मुझे वहां बहुत सी सलाह दिखाई दे रही है जो कुछ कहती है, "अपने कर्सर को एक सेट-आधारित ऑपरेशन में बदलें; इससे यह तेज़ हो जाएगा।" जबकि अक्सर ऐसा हो सकता है, यह हमेशा सच नहीं होता है। एक उपयोग का मामला मैं देखता हूं कि जहां एक कर्सर बार-बार विशिष्ट सेट-आधारित दृष्टिकोण से बेहतर प्रदर्शन करता है, वह कुल योग की गणना है। ऐसा इसलिए है क्योंकि सेट-आधारित दृष्टिकोण को आमतौर पर अंतर्निहित डेटा के कुछ हिस्से को एक से अधिक बार देखना पड़ता है, जो डेटा के बड़े होने के साथ-साथ तेजी से खराब हो सकता है; जबकि एक कर्सर - जितना दर्दनाक लग सकता है - प्रत्येक पंक्ति/मान के माध्यम से ठीक एक बार कदम उठा सकता है।
SQL सर्वर के सबसे सामान्य संस्करणों में ये हमारे मूल विकल्प हैं। SQL सर्वर 2012 में, हालांकि, विंडोिंग फ़ंक्शंस और ओवर क्लॉज़ में कई संवर्द्धन किए गए हैं, जो ज्यादातर साथी एमवीपी इत्ज़िक बेन-गण (यहां उनके सुझावों में से एक है) द्वारा प्रस्तुत कई महान सुझावों से उपजी हैं। वास्तव में इत्ज़िक के पास एक नई MS-Press पुस्तक है जो इन सभी संवर्द्धन को बहुत अधिक विस्तार से कवर करती है, जिसका शीर्षक है, "Microsoft SQL Server 2012 उच्च-प्रदर्शन T-SQL विंडो फ़ंक्शंस का उपयोग करना।"
तो स्वाभाविक रूप से, मैं उत्सुक था; क्या नई विंडोिंग कार्यक्षमता कर्सर और सेल्फ-जॉइन तकनीकों को अप्रचलित बना देगी? क्या उन्हें कोड करना आसान होगा? क्या वे किसी भी (कोई बात नहीं) मामलों में तेज़ होंगे? अन्य कौन से दृष्टिकोण मान्य हो सकते हैं?
सेटअप
कुछ परीक्षण करने के लिए, आइए एक डेटाबेस सेट करें:
उपयोग [मास्टर];GOIF DB_ID('RunningTotals') डेटाबेस को बदलने वाले कुल योग नहीं हैं, तत्काल रोलबैक के साथ SINGLE_USER सेट करें; DROP DATABASE रनिंग टोटल; ENDGOCREATE DATABASE रनिंग टोटल; GOUSE रनिंग टोटल; GOSET NOCOUNT ON;GO और फिर 10,000 पंक्तियों के साथ एक तालिका भरें जिसका उपयोग हम कुछ चल रहे योगों को करने के लिए कर सकते हैं। कुछ भी जटिल नहीं है, बस एक सारांश तालिका जिसमें प्रत्येक तिथि के लिए एक पंक्ति है और एक संख्या है जो दर्शाती है कि कितने तेज टिकट जारी किए गए थे। मेरे पास कुछ वर्षों में तेज़ टिकट नहीं था, इसलिए मुझे नहीं पता कि यह एक सरल डेटा मॉडल के लिए मेरी अवचेतन पसंद क्यों थी, लेकिन वहाँ है।
टेबल डीबीओ बनाएं। स्पीडिंग टिकट ([दिनांक] दिनांक शून्य नहीं है, टिकटकाउंट आईएनटी); वैकल्पिक तालिका डीबीओ जाओ। स्पीडिंग टिकट प्रतिबंध पीके प्राथमिक कुंजी क्लस्टर ([दिनांक]) जोड़ें; एक्स (डी, एच) के रूप में जाओ (चयन करें) टॉप (250) ROW_NUMBER () ओवर ([ऑब्जेक्ट_आईडी] द्वारा ऑर्डर), कन्वर्ट (आईएनटी, राइट ([ऑब्जेक्ट_आईडी], 2)) sys.all_objects से ऑर्डर [ऑब्जेक्ट_आईडी] द्वारा ऑर्डर करें) डीबीओ डालें। स्पीडिंग टिकट ([दिनांक], टिकटकाउंट) टॉप (10000) d =DATEADD (दिन, x2.d + ((x.d-1) * 250), '19831231'), x2.hFROM x क्रॉस जॉइन x के रूप में x2ORDER से d का चयन करें; चुनें [दिनांक], टिकट की संख्या से dbo.SpeedingTickets [Date] तक ऑर्डर करें;GO
