यह बहु-श्रृंखला का दूसरा भाग है बेंचमार्किंग प्रबंधित PostgreSQL क्लाउड समाधान . भाग 1 में मैंने उपलब्ध उपकरणों का एक सिंहावलोकन प्रस्तुत किया, मैंने औरोरा के लिए AWS बेंचमार्क प्रक्रिया का उपयोग करने के कारण, साथ ही साथ उपयोग किए जाने वाले PostgreSQL संस्करणों पर चर्चा की, और मैंने Amazon Aurora PostgreSQL 10.6 की समीक्षा की।
इस भाग में, PostgreSQL 11.1 के लिए Amazon RDS के विरुद्ध pgbench और sysbench चलेंगे। इस लेखन के समय नवीनतम PostgreSQL संस्करण 11.2 लगभग एक महीने पहले जारी किया गया है।
क्लाउड में वर्तमान में उपलब्ध PostgreSQL संस्करणों की त्वरित समीक्षा करने के लिए यह एक सेकंड के लिए रुकने लायक है:
- अमेज़ॅन ऑरोरा पोस्टग्रेएसक्यूएल 10.6
- PostgreSQL 11.1 के लिए Amazon RDS
- PostgreSQL 9.6 के लिए Google क्लाउड SQL
- Microsoft Azure PostgreSQL 10.5
अमेज़ॅन फिर से एक विजेता है, इसके आरडीएस की पेशकश के साथ, पोस्टग्रेएसक्यूएल का नवीनतम संस्करण प्रदान करके। जैसा कि RDS फ़ोरम में घोषित किया गया था, AWS ने PostgreSQL 11.1 को 13 मार्च को उपलब्ध कराया, जो कि सामुदायिक रिलीज़ के चार महीने बाद है।
पर्यावरण की स्थापना
पर्यावरण को स्थापित करने और बेंचमार्क चलाने से संबंधित बाधाओं के बारे में कुछ नोट्स, जिन बिंदुओं पर इस श्रृंखला के भाग 1 के दौरान अधिक विस्तार से चर्चा की गई:
- क्लाउड प्रदाता डिफ़ॉल्ट GUC सेटिंग्स में कोई परिवर्तन नहीं।
- कनेक्शन अधिकतम 1,000 तक सीमित हैं क्योंकि pgbench के लिए AWS पैच सफाई से लागू नहीं हुआ। संबंधित नोट पर, मुझे इस pgsql-hackers सबमिशन से AWS टाइमिंग पैच डाउनलोड करना पड़ा क्योंकि यह अब गाइड में उल्लिखित लिंक पर उपलब्ध नहीं था।
- उन्नत नेटवर्किंग क्लाइंट इंस्टेंस के लिए सक्षम होना चाहिए।
- डेटाबेस में प्रतिकृति शामिल नहीं है।
- डेटाबेस संग्रहण एन्क्रिप्ट नहीं किया गया है।
- क्लाइंट और टारगेट इंस्टेंस दोनों एक ही उपलब्धता क्षेत्र में हैं।
सबसे पहले, क्लाइंट और डेटाबेस इंस्टेंस सेट करें:
- ग्राहक मांग पर r4.8xबड़ा EC2 उदाहरण है:
- vCPU:32 (16 करोड़ x 2 थ्रेड/कोर)
- रैम:244 जीआईबी
- संग्रहण:ईबीएस अनुकूलित
- नेटवर्क:10 गीगाबिट
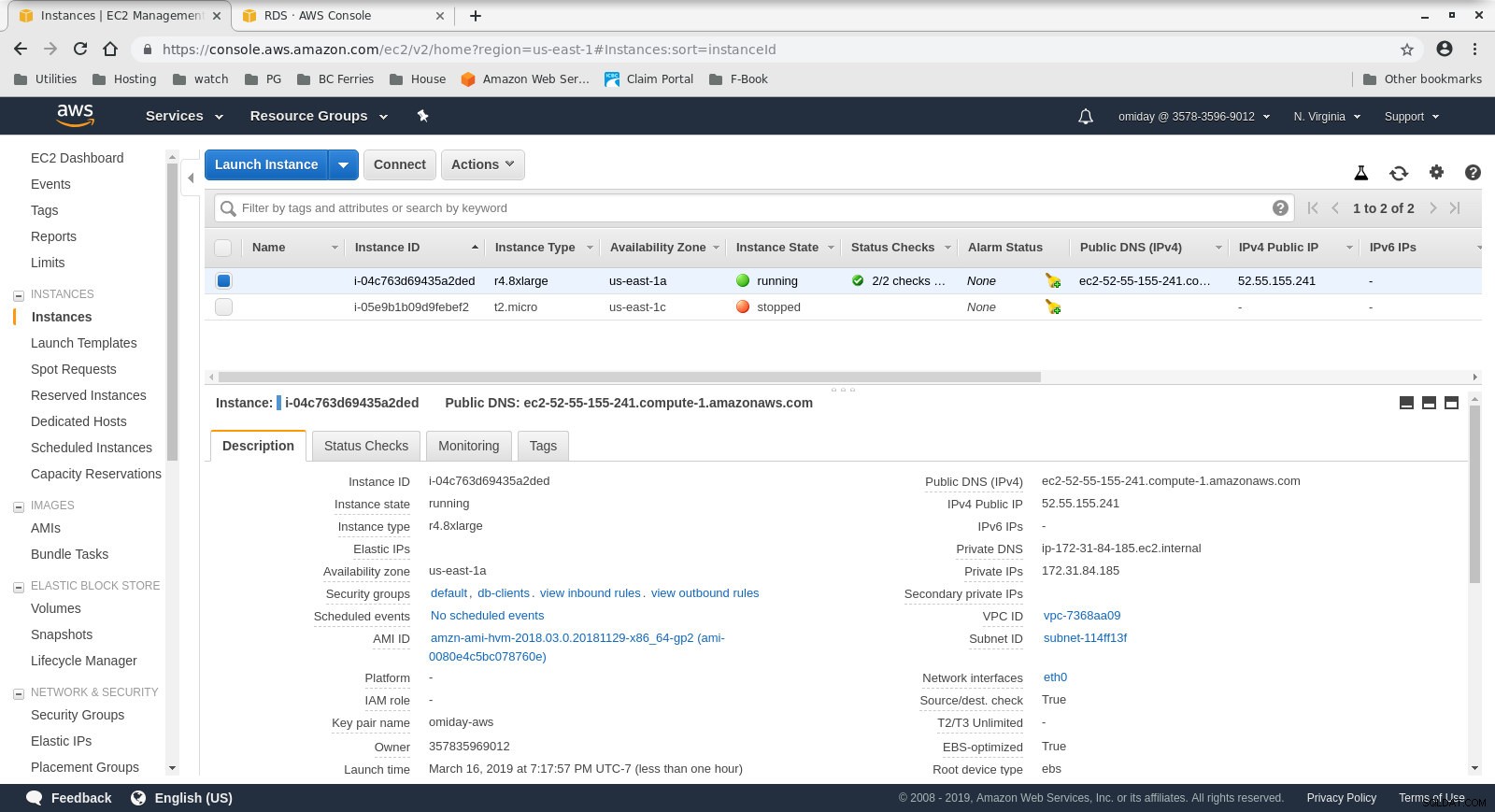 क्लाइंट इंस्टेंस कॉन्फ़िगरेशन
क्लाइंट इंस्टेंस कॉन्फ़िगरेशन - डीबी क्लस्टर मांग पर है db.r4.2xबड़ा:
- vCPU:8
- रैम:61GiB
- संग्रहण:ईबीएस अनुकूलित
