जब आप अपना डेटाबेस डिज़ाइन करियर शुरू कर रहे थे तो आपने शायद इनमें से कुछ गलतियाँ की होंगी। हो सकता है कि आप अभी भी उन्हें बना रहे हों, या आप भविष्य में कुछ बना लेंगे। हम समय पर वापस नहीं जा सकते हैं और आपकी त्रुटियों को पूर्ववत करने में आपकी सहायता नहीं कर सकते हैं, लेकिन हम आपको कुछ भविष्य (या वर्तमान) सिरदर्द से बचा सकते हैं।
इस लेख को पढ़ने से आपको डिज़ाइन और कोड की समस्याओं को ठीक करने में लगने वाले घंटों की बचत हो सकती है, तो आइए इसमें गोता लगाते हैं। मैंने त्रुटियों की सूची को दो मुख्य समूहों में विभाजित किया है:वे जो गैर-तकनीकी हैं प्रकृति में और वे जो कड़ाई से तकनीकी . हैं . ये दोनों समूह डेटाबेस डिजाइन का एक महत्वपूर्ण हिस्सा हैं।
जाहिर है, अगर आपके पास तकनीकी कौशल नहीं है, तो आप नहीं जानते कि कुछ कैसे करना है। सूची में इन त्रुटियों को देखना आश्चर्यजनक नहीं है। लेकिन गैर-तकनीकी कौशल? लोग उनके बारे में भूल सकते हैं, लेकिन ये कौशल भी डिजाइन प्रक्रिया का एक बहुत ही महत्वपूर्ण हिस्सा हैं। वे आपके कोड में मूल्य जोड़ते हैं और वे तकनीक को वास्तविक दुनिया की समस्या से जोड़ते हैं जिसे आपको हल करने की आवश्यकता होती है।
तो, पहले गैर-तकनीकी मुद्दों से शुरू करते हैं, फिर तकनीकी मुद्दों पर चलते हैं।
गैर-तकनीकी डेटाबेस डिज़ाइन त्रुटियाँ
#1 खराब योजना
यह निश्चित रूप से एक गैर-तकनीकी समस्या है, लेकिन यह एक बड़ी और सामान्य समस्या है। जब कोई नया प्रोजेक्ट शुरू होता है तो हम सभी उत्साहित हो जाते हैं और उसमें जाने पर सब कुछ बहुत अच्छा लगता है। शुरुआत में, परियोजना अभी भी एक खाली पृष्ठ है और आप और आपके ग्राहक किसी ऐसी चीज पर काम करना शुरू करने में प्रसन्न हैं जो आप दोनों के लिए बेहतर भविष्य बनाएगी। यह सब बहुत अच्छा है, और एक महान भविष्य शायद अंतिम परिणाम होगा। लेकिन फिर भी हमें एकाग्र रहने की जरूरत है। यह उस परियोजना का हिस्सा है जहाँ हम महत्वपूर्ण गलतियाँ कर सकते हैं।
डेटा मॉडल बनाने के लिए बैठने से पहले, आपको यह सुनिश्चित करना होगा कि:
- आप पूरी तरह से जानते हैं कि आपका ग्राहक क्या करता है (यानी इस परियोजना से संबंधित उनकी व्यावसायिक योजनाएं और उनकी समग्र तस्वीर भी) और वे इस परियोजना को अभी और भविष्य में क्या हासिल करना चाहते हैं।
- आप व्यवसाय प्रक्रिया को समझते हैं और, यदि या जब आवश्यक हो, तो आप इसे सरल और बेहतर बनाने के लिए सुझाव देने के लिए तैयार हैं (उदाहरण के लिए दक्षता और आय बढ़ाने के लिए, लागत और काम के घंटे कम करने आदि)।
- आप क्लाइंट की कंपनी में डेटा प्रवाह को समझते हैं। आदर्श रूप से, आपको हर विवरण पता होगा:डेटा के साथ कौन काम करता है, कौन परिवर्तन करता है, कौन सी रिपोर्ट की आवश्यकता है, यह सब कब और क्यों होता है।
