चयन * तालिका प्रारूप से विशिष्ट प्रश्न कभी-कभी पर्याप्त नहीं होते हैं। जब किसी क्वेरी के लिए डेटा एक तालिका में नहीं, बल्कि कई में होता है, या जब एक साथ कई चयन पैरामीटर निर्दिष्ट करना आवश्यक होता है, तो आपको अधिक परिष्कृत प्रश्नों की आवश्यकता होगी।
यह लेख इस तरह की क्वेरी बनाने और जटिल SQL क्वेरी के उदाहरण प्रदान करने का तरीका बताएगा।
जटिल क्वेरी कैसी दिखती है?
सबसे पहले, SQL क्वेरी की रचना के लिए शर्तों को परिभाषित करते हैं। विशेष रूप से, आपको निम्नलिखित चयन मापदंडों का उपयोग करने की आवश्यकता होगी:
- उन तालिकाओं के नाम जिनसे आप डेटा निकालना चाहते हैं;
- डेटाबेस में परिवर्तन करने के बाद फ़ील्ड के मान जो मूल में वापस किए जाने चाहिए;
- तालिकाओं के बीच संबंध;
- नमूना की शर्तें;
- सहायक चयन मानदंड (प्रतिबंध, जानकारी प्रस्तुत करने के तरीके, छँटाई का प्रकार)।
विषय को बेहतर ढंग से समझने के लिए, आइए एक उदाहरण पर विचार करें जो निम्नलिखित चार सरल तालिकाओं का उपयोग करता है। पहली पंक्ति तालिका का नाम है जो जटिल प्रश्नों में विदेशी कुंजी के रूप में कार्य करती है। हम इस पर एक उदाहरण के साथ आगे विस्तार से विचार करेंगे:
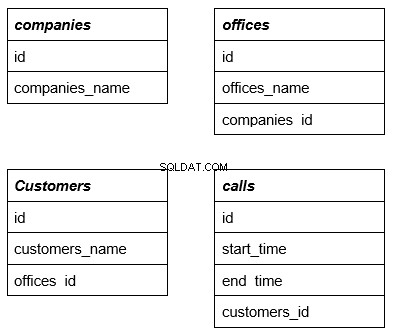
प्रत्येक तालिका में कुछ अन्य तालिकाओं से संबंधित पंक्तियाँ होती हैं। हम आगे बताएंगे कि यह क्यों जरूरी है।
अब, मूल SQL क्वेरी पर नज़र डालते हैं:
SELECT * FROM companies WHERE companies_name %STARTSWITH 'P';%STARTSWITH विधेय निर्दिष्ट वर्ण/वर्णों से शुरू होने वाली पंक्तियों का चयन करता है।
परिणाम इस तरह दिखता है:

अब, एक जटिल SQL क्वेरी पर विचार करें:
SELECT
companies.companies_name,
SUM(CASE WHEN call.id IS NOT NULL THEN 1 ELSE 0 END) AS calls,
AVG(ISNULL(DATEDIFF(SECOND, calls.start_time, calls.end_time),0)) AS avgdifference
FROM companies
LEFT JOIN offices ON offices.companies_id = companies.id
LEFT JOIN customers ON offices.id = customers.offices_id
LEFT JOIN calls ON calls.customers_id = customers.id
GROUP BY
companies.id,
companies.companies_name
HAVING AVG(ISNULL(DATEDIFF(SECOND, calls.start_time, calls.end_time),0)) > (SELECT AVG(DATEDIFF(SECOND, calls.start_time, calls.end_time)) FROM calls)
ORDER BY calls DESC, companies.id ASC;
परिणाम निम्न तालिका है:

तालिका कंपनियों, फ़ोन कॉलों की संगत संख्या और उनकी अनुमानित अवधि को दर्शाती है।
इसके अलावा, यह केवल उन कंपनी के नामों को सूचीबद्ध करता है जहां औसत कॉल अवधि अन्य कंपनियों में औसत कॉल अवधि से अधिक है।
जटिल SQL क्वेरी बनाने के मुख्य नियम क्या हैं?
