उच्च उपलब्धता इन दिनों बहुत जरूरी है क्योंकि अधिकांश संगठन स्वयं को अपना डेटा खोने की अनुमति नहीं दे सकते हैं। उच्च उपलब्धता, हालांकि, हमेशा एक मूल्य टैग के साथ आता है (जो बहुत भिन्न हो सकता है।) कोई भी सेटअप जिसके लिए लगभग-तत्काल कार्रवाई की आवश्यकता होती है, आमतौर पर एक महंगे वातावरण की आवश्यकता होती है जो उत्पादन सेटअप को सटीक रूप से प्रतिबिंबित करेगा। लेकिन, ऐसे अन्य विकल्प हैं जो कम खर्चीले हो सकते हैं। हो सकता है कि ये आपदा रिकवरी क्लस्टर में तत्काल स्विच करने की अनुमति न दें, लेकिन फिर भी वे व्यवसाय की निरंतरता की अनुमति देंगे (और बजट को खत्म नहीं करेंगे।)
इस प्रकार के सेटअप का एक उदाहरण "कोल्ड-स्टैंडबाय" DR वातावरण है। यह आपको अपने खर्चों को कम करने की अनुमति देता है, जबकि अभी भी किसी बाहरी स्थान पर एक नया वातावरण तैयार करने में सक्षम होने के कारण आपदा आती है। इस ब्लॉग पोस्ट में हम प्रदर्शित करेंगे कि ऐसा सेटअप कैसे बनाया जाता है।
प्रारंभिक सेटअप
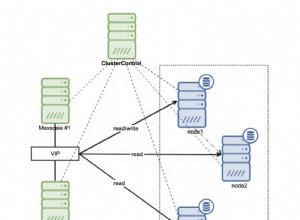
मान लें कि हमारे पास अपने डेटासेंटर में काफी मानक मास्टर / स्लेव MySQL प्रतिकृति सेटअप है। यह वर्चुअल आईपी हैंडलिंग के लिए ProxySQL और Keepalived के साथ अत्यधिक उपलब्ध सेटअप है। मुख्य जोखिम यह है कि डेटासेंटर अनुपलब्ध हो जाएगा। यह एक छोटा डीसी है, शायद यह केवल एक आईएसपी है जिसमें कोई बीजीपी नहीं है। और इस स्थिति में, हम यह मानेंगे कि यदि डेटाबेस को वापस लाने में घंटों लगेंगे तो यह ठीक है जब तक कि इसे वापस लाना संभव है।
इस क्लस्टर को परिनियोजित करने के लिए हमने ClusterControl का उपयोग किया, जिसे आप मुफ्त में डाउनलोड कर सकते हैं। हमारे DR परिवेश के लिए हम EC2 का उपयोग करेंगे (लेकिन यह कोई अन्य क्लाउड प्रदाता भी हो सकता है।)
चुनौती
