पिछले महीने मैंने एक विशेष द्वीप चुनौती को कवर किया था। कार्य प्रत्येक सेवा आईडी के लिए गतिविधि की अवधि की पहचान करना था, सेकंड की एक इनपुट संख्या तक के अंतराल को सहन करना (@allowedgap ) चेतावनी यह थी कि समाधान 2012 से पहले संगत होना चाहिए, इसलिए आप LAG और LEAD जैसे कार्यों का उपयोग नहीं कर सकते हैं, या एक फ्रेम के साथ विंडो फ़ंक्शन को एकत्रित नहीं कर सकते। मुझे टोबी ओवोड-एवरेट, पीटर लार्सन और कामिल कोस्नो द्वारा टिप्पणियों में पोस्ट किए गए कई बहुत ही रोचक समाधान मिले। उनके समाधानों पर जाना सुनिश्चित करें क्योंकि वे सभी काफी रचनात्मक हैं।
मजे की बात है, कई समाधान इसके बिना अनुशंसित सूचकांक के साथ धीमी गति से चलते हैं। इस लेख में मैं इसके लिए एक स्पष्टीकरण का प्रस्ताव करता हूं।
हालांकि सभी समाधान दिलचस्प थे, यहां मैं कामिल कोस्नो के समाधान पर ध्यान केंद्रित करना चाहता था, जो ज़ोपा के साथ एक ईटीएल डेवलपर हैं। अपने समाधान में, कामिल ने LAG और LEAD के बिना LAG और LEAD का अनुकरण करने के लिए एक बहुत ही रचनात्मक तकनीक का उपयोग किया। यदि आपको 2012 से पहले के संगत कोड का उपयोग करके LAG/LEAD जैसी गणना करने की आवश्यकता है तो आपको शायद तकनीक आसान लगेगी।
अनुशंसित अनुक्रमणिका के बिना कुछ समाधान तेज़ क्यों हैं?
एक अनुस्मारक के रूप में, मैंने चुनौती के समाधान का समर्थन करने के लिए निम्नलिखित अनुक्रमणिका का उपयोग करने का सुझाव दिया:
CREATE INDEX idx_sid_ltm_lid ON dbo.EventLog(serviceid, logtime, logid);
मेरा पूर्व-2012-संगत समाधान निम्नलिखित था:
DECLARE @allowedgap AS INT = 66; -- in seconds
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
),
C2 AS
(
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U
),
C3 AS
(
SELECT serviceid, eventtype, logtime,
(ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) - 1) / 2 + 1 AS grp
FROM C2
CROSS APPLY ( VALUES( CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END ) ) AS A(countactive)
WHERE (eventtype = 's' AND countactive = 1)
OR (eventtype = 'e' AND countactive = 0)
)
SELECT serviceid, s AS starttime, DATEADD(second, -@allowedgap, e) AS endtime
FROM C3
PIVOT( MAX(logtime) FOR eventtype IN (s, e) ) AS P; चित्र 1 में अनुशंसित अनुक्रमणिका के साथ मेरे समाधान की योजना है।
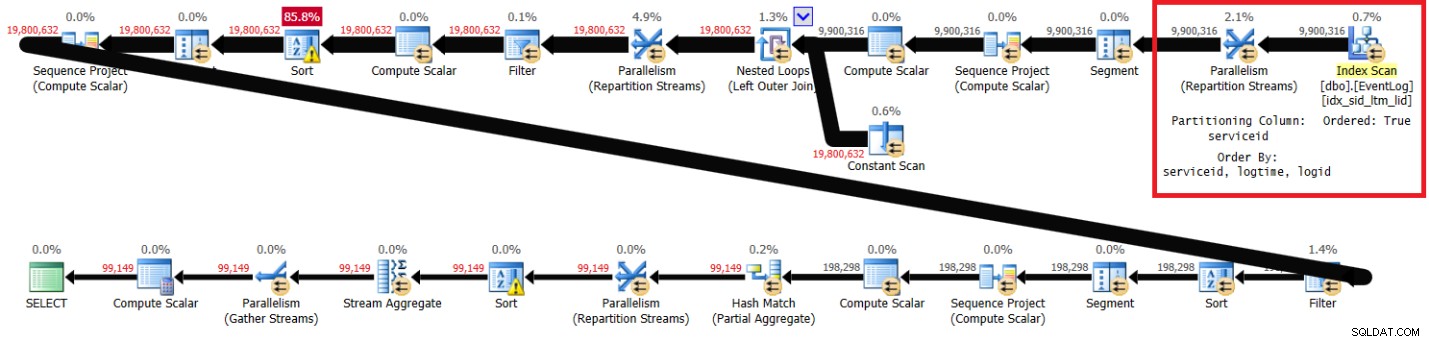 चित्र 1:अनुशंसित सूचकांक के साथ इत्ज़िक के समाधान की योजना
चित्र 1:अनुशंसित सूचकांक के साथ इत्ज़िक के समाधान की योजना