संक्षिप्त परिणाम:
तो फिर, बहुत ही सरल डेटा की 10,000 पंक्तियाँ - छोटे INT मान और 1984 से मई 2011 तक की तारीखों की एक श्रृंखला।
दृष्टिकोण
अब मेरा असाइनमेंट अपेक्षाकृत सरल है और कई अनुप्रयोगों के लिए विशिष्ट है:एक परिणामसेट लौटाएं जिसमें सभी 10,000 तिथियां हों, साथ ही उस तिथि तक सभी तेज टिकटों के संचयी कुल के साथ। अधिकांश लोग पहले कुछ इस तरह की कोशिश करेंगे (हम इसे "आंतरिक जुड़ाव . कहेंगे) "विधि):
st1 चुनें। .[दिनांक], st1.St1 द्वारा टिकट काउंटर।[दिनांक];
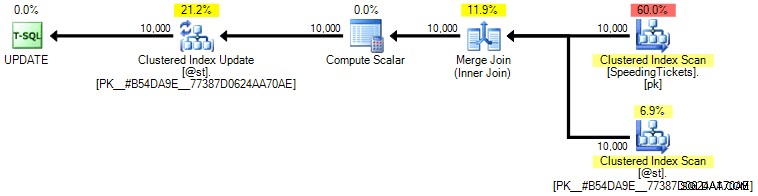
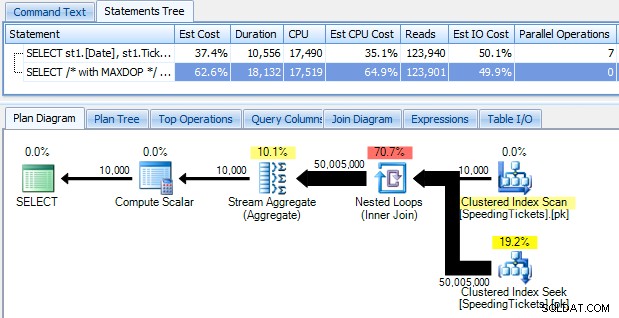
... और यह जानकर चौंक जाएंगे कि इसे चलाने में लगभग 10 सेकंड लगते हैं। SQL संतरी योजना एक्सप्लोरर का उपयोग करके, ग्राफिकल निष्पादन योजना को देखकर जल्दी से जांच करें कि क्यों:

बड़े मोटे तीरों को तत्काल संकेत देना चाहिए कि क्या हो रहा है:नेस्टेड लूप पहले एकत्रीकरण के लिए एक पंक्ति, दूसरी के लिए दो पंक्तियाँ, तीसरे के लिए तीन पंक्तियाँ, और 10,000 पंक्तियों के पूरे सेट के माध्यम से आगे और आगे पढ़ता है। इसका मतलब है कि हमें मोटे तौर पर ((10000 * (10000 + 1)) / 2) पंक्तियों को देखना चाहिए जो पूरे सेट को पार करने के बाद संसाधित होती हैं, और यह योजना में दिखाई गई पंक्तियों की संख्या से मेल खाती है।
ध्यान दें कि समानांतरता के बिना क्वेरी चलाना (विकल्प (MAXDOP 1) क्वेरी संकेत का उपयोग करके) योजना को थोड़ा सरल बनाता है, लेकिन निष्पादन समय या I/O में बिल्कुल भी मदद नहीं करता है; जैसा कि योजना में दिखाया गया है, अवधि वास्तव में लगभग दोगुनी हो जाती है, और केवल बहुत कम प्रतिशत की कमी होती है। पिछली योजना की तुलना में:
ऐसे कई अन्य दृष्टिकोण हैं जिन्हें लोगों ने कुशल चलने वाले योग प्राप्त करने का प्रयास किया है। एक उदाहरण है "सबक्वेरी विधि " जो ऊपर वर्णित आंतरिक जुड़ाव विधि के समान ही एक सहसंबद्ध उपश्रेणी का उपयोग करता है:
चुनें [दिनांक], टिकटकाउंट, रनिंग टोटल =टिकटकाउंट + कोलेस ((डीबीओ से SUM (टिकटकाउंट) चुनें। स्पीडिंग टिकट जहां से हैं। [दिनांक] <ओ। [दिनांक]), 0) डीबीओ से। स्पीडिंग टिकट के रूप में आदेश द्वारा [तारीख];
उन दो योजनाओं की तुलना करना:
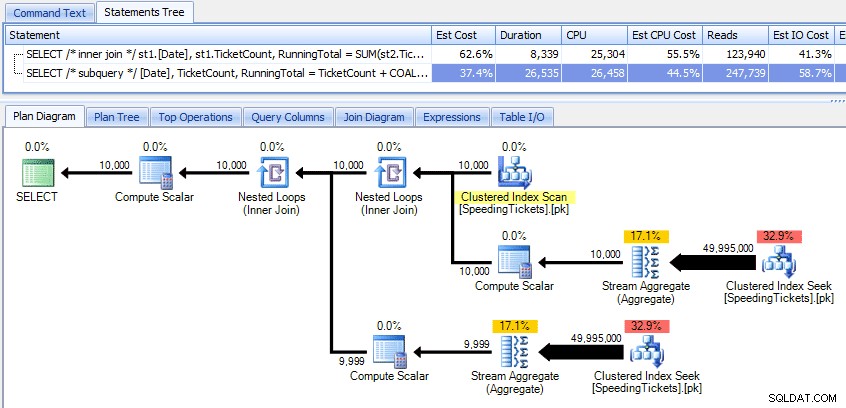