हमें जिस मुख्य मुद्दे से निपटना है, वह यह है कि हमें यह कैसे सुनिश्चित करना चाहिए कि आपदा रिकवरी वातावरण में हमारे डेटाबेस को पुनर्स्थापित करने के लिए हमारे पास एक नया डेटा है? बेशक, आदर्श रूप से हमारे पास ईसी 2 में एक प्रतिकृति दास होगा और चल रहा है ... लेकिन फिर हमें इसके लिए भुगतान करना होगा। अगर हम बजट पर तंग हैं, तो हम बैकअप के साथ इसे पाने की कोशिश कर सकते हैं। यह सही समाधान नहीं है, क्योंकि सबसे खराब स्थिति में, हम कभी भी सभी डेटा को पुनर्प्राप्त करने में सक्षम नहीं होंगे।
"सबसे खराब स्थिति" से हमारा तात्पर्य ऐसी स्थिति से है जिसमें हमारे पास मूल डेटाबेस सर्वर तक पहुंच नहीं होगी। अगर हम उन तक पहुंच पाते, तो डेटा नष्ट नहीं होता।
समाधान
डेटा के नष्ट होने की संभावना को कम करने के लिए हम एक बैकअप शेड्यूल सेट करने के लिए ClusterControl का उपयोग करने जा रहे हैं। हम क्लाउड पर बैकअप अपलोड करने के लिए क्लस्टरकंट्रोल फीचर का भी उपयोग करेंगे। यदि डेटासेंटर उपलब्ध नहीं होगा, तो हम आशा कर सकते हैं कि हमारे द्वारा चुना गया क्लाउड प्रदाता उपलब्ध होगा।
ClusterControl में बैकअप शेड्यूल सेट करना
सबसे पहले, हमें अपने क्लाउड क्रेडेंशियल के साथ ClusterControl को कॉन्फ़िगर करना होगा।
हम बाईं ओर के मेनू से "एकीकरण" का उपयोग करके ऐसा कर सकते हैं।
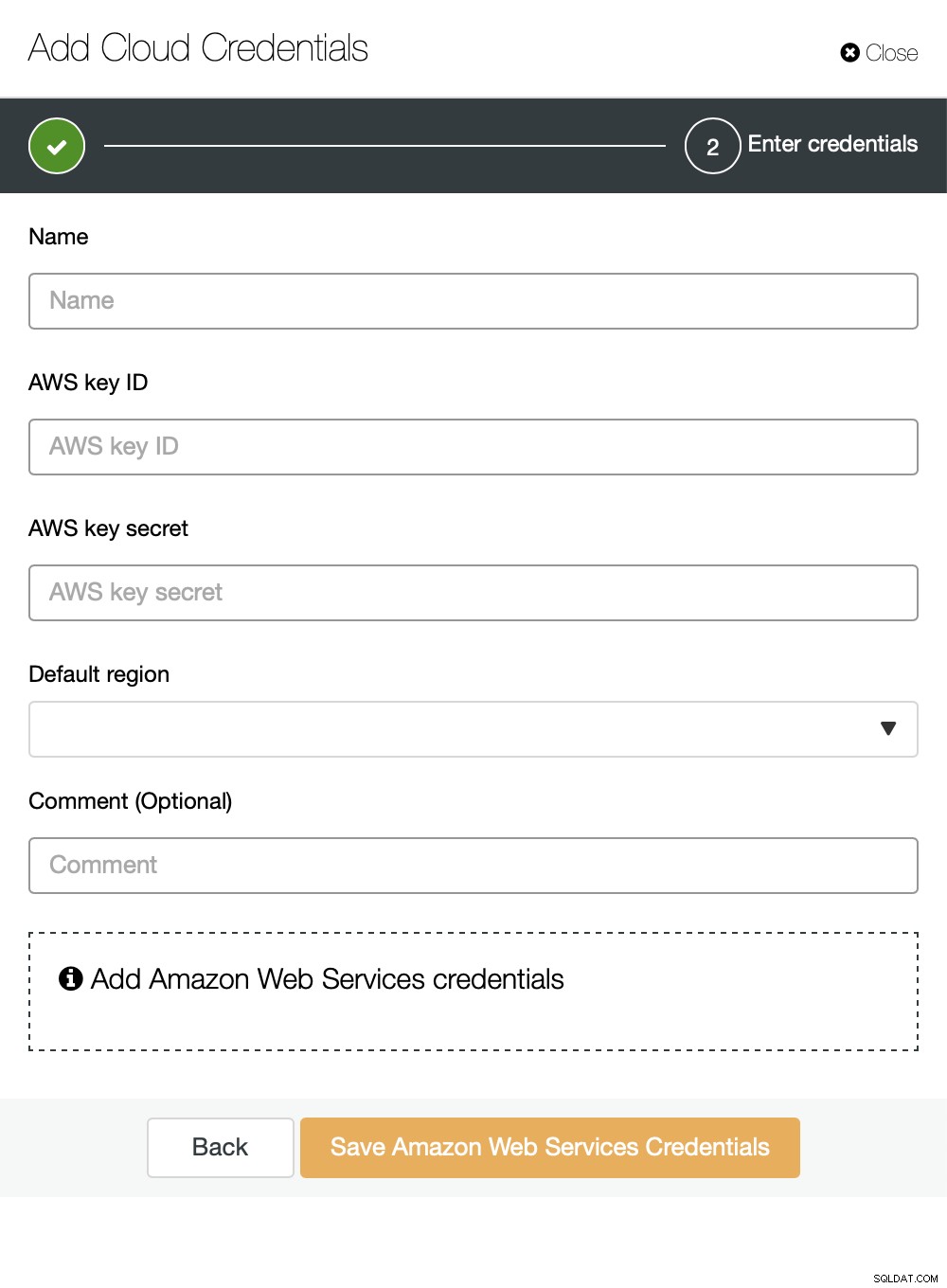
आप क्लाउड के रूप में Amazon Web Services, Google Cloud या Microsoft Azure को चुन सकते हैं आप चाहते हैं कि ClusterControl बैकअप अपलोड करे। हम AWS के साथ आगे बढ़ेंगे जहां ClusterControl बैकअप स्टोर करने के लिए S3 का उपयोग करेगा।
फिर हमें की आईडी और की सीक्रेट पास करने की जरूरत है, डिफ़ॉल्ट क्षेत्र चुनें और क्रेडेंशियल के इस सेट के लिए एक नाम चुनें।
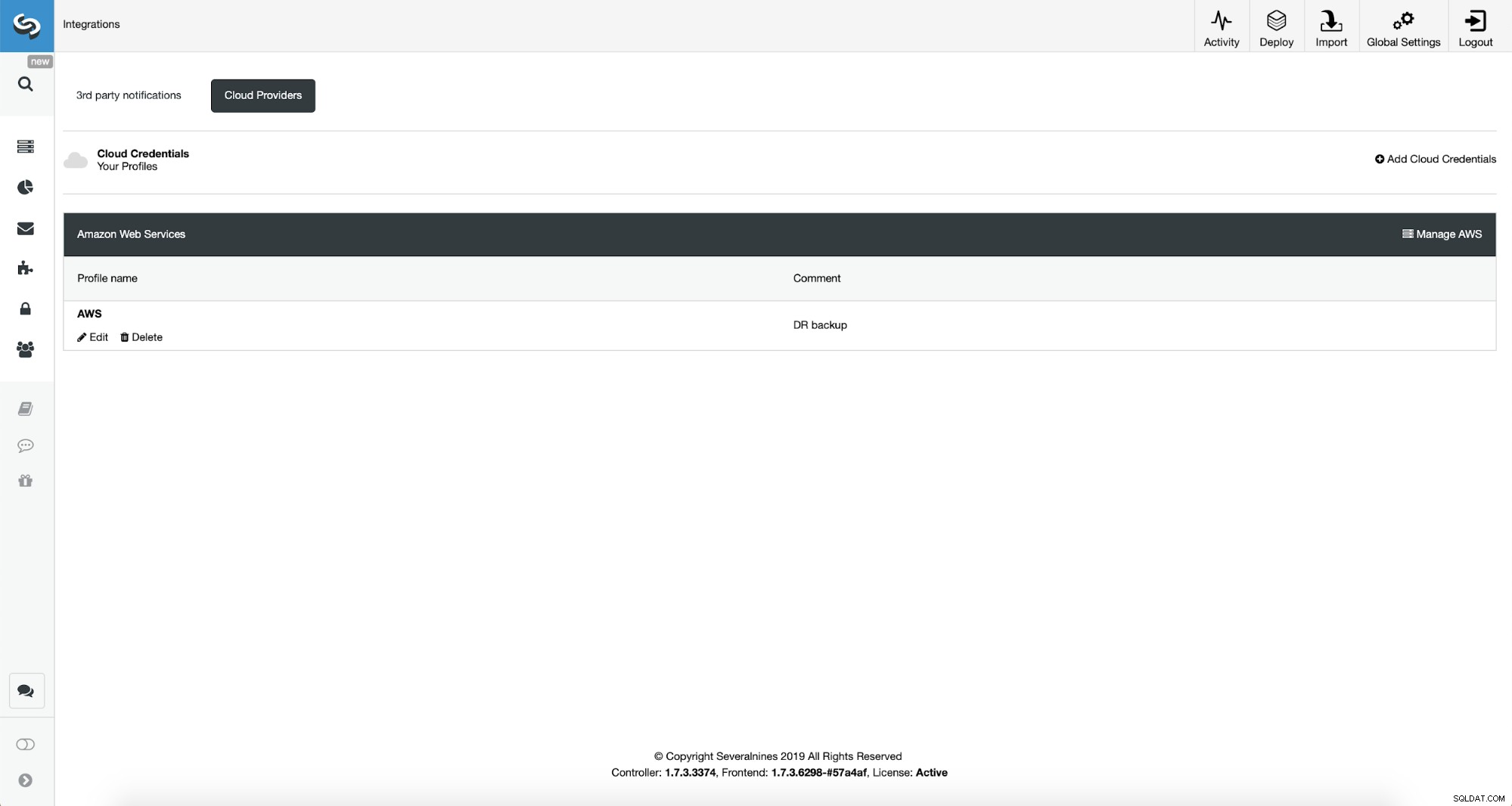
एक बार यह हो जाने के बाद, हम उन क्रेडेंशियल्स को देख सकते हैं जिन्हें हमने अभी-अभी जोड़ा है। क्लस्टर नियंत्रण।
अब, हम बैकअप शेड्यूल सेट करने के साथ आगे बढ़ेंगे।
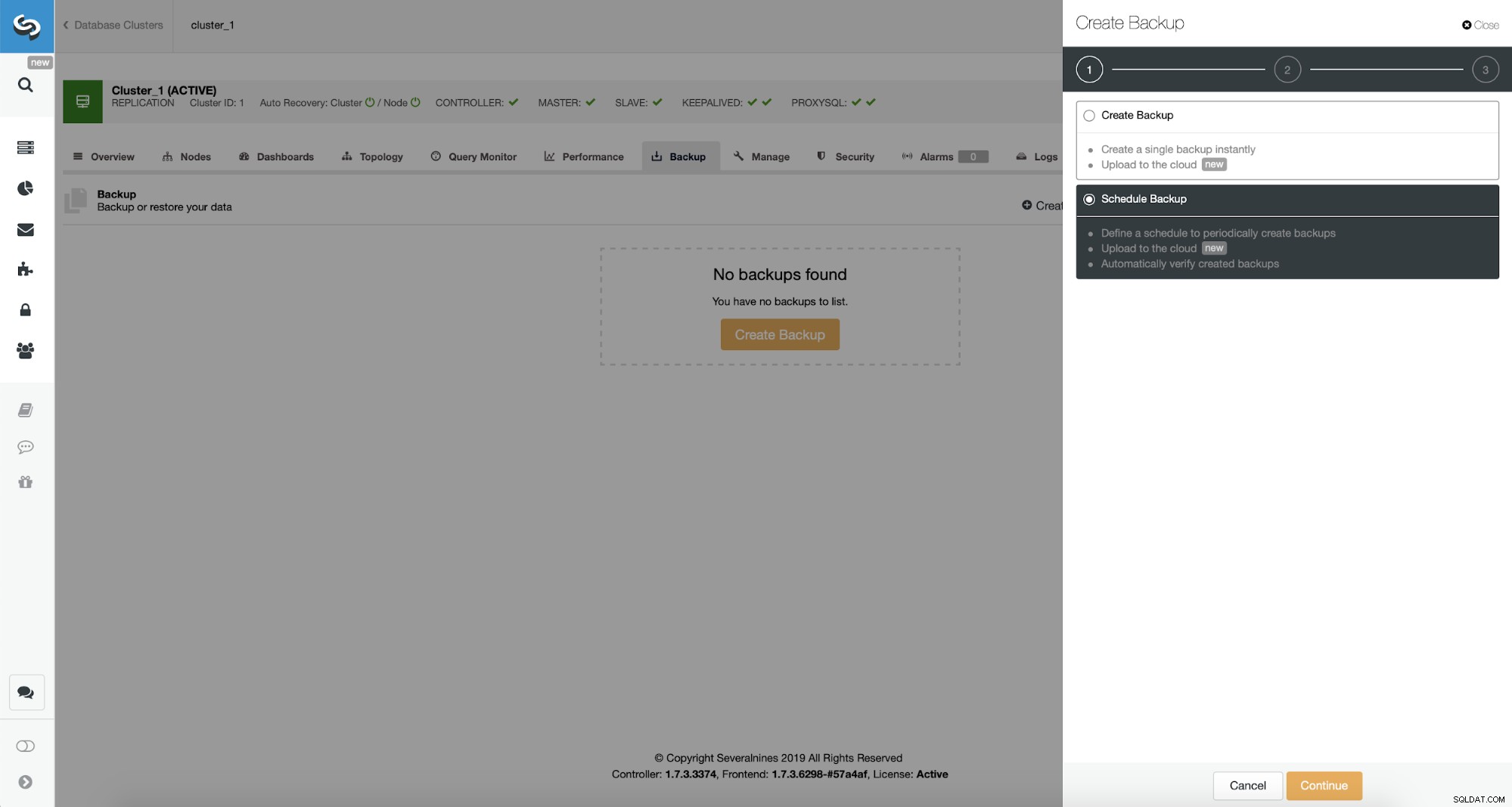
ClusterControl आपको या तो तुरंत बैकअप बनाने या इसे शेड्यूल करने की अनुमति देता है। हम दूसरे विकल्प के साथ जाएंगे। हम निम्नलिखित शेड्यूल बनाना चाहते हैं:
- प्रति दिन एक बार पूर्ण बैकअप बनाया गया
