“Waitstats हमें प्रदर्शन-संबंधी काउंटरों की पहचान करने में मदद करता है। लेकिन वेटिंग जानकारी अपने आप में प्रदर्शन समस्याओं का सटीक निदान करने के लिए पर्याप्त नहीं है। हमारी कार्यप्रणाली का क्यू घटक प्रदर्शन मॉनिटर काउंटरों से आता है, जो संसाधन के दृष्टिकोण से सिस्टम के प्रदर्शन का एक दृश्य प्रदान करते हैं।"टॉम डेविडसन, Microsoft का प्रदर्शन-ट्यूनिंग टूलबॉक्स खोलना
SQL सर्वर प्रो पत्रिका, दिसंबर 2003
जब टॉम डेविडसन ने उपरोक्त लेख के साथ-साथ 2006 में प्रसिद्ध SQL सर्वर 2005 प्रतीक्षा और कतार श्वेतपत्र प्रकाशित किया था, तब से प्रतीक्षा और कतार का उपयोग SQL सर्वर प्रदर्शन ट्यूनिंग पद्धति के रूप में किया गया है। जब संसाधन मेट्रिक्स के साथ संयोजन में लागू किया जाता है, तो प्रतीक्षा के लिए मूल्यवान हो सकता है कार्यभार की कुछ प्रदर्शन विशेषताओं का आकलन करना और ट्यूनिंग प्रयासों को चलाने में सहायता करना। कई SQL सर्वर प्रदर्शन निगरानी समाधानों द्वारा प्रतीक्षा डेटा सामने आया है, और मैं शुरू से ही इस पद्धति का उपयोग करने के लिए ट्यूनिंग का समर्थक रहा हूं। SQL संतरी प्रदर्शन डैशबोर्ड के डिज़ाइन में यह दृष्टिकोण प्रभावशाली था, जो सर्वर के प्रदर्शन का एक व्यापक दृश्य देने के लिए कतारों (प्रमुख संसाधन मेट्रिक्स) द्वारा प्रतीक्षारत प्रस्तुत करता है।
हालांकि, कुछ लोग संसाधनों के महत्व के बारे में डेविडसन की बात से चूक गए हैं और क्वेरी प्रदर्शन और सिस्टम स्वास्थ्य की एक तस्वीर पेश करने के लिए लगभग पूरी तरह से प्रतीक्षा पर भरोसा करते हैं। प्रतीक्षा आँकड़े सीधे SQL सर्वर इंजन से आते हैं और उपभोग और श्रेणीबद्ध करने में आसान होते हैं। प्रतीक्षारत प्रश्नों का अर्थ है प्रतीक्षारत एप्लिकेशन और उपयोगकर्ता, और कोई भी प्रतीक्षा करना पसंद नहीं करता है! वेट के साथ ट्यूनिंग को इंजील करना आसान है क्योंकि प्रश्नों और अनुप्रयोगों को तेजी से बनाने के लिए एकवचन समाधान के रूप में पूरी कहानी बताने की तुलना में अधिक है, जो अधिक शामिल है।
