SQL सर्वर के साथ काम करने वाले एक सलाहकार के रूप में, कई बार मुझे एक ऐसे सर्वर को देखने के लिए कहा जाता है जो ऐसा लगता है कि इसमें प्रदर्शन समस्याएँ हैं। सर्वर पर ट्राइएज करते समय, मैं कुछ प्रश्न पूछता हूं, जैसे:आपका सामान्य सीपीयू उपयोग क्या है, आपकी औसत डिस्क विलंबता क्या है, आपकी सामान्य मेमोरी उपयोग क्या है, और इसी तरह। इसका उत्तर आमतौर पर होता है, "हम नहीं जानते" या "हम उस जानकारी को नियमित रूप से कैप्चर नहीं कर रहे हैं।" हाल ही में आधार रेखा नहीं होने से यह जानना बहुत मुश्किल हो जाता है कि असामान्य व्यवहार कैसा दिखता है। यदि आप नहीं जानते कि सामान्य व्यवहार क्या है, तो आप निश्चित रूप से कैसे जान सकते हैं कि चीजें बेहतर हैं या बदतर? मैं अक्सर अभिव्यक्तियों का उपयोग करता हूं, "यदि आप इसकी निगरानी नहीं कर रहे हैं, तो आप इसे माप नहीं सकते हैं," और, "यदि आप इसे माप नहीं रहे हैं, तो आप इसे प्रबंधित नहीं कर सकते।"
निगरानी के नजरिए से, कम से कम, संगठनों को असफल नौकरियों जैसे बैकअप, इंडेक्स रखरखाव, DBCC CHECKDB, और किसी भी अन्य महत्वपूर्ण कार्य के लिए निगरानी करनी चाहिए। इनके लिए विफलता सूचनाएं सेट करना आसान है; हालाँकि आपको यह सुनिश्चित करने के लिए एक प्रक्रिया की भी आवश्यकता है कि कार्य अपेक्षित रूप से चल रहे हैं। मैंने ऐसे काम देखे हैं जो लटक जाते हैं और कभी पूरे नहीं होते। एक विफलता अधिसूचना अलार्म को ट्रिगर नहीं करेगी क्योंकि नौकरी कभी सफल या विफल नहीं होती है।
एक प्रदर्शन आधार रेखा से, कई प्रमुख मीट्रिक हैं जिन्हें कैप्चर किया जाना चाहिए। मैंने एक प्रक्रिया बनाई है जिसका उपयोग मैं उन ग्राहकों के साथ करता हूं जो नियमित रूप से प्रमुख मीट्रिक को कैप्चर करते हैं और उन मानों को उपयोगकर्ता डेटाबेस में संग्रहीत करते हैं। मेरी प्रक्रिया सरल है:संग्रहीत प्रक्रियाओं के साथ एक समर्पित डेटाबेस जो सामान्य स्क्रिप्ट का उपयोग कर रहे हैं जो परिणाम सेट को तालिकाओं में सम्मिलित करते हैं। मेरे पास नियमित अंतराल पर संग्रहीत प्रक्रियाओं को चलाने के लिए SQL एजेंट नौकरियां हैं और X दिनों से पुराने डेटा को शुद्ध करने के लिए एक क्लीनअप स्क्रिप्ट है। मेरे द्वारा हमेशा कैप्चर की जाने वाली मीट्रिक में शामिल हैं:
पृष्ठ जीवन प्रत्याशा :यदि आपका सिस्टम आंतरिक मेमोरी दबाव में है तो PLE शायद यह पता लगाने के सर्वोत्तम तरीकों में से एक है। अधिकांश प्रणालियों में PLE मान होते हैं जो सामान्य कार्यभार के दौरान उतार-चढ़ाव करते हैं। न्यूनतम, औसत और अधिकतम मान क्या हैं, यह जानने के लिए मैं इन मूल्यों को ट्रेंड करना पसंद करता हूं। मैं यह समझने की कोशिश करना चाहता हूं कि दिन के कुछ निश्चित समय के दौरान पीएलई किस कारण से गिर गया, यह देखने के लिए कि क्या उन प्रक्रियाओं को ट्यून किया जा सकता है। कई बार, कोई टेबल स्कैन कर रहा है और बफर पूल को फ्लश कर रहा है। उन प्रश्नों को ठीक से अनुक्रमित करने में सक्षम होने से मदद मिल सकती है। बस सुनिश्चित करें कि आप सही पीएलई काउंटर की निगरानी कर रहे हैं - देखें यहां ।
