अतिथि लेखक:माइकल जे स्वार्ट (@MJSwart)
मैं सॉफ्टवेयर आवश्यकताओं को स्कीमा और प्रश्नों में अनुवाद करने में बड़ी मात्रा में समय व्यतीत करता हूं। इन आवश्यकताओं को लागू करना कभी-कभी आसान होता है लेकिन अक्सर मुश्किल होता है। मैं यूआई डिज़ाइन विकल्पों के बारे में बात करना चाहता हूं जो डेटा एक्सेस पैटर्न की ओर ले जाते हैं जो SQL सर्वर का उपयोग करके लागू करने के लिए अजीब हैं।
कॉलम के अनुसार क्रमित करें
सॉर्ट-बाय-कॉलम एक ऐसा परिचित पैटर्न है जिसे हम मान सकते हैं। हर बार जब हम एक टेबल प्रदर्शित करने वाले सॉफ़्टवेयर के साथ इंटरैक्ट करते हैं, तो हम उम्मीद कर सकते हैं कि कॉलम इस तरह क्रमबद्ध होंगे:
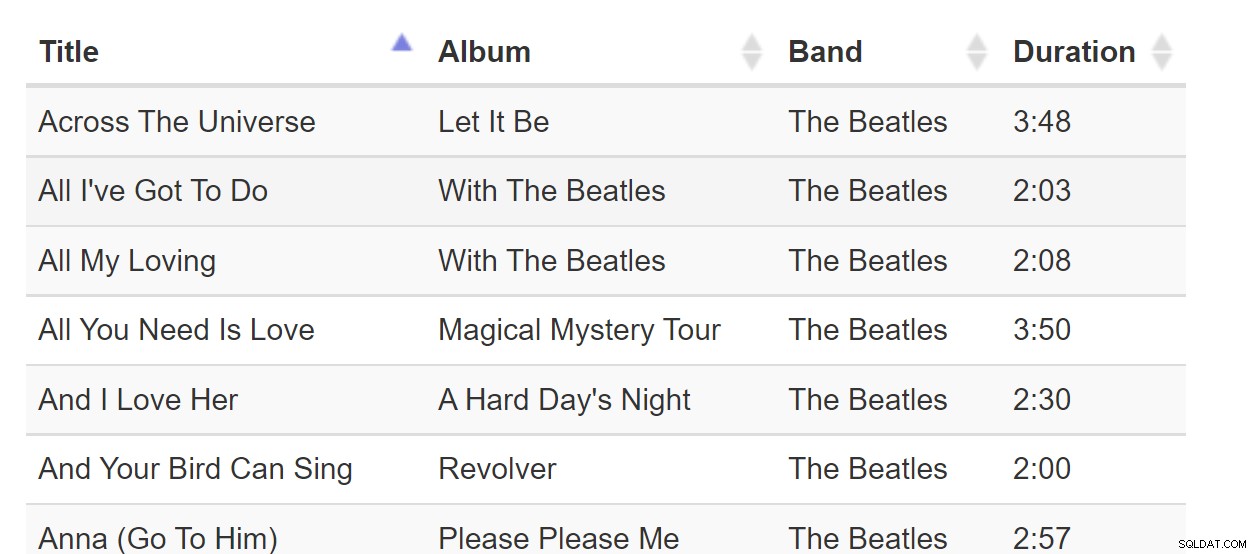
जब सभी डेटा ब्राउज़र में फ़िट हो सकते हैं, तो सॉर्ट-बाय-कॉलन एक बेहतरीन पैटर्न है। लेकिन अगर डेटा सेट अरबों पंक्तियों में बड़ा है तो यह अजीब हो सकता है, भले ही वेब पेज को केवल एक पेज डेटा की आवश्यकता हो। गीतों की इस तालिका पर विचार करें:
CREATE TABLE Songs
(
Title NVARCHAR(300) NOT NULL,
Album NVARCHAR(300) NOT NULL,
Band NVARCHAR(300) NOT NULL,
DurationInSeconds INT NOT NULL,
CONSTRAINT PK_Songs PRIMARY KEY CLUSTERED (Title),
);
CREATE NONCLUSTERED INDEX IX_Songs_Album
ON dbo.Songs(Album)
INCLUDE (Band, DurationInSeconds);
CREATE NONCLUSTERED INDEX IX_Songs_Band
ON dbo.Songs(Band); और प्रत्येक कॉलम के आधार पर छांटे गए इन चार प्रश्नों पर विचार करें:
SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY Title; SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY Album; SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY Band; SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY DurationInSeconds;
यहां तक कि एक प्रश्न के लिए यह सरल है, अलग-अलग क्वेरी योजनाएं हैं। पहले दो प्रश्न कवरिंग इंडेक्स का उपयोग करते हैं:
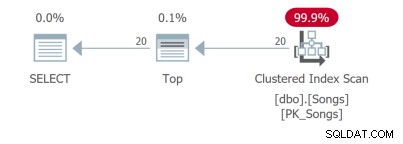
