यह साबित करना बहुत आसान है कि निम्नलिखित दो भाव एक ही परिणाम देते हैं:चालू माह का पहला दिन।
SELECT DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0),
CONVERT(DATE, DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE())); और उन्हें गणना करने में लगभग उतना ही समय लगता है:
SELECT SYSDATETIME(); GO DECLARE @d DATE = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0); GO 1000000 GO SELECT SYSDATETIME(); GO DECLARE @d DATE = DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE()); GO 1000000 SELECT SYSDATETIME();
मेरे सिस्टम पर, दोनों बैचों को पूरा होने में लगभग 175 सेकंड का समय लगा।
तो, आप एक विधि को दूसरे पर क्यों पसंद करेंगे? जब उनमें से एक वास्तव में कार्डिनैलिटी अनुमानों के साथ खिलवाड़ करता है .
एक त्वरित प्राइमर के रूप में, आइए इन दो मानों की तुलना करें:
SELECT DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0), -- today: 2013-09-01
DATEADD(MONTH, DATEDIFF(MONTH, GETDATE(), 0), 0); -- today: 1786-05-01
--------------------------------------^^^^^^^^^^^^ notice how these are swapped
(ध्यान दें कि यहां दर्शाए गए वास्तविक मान बदल जाएंगे, इस पर निर्भर करते हुए कि आप इस पोस्ट को कब पढ़ रहे हैं - "आज" टिप्पणी में संदर्भित 5 सितंबर, 2013 है, जिस दिन यह पोस्ट लिखा गया था। अक्टूबर 2013 में, उदाहरण के लिए, आउटपुट होगा हो 2013-10-01 और 1786-04-01 ।)
उस रास्ते से, मैं आपको दिखाता हूँ कि मेरा क्या मतलब है…
एक रेप्रो
आइए एक बहुत ही सरल तालिका बनाएं, जिसमें केवल एक संकुल DATE है कॉलम, और 15,000 पंक्तियों को मान के साथ लोड करें 1786-05-01 और 50 पंक्तियों का मान 2013-09-01 . है :
CREATE TABLE dbo.DateTest ( CreateDate DATE ); CREATE CLUSTERED INDEX x ON dbo.DateTest(CreateDate); INSERT dbo.DateTest(CreateDate) SELECT TOP (15000) DATEADD(MONTH, DATEDIFF(MONTH, GETDATE(), 0), 0) FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2 UNION ALL SELECT TOP (50) DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0) FROM sys.all_objects;
और फिर आइए इन दो प्रश्नों की वास्तविक योजनाओं को देखें:
SELECT /* Query 1 */ COUNT(*) FROM dbo.DateTest WHERE CreateDate = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0); SELECT /* Query 2 */ COUNT(*) FROM dbo.DateTest WHERE CreateDate = DATEADD(MONTH, DATEDIFF(MONTH, GETDATE(), 0), 0);
चित्रमय योजनाएँ सही दिखती हैं:
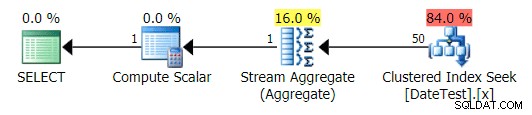
DATEDIFF के लिए ग्राफिकल प्लान(MONTH, 0, GETDATE()) क्वेरी
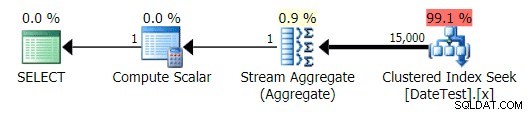
DATEDIFF(MONTH, GETDATE(), 0) के लिए ग्राफिकल प्लान क्वेरी
लेकिन अनुमानित लागत बेकार है – ध्यान दें कि पहली क्वेरी के लिए अनुमानित लागत कितनी अधिक है, जो केवल 50 पंक्तियों को लौटाती है, दूसरी क्वेरी की तुलना में, जो 15,000 पंक्तियों को लौटाती है!