इसलिए जब सबक्वायरी विधि में एक अधिक कुशल समग्र योजना प्रतीत होती है, तो यह और भी खराब है जहां यह मायने रखता है:अवधि और I/O। हम देख सकते हैं कि योजनाओं में थोड़ी गहराई से खुदाई करने से इसमें क्या योगदान होता है। टॉप ऑपरेशंस टैब पर जाने से, हम देख सकते हैं कि इनर जॉइन मेथड में, क्लस्टर्ड इंडेक्स सीक को 10,000 बार निष्पादित किया जाता है, और अन्य सभी ऑपरेशन केवल कुछ ही बार निष्पादित होते हैं। हालांकि, सबक्वेरी विधि में कई ऑपरेशन 9,999 या 10,000 बार निष्पादित किए जाते हैं:
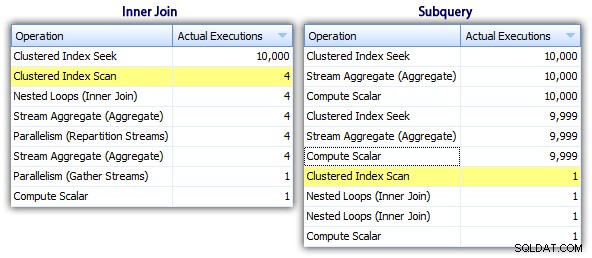
तो, सबक्वायरी दृष्टिकोण बदतर लगता है, बेहतर नहीं। अगली विधि जिसे हम आजमाएंगे, मैं "अजीब अपडेट . कहूंगा "विधि। यह काम करने की बिल्कुल गारंटी नहीं है, और मैं इसे उत्पादन कोड के लिए कभी भी अनुशंसा नहीं करता, लेकिन मैं इसे पूर्णता के लिए शामिल कर रहा हूं। मूल रूप से विचित्र अपडेट इस तथ्य का लाभ उठाता है कि एक अपडेट के दौरान आप असाइनमेंट और गणित को पुनर्निर्देशित कर सकते हैं। कि प्रत्येक पंक्ति के अपडेट होने पर परदे के पीछे परिवर्तनशील वृद्धि होती है।
घोषित @st तालिका ([दिनांक] दिनांक प्राथमिक कुंजी, टिकट गणना आईएनटी, रनिंग टोटल आईएनटी); DECLARE @RunningTotal INT =0; INSERT @st ([दिनांक], टिकटकाउंट, रनिंग टोटल) चुनें [दिनांक], टिकटकाउंट, रनिंग टोटल =0 डीबीओ से। स्पीडिंग टिकट ऑर्डर द्वारा [दिनांक]; अद्यतन @st सेट @RunningTotal =रनिंग टोटल =@RunningTotal + @st से टिकट गणना; [तारीख] चुनेंमैं फिर से बताऊंगा कि मुझे विश्वास नहीं है कि यह दृष्टिकोण उत्पादन के लिए सुरक्षित है, भले ही आप लोगों से यह गवाही सुनेंगे कि यह "कभी विफल नहीं होता है।" जब तक व्यवहार को प्रलेखित और गारंटीकृत नहीं किया जाता है, मैं देखे गए व्यवहार के आधार पर धारणाओं से दूर रहने की कोशिश करता हूं। आप कभी नहीं जानते कि अनुकूलक के निर्णय पथ में कब कुछ परिवर्तन (आंकड़ों में बदलाव, डेटा परिवर्तन, सर्विस पैक, ट्रेस फ्लैग, क्वेरी संकेत, आपके पास क्या है) के आधार पर योजना में भारी बदलाव आएगा और संभावित रूप से एक अलग क्रम में ले जाएगा। यदि आप वास्तव में इस सहज ज्ञान युक्त दृष्टिकोण को पसंद करते हैं, तो आप क्वेरी विकल्प FORCE ORDER का उपयोग करके खुद को थोड़ा बेहतर महसूस करा सकते हैं (और यह PK के ऑर्डर किए गए स्कैन का उपयोग करने का प्रयास करेगा, क्योंकि टेबल वैरिएबल पर यही एकमात्र योग्य इंडेक्स है):
अपडेट @st SET @RunningTotal =रनिंग टोटल =@RunningTotal + TicketCount @st OPTION (फोर्स ऑर्डर) से;थोड़ी अधिक I/O लागत पर थोड़ा अधिक आत्मविश्वास के लिए, आप मूल तालिका को वापस खेल में ला सकते हैं, और यह सुनिश्चित कर सकते हैं कि आधार तालिका पर PK का उपयोग किया गया है:
अपडेट सेंट सेट @RunningTotal =st.RunningTotal =@RunningTotal + t.TicketCount FROM dbo.SpeedingTicket as t विद (इंडेक्स =पीके) इनर जॉइन @st के रूप में टी पर। [दिनांक] =सेंट [दिनांक] विकल्प (बल आदेश);व्यक्तिगत रूप से मुझे नहीं लगता कि यह अधिक गारंटीकृत है, क्योंकि ऑपरेशन का एसईटी हिस्सा शेष क्वेरी से स्वतंत्र अनुकूलक को संभावित रूप से प्रभावित कर सकता है। दोबारा, मैं इस दृष्टिकोण की अनुशंसा नहीं कर रहा हूं, मैं केवल पूर्णता की तुलना शामिल कर रहा हूं। यहाँ इस क्वेरी से योजना है:
शीर्ष संचालन टैब में हम निष्पादन की संख्या के आधार पर देखते हैं (मैं आपको स्क्रीन शॉट छोड़ दूंगा; यह प्रत्येक ऑपरेशन के लिए 1 है), यह स्पष्ट है कि भले ही हम ऑर्डर करने के बारे में बेहतर महसूस करने के लिए शामिल हों, विचित्र अद्यतन डेटा के एकल पास में चल रहे कुल योग की गणना करने की अनुमति देता है। पिछले प्रश्नों की तुलना में, यह बहुत अधिक कुशल है, भले ही यह पहले डेटा को तालिका चर में डंप करता है और कई कार्यों में अलग किया जाता है:
यह हमें "पुनरावर्ती CTE . पर लाता है "विधि। यह विधि दिनांक मान का उपयोग करती है, और इस धारणा पर निर्भर करती है कि कोई अंतराल नहीं है। चूंकि हमने ऊपर इस डेटा को पॉप्युलेट किया है, हम जानते हैं कि यह पूरी तरह से सन्निहित श्रृंखला है, लेकिन कई परिदृश्यों में आप इसे नहीं बना सकते हैं धारणा। इसलिए, जबकि मैंने इसे पूर्णता के लिए शामिल किया है, यह दृष्टिकोण हमेशा मान्य नहीं होगा। किसी भी मामले में, यह तालिका में पहली (ज्ञात) तिथि के साथ एंकर के रूप में एक पुनरावर्ती सीटीई का उपयोग करता है, और पुनरावर्ती भाग एक दिन जोड़कर निर्धारित किया जाता है (MAXRECURSION विकल्प जोड़ना क्योंकि हम जानते हैं कि हमारे पास कितनी पंक्तियां हैं):
; एक्स एएस के साथ (चुनें [दिनांक], टिकटकाउंट, रनिंगटोटल =डीबीओ से टिकटकाउंट। स्पीडिंग टिकट जहां [दिनांक] ='19840101' यूनियन सभी का चयन करें। [दिनांक], वाई। टिकटकाउंट, एक्स। रनिंग टोटल + वाई। टिकटकाउंट एक्स इनर जॉइन dbo.SpeedingTicket AS y ON y। [दिनांक] =DATEADD (दिन, 1, x। [दिनांक])) चुनें [दिनांक], टिकट गणना, [दिनांक] विकल्प द्वारा x आदेश से कुल चल रहा है (MAXRECURSION 10000);यह क्वेरी उतनी ही कुशलता से काम करती है जितनी कि क्वर्की अपडेट मेथड। हम इसकी तुलना सबक्वेरी और इनर जॉइन मेथड्स से कर सकते हैं:
विचित्र अद्यतन पद्धति की तरह, मैं उत्पादन में इस सीटीई दृष्टिकोण की अनुशंसा नहीं करता जब तक कि आप पूरी तरह से गारंटी नहीं दे सकते कि आपके कुंजी कॉलम में कोई अंतराल नहीं है। यदि आपके डेटा में अंतराल हो सकता है, तो आप ROW_NUMBER() का उपयोग करके कुछ इसी तरह का निर्माण कर सकते हैं, लेकिन यह ऊपर सेल्फ-जॉइन विधि से अधिक कुशल नहीं होगा।
और फिर हमारे पास "कर्सर . है "दृष्टिकोण:
घोषित @st तालिका ([दिनांक] दिनांक प्राथमिक कुंजी, टिकट गणना आईएनटी, रनिंग टोटल आईएनटी); DECLARE @Date DATE, @TicketCount INT, @RunningTotal INT =0; DECLARE c CURSOR LOCAL STATIC FORWARD_ONLY READ_ONLY for Select [Date], TicketCount from dbo.SpeedingTicket ORDER by [Date]; खुला सी; C से @Date, @TicketCount तक अगला प्राप्त करें; जबकि @@ FETCH_STATUS =0BEGIN सेट @RunningTotal =@RunningTotal + @TicketCount; INSERT @st ([दिनांक], टिकटकाउंट, रनिंग टोटल) @ दिनांक, @TicketCount, @RunningTotal चुनें; C से @Date, @TicketCount तक अगला फ़ेच करें; अंत CLOSE c;DEALLOCATE c; [तारीख] चुनें...जो बहुत अधिक कोड है, लेकिन लोकप्रिय राय के सुझाव के विपरीत, 1 सेकंड में वापस आ जाता है। हम ऊपर दिए गए कुछ योजना विवरणों से क्यों देख सकते हैं:अधिकांश अन्य दृष्टिकोण एक ही डेटा को बार-बार पढ़ते हैं, जबकि कर्सर दृष्टिकोण प्रत्येक पंक्ति को एक बार पढ़ता है और कुल योग की गणना करने के बजाय एक चर में चल रहे कुल को रखता है और फिर से। हम इसे प्लान एक्सप्लोरर में एक वास्तविक योजना बनाकर कैप्चर किए गए बयानों को देखकर देख सकते हैं:
हम देख सकते हैं कि 20,000 से अधिक विवरण एकत्र किए गए हैं, लेकिन यदि हम अनुमानित या वास्तविक पंक्तियों के अनुसार क्रमबद्ध करते हैं, तो हम पाते हैं कि केवल दो ऑपरेशन हैं जो एक से अधिक पंक्तियों को संभालते हैं। जो उपरोक्त विधियों में से कुछ से बहुत दूर है जो प्रत्येक नई पंक्ति के लिए एक ही पिछली पंक्तियों को बार-बार पढ़ने के कारण घातीय पढ़ने का कारण बनता है।
अब, SQL सर्वर 2012 में नए विंडोिंग एन्हांसमेंट पर एक नज़र डालते हैं। विशेष रूप से, अब हम SUM OVER() की गणना कर सकते हैं और वर्तमान पंक्ति के सापेक्ष पंक्तियों का एक सेट निर्दिष्ट कर सकते हैं। इसलिए, उदाहरण के लिए:
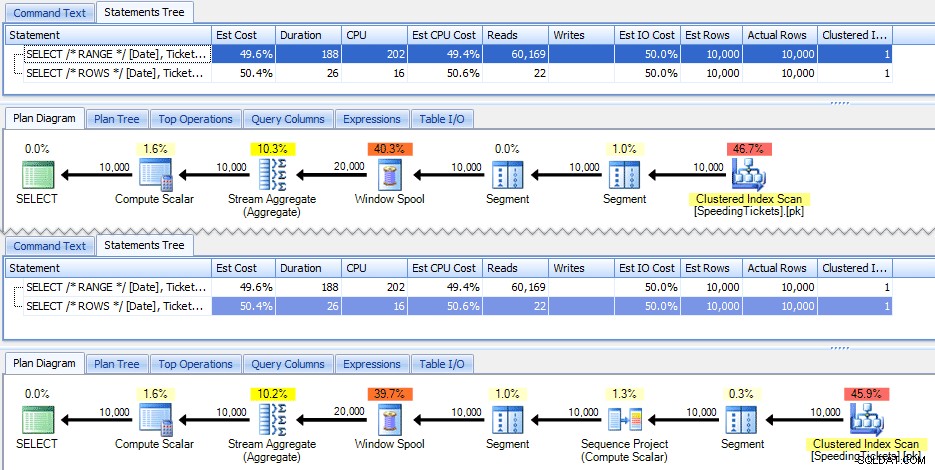
चुनें [दिनांक], टिकट गणना, योग (टिकट गणना) ओवर ([तारीख] सीमा से पहले का आदेश) डीबीओ से। dbo से [दिनांक], टिकट गणना, एसयूएम (टिकट गणना) का चयन करें ([दिनांक] पंक्तियों के आधार पर ऑर्डर करें) डीबीओ से।सही चल रहे योग के साथ, ये दो प्रश्न एक ही उत्तर देने के लिए होते हैं। लेकिन क्या वे बिल्कुल वही काम करते हैं? योजनाओं का सुझाव है कि वे नहीं करते हैं। ROWS वाले संस्करण में एक अतिरिक्त ऑपरेटर, एक 10,000-पंक्ति अनुक्रम प्रोजेक्ट है:
और यह चित्रमय योजना में अंतर की सीमा के बारे में है। लेकिन अगर आप वास्तविक रनटाइम मेट्रिक्स को थोड़ा करीब से देखते हैं, तो आप अवधि और सीपीयू में मामूली अंतर देखते हैं, और पढ़ने में बहुत बड़ा अंतर देखते हैं। ऐसा क्यों है? ठीक है, ऐसा इसलिए है क्योंकि RANGE ऑन-डिस्क स्पूल का उपयोग करता है, जबकि ROWS इन-मेमोरी स्पूल का उपयोग करता है। छोटे सेटों के साथ अंतर शायद नगण्य है, लेकिन ऑन-डिस्क स्पूल की लागत निश्चित रूप से अधिक स्पष्ट हो सकती है क्योंकि सेट बड़े हो जाते हैं। मैं अंत को खराब नहीं करना चाहता, लेकिन आपको संदेह हो सकता है कि इनमें से एक समाधान अधिक गहन परीक्षण में दूसरे की तुलना में बेहतर प्रदर्शन करेगा।
