अप्रैल में वापस मैंने SQL सर्वर के भीतर कुछ मूल विधियों के बारे में लिखा था जिनका उपयोग आंकड़ों के स्वचालित अपडेट को ट्रैक करने के लिए किया जा सकता है। मेरे द्वारा प्रदान किए गए तीन विकल्प SQL ट्रेस, विस्तारित ईवेंट और sys.dm_db_stats_properties के स्नैपशॉट थे। हालांकि ये तीन विकल्प व्यवहार्य रहते हैं (यहां तक कि SQL सर्वर 2014 में, हालांकि मेरी शीर्ष सिफारिश अभी भी XE है), एक अतिरिक्त विकल्प जो मैंने हाल ही में कुछ परीक्षण चलाते समय देखा, वह है SQL संतरी योजना एक्सप्लोरर।
आप में से कई लोग प्लान एक्सप्लोरर का उपयोग केवल निष्पादन योजनाओं को पढ़ने के लिए करते हैं, जो कि बहुत अच्छा है। जब योजनाओं की समीक्षा करने की बात आती है तो प्रबंधन स्टूडियो पर इसके कई लाभ होते हैं - छोटी चीजों से, जैसे कि शीर्ष ऑपरेटरों को छाँटने में सक्षम होना और कार्डिनैलिटी अनुमान के मुद्दों को आसानी से देखना, बड़े लाभों के लिए, जैसे जटिल और बड़ी योजनाओं को संभालना और एक का चयन करने में सक्षम होना आसान योजना समीक्षा के लिए एक बैच के भीतर बयान। लेकिन उन दृश्यों के पीछे जो योजनाओं को काटना आसान बनाते हैं, प्लान एक्सप्लोरर एक क्वेरी को निष्पादित करने और वास्तविक योजना को देखने की क्षमता भी प्रदान करता है (बजाय इसे प्रबंधन स्टूडियो में चलाने और इसे सहेजने के)। और उसके ऊपर, जब आप पीई से योजना चलाते हैं, तो अतिरिक्त जानकारी ली जाती है जो उपयोगी हो सकती है।
आइए अपने हालिया पोस्ट में उपयोग किए गए डेमो से शुरू करें, सांख्यिकी के स्वचालित अपडेट क्वेरी प्रदर्शन को कैसे प्रभावित कर सकते हैं। मैंने एडवेंचरवर्क्स2012 डेटाबेस के साथ शुरुआत की, और मैंने 200 मिलियन से अधिक पंक्तियों के साथ SalesOrderHeader तालिका की एक प्रति बनाई। तालिका में SalesOrderID पर एक संकुल अनुक्रमणिका है, और CustomerID, OrderDate, SubTotal पर एक गैर-संकुल अनुक्रमणिका है। [फिर से:यदि आप बार-बार परीक्षण करने जा रहे हैं, तो अपने आप को कुछ समय बचाने के लिए इस डेटाबेस का बैकअप लें।] मैंने पहले तालिका में पंक्तियों की वर्तमान संख्या और पंक्तियों की संख्या को सत्यापित किया है जिन्हें बदलने की आवश्यकता होगी। एक स्वचालित अपडेट का आह्वान करने के लिए:
SELECT OBJECT_NAME([p].[object_id]) [TableName], [si].[name] [IndexName], [au].[type_desc] [Type], [p].[rows] [RowCount], ([p].[rows]*.20) + 500 [UpdateThreshold], [au].total_pages [PageCount], (([au].[total_pages]*8)/1024)/1024 [TotalGB] FROM [sys].[partitions] [p] JOIN [sys].[allocation_units] [au] ON [p].[partition_id] = [au].[container_id] JOIN [sys].[indexes] [si] on [p].[object_id] = [si].object_id and [p].[index_id] = [si].[index_id] WHERE [p].[object_id] = OBJECT_ID(N'Sales.Big_SalesOrderHeader');

Big_SalesOrderHeader CIX और NCI जानकारी
मैंने अनुक्रमणिका के लिए वर्तमान सांख्यिकी शीर्षलेख को भी सत्यापित किया है:
DBCC SHOW_STATISTICS ('Sales.Big_SalesOrderHeader',[IX_Big_SalesOrderHeader_CustomerID_OrderDate_SubTotal]);

NCI सांख्यिकी:प्रारंभ में
परीक्षण के लिए मेरे द्वारा उपयोग की जाने वाली संग्रहीत कार्यविधि पहले से ही बनाई गई थी, लेकिन पूर्णता के लिए कोड नीचे सूचीबद्ध है:
CREATE PROCEDURE Sales.usp_GetCustomerStats
@CustomerID INT,
@StartDate DATETIME,
@EndDate DATETIME
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerID, DATEPART(YEAR, OrderDate), DATEPART(MONTH, OrderDate), COUNT([SalesOrderID]) as Computed
FROM [Sales].[Big_SalesOrderHeader]
WHERE CustomerID = @CustomerID
AND OrderDate BETWEEN @StartDate and @EndDate
GROUP BY CustomerID, DATEPART(YEAR, OrderDate), DATEPART(MONTH, OrderDate)
ORDER BY DATEPART(YEAR, OrderDate), DATEPART(MONTH, OrderDate);
END पहले, मैंने या तो एक ट्रेस या विस्तारित ईवेंट सत्र शुरू किया था, या किसी तालिका में sys.dm_db_stats_properties को स्नैपशॉट करने के लिए अपनी विधि सेट की थी। इस उदाहरण के लिए, मैंने उपरोक्त संग्रहीत कार्यविधि को कुछ ही बार चलाया:
