ClusterControl 1.7.3 क्लाउड एकीकरण में उल्लेखनीय सुधार के साथ आता है। क्लाउड पर एक MySQL और PostgreSQL प्रतिकृति क्लस्टर को तैनात करना संभव है, साथ ही स्वचालित रूप से क्लाउड इंस्टेंस लॉन्च करना और एक नया डेटाबेस नोड जोड़कर अपने डेटाबेस क्लस्टर को स्केल करना संभव है।
यह ब्लॉग पोस्ट दिखाता है कि एडब्ल्यूएस पर क्लस्टरकंट्रोल का उपयोग करके गैलेरा क्लस्टर को आसानी से कैसे तैनात किया जाए। यह नया फीचर क्लस्टरकंट्रोल कम्युनिटी एडिशन का हिस्सा है, जो फ्री डिप्लॉयमेंट और मॉनिटरिंग फीचर्स के साथ आता है। इसका मतलब है कि आप बिना किसी खर्च के इस सुविधा का लाभ उठा सकते हैं!
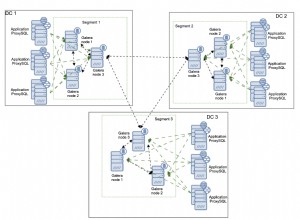
ClusterControl डेटाबेस क्लस्टर आर्किटेक्चर
निम्न आरेख हमारे समग्र डेटाबेस क्लस्टर आर्किटेक्चर को सारांशित करता है।
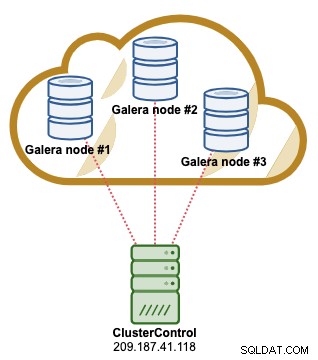
क्लस्टरकंट्रोल सर्वर AWS अवसंरचना के बाहर स्थित है, जो उचित दृश्यता की अनुमति देता है हमारे डेटाबेस क्लस्टर के लिए (फ्रैंकफर्ट में स्थित:ईयू-सेंट्रल -1)। ClusterControl सर्वर के पास एक समर्पित सार्वजनिक IP पता होना चाहिए। ऐसा इसलिए है क्योंकि डेटाबेस सर्वर और AWS सुरक्षा