- आप अपने क्लाइंट द्वारा उपयोग की जाने वाली भाषा/शब्दावली का उपयोग कर सकते हैं। जबकि आप उनके क्षेत्र के विशेषज्ञ हो सकते हैं या नहीं भी हो सकते हैं, आपका ग्राहक निश्चित रूप से है। उन्हें समझाने के लिए कहें कि आप क्या नहीं समझते हैं। और जब आप क्लाइंट को तकनीकी विवरण समझा रहे हों, तो उनके द्वारा समझी जाने वाली भाषा और शब्दावली का उपयोग करें।
- आप जानते हैं कि आप डेटाबेस इंजन और प्रोग्रामिंग भाषाओं से लेकर अन्य टूल तक किन तकनीकों का उपयोग करेंगे। आप जो उपयोग करने का निर्णय लेते हैं, वह आपके द्वारा हल की जाने वाली समस्या से निकटता से संबंधित है, लेकिन क्लाइंट की प्राथमिकताओं और उनके वर्तमान आईटी इन्फ्रास्ट्रक्चर को शामिल करना महत्वपूर्ण है।
नियोजन चरण के दौरान, आपको इन सवालों के जवाब मिलने चाहिए:
- आपके मॉडल में कौन सी टेबल केंद्रीय टेबल होंगी? आपके पास शायद उनमें से कुछ होंगे, जबकि अन्य टेबल कुछ सामान्य होंगे (जैसे user_account, role)। शब्दकोशों और तालिकाओं के बीच संबंधों के बारे में मत भूलना।
- मॉडल में तालिकाओं के लिए किन नामों का उपयोग किया जाएगा? याद रखें कि क्लाइंट जो कुछ भी वर्तमान में उपयोग करता है, उसके समान शब्दावली रखें।
- तालिकाओं और अन्य वस्तुओं का नामकरण करते समय कौन से नियम लागू होंगे? (नामकरण परंपराओं के बारे में बिंदु 4 देखें।)
- पूरे प्रोजेक्ट में कितना समय लगेगा? यह आपके शेड्यूल और क्लाइंट की टाइमलाइन दोनों के लिए महत्वपूर्ण है।
जब आपके पास ये सभी उत्तर होंगे तभी आप समस्या का प्रारंभिक समाधान साझा करने के लिए तैयार होंगे। यह समाधान एक पूर्ण अनुप्रयोग होने की आवश्यकता नहीं है - शायद एक छोटा दस्तावेज़ या क्लाइंट के व्यवसाय की भाषा में कुछ वाक्य भी।
अच्छी योजना डेटा मॉडलिंग के लिए विशिष्ट नहीं है; यह लगभग किसी भी आईटी (और गैर-आईटी) परियोजना पर लागू होता है। छोड़ना केवल एक विकल्प है यदि 1) आपके पास वास्तव में एक छोटी परियोजना है; 2) कार्य और लक्ष्य स्पष्ट हैं, और 3) आप वास्तव में जल्दी में हैं। एक ऐतिहासिक उदाहरण है स्पुतनिक 1 लॉन्चिंग इंजीनियर जो इसे असेंबल कर रहे तकनीशियनों को मौखिक निर्देश दे रहे हैं। इस खबर की वजह से परियोजना जल्दबाजी में थी कि अमेरिका जल्द ही अपना उपग्रह लॉन्च करने की योजना बना रहा था - लेकिन मुझे लगता है कि आप इतनी जल्दी में नहीं होंगे।
#2 ग्राहकों और डेवलपर्स के साथ अपर्याप्त संचार
जब आप डेटाबेस डिज़ाइन प्रक्रिया शुरू करते हैं, तो आप शायद अधिकांश मुख्य आवश्यकताओं को समझेंगे। कुछ व्यवसाय की परवाह किए बिना बहुत सामान्य हैं, उदा. उपयोगकर्ता भूमिकाएँ और स्थितियाँ। दूसरी ओर, आपके मॉडल में कुछ टेबल काफी विशिष्ट होंगे। उदाहरण के लिए, यदि आप कैब कंपनी के लिए एक मॉडल बना रहे हैं, तो आपके पास वाहनों, ड्राइवरों, ग्राहकों आदि के लिए टेबल होंगे।