- इंक्रीमेंटल बैकअप हर 10 मिनट में बनाया जाता है।
यहाँ विचार इस प्रकार है। सबसे खराब स्थिति में हम केवल 10 मिनट का ट्रैफिक खो देंगे। यदि डेटासेंटर बाहर से अनुपलब्ध हो जाएगा, लेकिन यह आंतरिक रूप से काम करेगा, तो हम 10 मिनट प्रतीक्षा करके किसी भी डेटा हानि से बचने की कोशिश कर सकते हैं, कुछ लैपटॉप पर नवीनतम वृद्धिशील बैकअप की प्रतिलिपि बना सकते हैं और फिर हम इसे मैन्युअल रूप से फोन टेदरिंग का उपयोग करके अपने डीआर डेटाबेस की ओर भेज सकते हैं। और आईएसपी विफलता के आसपास जाने के लिए एक सेलुलर कनेक्शन। यदि हम कुछ समय के लिए पुराने डेटासेंटर से डेटा प्राप्त करने में सक्षम नहीं होंगे, तो इसका उद्देश्य उन लेन-देन की मात्रा को कम करना है जिन्हें हमें मैन्युअल रूप से DR डेटाबेस में मर्ज करना होगा।
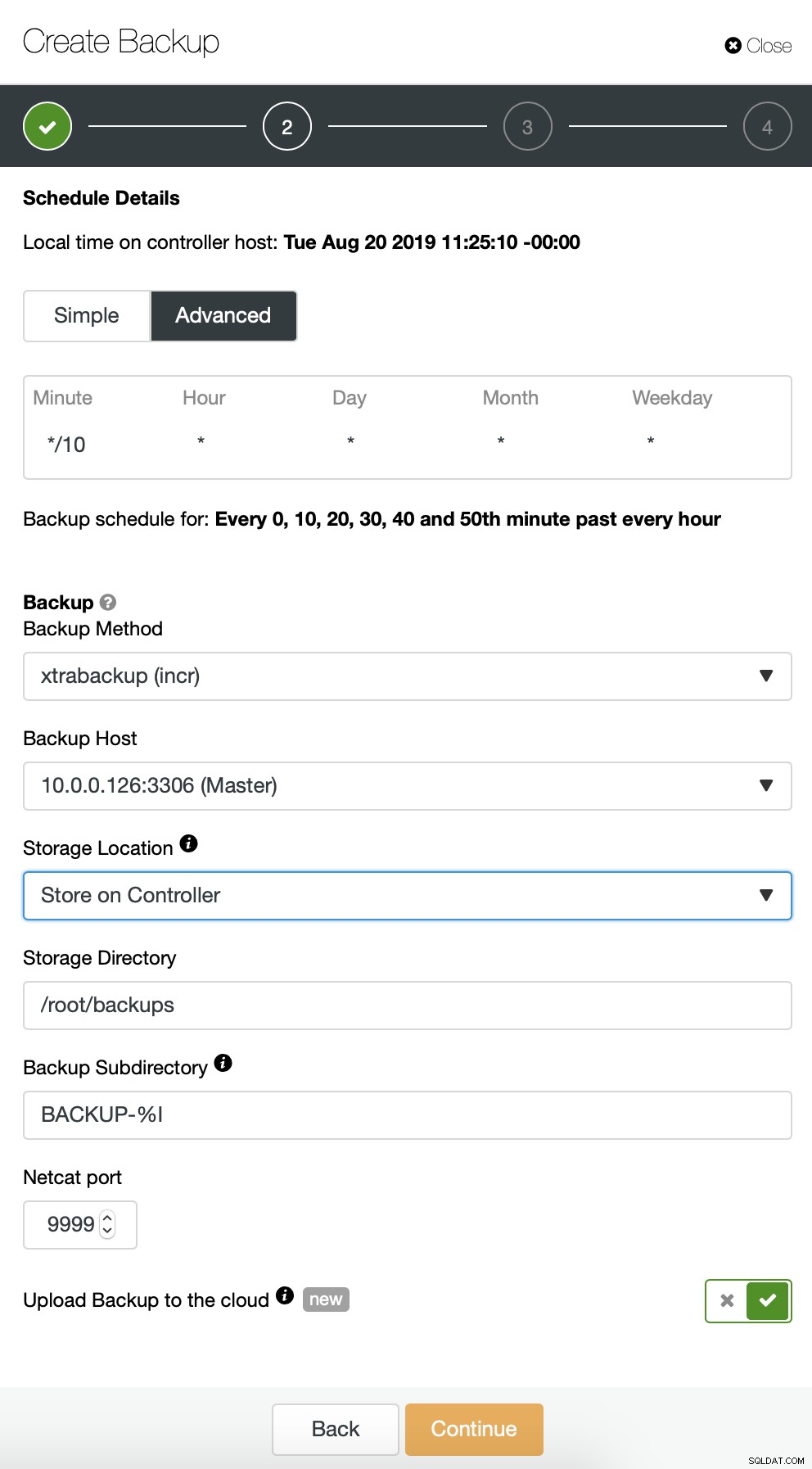
हम पूर्ण बैकअप के साथ प्रारंभ करते हैं जो प्रतिदिन 2:00 बजे होगा। हम बैकअप लेने के लिए मास्टर का उपयोग करेंगे, हम इसे/रूट/बैकअप/निर्देशिका के अंतर्गत नियंत्रक पर संग्रहीत करेंगे। हम "क्लाउड पर बैकअप अपलोड करें" विकल्प भी सक्षम करेंगे।
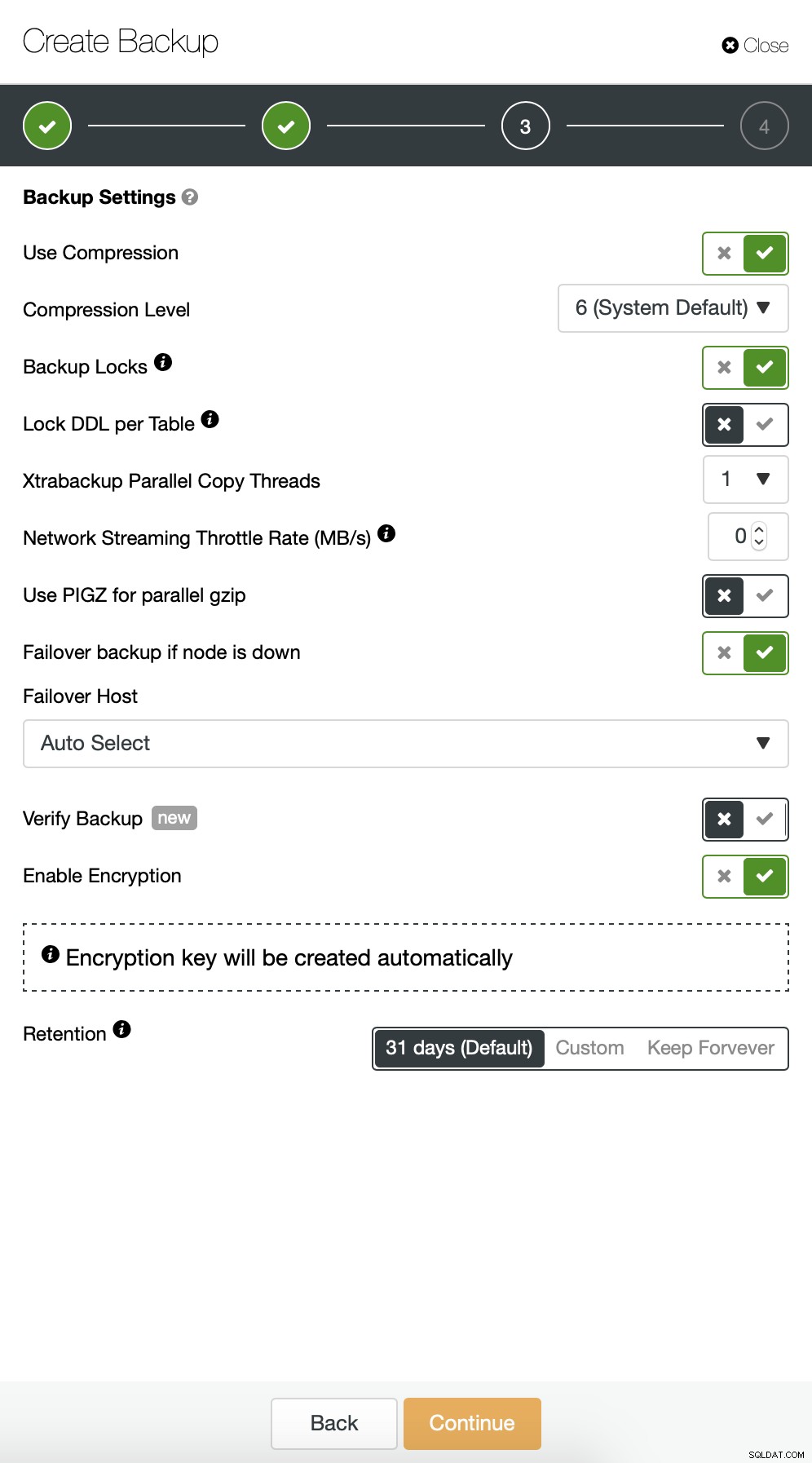
अगला, हम डिफ़ॉल्ट कॉन्फ़िगरेशन में कुछ बदलाव करना चाहते हैं। हमने स्वचालित रूप से चयनित फ़ेलओवर होस्ट के साथ जाने का निर्णय लिया (यदि हमारा मास्टर अनुपलब्ध होगा, तो ClusterControl किसी अन्य नोड का उपयोग करेगा जो उपलब्ध है)। हम एन्क्रिप्शन को भी सक्षम करना चाहते थे क्योंकि हम नेटवर्क पर अपना बैकअप भेजेंगे।
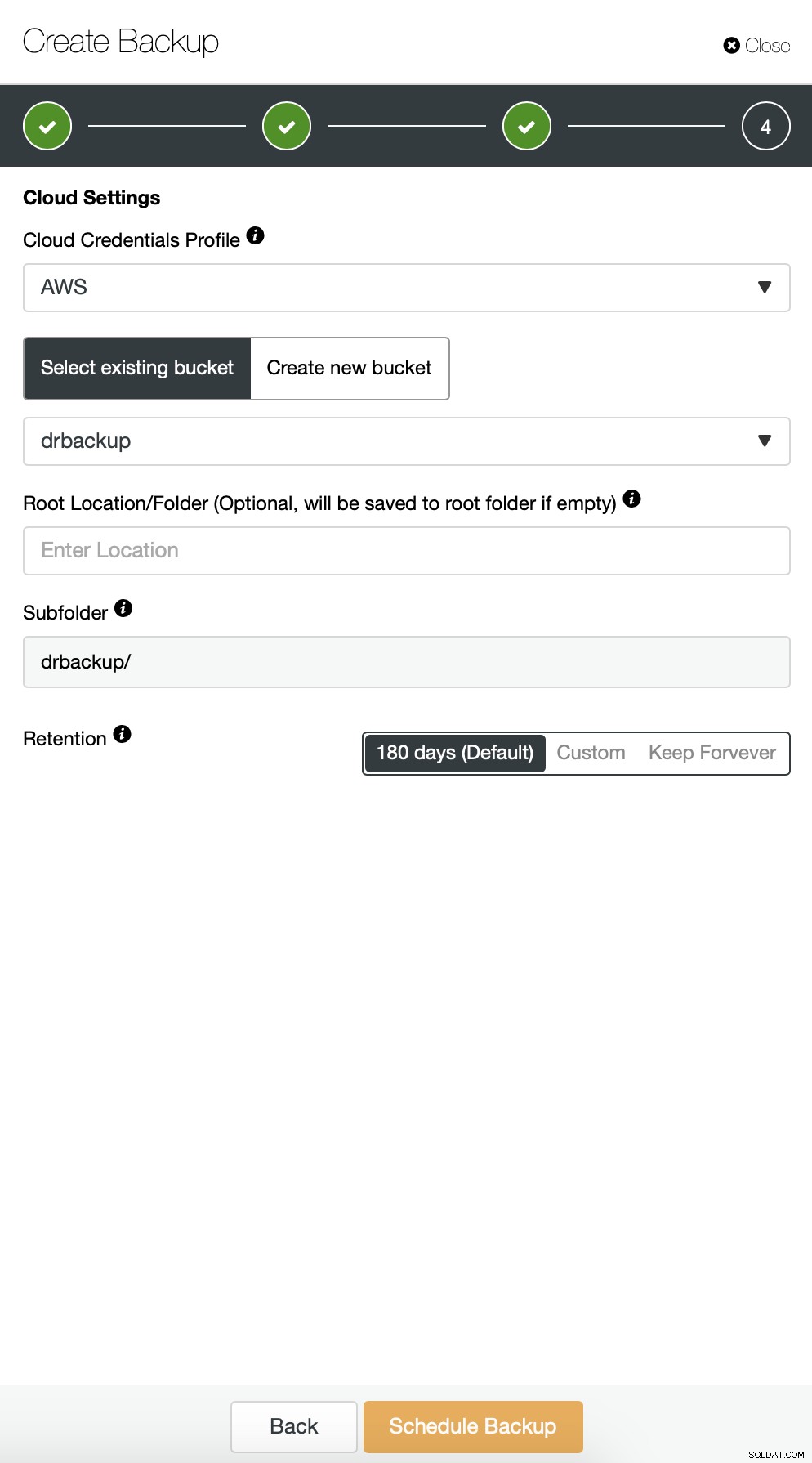
फिर हमें क्रेडेंशियल चुनना होगा, मौजूदा S3 बकेट का चयन करना होगा या एक बनाना होगा यदि आवश्यक हो तो नया।
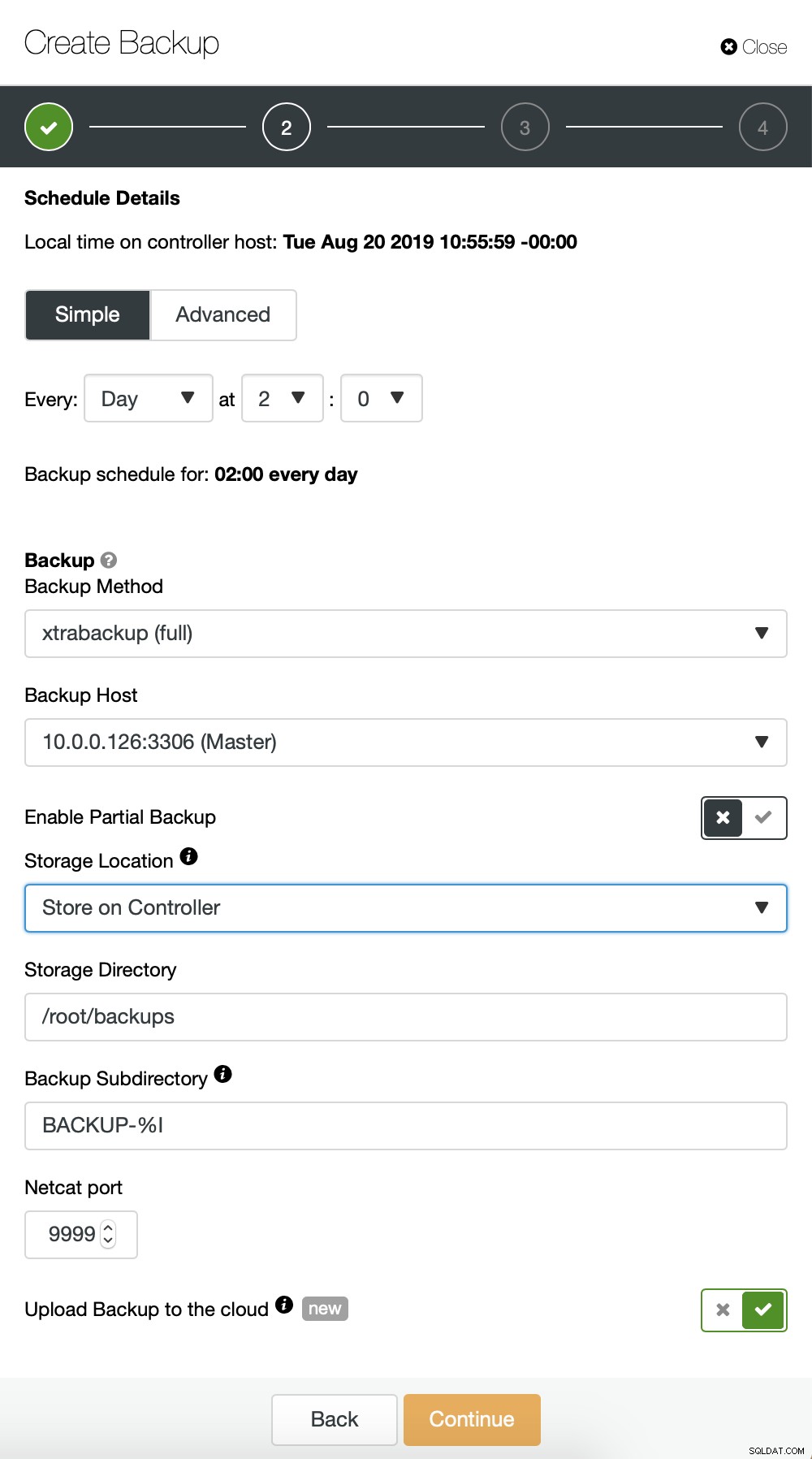
हम मूल रूप से वृद्धिशील बैकअप के लिए प्रक्रिया को दोहरा रहे हैं, इस बार हमने उपयोग किया हर 10 मिनट में बैकअप चलाने के लिए "उन्नत" संवाद।
बाकी सेटिंग्स समान हैं, हम S3 बकेट का पुन:उपयोग भी कर सकते हैं।
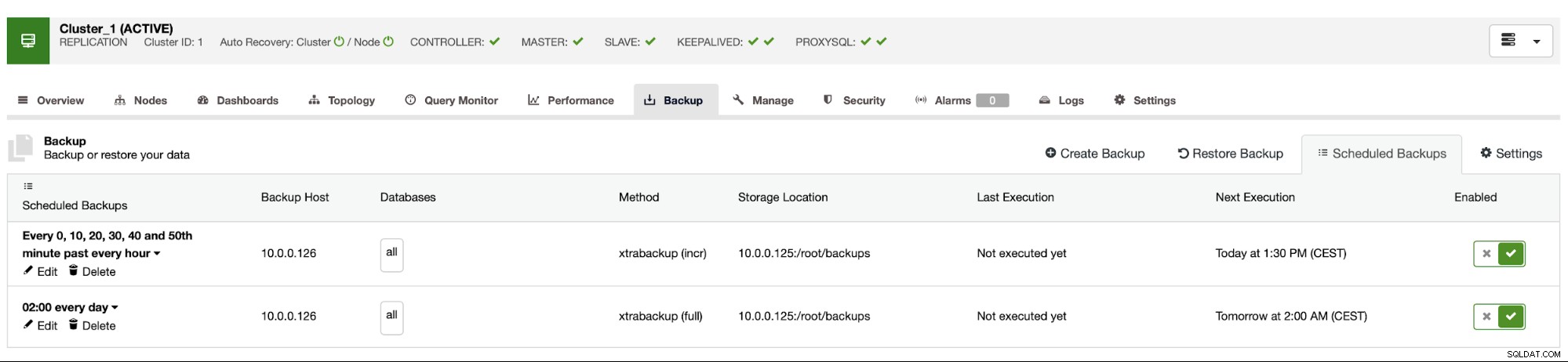
