StackExchange पर हाल के एक थ्रेड में, एक उपयोगकर्ता के पास निम्न समस्या थी:
<ब्लॉककोट>मुझे एक क्वेरी चाहिए जो ग्रुपआईडी =2 के साथ तालिका में पहले व्यक्ति को लौटाती है। अगर ग्रुपआईडी =2 वाला कोई भी मौजूद नहीं है, तो मुझे रोलआईडी =2 वाला पहला व्यक्ति चाहिए।
आइए, अभी के लिए, इस तथ्य को त्याग दें कि "पहले" को बहुत परिभाषित किया गया है। वास्तव में, उपयोगकर्ता को इस बात की परवाह नहीं थी कि उन्हें कौन सा व्यक्ति मिला है, चाहे वह बेतरतीब ढंग से, मनमाने ढंग से, या उनके मुख्य मानदंडों के अलावा कुछ स्पष्ट तर्क के माध्यम से आया हो। इसे अनदेखा करते हुए, मान लें कि आपके पास एक मूल तालिका है:
CREATE TABLE dbo.Users ( UserID INT PRIMARY KEY, GroupID INT, RoleID INT );
वास्तविक दुनिया में शायद अन्य कॉलम, अतिरिक्त बाधाएं, अन्य तालिकाओं के लिए विदेशी कुंजी, और निश्चित रूप से अन्य अनुक्रमणिकाएं हैं। लेकिन चलिए इसे सरल रखते हैं, और एक प्रश्न के साथ आते हैं।
संभावित समाधान
उस टेबल डिज़ाइन के साथ, समस्या को हल करना सीधा लगता है, है ना? संभवत:आप जो पहला प्रयास करेंगे वह है:
SELECT TOP (1) UserID, GroupID, RoleID FROM dbo.Users WHERE GroupID = 2 OR RoleID = 2 ORDER BY CASE GroupID WHEN 2 THEN 1 ELSE 2 END;
यह TOP . का उपयोग करता है और एक सशर्त ORDER BY उन उपयोगकर्ताओं को GroupID =2 के साथ उच्च प्राथमिकता के रूप में मानने के लिए। इस क्वेरी के लिए योजना बहुत सरल है, जिसमें अधिकांश लागत सॉर्ट ऑपरेशन में हो रही है। यहां एक खाली टेबल के सामने रनटाइम मेट्रिक्स दिए गए हैं:
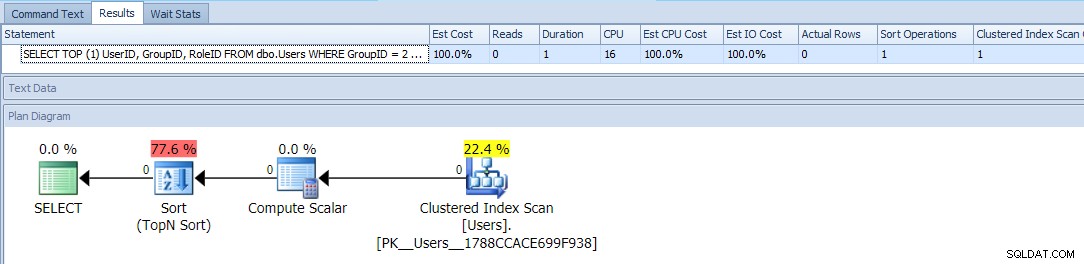
यह लगभग उतना ही अच्छा लगता है जितना आप कर सकते हैं - एक साधारण योजना जो केवल एक बार तालिका को स्कैन करती है, और एक अजीब प्रकार के अलावा जिसे आप के साथ रहने में सक्षम होना चाहिए, कोई समस्या नहीं है, है ना?