अनुमानित लागत दिखाने वाला स्टेटमेंट ग्रिड
और टॉप ऑपरेशंस टैब दिखाता है कि पहली क्वेरी (2013-09-01 . की तलाश में है) ) ने अनुमान लगाया कि उसे 15,000 पंक्तियाँ मिलेंगी, जबकि वास्तव में उसे केवल 50 मिलीं; दूसरी क्वेरी इसके विपरीत दिखाती है:यह 1786-05-01 . से मेल खाने वाली 50 पंक्तियों को खोजने की उम्मीद करती है , लेकिन 15,000 मिला। इस तरह के गलत कार्डिनैलिटी अनुमानों के आधार पर, मुझे यकीन है कि आप कल्पना कर सकते हैं कि यह बहुत बड़े डेटा सेट के मुकाबले अधिक जटिल प्रश्नों पर किस तरह का कठोर प्रभाव डाल सकता है।
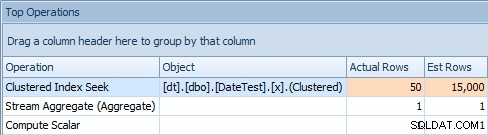
प्रथम क्वेरी के लिए शीर्ष संचालन टैब [DATEDIFF(MONTH, 0, GETDATE ())]
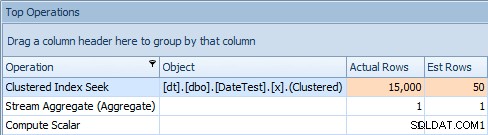
दूसरी क्वेरी के लिए शीर्ष संचालन टैब [DATEDIFF(MONTH, 0, GETDATE ())]
क्वेरी की थोड़ी भिन्न भिन्नता, महीने की शुरुआत की गणना करने के लिए एक अलग अभिव्यक्ति का उपयोग करके (पोस्ट की शुरुआत में संकेतित), इस लक्षण को प्रदर्शित नहीं करती है:
SELECT /* Query 3 */ COUNT(*) FROM dbo.DateTest WHERE CreateDate = CONVERT(DATE, DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE()));
यह योजना ऊपर दिए गए प्रश्न 1 से काफी मिलती-जुलती है, और यदि आपने करीब से नहीं देखा तो आप सोचेंगे कि ये योजनाएँ समकक्ष हैं:
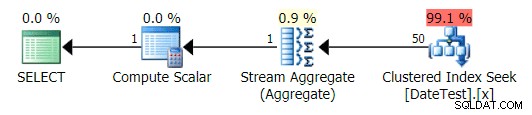
गैर-DATEDIFF क्वेरी के लिए ग्राफ़िकल प्लान
जब आप यहां शीर्ष संचालन टैब को देखते हैं, तो आप देखते हैं कि अनुमान धमाकेदार है:
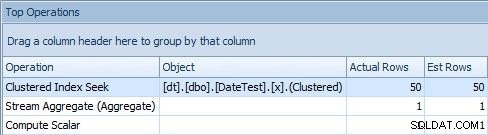
सटीक अनुमान दिखाने वाला शीर्ष संचालन टैब
इस विशेष डेटा आकार और क्वेरी पर, शुद्ध प्रदर्शन प्रभाव (सबसे विशेष रूप से अवधि और पढ़ता है) काफी हद तक अप्रासंगिक है। और यह ध्यान रखना महत्वपूर्ण है कि प्रश्न स्वयं अभी भी सही डेटा लौटाते हैं; यह सिर्फ इतना है कि अनुमान गलत हैं (और इससे भी बदतर योजना हो सकती है जो मैंने यहां प्रदर्शित की है)। उस ने कहा, यदि आप DATEDIFF का उपयोग करके स्थिरांक प्राप्त कर रहे हैं इस तरह आपके प्रश्नों में, आपको वास्तव में अपने परिवेश में इस प्रभाव का परीक्षण करना चाहिए।
तो ऐसा क्यों होता है?
