यह लेख कुछ कम प्रसिद्ध क्वेरी ऑप्टिमाइज़र सुविधाओं और सीमाओं की पड़ताल करता है, और एक विशिष्ट मामले में बेहद खराब हैश जॉइन प्रदर्शन के कारणों की व्याख्या करता है।
नमूना डेटा
निम्नलिखित नमूना डेटा निर्माण स्क्रिप्ट संख्याओं की मौजूदा तालिका पर निर्भर करती है। यदि आपके पास इनमें से कोई भी पहले से नहीं है, तो नीचे दी गई स्क्रिप्ट का उपयोग कुशलतापूर्वक एक बनाने के लिए किया जा सकता है। परिणामी तालिका में एक से दस लाख तक की संख्याओं वाला एक पूर्णांक स्तंभ होगा:
दस (एन) के रूप में (चुनें 1 यूनियन सभी चयन 1 यूनियन सभी चयन 1 यूनियन सभी चयन 1 यूनियन सभी चयन 1 यूनियन सभी चयन 1 यूनियन सभी चयन 1 यूनियन सभी चयन 1 यूनियन सभी चयन 1 यूनियन सभी चयन 1) चुनें टॉप (1000000) n =पहचान (int, 1, 1) dbo में। दस T10, दस T100, दस T1000, दस T10000, दस T100000, दस T1000000 से संख्या; ALTER TABLE dbo.NumbersADD CONSTRAINT PK_dbo_Numbers_nPRIMARY KEY CLUSTERED (n)साथ (SORT_IN_TEMPDB =ON, MAXDOP =1, FILLFACTOR =100);
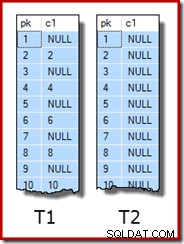
नमूना डेटा में ही दो टेबल, T1 और T2 होते हैं। दोनों में एक अनुक्रमिक पूर्णांक प्राथमिक कुंजी स्तंभ है जिसका नाम pk है, और दूसरा अशक्त स्तंभ है जिसका नाम c1 है। तालिका T1 में 600,000 पंक्तियाँ हैं जहाँ सम-संख्या वाली पंक्तियों का c1 के लिए pk स्तंभ के समान मान है, और विषम-संख्या वाली पंक्तियाँ शून्य हैं। तालिका c2 में 32,000 पंक्तियाँ हैं जहाँ स्तंभ c1 प्रत्येक पंक्ति में NULL है। निम्न स्क्रिप्ट इन तालिकाओं को बनाती और भरती है:
टेबल dbo.T1 बनाएं (pk इंटीजर नॉट NULL, c1 इंटीजर NULL, CONSTRAINT PK_dbo_T1 प्राथमिक कुंजी क्लस्टर (pk)); तालिका dbo.T2 बनाएं (पीके पूर्णांक शून्य नहीं, सी 1 पूर्णांक शून्य, प्रतिबंधित PK_dbo_T2 प्राथमिक कुंजी क्लस्टर (पीके)); INSERT dbo.T1 के साथ (TABLOCKX) (pk, c1) N.n चुनें, केस जब N.n% 2 =1 तब NULL ELSE N.n ENDFROM dbo.Numbers जैसे N.n 1 और 600000 के बीच; INSERT dbo.T2 के साथ (TABLOCKX) (pk, c1) N.n चुनें, dbo से NULL। नंबर 1 और 32000 के बीच N.N के रूप में N.N; अद्यतन सांख्यिकी dbo.T1 फुलस्कैन के साथ; अद्यतन सांख्यिकी dbo.T2 फुलस्कैन के साथ;
प्रत्येक तालिका में नमूना डेटा की पहली दस पंक्तियाँ इस तरह दिखती हैं:
दो तालिकाओं में शामिल होना
इस पहले परीक्षण में कॉलम c1 (pk कॉलम नहीं) पर दो तालिकाओं में शामिल होना और शामिल होने वाली पंक्तियों के लिए तालिका T1 से pk मान वापस करना शामिल है:
dbo.T1 से T1.pk चुनें T1 के रूप में शामिल हों dbo.T2 AS T2 पर T2.c1 =T1.c1;
क्वेरी वास्तव में कोई पंक्तियाँ नहीं लौटाएगी क्योंकि स्तंभ c1 तालिका T2 की सभी पंक्तियों में NULL है, इसलिए कोई भी पंक्तियाँ समानता में शामिल होने वाले विधेय से मेल नहीं खा सकती हैं। यह करने के लिए एक अजीब बात की तरह लग सकता है, लेकिन मुझे विश्वास है कि यह एक वास्तविक उत्पादन क्वेरी (चर्चा में आसानी के लिए बहुत सरल) पर आधारित है।
ध्यान दें कि यह खाली परिणाम ANSI_NULLS की सेटिंग पर निर्भर नहीं करता है, क्योंकि यह केवल नियंत्रित करता है कि कैसे एक अशक्त शाब्दिक या चर के साथ तुलना को नियंत्रित किया जाता है। स्तंभ तुलनाओं के लिए, एक समानता विधेय हमेशा नल को अस्वीकार करता है।
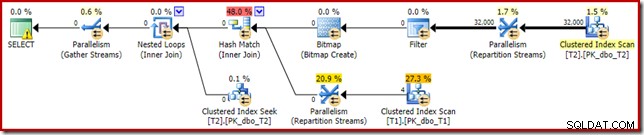
