परिचय
SQL सर्वर 2005 में उनके परिचय के बाद से, विंडो काम करती है जैसे ROW_NUMBER और रैंक आम टी-एसक्यूएल समस्याओं की एक विस्तृत विविधता को हल करने में बेहद उपयोगी साबित हुए हैं। ऐसे समाधानों को सामान्य बनाने के प्रयास में, डेटाबेस डिज़ाइनर अक्सर कोड एनकैप्सुलेशन और पुन:उपयोग को बढ़ावा देने के लिए उन्हें विचारों में शामिल करना चाहते हैं। दुर्भाग्य से, SQL सर्वर क्वेरी ऑप्टिमाइज़र में एक सीमा का अर्थ अक्सर यह होता है कि विंडो फ़ंक्शन वाले दृश्य अपेक्षा के अनुरूप प्रदर्शन नहीं करते हैं। यह पोस्ट समस्या के उदाहरणात्मक उदाहरण के माध्यम से काम करता है, कारणों का विवरण देता है, और कई समाधान प्रदान करता है।
<छोटा> यह समस्या व्युत्पन्न तालिकाओं, सामान्य तालिका अभिव्यक्तियों और इन-लाइन कार्यों में भी हो सकती है, लेकिन मैं इसे अक्सर विचारों के साथ देखता हूं क्योंकि वे जानबूझकर अधिक सामान्य होने के लिए लिखे गए हैं।
विंडो फ़ंक्शन
विंडो फ़ंक्शन एक OVER() . की उपस्थिति से पहचाने जाते हैं खंड और तीन किस्मों में आते हैं:
- रैंकिंग विंडो फ़ंक्शंस
ROW_NUMBERरैंकDENSE_RANKNTILE
- विंडो के कार्यों को पूरा करें
मिनट,मैक्स,एवीजी,योगCOUNT,COUNT_BIGCHECKSUM_AGGएसटीडीईवी,एसटीडीईवीपी,वीएआर,वीएआरपी
- विश्लेषक विंडो फ़ंक्शन
LAG,लीडFIRST_VALUE,LAST_VALUEPERCENT_RANK,PERCENTILE_CONT,PERCENTILE_DISC,CUME_DIST
रैंकिंग और कुल विंडो फ़ंक्शन SQL Server 2005 में पेश किए गए थे, और SQL Server 2012 में काफी विस्तारित किए गए थे। विश्लेषणात्मक विंडो फ़ंक्शन SQL Server 2012 के लिए नए हैं।
ऊपर सूचीबद्ध सभी विंडो फ़ंक्शंस इस आलेख में विस्तृत ऑप्टिमाइज़र सीमा के लिए अतिसंवेदनशील हैं।
उदाहरण
एडवेंचरवर्क्स नमूना डेटाबेस का उपयोग करते हुए, हाथ में कार्य एक क्वेरी लिखना है जो सभी उत्पाद # 878 लेनदेन लौटाता है जो सबसे हाल की उपलब्ध तारीख पर हुआ था। टी-एसक्यूएल में इस आवश्यकता को व्यक्त करने के सभी प्रकार के तरीके हैं, लेकिन हम एक विंडोिंग फ़ंक्शन का उपयोग करने वाली क्वेरी लिखना चुनेंगे। पहला कदम उत्पाद #878 के लिए लेन-देन रिकॉर्ड ढूंढना है और उन्हें अवरोही तिथि क्रम में रैंक करना है:
चुनें th.TransactionID, th.ReferenceOrderID, th.TransactionDate, th.Quantity, rnk =RANK() OVER ( th.TransactionDate DESC द्वारा ऑर्डर) प्रोडक्शन से। ट्रांजेक्शन हिस्ट्री जहां वें स्थान पर है। प्रोडक्टआईडी =878 ऑर्डर बाय आरएनके;
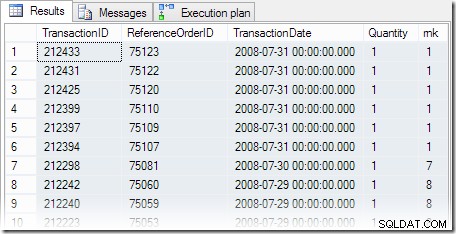

क्वेरी के परिणाम अपेक्षानुसार हैं, जिसमें छह लेन-देन सबसे हाल की तारीख पर उपलब्ध हैं। निष्पादन योजना में एक चेतावनी त्रिकोण होता है, जो हमें एक लापता सूचकांक के प्रति सचेत करता है:

हमेशा की तरह अनुपलब्ध अनुक्रमणिका सुझावों के लिए, हमें यह याद रखने की आवश्यकता है कि अनुशंसा क्वेरी के विश्लेषण का परिणाम नहीं है - यह एक संकेत के रूप में अधिक है कि हमें इस बारे में थोड़ा सोचने की आवश्यकता है कि यह क्वेरी उस डेटा तक कैसे पहुँचती है जिसकी उसे आवश्यकता है।
सुझाया गया सूचकांक निश्चित रूप से तालिका को पूरी तरह से स्कैन करने की तुलना में अधिक कुशल होगा, क्योंकि यह एक सूचकांक को उस विशेष उत्पाद की तलाश करने की अनुमति देगा जिसमें हम रुचि रखते हैं। सूचकांक में सभी आवश्यक कॉलम भी शामिल होंगे, लेकिन यह सॉर्ट से नहीं बचेंगे (द्वारा <द्वारा) कोड>लेनदेन दिनांक अवरोही)। इस क्वेरी के लिए आदर्श अनुक्रमणिका ProductID . पर खोज करने की अनुमति देगी , चयनित रिकॉर्ड को उल्टे TransactionDate . में लौटाएं आदेश दें, और अन्य लौटाए गए स्तंभों को कवर करें:
गैर-संकुलित अनुक्रमणिका बनाएं ixON Production.TransactionHistory (ProductID, TransactionDate DESC)INCLUDE (ReferenceOrderID, मात्रा);
उस सूचकांक के साथ, निष्पादन योजना बहुत अधिक कुशल है। क्लस्टर्ड इंडेक्स स्कैन को रेंज सीक से बदल दिया गया है, और एक स्पष्ट सॉर्ट अब आवश्यक नहीं है:

इस क्वेरी के लिए अंतिम चरण परिणामों को केवल उन पंक्तियों तक सीमित करना है जो # 1 रैंक करते हैं। हम सीधे WHERE . में फ़िल्टर नहीं कर सकते हमारी क्वेरी का खंड क्योंकि विंडो फ़ंक्शन केवल SELECT . में दिखाई दे सकते हैं और आर्डर बाय खंड।
हम व्युत्पन्न तालिका, सामान्य तालिका अभिव्यक्ति, फ़ंक्शन या दृश्य का उपयोग करके इस प्रतिबंध को हल कर सकते हैं। इस अवसर पर, हम एक सामान्य तालिका अभिव्यक्ति (उर्फ एक इन-लाइन दृश्य) का उपयोग करेंगे:
रैंक किए गए लेनदेन के साथ (वें। ट्रांज़ेक्शनआईडी, वें संदर्भ ऑर्डर आईडी, वें ट्रांज़ेक्शनडेट, वें मात्रा, आरएनके =रैंक() ओवर (वें। ट्रांज़ेक्शनडेट डीईएससी द्वारा ऑर्डर) प्रोडक्शन से। ट्रांज़ेक्शन हिस्ट्री जहां वें वें स्थान पर है। उत्पाद आईडी =878 ) TransactionID, ReferenceOrderID, TransactionDate, quantityFROM RankedTransactionWHERE rnk =1 चुनें;
निष्पादन योजना पहले की तरह ही है, केवल # 1 रैंक वाली पंक्तियों को वापस करने के लिए एक अतिरिक्त फ़िल्टर के साथ:

क्वेरी छह समान रैंक वाली पंक्तियाँ लौटाती है जिनकी हम अपेक्षा करते हैं:
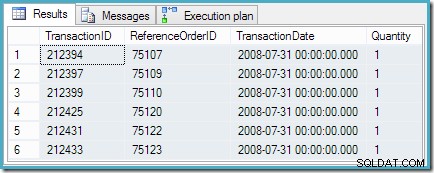
क्वेरी को सामान्य बनाना
यह पता चला है कि हमारी क्वेरी बहुत उपयोगी है, इसलिए इसे सामान्य बनाने और परिभाषा को एक दृश्य में संग्रहीत करने का निर्णय लिया जाता है। इसके लिए किसी भी उत्पाद के लिए काम करने के लिए, हमें दो काम करने होंगे:ProductID . लौटाएं दृश्य से, और उत्पाद द्वारा रैंकिंग फ़ंक्शन को विभाजित करें:
क्रिएट व्यू dbo.MostRecentTransactionsPerProductwith SCHEMABINDINGASSELECT sq1.ProductID, sq1.TransactionID, sq1.ReferenceOrderID, sq1.TransactionDate, sq1.QuantityFROM ( th.ProductID, th.TransactionID, th.ReferenceOrderID, वें चुनें। rnk =RANK() ओवर (वें.ProductID ORDER by th.TransactionDate DESC) प्रोडक्शन से। TransactionHistory AS th) AS sq1WHERE sq1.rnk =1;
दृश्य से सभी पंक्तियों का चयन करने से निम्नलिखित निष्पादन योजना और सही परिणाम प्राप्त होते हैं:

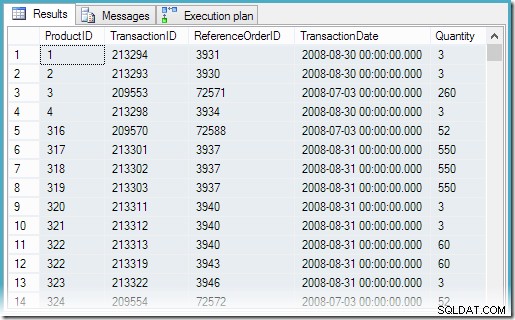
अब हम उत्पाद 878 के लिए सबसे हाल के लेन-देन को देखने पर एक बहुत ही सरल क्वेरी के साथ पा सकते हैं:
चुनें mrt.ProductID, mrt.TransactionID, mrt.ReferenceOrderID, mrt.TransactionDate, mrt.QuantityFROM dbo.MostRecentTransactionsPerProduct as mrt जहां mrt.ProductID =878;
हमारी अपेक्षा यह है कि इस नई क्वेरी के लिए निष्पादन योजना ठीक वैसी ही होगी जैसी हमने दृश्य बनाने से पहले की थी। क्वेरी ऑप्टिमाइज़र WHERE . में निर्दिष्ट फ़िल्टर को पुश करने में सक्षम होना चाहिए क्लॉज डाउन व्यू में, जिसके परिणामस्वरूप इंडेक्स की तलाश होती है।
हालाँकि, हमें इस बिंदु पर रुकने और थोड़ा सोचने की ज़रूरत है। क्वेरी ऑप्टिमाइज़र केवल निष्पादन योजनाओं का उत्पादन कर सकता है जो तार्किक क्वेरी विनिर्देश के समान परिणाम देने की गारंटी है - क्या हमारे WHERE को पुश करना सुरक्षित है दृश्य में खंड?<उत्तर हाँ है, जब तक हम जिस कॉलम को फ़िल्टर कर रहे हैं वह PARTITION BY में दिखाई देता है दृश्य में विंडो फ़ंक्शन का खंड। तर्क यह है कि विंडो फ़ंक्शन से पूर्ण समूहों (विभाजन) को समाप्त करने से क्वेरी द्वारा लौटाई गई पंक्तियों की रैंकिंग प्रभावित नहीं होगी। सवाल यह है कि क्या SQL सर्वर क्वेरी ऑप्टिमाइज़र यह जानता है? उत्तर इस बात पर निर्भर करता है कि हम SQL सर्वर का कौन सा संस्करण चला रहे हैं।
SQL सर्वर 2005 निष्पादन योजना

इस योजना में फ़िल्टर गुणों पर एक नज़र इसे दो विधेय लागू करते हुए दिखाती है:
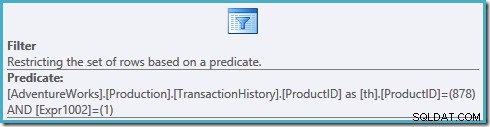
उत्पाद आईडी =878 विधेय को दृश्य में नीचे नहीं धकेला गया है, जिसके परिणामस्वरूप एक योजना है जो हमारी अनुक्रमणिका को स्कैन करती है, उत्पाद #878 के लिए फ़िल्टर करने से पहले तालिका में प्रत्येक पंक्ति की रैंकिंग करती है और पंक्तियों को # 1 स्थान दिया जाता है।
SQL सर्वर 2005 क्वेरी ऑप्टिमाइज़र कम क्वेरी स्कोप (दृश्य, सामान्य तालिका अभिव्यक्ति, इन-लाइन फ़ंक्शन या व्युत्पन्न तालिका) में विंडो फ़ंक्शन के पीछे उपयुक्त विधेय को धक्का नहीं दे सकता है। यह सीमा सभी SQL Server 2005 बिल्ड पर लागू होती है।