- नेटवर्क:अधिकतम 10 जीबीपीएस कनेक्शन पर 1,750 एमबीपीएस अधिकतम बैंडविड्थ
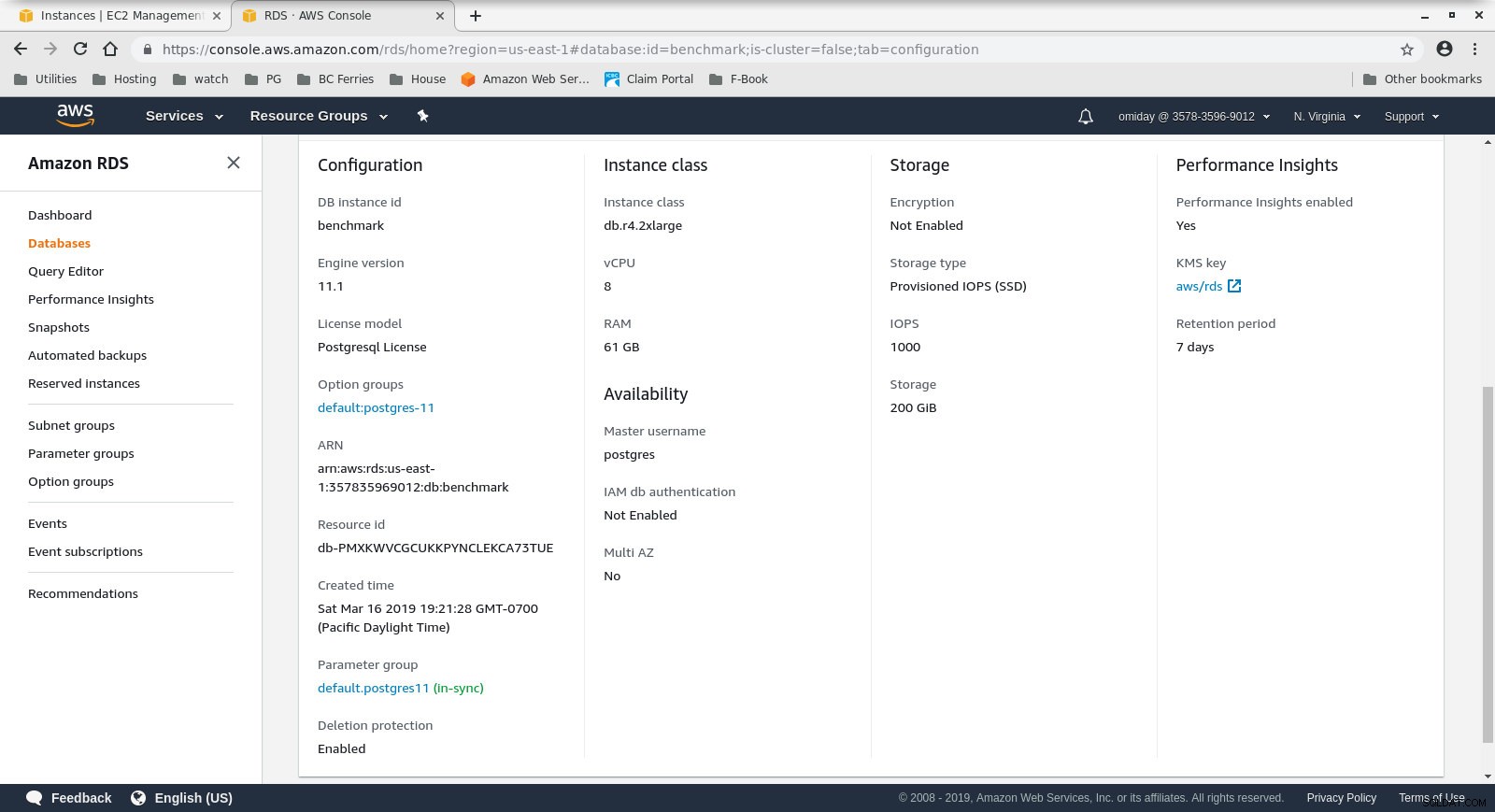 डेटाबेस इंस्टेंस कॉन्फ़िगरेशन
डेटाबेस इंस्टेंस कॉन्फ़िगरेशन
इसके बाद, Amazon गाइड में दिए गए निर्देशों का पालन करके बेंचमार्क टूल, pgbench और sysbench को इंस्टॉल और कॉन्फ़िगर करें।
वातावरण तैयार करने का अंतिम चरण PostgreSQL कनेक्शन पैरामीटर को कॉन्फ़िगर करना है। इसे करने का एक तरीका .bashrc में पर्यावरण चर को प्रारंभ करना है। साथ ही, हमें PostgreSQL बायनेरिज़ और लाइब्रेरी के लिए पथ सेट करने की आवश्यकता है:
निर्यात PGHOST=benchmark.ctfirtyhadgr.us-east-1.rds.amazonaws.com
export PGHOST=benchmark.ctfirtyhadgr.us-east-1.rds.amazonaws.com
export PGUSER=postgres
export PGPASSWORD=postgres
export PGDATABASE=postgres
export PATH=$PATH:/usr/local/pgsql/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/pgsql/lib
Verify that everything is in place:
[example@sqldat.com ~]# psql --version
psql (PostgreSQL) 11.1
[example@sqldat.com ~]# pgbench --version
pgbench (PostgreSQL) 11.1
[example@sqldat.com ~]# sysbench --version
sysbench 0.5बेंचमार्क चलाना
pgench
सबसे पहले, pgbench डेटाबेस को इनिशियलाइज़ करें।
[example@sqldat.com ~]# pgbench -i --fillfactor=90 --scale=10000आरंभीकरण प्रक्रिया में कुछ समय लगता है, और चलते समय निम्न आउटपुट उत्पन्न होता है:
dropping old tables...
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
creating tables...
generating data...
100000 of 1000000000 tuples (0%) done (elapsed 0.06 s, remaining 599.79 s)
200000 of 1000000000 tuples (0%) done (elapsed 0.15 s, remaining 739.16 s)
300000 of 1000000000 tuples (0%) done (elapsed 0.22 s, remaining 742.21 s)
400000 of 1000000000 tuples (0%) done (elapsed 0.33 s, remaining 814.64 s)
500000 of 1000000000 tuples (0%) done (elapsed 0.41 s, remaining 825.82 s)
600000 of 1000000000 tuples (0%) done (elapsed 0.51 s, remaining 854.13 s)
700000 of 1000000000 tuples (0%) done (elapsed 0.66 s, remaining 937.01 s)
800000 of 1000000000 tuples (0%) done (elapsed 1.52 s, remaining 1897.42 s)
900000 of 1000000000 tuples (0%) done (elapsed 1.66 s, remaining 1840.08 s)
...