फिर भी, किसी प्रोजेक्ट की शुरुआत में सब कुछ स्पष्ट नहीं होगा। आप कुछ आवश्यकताओं को गलत समझ सकते हैं, ग्राहक कुछ नई कार्यक्षमता जोड़ सकता है, आपको कुछ ऐसा दिखाई देगा जो अलग तरीके से किया जा सकता है, प्रक्रिया बदल सकती है, आदि। ये सभी कारण मॉडल में परिवर्तन करते हैं। अधिकांश परिवर्तनों के लिए नई तालिकाएँ जोड़ने की आवश्यकता होती है, लेकिन कभी-कभी आप तालिकाओं को हटा या संशोधित कर रहे होंगे। यदि आपने पहले ही कोड लिखना शुरू कर दिया है जो इन तालिकाओं का उपयोग करता है, तो आपको उस कोड को भी फिर से लिखना होगा।
अप्रत्याशित परिवर्तनों पर लगने वाले समय को कम करने के लिए, आपको यह करना चाहिए:
- डेवलपर्स और क्लाइंट्स से बात करें और महत्वपूर्ण व्यावसायिक प्रश्न पूछने से न डरें। जब आपको लगता है कि आप शुरू करने के लिए तैयार हैं, तो अपने आप से पूछें क्या स्थिति X हमारे डेटाबेस में शामिल है? क्लाइंट वर्तमान में Y इस तरह से कर रहा है; क्या हम निकट भविष्य में बदलाव की उम्मीद करते हैं? एक बार जब हमें विश्वास हो जाए कि हमारे मॉडल में हमारी जरूरत की हर चीज को सही तरीके से स्टोर करने की क्षमता है, तो हम कोडिंग शुरू कर सकते हैं।
- यदि आप अपने डिजाइन में एक बड़े बदलाव का सामना करते हैं और आपके पास पहले से ही बहुत सारे कोड लिखे हुए हैं, तो आपको जल्दी ठीक करने का प्रयास नहीं करना चाहिए। जैसा करना चाहिए था वैसा ही करें, चाहे मौजूदा स्थिति कैसी भी हो। एक त्वरित सुधार अब कुछ समय बचा सकता है और शायद कुछ समय के लिए ठीक काम करेगा, लेकिन यह बाद में एक वास्तविक दुःस्वप्न में बदल सकता है।
- अगर आपको लगता है कि अभी कुछ ठीक है लेकिन बाद में समस्या बन सकती है, तो इसे नज़रअंदाज़ न करें। उस क्षेत्र का विश्लेषण करें और परिवर्तनों को लागू करें यदि वे सिस्टम की गुणवत्ता और प्रदर्शन में सुधार करेंगे। इसमें कुछ समय लगेगा, लेकिन आप बेहतर उत्पाद देंगे और बेहतर नींद लेंगे।
यदि आप संभावित समस्या देखते समय अपने डेटा मॉडल में परिवर्तन करने से बचने का प्रयास करते हैं - या यदि आप इसे ठीक से करने के बजाय त्वरित सुधार का विकल्प चुनते हैं - तो आप जल्द या बाद में इसके लिए भुगतान करेंगे।
साथ ही, पूरे प्रोजेक्ट के दौरान अपने क्लाइंट और डेवलपर्स के संपर्क में रहें। हमेशा जांचें और देखें कि क्या आपकी पिछली चर्चा के बाद से कोई बदलाव किया गया है।
#3 खराब या अनुपलब्ध दस्तावेज़ीकरण
हम में से अधिकांश के लिए, प्रलेखन परियोजना के अंत में आता है। यदि हम अच्छी तरह से व्यवस्थित हैं, तो संभवतः हमने रास्ते में चीजों का दस्तावेजीकरण किया है और हमें केवल सब कुछ समेटने की आवश्यकता होगी। लेकिन ईमानदारी से, आमतौर पर ऐसा नहीं होता है। प्रोजेक्ट बंद होने से ठीक पहले प्रलेखन लिखना होता है - और उस डेटा मॉडल के साथ मानसिक रूप से समाप्त होने के ठीक बाद!