सरल शब्दों में कहें तो SQL सर्वर में एक DATEDIFF होता है बग जहां यह कार्डिनैलिटी अनुमान के लिए अभिव्यक्ति का मूल्यांकन करते समय दूसरे और तीसरे तर्कों को स्वैप करता है। ऐसा प्रतीत होता है कि इसमें निरंतर तह करना शामिल है, कम से कम परिधीय रूप से; इस Books Online लेख में लगातार फोल्डिंग के बारे में बहुत अधिक विवरण हैं, लेकिन दुर्भाग्य से, लेख में इस विशेष बग के बारे में कोई जानकारी नहीं है।
कोई समाधान है - या है?
एक नॉलेज बेस आलेख (KB #2481274) है जो समस्या का समाधान करने का दावा करता है, लेकिन इसकी अपनी कुछ समस्याएं हैं:
- KB आलेख का दावा है कि समस्या को विभिन्न सर्विस पैक या SQL Server 2005, 2008 और 2008 R2 के लिए संचयी अद्यतनों में ठीक किया गया है। हालांकि, लक्षण अभी भी उन शाखाओं में मौजूद हैं जिनका स्पष्ट रूप से उल्लेख नहीं किया गया है, भले ही उन्होंने लेख प्रकाशित होने के बाद से कई अतिरिक्त सीयू देखे हैं। मैं अभी भी इस समस्या को SQL Server 2008 SP3 CU #8 (10.0.5828) और SQL Server 2012 SP1 CU #5 (11.0.3373) पर पुन:पेश कर सकता हूं।
- यह उल्लेख करने की उपेक्षा करता है कि, फिक्स से लाभ उठाने के लिए, आपको ट्रेस फ्लैग 4199 चालू करना होगा (और अन्य सभी तरीकों से "लाभ" जो विशिष्ट ट्रेस ध्वज अनुकूलक को प्रभावित कर सकता है)। तथ्य यह है कि फिक्स के लिए यह ट्रेस ध्वज आवश्यक है, संबंधित कनेक्ट आइटम #630583 में उल्लेख किया गया है, लेकिन यह जानकारी इसे KB आलेख पर वापस नहीं लाती है। न तो KB आलेख और न ही कनेक्ट आइटम कारण के बारे में कोई जानकारी देते हैं (जो कि
DATEDIFFके तर्क हैं) मूल्यांकन के दौरान अदला-बदली की गई है)। साथ ही, उपरोक्त क्वेरीज़ को ट्रेस फ़्लैग के साथ चलाना (OPTION (QUERYTRACEON 4199)का उपयोग करके) ) ऐसी योजनाएं तैयार करता है जिनमें गलत अनुमान की समस्या नहीं होती है।
- यह सुझाव देता है कि आप समस्या को हल करने के लिए डायनेमिक SQL का उपयोग करें। मेरे परीक्षणों में, एक अलग अभिव्यक्ति का उपयोग करना (जैसे कि ऊपर वाला जो
DATEDIFFका उपयोग नहीं करता है ) SQL Server 2008 और SQL Server 2012 दोनों के आधुनिक बिल्ड में समस्या पर काबू पा लिया। यहां गतिशील SQL की सिफारिश करना अनावश्यक रूप से जटिल है और संभवत:ओवरकिल है, यह देखते हुए कि एक अलग अभिव्यक्ति समस्या को हल कर सकती है। लेकिन अगर आप डायनेमिक SQL का उपयोग करते हैं, तो मैं इसे इस तरह से करूँगा जिस तरह से वे KB आलेख में अनुशंसा करते हैं, सबसे महत्वपूर्ण रूप से SQL इंजेक्शन जोखिमों को कम करने के लिए:DECLARE @date DATE = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0), @sql NVARCHAR(MAX) = N'SELECT COUNT(*) FROM dbo.DateTest WHERE CreateDate = @date;'; EXEC sp_executesql @sql, N'@date DATE', @date;(और आप