EXEC Sales.usp_GetCustomerStats 11331, '2012-08-01 00:00:00.000', '2012-08-31 23:59:59.997' GO EXEC Sales.usp_GetCustomerStats 11330, '2013-01-01 00:00:00.000', '2013-01-31 23:59:59.997' GO EXEC Sales.usp_GetCustomerStats 11506, '2012-11-01 00:00:00.000', '2012-11-30 23:59:59.997' GO EXEC Sales.usp_GetCustomerStats 17061, '2013-01-01 00:00:00.000', '2013-01-31 23:59:59.997' GO EXEC Sales.usp_GetCustomerStats 11711, '2013-03-01 00:00:00.000', '2013-03-31 23:59:59.997' GO EXEC Sales.usp_GetCustomerStats 15131, '2013-02-01 00:00:00.000', '2013-02-28 23:59:59.997' GO EXEC Sales.usp_GetCustomerStats 29837, '2012-10-01 00:00:00.000', '2012-10-31 23:59:59.997' GO EXEC Sales.usp_GetCustomerStats 15750, '2013-03-01 00:00:00.000', '2013-03-31 23:59:59.997' GO
फिर मैंने निष्पादन संख्या को सत्यापित करने के लिए प्रक्रिया कैश की जाँच की, और कैश की गई योजना को भी सत्यापित किया:
SELECT OBJECT_NAME([st].[objectid]), [st].[text], [qs].[execution_count], [qs].[creation_time], [qs].[last_execution_time], [qs].[min_worker_time], [qs].[max_worker_time], [qs].[min_logical_reads], [qs].[max_logical_reads], [qs].[min_elapsed_time], [qs].[max_elapsed_time], [qp].[query_plan] FROM [sys].[dm_exec_query_stats] [qs] CROSS APPLY [sys].[dm_exec_sql_text]([qs].plan_handle) [st] CROSS APPLY [sys].[dm_exec_query_plan]([qs].plan_handle) [qp] WHERE [st].[text] LIKE '%usp_GetCustomerStats%' AND OBJECT_NAME([st].[objectid]) IS NOT NULL;

SP के लिए योजना कैश जानकारी:प्रारंभ में
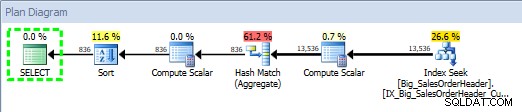
एसक्यूएल सेंट्री प्लान एक्सप्लोरर का उपयोग करते हुए संग्रहित प्रक्रिया के लिए क्वेरी प्लान
योजना 2014-09-29 23:23.01 पर बनाई गई थी।
इसके बाद मैंने वर्तमान आंकड़ों को अमान्य करने के लिए तालिका में 61 मिलियन पंक्तियाँ जोड़ीं, और एक बार सम्मिलित करने के बाद, मैंने पंक्तियों की संख्या की जाँच की:

Big_SalesOrderHeader CIX और NCI जानकारी:61 मिलियन डालने के बाद पंक्तियाँ