समूह पर ClusterControl द्वारा IP पता दिया जाएगा। गैलेरा डेटाबेस संस्करण जिसे हम परिनियोजित करने जा रहे हैं वह मारियाडीबी क्लस्टर 10.3 है, जो क्लस्टरकंट्रोल 1.7.3 का उपयोग कर रहा है।
एडब्ल्यूएस पर्यावरण तैयार करना
ClusterControl समर्थित क्लाउड प्लेटफ़ॉर्म, जैसे AWS, Google क्लाउड प्लेटफ़ॉर्म (GCP), और Microsoft Azure पर एक डेटाबेस क्लस्टर को तैनात करने में सक्षम है। पहली चीज जिसे हमें कॉन्फ़िगर करना है, वह है AWS एक्सेस कुंजियाँ प्राप्त करना ताकि ClusterControl को AWS सेवाओं के लिए प्रोग्रामेटिक अनुरोध करने की अनुमति मिल सके। आप रूट अकाउंट एक्सेस कुंजी का उपयोग कर सकते हैं, लेकिन यह अनुशंसित तरीका नहीं है। केवल इस उद्देश्य के लिए एक समर्पित पहचान और एक्सेस प्रबंधन (IAM) उपयोगकर्ता बनाना बेहतर है।
अपने एडब्ल्यूएस कंसोल में लॉगिन करें -> मेरी सुरक्षा साख -> उपयोगकर्ता -> उपयोगकर्ता जोड़ें . उपयोगकर्ता निर्दिष्ट करें और एक्सेस प्रकार के रूप में "प्रोग्रामेटिक एक्सेस" चुनें:
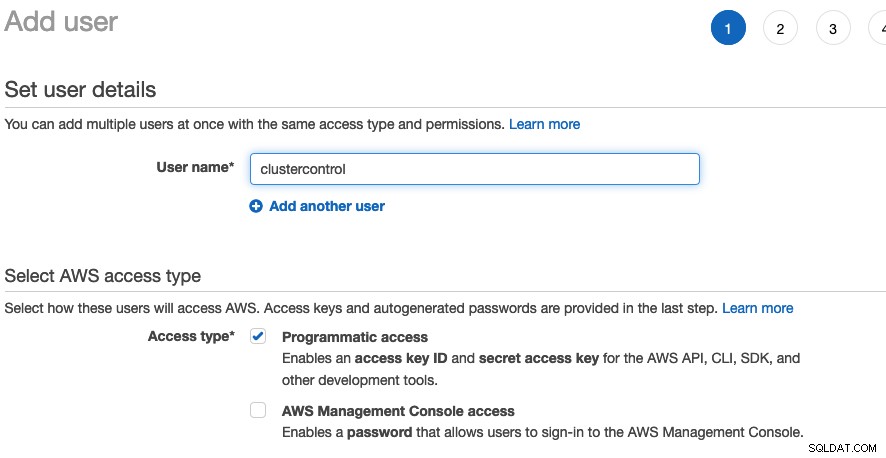
अगले पृष्ठ में, "बनाएं" पर क्लिक करके एक नया उपयोगकर्ता समूह बनाएं समूह" बटन और समूह का नाम "डेटाबेसऑटोमेशन" दें। निम्नलिखित एक्सेस प्रकार असाइन करें:
- AmazonEC2FullAccess
- अमेज़ॅनवीपीसीफुलएक्सेस
- AmazonS3FullAccess (केवल अगर आप डेटाबेस बैकअप को AWS S3 पर स्टोर करने की योजना बना रहे हैं)
डेटाबेसऑटोमेशन चेकबॉक्स पर टिक करें और "उपयोगकर्ता को समूह में जोड़ें" पर क्लिक करें:
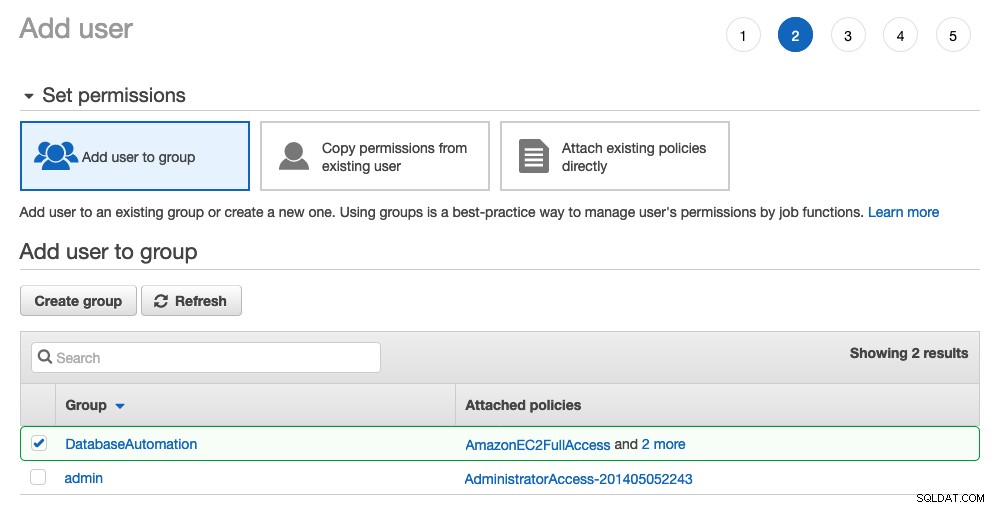
वैकल्पिक रूप से, आप अगले पृष्ठ पर टैग असाइन कर सकते हैं। अन्यथा, बस उपयोगकर्ता बनाने के लिए आगे बढ़ें। आपको दो सबसे महत्वपूर्ण चीजें मिलनी चाहिए, एक्सेस की आईडी और सीक्रेट एक्सेस की।
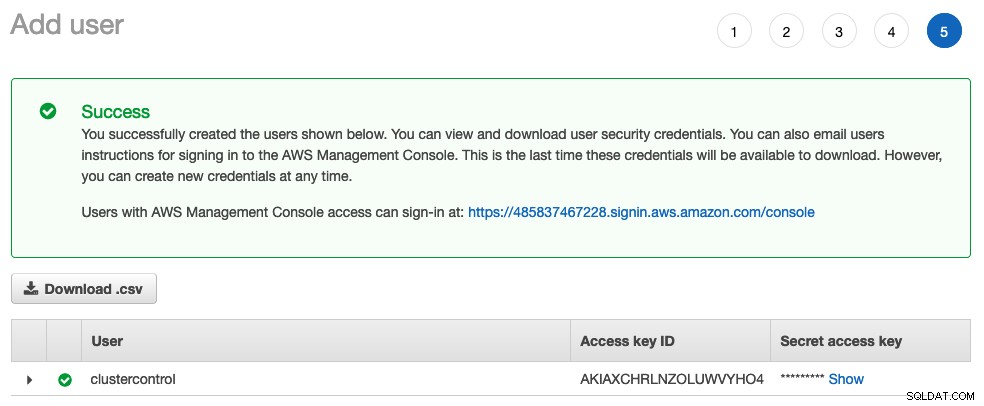
सीएसवी फ़ाइल डाउनलोड करें और उसे कहीं सुरक्षित रखें। अब हम क्लाउड पर परिनियोजन को स्वचालित करने के लिए अच्छे हैं।
संबंधित सर्वर पर ClusterControl स्थापित करें:
$ whoami
root
$ wget https://severalnines.com/downloads/cmon/install-cc
$ chmod 755 install-cc
$ ./install-ccस्थापना निर्देशों का पालन करें और https://192.168.0.11/clustercontrol पर जाएं और सुपर व्यवस्थापक उपयोगकर्ता और पासवर्ड बनाएं।
