क्या SQL DISTINCT अच्छा (या बुरा) है जब आपको परिणामों में डुप्लिकेट निकालने की आवश्यकता होती है?
कुछ लोग कहते हैं कि यह अच्छा है और डुप्लिकेट दिखाई देने पर DISTINCT जोड़ें। कुछ लोग कहते हैं कि यह खराब है और समग्र फ़ंक्शन के बिना GROUP BY का उपयोग करने का सुझाव देते हैं। दूसरों का कहना है कि जब आपको डुप्लिकेट निकालने की आवश्यकता होती है तो DISTINCT और GROUP BY समान होते हैं।
सही उत्तर पाने के लिए यह पोस्ट विवरण में गोता लगाएगा। तो, अंततः, आप आवश्यकता के आधार पर सर्वोत्तम कीवर्ड का उपयोग करेंगे। आइए शुरू करते हैं।
SQL SELECT DISTINCT स्टेटमेंट की बुनियादी बातों के बारे में एक संक्षिप्त रिमाइंडर
इससे पहले कि हम गहराई में जाएं, आइए याद करें कि SQL SELECT DISTINCT स्टेटमेंट क्या है। एक डेटाबेस तालिका में कई कारणों से डुप्लिकेट मान शामिल हो सकते हैं, लेकिन हम केवल अद्वितीय मान प्राप्त करना चाह सकते हैं। इस मामले में, SELECT DISTINCT काम आता है। यह DISTINCT क्लॉज सेलेक्ट स्टेटमेंट को केवल यूनिक रिकॉर्ड लाने के लिए बनाता है।
कथन का सिंटैक्स सरल है:
SELECT DISTINCT column
FROM table_name
WHERE [condition];यहां, WHERE की स्थिति वैकल्पिक है।
कथन एक कॉलम और एकाधिक कॉलम दोनों पर लागू होता है। एकाधिक स्तंभों पर लागू इस कथन का वाक्य-विन्यास इस प्रकार है:
SELECT DISTINCT
column_name1,
column_name2,
column_nameN.
FROM
table_name;ध्यान दें कि कई स्तंभों को क्वेरी करने का परिदृश्य विशिष्टता को निर्धारित करने के लिए कथन द्वारा परिभाषित सभी स्तंभों में मानों के संयोजन का उपयोग करने का सुझाव देगा।
और अब, SELECT DISTINCT स्टेटमेंट को लागू करने के व्यावहारिक उपयोग और कैच का पता लगाएं।
SQL DISTINCT डुप्लीकेट निकालने के लिए कैसे काम करता है
उत्तर पाना इतना कठिन नहीं है। SQL सर्वर ने हमें यह देखने के लिए निष्पादन योजनाएँ प्रदान की हैं कि हमें आवश्यक परिणाम देने के लिए किसी क्वेरी को कैसे संसाधित किया जाएगा।
निम्न अनुभाग DISTINCT का उपयोग करते समय निष्पादन योजना पर केंद्रित है। आपको Ctrl-M press दबाना होगा नीचे दिए गए प्रश्नों को निष्पादित करने से पहले SQL सर्वर प्रबंधन स्टूडियो में। या, वास्तविक निष्पादन योजना शामिल करें . क्लिक करें टूलबार से।
SQL DISTINCT में क्वेरी प्लान
आइए 2 प्रश्नों की तुलना करके शुरू करें। पहला DISTINCT का उपयोग नहीं करेगा, और दूसरा क्वेरी करेगा।
USE AdventureWorks
GO
-- Without DISTINCT. Duplicates included
SELECT Lastname FROM Person.Person;
-- With DISTINCT. Duplicates removed
SELECT DISTINCT Lastname FROM Person.Person;
यहाँ निष्पादन योजना है:
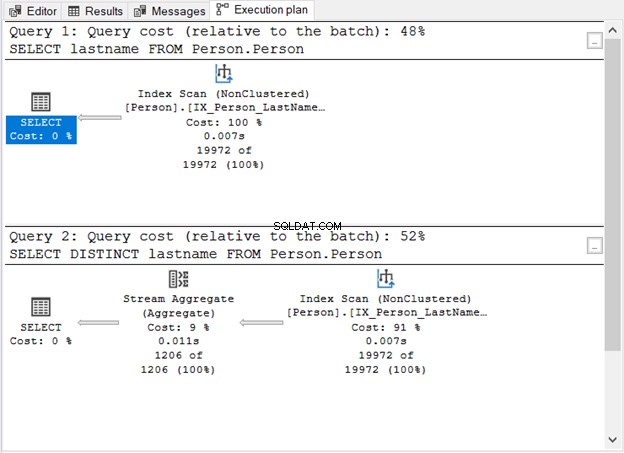
चित्र 1 ने हमें क्या दिखाया?