सीपीयू उपयोग :CPU उपयोग के लिए आधार रेखा होने से आपको पता चलता है कि आपका सिस्टम अचानक CPU दबाव में है या नहीं। अक्सर जब कोई उपयोगकर्ता प्रदर्शन के मुद्दों की शिकायत करता है, तो वे देखेंगे कि सीपीयू उच्च दिखता है। उदाहरण के लिए, यदि सीपीयू लगभग 80% मँडरा रहा है, तो वे उस संबंधित को पा सकते हैं, हालाँकि यदि पिछले सप्ताहों के दौरान सीपीयू भी 80% था, जब कोई समस्या नहीं बताई जा रही थी, तो सीपीयू के मुद्दे की संभावना बहुत कम है। ट्रेंडिंग सीपीयू केवल कैप्चरिंग के लिए नहीं है जब सीपीयू स्पाइक्स और लगातार उच्च मूल्य पर रहता है। मेरे पास कई कहानियां हैं जब मुझे एक सम्मेलन पुल की गंभीरता में लाया गया था क्योंकि एक आवेदन के साथ कोई समस्या थी। डीबीए होने के नाते, मैंने "डिफ़ॉल्ट दोष स्वीकर्ता" की टोपी पहनी थी। जब एप्लिकेशन टीम ने कहा कि डेटाबेस के साथ कोई समस्या थी, तो यह साबित करने के लिए मुझ पर था कि निर्दोष साबित होने तक डेटाबेस सर्वर दोषी था। मुझे एक घटना स्पष्ट रूप से याद है जहां एप्लिकेशन टीम को विश्वास था कि डेटाबेस सर्वर में समस्याएँ थीं क्योंकि उपयोगकर्ता कनेक्ट नहीं हो सकते थे। उन्होंने इंटरनेट पर पढ़ा था कि SQL सर्वर थ्रेड पूल भुखमरी से पीड़ित हो सकता है यदि यह कनेक्शन से इनकार कर रहा था। मैं सर्वर पर कूद गया और संसाधनों को देखना शुरू कर दिया, और वर्तमान में कौन सी प्रक्रियाएं चल रही थीं। कुछ ही मिनटों में मैंने वापस रिपोर्ट किया कि विचाराधीन सर्वर बहुत ऊब गया था। हमारे बेसलाइन मेट्रिक्स के आधार पर, सीपीयू आमतौर पर 60% था और यह लगभग 20% निष्क्रिय था, पृष्ठ जीवन प्रत्याशा सामान्य से काफी अधिक थी, और कोई लॉकिंग या अवरुद्ध नहीं हो रहा था, I/O बहुत अच्छा लग रहा था, किसी भी लॉग में कोई त्रुटि नहीं थी, और सत्र की संख्या उनकी सामान्य गणना की लगभग 1/3 थी। मैंने तब टिप्पणी की, "ऐसा प्रतीत होता है कि उपयोगकर्ता डेटाबेस सर्वर तक भी नहीं पहुंच रहे हैं।" उस पर नेटवर्क के लोगों का ध्यान गया और उन्होंने महसूस किया कि लोड बैलेंसर में किए गए बदलाव ठीक से काम नहीं कर रहे थे और उन्होंने निर्धारित किया कि 50% से अधिक कनेक्शन गलत तरीके से रूट किए जा रहे थे और इसे डेटाबेस सर्वर पर नहीं बना रहे थे। अगर मुझे पता नहीं होता कि आधार रेखा क्या है, तो हमें समाधान तक पहुँचने में बहुत अधिक समय लग जाता।