ClusterControl को क्लाउड पर स्वचालित परिनियोजन करने की अनुमति देने के लिए, किसी को एक मान्य AWS कुंजी आईडी और गुप्त के साथ चयनित क्षेत्र के लिए क्लाउड क्रेडेंशियल बनाना होगा। साइडबार -> एकीकरण -> क्लाउड प्रदाता -> अपना पहला क्लाउड क्रेडेंशियल जोड़ें -> Amazon वेब सेवाएं पर जाएं और आवश्यक विवरण दर्ज करें और फ्रैंकफर्ट को डिफ़ॉल्ट क्षेत्र के रूप में चुनें:
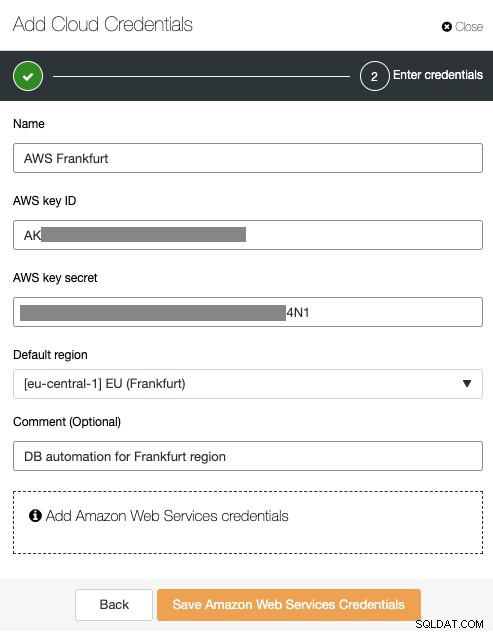
इस क्रेडेंशियल का उपयोग क्लस्टर नियंत्रण द्वारा क्लस्टर परिनियोजन और प्रबंधन को स्वचालित करने के लिए किया जाएगा। इस समय, हम अपना पहला क्लस्टर परिनियोजित करने के लिए तैयार हैं।
डेटाबेस क्लस्टर परिनियोजन
तैनाती -> क्लाउड में परिनियोजित करें -> MySQL गैलेरा -> मारियाडीबी 10.3 -> क्लस्टर कॉन्फ़िगर करें पर जाएं अगले पृष्ठ पर जाने के लिए।
क्लस्टर कॉन्फ़िगर करें अनुभाग के अंतर्गत, सुनिश्चित करें कि नोड्स की संख्या 3 है और क्लस्टर नाम और MySQL रूट पासवर्ड दें:
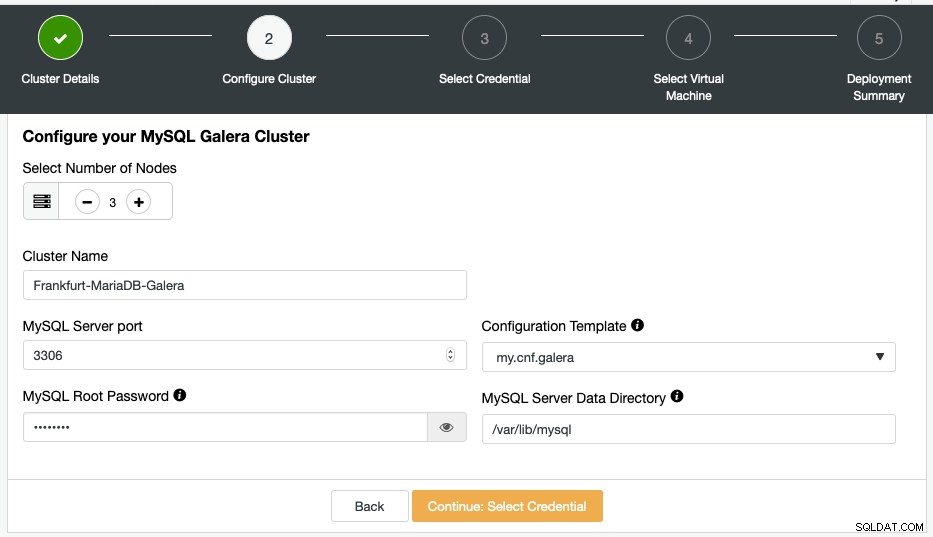
क्रेडेंशियल का चयन करें के तहत, "एडब्ल्यूएस फ्रैंकफर्ट" नामक एक क्रेडेंशियल चुनें और "वर्चुअल मशीन का चयन करें" पर क्लिक करके अगले पृष्ठ पर जाएं। पसंदीदा ऑपरेटिंग सिस्टम और इंस्टेंस आकार चुनें। हमारे बुनियादी ढांचे को एक निजी क्लाउड के अंदर