बैकअप शेड्यूल ऊपर जैसा दिखता है। हमें मैन्युअल रूप से पूर्ण बैकअप प्रारंभ करने की आवश्यकता नहीं है, क्लस्टरकंट्रोल शेड्यूल के अनुसार वृद्धिशील बैकअप चलाएगा और यदि यह पता चलता है कि कोई पूर्ण बैकअप उपलब्ध नहीं है, तो यह वृद्धिशील के बजाय पूर्ण बैकअप चलाएगा।
इस तरह के सेटअप के साथ हम सुरक्षित रूप से कह सकते हैं कि हम 10 मिनट की ग्रैन्युलैरिटी के साथ किसी भी बाहरी सिस्टम पर डेटा पुनर्प्राप्त कर सकते हैं।
मैन्युअल बैकअप पुनर्स्थापना
यदि ऐसा होता है कि आपको डिजास्टर रिकवरी इंस्टेंस पर बैकअप को पुनर्स्थापित करने की आवश्यकता होगी, तो आपको कुछ कदम उठाने होंगे। हम समय-समय पर इस प्रक्रिया का परीक्षण करने की दृढ़ता से अनुशंसा करते हैं, यह सुनिश्चित करते हुए कि यह सही ढंग से काम करती है और आप इसे निष्पादित करने में कुशल हैं।
सबसे पहले, हमें अपने लक्षित सर्वर पर AWS कमांड लाइन टूल इंस्टॉल करना होगा:
example@sqldat.com:~# apt install python3-pip
example@sqldat.com:~# pip3 install awscli --upgrade --userफिर हमें इसे उचित क्रेडेंशियल के साथ कॉन्फ़िगर करना होगा:
example@sqldat.com:~# ~/.local/bin/aws configure
AWS Access Key ID [None]: yourkeyID
AWS Secret Access Key [None]: yourkeySecret
Default region name [None]: us-west-1
Default output format [None]: jsonअब हम परीक्षण कर सकते हैं कि क्या हमारे पास हमारे S3 बकेट में डेटा तक पहुंच है:
example@sqldat.com:~# ~/.local/bin/aws s3 ls s3://drbackup/
PRE BACKUP-1/
PRE BACKUP-2/
PRE BACKUP-3/
PRE BACKUP-4/
PRE BACKUP-5/
PRE BACKUP-6/
PRE BACKUP-7/अब, हमें डेटा डाउनलोड करना होगा। हम बैकअप के लिए निर्देशिका बनाएंगे - याद रखें, हमें पूरा बैकअप सेट डाउनलोड करना होगा - एक पूर्ण बैकअप से लेकर अंतिम वृद्धिशील तक जिसे हम लागू करना चाहते हैं।
example@sqldat.com:~# mkdir backups
example@sqldat.com:~# cd backups/अब दो विकल्प हैं। हम या तो एक-एक करके बैकअप डाउनलोड कर सकते हैं:
example@sqldat.com:~# ~/.local/bin/aws s3 cp s3://drbackup/BACKUP-1/ BACKUP-1 --recursive
download: s3://drbackup/BACKUP-1/cmon_backup.metadata to BACKUP-1/cmon_backup.metadata
Completed 30.4 MiB/36.2 MiB (4.9 MiB/s) with 1 file(s) remaining
download: s3://drbackup/BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256 to BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256
example@sqldat.com:~# ~/.local/bin/aws s3 cp s3://drbackup/BACKUP-2/ BACKUP-2 --recursive
download: s3://drbackup/BACKUP-2/cmon_backup.metadata to BACKUP-2/cmon_backup.metadata
download: s3://drbackup/BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256 to BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256हम भी कर सकते हैं, खासकर यदि आपके पास सख्त रोटेशन शेड्यूल है, तो बकेट की सभी सामग्री को हमारे पास सर्वर पर स्थानीय रूप से सिंक करें:
example@sqldat.com:~/backups# ~/.local/bin/aws s3 sync s3://drbackup/ .
download: s3://drbackup/BACKUP-2/cmon_backup.metadata to BACKUP-2/cmon_backup.metadata
download: s3://drbackup/BACKUP-4/cmon_backup.metadata to BACKUP-4/cmon_backup.metadata
download: s3://drbackup/BACKUP-3/cmon_backup.metadata to BACKUP-3/cmon_backup.metadata
download: s3://drbackup/BACKUP-6/cmon_backup.metadata to BACKUP-6/cmon_backup.metadata
download: s3://drbackup/BACKUP-5/cmon_backup.metadata to BACKUP-5/cmon_backup.metadata
download: s3://drbackup/BACKUP-7/cmon_backup.metadata to BACKUP-7/cmon_backup.metadata
download: s3://drbackup/BACKUP-3/backup-incr-2019-08-20_115005.xbstream.gz.aes256 to BACKUP-3/backup-incr-2019-08-20_115005.xbstream.gz.aes256
download: s3://drbackup/BACKUP-1/cmon_backup.metadata to BACKUP-1/cmon_backup.metadata
download: s3://drbackup/BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256 to BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256