500600000 of 1000000000 tuples (50%) done (elapsed 814.78 s, remaining 812.83 s)
500700000 of 1000000000 tuples (50%) done (elapsed 814.81 s, remaining 812.53 s)
500800000 of 1000000000 tuples (50%) done (elapsed 814.83 s, remaining 812.23 s)
500900000 of 1000000000 tuples (50%) done (elapsed 815.11 s, remaining 812.19 s)
501000000 of 1000000000 tuples (50%) done (elapsed 815.20 s, remaining 811.94 s)
...
999200000 of 1000000000 tuples (99%) done (elapsed 1645.02 s, remaining 1.32 s)
999300000 of 1000000000 tuples (99%) done (elapsed 1645.17 s, remaining 1.15 s)
999400000 of 1000000000 tuples (99%) done (elapsed 1645.20 s, remaining 0.99 s)
999500000 of 1000000000 tuples (99%) done (elapsed 1645.23 s, remaining 0.82 s)
999600000 of 1000000000 tuples (99%) done (elapsed 1645.26 s, remaining 0.66 s)
999700000 of 1000000000 tuples (99%) done (elapsed 1645.28 s, remaining 0.49 s)
999800000 of 1000000000 tuples (99%) done (elapsed 1645.51 s, remaining 0.33 s)
999900000 of 1000000000 tuples (99%) done (elapsed 1645.77 s, remaining 0.16 s)
1000000000 of 1000000000 tuples (100%) done (elapsed 1646.03 s, remaining 0.00 s)
vacuuming...
creating primary keys...
total time: 5538.86 s (drop 0.00 s, tables 0.01 s, insert 1647.08 s, commit 0.03 s, primary 1251.60 s, foreign 0.00 s, vacuum 2640.14 s)
done.एक बार वह हिस्सा पूरा हो जाने के बाद, सत्यापित करें कि PostgreSQL डेटाबेस पॉप्युलेट हो गया है। डिस्क उपयोग क्वेरी के निम्नलिखित सरलीकृत संस्करण का उपयोग PostgreSQL डेटाबेस आकार को वापस करने के लिए किया जा सकता है:
SELECT
d.datname AS Name,
pg_catalog.pg_get_userbyid(d.datdba) AS Owner,
pg_catalog.pg_size_pretty(pg_catalog.pg_database_size(d.datname)) AS SIZE
FROM pg_catalog.pg_database d
WHERE d.datname = 'postgres';...और आउटपुट:
name | owner | size
----------+----------+--------
postgres | postgres | 160 GB
(1 row)सभी तैयारियों को पूरा करने के साथ हम पीजीबेंच टेस्ट पढ़ना/लिखना शुरू कर सकते हैं:
[example@sqldat.com ~]# pgbench --protocol=prepared -P 60 --time=600 --client=1000 --jobs=204810 मिनट के बाद हमें परिणाम मिलते हैं:
starting vacuum...end.