चलाने की अनुशंसा की जाती है ताकि हम अपने क्लाउड इंस्टेंस के लिए एक समर्पित आंतरिक आईपी पता प्राप्त कर सकें और मेजबान सीधे सार्वजनिक नेटवर्क के संपर्क में न आएं। वर्चुअल प्राइवेट क्लाउड (वीपीसी) फ़ील्ड के आगे "नया जोड़ें" बटन पर क्लिक करें और इस नेटवर्क को 10.10.0.0/16 का सबनेट दें:
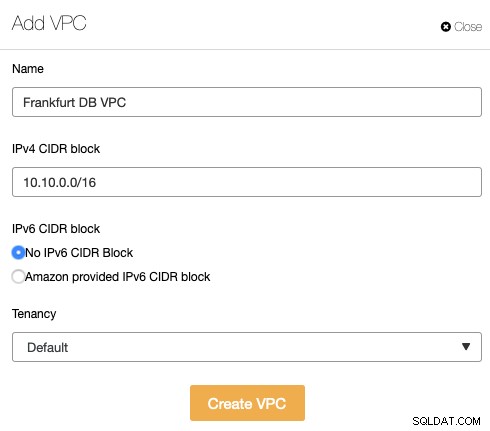
हमने जो वीपीसी बनाया है वह एक निजी क्लाउड है और इसमें इंटरनेट कनेक्टिविटी नहीं है। क्लस्टर कंट्रोल के लिए बाहरी एडब्ल्यूएस नेटवर्क से मेजबानों को तैनात और प्रबंधित करने में सक्षम होने के लिए, हमें इस वीपीसी को इंटरनेट कनेक्टिविटी की अनुमति देनी होगी। ऐसा करने के लिए, हमें निम्नलिखित कार्य करने होंगे:
- इंटरनेट गेटवे बनाएं
- रूट टेबल में बाहरी रूटिंग जोड़ें
- सबनेट को रूट टेबल से संबद्ध करें
इंटरनेट गेटवे बनाने के लिए, AWS प्रबंधन कंसोल -> VPC -> इंटरनेट गेटवे -> इंटरनेट गेटवे बनाएं -> में लॉगिन करें इस गेटवे के लिए एक नाम निर्दिष्ट करें . फिर सूची से निर्मित गेटवे का चयन करें और क्रियाएँ -> VPC से संलग्न करें -> ड्रॉपडाउन सूची के लिए VPC चुनें -> संलग्न करें पर जाएं। . अब हमने निजी क्लाउड के लिए एक