कुछ हफ्ते पहले PASS समिट में, Microsoft ने SQL Server 2019 का CTP2.1 जारी किया, और CTP में शामिल एक बड़ी सुविधा एन्हांसमेंट स्केलर UDF इनलाइनिंग है। इस रिलीज से पहले मैं स्केलर यूडीएफ की इनलाइनिंग और एसक्यूएल सर्वर के पुराने संस्करणों में स्केलर यूडीएफ के आरबीएआर (पंक्ति-दर-एगोनाइजिंग-पंक्ति) निष्पादन के बीच प्रदर्शन अंतर के साथ खेलना चाहता था और मैं इसके लिए एक वाक्यविन्यास विकल्प पर हुआ था समारोह बनाएं SQL सर्वर बुक्स ऑनलाइन में कथन जो मैंने पहले कभी नहीं देखा था।
सृजन समारोह . के लिए डीडीएल फ़ंक्शन विकल्पों के लिए WITH क्लॉज़ का समर्थन करता है और ऑनलाइन पुस्तकें पढ़ते समय मैंने देखा कि सिंटैक्स में निम्नलिखित शामिल हैं:
-- ट्रांजैक्ट-एसक्यूएल फंक्शन क्लॉज::= { [ एनक्रिप्शन ] | [ योजना बनाना ] | [ न्यूल इनपुट पर रिटर्न देता है | पूर्ण इनपुट पर कॉल किया गया] | [ EXECUTE_AS_Clause ] }
मैं वास्तव में न्यूल इनपुट पर रिटर्न के बारे में उत्सुक था फ़ंक्शन विकल्प इसलिए मैंने कुछ परीक्षण करने का निर्णय लिया। मुझे यह जानकर बहुत आश्चर्य हुआ कि यह वास्तव में स्केलर यूडीएफ ऑप्टिमाइज़ेशन का एक रूप है जो कम से कम SQL Server 2008 R2 के बाद से उत्पाद में है।
यह पता चला है कि यदि आप जानते हैं कि एक स्केलर UDF हमेशा एक NULL परिणाम लौटाएगा जब एक NULL इनपुट प्रदान किया जाता है तो UDF को हमेशा NULL इनपुट पर रिटर्न के साथ बनाया जाना चाहिए। विकल्प, क्योंकि तब SQL सर्वर किसी भी पंक्ति के लिए फ़ंक्शन परिभाषा को बिल्कुल भी नहीं चलाता है जहाँ इनपुट NULL है - इसे प्रभावी रूप से शॉर्ट-सर्किट करना और फ़ंक्शन बॉडी के व्यर्थ निष्पादन से बचना।
आपको यह व्यवहार दिखाने के लिए, मैं नवीनतम संचयी अद्यतन और AdventureWorks2017 के साथ SQL सर्वर 2017 इंस्टेंस का उपयोग करने जा रहा हूं। GitHub से डेटाबेस (आप इसे यहाँ से डाउनलोड कर सकते हैं) जो एक dbo.ufnLeadingZeros के साथ आता है फ़ंक्शन जो केवल इनपुट मान में अग्रणी शून्य जोड़ता है और एक आठ वर्ण स्ट्रिंग देता है जिसमें वे अग्रणी शून्य शामिल होते हैं। मैं उस फ़ंक्शन का एक नया संस्करण बनाने जा रहा हूं जिसमें शामिल है विकल्प ताकि मैं निष्पादन प्रदर्शन के लिए मूल फ़ंक्शन के विरुद्ध इसकी तुलना कर सकूं।
उपयोग [AdventureWorks2017];GO CREATE FUNCTION [dbo].[ufnLeadingZeros_new]( @Value int ) SCHEMABINDING के साथ varchar(8) लौटाता है, न्यूल इनपुट पर NULL देता है जैसे BEGIN DECLARE @ReturnValue @ReturnValue; SET @ReturnValue =CONVERT(varchar(8), @Value); SET @ReturnValue =REPLICATE('0', 8 - DATALENGTH(@ReturnValue)) + @ReturnValue; रिटर्न (@ReturnValue); अंत; जाओ दो कार्यों के डेटाबेस इंजन के भीतर निष्पादन प्रदर्शन अंतर के परीक्षण के प्रयोजनों के लिए, मैंने sqlserver.module_end को ट्रैक करने के लिए सर्वर पर एक विस्तारित ईवेंट सत्र बनाने का निर्णय लिया। घटना, जो प्रत्येक पंक्ति के लिए स्केलर यूडीएफ के प्रत्येक निष्पादन के अंत में सक्रिय होती है। यह मुझे पंक्ति-दर-पंक्ति प्रसंस्करण शब्दार्थ प्रदर्शित करने देता है, और मुझे यह भी ट्रैक करने देता है कि परीक्षण के दौरान वास्तव में कितनी बार फ़ंक्शन लागू किया गया था। मैंने sql_batch_completed . को भी एकत्रित करने का निर्णय लिया है और sql_statement_completed ईवेंट और सब कुछ session_id . द्वारा फ़िल्टर करें यह सुनिश्चित करने के लिए कि मैं केवल उस सत्र से संबंधित जानकारी कैप्चर कर रहा था जिस पर मैं वास्तव में परीक्षण चला रहा था (यदि आप इन परिणामों को दोहराना चाहते हैं, तो आपको नीचे दिए गए कोड में सभी स्थानों में 74 को बदलना होगा, जो भी सत्र आईडी आपका परीक्षण कोड चल रहा होगा)। इवेंट सत्र TRACK_CAUSALITY का उपयोग कर रहा है ताकि यह गिनना आसान हो कि activity_id.seq_no के माध्यम से फ़ंक्शन के कितने निष्पादन हुए। ईवेंट के लिए मान (जो session_id को संतुष्ट करने वाले प्रत्येक ईवेंट के लिए एक से बढ़ जाता है) फ़िल्टर)।