ध्यान दें कि योजना मुख्य क्रम में अनुशंसित सूचकांक को स्कैन करती है (ऑर्डर की गई संपत्ति सही है), ऑर्डर-संरक्षण एक्सचेंज का उपयोग करके सर्विसिड द्वारा स्ट्रीम को विभाजित करता है, और फिर सॉर्टिंग की आवश्यकता के बिना इंडेक्स ऑर्डर पर निर्भर पंक्ति संख्याओं की प्रारंभिक गणना लागू करता है। मेरे लैपटॉप पर इस क्वेरी निष्पादन के लिए मुझे मिले प्रदर्शन आँकड़े निम्नलिखित हैं (बीता हुआ समय, CPU समय और सेकंड में व्यक्त शीर्ष प्रतीक्षा):
elapsed: 43, CPU: 60, logical reads: 144,120 , top wait: CXPACKET: 166
मैंने तब अनुशंसित सूचकांक को छोड़ दिया और समाधान को फिर से चलाया:
DROP INDEX idx_sid_ltm_lid ON dbo.EventLog;
मुझे चित्र 2 में दिखाया गया प्लान मिला है।
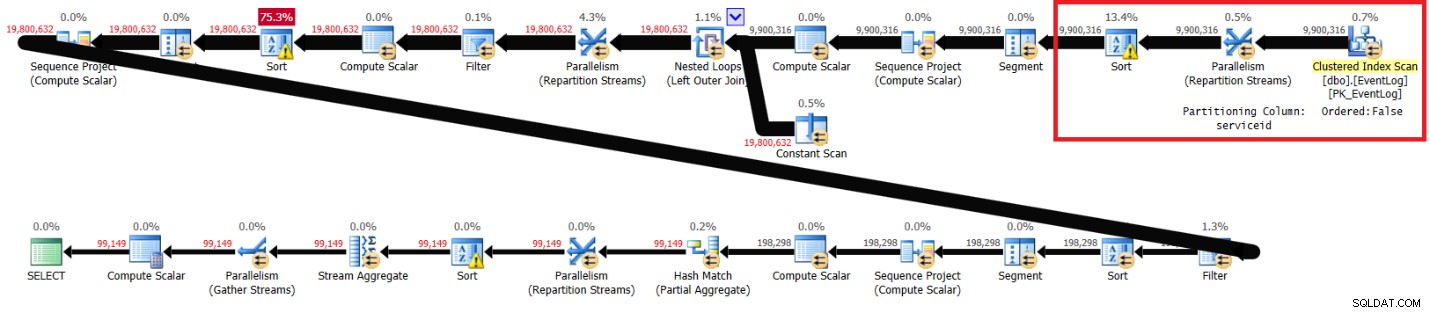 चित्र 2:अनुशंसित अनुक्रमणिका के बिना इत्ज़िक के समाधान की योजना बनाएं
चित्र 2:अनुशंसित अनुक्रमणिका के बिना इत्ज़िक के समाधान की योजना बनाएं
दो योजनाओं में हाइलाइट किए गए खंड अंतर दिखाते हैं। अनुशंसित इंडेक्स के बिना योजना क्लस्टर्ड इंडेक्स का एक अनियंत्रित स्कैन करती है, गैर-आदेश-संरक्षण एक्सचेंज का उपयोग करके सर्विसिड द्वारा स्ट्रीम को विभाजित करती है, और फिर विंडो फ़ंक्शन की ज़रूरतों (सर्विसिड, लॉगटाइम, लॉगिड द्वारा) जैसी पंक्तियों को सॉर्ट करती है। बाकी काम दोनों योजनाओं में एक जैसा लगता है। आपको लगता है कि अनुशंसित सूचकांक के बिना योजना धीमी होनी चाहिए क्योंकि इसमें एक अतिरिक्त प्रकार है जो अन्य योजना में नहीं है। लेकिन यहाँ प्रदर्शन आँकड़े हैं जो मुझे इस योजना के लिए मेरे लैपटॉप पर मिले:
elapsed: 31, CPU: 89, logical reads: 172,598 , CXPACKET waits: 84
इसमें अधिक CPU समय शामिल होता है, जो आंशिक रूप से अतिरिक्त प्रकार के कारण होता है; इसमें अधिक I/O शामिल है, शायद अतिरिक्त सॉर्ट स्पिल के कारण; हालाँकि, बीता हुआ समय लगभग 30 प्रतिशत तेज है। यह क्या समझा सकता है? इसका पता लगाने का एक तरीका एसएसएमएस में लाइव क्वेरी सांख्यिकी विकल्प सक्षम के साथ क्वेरी को चलाना है। जब मैंने ऐसा किया, तो सबसे सही समानांतरवाद (रिपार्टिशन स्ट्रीम) ऑपरेटर अनुशंसित इंडेक्स के बिना 6 सेकंड में और अनुशंसित इंडेक्स के साथ 35 सेकंड में समाप्त हो गया। मुख्य अंतर यह है कि पूर्व को एक इंडेक्स से पहले से ऑर्डर किया गया डेटा मिलता है, और यह ऑर्डर-संरक्षण एक्सचेंज है। बाद वाले को डेटा अनियंत्रित हो जाता है, और यह ऑर्डर-संरक्षण एक्सचेंज नहीं है। आदेश-संरक्षण एक्सचेंज गैर-आदेश-संरक्षण वाले एक्सचेंजों की तुलना में अधिक महंगे होते हैं। इसके अलावा, कम