आरबीसी में एक जूनियर फिक्स्ड इनकम एनालिस्ट करेन ली ने मुझे एक टी-एसक्यूएल चुनौती दी, जिसमें सटीक मिलान खोजने के बजाय निकटतम मैच ढूंढना शामिल है। इस लेख में मैं चुनौती के एक सामान्यीकृत, सरलीकृत रूप को कवर करता हूं।
चुनौती
चुनौती में दो तालिकाओं, T1 और T2 से मेल खाने वाली पंक्तियाँ शामिल हैं। टेस्टडीबी नामक एक नमूना डेटाबेस बनाने के लिए निम्नलिखित कोड का उपयोग करें, और इसके भीतर टेबल T1 और T2:
SET NOCOUNT ON;
IF DB_ID('testdb') IS NULL
CREATE DATABASE testdb;
GO
USE testdb;
DROP TABLE IF EXISTS dbo.T1, dbo.T2;
CREATE TABLE dbo.T1
(
keycol INT NOT NULL IDENTITY
CONSTRAINT PK_T1 PRIMARY KEY,
val INT NOT NULL,
othercols BINARY(100) NOT NULL
CONSTRAINT DFT_T1_col1 DEFAULT(0xAA)
);
CREATE TABLE dbo.T2
(
keycol INT NOT NULL IDENTITY
CONSTRAINT PK_T2 PRIMARY KEY,
val INT NOT NULL,
othercols BINARY(100) NOT NULL
CONSTRAINT DFT_T2_col1 DEFAULT(0xBB)
); जैसा कि आप देख सकते हैं, T1 और T2 दोनों में एक संख्यात्मक कॉलम (इस उदाहरण में INT प्रकार) है जिसे वैल कहा जाता है। चुनौती T1 से प्रत्येक पंक्ति से T2 की पंक्ति का मिलान करना है जहां T2.val और T1.val के बीच पूर्ण अंतर सबसे कम है। टाई के मामले में (T2 में कई मिलान वाली पंक्तियाँ), वैल आरोही, कीकोल आरोही क्रम के आधार पर शीर्ष पंक्ति का मिलान करें। यही है, वैल कॉलम में सबसे कम मान वाली पंक्ति, और यदि आपके पास अभी भी संबंध हैं, तो सबसे कम कीकोल मान वाली पंक्ति। टाईब्रेकर का उपयोग नियतिवाद की गारंटी के लिए किया जाता है।
अपने समाधानों की शुद्धता की जांच करने में सक्षम होने के लिए नमूना डेटा के छोटे सेट के साथ T1 और T2 को पॉप्युलेट करने के लिए निम्न कोड का उपयोग करें:
TRUNCATE TABLE dbo.T1;
TRUNCATE TABLE dbo.T2;
INSERT INTO dbo.T1 (val)
VALUES(1),(1),(3),(3),(5),(8),(13),(16),(18),(20),(21);
INSERT INTO dbo.T2 (val)
VALUES(2),(2),(7),(3),(3),(11),(11),(13),(17),(19); T1 की सामग्री की जाँच करें:
SELECT keycol, val, SUBSTRING(othercols, 1, 1) AS othercols FROM dbo.T1 ORDER BY val, keycol;
यह कोड निम्न आउटपुट उत्पन्न करता है:
keycol val othercols ----------- ----------- --------- 1 1 0xAA 2 1 0xAA 3 3 0xAA 4 3 0xAA 5 5 0xAA 6 8 0xAA 7 13 0xAA 8 16 0xAA 9 18 0xAA 10 20 0xAA 11 21 0xAA
T2 की सामग्री की जाँच करें:
SELECT keycol, val, SUBSTRING(othercols, 1, 1) AS othercols FROM dbo.T2 ORDER BY val, keycol;
यह कोड निम्न आउटपुट उत्पन्न करता है:
keycol val othercols ----------- ----------- --------- 1 2 0xBB 2 2 0xBB 4 3 0xBB 5 3 0xBB 3 7 0xBB 6 11 0xBB 7 11 0xBB 8 13 0xBB 9 17 0xBB 10 19 0xBB
यहां दिए गए नमूना डेटा के लिए वांछित परिणाम दिया गया है:
keycol1 val1 othercols1 keycol2 val2 othercols2 ----------- ----------- ---------- ----------- ----------- ---------- 1 1 0xAA 1 2 0xBB 2 1 0xAA 1 2 0xBB 3 3 0xAA 4 3 0xBB 4 3 0xAA 4 3 0xBB 5 5 0xAA 4 3 0xBB 6 8 0xAA 3 7 0xBB 7 13 0xAA 8 13 0xBB 8 16 0xAA 9 17 0xBB 9 18 0xAA 9 17 0xBB 10 20 0xAA 10 19 0xBB 11 21 0xAA 10 19 0xBB
इससे पहले कि आप चुनौती पर काम करना शुरू करें, वांछित परिणाम की जांच करें और सुनिश्चित करें कि आप मिलान तर्क को समझते हैं, जिसमें टाईब्रेकिंग लॉजिक भी शामिल है। उदाहरण के लिए, T1 में पंक्ति पर विचार करें जहां कीकॉल 5 है और वैल 5 है। इस पंक्ति में T2 में कई निकटतम मिलान हैं:
keycol val othercols ----------- ----------- --------- 4 3 0xBB 5 3 0xBB 3 7 0xBB
इन सभी पंक्तियों में T2.val और T1.val (5) के बीच पूर्ण अंतर 2 है। ऑर्डर वैल आरोही के आधार पर टाईब्रेकिंग लॉजिक का उपयोग करते हुए, कीकोल यहां सबसे ऊपर की पंक्ति में आरोही है जहां वैल 3 है और कीकोल 4 है।
आप अपने समाधानों की वैधता की जांच करने के लिए नमूना डेटा के छोटे सेटों का उपयोग करेंगे। प्रदर्शन की जांच करने के लिए, आपको बड़े सेट की आवश्यकता है। GetNums नामक एक सहायक फ़ंक्शन बनाने के लिए निम्न कोड का उपयोग करें, जो अनुरोधित श्रेणी में पूर्णांकों का एक क्रम उत्पन्न करता है:
DROP FUNCTION IF EXISTS dbo.GetNums;
GO
CREATE OR ALTER FUNCTION dbo.GetNums(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
L0 AS (SELECT c FROM (SELECT 1 UNION ALL SELECT 1) AS D(c)),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5)
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum;
GO नमूना डेटा के बड़े सेट के साथ T1 और T2 को पॉप्युलेट करने के लिए निम्न कोड का उपयोग करें:
DECLARE
@numrowsT1 AS INT = 1000000,
@maxvalT1 AS INT = 10000000,
@numrowsT2 AS INT = 1000000,
@maxvalT2 AS INT = 10000000;
TRUNCATE TABLE dbo.T1;
TRUNCATE TABLE dbo.T2;
INSERT INTO dbo.T1 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT1 + 1 AS val
