वह सभी जनमत डेटा कैसे संग्रहीत किया जाता है? हम एक जनमत सर्वेक्षण डेटा मॉडल की जांच करते हैं।
हर कोई जानना चाहता है कि जनता क्या सोचती है, राजनेताओं और कंपनियों से लेकर ऐसे व्यक्ति जो यह जानना चाहते हैं कि दूसरे किसी निश्चित विषय पर क्या सोचते हैं। इस तरह का काम आमतौर पर उन एजेंसियों द्वारा किया जाता है जो उस प्रकार के शोध में विशेषज्ञ होते हैं।
आज, हम एक ऐसे डेटा मॉडल पर एक नज़र डालेंगे, जिसका उपयोग ऐसी एजेंसी प्रश्नों और पूर्वनिर्धारित उत्तरों से लेकर वास्तविक फ़ीडबैक तक सभी प्रासंगिक पोल डेटा को संग्रहीत करने के लिए कर सकती है। इस डेटा का उपयोग बाद में विभिन्न रिपोर्ट बनाने के लिए किया जाएगा। तो चलिए शुरू करते हैं।
विचार
पोल कहीं भी बनाए जा सकते हैं। वे सुनियोजित हो सकते हैं और जनता का एक प्रतिनिधि नमूना (जनसांख्यिकी के आधार पर) शामिल कर सकते हैं। या आप उन्हें मौके पर ही कर सकते हैं, उदा। यदि आप एक नमूने के आधार पर चुनाव परिणामों की भविष्यवाणी करना चाहते हैं (जैसे एक्जिट पोल), तो आप शायद मतदान केंद्र पर लोगों से पूछेंगे कि उन्होंने कैसे मतदान किया।
दूसरी ओर, यदि आप चुनाव से पहले वही पोल बनाना चाहते हैं, तो आप शायद एक नमूना चुनेंगे और फोन या व्यक्तिगत रूप से व्यक्तियों से संपर्क करेंगे। आम तौर पर, इस प्रकार के मतदान के लिए कुछ ही प्रश्न होते हैं - कुछ जनसांख्यिकी को कवर करने के लिए, और अन्य जो हम वास्तव में रुचि रखते हैं उसे कवर करने के लिए।
मतदान बहुत अधिक जटिल भी हो सकते हैं, उदा. अगर आप किसी खास उत्पाद के बारे में जनता की राय जानना चाहते हैं, जिसमें उसके प्रदर्शन से लेकर उसकी पैकेजिंग तक सब कुछ शामिल है।
इस लेख में, मैं इस बात पर चर्चा नहीं करूंगा कि लोगों के एक नमूना समूह का चयन कैसे किया जाए; इसके बजाय, मैं स्वयं मतदान, उसके प्रश्नों और प्रतिक्रियाओं पर ध्यान दूंगा।
डेटा मॉडल
सार्वजनिक राय एजेंसी डेटा मॉडल
मॉडल में तीन विषय क्षेत्र होते हैं:
PollsQuestions & AnswersResult
हम प्रत्येक विषय क्षेत्र का उसके सूचीबद्ध क्रम में वर्णन करेंगे।