से कम योजना के सबसे दाहिने हिस्से में पहले क्रम तक, पूर्व पंक्तियों को एक्सचेंज विभाजन कॉलम के समान क्रम में वितरित करता है, इसलिए आपको समानांतर में पंक्तियों को वास्तव में संसाधित करने के लिए सभी थ्रेड नहीं मिलते हैं। बाद में पंक्तियों को अनियंत्रित किया जाता है, इसलिए आपको पंक्तियों को समानांतर में संसाधित करने के लिए सभी धागे मिलते हैं। आप देख सकते हैं कि दोनों योजनाओं में शीर्ष प्रतीक्षा CXPACKET है, लेकिन पहले मामले में प्रतीक्षा समय बाद वाले की तुलना में दोगुना है, आपको बता रहा है कि बाद के मामले में समांतरता प्रबंधन अधिक इष्टतम है। खेल में कुछ अन्य कारक हो सकते हैं जिनके बारे में मैं नहीं सोच रहा हूं। यदि आपके पास अतिरिक्त विचार हैं जो आश्चर्यजनक प्रदर्शन अंतर की व्याख्या कर सकते हैं, तो कृपया साझा करें।
मेरे लैपटॉप पर इसके परिणामस्वरूप अनुशंसित सूचकांक के बिना अनुशंसित सूचकांक के साथ निष्पादन तेज हो गया। फिर भी, एक और परीक्षण मशीन पर, यह दूसरी तरफ था। आखिरकार, आपके पास स्पिलिंग क्षमता के साथ एक अतिरिक्त प्रकार है।
जिज्ञासा से बाहर, मैंने अनुशंसित सूचकांक के साथ एक सीरियल निष्पादन (MAXDOP 1 विकल्प के साथ) का परीक्षण किया, और मेरे लैपटॉप पर निम्नलिखित प्रदर्शन आँकड़े प्राप्त किए:
elapsed: 42, CPU: 40, logical reads: 143,519
जैसा कि आप देख सकते हैं, रन टाइम अनुशंसित इंडेक्स के साथ समानांतर निष्पादन के रन टाइम के समान है। मेरे लैपटॉप में केवल 4 लॉजिकल सीपीयू हैं। बेशक, अलग-अलग हार्डवेयर के साथ आपका माइलेज अलग-अलग हो सकता है। मुद्दा यह है कि यह विभिन्न विकल्पों का परीक्षण करने योग्य है, जिसमें अनुक्रमण के साथ और बिना अनुक्रमणिका शामिल है जो आपको लगता है कि मदद करनी चाहिए। परिणाम कभी-कभी आश्चर्यजनक और विपरीत होते हैं।
कामिल का समाधान
मैं वास्तव में कामिल के समाधान से प्रभावित था और विशेष रूप से 2012 से पहले की संगत तकनीक के साथ एलएजी और लीड का अनुकरण करने का तरीका पसंद आया।
समाधान में पहला कदम लागू करने वाला कोड यहां दिया गया है:
SELECT serviceid, logtime, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time FROM dbo.EventLog;
यह कोड निम्नलिखित आउटपुट उत्पन्न करता है (केवल सर्विसिड 1 के लिए डेटा दिखा रहा है):
serviceid logtime end_time start_time ---------- -------------------- --------- ----------- 1 2018-09-12 08:00:00 1 0 1 2018-09-12 08:01:01 2 1 1 2018-09-12 08:01:59 3 2 1 2018-09-12 08:03:00 4 3 1 2018-09-12 08:05:00 5 4 1 2018-09-12 08:06:02 6 5 ...
