अक्सर, जब हम एक संग्रहित प्रक्रिया लिखते हैं, तो हम चाहते हैं कि यह उपयोगकर्ता इनपुट के आधार पर विभिन्न तरीकों से व्यवहार करे। आइए निम्नलिखित उदाहरण देखें:
CREATE PROCEDURE Sales.GetOrders ( @CustomerID AS INT = NULL , @SortOrder AS SYSNAME = N'OrderDate' ) AS SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID WHERE SalesOrders.CustomerID = @CustomerID OR @CustomerID IS NULL GROUP BY SalesOrders.SalesOrderID , SalesOrders.OrderDate , SalesOrders.DueDate , SalesOrders.[Status] , SalesOrders.CustomerID ORDER BY CASE @SortOrder WHEN N'OrderDate' THEN SalesOrders.OrderDate WHEN N'SalesOrderID' THEN SalesOrders.SalesOrderID END ASC; GO
यह संग्रहीत कार्यविधि, जिसे मैंने AdventureWorks2017 डेटाबेस में बनाया है, के दो पैरामीटर हैं:@CustomerID और @SortOrder। पहला पैरामीटर, @CustomerID, लौटाई जाने वाली पंक्तियों को प्रभावित करता है। यदि एक विशिष्ट ग्राहक आईडी को संग्रहीत प्रक्रिया में पास किया जाता है, तो यह इस ग्राहक के लिए सभी आदेश (शीर्ष 10) लौटाता है। अन्यथा, यदि यह NULL है, तो संग्रहीत कार्यविधि ग्राहक की परवाह किए बिना सभी ऑर्डर (शीर्ष 10) लौटाती है। दूसरा पैरामीटर, @SortOrder, यह निर्धारित करता है कि डेटा को कैसे सॉर्ट किया जाएगा—OrderDate या SalesOrderID द्वारा। ध्यान दें कि सॉर्ट क्रम के अनुसार केवल पहली 10 पंक्तियाँ ही वापस की जाएँगी।
इसलिए, उपयोगकर्ता क्वेरी के व्यवहार को दो तरह से प्रभावित कर सकते हैं—किस पंक्तियों को वापस करना है और उन्हें कैसे क्रमबद्ध करना है। अधिक सटीक होने के लिए, इस क्वेरी के लिए 4 अलग-अलग व्यवहार हैं:
- ऑर्डरडेट (डिफ़ॉल्ट व्यवहार) द्वारा क्रमबद्ध सभी ग्राहकों के लिए शीर्ष 10 पंक्तियां लौटाएं
- किसी विशिष्ट ग्राहक के लिए शीर्ष 10 पंक्तियों को ऑर्डरडेट के अनुसार क्रमबद्ध करें
- SalesOrderID द्वारा क्रमित सभी ग्राहकों के लिए शीर्ष 10 पंक्तियां लौटाएं
- SalesOrderID द्वारा क्रमबद्ध किसी विशिष्ट ग्राहक के लिए शीर्ष 10 पंक्तियां लौटाएं
आइए सभी 4 विकल्पों के साथ संग्रहीत कार्यविधि का परीक्षण करें और निष्पादन योजना और आँकड़ों की जाँच करें।
आदेश दिनांक के अनुसार क्रमित सभी ग्राहकों के लिए शीर्ष 10 पंक्तियां लौटाएं
संग्रहीत कार्यविधि को निष्पादित करने के लिए निम्नलिखित कोड है:
EXECUTE Sales.GetOrders; GO
यहाँ निष्पादन योजना है:
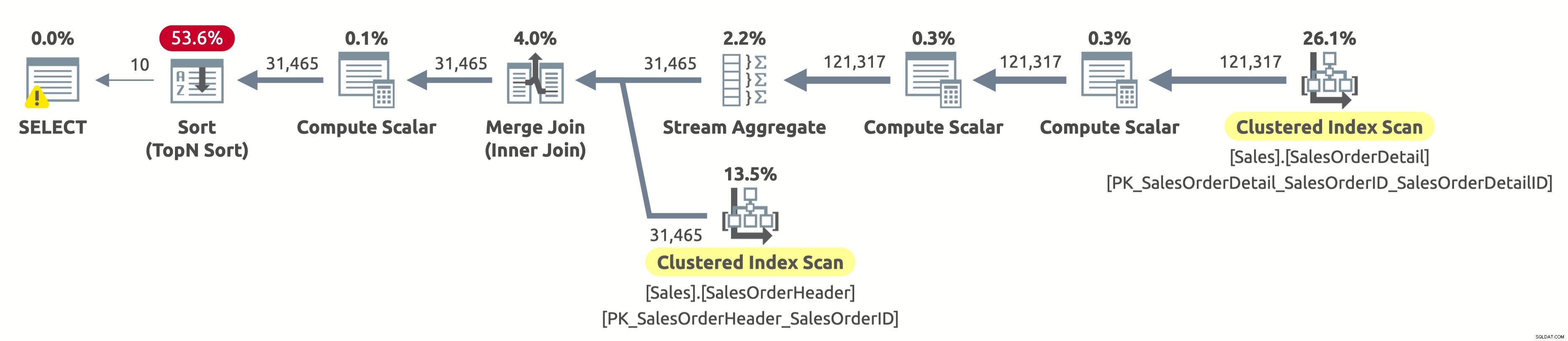
चूंकि हमने ग्राहक द्वारा फ़िल्टर नहीं किया है, इसलिए हमें पूरी तालिका को स्कैन करने की आवश्यकता है। ऑप्टिमाइज़र ने SalesOrderID पर अनुक्रमणिका का उपयोग करके दोनों तालिकाओं को स्कैन करना चुना, जो एक कुशल स्ट्रीम एग्रीगेट के साथ-साथ एक कुशल मर्ज जॉइन की अनुमति देता है।