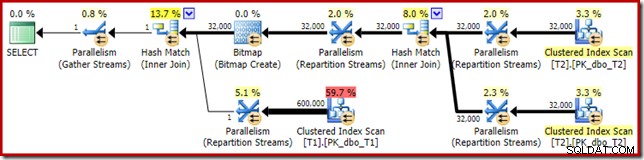
इस सरल जॉइन क्वेरी की निष्पादन योजना में कुछ दिलचस्प विशेषताएं हैं। हम पहले SQL सेंट्री प्लान एक्सप्लोरर में पूर्व-निष्पादन ('अनुमानित') योजना को देखेंगे:
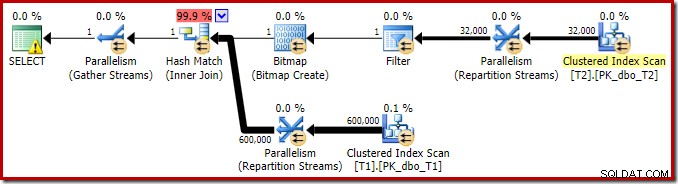
सेलेक्ट आइकन पर चेतावनी सिर्फ कॉलम c1 के लिए टेबल T1 पर एक लापता इंडेक्स के बारे में शिकायत कर रही है (पीके के साथ एक कॉलम के रूप में)। अनुक्रमणिका सुझाव यहाँ अप्रासंगिक है।
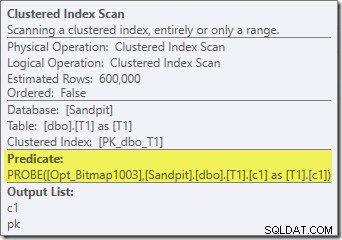
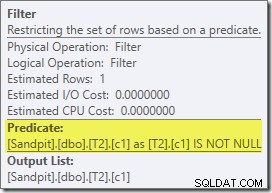
इस योजना में रुचि की पहली वास्तविक वस्तु फ़िल्टर है:
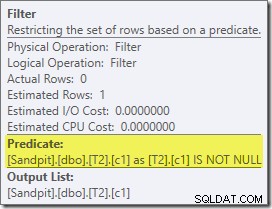
यह IS NOT NULL विधेय स्रोत क्वेरी में प्रकट नहीं होता है, हालांकि यह निहित है जैसा कि पहले उल्लेख किया गया है, विधेय में शामिल हों। यह दिलचस्प है कि इसे एक स्पष्ट अतिरिक्त ऑपरेटर के रूप में तोड़ा गया है, और ज्वाइन ऑपरेशन से पहले रखा गया है। ध्यान दें कि फ़िल्टर के बिना भी, क्वेरी अभी भी सही परिणाम देगी - जॉइन अभी भी नल को अस्वीकार कर देगा।
फ़िल्टर अन्य कारणों से भी उत्सुक है। इसकी अनुमानित लागत बिल्कुल शून्य है (भले ही यह 32,000 पंक्तियों पर संचालित होने की उम्मीद है), और इसे अवशिष्ट विधेय के रूप में क्लस्टर्ड इंडेक्स स्कैन में नीचे धकेला नहीं गया है। अनुकूलक आमतौर पर ऐसा करने के लिए बहुत उत्सुक होता है।
इन दोनों बातों को इस तथ्य से समझाया गया है कि इस फ़िल्टर को पोस्ट-ऑप्टिमाइज़ेशन पुनर्लेखन में पेश किया गया है। क्वेरी ऑप्टिमाइज़र द्वारा अपना लागत-आधारित संसाधन पूरा करने के बाद, निश्चित योजना पुनर्लेखन की अपेक्षाकृत कम संख्या पर विचार किया जाता है। इनमें से एक फ़िल्टर शुरू करने के लिए ज़िम्मेदार है।
हम गैर-दस्तावेजी ट्रेस फ़्लैग 8607 और परिचित 3604 का उपयोग करके कंसोल (एसएसएमएस में संदेश टैब) पर टेक्स्ट आउटपुट को निर्देशित करने के लिए लागत-आधारित योजना चयन (पुनर्लेखन से पहले) का आउटपुट देख सकते हैं:
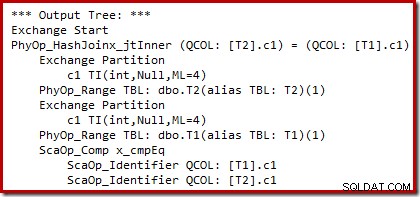
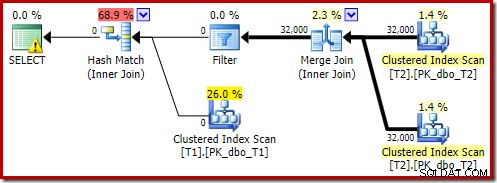
आउटपुट ट्री एक हैश जॉइन, दो स्कैन और कुछ समानांतरवाद (एक्सचेंज) ऑपरेटरों को दिखाता है। तालिका T2 के c1 कॉलम पर कोई नल-अस्वीकार फ़िल्टर नहीं है।
विशेष रूप से पोस्ट-ऑप्टिमाइज़ेशन पुनर्लेखन विशेष रूप से हैश जॉइन के बिल्ड इनपुट पर दिखता है। स्थिति के अपने आकलन के आधार पर, यह सम्मिलित कुंजी में रिक्त पंक्तियों को अस्वीकार करने के लिए एक स्पष्ट फ़िल्टर जोड़ सकता है। अनुमानित पंक्ति गणना पर फ़िल्टर का प्रभाव निष्पादन योजना में भी लिखा जाता है, लेकिन चूंकि लागत-आधारित अनुकूलन पहले ही पूरा हो चुका है, इसलिए फ़िल्टर की लागत की गणना नहीं की जाती है। यदि यह स्पष्ट नहीं है, तो लागत की गणना करना प्रयास की बर्बादी है यदि सभी लागत-आधारित निर्णय पहले ही किए जा चुके हैं।
फ़िल्टर सीधे बिल्ड इनपुट पर बना रहता है न कि क्लस्टर्ड इंडेक्स स्कैन में नीचे धकेल दिया जाता है क्योंकि मुख्य अनुकूलन गतिविधि पूरी हो चुकी है। पोस्ट-ऑप्टिमाइज़ेशन पुनर्लेखन एक पूर्ण निष्पादन योजना के लिए प्रभावी रूप से अंतिम-मिनट के बदलाव हैं।
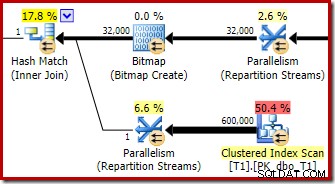
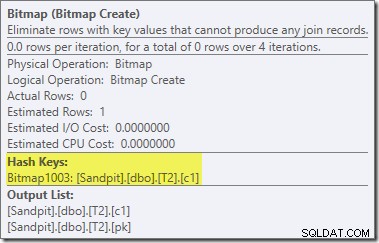
अंतिम योजना में बिटमैप ऑपरेटर के लिए एक दूसरा, और काफी अलग, पोस्ट-ऑप्टिमाइज़ेशन पुनर्लेखन जिम्मेदार है (आपने देखा होगा कि यह 8607 आउटपुट से भी गायब था):