मतदान
इससे पहले कि हम प्रश्न पूछना शुरू करें, हमें यह परिभाषित करने की आवश्यकता है कि हम किसमें रुचि रखते हैं। हम इस खंड में चुनाव और प्रश्नावली को परिभाषित करेंगे, फिर अगले में प्रश्न और उत्तर जोड़ेंगे।
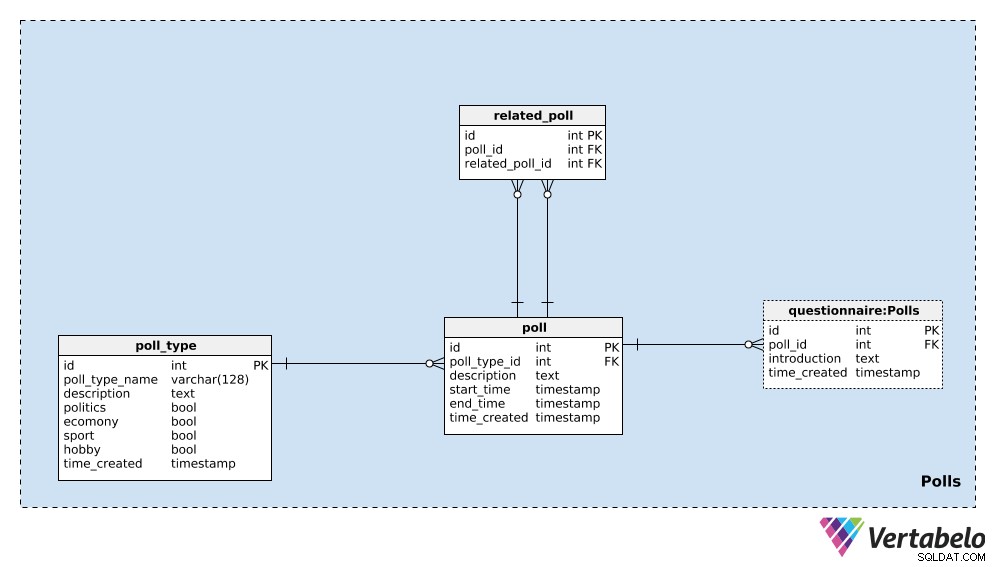
हम poll_type शब्दकोश। हम उम्मीद कर सकते हैं कि हम ज्यादातर उसी प्रकार के चुनाव दोहराएंगे। सबसे आम प्रकार शायद चुनावी चुनाव है, लेकिन हम रास्ते में नए प्रकार के मतदान जोड़ने में सक्षम होना चाहते हैं। प्रत्येक मतदान प्रकार के लिए, हम एक अद्वितीय poll_type_name . संग्रहित करेंगे और description का उपयोग करें अतिरिक्त विवरण प्रदान करने के लिए विशेषता।
चार झंडे - politics , economy , sport , और hobby - मतदान के प्रकार को दर्शाने के लिए उपयोग किया जाता है। एक सर्वेक्षण उन विषयों में से एक या अधिक को कवर कर सकता है; यदि आवश्यक हो, तो हम इन श्रेणियों को एक अलग शब्दकोश में विभाजित कर सकते हैं और उस शब्दकोश और poll_type टेबल।
इस तालिका में अंतिम विशेषता है time_created . यह उस पल को दर्शाता है जब इस तालिका में एक पंक्ति डाली जाती है।
अगली चीज़ जो हमें करने की ज़रूरत है वह है एक एकल poll . यह एक एकल उदाहरण है, उदा। “2020 यूनाइटेड स्टेट्स प्रेसिडेंशियल इलेक्शन – अप्रैल 2020 पोल” . प्रत्येक मतदान के लिए, हम निम्नलिखित विवरण संग्रहीत करेंगे:
poll_type_id-poll_type।description- इस मतदान से संबंधित सभी विवरण, पाठ्य प्रारूप में।start_timeऔरend_time- परिभाषित प्रारंभ और समाप्ति समय, जिसके दौरान यह मतदान किया जाता है।time_created- वास्तविक क्षण जब यह पोल बनाया गया था।
मतदान एक दूसरे से संबंधित हो सकते हैं। “2020 यूनाइटेड स्टेट्स प्रेसिडेंशियल इलेक्शन – अप्रैल 2020 पोल” . के उदाहरण में , हम सबसे वर्तमान राय देखने के लिए अगले महीने वही सर्वेक्षण कर सकते हैं। हम इसे “2020 युनाइटेड स्टेट्स प्रेसिडेंशियल इलेक्शन – मई 2020 पोल” . कहेंगे . ये दोनों चुनाव संबंधित हैं क्योंकि उनके परिणाम रुझान दिखाते हैं। उस संबंध को स्थापित करने के लिए, हम related_poll हमारे मॉडल में तालिका। इसमें poll_id . का केवल UNIQUE जोड़ा है - related_poll_id , मतदान और उसके पूर्ववर्ती को दर्शाता है।