इंटरनेट गेटवे संलग्न किया है। हालांकि, हमें इस इंटरनेट गेटवे के माध्यम से सभी बाहरी अनुरोधों को अग्रेषित करने के लिए नेटवर्क को कॉन्फ़िगर करने की आवश्यकता है। इसलिए, हमें रूट टेबल में एक डिफ़ॉल्ट रूट जोड़ना होगा। VPC -> रूट टेबल -> रूट टेबल चुनें -> रूट संपादित करें पर जाएं और गंतव्य नेटवर्क, 0.0.0.0/0 और लक्ष्य (बनाई गई इंटरनेट गेटवे आईडी) को नीचे बताए अनुसार निर्दिष्ट करें:
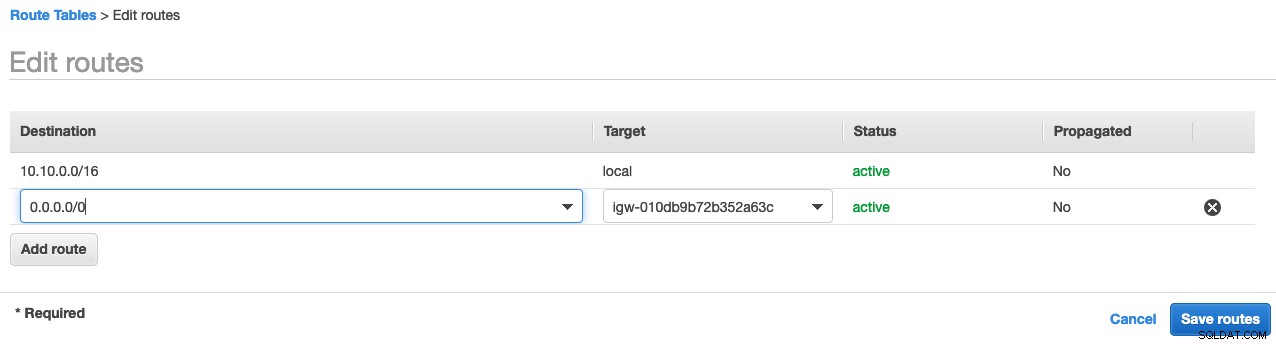
फिर, हमें डीबी सबनेट को इस नेटवर्क से जोड़ना होगा ताकि यह इस नेटवर्क के अंदर बनाए गए सभी इंस्टेंस को उस डिफ़ॉल्ट रूट पर असाइन करे जो हमने पहले बनाया है, रूट टेबल चुनें -> सबनेट एसोसिएशन संपादित करें -> डीबी सबनेट असाइन करें , जैसा कि नीचे दिखाया गया है:
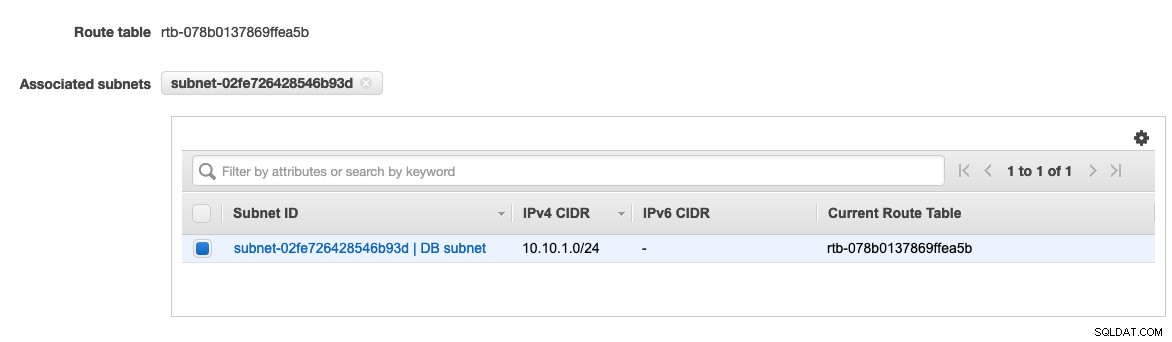
VPC अब ClusterControl द्वारा परिनियोजन के लिए उपयोग करने के लिए तैयार है।
बन जाने के बाद, ड्रॉपडाउन से निर्मित VPC चुनें। SSH कुंजी के लिए, हम ClusterControl से इसे स्वतः उत्पन्न करने के लिए कहेंगे:
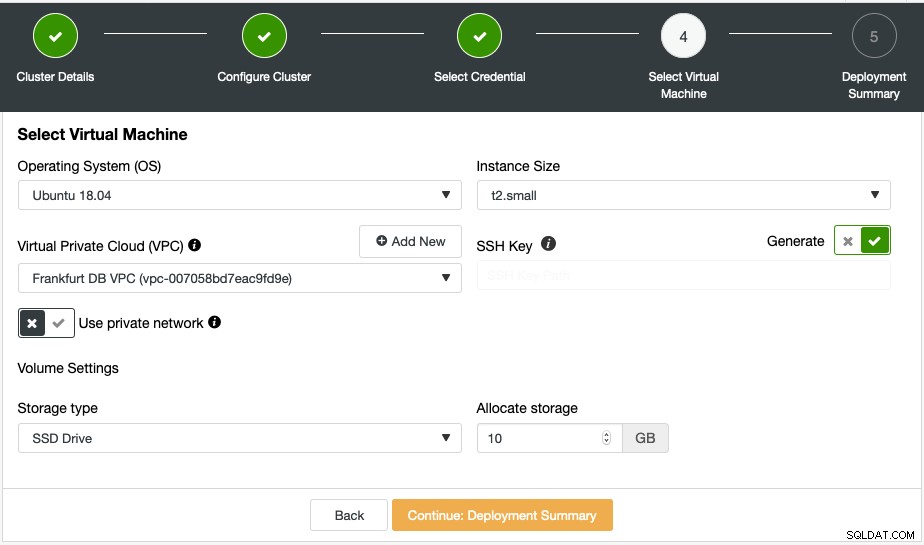
उत्पन्न SSH कुंजी /var/lib/cmon/autogenerated_ssh_keys/s9s/ निर्देशिका के अंतर्गत ClusterControl सर्वर के अंदर स्थित होगी।