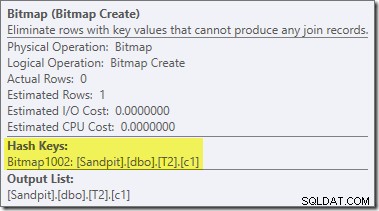
इस ऑपरेटर के पास I/O और CPU दोनों के लिए शून्य अनुमानित लागत भी है। दूसरी चीज जो इसे देर से ट्वीक (लागत-आधारित अनुकूलन के दौरान) द्वारा पेश किए गए ऑपरेटर के रूप में पहचानती है, वह यह है कि इसका नाम बिटमैप है जिसके बाद एक नंबर है। लागत-आधारित अनुकूलन के दौरान अन्य प्रकार के बिटमैप पेश किए गए हैं जिन्हें हम थोड़ी देर बाद देखेंगे।
अभी के लिए, इस बिटमैप के बारे में महत्वपूर्ण बात यह है कि यह हैश जॉइन के निर्माण चरण के दौरान देखे गए c1 मानों को रिकॉर्ड करता है। जब हैश का निर्माण चरण से जांच चरण में संक्रमण होता है, तो पूर्ण बिटमैप को शामिल होने के जांच पक्ष में धकेल दिया जाता है। बिटमैप का उपयोग प्रारंभिक अर्ध-जुड़ने में कमी करने के लिए किया जाता है, जांच पक्ष से उन पंक्तियों को समाप्त करता है जो संभवतः शामिल नहीं हो सकते हैं। अगर आपको इसके बारे में अधिक जानकारी चाहिए, तो कृपया इस विषय पर मेरा पिछला लेख देखें।
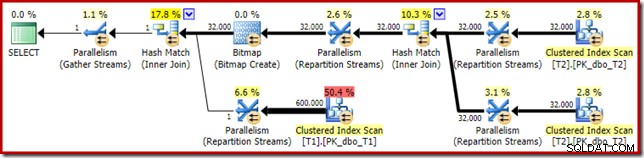
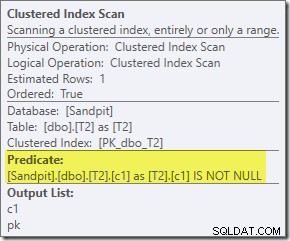
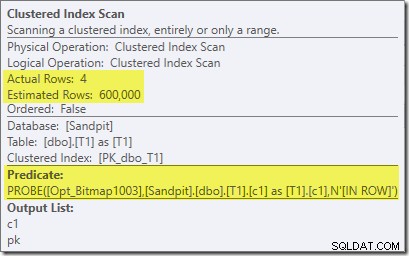
बिटमैप का दूसरा प्रभाव प्रोब-साइड क्लस्टर्ड इंडेक्स स्कैन पर देखा जा सकता है:
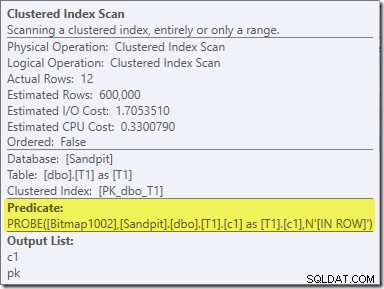
ऊपर दिया गया स्क्रीनशॉट पूर्ण बिटमैप को तालिका T1 पर क्लस्टर किए गए इंडेक्स स्कैन के भाग के रूप में चेक किया जा रहा है। चूंकि स्रोत कॉलम एक पूर्णांक है (एक बड़ा भी काम करेगा) बिटमैप चेक को क्वेरी प्रोसेसर द्वारा चेक किए जाने के बजाय स्टोरेज इंजन (जैसा कि 'INROW' क्वालिफायर द्वारा इंगित किया गया है) में सभी तरह से धकेल दिया जाता है। अधिक सामान्य रूप से, बिटमैप को जांच पक्ष के किसी भी ऑपरेटर पर एक्सचेंज डाउन से लागू किया जा सकता है। क्वेरी प्रोसेसर बिटमैप को कितनी दूर तक धकेल सकता है यह कॉलम के प्रकार और SQL सर्वर के संस्करण पर निर्भर करता है।
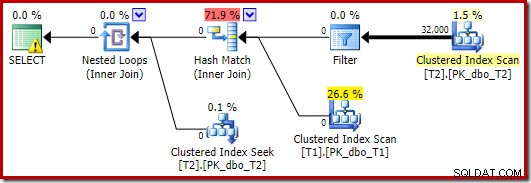
इस निष्पादन योजना की प्रमुख विशेषताओं के विश्लेषण को पूरा करने के लिए, हमें निष्पादन के बाद ('वास्तविक') योजना को देखने की जरूरत है:
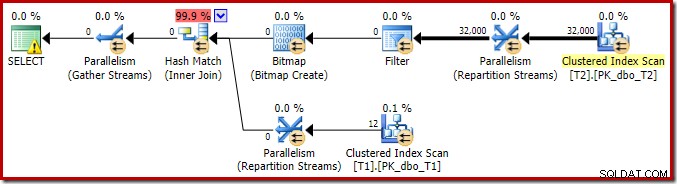
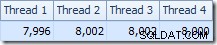
ध्यान देने वाली पहली बात यह है कि T2 स्कैन और इसके ठीक ऊपर रिपार्टिशन स्ट्रीम एक्सचेंज के बीच थ्रेड्स में पंक्तियों का वितरण होता है। एक परीक्षण चलाने पर, मैंने चार तार्किक प्रोसेसर वाले सिस्टम पर निम्नलिखित वितरण देखा:
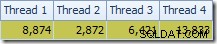
वितरण विशेष रूप से समान नहीं है, जैसा कि अक्सर अपेक्षाकृत कम संख्या में पंक्तियों पर समानांतर स्कैन के लिए होता है, लेकिन कम से कम सभी थ्रेड्स को कुछ काम मिला। एक ही रीपार्टिशन स्ट्रीम एक्सचेंज और फ़िल्टर के बीच थ्रेड वितरण बहुत अलग है:
इससे पता चलता है कि तालिका T2 की सभी 32,000 पंक्तियों को एक ही थ्रेड द्वारा संसाधित किया गया था। यह देखने के लिए कि हमें विनिमय गुणों को देखने की आवश्यकता क्यों है:

यह एक्सचेंज, हैश जॉइन के जांच पक्ष की तरह, यह सुनिश्चित करने की आवश्यकता है कि समान जॉइन कुंजी मान वाली पंक्तियाँ हैश जॉइन के समान उदाहरण पर समाप्त होती हैं। DOP 4 में, चार हैश जॉइन होते हैं, जिनमें से प्रत्येक की अपनी हैश तालिका होती है। सही परिणामों के लिए, बिल्ड-साइड पंक्तियाँ और प्रोब-साइड पंक्तियाँ समान जॉइन कुंजियों के साथ एक ही हैश जॉइन पर पहुंचनी चाहिए; अन्यथा हम गलत हैश तालिका के खिलाफ जांच-साइड पंक्ति की जांच कर सकते हैं।
