परिचय
डेटा संग्रहीत करना एक बात है; सार्थक, उपयोगी, सही को संग्रहित करना डेटा काफी अलग है। जबकि अर्थ और उपयोगिता स्वयं व्यक्तिपरक गुण हैं, कम से कम शुद्धता को तार्किक रूप से परिभाषित और लागू किया जा सकता है। प्रकार पहले से ही सुनिश्चित करते हैं कि संख्याएं संख्याएं हैं और तिथियां तिथियां हैं, लेकिन यह गारंटी नहीं दे सकती कि वजन या दूरी सकारात्मक संख्याएं हैं या दिनांक सीमाओं को ओवरलैप होने से रोकती हैं। टुपल, टेबल और डेटाबेस की कमी डेटा को संग्रहीत करने के लिए नियम लागू करती है और मूल्यों या मूल्यों के संयोजन को अस्वीकार करती है जो मस्टर पास नहीं करते हैं।
बाधाएं अन्य इनपुट सत्यापन तकनीकों को किसी भी तरह से बेकार नहीं करती हैं, तब भी जब वे समान अभिकथन का परीक्षण करते हैं। अमान्य डेटा को संग्रहीत करने की कोशिश करने और विफल होने में लगने वाला समय बर्बाद होता है। उल्लंघन संदेश, जैसे assert सिस्टम और एप्लिकेशन प्रोग्रामिंग भाषाओं में, केवल पहले उम्मीदवार रिकॉर्ड के साथ पहली समस्या को और अधिक विस्तार से प्रकट करता है, जो कि तुरंत डेटाबेस की जरूरतों में शामिल नहीं है। लेकिन जहां तक डेटा की शुद्धता का संबंध है, बाधाएं कानून हैं, अच्छे या बुरे के लिए; कुछ और सलाह है।
टुपल्स पर:नॉट नल, डिफॉल्ट, और चेक
गैर-शून्य बाधाएं सबसे सरल श्रेणी हैं। एक टपल में विवश विशेषता के लिए एक मान होना चाहिए, या दूसरे तरीके से कहें तो कॉलम के लिए अनुमत मानों के सेट में अब खाली सेट शामिल नहीं है। नो वैल्यू का मतलब टुपल नहीं है:इंसर्ट या अपडेट अस्वीकार कर दिया गया है।
शून्य मानों से सुरक्षा करना उतना ही आसान है जितना कि column_name COLUMN_TYPE NOT NULL घोषित करना CREATE TABLE में या ADD COLUMN . शून्य मान डेटाबेस और अंतिम उपयोगकर्ताओं के बीच समस्याओं की पूरी श्रेणियों का कारण बनते हैं, इसलिए बिना किसी कारण के किसी भी कॉलम पर गैर-शून्य बाधाओं को स्पष्ट रूप से परिभाषित करना नल की अनुमति देने के लिए एक अच्छी आदत है।
डिफ़ॉल्ट मान का प्रावधान यदि कुछ भी निर्दिष्ट नहीं है (चूक या स्पष्ट NULL . द्वारा ) किसी इंसर्ट या अपडेट में हमेशा एक बाधा नहीं माना जाता है, क्योंकि उम्मीदवार के रिकॉर्ड को संशोधित करने के बजाय संशोधित और संग्रहीत किया जाता है। कई DBMS में, डिफ़ॉल्ट मान किसी फ़ंक्शन द्वारा उत्पन्न किए जा सकते हैं, हालांकि MySQL इस उद्देश्य के लिए उपयोगकर्ता-परिभाषित फ़ंक्शन की अनुमति नहीं देता है।