तीसरी क्वेरी को एक महत्वपूर्ण खोज करने की आवश्यकता है जो आदर्श नहीं है:
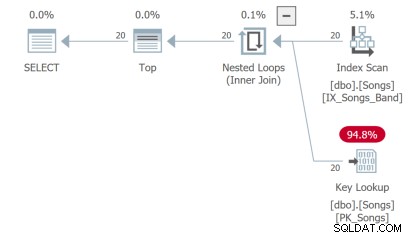
लेकिन सबसे खराब चौथी क्वेरी है जिसे पहली 20 पंक्तियों को वापस करने के लिए पूरी तालिका को स्कैन करने और एक प्रकार करने की आवश्यकता है:
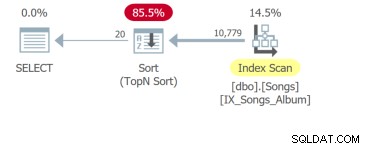
मुद्दा यह है कि भले ही केवल ORDER BY क्लॉज का अंतर है, उन प्रश्नों का अलग से विश्लेषण करना होगा। SQL ट्यूनिंग की मूल इकाई क्वेरी है। इसलिए यदि आप मुझे दस सॉर्ट करने योग्य कॉलम के साथ UI आवश्यकताएं दिखाते हैं, तो मैं आपको विश्लेषण करने के लिए दस क्वेरी दिखाऊंगा।
यह कब अजीब हो जाता है?
सॉर्ट-बाय-कॉलम फीचर एक बेहतरीन यूआई पैटर्न है, लेकिन अगर डेटा एक विशाल बढ़ती तालिका से कई, कई कॉलम के साथ आता है, तो यह अजीब हो सकता है। प्रत्येक कॉलम पर कवरिंग इंडेक्स बनाना आकर्षक हो सकता है, लेकिन इसमें अन्य ट्रेडऑफ़ हैं। कॉलमस्टोर इंडेक्स कुछ परिस्थितियों में मदद कर सकते हैं, लेकिन यह एक और स्तर की अजीबता का परिचय देता है। हमेशा एक आसान विकल्प नहीं होता है।
पृष्ठांकित परिणाम
पृष्ठांकित परिणामों का उपयोग करना उपयोगकर्ता को एक ही बार में बहुत अधिक जानकारी से अभिभूत न करने का एक अच्छा तरीका है। यह आमतौर पर डेटाबेस सर्वरों पर हावी न होने का एक अच्छा तरीका है।
इस डिज़ाइन पर विचार करें:

इस उदाहरण के पीछे के डेटा को परिणामों की संख्या की रिपोर्ट करने के लिए संपूर्ण डेटासेट को गिनने और संसाधित करने की आवश्यकता है। इस उदाहरण के लिए क्वेरी इस तरह सिंटैक्स का उपयोग कर सकती है:
... ORDER BY LastModifiedTime OFFSET @N ROWS FETCH NEXT 25 ROWS ONLY;
यह सुविधाजनक सिंटैक्स है, और क्वेरी केवल 25 पंक्तियों का उत्पादन करती है। लेकिन सिर्फ इसलिए कि परिणाम सेट छोटा है, इसका मतलब यह नहीं है कि यह सस्ता है। जैसा कि हमने सॉर्ट-बाय-कॉलम पैटर्न के साथ देखा, एक TOP ऑपरेटर केवल तभी सस्ता होता है, जब उसे पहले बहुत सारे डेटा को सॉर्ट करने की आवश्यकता नहीं होती है।
एसिंक्रोनस पेज अनुरोध