यदि आप Sales.SalesOrderHeader तालिका पर क्लस्टर्ड इंडेक्स स्कैन ऑपरेटर के गुणों की जाँच करते हैं, तो आपको निम्न विधेय मिलेगा:[AdventureWorks2017].[Sales].[SalesOrderHeader].[CustomerID] [SalesOrders] के रूप में।[CustomerID]=[ @CustomerID] या [@CustomerID] शून्य है। क्वेरी प्रोसेसर को तालिका में प्रत्येक पंक्ति के लिए इस विधेय का मूल्यांकन करना होता है, जो बहुत कुशल नहीं है क्योंकि यह हमेशा सत्य का मूल्यांकन करेगा।
पहली 10 पंक्तियों को वापस करने के लिए हमें अभी भी ऑर्डरडेट द्वारा सभी डेटा को सॉर्ट करने की आवश्यकता है। अगर ऑर्डरडेट पर एक इंडेक्स होता, तो ऑप्टिमाइज़र शायद इसका इस्तेमाल Sales.SalesOrderHeader से केवल पहली 10 पंक्तियों को स्कैन करने के लिए करता, लेकिन ऐसा कोई इंडेक्स नहीं है, इसलिए उपलब्ध इंडेक्स को देखते हुए योजना ठीक लगती है।
यहाँ आँकड़ों का आउटपुट है IO:
- तालिका 'SalesOrderHeader'। स्कैन गिनती 1, तार्किक 689 पढ़ता है
- तालिका 'SalesOrderDetail'। स्कैन गिनती 1, तार्किक 1248 पढ़ता है
यदि आप पूछ रहे हैं कि चयन ऑपरेटर पर चेतावनी क्यों है, तो यह अत्यधिक अनुदान चेतावनी है। इस मामले में, ऐसा इसलिए नहीं है क्योंकि निष्पादन योजना में कोई समस्या है, बल्कि इसलिए है क्योंकि क्वेरी प्रोसेसर ने 1,024KB (जो कि डिफ़ॉल्ट रूप से न्यूनतम है) का अनुरोध किया है और केवल 16KB का उपयोग किया है।
कभी-कभी योजना कैशिंग इतना अच्छा विचार नहीं होता
इसके बाद, हम ऑर्डरडेट द्वारा क्रमबद्ध किसी विशिष्ट ग्राहक के लिए शीर्ष 10 पंक्तियों को वापस करने के परिदृश्य का परीक्षण करना चाहते हैं। नीचे कोड है:
EXECUTE Sales.GetOrders @CustomerID = 11006; GO
निष्पादन योजना बिल्कुल पहले की तरह ही है। इस बार, योजना बहुत अक्षम है क्योंकि यह केवल 3 ऑर्डर वापस करने के लिए दोनों तालिकाओं को स्कैन करती है। इस क्वेरी को निष्पादित करने के कई बेहतर तरीके हैं।
इस मामले में कारण, योजना कैशिंग है। निष्पादन योजना पहले निष्पादन में उस विशिष्ट निष्पादन में पैरामीटर मानों के आधार पर उत्पन्न की गई थी - एक विधि जिसे पैरामीटर सूँघने के रूप में जाना जाता है। उस योजना को पुन:उपयोग के लिए योजना कैश में संग्रहीत किया गया था, और, अब से, इस संग्रहीत कार्यविधि की प्रत्येक कॉल उसी योजना का पुन:उपयोग करने जा रही है।