progress: 60.0 s, 878.3 tps, lat 1101.258 ms stddev 339.491
progress: 120.0 s, 885.2 tps, lat 1132.301 ms stddev 292.551
progress: 180.0 s, 656.3 tps, lat 1522.102 ms stddev 666.017
progress: 240.0 s, 436.8 tps, lat 2277.140 ms stddev 524.603
progress: 300.0 s, 742.2 tps, lat 1363.558 ms stddev 578.541
progress: 360.0 s, 866.4 tps, lat 1146.972 ms stddev 301.861
progress: 420.0 s, 878.2 tps, lat 1143.939 ms stddev 304.396
progress: 480.0 s, 872.7 tps, lat 1139.892 ms stddev 304.421
progress: 540.0 s, 881.0 tps, lat 1132.373 ms stddev 311.890
progress: 600.0 s, 729.3 tps, lat 1366.517 ms stddev 867.784
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 10000
query mode: prepared
number of clients: 1000
number of threads: 1000
duration: 600 s
number of transactions actually processed: 470582
latency average = 1274.340 ms
latency stddev = 544.179 ms
tps = 782.084354 (including connections establishing)
tps = 783.610726 (excluding connections establishing)सिसबेंच
पहला चरण कुछ डेटा जोड़ रहा है:
sysbench --test=/usr/local/share/sysbench/oltp.lua \
--pgsql-host=aurora.cluster-ctfirtyhadgr.us-east-1.rds.amazonaws.com \
--pgsql-db=postgres \
--pgsql-user=postgres \
--pgsql-password=postgres \
--pgsql-port=5432 \
--oltp-tables-count=250\
--oltp-table-size=450000 \
prepareकमांड 250 टेबल बनाता है, प्रत्येक टेबल में 2 इंडेक्स होते हैं:
sysbench 0.5: multi-threaded system evaluation benchmark
Creating table 'sbtest1'...
Inserting 450000 records into 'sbtest1'
Creating secondary indexes on 'sbtest1'...
Creating table 'sbtest2'...
...
Creating table 'sbtest250'...
Inserting 450000 records into 'sbtest250'
Creating secondary indexes on 'sbtest250'...आइए इंडेक्स देखें:
postgres=> \di
List of relations
Schema | Name | Type | Owner | Table
--------+-----------------------+-------+----------+------------------
public | k_1 | index | postgres | sbtest1
public | k_10 | index | postgres | sbtest10
public | k_100 | index | postgres | sbtest100
public | k_101 | index | postgres | sbtest101
public | k_102 | index | postgres | sbtest102
public | k_103 | index | postgres | sbtest103
...
public | k_97 | index | postgres | sbtest97
public | k_98 | index | postgres | sbtest98
public | k_99 | index | postgres | sbtest99
public | pgbench_accounts_pkey | index | postgres | pgbench_accounts
public | pgbench_branches_pkey | index | postgres | pgbench_branches
public | pgbench_tellers_pkey | index | postgres | pgbench_tellers
public | sbtest100_pkey | index | postgres | sbtest100
public | sbtest101_pkey | index | postgres | sbtest101
public | sbtest102_pkey | index | postgres | sbtest102
public | sbtest103_pkey | index | postgres | sbtest103
public | sbtest104_pkey | index | postgres | sbtest104
public | sbtest105_pkey | index | postgres | sbtest105
...
public | sbtest97_pkey | index | postgres | sbtest97
public | sbtest98_pkey | index | postgres | sbtest98
public | sbtest99_pkey | index | postgres | sbtest99
public | sbtest9_pkey | index | postgres | sbtest9
(503 rows)अच्छा लग रहा है...परीक्षण शुरू करने के लिए बस दौड़ें:
sysbench --test=/usr/local/share/sysbench/oltp.lua \
--pgsql-host=aurora.cluster-ctfirtyhadgr.us-east-1.rds.amazonaws.com \
--pgsql-db=postgres \
--pgsql-user=postgres \
--pgsql-password=postgres \
--pgsql-port=5432 \
--oltp-tables-count=250 \
--oltp-table-size=450000 \
--max-requests=0 \
--forced-shutdown \
--report-interval=60 \
--oltp_simple_ranges=0 \
--oltp-distinct-ranges=0 \
--oltp-sum-ranges=0 \
--oltp-order-ranges=0 \
--oltp-point-selects=0 \
--rand-type=uniform \
--max-time=600 \
--num-threads=1000 \
runसावधानी का एक नोट:
आरडीएस भंडारण "लोचदार" नहीं है, जिसका अर्थ है कि उदाहरण बनाते समय आवंटित भंडारण स्थान बेंचमार्क के दौरान उत्पन्न डेटा की मात्रा में फिट होने के लिए पर्याप्त होना चाहिए, अन्यथा आरडीएस विफल हो जाएगा:
FATAL: PQexec() failed: 7 PANIC: could not write to file "pg_wal/xlogtemp.29144": No space left on device
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
FATAL: failed query: COMMIT
FATAL: failed to execute function `event': 3
WARNING: terminating connection because of crash of another server process
DETAIL: The postmaster has commanded this server process to roll back the current transaction and exit, because another server process exited abnormally and possibly corrupted shared memory.
HINT: In a moment you should be able to reconnect to the database and repeat your command.
WARNING: terminating connection because of crash of another server processडेटाबेस को रोके बिना स्टोरेज का आकार बढ़ाया जा सकता है, हालाँकि, इसे 200 GiB से 500 GiB तक बढ़ाने में मुझे लगभग 30 मिनट का समय लगा:
 आरडीएस पर स्टोरेज स्पेस बढ़ाना
आरडीएस पर स्टोरेज स्पेस बढ़ाना और यहाँ sysbench परीक्षा परिणाम हैं:
sysbench 0.5: multi-threaded system evaluation benchmark
Running the test with following options:
Number of threads: 1000
Report intermediate results every 60 second(s)
Random number generator seed is 0 and will be ignored
Forcing shutdown in 630 seconds
Initializing worker threads...
Threads started!