जैसे ही उपयोगकर्ता परिणामों के एक पृष्ठ से दूसरे पृष्ठ पर जाता है, इसमें शामिल वेब अनुरोधों को सेकंड या मिनटों में अलग किया जा सकता है। यह उन मुद्दों की ओर जाता है जो NOLOCK का उपयोग करते समय देखे जाने वाले नुकसान की तरह दिखते हैं। उदाहरण के लिए:
SELECT [Some Columns] FROM [Some Table] ORDER BY [Sort Value] OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLY; -- wait a little bit SELECT [Some Columns] FROM [Some Table] ORDER BY [Sort Value] OFFSET 25 ROWS FETCH NEXT 25 ROWS ONLY;
जब दो अनुरोधों के बीच एक पंक्ति जोड़ी जाती है, तो उपयोगकर्ता एक ही पंक्ति को दो बार देख सकता है। और यदि एक पंक्ति को हटा दिया जाता है, तो उपयोगकर्ता पृष्ठों को नेविगेट करते समय एक पंक्ति को याद कर सकते हैं। यह पृष्ठांकित-परिणाम पैटर्न "मुझे 26-50 पंक्तियाँ दें" के बराबर है। जब वास्तविक प्रश्न होना चाहिए "मुझे अगली 25 पंक्तियाँ दें"। अंतर सूक्ष्म है।
बेहतर पैटर्न
पृष्ठांकित-परिणामों के साथ, जैसे-जैसे @N बढ़ता है, "ऑफसेट @N ROWS" में अधिक और अधिक समय लग सकता है। इसके बजाय लोड-मोर बटन या अनंत-स्क्रॉलिंग पर विचार करें। लोड-मोर पेजिंग के साथ, इंडेक्स का कुशल उपयोग करने का कम से कम एक मौका है। क्वेरी कुछ इस तरह दिखेगी:
SELECT [Some Columns] FROM [Some Table] WHERE [Sort Value] > @Bookmark ORDER BY [Sort Value] FETCH NEXT 25 ROWS ONLY;
यह अभी भी एसिंक्रोनस पेज अनुरोधों के कुछ नुकसानों से ग्रस्त है, लेकिन बुकमार्क के कारण, उपयोगकर्ता वहीं से शुरू होगा जहां उन्होंने छोड़ा था।
सबस्ट्रिंग के लिए टेक्स्ट खोजना
इंटरनेट पर हर जगह सर्च किया जा रहा है। लेकिन पिछले सिरे पर किस घोल का इस्तेमाल किया जाना चाहिए? मैं इस तरह के वाइल्डकार्ड के साथ SQL सर्वर के LIKE फ़िल्टर का उपयोग करके एक सबस्ट्रिंग की खोज के खिलाफ चेतावनी देना चाहता हूं:
SELECT Title, Category FROM MyContent WHERE Title LIKE '%' + @SearchTerm + '%';
यह इस तरह के अजीब परिणाम दे सकता है:
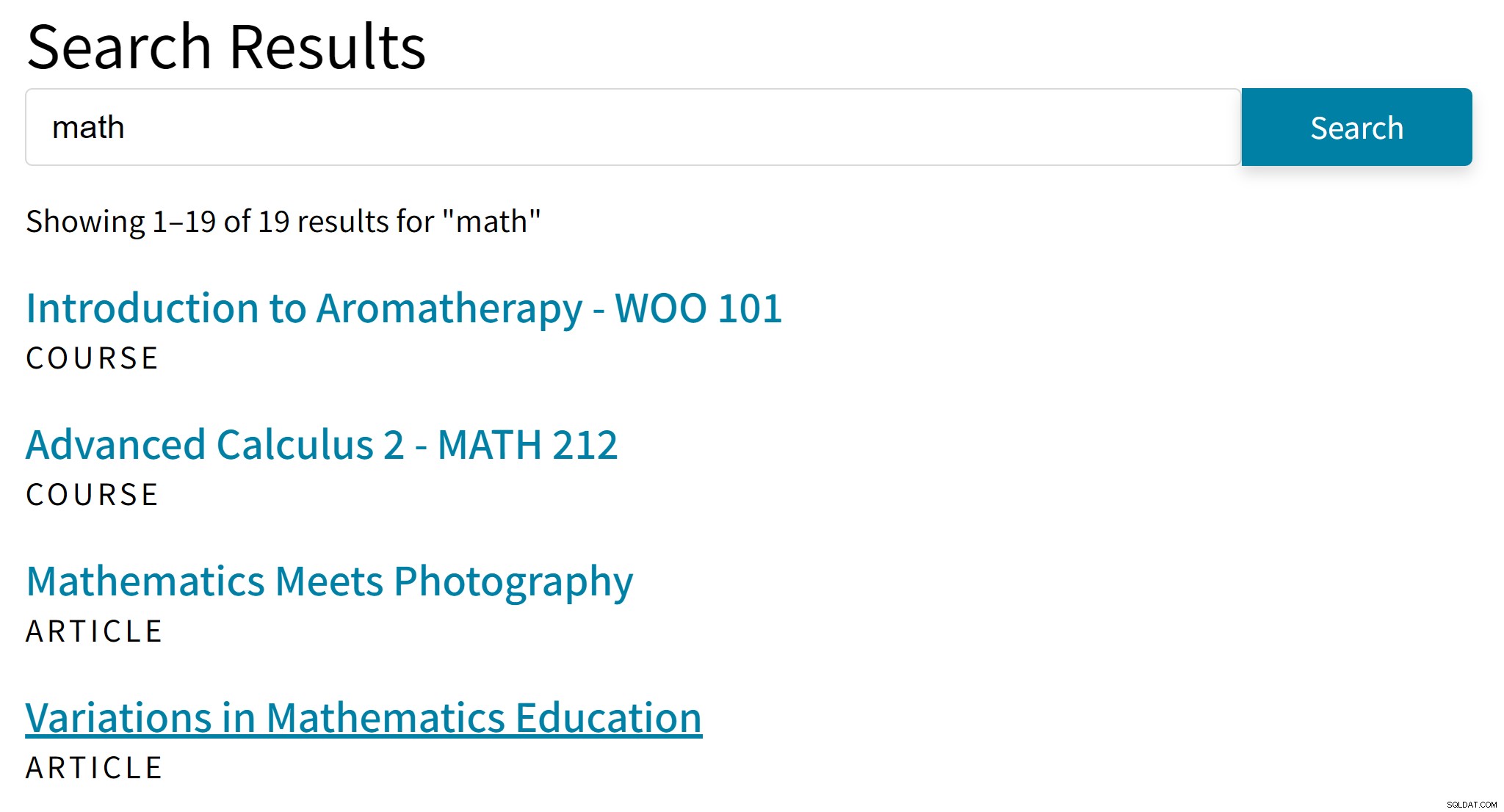
