यह आलेख समूहीकरण और एकत्रीकरण डेटा से संबंधित अनुकूलन थ्रेशोल्ड के बारे में श्रृंखला में दूसरा है। भाग 1 में, मैंने स्ट्रीम एग्रीगेट ऑपरेटर लागत के लिए रिवर्स-इंजीनियर्ड फॉर्मूला प्रदान किया था। मैंने समझाया कि इस ऑपरेटर को ग्रुपिंग सेट (इसके सदस्यों के किसी भी क्रम) द्वारा ऑर्डर की गई पंक्तियों का उपभोग करने की आवश्यकता है, और जब डेटा को इंडेक्स से प्रीऑर्डर किया जाता है, तो आपको पंक्तियों की संख्या और संख्या के संबंध में रैखिक स्केलिंग मिलती है। समूह। साथ ही, ऐसे मामले में स्मृति अनुदान की आवश्यकता नहीं है।
इस लेख में, मैं एक स्ट्रीम एग्रीगेट-आधारित ऑपरेशन की लागत और स्केलिंग पर ध्यान केंद्रित करता हूं, जब डेटा को किसी इंडेक्स से पहले से ऑर्डर नहीं किया जाता है, बल्कि इसे पहले सॉर्ट करना होता है।
मेरे उदाहरणों में, मैं PerformanceV3 नमूना डेटाबेस का उपयोग करूँगा, जैसे भाग 1 में। आप इस डेटाबेस को बनाने और पॉप्युलेट करने वाली स्क्रिप्ट यहाँ से डाउनलोड कर सकते हैं। इस आलेख के उदाहरणों को चलाने से पहले, सुनिश्चित करें कि आप कुछ अनावश्यक अनुक्रमणिकाओं को छोड़ने के लिए पहले निम्न कोड चलाते हैं:
DROP INDEX idx_nc_sid_od_cid ON dbo.Orders;DROP INDEX idx_unc_od_oid_i_cid_eid ON dbo.Orders;
इस तालिका में केवल दो अनुक्रमणिका छोड़ी जानी चाहिए idx_cl_od (orderdate . के साथ संकुलित कुंजी के रूप में) और PK_Orders (orderid के साथ गैर-संकुलित) कुंजी के रूप में)।
सॉर्ट + स्ट्रीम एग्रीगेट
इस लेख का फोकस यह पता लगाने की कोशिश करना है कि जब समूह समूह द्वारा डेटा को पूर्व-आदेशित नहीं किया जाता है तो एक स्ट्रीम एग्रीगेट ऑपरेशन कैसे स्केल करता है। चूंकि स्ट्रीम एग्रीगेट ऑपरेटर को ऑर्डर की गई पंक्तियों को संसाधित करना होता है, यदि वे किसी इंडेक्स में प्रीऑर्डर नहीं किए जाते हैं, तो योजना में एक स्पष्ट सॉर्ट ऑपरेटर शामिल होना चाहिए। तो आपके द्वारा ध्यान में रखे जाने वाले कुल संचालन की लागत Sort + Stream Aggregate ऑपरेटरों की लागतों का योग है।
मैं इस तरह के अनुकूलन को शामिल करने वाली योजना को प्रदर्शित करने के लिए निम्नलिखित क्वेरी (हम इसे प्रश्न 1 कहेंगे) का उपयोग करेंगे:
शिपरिड का चयन करें, MAX(आदेश दिनांक) अधिकतम के रूप में (सेलेक्ट टॉप (100) * डीबीओ से। ऑर्डर) शिपरिड द्वारा डी ग्रुप के रूप में;
इस क्वेरी की योजना चित्र 1 में दिखाई गई है।

चित्र 1:प्रश्न 1 की योजना
टॉप फ़िल्टर के साथ तालिका अभिव्यक्ति का उपयोग करने का कारण समूहीकरण और एकत्रीकरण में शामिल (अनुमानित) पंक्तियों की सटीक संख्या को नियंत्रित करना है। नियंत्रित परिवर्तनों को लागू करने से लागत फ़ार्मुलों को आज़माना और रिवर्स-इंजीनियर करना आसान हो जाता है।