- DISTINCT कीवर्ड के बिना, क्वेरी आसान है।
- DISTINCT जोड़ने के बाद एक अतिरिक्त चरण दिखाई देता है।
- DISTINCT का उपयोग करने की क्वेरी लागत इसके बिना की तुलना में अधिक है।
- दोनों में इंडेक्स स्कैन ऑपरेटर हैं। यह समझ में आता है क्योंकि हमारे प्रश्नों में कोई विशिष्ट WHERE क्लॉज नहीं है।
- अतिरिक्त चरण, स्ट्रीम एग्रीगेट ऑपरेटर, डुप्लिकेट को हटाने के लिए उपयोग किया जाता है।
यदि आप सांख्यिकी IO की जाँच करते हैं तो तार्किक रीड की संख्या समान (107) है। फिर भी, अभिलेखों की संख्या बहुत भिन्न है। पहली क्वेरी द्वारा 19,972 पंक्तियाँ लौटाई जाती हैं। इस बीच, दूसरी क्वेरी द्वारा 1,206 पंक्तियाँ लौटा दी जाती हैं।
इसलिए, आप जब चाहें DISTINCT नहीं जोड़ सकते। लेकिन अगर आपको अद्वितीय मूल्यों की आवश्यकता है, तो यह एक आवश्यक ओवरहेड है।
अद्वितीय मूल्यों को आउटपुट करने के लिए उपयोग किए जाने वाले ऑपरेटर हैं। आइए उनमें से कुछ की जाँच करें।
STREAM AGGREGATE
यह वह ऑपरेटर है जिसे आपने चित्र 1 में देखा था। यह एकल इनपुट को स्वीकार करता है और एक समग्र परिणाम को आउटपुट करता है। चित्रा 1 में, इनपुट इंडेक्स स्कैन ऑपरेटर से आता है। हालांकि, स्ट्रीम एग्रीगेट को एक क्रमबद्ध इनपुट की आवश्यकता होती है।
जैसा कि आप चित्र 1 में देख सकते हैं, यह IX_Person_LastName_FirstName_MiddleName का उपयोग करता है , नामों पर एक गैर-अद्वितीय अनुक्रमणिका। चूंकि इंडेक्स पहले से ही नाम से रिकॉर्ड्स को सॉर्ट करता है, स्ट्रीम एग्रीगेट इनपुट को स्वीकार करता है। इंडेक्स के बिना, क्वेरी ऑप्टिमाइज़र योजना में एक अतिरिक्त सॉर्ट ऑपरेटर का उपयोग करने का विकल्प चुन सकता है। और यह अधिक महंगा होगा। या, यह हैश मैच का उपयोग कर सकता है।
हैश मैच (कुल)
DISTINCT द्वारा उपयोग किया जाने वाला एक अन्य ऑपरेटर हैश मैच है। इस ऑपरेटर का उपयोग जॉइन और एग्रीगेशन के लिए किया जाता है।
DISTINCT का उपयोग करते समय, हैश मैच अद्वितीय मान उत्पन्न करने के लिए परिणामों को एकत्रित करता है। यहाँ एक उदाहरण है।
USE AdventureWorks
GO
-- Get unique first names
SELECT DISTINCT Firstname FROM Person.Person;
और ये रही निष्पादन योजना:
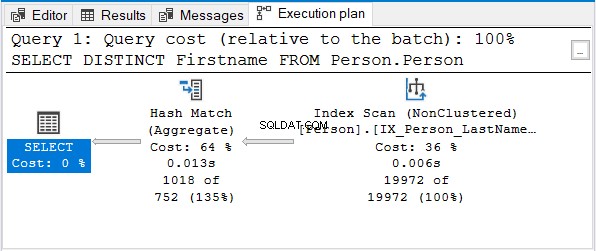
लेकिन स्ट्रीम एग्रीगेट क्यों नहीं?