[ 60s] threads: 1000, tps: 1070.40, reads: 0.00, writes: 4309.35, response time: 1808.81ms (95%), errors: 0.02, reconnects: 0.00
[ 120s] threads: 1000, tps: 889.68, reads: 0.00, writes: 3575.35, response time: 1951.12ms (95%), errors: 0.02, reconnects: 0.00
[ 180s] threads: 1000, tps: 574.57, reads: 0.00, writes: 2320.62, response time: 3936.73ms (95%), errors: 0.00, reconnects: 0.00
[ 240s] threads: 1000, tps: 232.10, reads: 0.00, writes: 928.43, response time: 10994.37ms (95%), errors: 0.00, reconnects: 0.00
[ 300s] threads: 1000, tps: 242.40, reads: 0.00, writes: 969.60, response time: 9412.39ms (95%), errors: 0.00, reconnects: 0.00
[ 360s] threads: 1000, tps: 257.73, reads: 0.00, writes: 1030.98, response time: 8833.64ms (95%), errors: 0.02, reconnects: 0.00
[ 420s] threads: 1000, tps: 264.65, reads: 0.00, writes: 1036.60, response time: 9192.42ms (95%), errors: 0.00, reconnects: 0.00
[ 480s] threads: 1000, tps: 278.07, reads: 0.00, writes: 1134.27, response time: 7133.76ms (95%), errors: 0.00, reconnects: 0.00
[ 540s] threads: 1000, tps: 250.40, reads: 0.00, writes: 1001.53, response time: 9628.97ms (95%), errors: 0.00, reconnects: 0.00
[ 600s] threads: 1000, tps: 249.97, reads: 0.00, writes: 996.92, response time: 10724.58ms (95%), errors: 0.00, reconnects: 0.00
OLTP test statistics:
queries performed:
read: 0
write: 1038401
other: 519199
total: 1557600
transactions: 259598 (428.59 per sec.)
read/write requests: 1038401 (1714.36 per sec.)
other operations: 519199 (857.18 per sec.)
ignored errors: 3 (0.00 per sec.)