यह चरण दो पंक्ति संख्याओं की गणना करता है जो प्रत्येक पंक्ति के लिए अलग होती हैं, सर्विसिड द्वारा विभाजित होती हैं, और लॉगटाइम द्वारा आदेशित होती हैं। वर्तमान पंक्ति संख्या समाप्ति समय का प्रतिनिधित्व करती है (इसे end_time कहते हैं), और वर्तमान पंक्ति संख्या घटा एक प्रारंभ समय का प्रतिनिधित्व करती है (इसे start_time कहते हैं)।
निम्नलिखित कोड समाधान के दूसरे चरण को लागू करता है:
WITH RNS AS
(
SELECT
serviceid,
logtime,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time
FROM dbo.EventLog
)
SELECT *
FROM RNS
UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U; यह चरण निम्न आउटपुट उत्पन्न करता है:
serviceid logtime rownum time_type ---------- -------------------- ------- ----------- 1 2018-09-12 08:00:00 0 start_time 1 2018-09-12 08:00:00 1 end_time 1 2018-09-12 08:01:01 1 start_time 1 2018-09-12 08:01:01 2 end_time 1 2018-09-12 08:01:59 2 start_time 1 2018-09-12 08:01:59 3 end_time 1 2018-09-12 08:03:00 3 start_time 1 2018-09-12 08:03:00 4 end_time 1 2018-09-12 08:05:00 4 start_time 1 2018-09-12 08:05:00 5 end_time 1 2018-09-12 08:06:02 5 start_time 1 2018-09-12 08:06:02 6 end_time ...
यह चरण प्रत्येक पंक्ति को दो पंक्तियों में खोल देता है, प्रत्येक लॉग प्रविष्टि को दोहराता है—एक बार समय के लिए start_time टाइप करें और दूसरा end_time के लिए। जैसा कि आप देख सकते हैं, न्यूनतम और अधिकतम पंक्ति संख्याओं के अलावा, प्रत्येक पंक्ति संख्या दो बार दिखाई देती है—एक बार वर्तमान घटना (start_time) के लॉग समय के साथ और दूसरी पिछली घटना (end_time) के लॉग समय के साथ।
निम्नलिखित कोड समाधान में तीसरे चरण को लागू करता है:
WITH RNS AS
(
SELECT
serviceid,
logtime,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time
FROM dbo.EventLog
)
SELECT *
FROM RNS
UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U
PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P; यह कोड निम्न आउटपुट उत्पन्न करता है:
serviceid rownum start_time end_time ----------- -------------------- --------------------------- --------------------------- 1 0 2018-09-12 08:00:00 NULL 1 1 2018-09-12 08:01:01 2018-09-12 08:00:00 1 2 2018-09-12 08:01:59 2018-09-12 08:01:01 1 3 2018-09-12 08:03:00 2018-09-12 08:01:59 1 4 2018-09-12 08:05:00 2018-09-12 08:03:00 1 5 2018-09-12 08:06:02 2018-09-12 08:05:00 1 6 NULL 2018-09-12 08:06:02 ...