एक तरफ, क्वेरी का निम्न संस्करण समान परिणाम देता है, लेकिन ऊपर के धीमे RANGE संस्करण की तरह काम करता है:
चुनें [दिनांक], टिकट गणना, एसयूएम (टिकट गणना) ओवर ([दिनांक] के अनुसार आदेश) डीबीओ से।इसलिए जब आप नए विंडोिंग फ़ंक्शंस के साथ खेल रहे हैं, तो आप इस तरह की छोटी-छोटी बातों को ध्यान में रखना चाहेंगे:किसी क्वेरी का संक्षिप्त संस्करण, या जिसे आपने पहले लिखा है, जरूरी नहीं कि वह वही हो जो आप चाहते हैं उत्पादन को आगे बढ़ाने के लिए।
वास्तविक परीक्षण
निष्पक्ष परीक्षण करने के लिए, मैंने प्रत्येक दृष्टिकोण के लिए एक संग्रहीत प्रक्रिया बनाई, और एक सर्वर पर बयानों को कैप्चर करके परिणामों को मापा, जहां मैं पहले से ही SQL संतरी के साथ निगरानी कर रहा था (यदि आप हमारे उपकरण का उपयोग नहीं कर रहे हैं, तो आप SQL:BatchCompleted ईवेंट एकत्र कर सकते हैं) इसी तरह SQL सर्वर प्रोफाइलर का उपयोग करके)।
"निष्पक्ष परीक्षण" से मेरा मतलब है कि, उदाहरण के लिए, विचित्र अद्यतन विधि को स्थिर डेटा के लिए एक वास्तविक अद्यतन की आवश्यकता होती है, जिसका अर्थ है अंतर्निहित स्कीमा को बदलना या एक अस्थायी तालिका/तालिका चर का उपयोग करना। इसलिए मैंने संग्रहित प्रक्रियाओं को प्रत्येक के लिए अपनी तालिका चर बनाने के लिए संरचित किया, और या तो वहां परिणाम संग्रहीत किए, या कच्चे डेटा को वहां संग्रहीत किया और फिर परिणाम अपडेट किया। दूसरा मुद्दा जिसे मैं समाप्त करना चाहता था वह क्लाइंट को डेटा लौटा रहा था - इसलिए प्रक्रियाओं में प्रत्येक के पास डीबग पैरामीटर होता है जो निर्दिष्ट करता है कि कोई परिणाम नहीं (डिफ़ॉल्ट), ऊपर/नीचे 5, या सभी वापस करना है या नहीं। प्रदर्शन परीक्षणों में मैंने इसे कोई परिणाम नहीं लौटाने के लिए सेट किया, लेकिन निश्चित रूप से यह सुनिश्चित करने के लिए प्रत्येक को मान्य किया कि वे सही परिणाम लौटा रहे हैं।
संग्रहीत कार्यविधियाँ सभी इस तरह से बनाई गई हैं (मैंने एक स्क्रिप्ट संलग्न की है जो डेटाबेस और संग्रहीत कार्यविधियाँ बनाती है, इसलिए मैं यहाँ संक्षिप्तता के लिए एक टेम्पलेट शामिल कर रहा हूँ):
CREATE PROCEDURE [dbo].[RunningTotals_] @debug TINYINT =0 -- @debug =1:शो टॉप/बॉटम 3 -- @debug =2 :सभी 50kASBEGIN SET NOCOUNT ON दिखाएं; DECLARE @st TABLE ( [दिनांक] दिनांक प्राथमिक कुंजी, टिकटकाउंट INT, रनिंग टोटल INT); INSERT @st ([दिनांक], टिकटकाउंट, रनिंग टोटल) - @t IF @debug =1 को पॉप्युलेट करने के लिए उपयोग किए जाने वाले सात दृष्टिकोणों में से एक - परिणामों को सत्यापित करने के