visible', 'BIT')
, t.c.value('../@name', 'SYSNAME')
, t.c.value('../@schema', 'SYSNAME')
, t.c.value('../@object', 'SYSNAME')
FROM @xml.nodes('tables/table/*') t(c) आइए ऑपरेटर से प्राप्त पंक्तियों की वास्तविक संख्या को देखें। मान असामान्य रूप से बड़ा है:
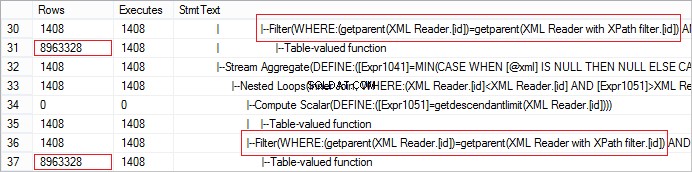
क्रॉस एप्लाई का उपयोग करके अनुरोध को आसानी से अनुकूलित किया जा सकता है:
SELECT
t2.c2.value('@name', 'SYSNAME')
, t2.c2.value('@order', 'INT')
, t2.c2.value('@visible', 'BIT')
, t.c.value('@name', 'SYSNAME')
, t.c.value('@schema', 'SYSNAME')
, t.c.value('@object', 'SYSNAME')
FROM @xml.nodes('tables/table') t(c)
CROSS APPLY t.c.nodes('column') t2(c2) आइए निष्पादन समय की तुलना करें:
(1408 row(s) affected) SQL Server Execution Times: CPU time = 10125 ms, elapsed time = 10135 ms. (1408 row(s) affected) SQL Server Execution Times: CPU time = 78 ms, elapsed time = 156 ms.
जैसा कि आप उदाहरण से देख सकते हैं, क्रॉस एप्लाई के साथ अनुरोध तुरंत काम करता है।
ध्यान देने के लिए आपको धन्यवाद। मुझे आशा है कि यह लेख उपयोगी था। बेझिझक कोई भी प्रश्न पूछें, इस लेख के संबंध में अपनी टिप्पणी और सुझाव दें।