ईवेंट सत्र बनाएं [सत्र 72] सर्वर पर जोड़ें ईवेंट sqlserver.module_end( जहां ([पैकेज0]। [पैकेज0]।[equal_uint64]([sqlserver].[session_id],(74)))), इवेंट जोड़ें ))), घटना जोड़ें sqlserver.sql_statement_completed( कहां ([पैकेज0]। ([sqlserver].[session_id],(74)))) के साथ (TRACK_CAUSALITY=ON) GO
एक बार जब मैंने इवेंट सत्र शुरू किया और प्रबंधन स्टूडियो में लाइव डेटा व्यूअर खोला, तो मैंने दो क्वेरी चलाईं; एक फ़ंक्शन के मूल संस्करण का उपयोग करके CurrencyRateID . पर शून्य को पैड करने के लिए Sales.SalesOrderHeader . में कॉलम तालिका, और नया फ़ंक्शन समान आउटपुट उत्पन्न करने के लिए, लेकिन NULL इनपुट पर रिटर्न NULL का उपयोग करके विकल्प, और मैंने तुलना के लिए वास्तविक निष्पादन योजना की जानकारी प्राप्त की।
SalesOrderID, dbo.ufnLeadingZeros(CurrencyRateID) को Sales.SalesOrderHeader से चुनें; SalesOrderID, dbo.ufnLeadingZeros_new(CurrencyRateID) से Sales.SalesOrderHeader चुनें; जाओ
विस्तारित ईवेंट डेटा की समीक्षा करने पर कुछ दिलचस्प चीज़ें दिखाई दीं। सबसे पहले, मूल फ़ंक्शन 31,465 बार चला (module_end . की गिनती से) इवेंट) और कुल CPU समय sql_statement_completed . के लिए घटना 482ms अवधि के साथ 204ms थी।
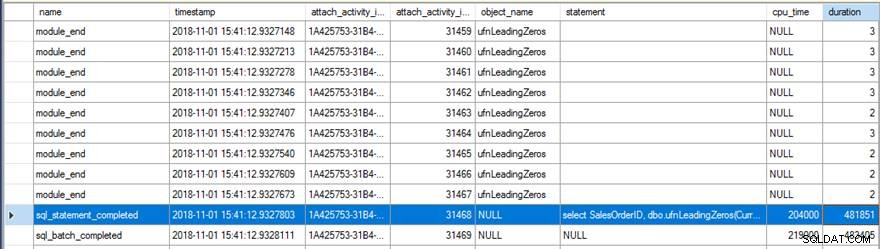
नया संस्करण न्यूल इनपुट पर रिटर्न देता है निर्दिष्ट विकल्प केवल 13,976 बार चला (फिर से, module_end . की गिनती से) ईवेंट) और CPU समय sql_statement_completed . के लिए 359ms अवधि के साथ इवेंट 78ms का था।

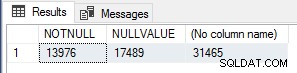
मुझे यह दिलचस्प लगा इसलिए निष्पादन की संख्या को सत्यापित करने के लिए मैंने NOT NULL गिनने के लिए निम्नलिखित क्वेरी चलाई Sales.SalesOrderHeader में मान पंक्तियाँ, NULL मान पंक्तियाँ और कुल पंक्तियाँ टेबल।
चुनें SUM (केस जब करेंसी रेटिड शून्य नहीं है तो 1 ELSE 0 END) NOTNULL के रूप में, SUM (केस जब करेंसी रेटिड शून्य हो तो 1 और 0 END) NULLVALUE के रूप में, FROM COUNT(*)ader;
ये संख्याएँ module_end . की संख्या के बिल्कुल अनुरूप हैं प्रत्येक परीक्षण के लिए ईवेंट, इसलिए यह निश्चित रूप से स्केलर यूडीएफ के लिए एक बहुत ही सरल प्रदर्शन अनुकूलन है जिसका उपयोग किया जाना चाहिए यदि आप जानते हैं कि फ़ंक्शन का परिणाम न्यूल होगा यदि इनपुट मान न्यूल हैं, शॉर्ट-सर्किट/बाईपास फ़ंक्शन निष्पादन के लिए पूरी तरह से उन पंक्तियों के लिए।
वास्तविक निष्पादन योजनाओं में QueryTimeStats जानकारी भी प्रदर्शन लाभ को दर्शाती है:
यह अकेले CPU समय में काफी महत्वपूर्ण कमी है, जो कुछ सिस्टमों के लिए एक महत्वपूर्ण दर्द बिंदु हो सकता है।
स्केलर यूडीएफ का उपयोग प्रदर्शन के लिए एक प्रसिद्ध डिजाइन विरोधी पैटर्न है और उनके उपयोग और प्रदर्शन हिट से बचने के लिए कोड को फिर से लिखने के लिए कई तरीके हैं। लेकिन अगर वे पहले से मौजूद हैं और उन्हें आसानी से बदला या हटाया नहीं जा सकता है, तो बस यूडीएफ को न्यूल इनपुट पर रिटर्न के साथ फिर से बनाएं। विकल्प प्रदर्शन को बढ़ाने का एक बहुत ही सरल तरीका हो सकता है यदि डेटा सेट में बहुत सारे NULL इनपुट हैं जहाँ UDF का उपयोग किया जाता है।