यदि आप सोच रहे हैं कि इस उदाहरण में इतनी कम संख्या में पंक्तियों को फ़िल्टर क्यों किया जाता है, तो इसका ऑप्टिमाइज़ेशन थ्रेशोल्ड से कोई लेना-देना नहीं है जो इस रणनीति को हैश एग्रीगेट एल्गोरिथम को पसंद करते हैं। भाग 3 में मैं हैश विकल्प की लागत और विस्तार का वर्णन करूँगा। ऐसे मामलों में जहां ऑप्टिमाइज़र अपने आप में एक स्ट्रीम एग्रीगेट ऑपरेशन का चयन नहीं करता है, उदाहरण के लिए, जब बड़ी संख्या में पंक्तियाँ शामिल होती हैं, तो आप इसे अनुसंधान प्रक्रिया के दौरान हमेशा संकेत विकल्प (ऑर्डर ग्रुप) के साथ बाध्य कर सकते हैं। धारावाहिक योजनाओं की लागत पर ध्यान केंद्रित करते समय, आप स्पष्ट रूप से समानता को खत्म करने के लिए MAXDOP 1 संकेत जोड़ सकते हैं।
जैसा कि उल्लेख किया गया है, एक गैर-आदेशित स्ट्रीम एग्रीगेट एल्गोरिदम की लागत और स्केलिंग का मूल्यांकन करने के लिए, आपको सॉर्ट + स्ट्रीम एग्रीगेट ऑपरेटरों के योग को ध्यान में रखना होगा। आप भाग 1 से स्ट्रीम एग्रीगेट ऑपरेटर के लिए लागत सूत्र पहले से ही जानते हैं:
@numrows * 0.0000006 + @numgroups * 0.0000005हमारी क्वेरी में हमारे पास 100 अनुमानित इनपुट पंक्तियाँ और 5 अनुमानित आउटपुट समूह हैं (घनत्व की जानकारी के आधार पर अनुमानित 5 अलग-अलग शिपर आईडी)। तो हमारी योजना में स्ट्रीम एग्रीगेट ऑपरेटर की लागत है:
100 * 0.0000006 + 5 * 0.0000005 =0.00000625आइए सॉर्ट ऑपरेटर के लिए लागत सूत्र जानने का प्रयास करें। याद रखें, हमारा ध्यान अनुमानित लागत और स्केलिंग पर है क्योंकि हमारा अंतिम लक्ष्य ऑप्टिमाइज़ेशन थ्रेसहोल्ड का पता लगाना है जहां ऑप्टिमाइज़र अपनी पसंद को एक रणनीति से दूसरी रणनीति में बदलता है।
I/O लागत अनुमान निश्चित प्रतीत होता है:0.0112613। पंक्तियों की संख्या, सॉर्ट कॉलम की संख्या, डेटा प्रकार, आदि जैसे कारकों के बावजूद मुझे समान I/O लागत मिलती है। यह संभवत:कुछ प्रत्याशित I/O कार्य के लिए जिम्मेदार है।
सीपीयू लागत के लिए, अफसोस, माइक्रोसॉफ्ट सार्वजनिक रूप से सटीक एल्गोरिदम का खुलासा नहीं करता है जो वे छँटाई के लिए उपयोग करते हैं। हालाँकि, सामान्य रूप से डेटाबेस इंजन द्वारा छँटाई के लिए उपयोग किए जाने वाले सामान्य एल्गोरिदम में मर्ज सॉर्ट और क्विकॉर्ट के विभिन्न कार्यान्वयन हैं। पॉल व्हाइट द्वारा किए गए प्रयासों के लिए धन्यवाद, जो विंडोज डिबगर स्टैक ट्रेस को देखने के शौकीन हैं (हम सभी के पास इसके लिए पेट नहीं है), हमारे पास विषय में थोड़ी