यह एक उदाहरण है जहां योजना कैशिंग इतना अच्छा विचार नहीं है। इस संग्रहित प्रक्रिया की प्रकृति के कारण, जिसमें 4 अलग-अलग व्यवहार हैं, हम प्रत्येक व्यवहार के लिए एक अलग योजना प्राप्त करने की अपेक्षा करते हैं। लेकिन हम एक ही योजना के साथ फंस गए हैं, जो पहले निष्पादन में उपयोग किए गए विकल्प के आधार पर 4 विकल्पों में से केवल एक के लिए अच्छा है।
आइए इस संग्रहीत कार्यविधि के लिए योजना कैशिंग को अक्षम करें, ताकि हम उस सर्वोत्तम योजना को देख सकें जिसे ऑप्टिमाइज़र अन्य 3 व्यवहारों में से प्रत्येक के लिए तैयार कर सकता है। हम इसे EXECUTE कमांड में RECOMPILE के साथ जोड़कर करेंगे।
आदेश दिनांक के अनुसार क्रमित किसी विशिष्ट ग्राहक के लिए शीर्ष 10 पंक्तियां लौटाएं
ऑर्डरडेट द्वारा क्रमबद्ध किसी विशिष्ट ग्राहक के लिए शीर्ष 10 पंक्तियों को वापस करने के लिए कोड निम्नलिखित है:
EXECUTE Sales.GetOrders @CustomerID = 11006 WITH RECOMPILE; GO
निम्नलिखित निष्पादन योजना है:
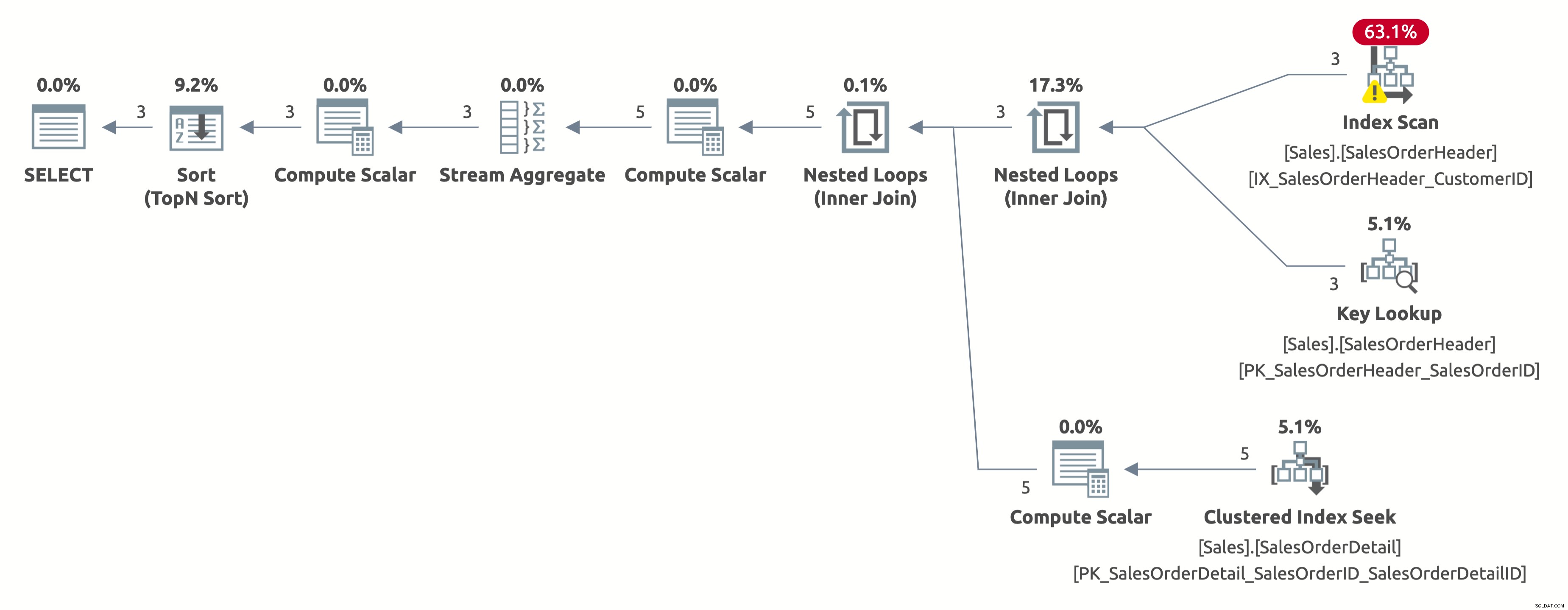
इस बार, हमें एक बेहतर योजना मिली है, जो CustomerID पर एक इंडेक्स का उपयोग करती है। ऑप्टिमाइज़र CustomerID =11006 . के लिए 2.6 पंक्तियों का सही अनुमान लगाता है (वास्तविक संख्या 3 है)। लेकिन ध्यान दें कि यह इंडेक्स की तलाश के बजाय इंडेक्स स्कैन करता है। यह एक अनुक्रमणिका खोज नहीं कर सकता क्योंकि उसे तालिका में प्रत्येक पंक्ति के लिए निम्नलिखित विधेय का मूल्यांकन करना होता है:[AdventureWorks2017].[Sales].[SalesOrderHeader].[CustomerID] [SalesOrders] के रूप में।[CustomerID]=[@CustomerID ] या [@CustomerID] शून्य है।
यहाँ आँकड़ों का आउटपुट है IO:
- तालिका 'SalesOrderDetail'। स्कैन काउंट 3, लॉजिकल रीड्स 9
- तालिका 'SalesOrderHeader'। स्कैन गिनती 1, तार्किक 66 पढ़ता है
SalesOrderID द्वारा क्रमबद्ध सभी ग्राहकों के लिए शीर्ष 10 पंक्तियां लौटाएं
SalesOrderID द्वारा क्रमबद्ध सभी ग्राहकों के लिए शीर्ष 10 पंक्तियों को वापस करने के लिए निम्नलिखित कोड है:
EXECUTE Sales.GetOrders @SortOrder = N'SalesOrderID' WITH RECOMPILE; GO
निम्नलिखित निष्पादन योजना है:
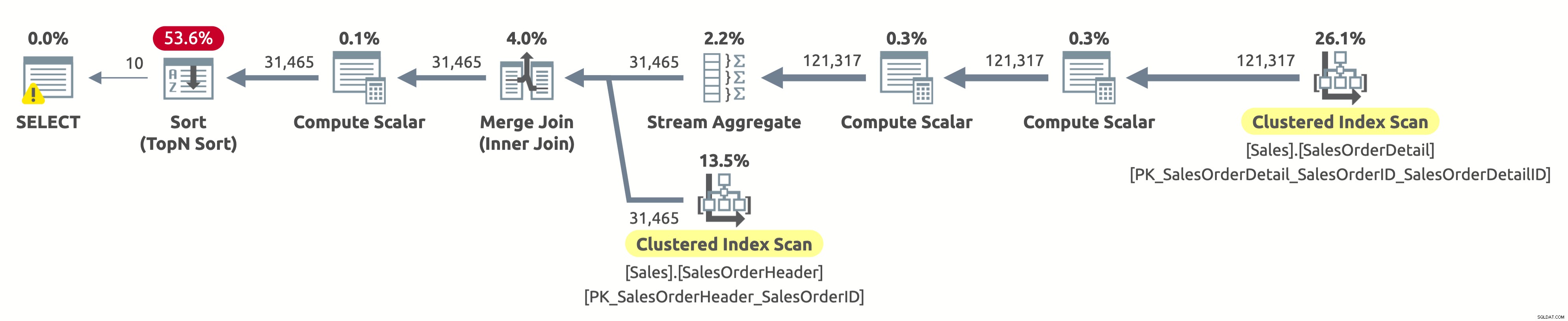
अरे, यह वही निष्पादन योजना है जो पहले विकल्प में है। लेकिन इस बार कुछ गड़बड़ है। हम पहले से ही जानते हैं कि दोनों तालिकाओं पर संकुल अनुक्रमणिका SalesOrderID द्वारा क्रमबद्ध हैं। हम यह भी जानते हैं कि योजना क्रमबद्ध क्रम को बनाए रखने के लिए दोनों को तार्किक क्रम में स्कैन करती है (ऑर्डर की गई संपत्ति सही पर सेट है)। मर्ज ज्वाइन ऑपरेटर भी सॉर्ट ऑर्डर को बरकरार रखता है। क्योंकि अब हम SalesOrderID द्वारा परिणाम को सॉर्ट करने के लिए कह रहे हैं, और यह पहले से ही इस तरह से सॉर्ट किया गया है, तो हमें महंगे सॉर्ट ऑपरेटर के लिए भुगतान क्यों करना पड़ता है?