SQL Server 2008+ निष्पादन योजना
SQL Server 2008 या बाद के संस्करण पर समान क्वेरी के लिए यह निष्पादन योजना है:

उत्पाद आईडी प्रेडिकेट को रैंकिंग ऑपरेटरों से सफलतापूर्वक आगे बढ़ाया गया है, इंडेक्स स्कैन को कुशल इंडेक्स सीक के साथ बदल दिया गया है।
2008 के क्वेरी ऑप्टिमाइज़र में एक नया सरलीकरण नियम शामिल है SelOnSeqPrj (अनुक्रम प्रोजेक्ट पर चयन करें) जो सुरक्षित बाहरी-स्कोप को पिछले विंडो फ़ंक्शंस की भविष्यवाणी करने में सक्षम है। SQL Server 2008 या बाद में इस क्वेरी के लिए कम कुशल योजना तैयार करने के लिए, हमें इस क्वेरी ऑप्टिमाइज़र सुविधा को अस्थायी रूप से अक्षम करना होगा:
चुनें mrt.ProductID, mrt.TransactionID, mrt.ReferenceOrderID, mrt.TransactionDate, mrt.QuantityFROM dbo.MostRecentTransactionsPerProduct as mrt जहां mrt.ProductID =878OPTION (QUERYRULEOFF SelOnSeqPrj);

दुर्भाग्य से, SelOnSeqPrj सरलीकरण नियम केवल काम करता है जब विधेय स्थिरांक के साथ . तुलना करता है . उस कारण से, निम्न क्वेरी SQL Server 2008 और बाद में उप-इष्टतम योजना तैयार करती है:
घोषणा @ProductID INT =878; चुनें mrt.ProductID, mrt.TransactionID, mrt.ReferenceOrderID, mrt.TransactionDate, mrt.QuantityFROM dbo.MostRecentTransactionsPerProduct as mrt जहां mrt.ProductID =@ProductID;

समस्या तब भी हो सकती है जब विधेय स्थिर मान का उपयोग करता है। SQL सर्वर तुच्छ प्रश्नों को स्वतः-पैरामीटर करने का निर्णय ले सकता है (जिसके लिए एक स्पष्ट सर्वोत्तम योजना मौजूद है)। यदि ऑटो-पैरामीटरीकरण सफल होता है, तो अनुकूलक स्थिरांक के बजाय एक पैरामीटर देखता है, और SelOnSeqPrj नियम लागू नहीं है।
उन प्रश्नों के लिए जहां ऑटो-पैरामीटराइजेशन का प्रयास नहीं किया गया है (या जहां इसे असुरक्षित माना जाता है), अनुकूलन अभी भी विफल हो सकता है, यदि डेटाबेस विकल्प Forced PARAMETERIZATION के लिए है चालू है। हमारी परीक्षण क्वेरी (स्थिर मान 878 के साथ) ऑटो-पैरामीटराइज़ेशन के लिए सुरक्षित नहीं है, लेकिन जबरन पैरामीटराइज़ेशन सेटिंग इसे ओवरराइड कर देती है, जिसके परिणामस्वरूप अक्षम योजना होती है:
ALTER DATABASE AdventureWorksSET PARAMETERIZATION FORSED;GOSELECT mrt.ProductID, mrt.TransactionID, mrt.ReferenceOrderID, mrt.TransactionDate, mrt.QuantityFROM dbo.MostRecentTransactionsPerProduct as mrt जहां mrt.ProductID =8prePARASERPALTER>
SQL सर्वर 2008+ समाधान
ऑप्टिमाइज़र को क्वेरी के लिए एक स्थिर मान 'देखने' की अनुमति देने के लिए जो एक स्थानीय चर या पैरामीटर का संदर्भ देता है, हम एक