FROM dbo.GetNums(1, @numrowsT1) AS Nums;
INSERT INTO dbo.T2 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT2 + 1 AS val
FROM dbo.GetNums(1, @numrowsT2) AS Nums; चर @ numrowsT1 और @ numrowsT2 उन पंक्तियों की संख्या को नियंत्रित करते हैं जिनसे आप तालिकाओं को पॉप्युलेट करना चाहते हैं। चर @ maxvalT1 और @ maxvalT2 वैल कॉलम में अलग-अलग मानों की श्रेणी को नियंत्रित करते हैं, और इसलिए कॉलम के घनत्व को प्रभावित करते हैं। उपरोक्त कोड प्रत्येक तालिका को 1,000,000 पंक्तियों से भरता है, और दोनों तालिकाओं में वैल कॉलम के लिए 1 - 10,000,000 की सीमा का उपयोग करता है। इसके परिणामस्वरूप कॉलम में कम घनत्व होता है (बड़ी संख्या में अलग-अलग मान, कम संख्या में डुप्लिकेट के साथ)। कम अधिकतम मानों का उपयोग करने से उच्च घनत्व (भिन्न मानों की छोटी संख्या, और इसलिए अधिक डुप्लीकेट) में परिणाम होगा।
समाधान 1, एक TOP सबक्वेरी का उपयोग करके
सबसे सरल और सबसे स्पष्ट समाधान शायद वह है जो T1 से पूछताछ करता है, और CROSS APPLY ऑपरेटर का उपयोग करके एक TOP (1) फ़िल्टर के साथ एक क्वेरी लागू करता है, T2.val का उपयोग करके T1.val और T2.val के बीच पूर्ण अंतर द्वारा पंक्तियों को क्रमबद्ध करता है। , T2.keycol टाईब्रेकर के रूप में। ये रहा समाधान का कोड:
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
A.keycol AS keycol2, A.val AS val2, SUBSTRING(A.othercols, 1, 1) AS othercols2
FROM dbo.T1
CROSS APPLY
( SELECT TOP (1) T2.*
FROM dbo.T2
ORDER BY ABS(T2.val - T1.val), T2.val, T2.keycol ) AS A; याद रखें, प्रत्येक तालिका में 1,000,000 पंक्तियाँ हैं। और दोनों तालिकाओं में वैल कॉलम का घनत्व कम है। दुर्भाग्य से, चूंकि लागू क्वेरी में कोई फ़िल्टरिंग विधेय नहीं है, और ऑर्डरिंग में एक अभिव्यक्ति शामिल है जो कॉलम में हेरफेर करती है, यहां सहायक इंडेक्स बनाने की कोई संभावना नहीं है। यह क्वेरी चित्र 1 में योजना तैयार करती है।
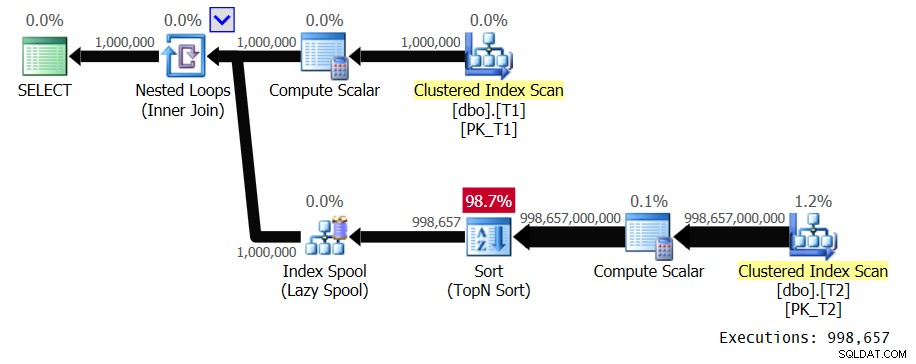 चित्र 1:समाधान 1 के लिए योजना
चित्र 1:समाधान 1 के लिए योजना
लूप का बाहरी इनपुट T1 से 1,000,000 पंक्तियों को स्कैन करता है। लूप का आंतरिक इनपुट प्रत्येक विशिष्ट T1.val मान के लिए T2 और एक TopN सॉर्ट का पूर्ण स्कैन करता है। हमारी योजना में ऐसा 998,657 बार होता है क्योंकि हमारे पास बहुत कम घनत्व है। यह पंक्तियों को एक इंडेक्स स्पूल में रखता है, जिसे T1.val द्वारा बंद किया जाता