ठीक है, यदि आप सॉर्ट ऑपरेटर की जांच करते हैं, तो आप देखेंगे कि यह डेटा को Expr1004 के अनुसार सॉर्ट करता है। और, यदि आप सॉर्ट ऑपरेटर के दाईं ओर कंप्यूट स्केलर ऑपरेटर की जांच करते हैं, तो आप पाएंगे कि Expr1004 इस प्रकार है:

यह एक सुंदर दृश्य नहीं है, मुझे पता है। यह वह अभिव्यक्ति है जो हमारे पास हमारी क्वेरी के ORDER BY खंड में है। समस्या यह है कि ऑप्टिमाइज़र संकलन समय पर इस अभिव्यक्ति का मूल्यांकन नहीं कर सकता है, इसलिए इसे रनटाइम पर प्रत्येक पंक्ति के लिए इसकी गणना करनी होगी, और फिर उसके आधार पर पूरे रिकॉर्ड सेट को सॉर्ट करना होगा।
आँकड़ों का आउटपुट IO पहले निष्पादन की तरह ही है:
- तालिका 'SalesOrderHeader'। स्कैन गिनती 1, तार्किक 689 पढ़ता है
- तालिका 'SalesOrderDetail'। स्कैन गिनती 1, तार्किक 1248 पढ़ता है
SalesOrderID द्वारा क्रमबद्ध किसी विशिष्ट ग्राहक के लिए शीर्ष 10 पंक्तियाँ लौटाएँ
SalesOrderID द्वारा क्रमबद्ध किसी विशिष्ट ग्राहक के लिए शीर्ष 10 पंक्तियों को वापस करने के लिए कोड निम्नलिखित है:
EXECUTE Sales.GetOrders @CustomerID = 11006 , @SortOrder = N'SalesOrderID' WITH RECOMPILE; GO
निष्पादन योजना दूसरे विकल्प के समान है (ऑर्डरडेट द्वारा क्रमबद्ध किसी विशिष्ट ग्राहक के लिए शीर्ष 10 पंक्तियां लौटाएं)। योजना में वही दो समस्याएं हैं, जिनका हम पहले ही उल्लेख कर चुके हैं। पहली समस्या WHERE क्लॉज में एक्सप्रेशन के कारण इंडेक्स की तलाश के बजाय इंडेक्स स्कैन कर रही है। दूसरी समस्या ORDER BY क्लॉज में अभिव्यक्ति के कारण एक महंगा प्रकार का प्रदर्शन कर रही है।
तो, हमें क्या करना चाहिए?
आइए पहले खुद को याद दिलाएं कि हम किसके साथ काम कर रहे हैं। हमारे पास पैरामीटर हैं, जो क्वेरी की संरचना निर्धारित करते हैं। पैरामीटर मानों के प्रत्येक संयोजन के लिए, हमें एक अलग क्वेरी संरचना मिलती है। @CustomerID पैरामीटर के मामले में, दो अलग-अलग व्यवहार NULL या NOT NULL हैं, और वे WHERE क्लॉज को प्रभावित करते हैं। @SortOrder पैरामीटर के मामले में, दो संभावित मान हैं, और वे ORDER BY क्लॉज को प्रभावित करते हैं। परिणाम 4 संभावित क्वेरी संरचनाएं हैं, और हम प्रत्येक के लिए एक अलग योजना प्राप्त करना चाहेंगे।
फिर हमारे सामने दो अलग-अलग समस्याएं हैं। पहला प्लान कैशिंग है। संग्रहीत प्रक्रिया के लिए केवल एक ही योजना है, और यह पहले निष्पादन में पैरामीटर मानों के आधार पर उत्पन्न होने वाली है। दूसरी समस्या यह है कि जब एक नई योजना तैयार की जाती है, तब भी यह कुशल नहीं है क्योंकि अनुकूलक संकलन समय पर WHERE क्लॉज और ORDER BY क्लॉज में "डायनेमिक" एक्सप्रेशन का मूल्यांकन नहीं कर सकता है।
हम इन समस्याओं को कई तरीकों से हल करने का प्रयास कर सकते हैं:
- IF-ELSE कथनों की श्रृंखला का उपयोग करें
- प्रक्रिया को अलग संग्रहीत कार्यविधियों में विभाजित करें
- विकल्प का उपयोग करें (पुनः संकलित करें)
- क्वेरी को गतिशील रूप से जेनरेट करें
IF-ELSE कथनों की श्रृंखला का उपयोग करें
यह विचार सरल है:WHERE क्लॉज और ORDER BY क्लॉज में "डायनेमिक" एक्सप्रेशन के बजाय, हम IF-ELSE स्टेटमेंट्स का उपयोग करके निष्पादन को 4 शाखाओं में विभाजित कर सकते हैं - प्रत्येक संभावित व्यवहार के लिए एक शाखा।