"परिनियोजन सारांश" पर क्लिक करें। इस पृष्ठ में, हमें VPC से डेटाबेस क्लस्टर में एक सबनेट असाइन करना होगा। चूंकि यह एक नया वीपीसी है, इसमें कोई सबनेट नहीं है और हमें एक नया सबनेट बनाना होगा। "नया सबनेट जोड़ें" बटन पर क्लिक करें और 10.10.1.0/24 को हमारे डेटाबेस क्लस्टर के लिए नेटवर्क के रूप में असाइन करें:
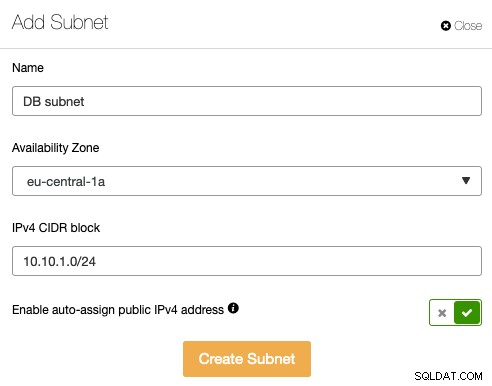
अंत में, टेक्स्टबॉक्स में क्रिएट सबनेट चुनें और "डिप्लॉय क्लस्टर" पर क्लिक करें:
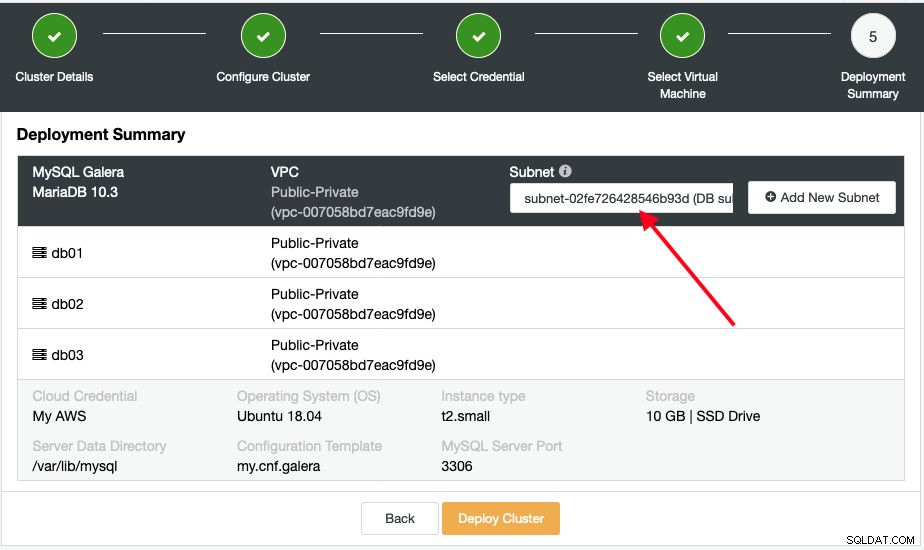
आप गतिविधि के अंतर्गत कार्य प्रगति की निगरानी कर सकते हैं -> नौकरियां -> क्लस्टर बनाएं . वास्तविक इंस्टॉलेशन चरण शुरू होने से पहले, ClusterControl आवश्यक प्री-इंस्टॉलेशन चरण निष्पादित करेगा जैसे क्लाउड इंस्टेंस बनाना, सुरक्षा समूह, SSH कुंजी बनाना आदि।
एक बार क्लस्टर तैयार हो जाने के बाद, आपको क्लस्टरकंट्रोल डैशबोर्ड में निम्नलिखित क्लस्टर देखना चाहिए:

हमारा क्लस्टर परिनियोजन अब पूरा हो गया है।
AWS डेटाबेस परिनियोजन पोस्ट करें