खैर, धागे में एक और जवाब ने इस अधिक जटिल बदलाव की पेशकश की:
SELECT TOP (1) UserID, GroupID, RoleID FROM ( SELECT TOP (1) UserID, GroupID, RoleID, o = 1 FROM dbo.Users WHERE GroupId = 2 UNION ALL SELECT TOP (1) UserID, GroupID, RoleID, o = 2 FROM dbo.Users WHERE RoleID = 2 ) AS x ORDER BY o;
पहली नज़र में, आप शायद सोचेंगे कि यह क्वेरी बेहद कम कुशल है, क्योंकि इसके लिए दो क्लस्टर इंडेक्स स्कैन की आवश्यकता होती है। आप निश्चित रूप से इसके बारे में सही होंगे; यहां एक खाली टेबल के सामने प्लान और रनटाइम मेट्रिक्स दिया गया है:
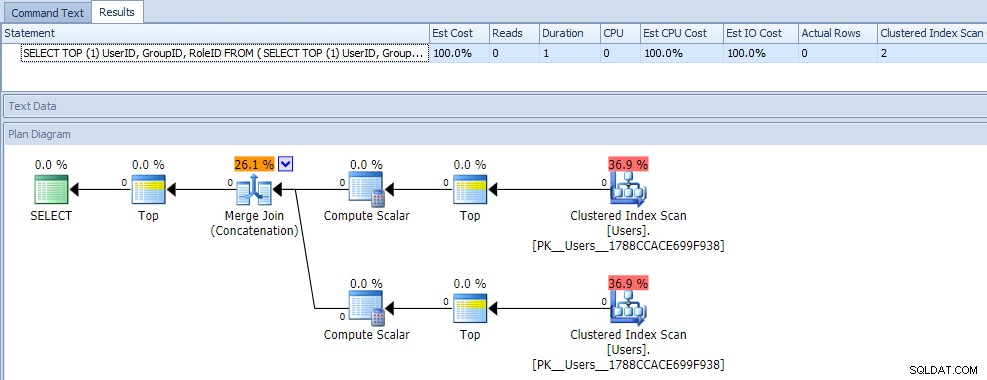
लेकिन अब, चलिए डेटा जोड़ते हैं
इन प्रश्नों का परीक्षण करने के लिए, मैं कुछ यथार्थवादी डेटा का उपयोग करना चाहता था। तो सबसे पहले मैंने sys.all_objects से 1,000 पंक्तियों को आबाद किया, कुछ अच्छे वितरण प्राप्त करने के लिए object_id के खिलाफ मॉड्यूलो संचालन के साथ:
INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (1000) ABS([object_id]), ABS([object_id]) % 7, ABS([object_id]) % 4 FROM sys.all_objects ORDER BY [object_id]; SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 126 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 248 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 26 overlap
अब जब मैं दो प्रश्नों को चलाता हूं, तो यहां रनटाइम मेट्रिक्स होते हैं:

UNION ALL संस्करण थोड़ा कम I/O (4 रीड बनाम 5), कम अवधि और कम अनुमानित समग्र लागत के साथ आता है, जबकि सशर्त ORDER BY संस्करण में अनुमानित CPU लागत कम है। कोई निष्कर्ष निकालने के लिए यहां डेटा बहुत छोटा है; मैं बस इसे जमीन में हिस्सेदारी के रूप में चाहता था। अब, वितरण को बदलते हैं ताकि अधिकांश पंक्तियाँ कम से कम एक मानदंड (और कभी-कभी दोनों) को पूरा करें:
DROP TABLE dbo.Users; GO CREATE TABLE dbo.Users ( UserID INT PRIMARY KEY, GroupID INT, RoleID INT ); GO INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (1000) ABS([object_id]), ABS([object_id]) % 2 + 1, SUBSTRING(RTRIM([object_id]),7,1) % 2 + 1 FROM sys.all_objects WHERE ABS([object_id]) > 9999999 ORDER BY [object_id]; SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 500 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 475 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 221 overlap
इस बार, द्वारा सशर्त आदेश की CPU और I/O दोनों में उच्चतम अनुमानित लागत है:

लेकिन फिर, इस डेटा आकार पर, अवधि और पढ़ने के लिए अपेक्षाकृत महत्वहीन प्रभाव पड़ता है, और अनुमानित लागतों (जो बड़े पैमाने पर वैसे भी बनायी जाती हैं) के अलावा, यहां विजेता घोषित करना कठिन है।
तो, चलिए बहुत अधिक डेटा जोड़ते हैं
जबकि मैं कैटलॉग दृश्यों से नमूना डेटा बनाने का आनंद लेता हूं, क्योंकि सभी के पास वे हैं, इस बार मैं टेबल पर आकर्षित करने जा रहा हूं। मेरे सिस्टम पर, इस तालिका में 1,258,600 पंक्तियाँ हैं। निम्न स्क्रिप्ट हमारी dbo.Users तालिका में उन लाखों पंक्तियों को सम्मिलित करेगी:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (1000000) SalesOrderID, SalesOrderID % 7, SalesOrderID % 4 FROM Sales.SalesOrderHeaderEnlarged; SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 142,857 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 250,000 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 35,714 overlap
ठीक है, अब जब हम क्वेरीज़ चलाते हैं, तो हमें एक समस्या दिखाई देती है:ORDER BY वेरिएशन समानांतर हो गया है और रीड और CPU दोनों को मिटा दिया है, जिससे अवधि में लगभग 120X का अंतर आता है:
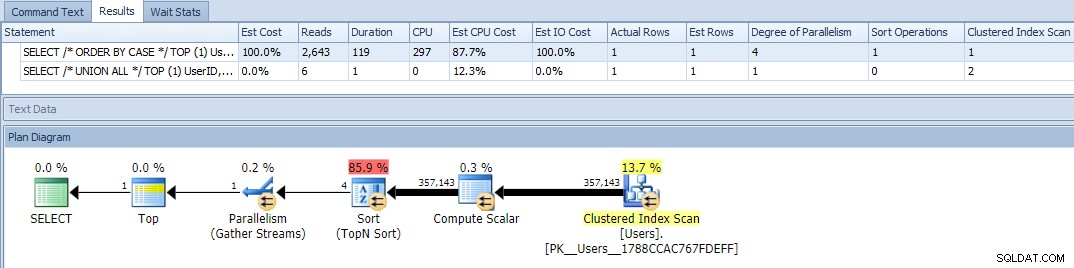
समांतरता को खत्म करने (MAXDOP का उपयोग करने से) मदद नहीं मिली:
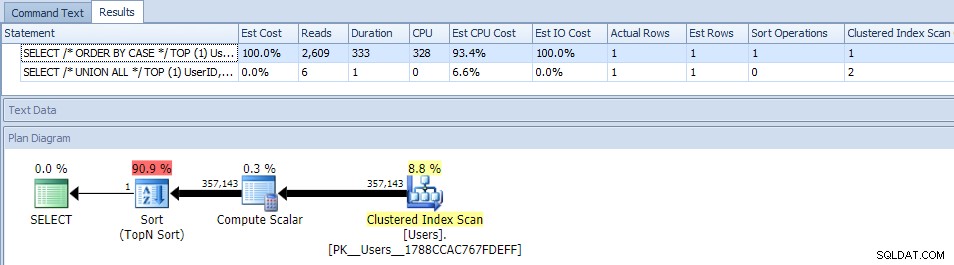
(यूनियन सभी योजना अभी भी वही दिखती है।)
और अगर हम तिरछा को सम में बदलते हैं, जहाँ 95% पंक्तियाँ कम से कम एक मानदंड को पूरा करती हैं:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (475000) SalesOrderID, 2, SalesOrderID % 7 FROM Sales.SalesOrderHeaderEnlarged WHERE SalesOrderID % 2 = 1 UNION ALL SELECT TOP (475000) SalesOrderID, SalesOrderID % 7, 2 FROM Sales.SalesOrderHeaderEnlarged WHERE SalesOrderID % 2 = 0; INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (50000) SalesOrderID, 1, 1 FROM Sales.SalesOrderHeaderEnlarged AS h WHERE NOT EXISTS (SELECT 1 FROM dbo.Users WHERE UserID = h.SalesOrderID); SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 542,851 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 542,851 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 135,702 overlap
क्वेरी अब भी दिखाती हैं कि सॉर्ट करना बेहद महंगा है:

और MAXDOP =1 के साथ यह बहुत खराब था (केवल अवधि देखें):