एक खराब दस्तावेज वाली परियोजना के लिए भुगतान की गई कीमत काफी अधिक हो सकती है, जो कीमत हम सब कुछ ठीक से दस्तावेज करने के लिए भुगतान की कीमत से कुछ गुना अधिक है। प्रोजेक्ट को बंद करने के कुछ महीने बाद एक बग खोजने की कल्पना करें। क्योंकि आपने ठीक से दस्तावेज़ नहीं किया है, आप नहीं जानते कि कहां से शुरू करें।
जैसा कि आप काम कर रहे हैं, टिप्पणियाँ लिखना न भूलें। अतिरिक्त स्पष्टीकरण की आवश्यकता वाली हर चीज़ की व्याख्या करें, और मूल रूप से वह सब कुछ लिखें जो आपको लगता है कि एक दिन उपयोगी होगा। आप कभी नहीं जानते कि आपको उस अतिरिक्त जानकारी की आवश्यकता होगी या नहीं।
तकनीकी डेटाबेस डिजाइन गलतियां
#4 नामकरण परंपरा का उपयोग नहीं करना
आप निश्चित रूप से कभी नहीं जानते कि कोई प्रोजेक्ट कितने समय तक चलेगा और यदि आपके पास डेटा मॉडल पर काम करने वाले एक से अधिक व्यक्ति होंगे। एक बिंदु है जब आप वास्तव में डेटा मॉडल के करीब होते हैं, लेकिन आपने वास्तव में इसे अभी तक चित्रित करना शुरू नहीं किया है। यह तब होता है जब यह तय करना बुद्धिमानी है कि आप अपने मॉडल में, डेटाबेस में और सामान्य एप्लिकेशन में ऑब्जेक्ट्स का नाम कैसे देंगे। मॉडलिंग से पहले, आपको पता होना चाहिए:
- टेबल नाम एकवचन हैं या बहुवचन?
- क्या हम नामों का उपयोग करके तालिकाओं को समूहीकृत करेंगे? (उदाहरण के लिए, सभी क्लाइंट-संबंधित तालिकाओं में "क्लाइंट_" होता है, सभी कार्य-संबंधित तालिकाओं में "टास्क_", आदि होते हैं)
- क्या हम अपरकेस और लोअरकेस अक्षरों का उपयोग करेंगे, या केवल लोअरकेस का?
- आईडी कॉलम के लिए हम किस नाम का उपयोग करेंगे? (सबसे अधिक संभावना है, यह "आईडी" होगा।)
- हम विदेशी कुंजियों का नाम कैसे रखेंगे? (सबसे अधिक संभावना "id_" और संदर्भित तालिका का नाम।)
एक मॉडल के उस हिस्से की तुलना करें जो नामकरण परंपराओं का उपयोग नहीं करता है, उसी भाग के साथ जो नामकरण सम्मेलनों का उपयोग करता है, जैसा कि नीचे दिखाया गया है:
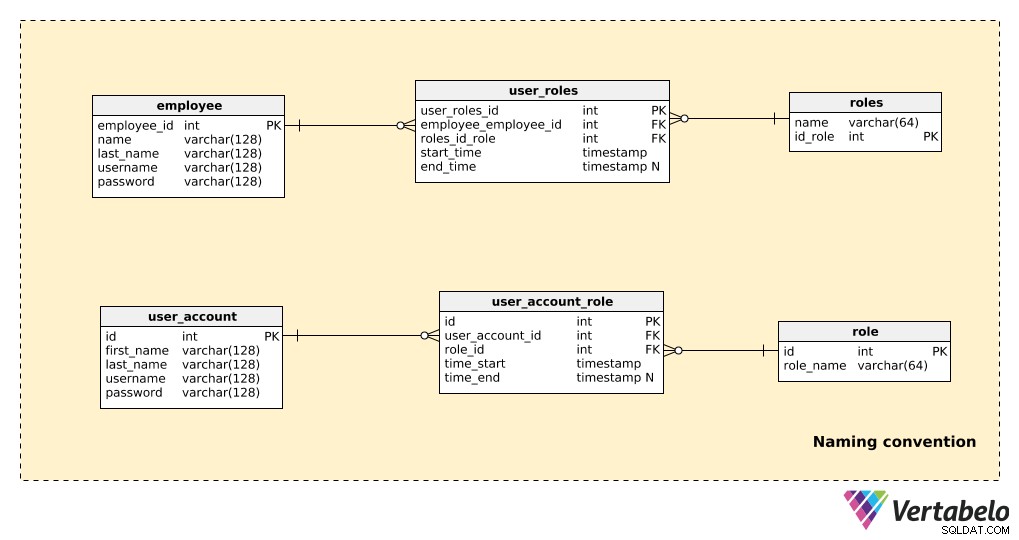
यहां केवल कुछ टेबल हैं, लेकिन यह अभी भी स्पष्ट है कि कौन सा मॉडल पढ़ना आसान है। ध्यान दें कि:
- दोनों मॉडल "काम" करते हैं, इसलिए तकनीकी पक्ष में कोई समस्या नहीं है।
- गैर-नामकरण-सम्मेलन उदाहरण (ऊपरी तीन टेबल) में, कुछ चीजें हैं जो पठनीयता को महत्वपूर्ण रूप से प्रभावित करती हैं:तालिका नामों में एकवचन और बहुवचन दोनों रूपों का उपयोग करना; गैर-मानकीकृत प्राथमिक कुंजी नाम (