लिए शीर्ष 3 और अंतिम 3 दिखाएं; d AS के साथ (चुनें [दिनांक], टिकटकाउंट, रनिंगटोटल, आरएन =ROW_NUMBER () ओवर ([दिनांक तक ऑर्डर करें) @st से) चुनें [दिनांक], टिकटकाउंट, रनिंग टोटल जहां से आरएन <4 या आरएन> 9997 ऑर्डर द्वारा [दिनांक]; END IF @debug =2 -- सभी BEGIN SELECT [Date], TicketCount, RunTotal FROM @st ORDER by [Date] दिखाएं; ENDENDGOऔर मैंने उन्हें एक बैच में इस प्रकार बुलाया:
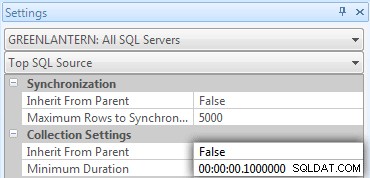
EXEC dbo.RunningTotals_DateCTE @debug =0;GOEXEC dbo.RunningTotals_Cursor @debug =0;GOEXEC dbo.RunningTotals_Subquery @debug =0;GOEXEC dbo.RunningTotals_InnerdateGOEXDEbug =0; .RunningTotals_Windowed_Range @debug =0;GOEXEC dbo.RunningTotals_Windowed_Rows @debug =0;GOमुझे जल्दी से एहसास हुआ कि इनमें से कुछ कॉल टॉप एसक्यूएल में नहीं दिख रहे थे क्योंकि डिफ़ॉल्ट थ्रेशोल्ड 5 सेकंड है। मैंने इसे 100 मिलीसेकंड में बदल दिया (कुछ ऐसा जो आप कभी भी उत्पादन प्रणाली पर नहीं करना चाहते!) निम्नानुसार है:
मैं दोहराऊंगा:इस व्यवहार को उत्पादन प्रणालियों के लिए माफ नहीं किया जाता है!
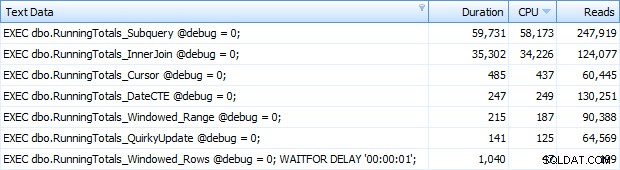
मैंने अभी भी पाया कि ऊपर दिए गए आदेशों में से एक शीर्ष SQL थ्रेशोल्ड द्वारा पकड़ा नहीं जा रहा था; यह Windowed_Rows संस्करण था। इसलिए मैंने निम्नलिखित को केवल उस बैच में जोड़ा:
EXEC dbo.RunningTotals_Windowed_Rows @debug =0;WAITFOR DELAY '00:00:01';GOऔर अब मुझे शीर्ष SQL में सभी 7 पंक्तियाँ वापस मिल रही थीं। यहां उन्हें CPU उपयोग द्वारा अवरोही क्रम में क्रमबद्ध किया गया है:
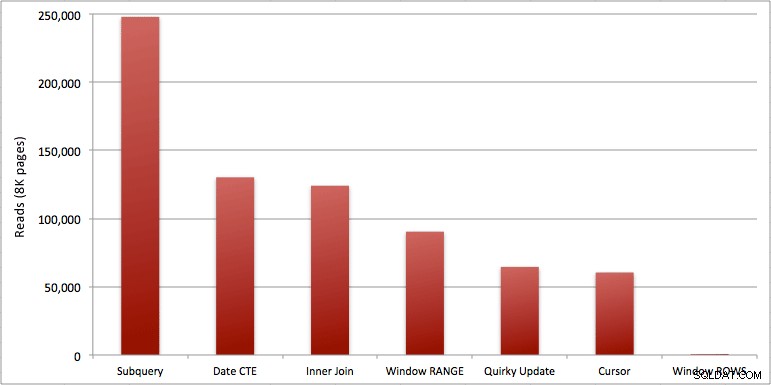
आप Windowed_Rows बैच में मेरे द्वारा जोड़े गए अतिरिक्त सेकंड को देख सकते हैं; यह शीर्ष SQL थ्रेशोल्ड द्वारा पकड़ा नहीं जा रहा था क्योंकि यह केवल 40 मिलीसेकंड में पूरा हुआ! यह स्पष्ट रूप से हमारा सर्वश्रेष्ठ प्रदर्शन है और, यदि हमारे पास SQL सर्वर 2012 उपलब्ध है, तो यह वह तरीका होना चाहिए जिसका हम उपयोग करते हैं। शेष समाधानों के साथ प्रदर्शन या अन्य मुद्दों को देखते हुए, कर्सर आधा-खराब नहीं है। एक ग्राफ पर अवधि को प्लॉट करना बहुत ही अर्थहीन है - दो उच्च बिंदु और पांच अलग-अलग निम्न बिंदु। लेकिन अगर I/O आपकी अड़चन है, तो आपको पढ़ने का विज़ुअलाइज़ेशन दिलचस्प लग सकता है:
निष्कर्ष
इन परिणामों से हम कुछ निष्कर्ष निकाल सकते हैं:
- एसक्यूएल सर्वर 2012 में विंडोड एग्रीगेट्स रनिंग टोटल कंप्यूटेशंस (और कई अन्य अगली पंक्ति (पंक्तियों) / पिछली पंक्ति (समस्याओं) की समस्याओं) के साथ प्रदर्शन के मुद्दों को खतरनाक रूप से अधिक कुशल बनाते हैं। जब मैंने कम संख्या में पठन देखा तो मुझे लगा कि निश्चित रूप से कोई गलती है, कि मैं वास्तव में कोई भी काम करना भूल गया हूँ। लेकिन नहीं, यदि आपकी संग्रहीत प्रक्रिया स्पीडिंग टिकट तालिका से सामान्य चयन करती है तो आपको समान संख्या में पढ़ा जाता है। (सांख्यिकी IO के साथ स्वयं इसका परीक्षण करने के लिए स्वतंत्र महसूस करें।)