download: s3://drbackup/BACKUP-7/backup-incr-2019-08-20_123008.xbstream.gz.aes256 to BACKUP-7/backup-incr-2019-08-20_123008.xbstream.gz.aes256
download: s3://drbackup/BACKUP-6/backup-incr-2019-08-20_122008.xbstream.gz.aes256 to BACKUP-6/backup-incr-2019-08-20_122008.xbstream.gz.aes256
download: s3://drbackup/BACKUP-5/backup-incr-2019-08-20_121007.xbstream.gz.aes256 to BACKUP-5/backup-incr-2019-08-20_121007.xbstream.gz.aes256
download: s3://drbackup/BACKUP-4/backup-incr-2019-08-20_120007.xbstream.gz.aes256 to BACKUP-4/backup-incr-2019-08-20_120007.xbstream.gz.aes256
download: s3://drbackup/BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256 to BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256जैसा कि आपको याद है, बैकअप एन्क्रिप्टेड होते हैं। हमारे पास एन्क्रिप्शन कुंजी होनी चाहिए जो ClusterControl में संग्रहीत है। सुनिश्चित करें कि आपके पास इसकी कॉपी मुख्य डेटासेंटर के बाहर कहीं सुरक्षित है। यदि आप उस तक नहीं पहुंच सकते हैं, तो आप बैकअप को डिक्रिप्ट नहीं कर पाएंगे। कुंजी को ClusterControl कॉन्फ़िगरेशन में पाया जा सकता है:
example@sqldat.com:~# grep backup_encryption_key /etc/cmon.d/cmon_1.cnf
backup_encryption_key='aoxhIelVZr1dKv5zMbVPLxlLucuYpcVmSynaeIEeBnM='इसे बेस 64 का उपयोग करके एन्कोड किया गया है, इसलिए हमें इसे पहले डीकोड करना होगा और बैकअप को डिक्रिप्ट करना शुरू करने से पहले इसे फ़ाइल में स्टोर करना होगा:
echo "aoxhIelVZr1dKv5zMbVPLxlLucuYpcVmSynaeIEeBnM=" | opensl enc -base64 -d> पास
अब हम बैकअप को डिक्रिप्ट करने के लिए इस फ़ाइल का पुन:उपयोग कर सकते हैं। अभी के लिए, मान लें कि हम एक पूर्ण और दो वृद्धिशील बैकअप करेंगे।
mkdir 1
mkdir 2
mkdir 3
cat BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256 | openssl enc -d -aes-256-cbc -pass file:/root/backups/pass | zcat | xbstream -x -C /root/backups/1/