दुर्भाग्य से, संसाधन विश्लेषण के बहिष्करण के लिए एक प्रतीक्षा-केंद्रित दृष्टिकोण गुमराह कर सकता है, और सबसे खराब स्थिति आपको अंधा बना देती है। SentryOne टीम के सदस्य केविन क्लाइन और स्टीव राइट पहले इस पर यहाँ और यहाँ स्पर्श कर चुके हैं। इस पोस्ट में मैं क्वेरी स्टोर द्वारा संभव किए गए कुछ हालिया शोध में गहराई से गोता लगाने जा रहा हूं, जिसने इस बात पर नई रोशनी डाली है कि कैसे कम प्रतीक्षा-अनन्य ट्यूनिंग वास्तव में हो सकती है।
प्रमुख क्वेरी जो नहीं थीं
हाल ही में, एक SentryOne ग्राहक ने अपने SentryOne डेटाबेस के प्रदर्शन संबंधी चिंताओं के बारे में मुझसे संपर्क किया। प्रत्येक SentryOne निगरानी वातावरण के केंद्र में एक एकल SQL सर्वर डेटाबेस है, और यह ग्राहक हमारे सॉफ़्टवेयर के साथ लगभग 600 सर्वरों की निगरानी कर रहा था। उस पैमाने पर कभी-कभी क्वेरी प्रदर्शन समस्या को देखना और थोड़ा ट्यूनिंग करना असामान्य नहीं है, और कार्यभार में कुछ नए प्रश्न उनकी चिंता का स्रोत थे।
मैं देखने के लिए एक स्क्रीन-शेयर सत्र में शामिल हुआ, और ग्राहक ने पहले मुझे एक अलग सिस्टम से डेटा प्रस्तुत किया जो सेंट्रीऑन डेटाबेस की निगरानी भी कर रहा था। सिस्टम ने एक क्वेरी-स्तरीय प्रतीक्षा दृष्टिकोण का उपयोग किया और SQL संतरी डेटाबेस सर्वर पर लगभग आधे प्रतीक्षा के लिए जिम्मेदार के रूप में दो संग्रहीत कार्यविधियों को दिखाया। यह असामान्य था क्योंकि ये दो प्रक्रियाएं हमेशा बहुत तेज़ी से चलती हैं और कभी भी हमारे डेटाबेस में वास्तविक प्रदर्शन समस्या का संकेत नहीं देती हैं। हैरान, मैंने यह देखने के लिए SQL संतरी पर स्विच किया कि यह हमें क्या दिखाएगा, और यह देखकर आश्चर्य हुआ कि उसी अंतराल पर अन्य सिस्टम में # 1 प्रक्रिया # 6, # 7 और # 8 कुल अवधि के संदर्भ में थी, CPU और तार्किक क्रमशः पढ़ता है:
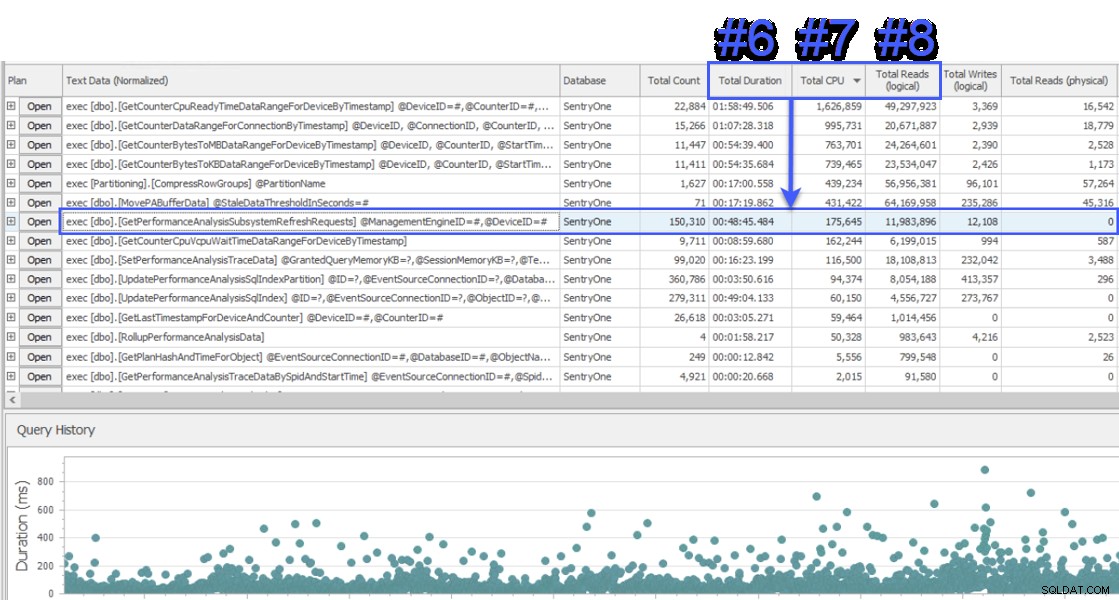 SQL संतरी का "शीर्ष SQL" दृश्य
SQL संतरी का "शीर्ष SQL" दृश्य
संसाधन खपत के दृष्टिकोण से, इसका मतलब है कि इसके ऊपर के प्रश्न कुल अवधि का 75%, कुल CPU का 87% और तार्किक पढ़ने का 88% प्रतिनिधित्व करते हैं। इसके अलावा, अन्य सिस्टम में #2 प्रक्रिया किसी भी उपाय से SQL संतरी में शीर्ष 30 में भी नहीं थी! ये दो प्रश्न शीर्ष 2 से बहुत दूर थे, और वे प्रश्न जो अधिकांश वास्तविक के लिए जिम्मेदार थे सिस्टम पर खपत का बहुत कम प्रतिनिधित्व किया जा रहा था।