विकल्प (RECOMPILE)जोड़ सकते हैं। क्वेरी संकेत:घोषणा @ProductID INT =878; चुनें mrt.ProductID, mrt.TransactionID, mrt.ReferenceOrderID, mrt.TransactionDate, mrt.QuantityFROM dbo.MostRecentTransactionsPerProduct as mrt जहां mrt.ProductID =@ProductIDOPTION (RECOMPILE);नोट: पूर्व-निष्पादन ('अनुमानित') निष्पादन योजना अभी भी एक सूचकांक स्कैन दिखाती है क्योंकि चर का मूल्य वास्तव में अभी तक निर्धारित नहीं है। जब क्वेरी निष्पादित की जाती है , हालांकि, निष्पादन योजना वांछित अनुक्रमणिका तलाश योजना दिखाती है:
SelOnSeqPrjSQL सर्वर 2005 में नियम मौजूद नहीं है, इसलिएOPTION (RECOMPILE)वहां मदद नहीं कर सकता। यदि आप सोच रहे हैं, तोविकल्प (RECOMPILE)वर्कअराउंड का परिणाम खोज में होता है, भले ही जबरन पैरामीटरकरण के लिए डेटाबेस विकल्प चालू हो।सभी संस्करण वैकल्पिक हल #1
कुछ मामलों में, समस्याग्रस्त दृश्य, सामान्य तालिका अभिव्यक्ति, या व्युत्पन्न तालिका को पैरामीटरयुक्त इन-लाइन तालिका-मूल्यवान फ़ंक्शन के साथ बदलना संभव है:
CREATE FUNCTION dbo.MostRecentTransactionsForProduct( @ProductID पूर्णांक) SCHEMABINDING ASRETURN SELECT sq1.ProductID, sq1.TransactionID, sq1.ReferenceOrderID, sq1.TransactionID, sq1. मात्रा से तालिका के साथ रिटर्न तालिका (चुनें वें। ReferenceOrderID, th.TransactionDate, th.Quantity, rnk =RANK() OVER (वें.ProductID ORDER by th.TransactionDate DESC) प्रोडक्शन से। ट्रांजेक्शन हिस्ट्री जहां वें वें। 1;यह फ़ंक्शन स्पष्ट रूप से
ProductIDरखता है ऑप्टिमाइज़र सीमा से परहेज करते हुए, विंडो फ़ंक्शन के समान दायरे में भविष्यवाणी करें। इन-लाइन फ़ंक्शन का उपयोग करने के लिए लिखा गया, हमारी उदाहरण क्वेरी बन जाती है:चुनें mrt.ProductID, mrt.TransactionID, mrt.ReferenceOrderID, mrt.TransactionDate, mrt.QuantityFROM dbo.MostRecentTransactionsForProduct(878) AS mrt;यह SQL सर्वर के सभी संस्करणों पर वांछित अनुक्रमणिका तलाश योजना तैयार करता है जो विंडो फ़ंक्शंस का समर्थन करता है। यह वर्कअराउंड एक खोज उत्पन्न करता है, यहां तक कि जहां विधेय एक पैरामीटर या स्थानीय चर का संदर्भ देता है -
OPTION (RECOMPILE)आवश्यक नहीं है। खंड, और अबProductID. वापस नहीं लौटाने के लिए कॉलम। मैंने परिभाषा को वैसे ही छोड़ दिया, जैसा कि इसे बदलने के लिए और अधिक स्पष्ट रूप से निष्पादन योजना के अंतर के कारण को स्पष्ट करता है।सभी वर्शन वर्कअराउंड #2
दूसरा समाधान केवल रैंकिंग विंडो फ़ंक्शंस पर लागू होता है, जिन्हें नंबर 1 या रैंक वाली पंक्तियों को वापस करने के लिए फ़िल्टर किया जाता है (