- जिन मुद्दों को मैंने पहले RANGE बनाम ROWS के बारे में बताया था, वे थोड़े अलग रनटाइम उत्पन्न करते हैं (लगभग 6x का अवधि अंतर - दूसरे को अनदेखा करना याद रखें जिसे मैंने WAITFOR के साथ जोड़ा था), लेकिन ऑन-डिस्क स्पूल के कारण पढ़ने के अंतर खगोलीय हैं। यदि ROWS का उपयोग करके आपके विंडोड एग्रीगेट को हल किया जा सकता है, तो RANGE से बचें, लेकिन आपको यह जांचना चाहिए कि दोनों एक ही परिणाम देते हैं (या कम से कम ROWS सही उत्तर देता है)। आपको यह भी ध्यान रखना चाहिए कि यदि आप एक समान क्वेरी का उपयोग कर रहे हैं और आप RANGE या ROWS निर्दिष्ट नहीं करते हैं, तो योजना ऐसे काम करेगी जैसे कि आपने RANGE निर्दिष्ट किया हो)।
- सबक्वायरी और इनर जॉइन के तरीके अपेक्षाकृत कम हैं। इन चल रहे योगों को उत्पन्न करने के लिए 35 सेकंड से एक मिनट तक? और यह ग्राहक को परिणाम लौटाए बिना एकल, पतली मेज पर था। इन तुलनाओं का उपयोग लोगों को यह दिखाने के लिए किया जा सकता है कि एक विशुद्ध रूप से सेट-आधारित समाधान हमेशा सबसे अच्छा उत्तर क्यों नहीं होता है।
- तेज़ तरीकों में, यह मानते हुए कि आप अभी तक SQL Server 2012 के लिए तैयार नहीं हैं, और यह मानते हुए कि आप विचित्र अद्यतन विधि (असमर्थित) और CTE दिनांक विधि (एक सन्निहित अनुक्रम की गारंटी नहीं दे सकते) दोनों को त्याग देते हैं, केवल कर्सर ही प्रदर्शन करता है स्वीकार्य रूप से। इसमें "तेज़" समाधानों की उच्चतम अवधि है, लेकिन पढ़ने की मात्रा कम है।
मुझे उम्मीद है कि ये परीक्षण Microsoft द्वारा SQL Server 2012 में जोड़े गए विंडोिंग एन्हांसमेंट के लिए बेहतर प्रशंसा देने में मदद करते हैं। कृपया इत्ज़िक को धन्यवाद देना सुनिश्चित करें यदि आप उसे ऑनलाइन या व्यक्तिगत रूप से देखते हैं, क्योंकि वह इन परिवर्तनों के पीछे प्रेरक शक्ति था। इसके अलावा, मुझे आशा है कि इससे कुछ दिमागों को खोलने में मदद मिलेगी कि एक कर्सर हमेशा बुरा और भयानक समाधान नहीं हो सकता है जिसे अक्सर दर्शाया जाता है।
(एक परिशिष्ट के रूप में, मैंने Pavel Pawlowski द्वारा पेश किए गए CLR फ़ंक्शन का परीक्षण किया था, और प्रदर्शन विशेषताएँ ROWS का उपयोग करते हुए SQL Server 2012 समाधान के लगभग समान थीं। रीड समान थे, CPU 78 बनाम 47 था, और समग्र अवधि 73 के बजाय थी 40. इसलिए यदि आप निकट भविष्य में SQL Server 2012 में नहीं जा रहे हैं, तो आप अपने परीक्षणों में पावेल का समाधान जोड़ना चाह सकते हैं।)
अटैचमेंट:RunTotals_Demo.sql.zip (2kb)