मैंने हमेशा माना था कि शीर्ष वेटर्स और शीर्ष संसाधन उपभोक्ताओं के बीच एक मजबूत संबंध था, लेकिन इस तरह की प्रत्यक्ष क्वेरी-स्तर की तुलना कभी नहीं की थी, इसलिए ये परिणाम कम से कम कहने के लिए आश्चर्यजनक थे। मेरी रुचि बढ़ गई, मैंने यह निर्धारित करने के लिए जांच करने का निर्णय लिया कि यह स्थिति विशिष्ट थी या विषम।
बचाव के लिए क्वेरी स्टोर 2017
SQL सर्वर 2017 और इसके बाद के संस्करण में, क्वेरी स्टोर क्वेरी संसाधन खपत के अलावा क्वेरी-स्तर प्रतीक्षा को कैप्चर करता है। एरिन स्टेलेटो ने यहां क्वेरी स्टोर वेट पर एक बेहतरीन पोस्ट की। यह कम ओवरहेड है और पूछताछ की तुलना में अधिक सटीक है, डीएमवी हर सेकेंड इन-फ्लाइट प्रश्नों को पकड़ने की उम्मीद करते हैं, उपरोक्त एक सहित अन्य उपकरणों द्वारा उपयोग किए जाने वाले मानक दृष्टिकोण।
ओवरहेड और सटीकता के बारे में इन चिंताओं के कारण SQL संतरी ने हमेशा प्रतीक्षा पर कब्जा कर लिया है लेकिन SQL सर्वर आवृत्ति स्तर पर। एकीकृत प्लान एक्सप्लोरर के माध्यम से मांग पर विस्तृत क्वेरी प्रतीक्षा उपलब्ध हैं, और हम उपलब्ध होने पर क्वेरी स्टोर से क्वेरी-स्तरीय डेटा के साथ इंस्टेंस-स्तरीय प्रतीक्षा को बढ़ाने का मूल्यांकन कर रहे हैं।
इस प्रयास के लिए मैंने SentryOne उत्पाद सलाहकार परिषद, SentryOne ग्राहकों, भागीदारों और उद्योग में दोस्तों के एक समूह की मदद ली, जो एक निजी स्लैक चैनल में भाग लेते हैं। मैंने क्वेरी स्टोर से पिछले 8 घंटों के डेटा को डंप करने के लिए इस स्क्रिप्ट को साझा किया और वित्तीय सेवाओं, गेम प्रकाशन, फिटनेस ट्रैकिंग और बीमा सहित कई वर्टिकल में 11 उत्पादन सर्वरों के लिए परिणाम प्राप्त किए।
क्वेरी स्टोर प्रतीक्षा श्रेणियां यहां प्रलेखित हैं। इनके अलावा सभी श्रेणियों को विश्लेषण में शामिल किया गया था, जिन्हें उद्धृत कारणों से हटा दिया गया था:
- समानता - यह किसी क्वेरी के प्रतीक्षा समय को उसकी वास्तविक अवधि से काफी बढ़ा सकता है क्योंकि कई थ्रेड संबंधित प्रतीक्षा को बंद कर सकते हैं, अवधि और अन्य मेट्रिक्स के साथ सहसंबंध को भ्रमित कर सकते हैं। इसके अलावा, हालांकि CXPACKET/CXCONSUMER विभाजन सहायक है, CXPACKET का अभी भी केवल यही अर्थ है कि आपके पास समानता है और यह आवश्यक रूप से समस्याग्रस्त या कार्रवाई योग्य नहीं है।
- सीपीयू - संसाधन प्रतीक्षा के साथ सहसंबंध के माध्यम से CPU बाधाओं का पता लगाने के लिए सिग्नल प्रतीक्षा समय सहायक हो सकता है, लेकिन क्वेरी स्टोर में वर्तमान में इस श्रेणी में केवल SOS_SCHEDULER_YIELD शामिल है, जो पारंपरिक अर्थों में प्रतीक्षा नहीं है जैसा कि यहां कवर किया गया है। यह आसान तुलना या सहसंबंध के लिए खुद को उधार नहीं देता है, खासकर जब SQL सर्वर एक VM पर होता है जो एक ओवर-सब्सक्राइब्ड होस्ट पर रहता है। उदाहरण के लिए, एक सर्वर पर क्वेरी स्टोर सीपीयू प्रतीक्षा बिना किसी समानता के सभी प्रश्नों में कुल सीपीयू समय का 227% था, जो संभव नहीं होना चाहिए।
- उपयोगकर्ता प्रतीक्षा करें और निष्क्रिय - इन श्रेणियों में विशेष रूप से टाइमर और कतार प्रतीक्षा शामिल हैं और इसी कारण से बाहर रखा गया था कि किसी को हमेशा इन प्रकारों को बाहर करना चाहिए - वे सहज हैं और केवल शोर पैदा करते हैं।
एक तरफ के रूप में, मैंने हाल ही में क्वेरी स्टोर के पिता, कॉनर कनिंघम के साथ, क्वेरी स्टोर प्रतीक्षा प्रकारों और श्रेणियों में भविष्य के परिवर्तनों की संभावना के बारे में बात की और उन्होंने संकेत दिया कि यह निश्चित रूप से संभव था ... इसलिए हमें इस पर नज़र रखने की आवश्यकता होगी यह।
विश्लेषण परिणाम TL;DR
व्यापक विश्लेषण के बाद, मैंने पुष्टि की है कि ग्राहक प्रणाली पर देखे गए परिणाम विषम नहीं हैं, बल्कि सामान्य हैं। इसका मतलब यह है कि यदि आप अपने कार्यभार की निगरानी और ट्यूनिंग के लिए प्रतीक्षा-केंद्रित टूल पर निर्भर हैं, तो इस बात की बहुत अधिक संभावना है कि आप गलत प्रश्नों पर ध्यान केंद्रित कर रहे हैं और अधिकांश के लिए जिम्मेदार लोगों को याद कर रहे हैं। एक सिस्टम पर क्वेरी अवधि और संसाधन खपत का। चूंकि CPU और IO की खपत सीधे सर्वर हार्डवेयर और क्लाउड खर्च में बदल जाती है, यह महत्वपूर्ण है।