OPTION (RECOMPILE). जोड़ सकते हैं वहां, इस पर निर्भर करता है कि आप SQL सर्वर को पैरामीटर सूँघने के लिए कैसे संभालना चाहते हैं।)यह उसी योजना की ओर ले जाता है जो पिछली क्वेरी के रूप में है जो
DATEDIFF. का उपयोग नहीं करती है , उचित अनुमानों के साथ और लागत का 99.1% क्लस्टर्ड इंडेक्स की तलाश में।एक अन्य दृष्टिकोण जो आपको लुभा सकता है (और आपके द्वारा, मेरा मतलब है, जब मैंने पहली बार जांच शुरू की थी) पहले से मूल्य की गणना करने के लिए एक चर का उपयोग करना है:
DECLARE @d DATE = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0); SELECT COUNT(*) FROM dbo.DateTest WHERE CreateDate = @d;
इस दृष्टिकोण के साथ समस्या यह है कि, एक चर के साथ, आप एक स्थिर योजना के साथ समाप्त होने जा रहे हैं, लेकिन कार्डिनैलिटी एक अनुमान पर आधारित होने जा रही है (और अनुमान का प्रकार आंकड़ों की उपस्थिति या अनुपस्थिति पर निर्भर करेगा) . इस मामले में, यहां अनुमानित बनाम वास्तविक हैं:
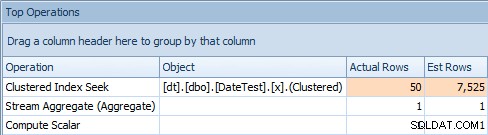
वेरिएबल का उपयोग करने वाली क्वेरी के लिए शीर्ष संचालन टैबयह स्पष्ट रूप से सही नहीं है; ऐसा लगता है कि SQL सर्वर ने अनुमान लगाया है कि वेरिएबल तालिका में 50% पंक्तियों से मेल खाएगा।
एसक्यूएल सर्वर 2014
मुझे SQL सर्वर 2014 में थोड़ा अलग मुद्दा मिला। पहले दो प्रश्न तय किए गए हैं (कार्डिनैलिटी अनुमानक या अन्य सुधारों में बदलाव के द्वारा), जिसका अर्थ है कि DATEDIFF तर्क अब स्विच नहीं हैं। वाह!
हालांकि, एक प्रतिगमन एक अलग अभिव्यक्ति का उपयोग करने के कामकाज के लिए पेश किया गया लगता है - अब यह एक गलत अनुमान से ग्रस्त है (एक चर का उपयोग करने के समान 50% अनुमान के आधार पर)। ये वे प्रश्न हैं जो मैंने चलाए:
SELECT /* 0, GETDATE() (2013) */ COUNT(*) FROM dbo.DateTest
WHERE CreateDate = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0);
SELECT /* GETDATE(), 0 (1786) */ COUNT(*) FROM dbo.DateTest
WHERE CreateDate = DATEADD(MONTH, DATEDIFF(MONTH, GETDATE(), 0), 0);
SELECT /* Non-DATEDIFF */ COUNT(*) FROM dbo.DateTest
WHERE CreateDate = CONVERT(DATE, DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE()));
DECLARE @d DATE = DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE());
SELECT /* Variable */ COUNT(*) FROM dbo.DateTest WHERE CreateDate = @d;
DECLARE
@date DATE = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0),
@sql NVARCHAR(MAX) = N'SELECT /* Dynamic SQL */ COUNT(*) FROM dbo.DateTest
WHERE CreateDate = @date;';