employees_id,id_role); और अलग-अलग तालिकाओं में विशेषताएँ समान नाम साझा करती हैं (उदा. नाम “employee” और “roles” टेबल) ।
अब कल्पना कीजिए कि अगर हमारे मॉडल में सैकड़ों टेबल होते तो हम क्या गड़बड़ करते। हो सकता है कि हम ऐसे मॉडल के साथ काम कर सकें (अगर हमने इसे खुद बनाया है) लेकिन हम किसी को बहुत बदकिस्मत बना देंगे अगर उन्हें हमारे बाद इस पर काम करना पड़े।
नामों के साथ भविष्य की समस्याओं से बचने के लिए, SQL आरक्षित शब्दों, विशेष वर्णों या उनमें रिक्त स्थान का उपयोग न करें।
इसलिए, इससे पहले कि आप कोई भी नाम बनाना शुरू करें, एक साधारण दस्तावेज़ बनाएं (शायद केवल कुछ पेज लंबा) जो आपके द्वारा उपयोग किए गए नामकरण परंपरा का वर्णन करता है। यह पूरे मॉडल की पठनीयता को बढ़ाएगा और भविष्य के काम को सरल करेगा।
आप इन दो लेखों में नामकरण परंपराओं के बारे में अधिक पढ़ सकते हैं:
- डेटाबेस मॉडलिंग में नामकरण परंपराएं
- एसक्यूएल सर्वर नामकरण सम्मेलनों पर एक भावनात्मक तार्किक नजरिया
#5 सामान्यीकरण के मुद्दे
सामान्यीकरण डेटाबेस डिजाइन का एक अनिवार्य हिस्सा है। प्रत्येक डेटाबेस को कम से कम 3NF के लिए सामान्यीकृत किया जाना चाहिए (प्राथमिक कुंजी परिभाषित हैं, कॉलम परमाणु हैं, और कोई दोहराए जाने वाले समूह, आंशिक निर्भरता या संक्रमणीय निर्भरताएं नहीं हैं)। यह डेटा दोहराव को कम करता है और संदर्भात्मक अखंडता सुनिश्चित करता है।
आप इस लेख में सामान्यीकरण के बारे में अधिक पढ़ सकते हैं। संक्षेप में, जब भी हम संबंधपरक डेटाबेस मॉडल के बारे में बात करते हैं, तो हम सामान्यीकृत डेटाबेस के बारे में बात कर रहे होते हैं। यदि डेटाबेस को सामान्य नहीं किया जाता है, तो हम डेटा अखंडता से संबंधित कई समस्याओं का सामना करेंगे।
कुछ मामलों में, हम अपने डेटाबेस को असामान्य बनाना चाह सकते हैं। यदि आप ऐसा करते हैं, तो वास्तव में एक अच्छा कारण है। आप यहां डेटाबेस डीनॉर्मलाइजेशन के बारे में अधिक पढ़ सकते हैं।
#6 एंटिटी-एट्रिब्यूट-वैल्यू (EAV) मॉडल का उपयोग करना
EAV,इकाई-विशेषता-मूल्य के लिए खड़ा है। इस संरचना का उपयोग हमारे मॉडल में किसी भी चीज़ के बारे में अतिरिक्त डेटा संग्रहीत करने के लिए किया जा सकता है। आइए एक उदाहरण पर एक नजर डालते हैं।