डिस्क I/O :डिस्क मेट्रिक्स को कैप्चर करना बहुत महत्वपूर्ण है। अंतिम सर्वर के पुनरारंभ होने के बाद से DMV sys.dm_io_virtual_file_stats संचयी है। एक समय अंतराल पर अपने I/O विलंबता को कैप्चर करने से आपको उस समय के सामान्य होने की आधार रेखा मिल जाएगी। संचयी मूल्य पर भरोसा करने से आपको व्यावसायिक घंटे की गतिविधियों या लंबे समय तक जहां सिस्टम निष्क्रिय था, से विषम डेटा मिल सकता है। पॉल ने चर्चा की कि यहां ।
डेटाबेस फ़ाइल आकार :आपके डेटाबेस की एक सूची जिसमें फ़ाइल का आकार, उपयोग किया गया आकार, खाली स्थान, और बहुत कुछ शामिल है, आपको डेटाबेस वृद्धि का पूर्वानुमान लगाने में मदद कर सकता है। अक्सर मुझसे यह पूर्वानुमान लगाने के लिए कहा जाता है कि आने वाले वर्ष में डेटाबेस सर्वर के लिए कितने संग्रहण की आवश्यकता होगी। साप्ताहिक या मासिक वृद्धि की प्रवृत्ति को जाने बिना, मेरे पास समझदारी से किसी आंकड़े के साथ आने का कोई तरीका नहीं है। एक बार जब मैं इन मूल्यों को ट्रैक करना शुरू कर दूं तो मैं इसे ठीक से ट्रेंड कर सकता हूं। ट्रेंडिंग के अलावा, मुझे यह भी पता चल सकता है कि अप्रत्याशित डेटाबेस वृद्धि कब हुई थी। जब मैं अप्रत्याशित वृद्धि देखता हूं और जांच करता हूं, तो मैं आमतौर पर पाता हूं कि किसी ने या तो कुछ परीक्षण करने के लिए एक तालिका की नकल की (हाँ, उत्पादन में!) इस प्रकार के डेटा को ट्रैक करना, और विसंगतियों के होने पर प्रतिक्रिया देने में सक्षम होने से यह दिखाने में मदद मिलती है कि आप सक्रिय हैं और अपने सिस्टम पर नजर रख रहे हैं।
आंकड़ों की प्रतीक्षा करें :प्रतीक्षा आँकड़ों की निगरानी करने से आपको कुछ प्रदर्शन समस्याओं के कारण का पता लगाने में मदद मिल सकती है। कई नए डीबीए चिंतित हो जाते हैं जब वे पहली बार प्रतीक्षा आंकड़ों पर शोध करना शुरू करते हैं और यह महसूस करने में असफल होते हैं कि प्रतीक्षा हमेशा होती है, और यही वह तरीका है जो SQL सर्वर का शेड्यूलिंग सिस्टम काम करता है। ऐसे बहुत से इंतजार भी हैं जिन्हें सौम्य, या अधिकतर हानिरहित माना जा सकता है। पॉल रान्डल ने अपनी लोकप्रिय प्रतीक्षा सांख्यिकी स्क्रिप्ट में इन ज्यादातर हानिरहित प्रतीक्षाओं को शामिल नहीं किया है। पॉल ने विभिन्न प्रतीक्षा प्रकारों . का एक विशाल पुस्तकालय भी बनाया है और कुंडी कक्षाएं विवरण और प्रतीक्षा और कुंडी के समस्या निवारण के बारे में अन्य जानकारी के साथ।