उदाहरण के लिए, पहली शाखा का कोड निम्नलिखित है:
IF @CustomerID IS NULL AND @SortOrder = N'OrderDate' BEGIN SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID GROUP BY SalesOrders.SalesOrderID, SalesOrders.OrderDate, SalesOrders.DueDate, SalesOrders.[Status], SalesOrders.CustomerID ORDER BY SalesOrders.OrderDate ASC; END;
यह दृष्टिकोण बेहतर योजनाएँ बनाने में मदद कर सकता है, लेकिन इसकी कुछ सीमाएँ हैं।
सबसे पहले, संग्रहीत प्रक्रिया काफी लंबी हो जाती है, और इसे लिखना, पढ़ना और बनाए रखना अधिक कठिन होता है। और यह तब होता है जब हमारे पास केवल दो पैरामीटर होते हैं। यदि हमारे पास 3 पैरामीटर होते, तो हमारे पास 8 शाखाएँ होतीं। कल्पना कीजिए कि आपको SELECT क्लॉज में एक कॉलम जोड़ने की जरूरत है। आपको कॉलम को 8 अलग-अलग प्रश्नों में जोड़ना होगा। यह मानवीय त्रुटि के उच्च जोखिम के साथ रखरखाव दुःस्वप्न बन जाता है।
दूसरा, हमें अभी भी कुछ हद तक प्लान कैशिंग और पैरामीटर सूँघने की समस्या है। ऐसा इसलिए है क्योंकि पहले निष्पादन में, ऑप्टिमाइज़र उस निष्पादन में पैरामीटर मानों के आधार पर सभी 4 प्रश्नों के लिए एक योजना तैयार करने जा रहा है। मान लें कि पहला निष्पादन पैरामीटर के लिए डिफ़ॉल्ट मानों का उपयोग करने जा रहा है। विशेष रूप से, @CustomerID का मान NULL होगा। WHERE क्लॉज (SalesOrders.CustomerID =@CustomerID) के साथ क्वेरी सहित, सभी प्रश्नों को उस मान के आधार पर अनुकूलित किया जाएगा। अनुकूलक इन प्रश्नों के लिए 0 पंक्तियों का अनुमान लगाने जा रहा है। अब, मान लें कि दूसरा निष्पादन @CustomerID के लिए एक गैर-शून्य मान का उपयोग करने जा रहा है। कैश्ड योजना, जो 0 पंक्तियों का अनुमान लगाती है, का उपयोग किया जाएगा, भले ही ग्राहक के पास तालिका में बहुत सारे ऑर्डर हों।
प्रक्रिया को अलग संग्रहीत कार्यविधियों में विभाजित करें
एक ही संग्रहीत प्रक्रिया के भीतर 4 शाखाओं के बजाय, हम 4 अलग-अलग संग्रहीत कार्यविधियाँ बना सकते हैं, प्रत्येक में संबंधित पैरामीटर और संबंधित क्वेरी। फिर, हम वांछित व्यवहार के अनुसार निष्पादित करने के लिए कौन सी संग्रहीत कार्यविधि तय करने के लिए एप्लिकेशन को फिर से लिख सकते हैं। या, यदि हम चाहते हैं कि यह एप्लिकेशन के लिए पारदर्शी हो, तो हम यह तय करने के लिए मूल संग्रहीत कार्यविधि को फिर से लिख सकते हैं कि पैरामीटर मानों के आधार पर किस प्रक्रिया को निष्पादित किया जाए। हम समान IF-ELSE कथनों का उपयोग करने जा रहे हैं, लेकिन प्रत्येक शाखा में एक क्वेरी निष्पादित करने के बजाय, हम एक अलग संग्रहीत कार्यविधि निष्पादित करेंगे।
लाभ यह है कि हम योजना कैशिंग समस्या को हल करते हैं क्योंकि प्रत्येक संग्रहीत कार्यविधि की अब अपनी योजना है, और प्रत्येक संग्रहीत कार्यविधि के लिए योजना पैरामीटर सूँघने के आधार पर इसके पहले निष्पादन में उत्पन्न होने वाली है।
लेकिन हमें अभी भी रखरखाव की समस्या है। कुछ लोग कह सकते हैं कि अब यह और भी बुरा है, क्योंकि हमें कई संग्रहीत प्रक्रियाओं को बनाए रखने की आवश्यकता है। फिर से, यदि हम मापदंडों की संख्या को बढ़ाकर 3 कर देते हैं, तो हमारे पास 8 अलग-अलग संग्रहीत कार्यविधियाँ होंगी।