कोई अन्य सत्यापन नियम जो केवल एक टपल के भीतर मूल्यों पर निर्भर करता है उसे CHECK के रूप में लागू किया जा सकता है बाधा एक मायने में, NOT NULL CHECK (column_name IS NOT NULL) . के लिए खुद एक शॉर्टहैंड है; उल्लंघन में प्राप्त त्रुटि संदेश से सबसे अधिक फर्क पड़ता है। CHECK हालांकि, किसी भी बूलियन विधेय की सच्चाई को एक टपल पर लागू कर सकता है और लागू कर सकता है। उदाहरण के लिए, भौगोलिक स्थानों को संग्रहीत करने वाली तालिका को CHECK (latitude >= -90 AND latitude < 90) होना चाहिए , और इसी तरह -180 और 180 के बीच के देशांतर के लिए -- या, यदि उपलब्ध हो, तो GEOGRAPHY का उपयोग और सत्यापन करें डेटा प्रकार।
टेबल्स पर:यूनिक और एक्सक्लूजन
तालिका-स्तर की बाधाएं एक-दूसरे के विरुद्ध परीक्षण टुपल्स करती हैं। एक अद्वितीय बाधा में, केवल एक रिकॉर्ड में सीमित स्तंभों के लिए दिए गए मानों का कोई सेट हो सकता है। शून्यता यहां समस्याएं पैदा कर सकती है, क्योंकि NULL NULL . तक और इसके अलावा, किसी भी चीज़ के बराबर कभी नहीं अपने आप। (batman, robin) . पर एक अद्वितीय बाधा इसलिए किसी भी रॉबिनलेस बैटमैन की अनंत प्रतियों की अनुमति देता है।
बहिष्करण बाधाएं केवल PostgreSQL और DB2 में समर्थित हैं, लेकिन एक बहुत ही उपयोगी जगह भरें:वे ओवरलैप को रोक सकते हैं। सीमित फ़ील्ड और संचालन निर्दिष्ट करें जिसके द्वारा प्रत्येक का मूल्यांकन किया जाएगा, और एक नया रिकॉर्ड केवल तभी स्वीकार किया जाएगा जब कोई मौजूदा रिकॉर्ड प्रत्येक फ़ील्ड और ऑपरेशन के साथ सफलतापूर्वक तुलना नहीं करता है। उदाहरण के लिए, एक schedules तालिका को विरोधों को अस्वीकार करने के लिए कॉन्फ़िगर किया जा सकता है:
-- text, int, etc. comparisons in exclusion constraints require this-- Postgres extensionCREATE EXTENSION btree_gist;CREATE TABLE schedules ( schedule_id SERIAL NOT NULL PRIMARY KEY, room_number TEXT NOT NULL, -- a range of TIMESTAMP WITH TIME ZONE provides both start and end duration TSTZRANGE, -- table-level constraints imply an index, since otherwise they'd -- have to search the entire table to validate a candidate record; -- GiST (generalized search tree) indexes are usually used in -- Postgres EXCLUDE USING GIST ( room_number WITH =, duration WITH && ));INSERT INTO schedules (room_number, duration)VALUES ('32A', '[2020-08-20T10:00:00Z,2020-08-20T11:00:00Z)');-- the same time in a different room: acceptedINSERT INTO schedules (room_number, duration)VALUES ('32B', '[2020-08-20T10:00:00Z,2020-08-20T11:00:00Z)');-- a half-hour overlap for an already-scheduled room: rejectedINSERT INTO schedules (room_number, duration)VALUES ('32A', '[2020-08-20T10:30:00Z,2020-08-20T11:30:00Z)');