ROW_NUMBERका उपयोग करके) ,रैंक, याDENSE_RANK) हालांकि यह एक बहुत ही सामान्य उपयोग है, इसलिए यह ध्यान देने योग्य है।एक अतिरिक्त लाभ यह है कि यह समाधान ऐसी योजनाएं तैयार कर सकता है जो अधिक कुशल . हैं सूचकांक की तुलना में पहले देखी गई योजनाओं की तलाश है। एक अनुस्मारक के रूप में, पिछली सबसे अच्छी योजना इस तरह दिखती थी:
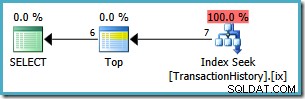
उस निष्पादन योजना का रैंक 1,918 . है पंक्तियाँ, भले ही यह अंततः केवल 6 . ही लौटाती हैं . हम
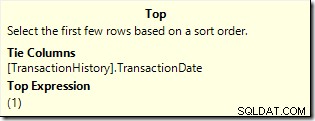
ORDER BY. में विंडो फ़ंक्शन का उपयोग करके इस निष्पादन योजना को बेहतर बना सकते हैं पंक्तियों को रैंक करने और फिर रैंक #1 के लिए फ़िल्टर करने के बजाय क्लॉज़:शीर्ष चुनें (1) टाई के साथ th.TransactionID, th.ReferenceOrderID, th.TransactionDate, th.QuantityFROM Production.TransactionHistory जहाँ th.ProductID =878ORDER by RANK() OVER (th.TransactionDate DESC द्वारा ऑर्डर);
यह क्वेरी
ORDER BY. में विंडो फ़ंक्शन के उपयोग को अच्छी तरह से दर्शाती है खंड, लेकिन हम और भी बेहतर कर सकते हैं, विंडो फ़ंक्शन को पूरी तरह से समाप्त कर सकते हैं:शीर्ष चुनें (1) टाई के साथ th.TransactionID, th.ReferenceOrderID, th.TransactionDate, th.QuantityFROM Production.TransactionHistory जहाँ th.ProductID =878ORDER by th.TransactionDate DESC;
यह योजना समान 6-पंक्ति परिणाम सेट को वापस करने के लिए तालिका से केवल 7 पंक्तियों को पढ़ती है। 7 पंक्तियाँ क्यों? शीर्ष ऑपरेटर
WITHमें चल रहा है मोड:
जब तक TransactionDate में परिवर्तन नहीं हो जाता, तब तक यह अपने सबट्री से एक समय में एक पंक्ति का अनुरोध करना जारी रखता है। सातवीं पंक्ति शीर्ष के लिए यह सुनिश्चित करने के लिए आवश्यक है कि कोई और बंधी-मूल्य वाली पंक्तियाँ योग्य नहीं होंगी।
हम समस्याग्रस्त दृश्य परिभाषा को बदलने के लिए उपरोक्त क्वेरी के तर्क को बढ़ा सकते हैं:
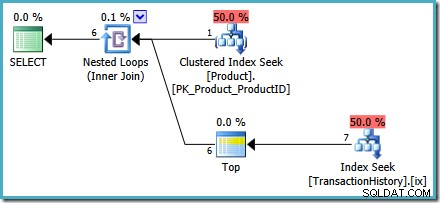
एल्टर व्यू dbo.MostRecentTransactionsPerProductwith SCHEMABINDINGASSELECT p.ProductID, Ranked1.TransactionID, Ranked1.ReferenceOrderID, Ranked1.TransactionDate, Ranked1.QuantityFROM - उत्पाद आईडी की सूची (उत्पादन से उत्पाद आईडी चुनें। प्रत्येक उत्पाद आईडी के लिए # 1 परिणाम शीर्ष (1) TIES th.TransactionID, th.ReferenceOrderID, th.TransactionDate, th.Quantity From Production.TransactionHistory के रूप में वें जहां वें।ProductID =p.ProductID ORDER TH.TransactionDate DESC के साथ) एएस रैंक1;दृश्य अब