है, ताकि यह T1.val मानों की डुप्लिकेट घटनाओं के लिए उनका पुन:उपयोग कर सके, लेकिन हमारे पास बहुत कम डुप्लिकेट हैं। इस योजना में द्विघात जटिलता है। लूप की आंतरिक शाखा के सभी अपेक्षित निष्पादन के बीच, यह एक ट्रिलियन पंक्तियों के करीब संसाधित होने की उम्मीद है। किसी क्वेरी को संसाधित करने के लिए बड़ी संख्या में पंक्तियों के बारे में बात करते समय, एक बार जब आप अरबों पंक्तियों का उल्लेख करना शुरू करते हैं, तो लोग पहले से ही जानते हैं कि आप एक महंगी क्वेरी के साथ काम कर रहे हैं। आम तौर पर, लोग खरबों की तरह शब्दों का उच्चारण नहीं करते हैं, जब तक कि वे अमेरिकी राष्ट्रीय ऋण, या शेयर बाजार के दुर्घटनाग्रस्त होने पर चर्चा नहीं कर रहे हों। आप आमतौर पर क्वेरी प्रोसेसिंग के संदर्भ में ऐसे नंबरों से निपटते नहीं हैं। लेकिन द्विघात जटिलता वाली योजनाएँ ऐसी संख्याओं के साथ जल्दी समाप्त हो सकती हैं। SSMS में क्वेरी को शामिल करें लाइव क्वेरी सांख्यिकी सक्षम के साथ चलाने में मेरे लैपटॉप पर T1 से केवल 100 पंक्तियों को संसाधित करने में 39.6 सेकंड का समय लगा। इसका मतलब है कि इस क्वेरी को पूरा होने में लगभग 4.5 दिन लगने चाहिए। सवाल यह है कि क्या आप वास्तव में लाइव क्वेरी योजनाओं को द्वि घातुमान देख रहे हैं? कोशिश करने और सेट करने के लिए एक दिलचस्प गिनीज रिकॉर्ड हो सकता है।
समाधान 2, दो शीर्ष उपश्रेणियों का उपयोग करते हुए
यह मानते हुए कि आप एक ऐसे समाधान के पीछे हैं जिसे पूरा होने में कुछ सेकंड लगते हैं, दिन नहीं, यहाँ एक विचार है। एप्लाइड टेबल एक्सप्रेशन में, दो आंतरिक TOP (1) क्वेरीज़ को एकीकृत करें- एक पंक्ति को फ़िल्टर करना जहाँ T2.val
इस समाधान का समर्थन करने के लिए यहां अनुशंसित अनुक्रमणिकाएं दी गई हैं:
CREATE INDEX idx_val_key ON dbo.T1(val, keycol) INCLUDE(othercols); CREATE INDEX idx_val_key ON dbo.T2(val, keycol) INCLUDE(othercols); CREATE INDEX idx_valD_key ON dbo.T2(val DESC, keycol) INCLUDE(othercols);
यहां संपूर्ण समाधान कोड दिया गया है:
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
A.keycol AS keycol2, A.val AS val2, SUBSTRING(A.othercols, 1, 1) AS othercols2
FROM dbo.T1
CROSS APPLY
( SELECT TOP (1) D.*
FROM ( SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val < T1.val
ORDER BY T2.val DESC, T2.keycol
UNION ALL
SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val >= T1.val