आइए जटिल प्रश्नों को लिखने के लिए एक बहुउद्देशीय एल्गोरिदम बनाने का प्रयास करें।
सबसे पहले, आपको क्वेरी में भाग लेने वाले डेटा से युक्त तालिकाओं पर निर्णय लेने की आवश्यकता है।
ऊपर दिए गए उदाहरण में कंपनियां . शामिल हैं और कॉल टेबल। यदि आवश्यक डेटा वाली तालिकाएं एक-दूसरे से सीधे संबंधित नहीं हैं, तो आपको उन मध्यवर्ती तालिकाओं को भी शामिल करना होगा जो उनसे जुड़ती हैं।
इस कारण से, हम तालिकाओं को भी जोड़ते हैं, जैसे कार्यालय और ग्राहक , विदेशी कुंजियों का उपयोग करना। इसलिए, इस उदाहरण से तालिकाओं के साथ क्वेरी के किसी भी परिणाम में हमेशा नीचे की पंक्तियाँ शामिल होंगी:
SELECT
...
FROM companies
LEFT JOIN offices ON offices.companies_id = companies.id
LEFT JOIN customers ON offices.id = customers.offices_id
LEFT JOIN calls ON calls.customers_id = customers.id
...;
After that, you must test the correctness of the behavior in the following part of the query:
SELECT * FROM companies
LEFT JOIN offices ON offices.companies_id = companies.id
LEFT JOIN customers ON offices.id = customers.offices_id
LEFT JOIN calls ON calls.customers_id = customers.id;
एक संयुक्त तालिका तीन सबसे महत्वपूर्ण बिंदुओं का सुझाव देती है:
- चयन के बाद फ़ील्ड की सूची पर ध्यान दें। सम्मिलित तालिकाओं से डेटा पढ़ने के संचालन के लिए आवश्यक है कि आप नाम में शामिल होने वाली तालिका का नाम निर्दिष्ट करें फ़ील्ड.
- आपकी जटिल क्वेरी में हमेशा मुख्य तालिका होगी (कंपनियां ) अधिकांश फ़ील्ड इससे पढ़े जाते हैं। संलग्न तालिका, हमारे उदाहरण में, तीन तालिकाओं का उपयोग करती है - कार्यालय , ग्राहक , और कॉल . नाम जॉइन ऑपरेटर के बाद निर्धारित किया जाता है।
- दूसरी तालिका का नाम निर्दिष्ट करने के अलावा, शामिल होने के लिए शर्त निर्दिष्ट करना सुनिश्चित करें। हम इस शर्त पर आगे चर्चा करेंगे।
- क्वेरी बड़ी संख्या में पंक्तियों के साथ एक तालिका प्रदर्शित करेगी। इसे यहां प्रकाशित करने की कोई आवश्यकता नहीं है, क्योंकि यह मध्यवर्ती परिणाम प्रदर्शित करता है। हालाँकि, आप हमेशा इसका आउटपुट स्वयं जाँच सकते हैं। यह बहुत महत्वपूर्ण है, क्योंकि यह अंतिम परिणाम में गलतियों से बचने में मदद करता है।
अब आइए क्वेरी के उस हिस्से को देखें जो प्रत्येक कंपनी के भीतर और सभी कंपनियों के बीच कॉल अवधि की तुलना करता है। हमें सभी कॉलों की औसत अवधि की गणना करने की आवश्यकता है। निम्नलिखित क्वेरी का प्रयोग करें:
SELECT AVG(DATEDIFF(SECOND, calls.start_time, calls.end_time)) FROM calls
ध्यान दें कि हमने DATEDIFF . का उपयोग किया है फ़ंक्शन जो निर्दिष्ट अवधियों के बीच अंतर को आउटपुट करता है। हमारे मामले में, औसत कॉल अवधि 335 सेकंड के बराबर है।
अब क्वेरी में सभी कंपनियों के कॉल पर डेटा जोड़ें।