एक पंक्ति-मोड समानांतर योजना में, SQL सर्वर एक ही हैश फ़ंक्शन का उपयोग करके दोनों इनपुट को जॉइन कॉलम पर पुन:विभाजित करके प्राप्त करता है। वर्तमान मामले में, जॉइन कॉलम c1 पर है, इसलिए जॉइन की कॉलम (c1) में हैश फंक्शन (विभाजन प्रकार:हैश) को लागू करके इनपुट थ्रेड्स में वितरित किए जाते हैं। यहां मुद्दा यह है कि स्तंभ c1 में तालिका T2 में केवल एक मान - नल - होता है, इसलिए सभी 32,000 पंक्तियों को समान हैश मान दिया जाता है, इसलिए सभी एक ही थ्रेड पर समाप्त होते हैं।
अच्छी खबर यह है कि इनमें से कोई भी वास्तव में इस प्रश्न के लिए मायने नहीं रखता है। पोस्ट-ऑप्टिमाइज़ेशन पुनर्लेखन फ़िल्टर बहुत अधिक काम करने से पहले सभी पंक्तियों को हटा देता है। मेरे लैपटॉप पर, उपरोक्त क्वेरी लगभग 70ms . में निष्पादित होती है (उम्मीद के अनुसार कोई परिणाम नहीं देती है) ।
तीन तालिकाओं में शामिल होना
दूसरे परीक्षण के लिए, हम तालिका T2 से इसकी प्राथमिक कुंजी पर एक अतिरिक्त जुड़ाव जोड़ते हैं:
dbo.T1 से T1.pk चुनें T1JOIN dbo.T2 AS T2 पर T2.c1 =T1.c1JOIN dbo.T2 AS T3 - नया! T3.pk =T2.pk पर;
यह क्वेरी के तार्किक परिणामों को नहीं बदलता है, लेकिन यह निष्पादन योजना को बदल देता है:
जैसा कि अपेक्षित था, तालिका T2 की प्राथमिक कुंजी पर स्वयं-जुड़ने का उस तालिका से योग्य पंक्तियों की संख्या पर कोई प्रभाव नहीं पड़ता है:
इस योजना अनुभाग में सभी थ्रेड्स में पंक्तियों का वितरण भी अच्छा है। स्कैन के लिए, यह पहले जैसा ही है क्योंकि समानांतर स्कैन मांग पर थ्रेड्स को पंक्तियों को वितरित करता है। जॉइन की के हैश के आधार पर एक्सचेंजों का पुनर्विभाजन, जो कि इस बार पीके कॉलम है। विभिन्न पीके मूल्यों की सीमा को देखते हुए, परिणामी धागा वितरण भी बहुत समान है:
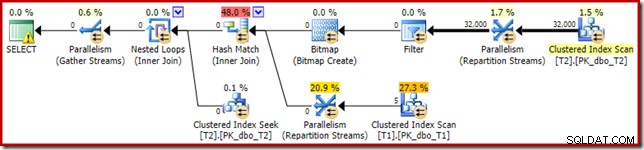
अनुमानित योजना के अधिक दिलचस्प खंड की ओर मुड़ते हुए, दो-तालिका परीक्षण से कुछ अंतर हैं:

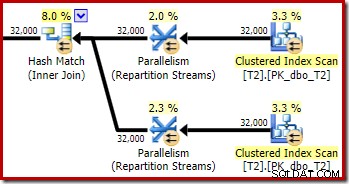
एक बार फिर, बिल्ड-साइड एक्सचेंज सभी पंक्तियों को एक ही थ्रेड पर रूट करना समाप्त कर देता है क्योंकि c1 जॉइन की है, और इसलिए रिपार्टिशन स्ट्रीम एक्सचेंजों के लिए विभाजन कॉलम (याद रखें, तालिका T2 में सभी पंक्तियों के लिए c1 शून्य है)।
पिछले परीक्षण की तुलना में योजना के इस खंड में दो अन्य महत्वपूर्ण अंतर हैं। सबसे पहले, हैश जॉइन के निर्माण पक्ष से नल-सी 1 पंक्तियों को हटाने के लिए कोई फ़िल्टर नहीं है। इसके लिए स्पष्टीकरण दूसरे अंतर से जुड़ा हुआ है - बिटमैप बदल गया है, हालांकि यह ऊपर की तस्वीर से स्पष्ट नहीं है:
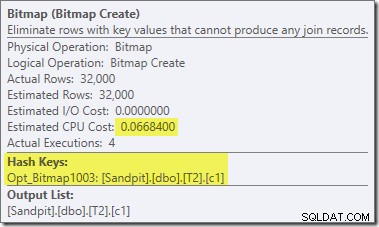
यह एक ऑप्ट_बिटमैप है, बिटमैप नहीं। अंतर यह है कि यह बिटमैप लागत-आधारित अनुकूलन के दौरान पेश किया गया था, न कि अंतिम-मिनट के पुनर्लेखन द्वारा। अनुकूलित बिटमैप्स पर विचार करने वाला तंत्र स्टार-जॉइन प्रश्नों को संसाधित करने से जुड़ा है। स्टार-जॉइन लॉजिक के लिए कम से कम तीन जॉइन टेबल की आवश्यकता होती है, इसलिए यह बताता है कि क्यों एक अनुकूलित बिटमैप को टू-टेबल जॉइन उदाहरण में नहीं माना गया था।
