"अपने आप को दोहराएं नहीं" सिद्धांत बताता है कि आपको पुनरावृत्ति को कम करना चाहिए। इस हफ्ते मेरे सामने एक ऐसा मामला आया, जिसमें डीआरवाई को खिड़की से बाहर फेंक दिया जाना चाहिए। अन्य मामले भी हैं (उदाहरण के लिए, स्केलर फ़ंक्शंस), लेकिन यह एक दिलचस्प था जिसमें बिटवाइज़ लॉजिक शामिल था।
आइए निम्न तालिका की कल्पना करें:
CREATE TABLE dbo.CarOrders
(
OrderID INT PRIMARY KEY,
WheelFlag TINYINT,
OrderDate DATE
--, ... other columns ...
);
CREATE INDEX IX_WheelFlag ON dbo.CarOrders(WheelFlag); "व्हीलफ्लैग" बिट्स निम्नलिखित विकल्पों का प्रतिनिधित्व करते हैं:
0 = stock wheels 1 = 17" wheels 2 = 18" wheels 4 = upgraded tires
तो संभावित संयोजन हैं:
0 = no upgrade 1 = upgrade to 17" wheels only 2 = upgrade to 18" wheels only 4 = upgrade tires only 5 = 1 + 4 = upgrade to 17" wheels and better tires 6 = 2 + 4 = upgrade to 18" wheels and better tires
आइए कम से कम अभी के लिए तर्कों को अलग रख दें, कि क्या इसे पहली बार में एक टिन्यिनट में पैक किया जाना चाहिए, या अलग कॉलम के रूप में संग्रहीत किया जाना चाहिए, या एक ईएवी मॉडल का उपयोग करना चाहिए ... डिज़ाइन को ठीक करना एक अलग मुद्दा है। यह आपके पास जो है उसके साथ काम करने के बारे में है।
उदाहरणों को उपयोगी बनाने के लिए, आइए इस तालिका को यादृच्छिक डेटा के एक समूह से भर दें। (और सरलता के लिए, हम मान लेंगे कि इस तालिका में केवल वही ऑर्डर हैं जो अभी तक शिप नहीं हुए हैं।) यह छह विकल्प संयोजनों के बीच लगभग समान वितरण की 50,000 पंक्तियों को सम्मिलित करेगा:
;WITH n AS
(
SELECT n,Flag FROM (VALUES(1,0),(2,1),(3,2),(4,4),(5,5),(6,6)) AS n(n,Flag)
)
INSERT dbo.CarOrders
(
OrderID,
WheelFlag,
OrderDate
)
SELECT x.rn, n.Flag, DATEADD(DAY, x.rn/100, '20100101')
FROM n
INNER JOIN
(
SELECT TOP (50000)
n = (ABS(s1.[object_id]) % 6) + 1,
rn = ROW_NUMBER() OVER (ORDER BY s2.[object_id])
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
) AS x
ON n.n = x.n; यदि हम टूटने को देखें, तो हम इस वितरण को देख सकते हैं। ध्यान दें कि आपके सिस्टम में ऑब्जेक्ट्स के आधार पर आपके परिणाम मेरे से थोड़े भिन्न हो सकते हैं:
SELECT WheelFlag, [Count] = COUNT(*) FROM dbo.CarOrders GROUP BY WheelFlag;
परिणाम:
WheelFlag Count --------- ----- 0 7654 1 8061 2 8757 4 8682 5 8305 6 8541
अब मान लीजिए कि यह मंगलवार है, और हमें अभी-अभी 18" पहियों का शिपमेंट मिला है, जो पहले स्टॉक में नहीं थे। इसका मतलब है कि हम उन सभी ऑर्डरों को पूरा करने में सक्षम हैं, जिनके लिए 18" पहियों की आवश्यकता होती है - वे दोनों जो टायरों को अपग्रेड करते हैं (6), और जो नहीं (2)। तो हम निम्नलिखित की तरह एक प्रश्न *लिख सकते हैं:
SELECT OrderID
FROM dbo.CarOrders
WHERE WheelFlag IN (2,6); वास्तविक जीवन में, निश्चित रूप से, आप वास्तव में ऐसा नहीं कर सकते; क्या होगा यदि बाद में और विकल्प जोड़े जाएं, जैसे व्हील लॉक, लाइफटाइम व्हील वारंटी, या एकाधिक टायर विकल्प? आप हर संभव संयोजन के लिए IN() मानों की एक श्रृंखला नहीं लिखना चाहते हैं। इसके बजाय हम उन सभी पंक्तियों को खोजने के लिए एक बिटवाइज़ और ऑपरेशन लिख सकते हैं जहाँ दूसरा बिट सेट है, जैसे:
DECLARE @Flag TINYINT = 2;
SELECT OrderID
FROM dbo.CarOrders
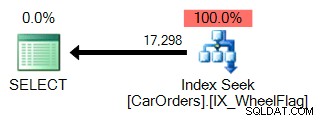
WHERE WheelFlag & @Flag = @Flag; यह मुझे IN() क्वेरी के समान परिणाम देता है, लेकिन अगर मैं SQL संतरी योजना एक्सप्लोरर का उपयोग करके उनकी तुलना करता हूं, तो प्रदर्शन काफी अलग है:

यह देखना आसान है कि क्यों। व्हीलफ्लैग कॉलम पर एक फिल्टर के साथ, क्वेरी को संतुष्ट करने वाली पंक्तियों को अलग करने के लिए पहले इंडेक्स का उपयोग करता है:

दूसरा एक स्कैन का उपयोग करता है, एक अंतर्निहित रूपांतरण के साथ, और बहुत गलत आंकड़े। सभी बिटवाइज़ और ऑपरेटर के कारण:
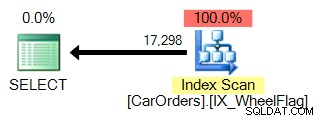


अच्छा तो इसका क्या मतलब है? इसके मूल में, यह हमें बताता है कि BITWISE AND संचालन सुगम नहीं है ।
लेकिन सारी उम्मीद खत्म नहीं होती है।
यदि हम एक पल के लिए DRY सिद्धांत को अनदेखा करते हैं, तो हम व्हीलफ्लैग कॉलम पर इंडेक्स का लाभ उठाने के लिए थोड़ा बेमानी होकर थोड़ी अधिक कुशल क्वेरी लिख सकते हैं। यह मानते हुए कि हम 0 से ऊपर किसी भी व्हीलफ्लैग विकल्प के बाद हैं (बिल्कुल कोई अपग्रेड नहीं), हम क्वेरी को इस तरह से फिर से लिख सकते हैं, SQL सर्वर को बता रहे हैं कि व्हीलफ्लैग मान कम से कम ध्वज के समान होना चाहिए (जो 0 और 1 को समाप्त करता है) ), और फिर पूरक जानकारी जोड़ना कि उसमें वह ध्वज भी होना चाहिए (इस प्रकार 5 को समाप्त करना)।
SELECT OrderID FROM dbo.CarOrders WHERE WheelFlag >= @Flag AND WheelFlag & @Flag = @Flag;
इस खंड का>=भाग स्पष्ट रूप से BITWISE भाग द्वारा कवर किया गया है, इसलिए यह वह जगह है जहां हम DRY का उल्लंघन करते हैं। लेकिन चूंकि हमने जो क्लॉज जोड़ा है, वह सारगर्भित है, बिटवाइज और ऑपरेशन को द्वितीयक खोज स्थिति में बदलने से अभी भी वही परिणाम मिलता है, और समग्र क्वेरी बेहतर प्रदर्शन देती है। हम उपरोक्त क्वेरी के हार्ड-कोडेड संस्करण की तलाश में एक समान इंडेक्स देखते हैं, और जबकि अनुमान और भी दूर हैं (कुछ ऐसा जिसे एक अलग मुद्दे के रूप में संबोधित किया जा सकता है), रीड अभी भी बिटवाइज़ और अकेले ऑपरेशन की तुलना में कम हैं:

हम यह भी देख सकते हैं कि अनुक्रमणिका के विरुद्ध एक फ़िल्टर का उपयोग किया जाता है, जिसे हमने केवल BITWISE AND संचालन का उपयोग करते समय नहीं देखा था:

निष्कर्ष
अपने आप को दोहराने से डरो मत। ऐसे समय होते हैं जब यह जानकारी अनुकूलक की मदद कर सकती है; भले ही यह प्रदर्शन में सुधार के लिए *जोड़ें* मानदंड के लिए पूरी तरह से सहज न हो, यह समझना महत्वपूर्ण है कि जब अतिरिक्त क्लॉज अंतिम परिणाम के लिए डेटा को कम करने में मदद करते हैं, बजाय ऑप्टिमाइज़र के लिए सटीक पंक्तियों को खोजने के लिए इसे "आसान" बनाने के लिए। अपने आप।