मान लीजिए कि हम कुछ अतिरिक्त ग्राहक विशेषताओं को संग्रहीत करना चाहते हैं। “customer “तालिका हमारी इकाई है, “attribute “ तालिका स्पष्ट रूप से हमारी विशेषता है, और “attribute_value ” तालिका में उस ग्राहक के लिए उस विशेषता का मान होता है।
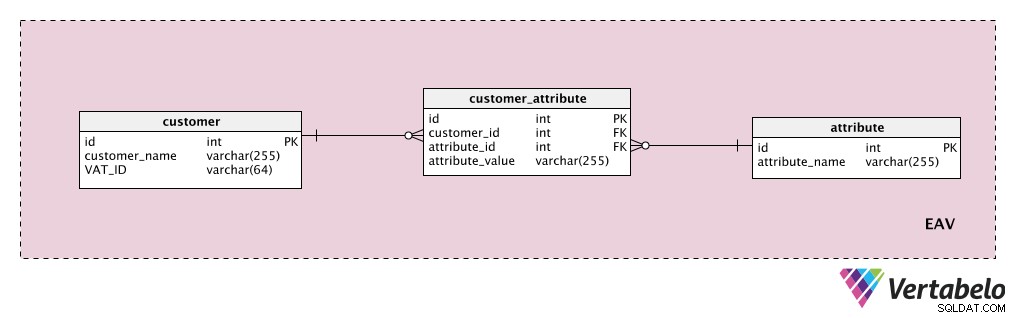
सबसे पहले, हम उन सभी संभावित गुणों की सूची के साथ एक शब्दकोश जोड़ेंगे जो हम किसी ग्राहक को सौंप सकते हैं। यह "attribute " टेबल। इसमें "ग्राहक मूल्य", "संपर्क विवरण", "अतिरिक्त जानकारी" आदि जैसे गुण हो सकते हैं। "customer_attribute तालिका में प्रत्येक ग्राहक के लिए मूल्यों के साथ सभी विशेषताओं की एक सूची है। प्रत्येक ग्राहक के लिए, हमारे पास केवल उनके पास मौजूद विशेषताओं के लिए रिकॉर्ड होंगे, और हम “attribute_value ” उस विशेषता के लिए।
यह वास्तव में बहुत अच्छा लग सकता है। यह हमें नई संपत्तियों को आसानी से जोड़ने की अनुमति देगा (क्योंकि हम उन्हें “customer_attribute " टेबल)। इस प्रकार, हम डेटाबेस में परिवर्तन करने से बचेंगे। सच होने के लिए लगभग बहुत अच्छा है।
और यह बहुत अच्छा है। जबकि मॉडल हमारे लिए आवश्यक डेटा संग्रहीत करेगा, ऐसे डेटा के साथ काम करना कहीं अधिक जटिल है। और इसमें लगभग सब कुछ शामिल है, साधारण SELECT क्वेरी लिखने से लेकर सभी ग्राहक-संबंधी मान प्राप्त करने से लेकर मान डालने, अपडेट करने या हटाने तक।
संक्षेप में, हमें EAV संरचना से बचना चाहिए। यदि आपको इसका उपयोग करना है, तो इसका उपयोग केवल तभी करें जब आप 100% सुनिश्चित हों कि इसकी वास्तव में आवश्यकता है।
#7 प्राथमिक कुंजी के रूप में GUID/UUID का उपयोग करना
GUID (वैश्विक रूप से विशिष्ट पहचानकर्ता) RFC 4122 में परिभाषित नियमों के अनुसार उत्पन्न 128-बिट संख्या है। उन्हें कभी-कभी UUIDs (सार्वभौमिक रूप से विशिष्ट पहचानकर्ता) के रूप में भी जाना जाता है। GUID का मुख्य लाभ यह है कि यह अद्वितीय है; आपके द्वारा एक ही GUID को दो बार मारने की संभावना वास्तव में असंभव है। इसलिए, प्राथमिक कुंजी कॉलम के लिए GUID एक महान उम्मीदवार की तरह प्रतीत होते हैं। लेकिन ऐसा नहीं है।