ORDER BY T2.val, T2.keycol ) AS D
ORDER BY ABS(D.val - T1.val), D.val, D.keycol ) AS A; याद रखें कि हमारे पास प्रत्येक तालिका में 1,000,000 पंक्तियाँ हैं, वैल कॉलम में 1 - 10,000,000 (कम घनत्व) की सीमा में मान हैं, और इष्टतम अनुक्रमणिकाएँ हैं।
इस क्वेरी की योजना चित्र 2 में दिखाई गई है।
चित्र 2:समाधान 2 के लिए योजना
T2 पर इंडेक्स के इष्टतम उपयोग का निरीक्षण करें, जिसके परिणामस्वरूप रैखिक स्केलिंग के साथ एक योजना बनती है। यह योजना एक इंडेक्स स्पूल का उपयोग उसी तरह करती है जैसे पिछली योजना ने किया था, अर्थात, डुप्लिकेट T1.val मानों के लिए लूप की आंतरिक शाखा में कार्य को दोहराने से बचने के लिए। मेरे सिस्टम पर इस क्वेरी के निष्पादन के लिए मुझे जो प्रदर्शन आंकड़े मिले हैं, वे यहां दिए गए हैं:
Elapsed: 27.7 sec, CPU: 27.6 sec, logical reads: 17,304,674
समाधान 2, स्पूलिंग अक्षम के साथ
आप मदद नहीं कर सकते लेकिन आश्चर्य करते हैं कि क्या इंडेक्स स्पूल वास्तव में यहां फायदेमंद है। मुद्दा यह है कि डुप्लिकेट T1.val मानों के लिए दोहराए जाने वाले कार्य से बचने के लिए, लेकिन हमारे जैसी स्थिति में जहां हमारे पास बहुत कम घनत्व है, वहां बहुत कम डुप्लिकेट हैं। इसका मतलब यह है कि स्पूलिंग में शामिल कार्य सबसे अधिक संभावना है कि डुप्लिकेट के लिए काम को दोहराने से कहीं अधिक है। इसे सत्यापित करने का एक आसान तरीका है—ट्रेस फ्लैग 8690 का उपयोग करके आप योजना में स्पूलिंग को अक्षम कर सकते हैं, जैसे:
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
A.keycol AS keycol2, A.val AS val2, SUBSTRING(A.othercols, 1, 1) AS othercols2
FROM dbo.T1
CROSS APPLY
( SELECT TOP (1) D.*
FROM ( SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val < T1.val
ORDER BY T2.val DESC, T2.keycol
UNION ALL
SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val >= T1.val
ORDER BY T2.val, T2.keycol ) AS D
ORDER BY ABS(D.val - T1.val), D.val, D.keycol ) AS A
OPTION(QUERYTRACEON 8690); मुझे इस निष्पादन के लिए चित्र 3 में दिखाई गई योजना मिली:
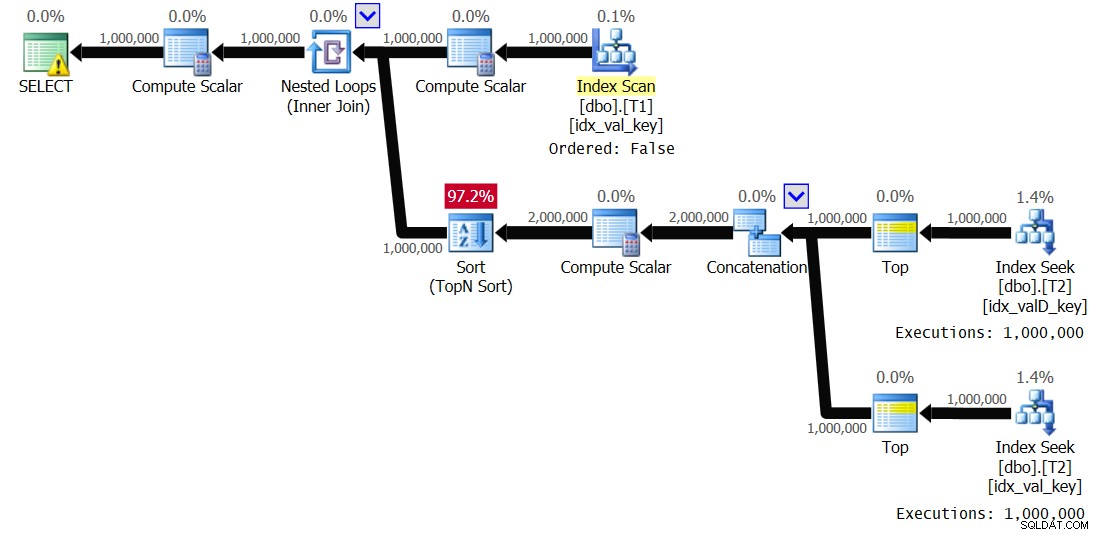 चित्र 3:स्पूलिंग अक्षम के साथ समाधान 2 की योजना
चित्र 3:स्पूलिंग अक्षम के साथ समाधान 2 की योजना
ध्यान दें कि इंडेक्स स्पूल गायब हो गया है, और इस बार लूप की आंतरिक शाखा को 1,000,000 बार निष्पादित किया जाता है। इस निष्पादन के लिए मुझे जो प्रदर्शन आंकड़े मिले हैं, वे यहां दिए गए हैं:
Elapsed: 19.18 sec, CPU: 19.17 sec, logical reads: 6,042,148
यह निष्पादन समय में 44 प्रतिशत की कमी है।
समाधान 2, संशोधित मान श्रेणी और अनुक्रमण के साथ
जब आप T1.val मानों में कम घनत्व रखते हैं, तो स्पूलिंग को अक्षम करना बहुत मायने रखता है; हालांकि, जब आपके पास उच्च घनत्व होता है तो स्पूलिंग बहुत फायदेमंद हो सकती है। उदाहरण के लिए, नमूना डेटा सेटिंग @maxvalT1 और @maxvalT2 से 1000 (1,000 अधिकतम विशिष्ट मान) के साथ T1 और T2 को फिर से पॉप्युलेट करने के लिए निम्न कोड चलाएँ:
DECLARE
@numrowsT1 AS INT = 1000000,
@maxvalT1 AS INT = 1000,
@numrowsT2 AS INT = 1000000,
@maxvalT2 AS INT = 1000;
TRUNCATE TABLE dbo.T1;
TRUNCATE TABLE dbo.T2;
INSERT INTO dbo.T1 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT1 + 1 AS val
FROM dbo.GetNums(1, @numrowsT1) AS Nums;
INSERT INTO dbo.T2 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT2 + 1 AS val
FROM dbo.GetNums(1, @numrowsT2) AS Nums; समाधान 2 को फिर से चलाएँ, पहले बिना ट्रेस फ़्लैग के:
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
A.keycol AS keycol2, A.val AS val2, SUBSTRING(A.othercols, 1, 1) AS othercols2
FROM dbo.T1
CROSS APPLY
( SELECT TOP (1) D.*
FROM ( SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val < T1.val
ORDER BY T2.val DESC, T2.keycol
UNION ALL
SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val >= T1.val
ORDER BY T2.val, T2.keycol ) AS D
ORDER BY ABS(D.val - T1.val), D.val, D.keycol ) AS A; इस निष्पादन की योजना चित्र 4 में दिखाई गई है:
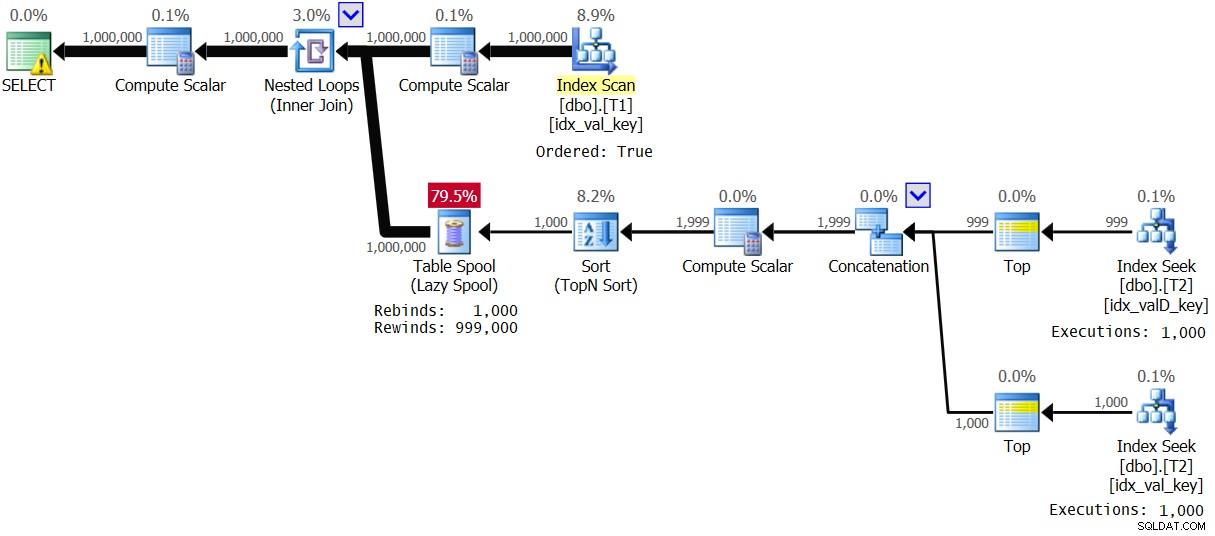 चित्र 4:समाधान 2 के लिए योजना, मूल्य श्रेणी 1 - 1000 के साथ
चित्र 4:समाधान 2 के लिए योजना, मूल्य श्रेणी 1 - 1000 के साथ
ऑप्टिमाइज़र ने T1.val में उच्च घनत्व के कारण एक अलग योजना का उपयोग करने का निर्णय लिया। ध्यान दें कि T1 पर सूचकांक कुंजी क्रम में स्कैन किया गया है। इसलिए, एक विशिष्ट T1.val मान की प्रत्येक पहली घटना के लिए लूप की आंतरिक शाखा को निष्पादित किया जाता है, और परिणाम एक नियमित टेबल स्पूल (रिबाइंड) में स्पूल किया जाता है। फिर, मान की प्रत्येक गैर-प्रथम घटना के लिए, एक रिवाइंड लागू किया जाता है। 1,000 अलग-अलग मानों के साथ, आंतरिक शाखा को केवल 1,000 बार निष्पादित किया जाता है। इसके परिणामस्वरूप उत्कृष्ट प्रदर्शन आँकड़े प्राप्त होते हैं:
Elapsed: 1.16 sec, CPU: 1.14 sec, logical reads: 23,278
अब अक्षम स्पूलिंग के साथ समाधान चलाने का प्रयास करें:
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
A.keycol AS keycol2, A.val AS val2, SUBSTRING(A.othercols, 1, 1) AS othercols2
FROM dbo.T1
CROSS APPLY
( SELECT TOP (1) D.*
FROM ( SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val < T1.val
ORDER BY T2.val DESC, T2.keycol
UNION ALL
SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val >= T1.val
ORDER BY T2.val, T2.keycol ) AS D
ORDER BY ABS(D.val - T1.val), D.val, D.keycol ) AS A
OPTION(QUERYTRACEON 8690); मुझे चित्र 5 में दिखाया गया प्लान मिला है।
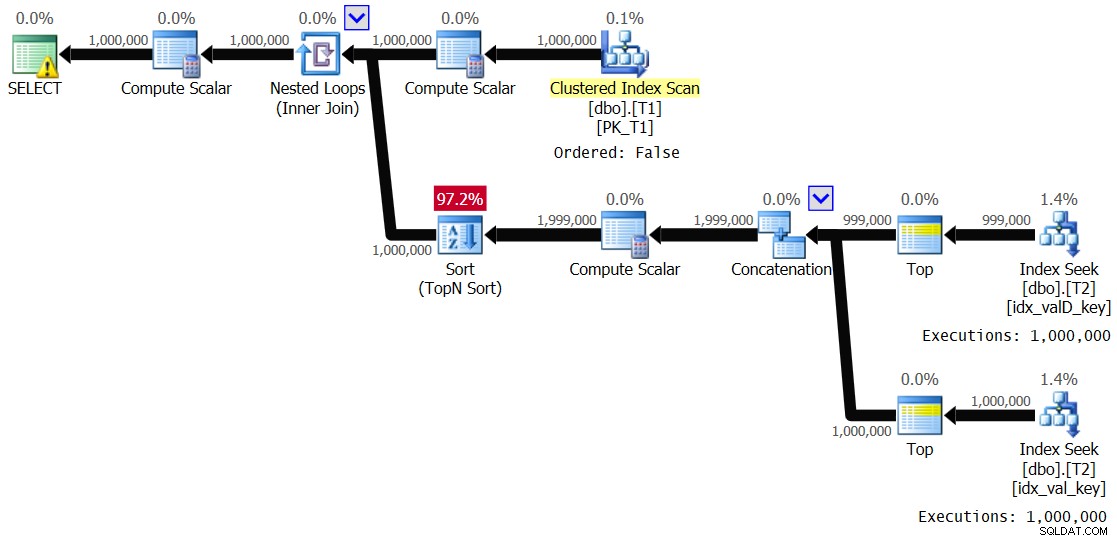 चित्र 5:समाधान 2 के लिए योजना, मूल्य श्रेणी 1 - 1,000 और स्पूलिंग अक्षम के साथ
चित्र 5:समाधान 2 के लिए योजना, मूल्य श्रेणी 1 - 1,000 और स्पूलिंग अक्षम के साथ
यह अनिवार्य रूप से वही योजना है जिसे पहले चित्र 3 में दिखाया गया है। लूप की आंतरिक शाखा को 1,000,000 बार निष्पादित किया जाता है। इस निष्पादन के लिए मुझे जो प्रदर्शन आंकड़े मिले हैं, वे यहां दिए गए हैं:
Elapsed: 24.5 sec, CPU: 24.2 sec, logical reads: 8,012,548
स्पष्ट रूप से, आप सावधान रहना चाहते हैं कि T1.val में उच्च घनत्व होने पर स्पूलिंग को अक्षम न करें।
जीवन अच्छा है जब आपकी स्थिति इतनी सरल है कि आप सहायक सूचकांक बनाने में सक्षम हैं। वास्तविकता यह है कि व्यवहार में कुछ मामलों में, क्वेरी में पर्याप्त अतिरिक्त तर्क होते हैं, जो इष्टतम सहायक अनुक्रमणिका बनाने की क्षमता को रोकता है। ऐसे मामलों में, समाधान 2 अच्छा नहीं करेगा।
इंडेक्स का समर्थन किए बिना समाधान 2 के प्रदर्शन को प्रदर्शित करने के लिए, नमूना डेटा सेटिंग @maxvalT1 और @maxvalT2 से 10000000 (मान रेंज 1 - 10M) के साथ T1 और T2 को फिर से पॉप्युलेट करें, और सपोर्टिंग इंडेक्स को भी हटा दें:
DROP INDEX IF EXISTS idx_val_key ON dbo.T1;
DROP INDEX IF EXISTS idx_val_key ON dbo.T2;
DROP INDEX IF EXISTS idx_valD_key ON dbo.T2;
DECLARE
@numrowsT1 AS INT = 1000000,
@maxvalT1 AS INT = 10000000,
@numrowsT2 AS INT = 1000000,
@maxvalT2 AS INT = 10000000;
TRUNCATE TABLE dbo.T1;
TRUNCATE TABLE dbo.T2;
INSERT INTO dbo.T1 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT1 + 1 AS val