अधिक अंतर्दृष्टि है, जो उनकी श्रृंखला "इंटर्नल्स ऑफ द सेवन एसक्यूएल सर्वर" में प्रकाशित हुई है। क्रमबद्ध करें।" पॉल के निष्कर्षों के अनुसार, सामान्य सॉर्ट वर्ग (उपरोक्त योजना में प्रयुक्त) मर्ज सॉर्ट (पहले आंतरिक, फिर बाहरी में संक्रमण) का उपयोग करता है। औसतन, इस एल्गोरिथम को n आइटम को सॉर्ट करने के लिए n लॉग n तुलना की आवश्यकता होती है। इसे ध्यान में रखते हुए, यह संभवतः एक प्रारंभिक बिंदु के रूप में एक सुरक्षित शर्त है कि यह मान लिया जाए कि ऑपरेटर की लागत का सीपीयू भाग एक सूत्र पर आधारित है जैसे:
ऑपरेटर CPU लागत =<स्टार्टअप लागत> + @numrows * LOG(@numrows) * <तुलना लागत>बेशक, यह Microsoft द्वारा उपयोग किए जाने वाले वास्तविक लागत सूत्र का एक ओवरसिम्प्लीफिकेशन हो सकता है, लेकिन इस मामले पर कोई दस्तावेज़ीकरण अनुपस्थित है, यह एक प्रारंभिक सर्वोत्तम अनुमान है।
इसके बाद, आप अलग-अलग पंक्तियों, जैसे कि 1000 और 2000 को छांटने के लिए तैयार की गई दो क्वेरी योजनाओं से सॉर्ट सीपीयू लागत प्राप्त कर सकते हैं, और उन और उपरोक्त सूत्र के आधार पर, तुलनात्मक लागत और स्टार्टअप लागत को रिवर्स इंजीनियर कर सकते हैं। इस उद्देश्य के लिए, आपको समूहीकृत क्वेरी का उपयोग करने की आवश्यकता नहीं है; यह केवल एक बुनियादी ORDER BY करने के लिए पर्याप्त है। मैं निम्नलिखित दो प्रश्नों का उपयोग करूंगा (हम उन्हें प्रश्न 2 और प्रश्न 3 कहेंगे):
सेलेक्ट ऑर्डरिड% 1000000000 myorderid से (सेलेक्ट टॉप (1000) * dbo.Orders से) myorderid द्वारा AS D ORDER; ऑर्डरिड% 1000000000 को myorderid के रूप में चुनें (शीर्ष चुनें (2000) * dbo.Orders से) myorderid द्वारा AS D ORDER;
गणना के परिणाम के आधार पर क्रमबद्ध करने का उद्देश्य एक सॉर्ट ऑपरेटर को योजना में उपयोग करने के लिए बाध्य करना है।
चित्र 2 दो योजनाओं के प्रासंगिक भागों को दिखाता है:
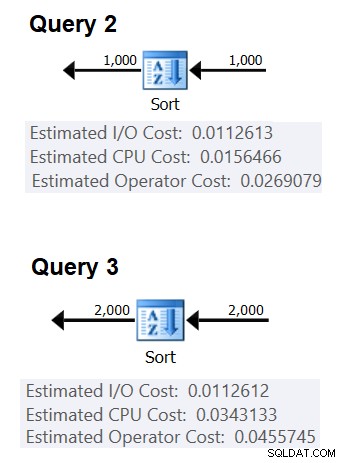
चित्र 2:प्रश्न 2 और प्रश्न 3 के लिए योजनाएं
एक तुलना की लागत का अनुमान लगाने और अनुमान लगाने के लिए, आप निम्न सूत्र का उपयोग करेंगे:
तुलना लागत =
((<क्वेरी 3 CPU लागत> - <स्टार्टअप लागत> ) - (<क्वेरी 2 CPU लागत> - <स्टार्टअप लागत> ))
/ (<प्रश्न 3 #तुलना> – <प्रश्न 2 #तुलना>) =
(0.03431333 - 0.0156466) / (2000 * लॉग (2000) - 1000 * लॉग (1000)) =2.25061348918698ई-06
स्टार्टअप लागत के लिए, आप किसी भी योजना के आधार पर इसका अनुमान लगा सकते हैं, उदाहरण के लिए, उस योजना के आधार पर जो 2000 पंक्तियों को क्रमबद्ध करती है:
स्टार्टअप लागत =0.0343133 - 2000*LOG(2000) * 2.25061348918698E-06 =9.99127891201865E-05