प्राथमिक कुंजी के लिए एक सामान्य नियम यह है कि हम एक पूर्णांक कॉलम का उपयोग करते हैं जिसमें ऑटोइनक्रिकमेंट प्रॉपर्टी "हां" पर सेट होती है। यह प्राथमिक कुंजी में क्रमिक क्रम में डेटा जोड़ देगा और इष्टतम प्रदर्शन प्रदान करेगा। अनुक्रमिक कुंजी या टाइमस्टैम्प के बिना, यह जानने का कोई तरीका नहीं है कि कौन सा डेटा पहले डाला गया था। यह समस्या तब भी उत्पन्न होती है जब हम अद्वितीय वास्तविक-विश्व मूल्यों (उदा. वैट आईडी) का उपयोग करते हैं। जबकि उनके पास UNIQUE मान हैं, वे अच्छी प्राथमिक कुंजी नहीं बनाते हैं। इसके बजाय वैकल्पिक कुंजियों के रूप में उनका उपयोग करें।
एक अतिरिक्त नोट: मैं प्राथमिक कुंजी के रूप में सिंगल-कॉलम ऑटो-जेनरेटेड पूर्णांक विशेषताओं का उपयोग करना पसंद करता हूं। यह निश्चित रूप से सबसे अच्छा अभ्यास है। मेरा सुझाव है कि आप मिश्रित प्राथमिक कुंजियों का उपयोग करने से बचें।
#8 अपर्याप्त अनुक्रमण
इंडेक्स डेटाबेस के साथ काम करने का एक बहुत ही महत्वपूर्ण हिस्सा हैं, लेकिन उनकी गहन चर्चा इस लेख के दायरे से बाहर है। सौभाग्य से, हमारे पास पहले से ही अनुक्रमणिका से संबंधित कुछ लेख हैं जिन्हें आप अधिक जानने के लिए देख सकते हैं:- डेटाबेस इंडेक्स क्या है?
- सूचकांक के बारे में सब कुछ:बहुत मूल बातें
- अनुक्रमणिका के बारे में सब कुछ भाग 2:MySQL अनुक्रमणिका संरचना और प्रदर्शन
संक्षिप्त संस्करण यह है कि मैं आपको एक इंडेक्स जोड़ने की सलाह देता हूं जहां आपको इसकी आवश्यकता होगी। डेटाबेस के उत्पादन में होने के बाद आप उन्हें भी जोड़ सकते हैं यदि आप देखते हैं कि किसी निश्चित स्थान पर अनुक्रमणिका जोड़ने से प्रदर्शन में सुधार होगा।
#9 अनावश्यक डेटा
किसी भी मॉडल में आम तौर पर अनावश्यक डेटा से बचा जाना चाहिए। यह न केवल अतिरिक्त डिस्क स्थान लेता है बल्कि यह डेटा अखंडता समस्याओं की संभावना को भी काफी बढ़ा देता है। अगर कुछ अनावश्यक होना है, तो हमें इस बात का ध्यान रखना चाहिए कि मूल डेटा और "कॉपी" हमेशा सुसंगत स्थिति में हों। वास्तव में, ऐसी कुछ स्थितियां हैं जहां अनावश्यक डेटा वांछनीय है:
- कुछ मामलों में, हमें एक निश्चित क्रिया को प्राथमिकता देनी होगी - और ऐसा करने के लिए, हमें जटिल गणनाएँ करनी होंगी। ये गणना कई तालिकाओं का उपयोग कर सकती हैं और बहुत सारे संसाधनों का उपभोग कर सकती हैं। ऐसे मामलों में, इन गणनाओं को बंद घंटों के दौरान करना बुद्धिमानी होगी (इस प्रकार काम के घंटों के दौरान प्रदर्शन के मुद्दों से बचना)। यदि हम इसे इस तरह से करते हैं, तो हम उस परिकलित मूल्य को संग्रहीत कर सकते हैं और बाद में इसका पुनर्गणना किए बिना इसका उपयोग कर सकते हैं। बेशक, मूल्य बेमानी है; हालांकि, हम प्रदर्शन में जो हासिल करते हैं, वह हमारे द्वारा खोए गए (कुछ हार्ड ड्राइव स्थान) की तुलना में काफी अधिक है।