मैंने अपनी डेटा संग्रह प्रक्रिया का दस्तावेजीकरण कर दिया है, और आप मेरे ब्लॉग . पर कोड पा सकते हैं . ग्राहक की स्थिति और प्रकार के मुद्दों के आधार पर, मैं अतिरिक्त मीट्रिक भी कैप्चर करना चाह सकता हूं। ग्लेन बेरी उन्होंने एक ऐसी प्रक्रिया के बारे में ब्लॉग किया, जो सभी NUMA नोड्स में औसत कार्य गणना, औसत चलने योग्य कार्य गणना, औसत लंबित I/O गणना, SQL सर्वर प्रक्रिया CPU उपयोग, और औसत पृष्ठ जीवन प्रत्याशा को कैप्चर करती है। एक त्वरित इंटरनेट खोज कई अन्य डेटा संग्रह प्रक्रियाओं को चालू करेगी जिन्हें लोगों ने साझा किया है, यहां तक कि एसक्यूएल सर्वर टाइगर टीम भी। एक प्रक्रिया है जो T-SQL और PowerShell का उपयोग करती है।
एक कस्टम डेटाबेस का उपयोग करना और अपना खुद का डेटा संग्रह पैकेज बनाना आधार रेखा को कैप्चर करने के लिए एक वैध समाधान है, लेकिन हम में से अधिकांश SQL सर्वर निगरानी समाधानों पर पूर्ण-निर्माण के व्यवसाय में नहीं हैं। बहुत कुछ है जो कैप्चर करने में मददगार होगा, लंबे समय तक चलने वाले प्रश्न, शीर्ष प्रश्न और मेमोरी, I/O, और CPU, गतिरोध, सूचकांक विखंडन, प्रति सेकंड लेनदेन, और बहुत कुछ के आधार पर संग्रहीत कार्यविधियाँ। उसके लिए, मैं हमेशा अनुशंसा करता हूं कि ग्राहक एक तृतीय-पक्ष निगरानी उपकरण खरीदें। ये विक्रेता SQL सर्वर के नवीनतम रुझानों और सुविधाओं पर गति बनाए रखने में माहिर हैं ताकि आप यह सुनिश्चित करने पर अपना समय केंद्रित कर सकें कि SQL सर्वर यथासंभव स्थिर और तेज़ है।
समाधान जैसे एसक्यूएल संतरी (एसक्यूएल सर्वर के लिए) और डीबी संतरी (Azure SQL डेटाबेस के लिए) आपके लिए इन सभी मेट्रिक्स को कैप्चर करता है, और आपको आसानी से अलग-अलग बेसलाइन बनाने की अनुमति देता है। आपके पास एक सामान्य आधार रेखा, महीने के अंत, तिमाही के अंत और बहुत कुछ हो सकता है। फिर आप आधार रेखा को लागू कर सकते हैं और देख सकते हैं कि चीजें कैसे भिन्न हैं। इससे भी महत्वपूर्ण बात यह है कि आप विभिन्न स्थितियों के लिए कितनी भी अलर्ट कॉन्फ़िगर कर सकते हैं और मेट्रिक्स आपकी सीमा से अधिक होने पर आपको सूचित किया जा सकता है।
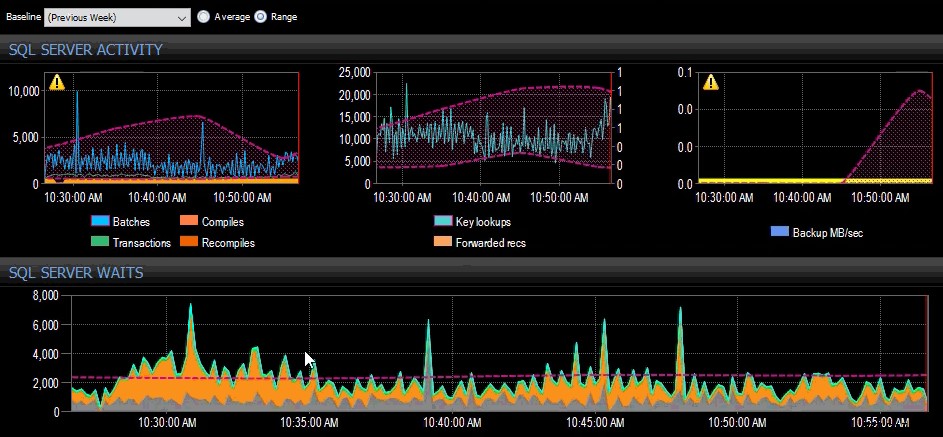 पिछले हफ्ते की बेसलाइन SQL संतरी डैशबोर्ड पर कई SQL सर्वर मेट्रिक्स पर लागू हुई।
पिछले हफ्ते की बेसलाइन SQL संतरी डैशबोर्ड पर कई SQL सर्वर मेट्रिक्स पर लागू हुई।
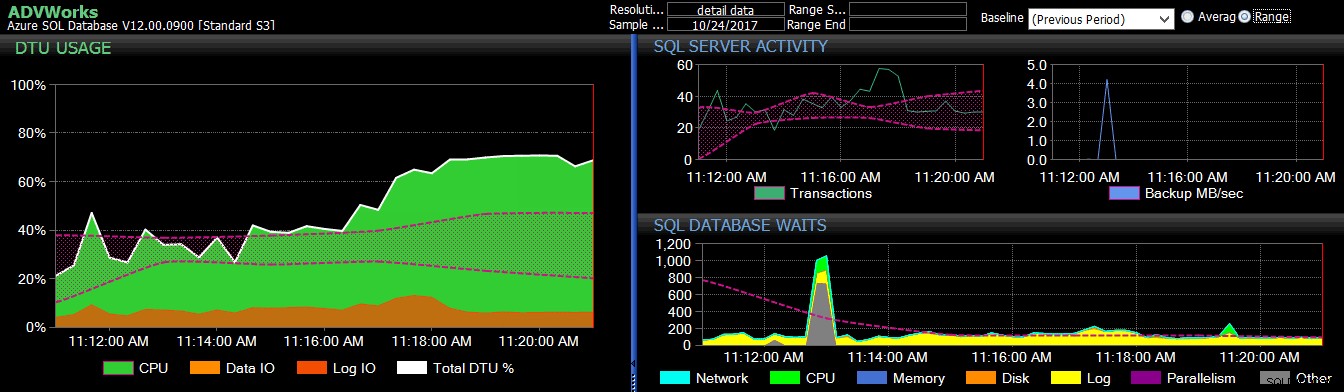 पिछली अवधि की आधार रेखा DB संतरी डैशबोर्ड पर कई Azure SQL डेटाबेस मेट्रिक्स पर लागू होती है।
पिछली अवधि की आधार रेखा DB संतरी डैशबोर्ड पर कई Azure SQL डेटाबेस मेट्रिक्स पर लागू होती है।
SentryOne में बेसलाइन के बारे में अधिक जानकारी के लिए, ये पोस्ट देखें उनके टीम ब्लॉग पर, या यह 2 मिनट मंगलवार का वीडियो . परीक्षण डाउनलोड करने के इच्छुक हैं? उन्होंने आपको वहां भी कवर कर लिया है ।