और इस प्रकार हमारा सीपीयू लागत सूत्र बन जाता है:
सॉर्ट ऑपरेटर CPU लागत =9.99127891201865E-05 + @numrows * LOG(@numrows) * 2.25061348918698E-06समान तकनीकों का उपयोग करते हुए, आप पाएंगे कि औसत पंक्ति आकार, ऑर्डरिंग कॉलम की संख्या और उनके डेटा प्रकार जैसे कारक अनुमानित सॉर्ट CPU लागत को प्रभावित नहीं करते हैं। प्रासंगिक प्रतीत होने वाला एकमात्र कारक पंक्तियों की अनुमानित संख्या है। ध्यान दें कि सॉर्ट को स्मृति अनुदान की आवश्यकता होगी, और अनुदान पंक्तियों की संख्या (समूह नहीं) और औसत पंक्ति आकार के लिए आनुपातिक है। लेकिन वर्तमान में हमारा ध्यान अनुमानित ऑपरेटर लागत पर है, और ऐसा प्रतीत होता है कि यह अनुमान केवल पंक्तियों की अनुमानित संख्या से प्रभावित होता है।
ऐसा लगता है कि यह सूत्र लगभग 5,000 पंक्तियों की सीमा तक सीपीयू की लागत का अनुमान लगाता है। इसे निम्न संख्याओं के साथ आज़माएँ:100, 200, 300, 400, 500, 1000, 2000, 3000, 4000, 5000:
अंकों का चयन करें, 9.99127891201865E-05 + अंक * लॉग (संख्या) * 2.25061348918698E-06 अनुमानित लागत से (VALUES(100), (200), (300), (400), (500), (1000) , (2000), (3000), (4000), (5000)) AS D(अंक);
तुलना करें कि सूत्र क्या भविष्यवाणी करता है और अनुमानित CPU लागत जो निम्न प्रश्नों के लिए योजनाएं दिखाती हैं:
सेलेक्ट ऑर्डरिड% 1000000000 myorderid के रूप में (सेलेक्ट टॉप (100) * dbo.Orders से) myorderid द्वारा AS D ORDER; ऑर्डरिड% 1000000000 को myorderid से चुनें (शीर्ष चुनें (200) * dbo.Orders से) myorderid द्वारा डी ऑर्डर के रूप में; ऑर्डरिड% 1000000000 को myorderid से चुनें (शीर्ष चुनें (300) * dbo.Orders से) myorderid द्वारा डी ऑर्डर के रूप में; myorderid के रूप में ऑर्डरिड% 1000000000 चुनें (शीर्ष चुनें (400) * dbo.Orders से) myorderid द्वारा डी ऑर्डर के रूप में; myorderid के रूप में ऑर्डरिड% 1000000000 का चयन करें (शीर्ष चुनें (500) * dbo.Orders से) myorderid द्वारा डी ऑर्डर के रूप में; myorderid के रूप में ऑर्डरिड% 1000000000 चुनें (शीर्ष चुनें (1000) * dbo.Orders से) myorderid द्वारा डी ऑर्डर के रूप में; myorderid के रूप में ऑर्डरिड% 1000000000 चुनें (शीर्ष चुनें (2000) * dbo.Orders से) myorderid द्वारा डी ऑर्डर के रूप में; ऑर्डरिड% 1000000000 को myorderid के रूप में चुनें (सेलेक्ट टॉप (3000) * dbo.Orders से) myorderid द्वारा डी ऑर्डर के रूप में; myorderid के रूप में ऑर्डरिड% 1000000000 चुनें (शीर्ष चुनें (4000) * dbo.Orders से) myorderid द्वारा डी ऑर्डर के रूप में; ऑर्डरिड% 1000000000 को myorderid के रूप में चुनें (शीर्ष चुनें (5000) * dbo.Orders से) myorderid द्वारा AS D ORDER;