पोस्टग्रेएसक्यूएल के ON CONFLICT जैसे अप्सर्ट ऑपरेशंस खंड या MySQL का ON DUPLICATE KEY UPDATE संघर्षों का पता लगाने के लिए तालिका-स्तर की बाधा का उपयोग करें। और जैसे गैर-शून्य बाधाओं को CHECK . के रूप में व्यक्त किया जा सकता है बाधाओं, एक अद्वितीय बाधा को समानता पर एक बहिष्करण बाधा के रूप में व्यक्त किया जा सकता है।
प्राथमिक कुंजी
अद्वितीय बाधाओं में विशेष रूप से उपयोगी विशेष मामला होता है। अद्वितीय स्तंभ या स्तंभों पर एक अतिरिक्त गैर-शून्य बाधा के साथ, तालिका में प्रत्येक रिकॉर्ड को सीमित स्तंभों के लिए इसके मानों द्वारा एकवचन में पहचाना जा सकता है, जिन्हें सामूहिक रूप से कुंजी कहा जाता है। . एक तालिका में एकाधिक उम्मीदवार कुंजियाँ एक साथ मौजूद हो सकती हैं, जैसे users अभी भी कभी-कभी विशिष्ट अद्वितीय और गैर-शून्य email s और username एस; लेकिन प्राथमिक कुंजी घोषित करने से एक एकल मानदंड स्थापित होता है जिसके द्वारा रिकॉर्ड सार्वजनिक रूप से और अनन्य रूप से ज्ञात होते हैं। कुछ RDBMS प्राथमिक कुंजी द्वारा पृष्ठों पर पंक्तियों को व्यवस्थित भी करते हैं, जिसे इस उद्देश्य के लिए क्लस्टर इंडेक्स कहा जाता है। , प्राथमिक कुंजी मानों द्वारा जितनी जल्दी हो सके खोज करने के लिए।
प्राथमिक कुंजी दो प्रकार की होती है। तालिका के डेटा में शामिल "स्वाभाविक रूप से" कॉलम या कॉलम पर एक प्राकृतिक कुंजी परिभाषित की जाती है, जबकि एक सरोगेट या सिंथेटिक कुंजी का आविष्कार केवल कुंजी बनने के उद्देश्य से किया जाता है। प्राकृतिक चाबियों को देखभाल की आवश्यकता होती है - नाम से लेकर नंबरिंग योजनाओं तक, डेटाबेस डिजाइनरों की तुलना में अधिक चीजें बदल सकती हैं। देश और क्षेत्र के नामों वाली एक लुकअप तालिका अपने संबंधित आईएसओ 3166 कोड को एक सुरक्षित प्राकृतिक प्राथमिक कुंजी के रूप में उपयोग कर सकती है, लेकिन एक users नाम या ईमेल पते जैसे परिवर्तनशील मूल्यों के आधार पर एक प्राकृतिक कुंजी वाली तालिका परेशानी को आमंत्रित करती है। जब संदेह हो, तो एक सरोगेट कुंजी बनाएं।