reconnects: 0 (0.00 per sec.)
General statistics:
total time: 605.7086s
total number of events: 259598
total time taken by event execution: 602999.7582s
response time:
min: 55.02ms
avg: 2322.82ms
max: 13133.36ms
approx. 95 percentile: 8400.39ms
Threads fairness:
events (avg/stddev): 259.5980/3.20
execution time (avg/stddev): 602.9998/2.77बेंचमार्क मेट्रिक्स
मेट्रिक्स को AWS मॉनिटरिंग टूल CloudWatch और Performance Insights का उपयोग करके कैप्चर किया जा सकता है। जिज्ञासुओं के लिए यहां कुछ नमूने:
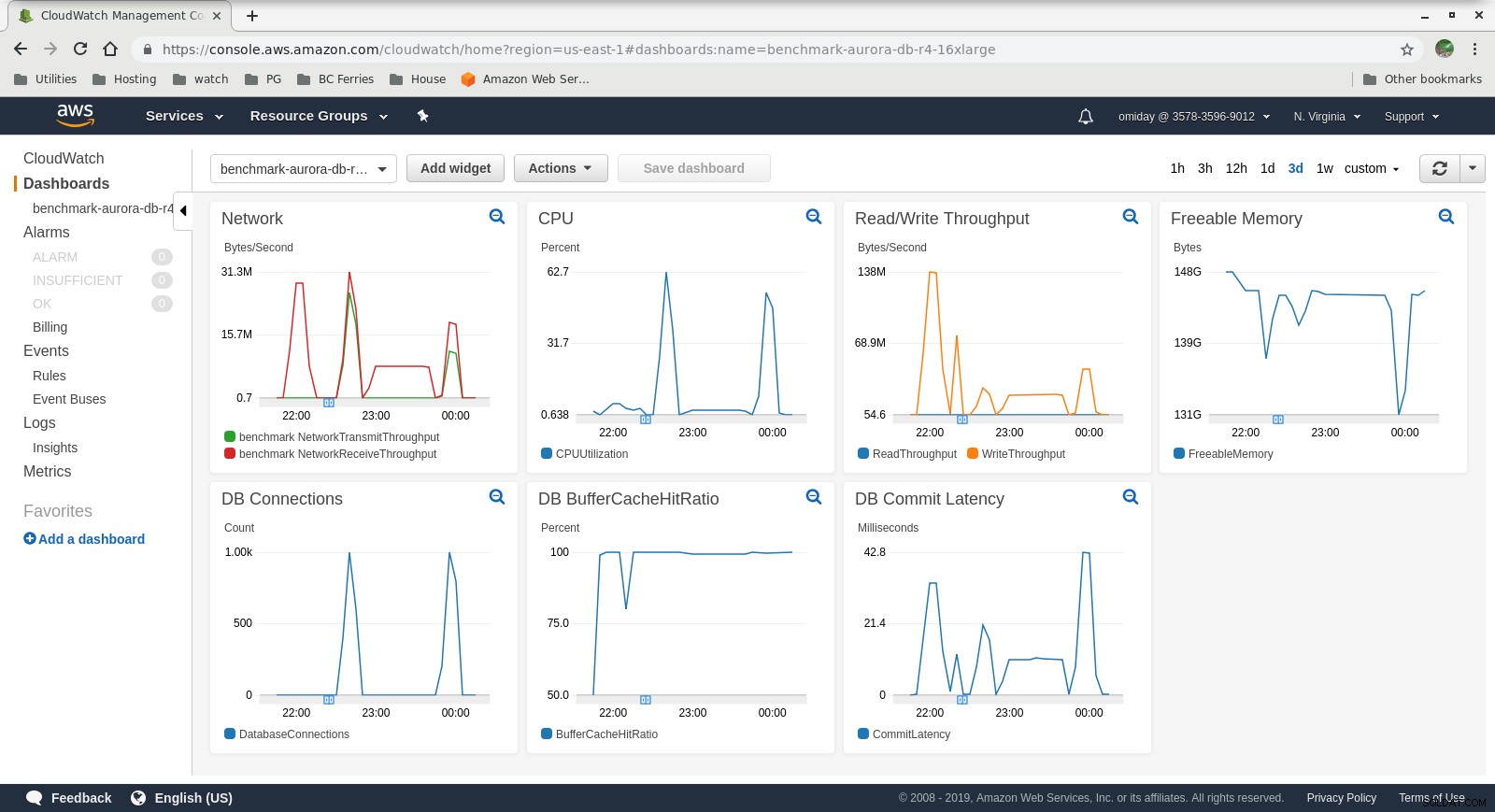 DB इंस्टेंस क्लाउडवॉच मेट्रिक्स
DB इंस्टेंस क्लाउडवॉच मेट्रिक्स 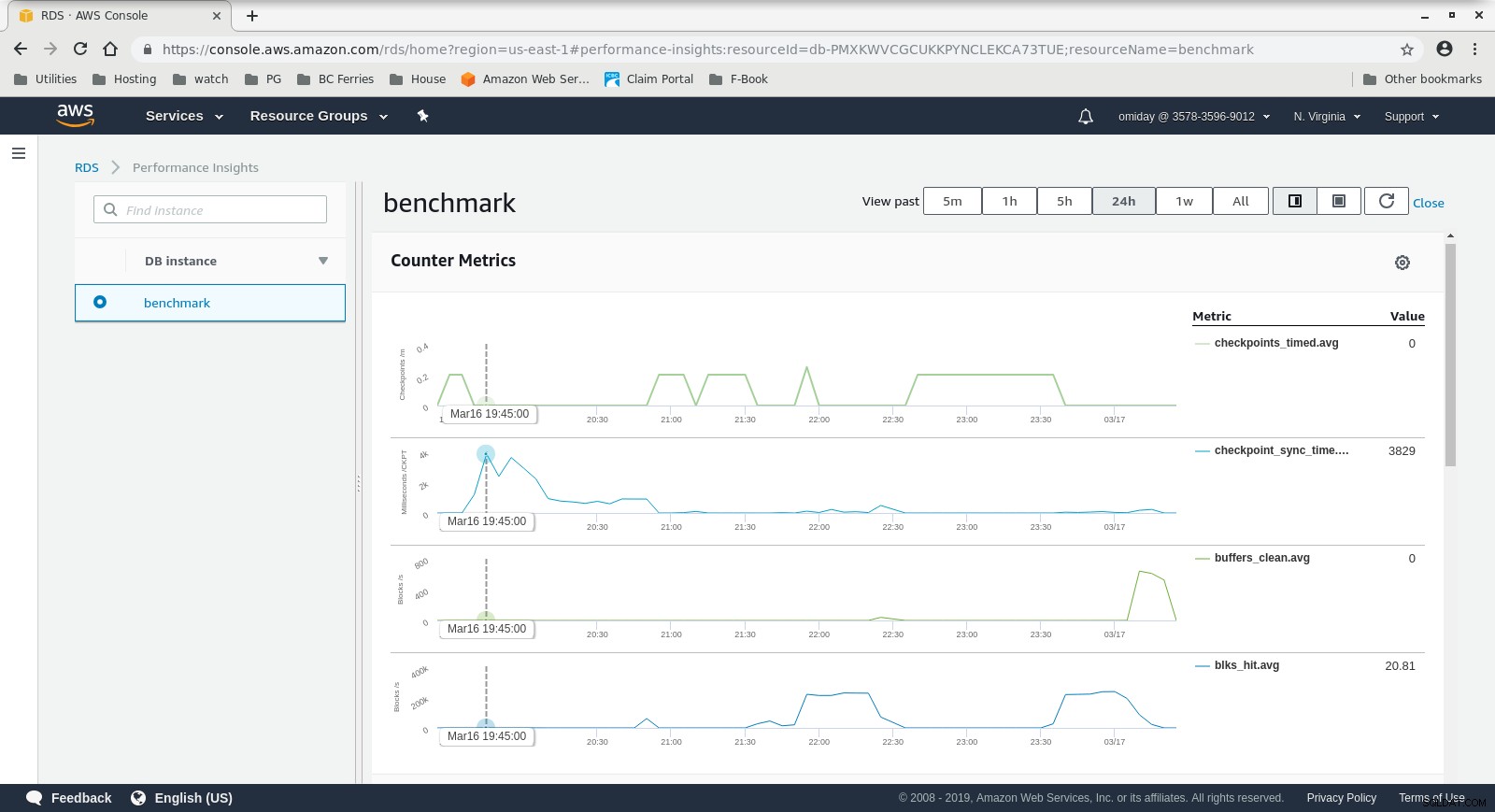 RDS प्रदर्शन अंतर्दृष्टि - काउंटर मेट्रिक्स
RDS प्रदर्शन अंतर्दृष्टि - काउंटर मेट्रिक्स 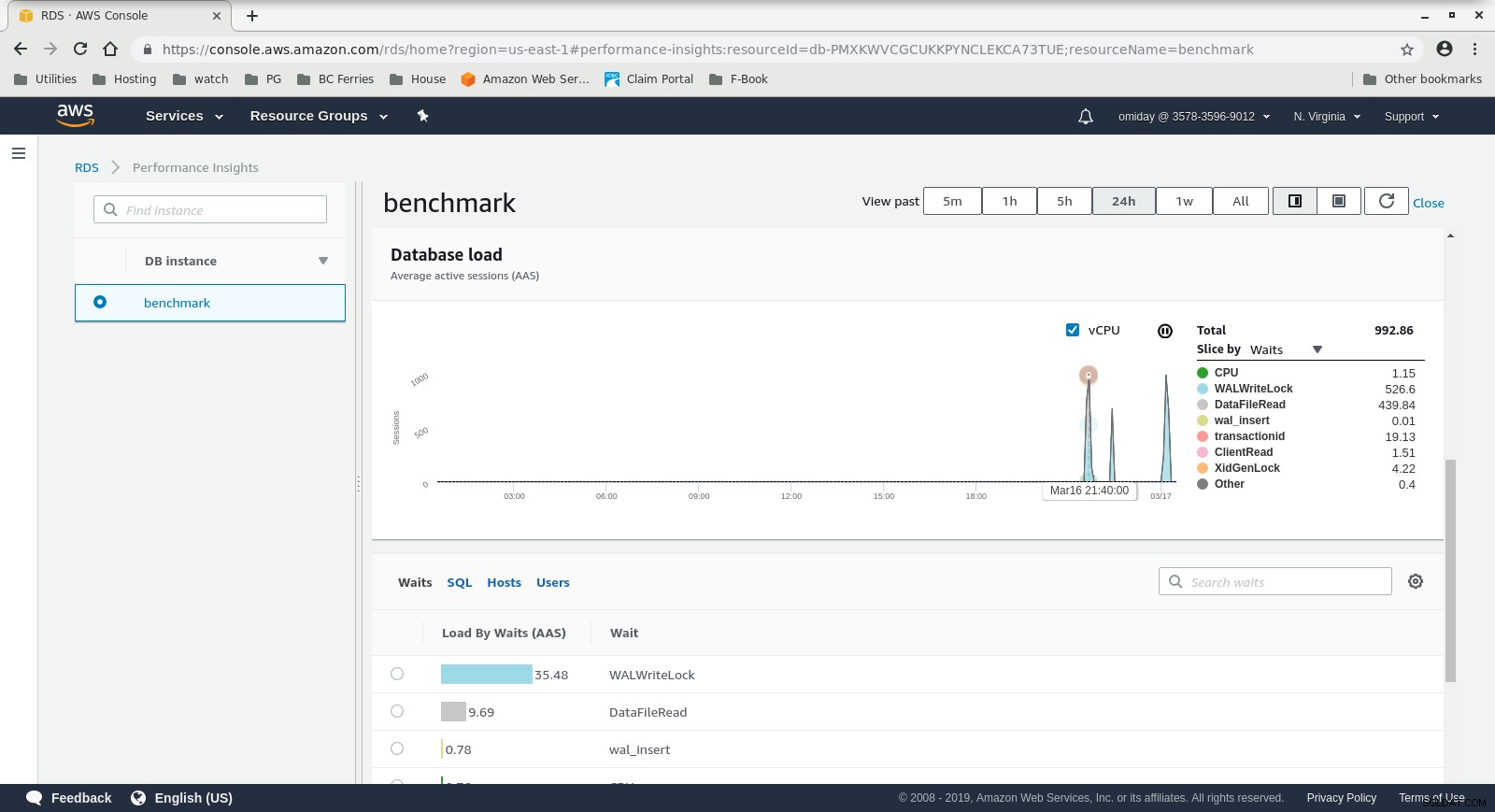 RDS प्रदर्शन अंतर्दृष्टि - डेटाबेस लोड