अंत में, किसी भी दिशा में लगभग 95% तिरछा कैसे होता है (उदाहरण के लिए अधिकांश पंक्तियाँ GroupID मानदंड को पूरा करती हैं, या अधिकांश पंक्तियाँ रोलआईडी मानदंड को पूरा करती हैं)? यह स्क्रिप्ट सुनिश्चित करेगी कि कम से कम 95% डेटा में GroupID =2 है:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (950000) SalesOrderID, 2, SalesOrderID % 7 FROM Sales.SalesOrderHeaderEnlarged; INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (50000) SalesOrderID, SalesOrderID % 7, 2 FROM Sales.SalesOrderHeaderEnlarged AS h WHERE NOT EXISTS (SELECT 1 FROM dbo.Users WHERE UserID = h.SalesOrderID); SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 957,143 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 185,714 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 142,857 overlap
परिणाम काफी समान हैं (मैं अभी से MAXDOP चीज़ को आज़माना बंद करने जा रहा हूँ):

और फिर अगर हम दूसरी तरफ झुकते हैं, जहां कम से कम 95% डेटा में रोलआईडी =2 है:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (950000) SalesOrderID, 2, SalesOrderID % 7 FROM Sales.SalesOrderHeaderEnlarged; INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (50000) SalesOrderID, SalesOrderID % 7, 2 FROM Sales.SalesOrderHeaderEnlarged AS h WHERE NOT EXISTS (SELECT 1 FROM dbo.Users WHERE UserID = h.SalesOrderID); SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 185,714 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 957,143 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 142,857 overlap
परिणाम:

निष्कर्ष
एक भी मामले में जिसे मैं "सरल" क्वेरी द्वारा ऑर्डर नहीं कर सकता था - यहां तक कि एक कम क्लस्टर इंडेक्स स्कैन के साथ - अधिक जटिल यूनियन सभी क्वेरी को बेहतर प्रदर्शन करता है। कभी-कभी आपको इस बारे में बहुत सावधान रहना पड़ता है कि SQL सर्वर को क्या करना है जब आप अपनी क्वेरी सेमेन्टिक्स में सॉर्ट जैसे ऑपरेशन पेश करते हैं, और अकेले योजना की सादगी पर भरोसा नहीं करते हैं (पिछले परिदृश्यों के आधार पर आपके किसी भी पूर्वाग्रह पर ध्यान न दें)।
आपकी पहली प्रवृत्ति अक्सर सही हो सकती है, लेकिन मैं शर्त लगाता हूं कि कई बार एक बेहतर विकल्प होता है जो सतह पर दिखता है, जैसे कि यह संभवतः बेहतर काम नहीं कर सकता। जैसा कि इस उदाहरण में है। मैं अवलोकनों से की गई धारणाओं पर सवाल उठाने के बारे में काफी बेहतर हो रहा हूं, और "स्कैन कभी अच्छा प्रदर्शन नहीं करता" और "सरल प्रश्न हमेशा तेजी से चलते हैं" जैसे कंबल बयान नहीं कर रहे हैं। यदि आप अपनी शब्दावली से कभी भी और हमेशा शब्दों को खत्म नहीं करते हैं, तो आप खुद को उन मान्यताओं और कंबल बयानों को परीक्षण में डाल सकते हैं, और बहुत बेहतर तरीके से समाप्त हो सकते हैं।