संग्रहीत कार्यविधि को फिर से चलाने से पहले, मैंने सत्यापित किया कि निष्पादन संख्या नहीं बदली थी, कि निर्माण_समय अभी भी योजना के लिए 2014-09-29 23:23.01 था, और आंकड़े अपडेट नहीं हुए थे:
SP के लिए योजना कैश जानकारी:डालने के तुरंत बाद

NCI सांख्यिकी:डालने के बाद
अब, पिछले ब्लॉग पोस्ट में, मैंने प्रबंधन स्टूडियो में स्टेटमेंट चलाया था, लेकिन इस बार, मैंने सीधे प्लान एक्सप्लोरर से क्वेरी चलाई, और पीई के माध्यम से वास्तविक योजना पर कब्जा कर लिया (विकल्प नीचे की छवि में लाल रंग में परिक्रमा करता है)।
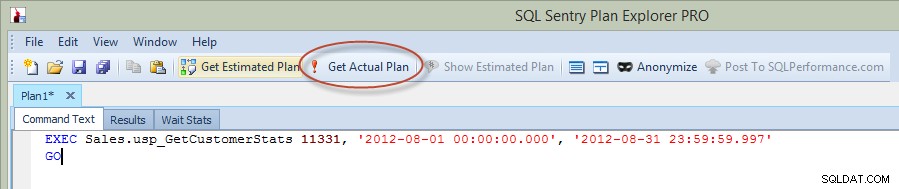
प्लान एक्सप्लोरर से संग्रहित प्रक्रिया निष्पादित करें
जब आप पीई से एक स्टेटमेंट निष्पादित करते हैं, तो आपको उस इंस्टेंस और डेटाबेस को दर्ज करना होगा जिससे आप कनेक्ट करना चाहते हैं, और फिर आपको सूचित किया जाता है कि क्वेरी चलेगी और वास्तविक योजना वापस कर दी जाएगी, लेकिन परिणाम वापस नहीं किए जाएंगे। ध्यान दें कि यह प्रबंधन स्टूडियो से अलग है, जहां आप परिणाम देखते हैं।
संग्रहित प्रक्रिया को चलाने के बाद, आउटपुट में मुझे न केवल योजना मिलती है, बल्कि मैं देखता हूं कि कौन से कथन निष्पादित किए गए थे:
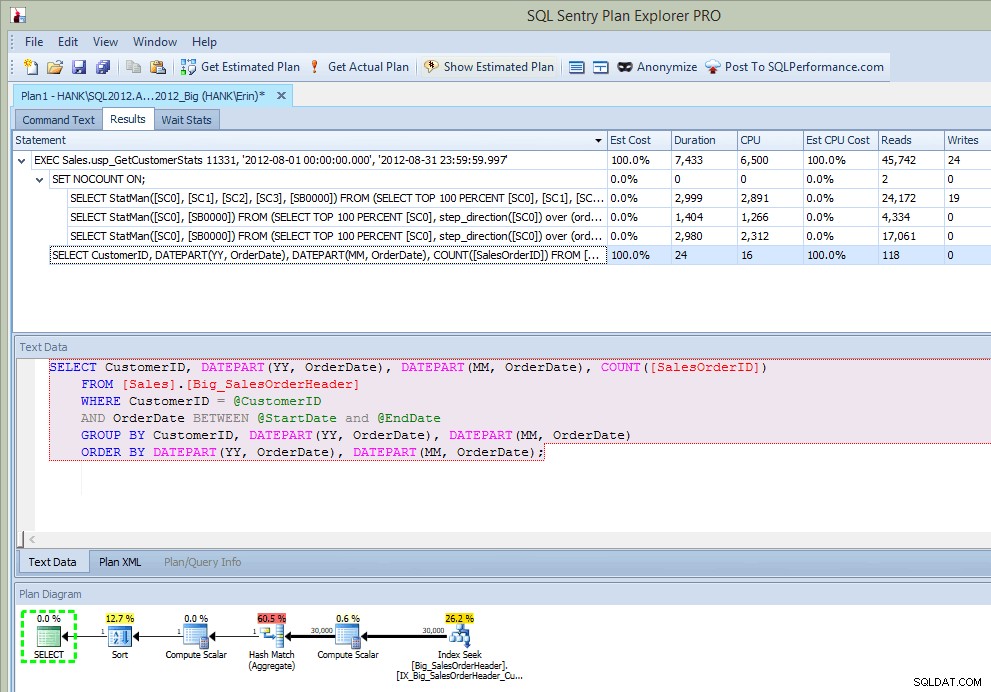
एसपी निष्पादन के बाद एक्सप्लोरर आउटपुट की योजना बनाएं (सम्मिलित करने के बाद)
यह बहुत अच्छा है ... संग्रहीत प्रक्रिया में निष्पादित कथन को देखने के अलावा, मैं आंकड़ों के अपडेट भी देखता हूं, जैसे मैंने विस्तारित ईवेंट या SQL ट्रेस का उपयोग करके अपडेट कैप्चर करते समय किया था। कथन निष्पादन के साथ, हम CPU, अवधि और IO जानकारी भी देख सकते हैं। अब - यहाँ चेतावनी यह है कि मैं यह जानकारी देख सकता हूँ अगर मैं स्टेटमेंट चलाता हूं जो प्लान एक्सप्लोरर से आंकड़े अपडेट को आमंत्रित करता है। यह शायद आपके उत्पादन वातावरण में अक्सर नहीं होगा, लेकिन आप इसे तब देख सकते हैं जब आप परीक्षण कर रहे हों (क्योंकि उम्मीद है कि आपके परीक्षण में केवल SELECT क्वेरी चलाना शामिल नहीं है, बल्कि इसमें INSERT/UPDATE/DELETE प्रश्न भी शामिल हैं जैसे आप करेंगे एक सामान्य कार्यभार