इस अनुकूलित बिटमैप में गैर-शून्य अनुमानित CPU लागत है, और अनुकूलक द्वारा चुनी गई समग्र योजना को सीधे प्रभावित करता है। प्रोब-साइड कार्डिनैलिटी अनुमान पर इसका प्रभाव रिपार्टिशन स्ट्रीम्स ऑपरेटर पर देखा जा सकता है:
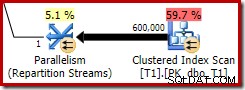
नोट करें कि कार्डिनैलिटी प्रभाव एक्सचेंज पर देखा जाता है, भले ही बिटमैप को अंततः स्टोरेज इंजन ('INROW') में नीचे धकेल दिया जाता है, जैसा कि हमने पहले टेस्ट में देखा था (लेकिन अब Opt_Bitmap संदर्भ पर ध्यान दें):
निष्पादन के बाद ('वास्तविक') योजना इस प्रकार है:
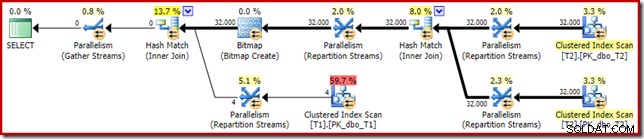
अनुकूलित बिटमैप की अनुमानित प्रभावशीलता का अर्थ है कि शून्य फ़िल्टर के लिए अलग पोस्ट-ऑप्टिमाइज़ेशन पुनर्लेखन लागू नहीं किया गया है। व्यक्तिगत रूप से, मुझे लगता है कि यह दुर्भाग्यपूर्ण है क्योंकि फ़िल्टर के साथ जल्दी से नल को खत्म करने से बिटमैप बनाने, हैश टेबल को पॉप्युलेट करने और टेबल टी 1 के बिटमैप-एन्हांस्ड स्कैन करने की आवश्यकता को अस्वीकार कर दिया जाएगा। फिर भी, अनुकूलक अन्यथा निर्णय लेता है और इस उदाहरण में इसके साथ कोई बहस नहीं है।
तालिका T2 के अतिरिक्त स्व-जुड़ने और लापता फ़िल्टर से जुड़े अतिरिक्त कार्य के बावजूद, यह निष्पादन योजना अभी भी त्वरित समय में अपेक्षित परिणाम (कोई पंक्तियाँ नहीं) उत्पन्न करती है। मेरे लैपटॉप पर एक सामान्य निष्पादन में लगभग 200ms . का समय लगता है ।
डेटा प्रकार बदलना
इस तीसरे परीक्षण के लिए, हम दोनों तालिकाओं में डेटा प्रकार के कॉलम c1 को पूर्णांक से दशमलव में बदल देंगे। इस पसंद के बारे में विशेष रूप से कुछ खास नहीं है; एक ही प्रभाव किसी भी संख्यात्मक प्रकार के साथ देखा जा सकता है जो पूर्णांक या बड़ा नहीं है।
वैकल्पिक तालिका dbo.T1ALTER COLUMN c1 दशमलव (9,0) NULL; वैकल्पिक तालिका dbo.T2ALTER कॉलम c1 दशमलव (9,0) NULL; ALTER INDEX PK_dbo_T1 ऑन dbo.T1 रीबिल्ड विद (MAXDOP =1); ALTER INDEX PK_dbo_T2 ऑन dbo.T2 रीबिल्ड विद (MAXDOP =1); अद्यतन सांख्यिकी dbo.T1 फुलस्कैन के साथ; अद्यतन सांख्यिकी dbo.T2 फुलस्कैन के साथ;
थ्री-जॉइन जॉइन क्वेरी का पुन:उपयोग करना:
dbo से T1.pk चुनें।अनुमानित निष्पादन योजना बहुत परिचित लगती है:
इस तथ्य के अलावा कि अनुकूलित बिटमैप अब डेटा प्रकार के परिवर्तन के कारण स्टोरेज इंजन द्वारा 'INROW' लागू नहीं किया जा सकता है, निष्पादन योजना अनिवार्य रूप से समान है। नीचे दिया गया कैप्चर स्कैन गुणों में बदलाव दिखाता है:
दुर्भाग्य से, प्रदर्शन नाटकीय रूप से प्रभावित होता है। यह क्वेरी 70ms या 200ms में नहीं, बल्कि लगभग 20 मिनट . में निष्पादित होती है . निम्नलिखित पोस्ट-निष्पादन योजना का निर्माण करने वाले परीक्षण में, रनटाइम वास्तव में 22 मिनट और 29 सेकंड था:
सबसे स्पष्ट अंतर यह है कि तालिका T1 पर क्लस्टर्ड इंडेक्स स्कैन अनुकूलित बिटमैप फ़िल्टर लागू होने के बाद भी 300,000 पंक्तियाँ देता है। यह कुछ समझ में आता है, क्योंकि बिटमैप उन पंक्तियों पर बनाया गया है जिनमें c1 कॉलम में केवल नल होते हैं। बिटमैप T1 स्कैन से गैर-शून्य पंक्तियों को हटा देता है, केवल 300,000 पंक्तियों को c1 के लिए शून्य मानों के साथ छोड़ देता है। याद रखें, T1 में आधी पंक्तियाँ शून्य हैं।