SELECT
companies.companies_name,
SUM(CASE WHEN calls.id IS NOT NULL THEN 1 ELSE 0 END) AS calls,
AVG(ISNULL(DATEDIFF(SECOND, calls.start_time, calls.end_time),0)) AS avgdifference
FROM companies
LEFT JOIN offices ON offices.companies_id = companies.id
LEFT JOIN customers ON offices.id = customers.offices_id
LEFT JOIN calls ON calls.customers_id = customers.id
GROUP BY
companies.id,
companies.companies_name
ORDER BY calls DESC, companies.id ASC;
इस क्वेरी में,
- योग (मामला जब call.id शून्य नहीं है तो 1 और 0 अंत) - अनावश्यक संचालन से बचने के लिए, हम केवल मौजूदा कॉलों को सारांशित करते हैं - जब किसी कंपनी में कॉल की संख्या शून्य नहीं होती है। संभावित शून्य मानों वाली बड़ी तालिकाओं में यह बहुत महत्वपूर्ण है।
- AVG (ISNULL (DATEDIFF (SECOND, call.start_time, call.end_time), 0)) - क्वेरी उपरोक्त AVG क्वेरी के समान है। हालांकि, यहां हम ISNULL . का उपयोग करते हैं ऑपरेटर जो NULL को 0 से बदल देता है। यह बिना कॉल वाली कंपनियों के लिए आवश्यक है।
हमारे परिणाम:
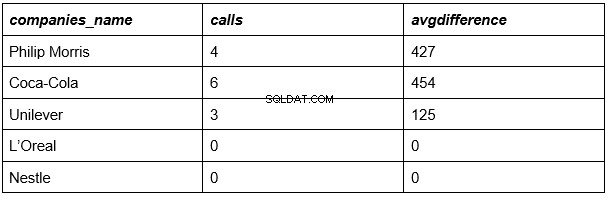
हम लगभग कर चुके हैं। उपरोक्त तालिका कंपनियों की सूची, उनमें से प्रत्येक के लिए संबंधित कॉलों की संख्या और उनमें से प्रत्येक में औसत कॉल अवधि प्रस्तुत करती है।
केवल एक चीज बची है, अंतिम कॉलम के नंबरों की तुलना सभी कंपनियों की सभी कॉलों की औसत अवधि (335 सेकंड) से करें।
यदि आप वह प्रश्न दर्ज करते हैं जिसे हमने शुरुआत में ही प्रस्तुत किया था, तो बस HAVING . जोड़कर भाग, आपको वह मिलेगा जो आपको चाहिए।
हम प्रत्येक पंक्ति पर टिप्पणियां जोड़ने की दृढ़ता से अनुशंसा करते हैं ताकि भविष्य में जब आपको कुछ मौजूदा जटिल SQL प्रश्नों को ठीक करने की आवश्यकता हो तो आप भ्रमित न हों।
अंतिम विचार
हालांकि प्रत्येक जटिल SQL क्वेरी के लिए एक व्यक्तिगत दृष्टिकोण की आवश्यकता होती है, कुछ अनुशंसाएँ ऐसे अधिकांश प्रश्नों की तैयारी के लिए उपयुक्त होती हैं।
- निर्धारित करें कि कौन सी तालिकाएं क्वेरी में भाग लेंगी;
- सरल भागों से जटिल क्वेरी बनाएं;
- प्रश्नों की सटीकता की क्रमिक रूप से, भागों में जांच करें;
- छोटी तालिकाओं के साथ अपनी क्वेरी की सटीकता का परीक्षण करें;
- संचालन वाली प्रत्येक पंक्ति पर '-' चिह्नों का प्रयोग करते हुए विस्तृत टिप्पणियाँ लिखें।
विशिष्ट उपकरण इस कार्य को और अधिक सरल बनाते हैं। उनमें से, हम क्वेरी बिल्डर का उपयोग करने की सलाह देते हैं - एक विज़ुअल टूल जो विज़ुअल मोड में सबसे जटिल प्रश्नों को बहुत तेज़ी से बनाने की अनुमति देता है। यह टूल एक स्टैंड-अलोन समाधान के रूप में या SQL सर्वर के लिए बहु-फ़ीचर्ड dbForge स्टूडियो के एक भाग के रूप में उपलब्ध है।
हमें उम्मीद है कि इस लेख ने आपको इस विशिष्ट मुद्दे को स्पष्ट करने में मदद की है।