हम अपने डेटा को क्लस्टर में लोड करना शुरू कर सकते हैं या आपके एप्लिकेशन उपयोग के लिए एक नया डेटाबेस बना सकते हैं। कनेक्ट करने के लिए, बस अपने एप्लिकेशन या क्लाइंट को डेटाबेस सर्वर में से किसी एक के निजी या सार्वजनिक आईपी पते से कनेक्ट करने का निर्देश दें। आप यह जानकारी Nodes पेज पर जाकर प्राप्त कर सकते हैं, जैसा कि निम्न स्क्रीनशॉट में दिखाया गया है:
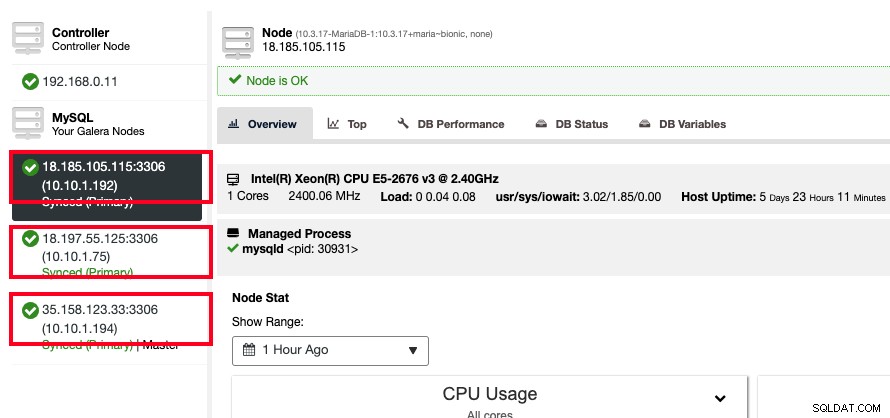
यदि आप डेटाबेस नोड्स को सीधे एक्सेस करना चाहते हैं, तो आप नोड क्रियाएँ -> SSH कंसोल पर ClusterControl वेब-एसएसएच मॉड्यूल का उपयोग कर सकते हैं। , जो आपको एसएसएच क्लाइंट के माध्यम से कनेक्ट होने जैसा समान अनुभव देता है।
डेटाबेस नोड जोड़कर क्लस्टर को बढ़ाने के लिए, आप बस क्लस्टर एक्शन (सर्वर स्टैक आइकन) -> नोड जोड़ें -> एक नए क्लाउड इंस्टेंस पर एक डीबी नोड जोड़ें पर जा सकते हैं। और आपको निम्नलिखित संवाद के साथ प्रस्तुत किया जाएगा:
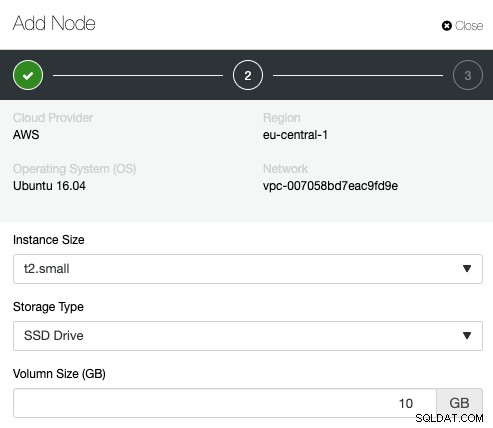
बस परिनियोजन विज़ार्ड का पालन करें और तदनुसार अपना नया उदाहरण कॉन्फ़िगर करें। एक बार इंस्टेंस बन जाने के बाद, ClusterControl नोड को स्वचालित रूप से क्लस्टर में स्थापित, कॉन्फ़िगर और जोड़ देगा।
अभी के लिए बस इतना ही, दोस्तों। क्लाउड में हैप्पी क्लस्टरिंग!