विकल्प का उपयोग करें (RECOMPILE)
OPTION (RECOMPILE) जादू की तरह काम करता है। आपको बस शब्दों को कहना है (या उन्हें क्वेरी में जोड़ना है), और जादू होता है। वास्तव में, यह कई समस्याओं को हल करता है क्योंकि यह रनटाइम पर क्वेरी को संकलित करता है, और यह प्रत्येक निष्पादन के लिए करता है।
लेकिन आपको सावधान रहना चाहिए क्योंकि आप जानते हैं कि वे क्या कहते हैं:"महान शक्ति के साथ बड़ी जिम्मेदारी आती है।" यदि आप एक व्यस्त OLTP सिस्टम पर बहुत बार निष्पादित की जाने वाली क्वेरी में OPTION (RECOMPILE) का उपयोग करते हैं, तो आप सिस्टम को मार सकते हैं क्योंकि सर्वर को बहुत सारे CPU संसाधनों का उपयोग करके प्रत्येक निष्पादन में एक नई योजना को संकलित और उत्पन्न करने की आवश्यकता होती है। ये वाकई खतरनाक है। हालाँकि, यदि क्वेरी केवल एक बार निष्पादित की जाती है, तो मान लें कि हर कुछ मिनटों में एक बार, तो यह शायद सुरक्षित है। लेकिन हमेशा अपने विशिष्ट वातावरण में प्रभाव का परीक्षण करें।
हमारे मामले में, यह मानते हुए कि हम सुरक्षित रूप से OPTION (RECOMPILE) का उपयोग कर सकते हैं, हमें बस अपनी क्वेरी के अंत में जादुई शब्दों को जोड़ना है, जैसा कि नीचे दिखाया गया है:
ALTER PROCEDURE Sales.GetOrders ( @CustomerID AS INT = NULL , @SortOrder AS SYSNAME = N'OrderDate' ) AS SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID WHERE SalesOrders.CustomerID = @CustomerID OR @CustomerID IS NULL GROUP BY SalesOrders.SalesOrderID , SalesOrders.OrderDate , SalesOrders.DueDate , SalesOrders.[Status] , SalesOrders.CustomerID ORDER BY CASE @SortOrder WHEN N'OrderDate' THEN SalesOrders.OrderDate WHEN N'SalesOrderID' THEN SalesOrders.SalesOrderID END ASC OPTION (RECOMPILE); GO
अब, आइए कार्रवाई में जादू देखें। उदाहरण के लिए, दूसरे व्यवहार की योजना निम्नलिखित है:
EXECUTE Sales.GetOrders @CustomerID = 11006; GO
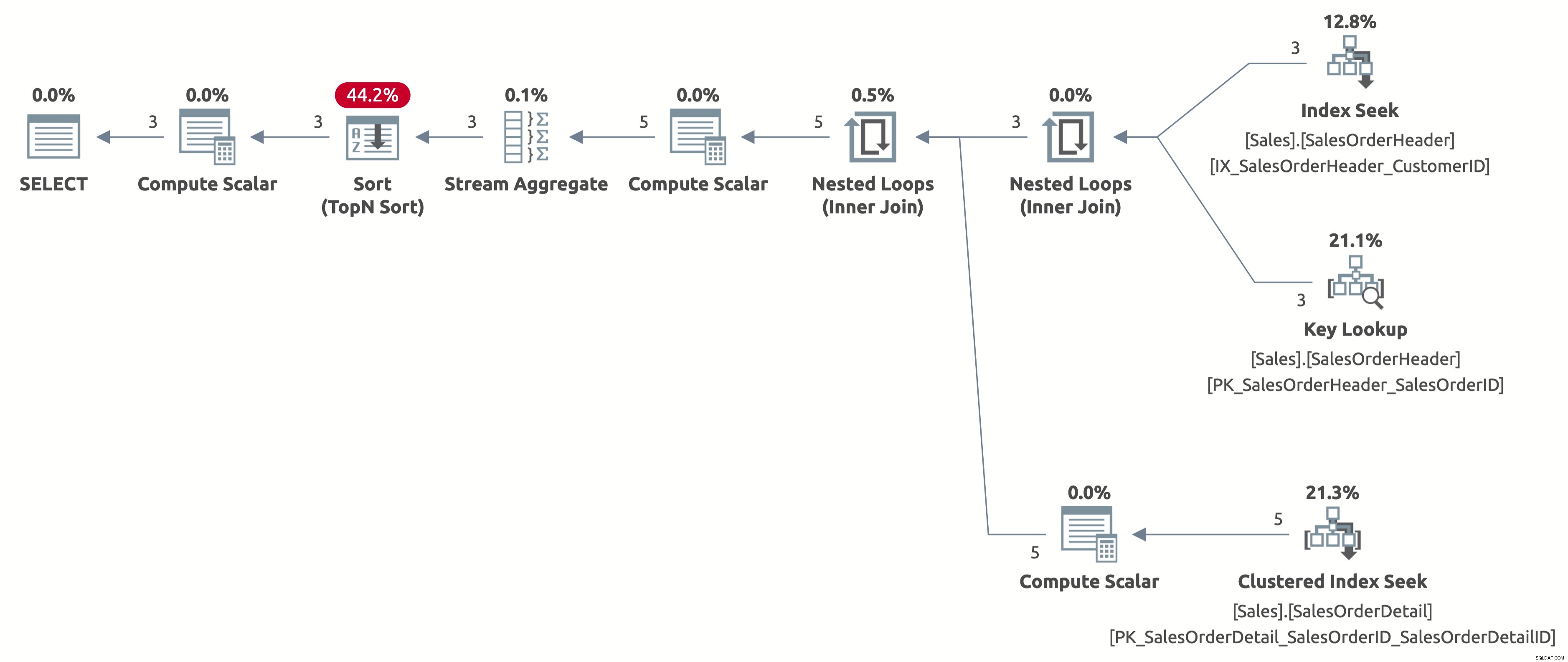
अब हमें 2.6 पंक्तियों के सही अनुमान के साथ एक कुशल इंडेक्स सीक मिलता है। हमें अभी भी ऑर्डरडेट द्वारा सॉर्ट करने की आवश्यकता है, लेकिन अब सॉर्ट सीधे ऑर्डर तिथि के अनुसार है, और हमें ऑर्डर द्वारा क्लॉज में केस एक्सप्रेशन की गणना करने की आवश्यकता नहीं है। उपलब्ध इंडेक्स के आधार पर इस क्वेरी व्यवहार के लिए यह सर्वोत्तम संभव योजना है।
यहाँ आँकड़ों का आउटपुट है IO:
- तालिका 'SalesOrderDetail'। स्कैन काउंट 3, लॉजिकल रीड्स 9
- तालिका 'SalesOrderHeader'। स्कैन गिनती 1, तार्किक 11 पढ़ता है
इस मामले में OPTION (RECOMPILE) के इतने कुशल होने का कारण यह है कि यह हमारे यहां मौजूद दो समस्याओं को ठीक करता है। याद रखें कि पहली समस्या कैशिंग योजना है। OPTION (RECOMPILE) इस समस्या को पूरी तरह से समाप्त कर देता है क्योंकि यह हर बार क्वेरी को फिर से कंपाइल करता है। दूसरी समस्या ऑप्टिमाइज़र की WHERE क्लॉज में और ORDER BY क्लॉज में कंपाइल टाइम पर जटिल एक्सप्रेशन का मूल्यांकन करने में असमर्थता है। चूंकि OPTION (RECOMPILE) रनटाइम पर होता है, यह समस्या को हल करता है। क्योंकि रनटाइम पर, ऑप्टिमाइज़र के पास संकलन समय की तुलना में बहुत अधिक जानकारी होती है, और इससे सभी फर्क पड़ता है।