"अरोमाथेरेपी" शायद खोज शब्द "गणित" के लिए एक अच्छी हिट नहीं है। इस बीच, खोज परिणामों में ऐसे लेख नहीं हैं जो केवल बीजगणित या त्रिकोणमिति का उल्लेख करते हैं।
SQL सर्वर का उपयोग करके कुशलता से खींचना भी बहुत मुश्किल हो सकता है। इस तरह की खोज का समर्थन करने वाला कोई सीधा सूचकांक नहीं है। पॉल व्हाइट ने SQL सर्वर में ट्रिग्राम वाइल्डकार्ड स्ट्रिंग सर्च के साथ एक मुश्किल समाधान दिया। ऐसी कठिनाइयाँ भी हैं जो कोलाज और यूनिकोड के साथ हो सकती हैं। यह एक गैर-अच्छे उपयोगकर्ता अनुभव के लिए एक महंगा समाधान बन सकता है।
इसके बजाय क्या उपयोग करें
SQL सर्वर की पूर्ण-पाठ खोज ऐसा लगता है कि यह मदद कर सकता है, लेकिन मैंने व्यक्तिगत रूप से इसका कभी भी उपयोग नहीं किया है। व्यवहार में, मैंने केवल SQL सर्वर (जैसे Elasticsearch) के बाहर के समाधानों में सफलता देखी है।
निष्कर्ष
अपने अनुभव में मैंने पाया है कि सॉफ़्टवेयर डिज़ाइनर अक्सर प्रतिक्रिया के लिए बहुत ग्रहणशील होते हैं कि उनके डिज़ाइन कभी-कभी लागू करने के लिए अजीब होने वाले होते हैं। जब वे नहीं होते हैं, तो मैंने नुकसान, लागत और डिलीवरी के समय को उजागर करना उपयोगी पाया है। बनाए रखने योग्य, मापनीय समाधान बनाने में मदद करने के लिए उस तरह की प्रतिक्रिया आवश्यक है।
लेखक के बारे में
 माइकल जे स्वार्ट एक उत्साही डेटाबेस पेशेवर और ब्लॉगर हैं जो डेटाबेस विकास और सॉफ्टवेयर आर्किटेक्चर पर ध्यान केंद्रित करते हैं। उन्हें डेटा से संबंधित किसी भी चीज़ के बारे में बोलने, सामुदायिक परियोजनाओं में योगदान करने में मज़ा आता है। माइकल michaeljswart.com पर "डेटाबेस व्हिस्परर" के रूप में ब्लॉग करता है।
माइकल जे स्वार्ट एक उत्साही डेटाबेस पेशेवर और ब्लॉगर हैं जो डेटाबेस विकास और सॉफ्टवेयर आर्किटेक्चर पर ध्यान केंद्रित करते हैं। उन्हें डेटा से संबंधित किसी भी चीज़ के बारे में बोलने, सामुदायिक परियोजनाओं में योगदान करने में मज़ा आता है। माइकल michaeljswart.com पर "डेटाबेस व्हिस्परर" के रूप में ब्लॉग करता है।