अधिकांश प्रश्न प्रतीक्षा नहीं करते
एक दिलचस्प और महत्वपूर्ण खोज जो मैं सबसे पहले कवर करूंगा वह यह है कि अधिकांश प्रश्न किसी भी तरह की प्रतीक्षा नहीं करते हैं। सभी सर्वरों पर कुल 56,438 प्रश्नों में से केवल 9,781 (17%) के पास कोई प्रतीक्षा समय था, और केवल 8,092 (14%) के पास महत्वपूर्ण प्रकारों से प्रतीक्षा समय था। यदि आप यह निर्धारित करने के लिए अकेले प्रतीक्षा का उपयोग कर रहे हैं कि किन प्रश्नों को अनुकूलित करना है, तो आप कार्यभार में अधिकांश प्रश्नों से चूक जाएंगे।
सहसंबद्ध प्रतीक्षा और संसाधन
मैंने विश्लेषण किया कि प्रतीक्षा और संसाधनों द्वारा प्रत्येक सिस्टम पर सभी प्रश्नों को रैंक करके और स्पीयरमैन के सहसंबंध की गणना करने के लिए रैंकों का उपयोग करके संसाधन खपत से कैसे संबंधित है। हम अंततः यह निर्धारित करने की कोशिश कर रहे हैं कि क्या शीर्ष वेटर शीर्ष उपभोक्ता हैं। जैसा कि यह पता चला है, वे नहीं करते हैं।
तालिका 1 औसत क्वेरी प्रतीक्षा . के लिए रंग-स्केल किए गए सहसंबंध गुणांक दिखाता है समय अन्य उपायों के लिए - 1.00 का मान (गहरा नीला) डेटा का प्रतिनिधित्व करता है जो पूरी तरह से सहसंबद्ध है। जैसा कि आप देख सकते हैं, अधिकांश सर्वरों पर प्रतीक्षा और अन्य उपायों के साथ संबंध मजबूत नहीं है, और एक सर्वर के लिए अधिकांश उपायों के साथ एक नकारात्मक सहसंबंध है।
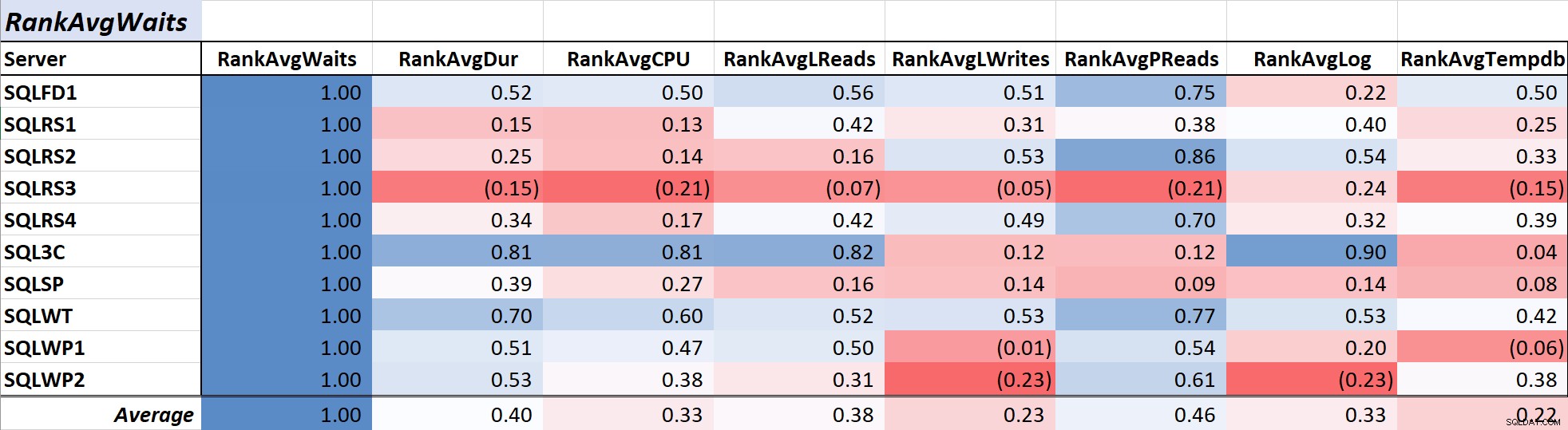 तालिका 1:औसत क्वेरी प्रतीक्षा समय (ms) के साथ सहसंबंध
तालिका 1:औसत क्वेरी प्रतीक्षा समय (ms) के साथ सहसंबंध
क्वेरी अवधि अक्सर डीबीए और डेवलपर्स के लिए एक प्राथमिक चिंता का विषय होती है क्योंकि यह सीधे उपयोगकर्ता अनुभव और तालिका 2 में बदल जाती है। औसत क्वेरी अवधि . के बीच के संबंध को दर्शाता है और अन्य उपाय। अवधि और दो प्राथमिक संसाधन उपायों, सीपीयू और तार्किक रीडिंग के साथ सहसंबंध, क्रमशः .97 और .75 पर काफी मजबूत है।
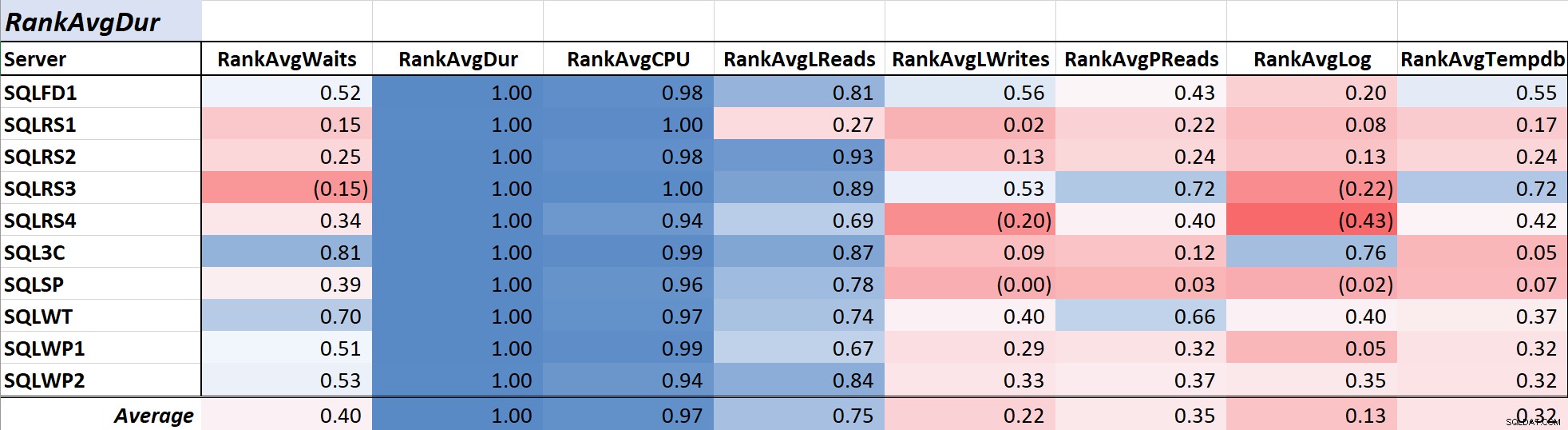 तालिका 2:औसत क्वेरी अवधि (ms) के साथ सहसंबंध