ध्यान दें कि समान नाम अनुक्रमणिका का उपयोग किया जाता है। वह अनुक्रमणिका अंतिम नाम . के साथ क्रमित होती है प्रथम। तो, एक प्रथम नाम केवल क्वेरी अक्रमित हो जाएगी।
डुप्लिकेट को हटाने के लिए हैश मैच (एग्रीगेट) अगला तार्किक विकल्प है।
HASH MATCH (फ्लो DISTINCT)
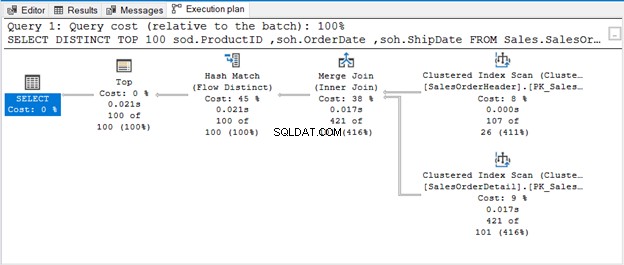
हैश मैच (एग्रीगेट) एक ब्लॉकिंग ऑपरेटर है। इस प्रकार, यह उस आउटपुट का उत्पादन नहीं करेगा जिसने पूरे इनपुट स्ट्रीम को संसाधित किया है। यदि हम पंक्तियों की संख्या को सीमित करते हैं (जैसे DISTINCT के साथ TOP का उपयोग करना), तो जैसे ही वे पंक्तियाँ उपलब्ध होंगी, यह एक अद्वितीय आउटपुट देगा। यही हैश मैच (फ्लो डिस्टिंक्ट) के बारे में है।
USE AdventureWorks
GO
SELECT DISTINCT TOP 100
sod.ProductID
,soh.OrderDate
,soh.ShipDate
FROM Sales.SalesOrderDetail sod
INNER JOIN Sales.SalesOrderHeader soh ON sod.SalesOrderID = soh.SalesOrderID;
क्वेरी DISTINCT के साथ TOP 100 का उपयोग करती है। यहाँ निष्पादन योजना है:
जब डुप्लीकेट निकालने के लिए कोई ऑपरेटर न हो
हां। ऐसा हो सकता है। नीचे दिए गए उदाहरण पर विचार करें।
USE AdventureWorks
GO
SELECT DISTINCT
BusinessEntityID
FROM Person.Person;
फिर, निष्पादन योजना की जाँच करें:
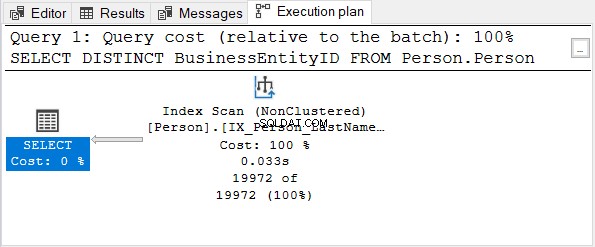
BusinessEntityID कॉलम प्राथमिक कुंजी है। चूंकि वह कॉलम पहले से ही अद्वितीय है, इसलिए DISTINCT लागू करने का कोई फायदा नहीं है। SELECT स्टेटमेंट से DISTINCT को हटाने का प्रयास करें - निष्पादन योजना चित्र 4 की तरह ही है।
अद्वितीय अनुक्रमणिका वाले स्तंभों पर DISTINCT का उपयोग करते समय भी यही बात लागू होती है।
SQL DISTINCT चयन सूची के सभी कॉलम पर काम करता है
अब तक, हमने अपने उदाहरणों में केवल 1 कॉलम का उपयोग किया है। हालाँकि, DISTINCT आपके द्वारा SELECT सूची में निर्दिष्ट सभी कॉलम पर काम करता है।
यहाँ एक उदाहरण है। यह क्वेरी सुनिश्चित करेगी कि सभी 3 कॉलम के मान अद्वितीय होंगे।
USE AdventureWorks
GO
SELECT DISTINCT
Lastname
,FirstName
,MiddleName
FROM Person.Person;
चित्र 5 में सेट किए गए परिणाम में पहली कुछ पंक्तियों पर ध्यान दें।
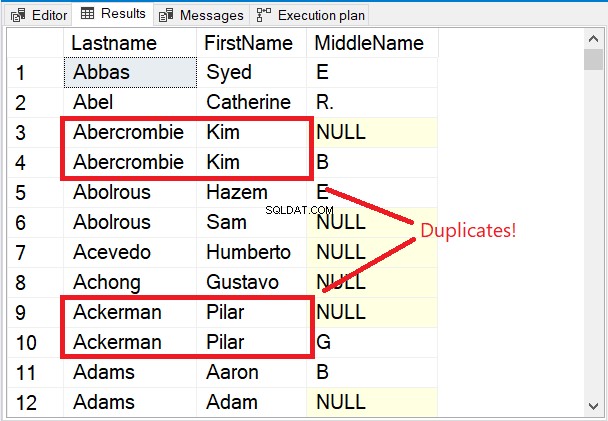
पहली कुछ पंक्तियाँ सभी अद्वितीय हैं। DISTINCT कीवर्ड ने सुनिश्चित किया कि मध्य नाम कॉलम भी माना जाता है। लाल रंग में बॉक्स किए गए 2 नामों पर ध्यान दें। अंतिम नाम . को ध्यान में रखते हुए और प्रथम नाम केवल उन्हें डुप्लिकेट बना देगा। लेकिन मध्य नाम adding जोड़ना मिश्रण में सब कुछ बदल गया।
क्या होगा यदि आप अद्वितीय प्रथम और अंतिम नाम प्राप्त करना चाहते हैं लेकिन परिणाम में मध्य नाम शामिल करना चाहते हैं?