में देखें)। हालांकि, यदि आप SQL संतरी जैसे उपकरण के साथ अपने परिवेश की निगरानी कर रहे हैं, तो आपको शीर्ष SQL में ये अपडेट दिखाई दे सकते हैं जब तक वे शीर्ष SQL संग्रह सीमा से अधिक हो जाते हैं। SQL संतरी में डिफ़ॉल्ट थ्रेशोल्ड होते हैं जो शीर्ष SQL के रूप में कैप्चर किए जाने से पहले प्रश्नों से अधिक होने चाहिए (जैसे अवधि पांच (5) सेकंड से अधिक होनी चाहिए), लेकिन आप उन्हें बदल सकते हैं और अन्य थ्रेसहोल्ड जैसे रीड्स जोड़ सकते हैं। इस उदाहरण में, केवल परीक्षण उद्देश्यों के लिए , मैंने अपनी शीर्ष SQL न्यूनतम अवधि सीमा को 10 मिलीसेकंड में और मेरी पढ़ने की सीमा को 500 में बदल दिया, और SQL संतरी कुछ आँकड़े अपडेट को कैप्चर करने में सक्षम था:
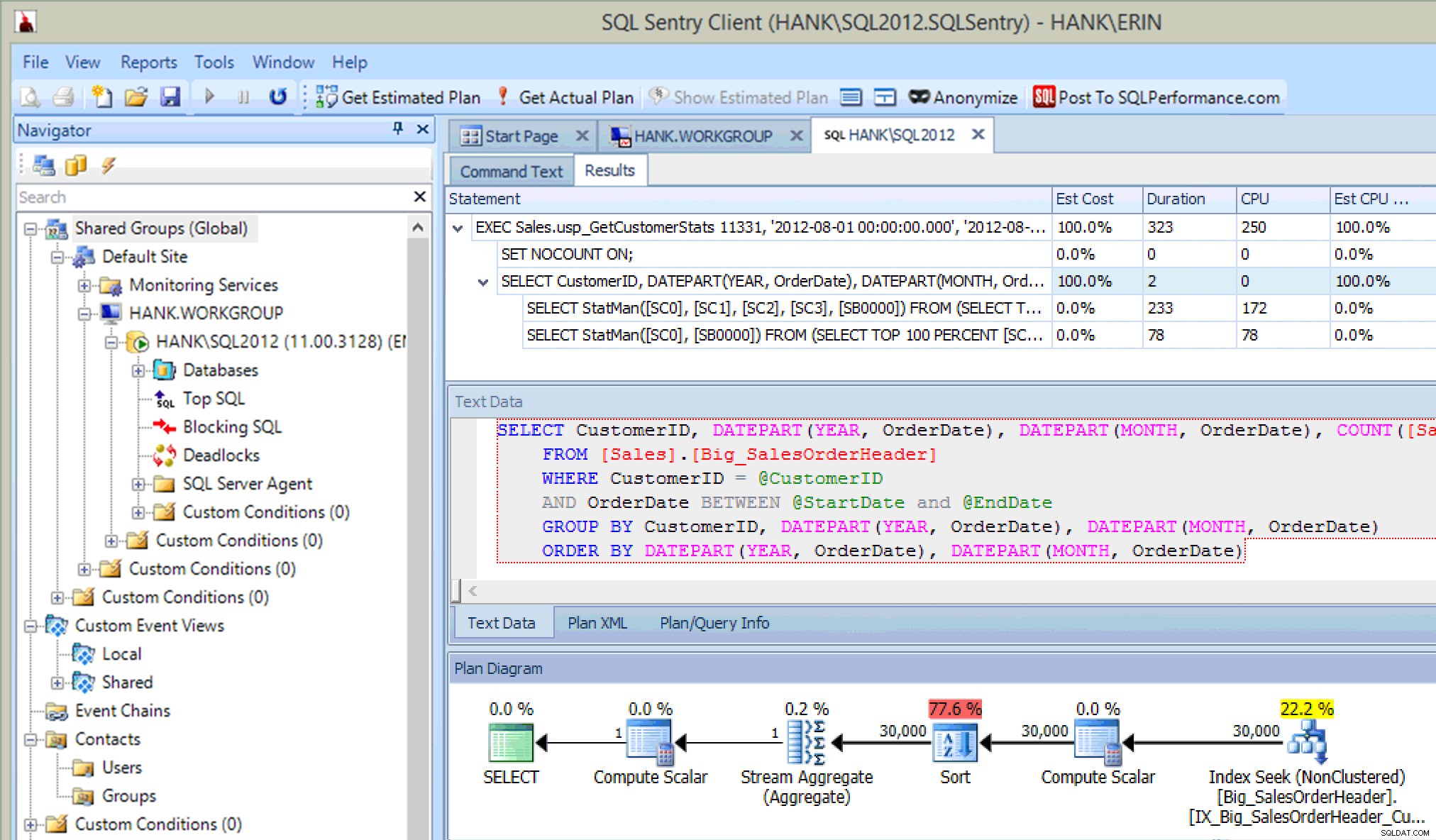
एसक्यूएल संतरी द्वारा कैप्चर किए गए आंकड़े अपडेट
उस ने कहा, क्या निगरानी इन घटनाओं को पकड़ सकती है, यह अंततः सिस्टम संसाधनों और डेटा की मात्रा पर निर्भर करेगा जिसे आंकड़ों को अपडेट करने के लिए पढ़ा जाना है। आपके आंकड़े अपडेट इन सीमाओं से अधिक नहीं हो सकते हैं, इसलिए आपको उन्हें खोजने के लिए और अधिक सक्रिय खुदाई करनी पड़ सकती है।
सारांश
मैं हमेशा डीबीए को आँकड़ों को सक्रिय रूप से प्रबंधित करने के लिए प्रोत्साहित करता हूँ - जिसका अर्थ है कि नियमित आधार पर आँकड़ों को अद्यतन करने के लिए एक नौकरी है। हालांकि, भले ही वह नौकरी हर रात चलती है (जिसकी मैं जरूरी अनुशंसा नहीं कर रहा हूं), यह अभी भी काफी संभव है कि आंकड़ों के अपडेट पूरे दिन स्वचालित रूप से होते हैं, क्योंकि कुछ टेबल दूसरों की तुलना में अधिक अस्थिर होते हैं और उनमें बड़ी संख्या में संशोधन होते हैं। यह असामान्य नहीं है, और तालिका के आकार और संशोधनों की मात्रा के आधार पर, स्वचालित अपडेट उपयोगकर्ता प्रश्नों के साथ महत्वपूर्ण रूप से हस्तक्षेप नहीं कर सकते हैं। लेकिन जानने का एकमात्र तरीका उन अपडेट की निगरानी करना है - चाहे आप स्थानीय टूल का उपयोग कर रहे हों या तृतीय-पक्ष टूल का - ताकि आप संभावित समस्याओं से आगे रह सकें और उनके बढ़ने से पहले उनका समाधान कर सकें।