तालिका 2:औसत क्वेरी अवधि (ms) के साथ सहसंबंध
चूंकि तार्किक रीड हमेशा सीपीयू का उपयोग करते हैं, और, अवधि की तरह, सीपीयू को मिलीसेकंड में मापा जाता है, यह संबंध आश्चर्यजनक नहीं है। परिणाम इस विचार के अनुरूप हैं कि यदि आप चाहते हैं कि आपके डेटाबेस एप्लिकेशन जितनी जल्दी हो सके, क्वेरी सीपीयू को कम करने पर ध्यान केंद्रित करें और लॉजिकल रीड अकेले प्रतीक्षा की तुलना में अवधि को कम करने में अधिक प्रभावी होंगे। सौभाग्य से, बेहतर क्वेरी डिज़ाइन, अनुक्रमण, आदि के माध्यम से ऐसा करना आमतौर पर क्वेरी प्रतीक्षा समय को सीधे कम करने की तुलना में अधिक सीधा प्रस्ताव है। सहकर्मी आरोन बर्ट्रेंड यहां प्रतीक्षा के साथ ट्यूनिंग करते समय कुछ चेतावनियों को प्रभावी ढंग से प्रस्तुत करते हैं।
कुल प्रतीक्षा समय का%
इसके बाद, मैंने देखा कि क्या उच्चतम प्रतीक्षा समय वाले प्रश्न सबसे अधिक संसाधन खपत के लिए जिम्मेदार हैं। हम यह निर्धारित करना चाहते हैं कि क्या हमने ग्राहक प्रणाली पर जो देखा वह असामान्य है, जहां शीर्ष 2 प्रतीक्षा क्वेरी कुल संसाधन खपत का अपेक्षाकृत कम प्रतिशत दर्शाती हैं।
चार्ट 1 नीचे कुल सीपीयू का% दिखाता है और प्रत्येक सर्वर के लिए तार्किक रीड कुल प्रतीक्षा समय के 75% का प्रतिनिधित्व करने वाले प्रश्नों के लिए जिम्मेदार है। केवल एक सर्वर का संसाधन 75% से अधिक था - SQLRS3 पर पढ़ता है। बाकी के लिए, 75% प्रतीक्षा समय के लिए ज़िम्मेदार प्रश्नों ने 75% से कम संसाधनों का उपभोग किया - अक्सर बहुत कम। यह दर्शाता है कि हमने ग्राहक प्रणाली पर क्या देखा और सहसंबंध विश्लेषण के अनुरूप है।
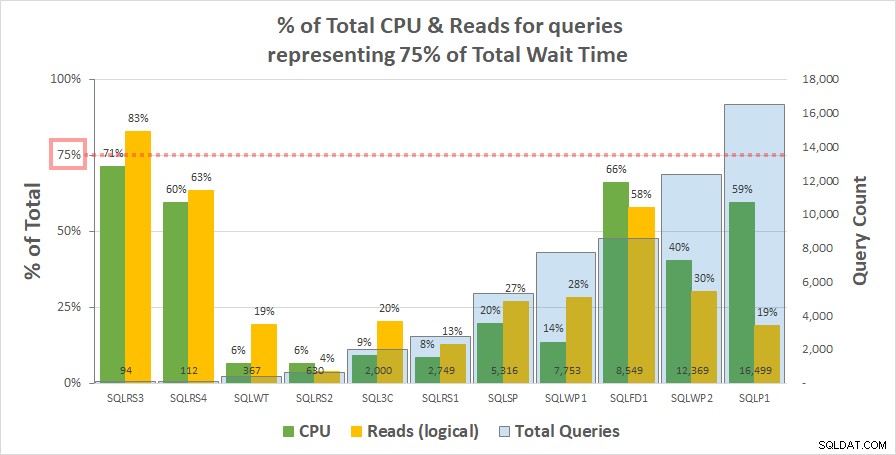 चार्ट 1
चार्ट 1
ध्यान दें कि कार्यभार में प्रश्नों की कुल संख्या के साथ संबंध प्रतीत होता है। इसे द्वितीयक y-अक्ष पर हल्के नीले स्तंभ श्रृंखला द्वारा दर्शाया जाता है और चार्ट को इस श्रृंखला द्वारा आरोही क्रम में लगाया जाता है। 