यदि एक प्राकृतिक कुंजी कई स्तंभों तक फैली हुई है, तो एक सरोगेट कुंजी को हमेशा कम से कम माना जाना चाहिए क्योंकि बहु-स्तंभ कुंजियों को प्रबंधित करने के लिए अधिक प्रयास करना पड़ता है। यदि प्राकृतिक कुंजी सूट करती है, हालांकि, कॉलम को बढ़ती विशिष्टता में क्रमबद्ध किया जाना चाहिए जैसे वे इंडेक्स में हैं:देश कोड फिर क्षेत्र कोड, उल्टे के बजाय।
सरोगेट कुंजी ऐतिहासिक रूप से एक पूर्णांक स्तंभ, या BIGINT . रही है जहां अरबों को अंततः सौंपा जाएगा। रिलेशनल डेटाबेस स्वचालित रूप से एक श्रृंखला में अगले पूर्णांक के साथ सरोगेट कुंजी भर सकते हैं, एक विशेषता जिसे आमतौर पर SERIAL कहा जाता है या IDENTITY ।
एक ऑटोइनक्रिमेंटिंग न्यूमेरिक काउंटर कमियों के बिना नहीं है:प्रीजेनरेटेड कुंजियों के साथ रिकॉर्ड में जोड़ने से संघर्ष हो सकता है, और यदि अनुक्रमिक मान उपयोगकर्ताओं के सामने आते हैं, तो उनके लिए यह अनुमान लगाना आसान होता है कि अन्य वैध कुंजी क्या हो सकती हैं। सार्वभौमिक रूप से अद्वितीय पहचानकर्ता, या यूयूआईडी, इन कमजोरियों से बचते हैं और सरोगेट कुंजियों के लिए एक सामान्य विकल्प बन गए हैं, हालांकि वे एक साधारण संख्या की तुलना में बहुत बड़े इन-पेज भी हैं। v1 (MAC पता-आधारित) और v4 (छद्म यादृच्छिक) UUID प्रकार सबसे अधिक बार उपयोग किए जाते हैं।
डेटाबेस पर:विदेशी कुंजी
रिलेशनल डेटाबेस मल्टी-टेबल बाधा के केवल एक वर्ग को लागू करते हैं,
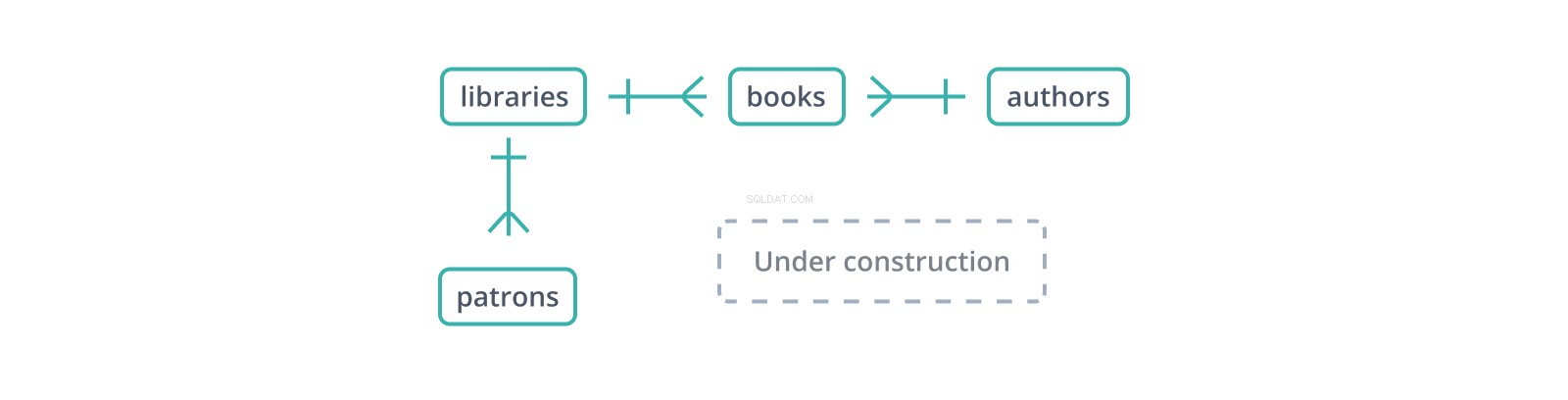
यह अनौपचारिक "इकाई-संबंध आरेख" या ईआरडी पुस्तकालयों और उनके संग्रह और संरक्षक के डेटाबेस के लिए एक स्कीमा की शुरुआत दिखाता है। प्रत्येक किनारा उन तालिकाओं के बीच संबंध का प्रतिनिधित्व करता है जो इसे जोड़ता है। | ग्लिफ़ अपने पक्ष में एक एकल रिकॉर्ड को इंगित करता है, जबकि "क्रोज़ फ़ुट" ग्लिफ़ कई का प्रतिनिधित्व करता है:एक पुस्तकालय में कई किताबें होती हैं और कई संरक्षक होते हैं।
एक विदेशी कुंजी किसी अन्य तालिका की प्राथमिक कुंजी की एक प्रति है, कॉलम के लिए कॉलम (सरोगेट कुंजी के पक्ष में एक बिंदु:प्रतिलिपि और संदर्भ के लिए केवल एक कॉलम), इस तालिका में रिकॉर्ड्स को "पैरेंट" रिकॉर्ड से जोड़ने वाले मानों के साथ। ऊपर दिए गए स्कीमा में, books तालिका एक library_id बनाए रखती है libraries . के लिए विदेशी कुंजी , जिसमें पुस्तकें हैं, और एक author_id authors . के लिए , जो उन्हें लिखते हैं। लेकिन क्या होता है यदि कोई पुस्तक author_id . के साथ डाली जाती है जो authors . में मौजूद नहीं है ?