आपके पास 2 विकल्प हैं:
- न्यूल मध्य नामों को हटाने के लिए WHERE क्लॉज जोड़ें। यह NULL मध्य नाम वाले सभी नामों को हटा देगा।
- या, अंतिम नाम . पर ग्रुप बाय क्लॉज जोड़ें और प्रथम नाम स्तंभ। फिर, मध्य नाम . पर MIN एग्रीगेट फ़ंक्शन का उपयोग करें कॉलम। इसे एक ही अंतिम और प्रथम नाम के साथ 1 मध्य नाम मिलेगा।
SQL DISTINCT बनाम GROUP BY
बिना समग्र कार्य के GROUP BY का उपयोग करते समय, यह DISTINCT की तरह कार्य करता है। हम कैसे जानते हैं? इसका पता लगाने का एक तरीका एक उदाहरण का उपयोग करना है।
USE AdventureWorks
GO
-- using DISTINCT
SELECT DISTINCT
soh.TerritoryID
,st.Name
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesTerritory st ON soh.TerritoryID = st.TerritoryID;
-- using GROUP BY
SELECT
soh.TerritoryID
,st.Name
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesTerritory st ON soh.TerritoryID = st.TerritoryID
GROUP BY
soh.TerritoryID
,st.Name;
उन्हें चलाएं और निष्पादन योजना देखें। क्या यह नीचे स्क्रीनशॉट जैसा है?
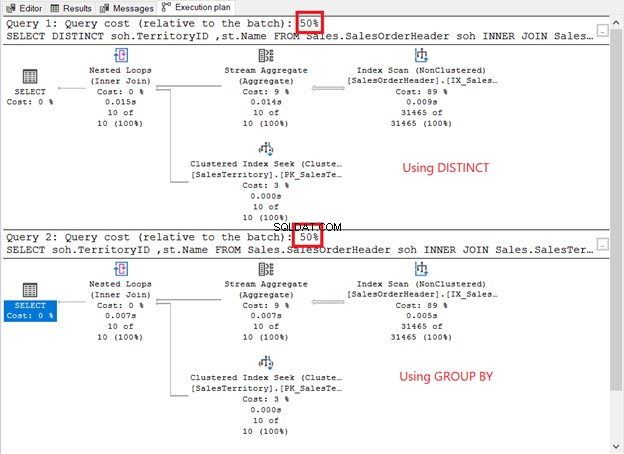
वे कैसे तुलना करते हैं?
- उनके पास एक ही योजना संचालक और क्रम है।
- प्रत्येक की ऑपरेटर लागत और क्वेरी लागत समान हैं।
यदि आप QueryPlanHash . की जांच करते हैं 2 चयन ऑपरेटरों के गुण, वे वही हैं। इसलिए, क्वेरी ऑप्टिमाइज़र ने समान परिणाम देने के लिए उसी प्रक्रिया का उपयोग किया।
अंत में, हम यह नहीं कह सकते कि अद्वितीय मूल्यों को वापस करने में GROUP BY का उपयोग करना DISTINCT से बेहतर है। DISTINCT को GROUP BY से बदलने के लिए उपरोक्त उदाहरणों का उपयोग करके आप इसे साबित कर सकते हैं।
यह अब वरीयता का मामला है जिसका आप उपयोग करेंगे। मुझे DISTINCT पसंद है। यह स्पष्ट रूप से क्वेरी में इरादा बताता है - अद्वितीय परिणाम उत्पन्न करने के लिए। और मेरे लिए, GROUP BY एक समग्र फ़ंक्शन का उपयोग करके परिणामों को समूहीकृत करने के लिए है। वह इरादा भी स्पष्ट और कीवर्ड के अनुरूप ही है। मुझे नहीं पता कि कोई और मेरे प्रश्नों को एक दिन बनाए रखेगा या नहीं। तो, कोड स्पष्ट होना चाहिए।
लेकिन यह कहानी का अंत नहीं है।
जब SQL DISTINCT GROUP BY के समान नहीं है
मैंने अभी-अभी अपनी राय व्यक्त की, और फिर यह?