75% प्रतीक्षा में उच्चतम संसाधन उपायों वाले दो सर्वरों में भी सबसे कम प्रश्न (SQLRS3 और SQLRS4) थे। कार्यभार जितना छोटा होता है, प्रश्नों की एक छोटी संख्या का संभावित प्रभाव उतना ही अधिक होता है, और निश्चित रूप से पर्याप्त होता है, दोनों सर्वरों पर अधिकांश प्रतीक्षा और संसाधनों के लिए केवल दो प्रश्नों का हिसाब होता है। इसे देखने का एक तरीका यह है कि जब आपको कम से कम इसकी आवश्यकता हो, तो आपके सबसे भारी प्रश्नों की पहचान करने के लिए प्रतीक्षा सबसे अधिक मदद करती है।
प्रतीक्षा समय और क्वेरी अवधि
अंत में, मैंने प्रत्येक सिस्टम पर कुल क्वेरी अवधि के लिए कुल प्रतीक्षा समय के% का मूल्यांकन किया। तालिका 3 इसके लिए कॉलम हैं:
- कुल क्वेरी अवधि एमएस में
- कुल प्रतीक्षा समय एमएस - कच्चा
- कुल प्रतीक्षा समय एमएस - समानांतरवाद, निष्क्रिय और उपयोगकर्ता प्रतीक्षा के बिना (Rev1)
- कुल प्रतीक्षा समय एमएस - समानांतरवाद के बिना, निष्क्रिय, उपयोगकर्ता प्रतीक्षा और सीपीयू (Rev2)
- डेटा बार के साथ 3 प्रतीक्षा समय कॉलम की अवधि का%
- डेटा बार के साथ कुल अद्वितीय क्वेरी संख्या
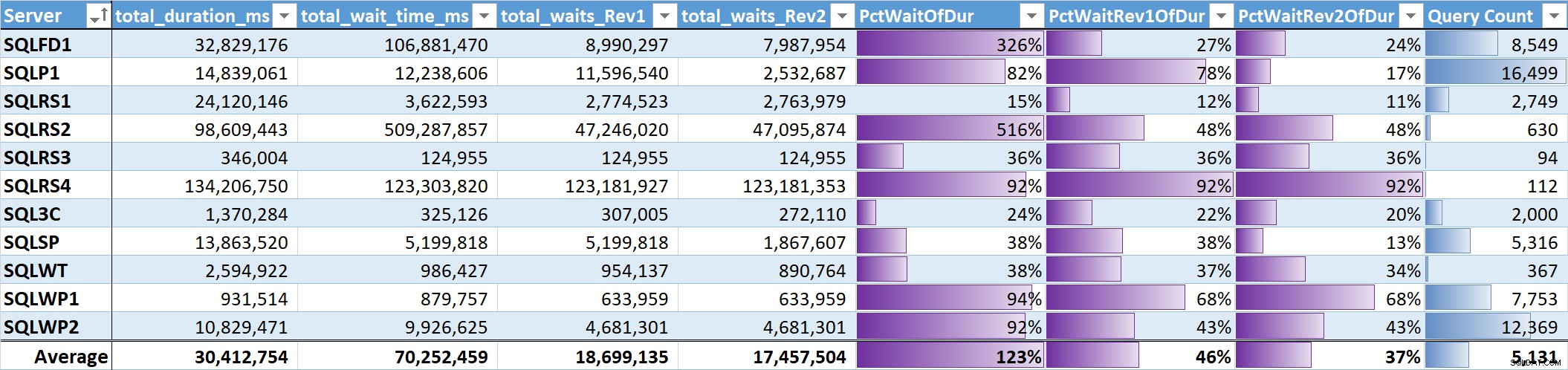 तालिका 3
तालिका 3
सार्थक प्रतीक्षा . के लिए भारित औसत (Rev2) सभी प्रणालियों में कुल क्वेरी अवधि का 37% है। पांच प्रणालियों में यह 25% से कम थी, और केवल दो प्रणालियों पर यह 50% से ऊपर थी। सिस्टम पर 92% प्रतीक्षा समय (एसक्यूएलआरएस4) के साथ, सबसे कम प्रश्नों वाला एक, दो प्रश्नों में 99% प्रतीक्षा, 97% अवधि, 84% सीपीयू, और 86% रीड्स शामिल हैं।
हालांकि प्रतीक्षा समय कुछ सिस्टम पर क्वेरी रनटाइम के एक महत्वपूर्ण हिस्से का प्रतिनिधित्व कर सकता है, और यह सहज लगता है कि यदि आप प्रतीक्षा समय को कम करते हैं तो क्वेरी अवधि भी कम हो जाएगी, हमने देखा है कि प्रतीक्षा समय और अवधि कमजोर रूप से सहसंबद्ध हैं। यह इतना आसान होने की संभावना नहीं है, और मेरा अपना अनुभव इसकी पुष्टि करता है। यहां और शोध की जरूरत है।
प्लान एक्सप्लोरर और एसक्यूएल संतरी के साथ व्यापक ट्यूनिंग