मुझे निम्नलिखित परिणाम मिले:
संख्या अनुमानित लागत अनुमानित लागत अनुपात ----------- ----------------------------- -------- ---- 100 0.0011363 0.0011365 1.00018 200 0.0024848 0.0024849 1.00004 300 0.0039510 0.0039511 1.00003 400 0.0054937 0.0054938 1.00002 500 0.0070933 0.0070933 1.00000 1000 0.0156466 0.0156466 1.00000 2000 0.0343133 0.0343133कॉलम अनुमानित लागत हमारे रिवर्स-इंजीनियर फॉर्मूला के आधार पर भविष्यवाणी दिखाती है, कॉलम अनुमानित लागत योजना में दिखाई देने वाली अनुमानित लागत दिखाती है, और कॉलम अनुपात बाद वाले और पूर्व के बीच के अनुपात को दर्शाता है।
भविष्यवाणी 5,000 पंक्तियों तक बहुत सटीक लगती है। हालांकि, 5,000 से अधिक संख्या के साथ, हमारा रिवर्स-इंजीनियर्ड फॉर्मूला अच्छी तरह से काम करना बंद कर देता है। निम्न क्वेरी आपको 6K, 7K, 10K, 20K, 100K और 200K पंक्तियों के लिए पूर्वानुमान देती है:
संख्याओं का चयन करें, 9.99127891201865E-05 + अंक * लॉग (अंक) * 2.25061348918698E-06 अनुमानित लागत के रूप में (VALUES(6000), (7000), (10000), (20000), (100000), (200000) ) एएस डी (अंक);योजनाओं से अनुमानित सीपीयू लागत प्राप्त करने के लिए निम्नलिखित प्रश्नों का उपयोग करें (एक धारावाहिक योजना को लागू करने के लिए संकेत पर ध्यान दें क्योंकि बड़ी संख्या में पंक्तियों के साथ यह अधिक संभावना है कि आपको एक समानांतर योजना मिलेगी जहां लागत सूत्र समानता के लिए समायोजित किए जाते हैं):
सेलेक्ट ऑर्डरआईडी% 1000000000 myorderid से (सेलेक्ट टॉप (6000) * dbo.Orders से) myorderid OPTION (MAXDOP 1) द्वारा डी ऑर्डर के रूप में; ऑर्डरिड% 1000000000 को myorderid के रूप में चुनें (सेलेक्ट टॉप (7000) * dbo.Orders से) myorderid विकल्प (MAXDOP 1) द्वारा डी ऑर्डर के रूप में; ऑर्डरिड% 1000000000 को myorderid के रूप में चुनें (सेलेक्ट टॉप (10000) * dbo.Orders से) myorderid विकल्प (MAXDOP 1) द्वारा डी ऑर्डर के रूप में; ऑर्डरिड% 1000000000 को myorderid के रूप में चुनें (सेलेक्ट टॉप (20000) * dbo.Orders से) myorderid विकल्प (MAXDOP 1) द्वारा डी ऑर्डर के रूप में; ऑर्डरिड% 1000000000 को myorderid से चुनें (सेलेक्ट टॉप (100000) * dbo.Orders से) myorderid विकल्प (MAXDOP 1) द्वारा डी ऑर्डर के रूप में; ऑर्डरिड% 1000000000 को myorderid के रूप में चुनें (सेलेक्ट टॉप (200000) * dbo.Orders से) myorderid OPTION (MAXDOP 1) द्वारा डी ऑर्डर के रूप में;मुझे निम्नलिखित परिणाम मिले:
संख्या अनुमानित लागत अनुमानित लागत अनुपात ----------- ----------------------------- -------- --- 6000 0.117575 0.160970 1.3691 7000 0.139583 0.244848 1.7541 10000 0.207389 0.603420 2.9096 20000 0.445878 1.311710 2.9419 100000 2.591210 7.623920 2.9422 200000 5.494330 16.165700 2.9423जैसा कि आप देख सकते हैं, 5,000 पंक्तियों से परे हमारा सूत्र कम और सटीक होता जाता है, लेकिन उत्सुकता से, सटीकता अनुपात लगभग 2.94 पर लगभग 20,000 पंक्तियों पर स्थिर हो जाता है। इसका तात्पर्य यह है कि बड़ी संख्या के साथ हमारा फॉर्मूला अभी भी लागू होता है, केवल एक उच्च तुलना लागत के साथ, और लगभग 5,000 और 20,000 पंक्तियों के बीच, यह धीरे-धीरे कम तुलना लागत से उच्च में परिवर्तित होता है। लेकिन छोटे पैमाने और बड़े पैमाने के बीच अंतर क्या समझा सकता है? अच्छी खबर यह है कि इसका उत्तर क्वांटम यांत्रिकी और स्ट्रिंग सिद्धांत के साथ सामान्य सापेक्षता को समेटने जितना जटिल नहीं है। यह सिर्फ इतना है कि छोटे पैमाने पर Microsoft इस तथ्य का हिसाब देना चाहता था कि CPU कैश का उपयोग किए जाने की संभावना है, और लागत उद्देश्यों के लिए, वे एक निश्चित कैश आकार ग्रहण करते हैं।
इसलिए, बड़े पैमाने पर तुलना लागत का पता लगाने के लिए, आप 20,000 से ऊपर की संख्या के लिए दो योजनाओं से क्रमबद्ध CPU लागत का उपयोग करना चाहते हैं। मैं 100,000 और 200,000 पंक्तियों का उपयोग करूँगा (उपरोक्त तालिका में अंतिम दो पंक्तियाँ)। यहां तुलना लागत का अनुमान लगाने का सूत्र दिया गया है:
तुलना लागत =
(16.1657 - 7.62392) / (200000*LOG(200000) - 100000*LOG(100000)) =6.62193536908588E-06इसके बाद, 200,000 पंक्तियों की योजना के आधार पर स्टार्टअप लागत का अनुमान लगाने का सूत्र यहां दिया गया है:
स्टार्टअप लागत =
16.1657 – 200000*LOG(200000) * 6.62193536908588E-06 =1.35166186417734E-04यह बहुत अच्छी तरह से हो सकता है कि छोटे और बड़े पैमाने के लिए स्टार्टअप लागत समान हो, और हमें जो अंतर मिला वह गोल त्रुटियों के कारण हो। किसी भी दर पर, बड़ी संख्या में पंक्तियों के साथ, स्टार्टअप लागत तुलना की लागत की तुलना में नगण्य हो जाती है।
संक्षेप में, बड़ी संख्या में (>=20000) के लिए सॉर्ट ऑपरेटर की CPU लागत का सूत्र यहां दिया गया है:
ऑपरेटर CPU लागत =1.35166186417734E-04 + @numrows * LOG(@numrows) * 6.62193536908588E-06आइए 500K, 1M और 10M पंक्तियों के साथ सूत्र की सटीकता का परीक्षण करें। निम्नलिखित कोड आपको हमारे सूत्र की भविष्यवाणी देता है:
संख्या चुनें, 1.35166186417734E-04 + अंक * लॉग (संख्या) * 6.62193536908588E-06 अनुमानित लागत के रूप में (VALUES(500000), (1000000), (10000000)) AS D(अंक);अनुमानित CPU लागत प्राप्त करने के लिए निम्नलिखित प्रश्नों का उपयोग करें:
सेलेक्ट ऑर्डरिड% 1000000000 myorderid से (सेलेक्ट टॉप (500000) * dbo.Orders से) myorderid OPTION (MAXDOP 1) के अनुसार D ऑर्डर के रूप में; ऑर्डरिड% 1000000000 को myorderid से चुनें (सेलेक्ट टॉप (1000000) * dbo.Orders से) myorderid OPTION (MAXDOP 1) द्वारा डी ऑर्डर के रूप में; चेकसम (नया ()) से myorderid के रूप में (सेलेक्ट टॉप (10000000) O1.orderid from dbo.Orders as O1 CROSS JOIN dbo.Orders as O2) as D ORDER by myorderid OPTION(MAXDOP 1);मुझे निम्नलिखित परिणाम मिले:
संख्या अनुमानित लागत अनुमानित लागत अनुपात ----------- ----------------------------- -------- --- 500000 43.4479 43.448 1.0000 1000000 91.4856 91.486 1.0000 10000000 1067.3300 1067.340 1.0000ऐसा लगता है कि बड़ी संख्या के लिए हमारा सूत्र बहुत अच्छा करता है।
सब कुछ एक साथ रखना
पंक्तियों की छोटी संख्या (<=5,000 पंक्तियों) के लिए स्पष्ट छँटाई के साथ एक स्ट्रीम एग्रीगेट लागू करने की कुल लागत है:
<क्रमबद्ध I/O लागत> ++ <स्ट्रीम कुल ऑपरेटर लागत> =
0.0112613
+ 9.99127891201865E-05 + @numrows * LOG(@ अंक) * 2.25061348918698ई-06
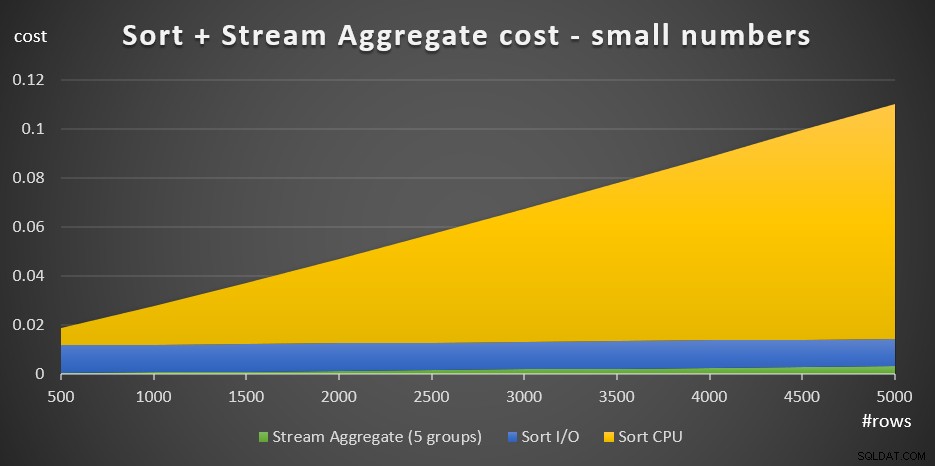
+ @numrows * 0.00000006 + @numgroups * 0.0000005चित्र 3 में एक क्षेत्र चार्ट दिखाया गया है कि यह लागत कैसे मापी जाती है।
चित्र 3:छोटी संख्या के लिए सॉर्ट + स्ट्रीम एग्रीगेट की लागत पंक्तियाँसॉर्ट सीपीयू लागत कुल सॉर्ट + स्ट्रीम कुल लागत का सबसे महत्वपूर्ण हिस्सा है। फिर भी, पंक्तियों की छोटी संख्या के साथ, स्ट्रीम कुल लागत और लागत का क्रमबद्ध I/O भाग पूरी तरह से नगण्य नहीं है। दृश्य शब्दों में, आप चार्ट के तीनों भागों को स्पष्ट रूप से देख सकते हैं।
बड़ी संख्या में पंक्तियों (>=20,000) के लिए, लागत सूत्र है:
0.0112613
+ 1.35166186417734E-04 + @numrows * LOG(@numrows) * 6.62193536908588E-06
+ @numrows * 0.0000006 + @numgroups * 0.0000005छोटे से बड़े पैमाने पर तुलनात्मक लागत परिवर्तन के सटीक तरीके को अपनाने में मुझे ज्यादा महत्व नहीं दिखाई दिया।
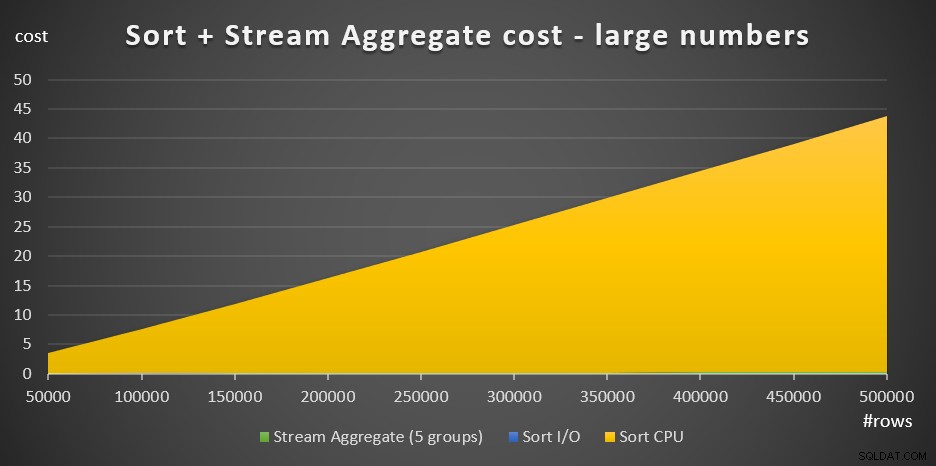
चित्र 4 में एक क्षेत्र चार्ट है जो दर्शाता है कि बड़ी संख्या के लिए लागत कैसे मापी जाती है।