यह सच है। वे हर समय एक जैसे नहीं रहेंगे। इस उदाहरण पर विचार करें।
-- using DISTINCT
SELECT DISTINCT
soh.TerritoryID
,(SELECT name FROM Sales.SalesTerritory st WHERE st.TerritoryID = soh.TerritoryID) AS TerritoryName
FROM Sales.SalesOrderHeader soh;
-- using GROUP BY
SELECT
soh.TerritoryID
,(SELECT name FROM Sales.SalesTerritory st WHERE st.TerritoryID = soh.TerritoryID) AS TerritoryName
FROM Sales.SalesOrderHeader soh
GROUP BY
soh.TerritoryID;
हालांकि परिणाम सेट को क्रमबद्ध नहीं किया गया है, लेकिन पंक्तियाँ पिछले उदाहरण की तरह ही हैं। सबक्वेरी के उपयोग में एकमात्र अंतर है:
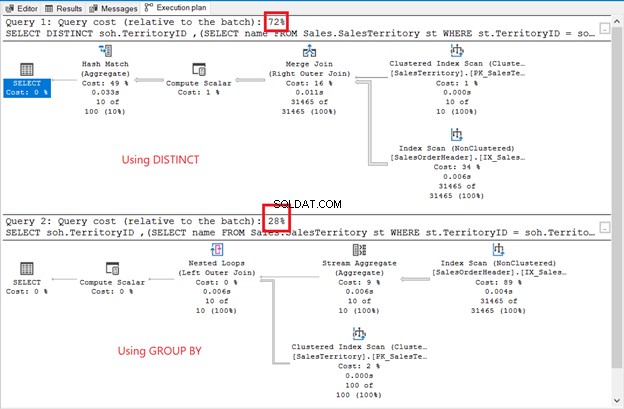
अंतर स्पष्ट हैं:ऑपरेटर, क्वेरी लागत, समग्र योजना। इस बार, GROUP BY केवल 28% क्वेरी लागत के साथ जीत गया। लेकिन ये रही बात।
उद्देश्य आपको यह दिखाना है कि वे भिन्न हो सकते हैं। बस इतना ही। यह किसी भी तरह से सिफारिश नहीं है। जॉइन का उपयोग करना बेहतर निष्पादन योजना है (चित्र 6 फिर से देखें)।
द बॉटमलाइन
हमने अब तक जो सीखा है वह यहां दिया गया है:
- DISTINCT डुप्लीकेट हटाने के लिए एक प्लान ऑपरेटर जोड़ता है।
- DISTINCT और GROUP BY बिना समग्र कार्य के परिणाम एक ही योजना में आते हैं। संक्षेप में, वे अधिकतर समय एक जैसे ही होते हैं।
- कभी-कभी, चयन सूची में सबक्वेरी शामिल होने पर DISTINCT और GROUP BY की अलग-अलग योजनाएँ हो सकती हैं।
तो, परिणामों में डुप्लीकेट हटाने में SQL DISTINCT अच्छा है या बुरा?
परिणाम कहते हैं कि यह अच्छा है। यह ग्रुप बाय से बेहतर या बदतर नहीं है क्योंकि योजनाएं समान हैं। लेकिन निष्पादन योजना की जांच करना एक अच्छी आदत है। शुरुआत से अनुकूलन के बारे में सोचें। इस तरह, यदि आप DISTINCT और GROUP BY में कोई अंतर पाते हैं, तो आप उन्हें खोज लेंगे।
इसके अलावा, आधुनिक उपकरण इस कार्य को बहुत आसान बनाते हैं। उदाहरण के लिए, एक लोकप्रिय उत्पाद dbForge SQL Complete from Devart में एक विशिष्ट विशेषता है जो SSMS परिणाम ग्रिड के तैयार परिणाम सेट में कुल कार्यों में मानों की गणना करती है। DISTINCT मान भी वहां मौजूद हैं।
पोस्ट की तरह? फिर, कृपया इसे अपने पसंदीदा सोशल मीडिया प्लेटफॉर्म पर साझा करके इसे फैलाएं।
अधिक जानकारी के लिए संबंधित लेख
- SQL GROUP BY:एक पेशेवर की तरह परिणामों को समूहीकृत करने के लिए 3 आसान टिप्स
- चयन में SQL सम्मिलित करें:डुप्लिकेट को संभालने के 5 आसान तरीके
- एसक्यूएल समग्र कार्य क्या हैं? (नौसिखियों के लिए आसान टिप्स)
- एसक्यूएल क्वेरी ऑप्टिमाइज़ेशन:प्रश्नों को बढ़ावा देने के लिए 5 मुख्य तथ्य