यदि विदेशी कुंजी विवश नहीं है - यानी, यह सिर्फ एक और कॉलम या कॉलम है - एक पुस्तक में एक लेखक हो सकता है जो अस्तित्व में नहीं है। यह एक समस्या है:यदि कोई books . के बीच की कड़ी का अनुसरण करने का प्रयास करता है और authors , वे कहीं नहीं हवा। अगर authors.author_id एक सीरियल इंटीजर है, इस बात की भी संभावना है कि नकली author_id तक कोई भी नोटिस न करे अंततः असाइन किया गया है, और आप डॉन क्विक्सोट . की एक विशेष प्रति के साथ समाप्त होते हैं इसका श्रेय पहले किसी को ज्ञात नहीं और फिर पियरे मेनार्ड को दिया गया, मिगुएल सर्वेंटिस का कहीं पता नहीं चला।
यदि गलत author_id होना चाहिए, तो विदेशी कुंजी को प्रतिबंधित करने से किसी पुस्तक को गलत श्रेय देने से नहीं रोका जा सकता है authors . में मौजूदा रिकॉर्ड की ओर इशारा करते हैं , इसलिए अन्य जांच और परीक्षण महत्वपूर्ण रहते हैं। हालांकि, मौजूदा विदेशी कुंजी मानों का सेट लगभग हमेशा संभव . का एक छोटा उपसमुच्चय होता है विदेशी कुंजी मान, इसलिए विदेशी कुंजी बाधाएं अधिकांश गलत मानों को पकड़ लेंगी और रोक देंगी। एक विदेशी कुंजी बाधा के साथ, क्विक्सोट एक गैर-मौजूद लेखक के साथ रिकॉर्ड किए जाने के बजाय खारिज कर दिया जाएगा।
क्या यही वह जगह है जहां से "रिलेशनल डेटाबेस" में "रिलेशनल" आता है?
<लेबल for="tab-2" class="collapsible__Label-yt6g6p-2 cnFMTL">जैसा कि होता है, नहीं!विदेशी कुंजियाँ तालिकाओं के बीच संबंध बनाती हैं, लेकिन जैसा कि हम जानते हैं कि तालिकाएँ गणितीय रूप से संबंध . हैं प्रत्येक विशेषता के लिए संभावित मानों के सेट के बीच। एक एकल टपल स्तंभ A के मान को स्तंभ B और आगे के मान से संबंधित करता है। E.F. Codd का मूल पेपर इस अर्थ में "रिलेशनल" का उपयोग करता है।
इससे भ्रम का कोई अंत नहीं हुआ है और संभवत:ऐसा हमेशा के लिए जारी रहेगा।
सही के कुछ मूल्यों के लिए
ऐसे और भी कई तरीके हैं जिनसे डेटा यहां बताए गए तरीके से गलत हो सकता है। बाधाएं मदद करती हैं, लेकिन वे भी केवल इतनी लचीली होती हैं; कई सामान्य इंट्रा-टेबल विनिर्देश, जैसे किसी स्तंभ में किसी मान के प्रदर्शित होने की संख्या पर दो या अधिक की सीमा, केवल ट्रिगर के साथ लागू की जा सकती है।
लेकिन ऐसे भी तरीके हैं जिनसे तालिका की संरचना ही विसंगतियों को जन्म दे सकती है। इन्हें रोकने के लिए, हमें न केवल परिभाषित और मान्य करने के लिए बल्कि सामान्यीकरण करने के लिए प्राथमिक और विदेशी दोनों कुंजियों को मार्शल करना होगा तालिकाओं के बीच संबंध। सबसे पहले, हालांकि, हमने मुश्किल से इस बात की सतह को खंगाला है कि कैसे तालिकाओं के बीच संबंध डेटाबेस की संरचना को ही परिभाषित करते हैं।