चित्र 4:बड़ी संख्या में के लिए सॉर्ट + स्ट्रीम एग्रीगेट की लागत पंक्तियाँबड़ी संख्या में पंक्तियों के साथ, स्ट्रीम कुल लागत और सॉर्ट I/O लागत सॉर्ट CPU लागत की तुलना में इतनी नगण्य हैं कि वे चार्ट में नग्न आंखों के लिए भी दिखाई नहीं दे रहे हैं। इसके अलावा, स्टार्टअप कार्य के लिए जिम्मेदार सॉर्ट सीपीयू लागत का हिस्सा भी नगण्य है। इसलिए, लागत गणना का एकमात्र हिस्सा जो वास्तव में सार्थक है वह है कुल तुलना लागत:
@numrows * LOG(@numrows) * <तुलना लागत>इसका मतलब यह है कि जब आपको सॉर्ट + स्ट्रीम एग्रीगेट रणनीति के स्केलिंग का मूल्यांकन करने की आवश्यकता होती है, तो आप इसे केवल इस प्रमुख भाग में सरल बना सकते हैं। उदाहरण के लिए, यदि आपको मूल्यांकन करने की आवश्यकता है कि लागत 100,000 पंक्तियों से 100,000,000 पंक्तियों तक कैसे होगी, तो आप सूत्र का उपयोग कर सकते हैं (ध्यान दें कि तुलना लागत अप्रासंगिक है):
(10000000 * लॉग (100000000)* <तुलना लागत>) / (100000 * लॉग(100000)* <तुलना लागत>) =1600यह आपको बताता है कि जब पंक्तियों की संख्या 100,000 से बढ़कर 1,00,000,000 हो जाती है, तो अनुमानित लागत 1,600 के कारक से बढ़ जाती है।
1,000,000 से 1,00,000,000 पंक्तियों की स्केलिंग की गणना इस प्रकार की जाती है:
(1000000000 * लॉग (1000000000)) / (1000000 * लॉग (1000000)) =1500यानी, जब पंक्तियों की संख्या 1,000 के एक कारक से 1,000,000 से बढ़ जाती है, तो अनुमानित लागत 1,500 के कारक से बढ़ जाती है।
सॉर्ट + स्ट्रीम एग्रीगेट स्ट्रैटेजी स्केल के तरीके के बारे में ये दिलचस्प अवलोकन हैं। इसकी बहुत कम स्टार्टअप लागत और अतिरिक्त रैखिक स्केलिंग के कारण, आप उम्मीद करेंगे कि यह रणनीति बहुत कम पंक्तियों के साथ अच्छा प्रदर्शन करेगी, लेकिन बड़ी संख्या के साथ इतनी अच्छी तरह से नहीं। इसके अलावा, तथ्य यह है कि स्ट्रीम एग्रीगेट ऑपरेटर अकेले लागत के इतने छोटे हिस्से का प्रतिनिधित्व करता है, जब एक प्रकार की भी आवश्यकता होती है, तो आपको बताता है कि यदि स्थिति ऐसी है कि आप एक सहायक सूचकांक बनाने में सक्षम हैं तो आप काफी बेहतर प्रदर्शन प्राप्त कर सकते हैं। ।
श्रृंखला के अगले भाग में, मैं हैश एग्रीगेट एल्गोरिथम के स्केलिंग को कवर करूँगा। यदि आप लागत-सूत्रों का पता लगाने की कोशिश करने के इस अभ्यास का आनंद लेते हैं, तो देखें कि क्या आप इस एल्गोरिथम के लिए इसका पता लगा सकते हैं। महत्वपूर्ण यह है कि इसे प्रभावित करने वाले कारकों का पता लगाया जाए, इसका मापन कैसे किया जाता है, और किन परिस्थितियों में यह अन्य एल्गोरिदम से बेहतर करता है।