फिर भी, यह अजीब लगता है कि 32,000 पंक्तियों के साथ 300,000 पंक्तियों में शामिल होने में 20 मिनट से अधिक समय लगना चाहिए। यदि आप सोच रहे थे, तो पूरे निष्पादन के लिए एक सीपीयू कोर 100% पर आंकी गई थी। इस खराब प्रदर्शन और अत्यधिक संसाधन उपयोग की व्याख्या कुछ विचारों पर आधारित है जिन्हें हमने पहले खोजा था:
उदाहरण के लिए, हम पहले से ही जानते हैं कि समानांतर निष्पादन चिह्नों के बावजूद, T2 की सभी पंक्तियाँ एक ही धागे पर समाप्त होती हैं। एक अनुस्मारक के रूप में, पंक्ति-मोड समानांतर हैश जॉइन के लिए जॉइन कॉलम (c1) पर पुनर्विभाजन की आवश्यकता होती है। T2 की सभी पंक्तियों का मान समान है - शून्य - स्तंभ c1 में, इसलिए सभी पंक्तियाँ एक ही धागे पर समाप्त होती हैं। इसी तरह, T1 की सभी पंक्तियाँ जो बिटमैप फ़िल्टर को पास करती हैं, कॉलम c1 में भी शून्य होती हैं, इसलिए वे भी उसी थ्रेड में पुन:विभाजित होती हैं। यह बताता है कि क्यों एक ही कोर सारा काम करता है।
यह अभी भी अनुचित लग सकता है कि हैश को 300,000 पंक्तियों के साथ 32,000 पंक्तियों में शामिल होने में 20 मिनट लगने चाहिए, खासकर जब से दोनों पक्षों में शामिल होने वाले कॉलम शून्य हैं, और वैसे भी शामिल नहीं होंगे। इसे समझने के लिए, हमें यह सोचना होगा कि यह हैश जॉइन कैसे काम करता है।
बिल्ड इनपुट (32,000 पंक्तियाँ) जॉइन कॉलम, c1 का उपयोग करके एक हैश टेबल बनाता है। चूंकि प्रत्येक बिल्ड-साइड पंक्ति में कॉलम c1 में शामिल होने के लिए समान मान (शून्य) होता है, इसका मतलब है कि सभी 32,000 पंक्तियां एक ही हैश बाल्टी में समाप्त होती हैं। जब हैश जॉइन करता है तो मैचों की जांच के लिए स्विच करता है, प्रत्येक जांच-साइड पंक्ति एक नल c1 कॉलम के साथ भी उसी बाल्टी में हैश हो जाती है। हैश जॉइन को मैच के लिए उस बकेट में सभी 32,000 प्रविष्टियों की जांच करनी चाहिए।
300,000 जांच पंक्तियों की जाँच के परिणामस्वरूप 32,000 तुलनाएँ 300,000 बार की जाती हैं। हैश जॉइन के लिए यह सबसे खराब स्थिति है:सभी साइड रो हैश को एक ही बकेट में बनाते हैं, जिसके परिणामस्वरूप अनिवार्य रूप से कार्टेशियन उत्पाद होता है। यह लंबे निष्पादन समय और निरंतर 100% प्रोसेसर उपयोग की व्याख्या करता है क्योंकि हैश लंबी हैश बकेट श्रृंखला का अनुसरण करता है।
यह खराब प्रदर्शन यह समझाने में मदद करता है कि हैश जॉइन में बिल्ड इनपुट पर नल को खत्म करने के लिए पोस्ट-ऑप्टिमाइज़ेशन रीराइट क्यों मौजूद है। यह दुर्भाग्यपूर्ण है कि इस मामले में फ़िल्टर लागू नहीं किया गया।
समाधान
अनुकूलक इस योजना आकार को चुनता है क्योंकि यह गलत अनुमान लगाता है कि अनुकूलित बिटमैप तालिका T1 से सभी पंक्तियों को फ़िल्टर कर देगा। हालांकि यह अनुमान क्लस्टर्ड इंडेक्स स्कैन के बजाय पुनर्विभाजन धाराओं में दिखाया गया है, यह अभी भी निर्णय का आधार है। एक अनुस्मारक के रूप में पूर्व-निष्पादन योजना का प्रासंगिक खंड फिर से है:
यदि यह एक सही अनुमान होता, तो हैश जॉइन को संसाधित करने में बिल्कुल भी समय नहीं लगता। यह दुर्भाग्यपूर्ण है कि अनुकूलित बिटमैप के लिए चयनात्मकता अनुमान बहुत गलत है जब डेटा प्रकार एक साधारण पूर्णांक या बड़ा नहीं है। ऐसा लगता है कि एक पूर्णांक या बिगिंट कुंजी पर बनाया गया बिटमैप भी नल पंक्तियों को फ़िल्टर करने में सक्षम है जो शामिल नहीं हो सकते हैं। यदि वास्तव में ऐसा है, तो यह पूर्णांक या बिगिन्ट जॉइन कॉलम को प्राथमिकता देने का एक प्रमुख कारण है।