यह चरण डेटा को पिवट करता है, समान पंक्ति संख्या के साथ पंक्तियों के जोड़े को समूहीकृत करता है, और वर्तमान ईवेंट लॉग समय (start_time) के लिए एक कॉलम लौटाता है और दूसरा पिछले ईवेंट लॉग समय (end_time) के लिए लौटाता है। यह हिस्सा प्रभावी रूप से एक एलएजी फ़ंक्शन का अनुकरण करता है।
निम्नलिखित कोड समाधान में चौथा चरण लागू करता है:
DECLARE @allowedgap AS INT = 66;
WITH RNS AS
(
SELECT
serviceid,
logtime,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time
FROM dbo.EventLog
)
SELECT serviceid, rownum, start_time, end_time,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) AS start_time_grp,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) -1 AS end_time_grp
FROM RNS
UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U
PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P
WHERE ISNULL(DATEDIFF(second, end_time, start_time), @allowedgap + 1) > @allowedgap; यह कोड निम्न आउटपुट उत्पन्न करता है:
serviceid rownum start_time end_time start_time_grp end_time_grp ---------- ------- -------------------- -------------------- --------------- ------------- 1 0 2018-09-12 08:00:00 NULL 1 0 1 4 2018-09-12 08:05:00 2018-09-12 08:03:00 2 1 1 6 NULL 2018-09-12 08:06:02 3 2 ...
यह चरण उन युग्मों को फ़िल्टर करता है जहां पिछले समाप्ति समय और वर्तमान प्रारंभ समय के बीच का अंतर अनुमत अंतराल से अधिक है, और पंक्तियों में केवल एक घटना है। अब आपको प्रत्येक वर्तमान पंक्ति के प्रारंभ समय को अगली पंक्ति के समाप्ति समय से जोड़ने की आवश्यकता है। इसके लिए LEAD जैसी गणना की आवश्यकता होती है। इसे प्राप्त करने के लिए, कोड, फिर से, पंक्ति संख्याएँ बनाता है जो एक-दूसरे से अलग होती हैं, केवल इस बार वर्तमान पंक्ति संख्या प्रारंभ समय (start_time_grp ) का प्रतिनिधित्व करती है और वर्तमान पंक्ति संख्या माइनस एक समाप्ति समय (end_time_grp) का प्रतिनिधित्व करती है।
पहले की तरह, अगला चरण (नंबर 5) पंक्तियों को अनपिवट करना है। इस चरण को लागू करने वाला कोड यहां दिया गया है:
DECLARE @allowedgap AS INT = 66;
WITH RNS AS
(
SELECT
serviceid,
logtime,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time
FROM dbo.EventLog
),
Ranges as
(
SELECT serviceid, rownum, start_time, end_time,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) AS start_time_grp,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) -1 AS end_time_grp
FROM RNS
UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U
PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P
WHERE ISNULL(DATEDIFF(second, end_time, start_time), @allowedgap + 1) > @allowedgap
)
SELECT *
FROM Ranges
UNPIVOT(grp FOR grp_type IN(start_time_grp, end_time_grp)) AS U; आउटपुट:
serviceid rownum start_time end_time grp grp_type ---------- ------- -------------------- -------------------- ---- --------------- 1 0 2018-09-12 08:00:00 NULL 0 end_time_grp 1 4 2018-09-12 08:05:00 2018-09-12 08:03:00 1 end_time_grp 1 0 2018-09-12 08:00:00 NULL 1 start_time_grp 1 6 NULL 2018-09-12 08:06:02 2 end_time_grp 1 4 2018-09-12 08:05:00 2018-09-12 08:03:00 2 start_time_grp 1 6 NULL 2018-09-12 08:06:02 3 start_time_grp ...