cat BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256 | openssl enc -d -aes-256-cbc -pass file:/root/backups/pass | zcat | xbstream -x -C /root/backups/2/
cat BACKUP-3/backup-incr-2019-08-20_115005.xbstream.gz.aes256 | openssl enc -d -aes-256-cbc -pass file:/root/backups/pass | zcat | xbstream -x -C /root/backups/3/हमारे पास डेटा डिक्रिप्ट हो गया है, अब हमें अपना MySQL सर्वर सेट करने के साथ आगे बढ़ना होगा। आदर्श रूप से, यह बिल्कुल वैसा ही संस्करण होना चाहिए जैसा कि उत्पादन प्रणालियों पर होता है। हम MySQL के लिए Percona सर्वर का उपयोग करेंगे:
cd ~
wget https://repo.percona.com/apt/percona-release_latest.generic_all.deb
sudo dpkg -i percona-release_latest.generic_all.deb
apt-get update
apt-get install percona-server-5.7कुछ भी जटिल नहीं है, बस नियमित इंस्टालेशन है। एक बार यह तैयार और तैयार हो जाने पर हमें इसे रोकना होगा और इसकी डेटा निर्देशिका की सामग्री को हटाना होगा।
service mysql stop
rm -rf /var/lib/mysql/*बैकअप को पुनर्स्थापित करने के लिए हमें Xtrabackup की आवश्यकता होगी - एक उपकरण CC इसे बनाने के लिए उपयोग करता है (कम से कम Perona और Oracle MySQL के लिए, MariaDB मारियाबैकअप का उपयोग करता है)। यह महत्वपूर्ण है कि यह उपकरण उसी संस्करण में स्थापित किया गया है जैसे उत्पादन सर्वर पर:
apt install percona-xtrabackup-24हमें बस इतना ही तैयार करना है। अब हम बैकअप को पुनर्स्थापित करना शुरू कर सकते हैं। वृद्धिशील बैकअप के साथ यह ध्यान रखना महत्वपूर्ण है कि आपको उन्हें आधार बैकअप के ऊपर तैयार करना और लागू करना है। बेस बैकअप भी तैयार करना होगा। रोलबैक चरण को चलाने से एक्स्ट्राबैकअप को रोकने के लिए '--लागू-लॉग-ओनली' विकल्प के साथ तैयारी को चलाना महत्वपूर्ण है। अन्यथा आप अगला वृद्धिशील बैकअप लागू नहीं कर पाएंगे।
xtrabackup --prepare --apply-log-only --target-dir=/root/backups/1/