EXEC sp_executesql @sql, N'@date DATE', @date; अनुमानित लागत और वास्तविक रनटाइम मेट्रिक्स की तुलना करने वाला स्टेटमेंट ग्रिड यहां दिया गया है:
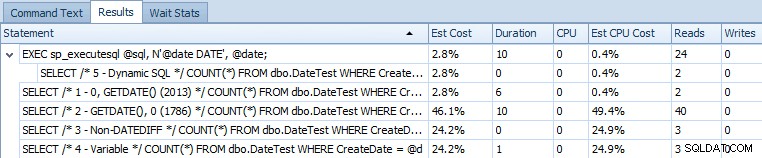
एसक्यूएल सर्वर 2014 पर 5 नमूना प्रश्नों की अनुमानित लागत
और ये उनकी अनुमानित और वास्तविक पंक्ति गणना हैं (फ़ोटोशॉप का उपयोग करके एकत्रित):

एसक्यूएल सर्वर 2014 पर 5 प्रश्नों के लिए अनुमानित और वास्तविक पंक्ति गणना
इस आउटपुट से यह स्पष्ट है कि जिस अभिव्यक्ति ने पहले इस मुद्दे को हल किया था उसने अब एक अलग पेश किया है। मुझे यकीन नहीं है कि यह एक सीटीपी में चलने का लक्षण है (उदाहरण के लिए कुछ जो तय किया जाएगा) या अगर यह वास्तव में एक प्रतिगमन है।
इस मामले में, ट्रेस फ्लैग 4199 (अपने आप) का कोई प्रभाव नहीं पड़ता है; नया कार्डिनैलिटी अनुमानक अनुमान लगा रहा है और बस सही नहीं है। क्या यह वास्तविक प्रदर्शन के मुद्दे की ओर जाता है, इस पोस्ट के दायरे से परे कई अन्य कारकों पर निर्भर करता है।
यदि आप इस समस्या का सामना करते हैं, तो आप - कम से कम वर्तमान सीटीपी में - OPTION (QUERYTRACEON 9481, QUERYTRACEON 4199) का उपयोग करके पुराने व्यवहार को पुनर्स्थापित कर सकते हैं। . ट्रेस फ़्लैग 9481 नए कार्डिनैलिटी अनुमानक को अक्षम करता है, जैसा कि इन रिलीज़ नोटों में वर्णित है (जो निश्चित रूप से गायब हो जाएगा या कम से कम किसी बिंदु पर चलेगा)। यह बदले में गैर-DATEDIFF . के लिए सही अनुमानों को पुनर्स्थापित करता है क्वेरी का संस्करण, लेकिन दुर्भाग्य से अभी भी उस मुद्दे को हल नहीं करता है जहां एक चर के आधार पर अनुमान लगाया जाता है (और अकेले TF9481 का उपयोग करके, TF4199 के बिना, पहले दो प्रश्नों को पुराने तर्क-स्वैपिंग व्यवहार पर वापस जाने के लिए मजबूर करता है)।
निष्कर्ष
मैं स्वीकार करूंगा कि यह मेरे लिए बहुत बड़ा आश्चर्य था। कुडोस टू मार्टिन स्मिथ और t-clausen.dk मुझे दृढ़ता और आश्वस्त करने के लिए कि यह एक वास्तविक और काल्पनिक मुद्दा नहीं था। पॉल व्हाइट (@SQL_Kiwi) को भी बहुत-बहुत धन्यवाद, जिन्होंने मुझे अपना विवेक बनाए रखने में मदद की और मुझे उन चीजों की याद दिला दी जो मुझे नहीं कहनी चाहिए। :-)
इस बग से अनजान होने के कारण, मैं इस बात पर अडिग था कि बेहतर क्वेरी प्लान केवल क्वेरी टेक्स्ट को बदलकर तैयार किया गया था, न कि विशिष्ट परिवर्तन के कारण। जैसा कि यह पता चला है, कभी-कभी उस क्वेरी में परिवर्तन जिसे आप मान लेते हैं कोई फर्क नहीं पड़ेगा, वास्तव में होगा। इसलिए मेरा सुझाव है कि यदि आपके वातावरण में कोई समान क्वेरी पैटर्न है, तो आप उनका परीक्षण करें और सुनिश्चित करें कि कार्डिनैलिटी अनुमान सही निकल रहे हैं। और अपग्रेड करते समय उनका दोबारा परीक्षण करने के लिए एक नोट बनाएं।