जैसा कि आप देख सकते हैं, सेवा आईडी के भीतर प्रत्येक द्वीप के लिए जीआरपी कॉलम अद्वितीय है।
चरण 6 समाधान का अंतिम चरण है। यहां इस चरण को लागू करने वाला कोड है, जो संपूर्ण समाधान कोड भी है:
DECLARE @allowedgap AS INT = 66;
WITH RNS AS
(
SELECT
serviceid,
logtime,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time
FROM dbo.EventLog
),
Ranges as
(
SELECT serviceid, rownum, start_time, end_time,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) AS start_time_grp,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) -1 AS end_time_grp
FROM RNS
UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U
PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P
WHERE ISNULL(DATEDIFF(second, end_time, start_time), @allowedgap + 1) > @allowedgap
)
SELECT
serviceid, MIN(start_time) AS start_time, MAX(end_time) AS end_time
FROM Ranges
UNPIVOT(grp FOR grp_type IN(start_time_grp, end_time_grp)) AS U
GROUP BY serviceid, grp
HAVING (MIN(start_time) IS NOT NULL AND MAX(end_time) IS NOT NULL); यह चरण निम्न आउटपुट उत्पन्न करता है:
serviceid start_time end_time ----------- --------------------------- --------------------------- 1 2018-09-12 08:00:00 2018-09-12 08:03:00 1 2018-09-12 08:05:00 2018-09-12 08:06:02 ...
यह चरण सर्विसिड और जीआरपी द्वारा पंक्तियों को समूहित करता है, केवल प्रासंगिक समूहों को फ़िल्टर करता है, और द्वीप की शुरुआत के रूप में न्यूनतम start_time और द्वीप के अंत के रूप में अधिकतम समाप्ति समय देता है।
चित्र 3 में वह योजना है जो मुझे इस समाधान के लिए अनुशंसित अनुक्रमणिका के साथ मिली है:
CREATE INDEX idx_sid_ltm_lid ON dbo.EventLog(serviceid, logtime, logid);
चित्र 3 में अनुशंसित अनुक्रमणिका के साथ योजना बनाएं।