RDS प्रदर्शन अंतर्दृष्टि - डेटाबेस लोड परिणाम
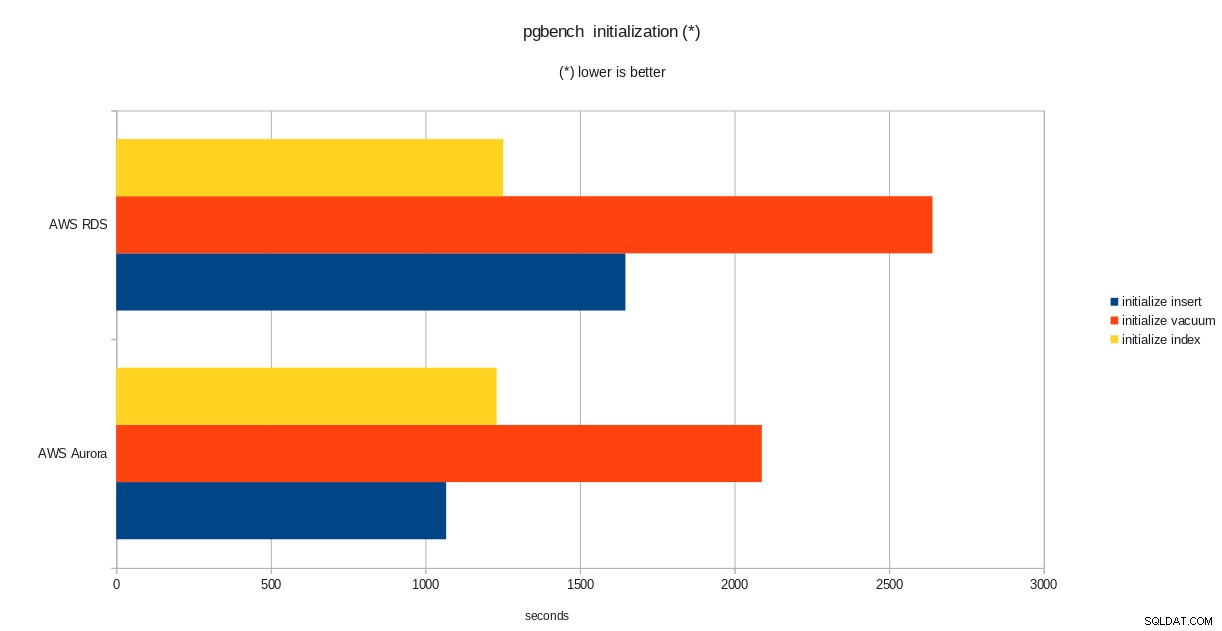 pgbench आरंभीकरण परिणाम
pgbench आरंभीकरण परिणाम 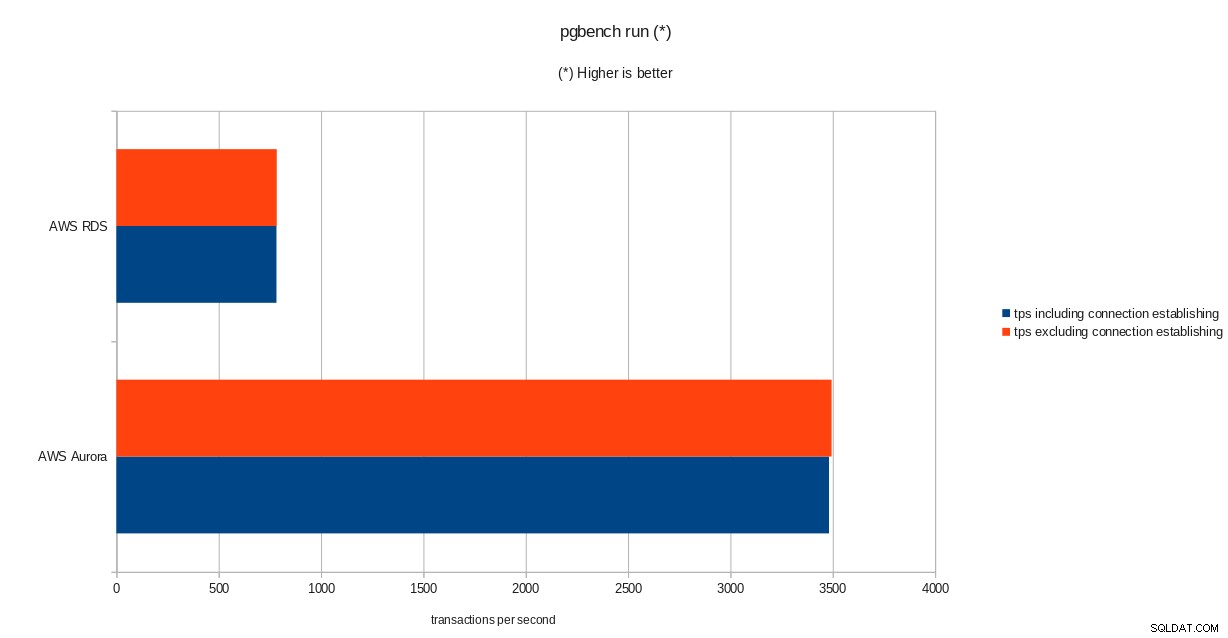 pgbench रन परिणाम
pgbench रन परिणाम 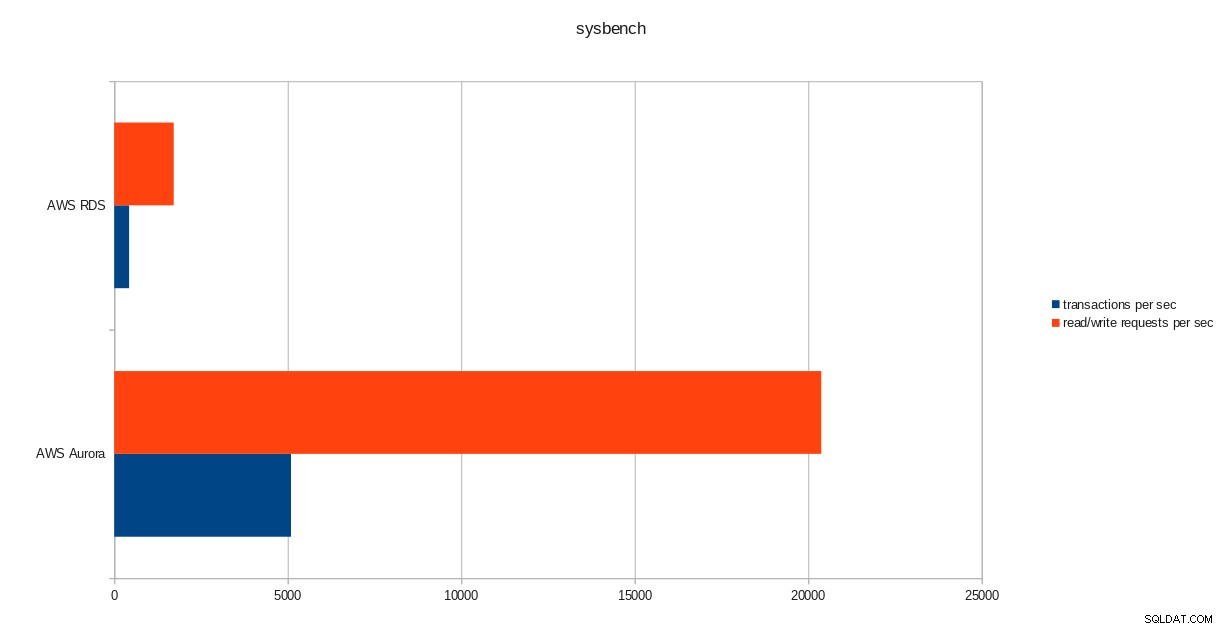 sysbench परिणाम
sysbench परिणाम निष्कर्ष
PostgreSQL संस्करण 10.6 चलाने के बावजूद, Amazon Aurora स्पष्ट रूप से RDS से बेहतर प्रदर्शन करता है जो संस्करण 11.1 पर है, और यह कोई आश्चर्य की बात नहीं है। ऑरोरा अक्सर पूछे जाने वाले प्रश्नों के अनुसार, अमेज़ॅन ने समग्र डेटाबेस प्रदर्शन को बेहतर बनाने के लिए बहुत अधिक प्रयास किया, जो एक पुन:डिज़ाइन किए गए स्टोरेज इंजन के शीर्ष पर बनाया गया था।
श्रृंखला में अगला
अगला भाग PostgreSQL के लिए Google क्लाउड SQL के बारे में होगा।