इसके बाद के समाधान काफी हद तक समस्याग्रस्त अनुकूलित बिटमैप को समाप्त करने के विचार पर आधारित हैं।
सीरियल निष्पादन
अनुकूलित बिटमैप्स को रोकने का एक तरीका गैर-समानांतर योजना की आवश्यकता है। रो-मोड बिटमैप ऑपरेटर (अनुकूलित या अन्यथा) केवल समानांतर योजनाओं में देखे जाते हैं:
से T1.pk चुनें (dbo.T2 के रूप में T2 में शामिल हों dbo.T2 के रूप में T3 पर T3.pk =T2.pk) शामिल हों dbo.T1 के रूप में T1 पर T1.c1 =T2.c1 विकल्प (MAXDOP 1, बल आदेश);उस क्वेरी को एक योजना आकार उत्पन्न करने के लिए एक बल आदेश संकेत के साथ थोड़ा अलग वाक्यविन्यास का उपयोग करके व्यक्त किया जाता है जो पिछली समानांतर योजनाओं के साथ तुलना में अधिक आसानी से तुलनीय है। आवश्यक विशेषता MAXDOP 1 संकेत है।
वह अनुमानित योजना दिखाती है कि ऑप्टिमाइज़ेशन के बाद फिर से लिखना फ़िल्टर बहाल किया जा रहा है:
योजना के निष्पादन के बाद के संस्करण से पता चलता है कि यह बिल्ड इनपुट से सभी पंक्तियों को फ़िल्टर करता है, जिसका अर्थ है कि जांच पक्ष स्कैन को पूरी तरह से छोड़ दिया जा सकता है:
जैसा कि आप उम्मीद करेंगे, क्वेरी का यह संस्करण बहुत तेज़ी से निष्पादित होता है - मेरे लिए औसतन लगभग 20ms। हम बल आदेश संकेत और क्वेरी पुनर्लेखन के बिना एक समान प्रभाव प्राप्त कर सकते हैं:
dbo.T1 से T1.pk चुनें, T1 में शामिल हों।ऑप्टिमाइज़र इस मामले में एक अलग योजना आकार चुनता है, जिसमें फ़िल्टर सीधे T2 के स्कैन के ऊपर रखा जाता है:
यह और भी तेजी से निष्पादित होता है - लगभग 10ms में - जैसा कि कोई उम्मीद करेगा। स्वाभाविक रूप से, यह एक अच्छा विकल्प नहीं होगा यदि मौजूद (और जुड़ने योग्य) पंक्तियों की संख्या बहुत अधिक होती।
अनुकूलित बिटमैप्स को बंद करना
अनुकूलित बिटमैप्स को बंद करने के लिए कोई क्वेरी संकेत नहीं है, लेकिन हम कुछ अनिर्दिष्ट ट्रेस फ़्लैग का उपयोग करके समान प्रभाव प्राप्त कर सकते हैं। हमेशा की तरह, यह केवल ब्याज मूल्य के लिए है; आप इन्हें वास्तविक सिस्टम या एप्लिकेशन में कभी भी उपयोग नहीं करना चाहेंगे:
dbo.T1 से T1.pk चुनें, T1 के रूप में शामिल हों।>परिणामी निष्पादन योजना है:
बिटमैप एक पोस्ट-ऑप्टिमाइज़ेशन पुनर्लेखन बिटमैप है, न कि एक अनुकूलित बिटमैप:
शून्य लागत अनुमानों और बिटमैप नाम (Opt_Bitmap के बजाय) पर ध्यान दें। लागत अनुमानों को तिरछा करने के लिए एक अनुकूलित बिटमैप के बिना, एक नल-अस्वीकार फ़िल्टर को शामिल करने के लिए पोस्ट-ऑप्टिमाइज़ेशन फिर से लिखना सक्रिय है। यह निष्पादन योजना लगभग 70ms . में चलती है ।
एक ही निष्पादन योजना (फ़िल्टर और गैर-अनुकूलित बिटमैप के साथ) को स्टार जॉइन बिटमैप योजनाओं को उत्पन्न करने के लिए जिम्मेदार ऑप्टिमाइज़र नियम को अक्षम करके भी तैयार किया जा सकता है (फिर से, सख्ती से अनिर्दिष्ट और वास्तविक दुनिया के उपयोग के लिए नहीं):
dbo से T1.pk चुनें।
एक स्पष्ट फ़िल्टर सहित
यह सबसे आसान विकल्प है, लेकिन अब तक चर्चा किए गए मुद्दों से अवगत होने पर ही कोई ऐसा करने के बारे में सोचेगा। अब जब हम जानते हैं कि हमें T2.c1 से नल को समाप्त करने की आवश्यकता है, तो हम इसे सीधे क्वेरी में जोड़ सकते हैं:
डीबीओ से टी1.पीके चुनें। -- नया!परिणामी अनुमानित निष्पादन योजना शायद वह नहीं है जिसकी आप अपेक्षा कर रहे हैं:
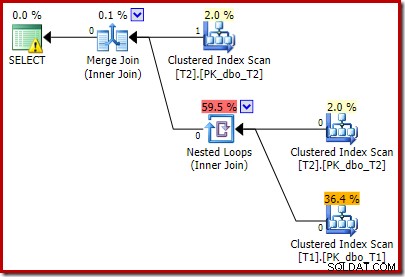
हमने जो अतिरिक्त विधेय जोड़ा है उसे T2 के मध्य क्लस्टर इंडेक्स स्कैन में धकेल दिया गया है:
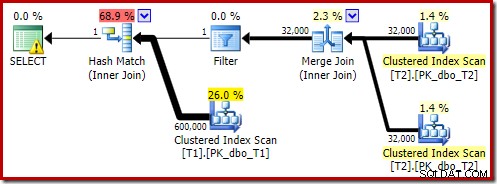
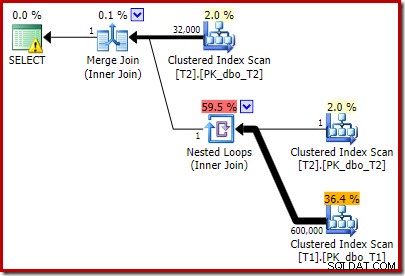
निष्पादन के बाद की योजना है:
ध्यान दें कि मर्ज जॉइन अपने शीर्ष इनपुट से एक पंक्ति को पढ़ने के बाद बंद हो जाता है, फिर हमारे द्वारा जोड़े गए विधेय के प्रभाव के कारण इसके निचले इनपुट पर एक पंक्ति खोजने में विफल रहता है। तालिका T1 का क्लस्टर्ड इंडेक्स स्कैन कभी भी निष्पादित नहीं किया जाता है, क्योंकि नेस्टेड लूप्स जॉइन को इसके ड्राइविंग इनपुट पर कभी भी एक पंक्ति नहीं मिलती है। यह अंतिम क्वेरी फ़ॉर्म एक या दो मिलीसेकंड में निष्पादित होता है।
अंतिम विचार
इस लेख में कुछ कम प्रसिद्ध क्वेरी ऑप्टिमाइज़र व्यवहारों का पता लगाने के लिए और एक विशिष्ट मामले में बेहद खराब हैश जॉइन प्रदर्शन के कारणों की व्याख्या करने के लिए उचित मात्रा में जमीन को कवर किया गया है।
यह पूछना आकर्षक हो सकता है कि ऑप्टिमाइज़र समानता में शामिल होने से पहले नियमित रूप से नल-अस्वीकार फ़िल्टर क्यों नहीं जोड़ता है। कोई केवल यह मान सकता है कि यह पर्याप्त सामान्य मामलों में फायदेमंद नहीं होगा। अधिकांश जॉइन से कई अशक्त =अशक्त अस्वीकृतियों का सामना करने की उम्मीद नहीं की जाती है, और नियमित रूप से विधेय जोड़ना जल्दी से प्रति-उत्पादक बन सकता है, खासकर यदि कई जॉइन कॉलम मौजूद हैं। अधिकांश जॉइन के लिए, जॉइन ऑपरेटर के अंदर नल को अस्वीकार करना शायद एक बेहतर विकल्प है (लागत मॉडल के नजरिए से) एक स्पष्ट फ़िल्टर शुरू करने की तुलना में।
ऐसा लगता है कि सबसे खराब मामलों को पोस्ट-ऑप्टिमाइज़ेशन रीराइट के माध्यम से प्रकट होने से रोकने का प्रयास है, जो हैश जॉइन के बिल्ड इनपुट तक पहुंचने से पहले नल जॉइन पंक्तियों को अस्वीकार करने के लिए डिज़ाइन किया गया है। ऐसा लगता है कि अनुकूलित बिटमैप फ़िल्टर के प्रभाव और इस पुनर्लेखन के अनुप्रयोग के बीच एक दुर्भाग्यपूर्ण बातचीत मौजूद है। यह भी दुर्भाग्यपूर्ण है कि जब यह प्रदर्शन समस्या होती है, तो अकेले निष्पादन योजना से निदान करना बहुत मुश्किल होता है।
अभी के लिए, सबसे अच्छा विकल्प इस संभावित प्रदर्शन समस्या के बारे में पता है, जिसमें हैश के साथ अशक्त स्तंभों पर जुड़ता है, और यदि आवश्यक हो, तो एक कुशल निष्पादन योजना तैयार की जाती है, यह सुनिश्चित करने के लिए स्पष्ट अशक्त-अस्वीकार विधेय (एक टिप्पणी के साथ!) MAXDOP 1 संकेत का उपयोग करने से टेल-टेल फ़िल्टर के साथ एक वैकल्पिक योजना भी सामने आ सकती है।
एक सामान्य नियम के रूप में, क्वेरी जो पूर्णांक प्रकार के स्तंभों पर जुड़ती हैं और मौजूद डेटा की तलाश में जाती हैं, वे विकल्प के बजाय ऑप्टिमाइज़र मॉडल और निष्पादन इंजन क्षमताओं के अनुकूल होती हैं।
पावती
मैं SQL_Sasquatch (@sqL_handLe) को तकनीकी विश्लेषण के साथ उनके मूल लेख का जवाब देने की अनुमति के लिए धन्यवाद देना चाहता हूं। यहां इस्तेमाल किया गया नमूना डेटा काफी हद तक उस लेख पर आधारित है।
मैं वर्षों से हमारी तकनीकी चर्चाओं के लिए रॉब फ़ार्ले (ब्लॉग | ट्विटर) को भी धन्यवाद देना चाहता हूं, और विशेष रूप से जनवरी 2015 में जहां हमने समान-जुड़ने के लिए अतिरिक्त नल-अस्वीकार भविष्यवाणी के प्रभावों पर चर्चा की। रॉब ने संबंधित विषयों के बारे में कई बार लिखा है, जिसमें इनवर्स प्रेडिकेट्स भी शामिल है - पार करने से पहले दोनों तरह से देखें।