- हम डेटाबेस के अंदर रिपोर्टिंग डेटा का एक छोटा सा सेट भी स्टोर कर सकते हैं। उदाहरण के लिए, दिन के अंत में, हम उस दिन की गई कॉलों की संख्या, सफल बिक्री की संख्या आदि को संग्रहीत करेंगे। रिपोर्टिंग डेटा केवल इस तरह से संग्रहीत किया जाना चाहिए यदि हमें इसे अक्सर उपयोग करने की आवश्यकता होती है। एक बार फिर, हम थोड़ा हार्ड ड्राइव स्थान खो देंगे, लेकिन हम डेटा की पुनर्गणना या रिपोर्टिंग डेटाबेस से कनेक्ट होने से बचेंगे (यदि हमारे पास एक है)।
ज्यादातर मामलों में, हमें अनावश्यक डेटा का उपयोग नहीं करना चाहिए क्योंकि:
- डेटाबेस में एक ही डेटा को एक से अधिक बार संग्रहीत करने से डेटा अखंडता प्रभावित हो सकती है। यदि आप क्लाइंट के नाम को दो अलग-अलग जगहों पर स्टोर करते हैं, तो आपको एक ही समय में दोनों जगहों पर कोई भी बदलाव (सम्मिलित/अपडेट/डिलीट) करना चाहिए। यह उस कोड को भी जटिल बनाता है जिसकी आपको आवश्यकता होगी, यहां तक कि सरलतम कार्यों के लिए भी।
- जबकि हम अपने परिचालन डेटाबेस में कुछ एकत्रित संख्याओं को संग्रहीत कर सकते हैं, हमें ऐसा तभी करना चाहिए जब हमें वास्तव में आवश्यकता हो। एक परिचालन डेटाबेस रिपोर्टिंग डेटा को संग्रहीत करने के लिए नहीं है, और इन दोनों को मिलाना आम तौर पर एक बुरा अभ्यास है। रिपोर्ट बनाने वाले किसी भी व्यक्ति को उन्हीं संसाधनों का उपयोग करना होगा जो परिचालन कार्यों पर काम करने वाले उपयोगकर्ताओं को करना होगा; रिपोर्टिंग क्वेरी आमतौर पर अधिक जटिल होती हैं और प्रदर्शन को प्रभावित कर सकती हैं। इसलिए, आपको अपने परिचालन डेटाबेस और अपने रिपोर्टिंग डेटाबेस को अलग कर देना चाहिए।
अब वजन करने की आपकी बारी है
मुझे उम्मीद है कि इस लेख को पढ़ने से आपको कुछ नई जानकारी मिली होगी और आपको डेटा मॉडलिंग की सर्वोत्तम प्रथाओं का पालन करने के लिए प्रोत्साहित किया जाएगा। वे आपका कुछ समय बचाएंगे!
क्या आपने इस लेख में उल्लिखित किसी भी मुद्दे का अनुभव किया है? क्या आपको लगता है कि हमने कुछ महत्वपूर्ण याद किया? या आपको लगता है कि हमें अपनी सूची से कुछ हटा देना चाहिए? कृपया हमें नीचे कमेंट्स में बताएं।