FROM dbo.GetNums(1, @numrowsT1) AS Nums;
INSERT INTO dbo.T2 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT2 + 1 AS val
FROM dbo.GetNums(1, @numrowsT2) AS Nums; समाधान 2 को फिर से चलाएँ, SSMS में शामिल लाइव क्वेरी सांख्यिकी के साथ:
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
A.keycol AS keycol2, A.val AS val2, SUBSTRING(A.othercols, 1, 1) AS othercols2
FROM dbo.T1
CROSS APPLY
( SELECT TOP (1) D.*
FROM ( SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val < T1.val
ORDER BY T2.val DESC, T2.keycol
UNION ALL
SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val >= T1.val
ORDER BY T2.val, T2.keycol ) AS D
ORDER BY ABS(D.val - T1.val), D.val, D.keycol ) AS A; मुझे इस प्रश्न के लिए चित्र 6 में दिखाया गया प्लान मिला है:
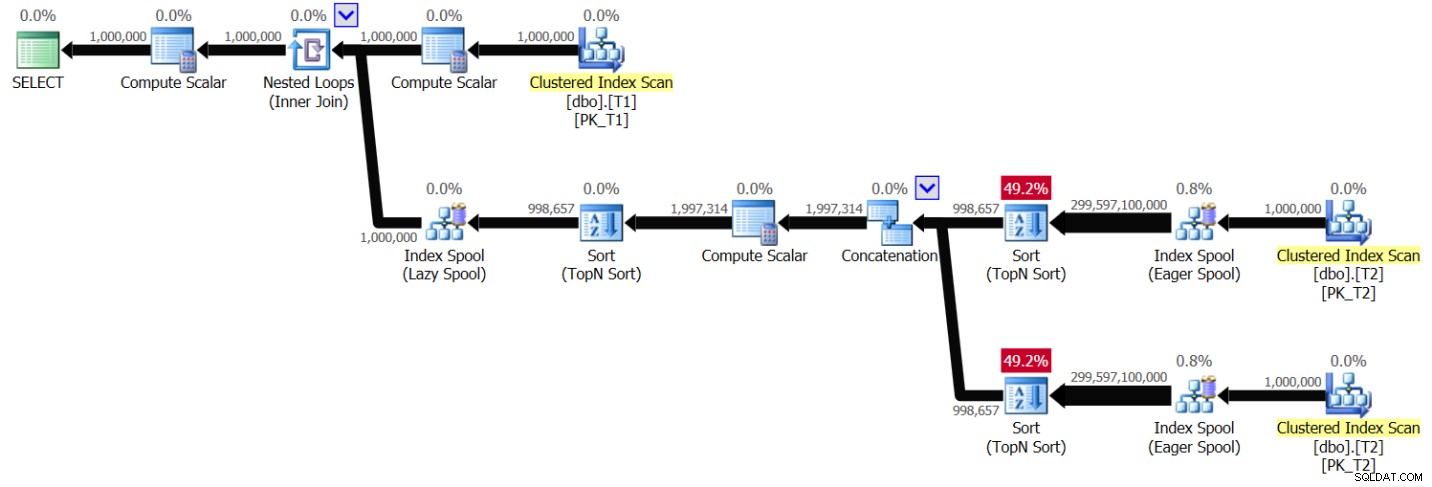 चित्र 6:समाधान 2 के लिए योजना, अनुक्रमण के बिना, मूल्य श्रेणी 1 - 1,000,000 के साथ
चित्र 6:समाधान 2 के लिए योजना, अनुक्रमण के बिना, मूल्य श्रेणी 1 - 1,000,000 के साथ
आप चित्र 1 में पहले दिखाए गए पैटर्न के समान ही एक पैटर्न देख सकते हैं, केवल इस बार योजना T2 को अलग-अलग T1.val मान पर दो बार स्कैन करती है। फिर से, योजना की जटिलता द्विघात हो जाती है। एसएसएमएस में क्वेरी को शामिल करें लाइव क्वेरी सांख्यिकी सक्षम के साथ चलाने में मेरे लैपटॉप पर T1 से 100 पंक्तियों को संसाधित करने में 49.6 सेकंड का समय लगा, जिसका अर्थ है कि इस क्वेरी को पूरा होने में लगभग 5.7 दिन लगने चाहिए। यदि आप लाइव क्वेरी प्लान को द्वि घातुमान देखने के लिए गिनीज वर्ल्ड रिकॉर्ड तोड़ने की कोशिश कर रहे हैं, तो यह निश्चित रूप से अच्छी खबर हो सकती है।
निष्कर्ष
मैं आरबीसी से करेन लाई को धन्यवाद देना चाहता हूं कि उन्होंने मुझे इस सबसे करीबी मैच चुनौती के साथ पेश किया। मैं इसे संभालने के लिए उसके कोड से काफी प्रभावित था, जिसमें बहुत सारे अतिरिक्त तर्क शामिल थे जो उसके सिस्टम के लिए विशिष्ट थे। जब आप इष्टतम सहायक अनुक्रमणिका बनाने में सक्षम होते हैं तो इस लेख में मैंने उचित प्रदर्शन करने वाले समाधान दिखाए। लेकिन जैसा कि आप देख सकते हैं, ऐसे मामलों में जहां यह एक विकल्प नहीं है, जाहिर है कि निष्पादन का समय जो आपको मिलता है वह बहुत ही कम है। क्या आप उन समाधानों के बारे में सोच सकते हैं जो इष्टतम सहायक सूचकांकों के बिना भी अच्छा प्रदर्शन करेंगे? जारी रखने के लिए…