जैसा कि यह उत्कृष्ट SQLskills श्वेतपत्र अक्सर सुझाव देता है, उच्च प्रतीक्षा की जड़ अक्सर अडॉप्टिमाइज्ड क्वेरी और इंडेक्स होती है। मुफ़्त SentryOne Plan Explorer अपने इंडेक्स एनालिसिस मॉड्यूल और कई अन्य नवीन सुविधाओं का उपयोग करके कुशल क्वेरी ट्यूनिंग के माध्यम से संसाधन खपत को कम करने के उद्देश्य से बनाया गया है। एसक्यूएल संतरी प्लान एक्सप्लोरर को सीधे शीर्ष एसक्यूएल, ब्लॉकिंग और डेडलॉक मॉड्यूल में एकीकृत करता है, ताकि आप एक ही स्थान पर समस्याग्रस्त प्रश्नों को स्वचालित रूप से कैप्चर और ट्यून कर सकें। आप SQL संतरी डैशबोर्ड के ऐतिहासिक प्रतीक्षा, CPU, या IO चार्ट पर आसानी से रुचि की एक श्रेणी का चयन कर सकते हैं और उस समय के दौरान शीर्ष संसाधन-खपत प्रश्नों को खोजने के लिए शीर्ष SQL दृश्य पर जा सकते हैं। फिर एक क्लिक से आप प्लान एक्सप्लोरर में एक क्वेरी खोल सकते हैं और विस्तृत क्वेरी-स्तरीय प्रतीक्षा प्राप्त कर सकते हैं और जरूरत पड़ने पर मांग पर संसाधन। मुझे नहीं लगता कि पूर्ण प्रतीक्षा और कतार ट्यूनिंग पद्धति का इससे बेहतर अवतार कोई हो सकता है।
 SQL संतरी डैशबोर्ड "वेट्स" चार्ट
SQL संतरी डैशबोर्ड "वेट्स" चार्ट
 संचालन-स्तर के साथ-साथ समय के साथ प्रतीक्षा दिखाने वाला निःशुल्क सेंट्रीवन प्लान एक्सप्लोरर लागत और संसाधन
संचालन-स्तर के साथ-साथ समय के साथ प्रतीक्षा दिखाने वाला निःशुल्क सेंट्रीवन प्लान एक्सप्लोरर लागत और संसाधन
निष्कर्ष
प्रतीक्षा और कतारों के साथ ट्यूनिंग आज भी SQL सर्वर के प्रदर्शन के लिए लागू है जैसा कि यह 2006 में वापस था। हालांकि, संसाधनों के बहिष्करण के लिए प्रतीक्षा पर ध्यान केंद्रित करना खतरनाक व्यवसाय है, क्योंकि यह डेटा से स्पष्ट है कि ऐसा करने से आम तौर पर अडॉप्टिमाइज्ड हो जाएगा और लागत-अक्षम प्रणाली। जब हार्डवेयर संसाधनों और क्लाउड खर्च की बात आती है, तो आप अंततः कंप्यूट और आईओ संसाधनों के लिए भुगतान कर रहे हैं, प्रतीक्षा समय नहीं, इसलिए उपभोग के लिए सीधे अनुकूलन करना समीचीन है। मेरे अनुभव में, जैसे-जैसे संसाधन की खपत और संबंधित विवाद कम होता जाएगा, प्रतीक्षा समय कम होना स्वाभाविक रूप से होगा।
पावती
मैं सेंट्रीऑन के लीड डेटा साइंटिस्ट फ्रेड फ्रॉस्ट को उनके बहुमूल्य इनपुट और इस विश्लेषण की आलोचनात्मक समीक्षा के लिए धन्यवाद देना चाहता हूं।