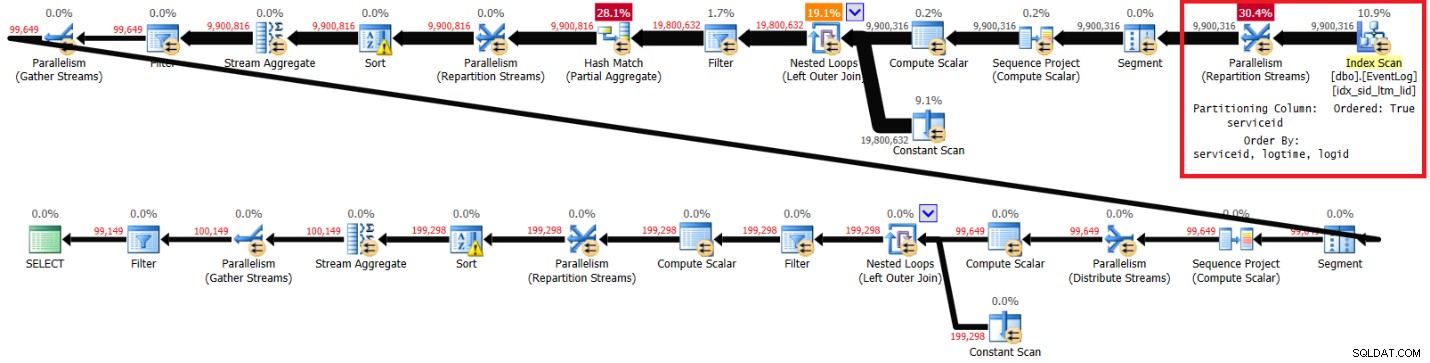 चित्र 3:अनुशंसित सूचकांक के साथ कामिल के समाधान की योजना
चित्र 3:अनुशंसित सूचकांक के साथ कामिल के समाधान की योजना
मेरे लैपटॉप पर इस निष्पादन के लिए मुझे जो प्रदर्शन आंकड़े मिले हैं, वे यहां दिए गए हैं:
elapsed: 44, CPU: 66, logical reads: 72979, top wait: CXPACKET: 148
मैंने तब अनुशंसित सूचकांक को छोड़ दिया और समाधान को फिर से चलाया:
DROP INDEX idx_sid_ltm_lid ON dbo.EventLog;
मुझे अनुशंसित इंडेक्स के बिना निष्पादन के लिए चित्र 4 में दिखाया गया प्लान मिला है।
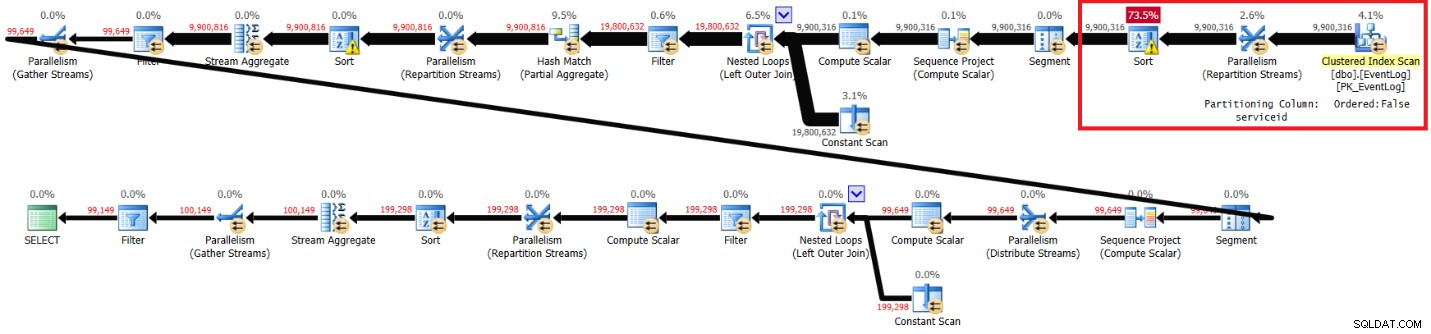 चित्र 4:अनुशंसित अनुक्रमणिका के बिना कामिल के समाधान की योजना बनाएं
चित्र 4:अनुशंसित अनुक्रमणिका के बिना कामिल के समाधान की योजना बनाएं
इस निष्पादन के लिए मुझे जो प्रदर्शन आंकड़े मिले हैं, वे यहां दिए गए हैं:
elapsed: 30, CPU: 85, logical reads: 94813, top wait: CXPACKET: 70
रन टाइम, सीपीयू टाइम्स, और सीएक्सपैकेट प्रतीक्षा समय मेरे समाधान के समान हैं, हालांकि लॉजिकल रीड कम हैं। कामिल का समाधान भी अनुशंसित सूचकांक के बिना मेरे लैपटॉप पर तेजी से चलता है, और ऐसा लगता है कि यह समान कारणों से है।
निष्कर्ष
विसंगतियाँ अच्छी बात हैं। वे आपको जिज्ञासु बनाते हैं और आपको समस्या के मूल कारण की खोज करने के लिए प्रेरित करते हैं, और परिणामस्वरूप, नई चीजें सीखते हैं। यह देखना दिलचस्प है कि कुछ प्रश्न, कुछ मशीनों पर, अनुशंसित अनुक्रमण के बिना तेजी से चलते हैं।
आपके समाधान के लिए टोबी, पीटर और कामिल को फिर से धन्यवाद। इस लेख में मैंने कामिल के समाधान को कवर किया है, जिसमें पंक्ति संख्याओं के साथ LAG और LEAD का अनुकरण करने की उनकी रचनात्मक तकनीक है, जो बिना धुरी के और धुरी है। आपको यह तकनीक तब उपयोगी लगेगी जब आपको LAG- और LEAD जैसी गणनाओं की आवश्यकता होगी, जिन्हें 2012 से पहले के वातावरण में समर्थित होना चाहिए।