अब, देखते हैं कि जब हम तीसरे व्यवहार को आजमाते हैं तो क्या होता है:
EXECUTE Sales.GetOrders @SortOrder = N'SalesOrderID'; GO
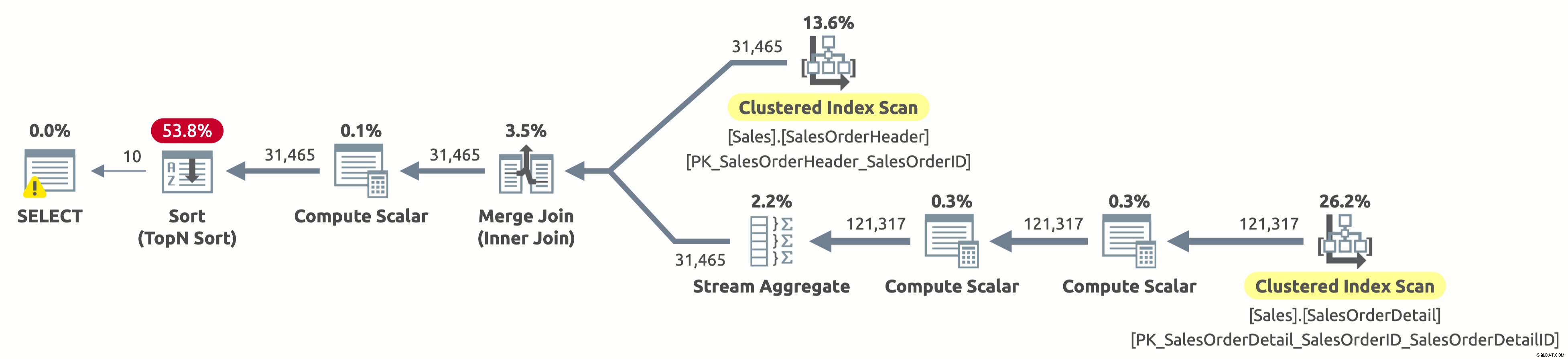
हॉस्टन हमारे पास समस्या हे। योजना अभी भी पूरी तरह से दोनों तालिकाओं को स्कैन करती है और फिर Sales.SalesOrderHeader से केवल पहली 10 पंक्तियों को स्कैन करने और सॉर्ट को पूरी तरह से टालने के बजाय सब कुछ सॉर्ट करती है। क्या हुआ?
यह एक दिलचस्प "मामला" है, और इसे ORDER BY क्लॉज में CASE अभिव्यक्ति के साथ करना है। CASE व्यंजक शर्तों की सूची का मूल्यांकन करता है और परिणाम व्यंजकों में से एक देता है। लेकिन परिणाम अभिव्यक्तियों में भिन्न डेटा प्रकार हो सकते हैं। तो, संपूर्ण CASE व्यंजक का डेटा प्रकार क्या होगा? खैर, CASE व्यंजक हमेशा उच्चतम प्राथमिकता डेटा प्रकार देता है। हमारे मामले में, कॉलम ऑर्डरडेट में DATETIME डेटा प्रकार है, जबकि कॉलम SalesOrderID में INT डेटा प्रकार है। DATETIME डेटा प्रकार की प्राथमिकता अधिक होती है, इसलिए CASE व्यंजक हमेशा DATETIME लौटाता है।
इसका अर्थ यह है कि यदि हम SalesOrderID द्वारा क्रमबद्ध करना चाहते हैं, तो CASE अभिव्यक्ति को क्रमबद्ध करने से पहले प्रत्येक पंक्ति के लिए SalesOrderID के मान को DATETIME में परोक्ष रूप से परिवर्तित करना होगा। उपरोक्त योजना में सॉर्ट ऑपरेटर के दाईं ओर कंप्यूट स्केलर ऑपरेटर देखें? यह ठीक यही करता है।
यह अपने आप में एक समस्या है, और यह दर्शाती है कि एक केस एक्सप्रेशन में विभिन्न डेटा प्रकारों को मिलाना कितना खतरनाक हो सकता है।
हम अन्य तरीकों से ORDER BY क्लॉज को फिर से लिखकर इस समस्या को हल कर सकते हैं, लेकिन यह कोड को और भी बदसूरत और पढ़ने और बनाए रखने में मुश्किल बना देगा। इसलिए, मैं उस दिशा में नहीं जाऊंगा।
इसके बजाय, आइए अगली विधि आज़माएँ…
क्वेरी को गतिशील रूप से जेनरेट करें
चूंकि हमारा लक्ष्य एक ही क्वेरी के भीतर 4 अलग-अलग क्वेरी संरचनाएँ उत्पन्न करना है, इस मामले में डायनेमिक SQL बहुत उपयोगी हो सकता है। विचार पैरामीटर मानों के आधार पर गतिशील रूप से क्वेरी बनाना है। इस तरह, हम एक ही कोड में 4 अलग-अलग क्वेरी स्ट्रक्चर बना सकते हैं, बिना क्वेरी की 4 कॉपी बनाए रख सकते हैं। प्रत्येक क्वेरी संरचना एक बार संकलित होगी, जब इसे पहली बार निष्पादित किया जाएगा, और इसे सबसे अच्छी योजना मिलेगी क्योंकि इसमें कोई जटिल अभिव्यक्ति नहीं है।
यह समाधान कई संग्रहीत कार्यविधियों के समाधान के समान है, लेकिन 3 पैरामीटर के लिए 8 संग्रहीत कार्यविधियों को बनाए रखने के बजाय, हम केवल एक कोड बनाए रखते हैं जो क्वेरी को गतिशील रूप से बनाता है।
मुझे पता है, गतिशील एसक्यूएल भी बदसूरत है और कभी-कभी इसे बनाए रखना काफी मुश्किल हो सकता है, लेकिन मुझे लगता है कि यह कई संग्रहीत प्रक्रियाओं को बनाए रखने की तुलना में अभी भी आसान है, और यह तेजी से स्केल नहीं करता है क्योंकि पैरामीटर की संख्या बढ़ती है।
निम्नलिखित कोड है:
ALTER PROCEDURE Sales.GetOrders ( @CustomerID AS INT = NULL , @SortOrder AS SYSNAME = N'OrderDate' ) AS DECLARE @Command AS NVARCHAR(MAX); SET @Command = N' SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID ' + CASE WHEN @CustomerID IS NULL THEN N'' ELSE N'WHERE SalesOrders.CustomerID = @pCustomerID ' END + N'GROUP BY SalesOrders.SalesOrderID , SalesOrders.OrderDate , SalesOrders.DueDate , SalesOrders.[Status] , SalesOrders.CustomerID ORDER BY ' + CASE @SortOrder WHEN N'OrderDate' THEN N'SalesOrders.OrderDate' WHEN N'SalesOrderID' THEN N'SalesOrders.SalesOrderID' END + N' ASC; '; EXECUTE sys.sp_executesql @stmt = @Command , @params = N'@pCustomerID AS INT' , @pCustomerID = @CustomerID; GO
ध्यान दें कि मैं अभी भी ग्राहक आईडी के लिए एक आंतरिक पैरामीटर का उपयोग करता हूं, और मैं sys.sp_executesql का उपयोग करके डायनेमिक कोड निष्पादित करता हूं पैरामीटर मान पास करने के लिए। यह दो कारणों से महत्वपूर्ण है। सबसे पहले, @CustomerID के विभिन्न मानों के लिए एक ही क्वेरी संरचना के कई संकलनों से बचने के लिए। दूसरा, SQL इंजेक्शन से बचने के लिए।
यदि आप अलग-अलग पैरामीटर मानों का उपयोग करके अब संग्रहीत कार्यविधि को निष्पादित करने का प्रयास करते हैं, तो आप देखेंगे कि प्रत्येक क्वेरी व्यवहार या क्वेरी संरचना को सर्वोत्तम निष्पादन योजना मिलती है, और 4 योजनाओं में से प्रत्येक केवल एक बार संकलित होती है।
उदाहरण के तौर पर, तीसरे व्यवहार की योजना निम्नलिखित है:
EXECUTE Sales.GetOrders @SortOrder = N'SalesOrderID'; GO
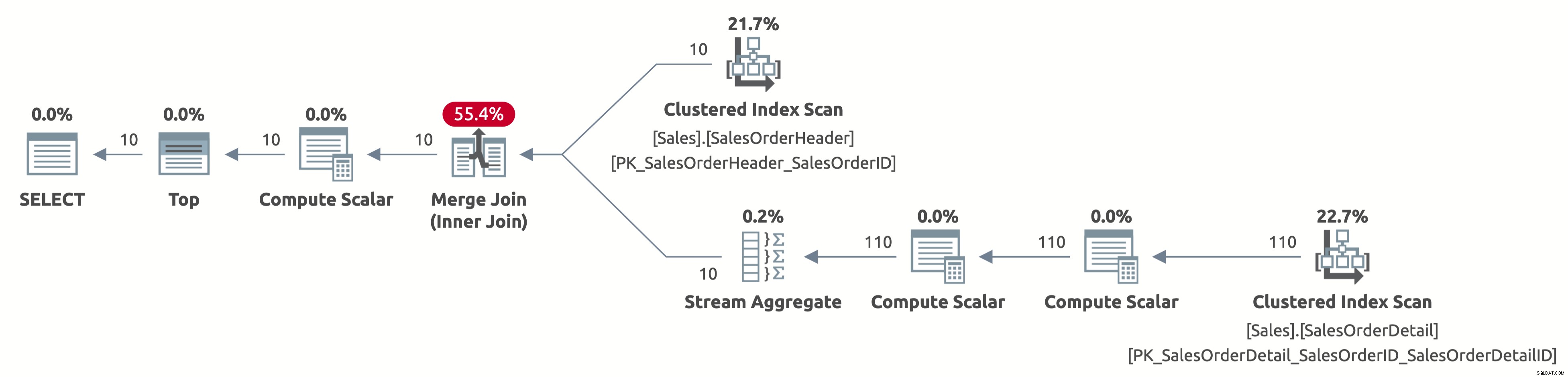
अब, हम Sales.SalesOrderHeader तालिका से केवल पहली 10 पंक्तियों को स्कैन करते हैं, और हम Sales.SalesOrderDetail तालिका से केवल पहली 110 पंक्तियों को भी स्कैन करते हैं। इसके अलावा, कोई सॉर्ट ऑपरेटर नहीं है क्योंकि डेटा पहले से ही SalesOrderID द्वारा सॉर्ट किया गया है।
यहाँ आँकड़ों का आउटपुट है IO:
- तालिका 'SalesOrderDetail'। स्कैन गिनती 1, तार्किक 4 पढ़ता है
- तालिका 'SalesOrderHeader'। स्कैन गिनती 1, तार्किक 3 पढ़ता है
निष्कर्ष
जब आप अपनी क्वेरी की संरचना को बदलने के लिए पैरामीटर का उपयोग करते हैं, तो अपेक्षित व्यवहार प्राप्त करने के लिए क्वेरी के भीतर जटिल अभिव्यक्तियों का उपयोग न करें। ज्यादातर मामलों में, यह खराब प्रदर्शन और अच्छे कारणों से होगा। पहला कारण यह है कि पहले निष्पादन के आधार पर योजना तैयार की जाएगी, और फिर बाद के सभी निष्पादन उसी योजना का पुन:उपयोग करेंगे, जो केवल एक क्वेरी संरचना के लिए उपयुक्त है। दूसरा कारण यह है कि ऑप्टिमाइज़र संकलन समय पर उन जटिल अभिव्यक्तियों का मूल्यांकन करने की अपनी क्षमता में सीमित है।
इन समस्याओं को दूर करने के कई तरीके हैं, और हमने इस लेख में उनकी जांच की है। ज्यादातर मामलों में, पैरामीटर मानों के आधार पर गतिशील रूप से क्वेरी बनाने का सबसे अच्छा तरीका होगा। इस तरह, प्रत्येक क्वेरी संरचना को सर्वोत्तम संभव योजना के साथ एक बार संकलित किया जाएगा।
जब आप डायनेमिक SQL का उपयोग करके क्वेरी बनाते हैं, तो सुनिश्चित करें कि जहां उपयुक्त हो वहां पैरामीटर का उपयोग करें और सत्यापित करें कि आपका कोड सुरक्षित है।