xtrabackup --prepare --apply-log-only --target-dir=/root/backups/1/ --incremental-dir=/root/backups/2/
xtrabackup --prepare --target-dir=/root/backups/1/ --incremental-dir=/root/backups/3/अंतिम आदेश में हमने xtrabackup को पूर्ण नहीं किए गए लेनदेन के रोलबैक को चलाने की अनुमति दी थी - हम बाद में कोई और वृद्धिशील बैकअप लागू नहीं करेंगे। अब बैकअप के साथ डेटा निर्देशिका को पॉप्युलेट करने का समय है, MySQL प्रारंभ करें और देखें कि सब कुछ अपेक्षित रूप से काम करता है या नहीं:
example@sqldat.com:~/backups# mv /root/backups/1/* /var/lib/mysql/
example@sqldat.com:~/backups# chown -R mysql.mysql /var/lib/mysql
example@sqldat.com:~/backups# service mysql start
example@sqldat.com:~/backups# mysql -ppass
mysql: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 6
Server version: 5.7.26-29 Percona Server (GPL), Release '29', Revision '11ad961'
Copyright (c) 2009-2019 Percona LLC and/or its affiliates
Copyright (c) 2000, 2019, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> show schemas;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| proxydemo |
| sbtest |
| sys |
+--------------------+
6 rows in set (0.00 sec)
mysql> select count(*) from sbtest.sbtest1;
+----------+
| count(*) |
+----------+
| 10506 |
+----------+
1 row in set (0.01 sec)जैसा कि आप देख सकते हैं, सब ठीक है। MySQL सही ढंग से शुरू हुआ और हम इसे एक्सेस करने में सक्षम थे (और डेटा वहां है!) हम सफलतापूर्वक अपने डेटाबेस को एक अलग स्थान पर वापस लाने और चलाने में कामयाब रहे। आवश्यक कुल समय डेटा के आकार पर सख्ती से निर्भर करता है - हमें S3 से डेटा डाउनलोड करना था, इसे डिक्रिप्ट और डीकंप्रेस करना था और अंत में बैकअप तैयार करना था। फिर भी, यह एक बहुत ही सस्ता विकल्प है (आपको केवल S3 डेटा के लिए भुगतान करना होगा) जो आपको व्यापार निरंतरता के लिए एक विकल्प देता है यदि कोई आपदा आती है।