क्रॉस लागूका उपयोग करता है हमारे अनुकूलितORDER BY. के परिणामों को संयोजित करने के लिए प्रत्येक उत्पाद के लिए क्वेरी। हमारी परीक्षण क्वेरी अपरिवर्तित है:DECLARE @ProductID पूर्णांक;सेट @ProductID =878; चुनें mrt.ProductID, mrt.TransactionID, mrt.ReferenceOrderID, mrt.TransactionDate, mrt.QuantityFROM dbo.MostRecentTransactionsPerProduct as mrt जहां mrt.ProductID =@ProductID;निष्पादन से पहले और बाद की दोनों योजनाएं
OPTION (RECOMPILE)की आवश्यकता के बिना एक अनुक्रमणिका खोज दिखाती हैं प्रश्न संकेत। निम्नलिखित निष्पादन के बाद ('वास्तविक') योजना है:
यदि दृश्य में
ROW_NUMBERका उपयोग किया गया होतारैंक. के बजाय , प्रतिस्थापन दृश्य बसwith TIES. को छोड़ देताTOP(1). पर क्लॉज . नए दृश्य को निश्चित रूप से एक पैरामीटरयुक्त इन-लाइन तालिका-मूल्यवान फ़ंक्शन के रूप में भी लिखा जा सकता है।कोई यह तर्क दे सकता है कि मूल सूचकांक
rnk =1. के साथ योजना चाहता है विधेय को केवल 7 पंक्तियों का परीक्षण करने के लिए अनुकूलित किया जा सकता है। आखिरकार, ऑप्टिमाइज़र को पता होना चाहिए कि सीक्वेंस प्रोजेक्ट ऑपरेटर द्वारा सख्त आरोही क्रम में रैंकिंग तैयार की जाती है, इसलिए जैसे ही एक से अधिक रैंक वाली पंक्ति दिखाई देती है, निष्पादन समाप्त हो सकता है। हालांकि, आज अनुकूलक में यह तर्क नहीं है।अंतिम विचार
विंडो फ़ंक्शंस को शामिल करने वाले विचारों के प्रदर्शन से लोग अक्सर निराश होते हैं। इस पोस्ट में वर्णित ऑप्टिमाइज़र सीमा के कारण अक्सर पता लगाया जा सकता है (या शायद इसलिए कि दृश्य डिज़ाइनर ने इस बात की सराहना नहीं की कि दृश्य पर लागू विधेय
PARTITION BYमें प्रकट होना चाहिए। क्लॉज को सुरक्षित रूप से नीचे धकेल दिया जाए)।मैं इस बात पर जोर देना चाहता हूं कि यह सीमा केवल विचारों पर लागू नहीं होती है, और न ही यह
ROW_NUMBERतक सीमित है ,रैंक, औरDENSE_RANK.OVER. के साथ किसी फ़ंक्शन का उपयोग करते समय आपको इस सीमा के बारे में पता होना चाहिए एक दृश्य में खंड, सामान्य तालिका अभिव्यक्ति, व्युत्पन्न तालिका, या इन-लाइन तालिका-मूल्यवान फ़ंक्शन।SQL सर्वर 2005 उपयोगकर्ता जो इस समस्या का सामना करते हैं, उन्हें एक पैरामीटरयुक्त इन-लाइन तालिका-मूल्यवान फ़ंक्शन के रूप में दृश्य को फिर से लिखने या
लागू करेंका उपयोग करने के विकल्प का सामना करना पड़ता है। तकनीक (जहां लागू हो)।SQL Server 2008 उपयोगकर्ताओं के पास
OPTION (RECOMPILE). का उपयोग करने का अतिरिक्त विकल्प है क्वेरी संकेत यदि ऑप्टिमाइज़र को चर या पैरामीटर संदर्भ के बजाय स्थिरांक देखने की अनुमति देकर समस्या को हल किया जा सकता है। हालांकि इस संकेत का उपयोग करते समय निष्पादन के बाद की योजनाओं की जांच करना याद रखें:पूर्व-निष्पादन योजना आम तौर पर इष्टतम योजना नहीं दिखा सकती है।