ध्यान दें कि हम इस तालिका का उपयोग उन सभी पोलों को संग्रहीत करने के लिए कर सकते हैं जो किसी भी तरह से संबंधित हैं, न कि केवल पूर्ववर्ती/उत्तराधिकारी। अगर हम अलग-अलग रिश्तों को परिभाषित करना चाहते हैं, तो हमें एक और शब्दकोश जोड़ना होगा - लेकिन हम इस लेख में ऐसा नहीं करेंगे।
इस विषय क्षेत्र में अंतिम तालिका questionnaire टेबल। ज्यादातर मामलों में, प्रत्येक मतदान में ठीक एक प्रश्नावली होगी, लेकिन मैं इस विकल्प को छोड़ना चाहता हूं कि जरूरत पड़ने पर हमारे पास एक से अधिक प्रश्न हो सकते हैं। इसलिए, मैंने एक अलग तालिका का उपयोग किया है। इस तालिका में, हम संबंधित मतदान की केवल आईडी संग्रहीत करेंगे (poll_id ), एक introduction उस प्रश्नावली और उस टाइमस्टैम्प का वर्णन करते हुए जब रिकॉर्ड डाला गया था (time_created )।
प्रश्न और उत्तर
अब हम सभी प्रश्नावली विवरण तैयार करने के लिए तैयार हैं। हम उन सभी प्रश्नों को भी सूचीबद्ध कर सकते हैं जिन्हें हम पूछना चाहते हैं और साथ ही सभी पूर्वनिर्धारित उत्तरों को भी सूचीबद्ध कर सकते हैं।
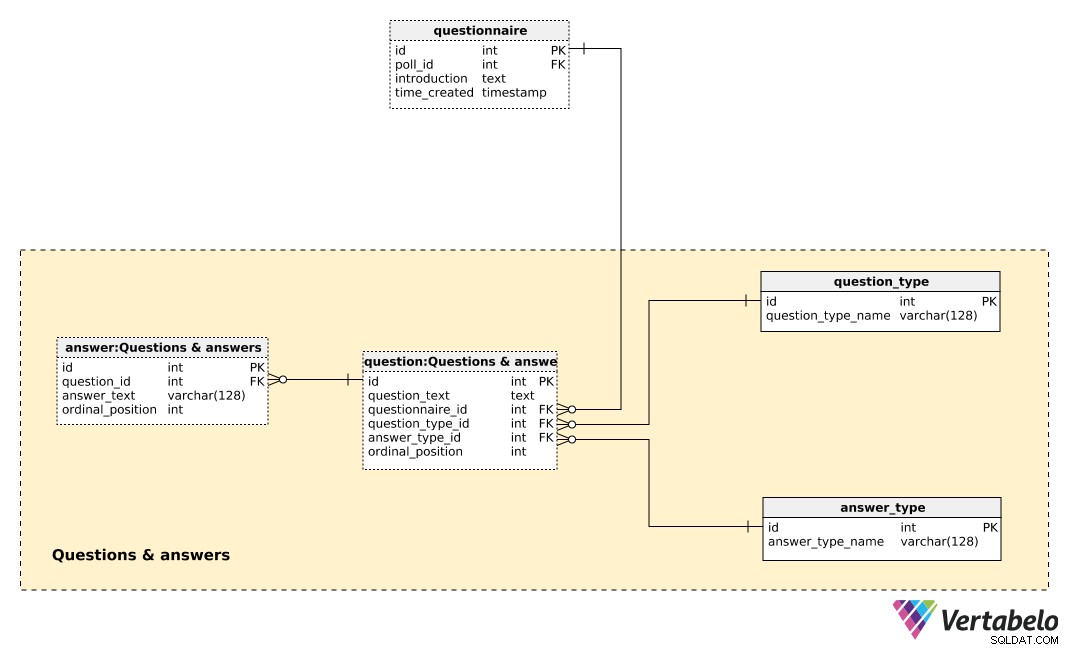
इस विषय क्षेत्र में केंद्रीय तालिका question टेबल। प्रत्येक प्रश्न निम्नलिखित विवरण द्वारा परिभाषित किया गया है:
question_text- एक पाठ जो मतदान किए जाने वाले प्रत्येक व्यक्ति को प्रदर्शित किया जाएगा।questionnaire_id- इस प्रश्न की प्रश्नावली को दर्शाने वाला एक संदर्भ।question_type_id-question_type, जिसे UNIQUELYquestion_type_name. द्वारा दर्शाया गया है . ये मूल रूप से श्रेणियां हैं, उदा। "जनसांख्यिकी", "राय", "नियंत्रण", आदि। ये हमें जनसांख्यिकीय और राय प्रश्नों को अलग करने और उनके बीच एक संबंध खोजने की अनुमति देंगे।answer_type_id- इस प्रश्न के लिए उपयोग किए जाने वाले उत्तर के प्रकार का संदर्भ। प्रत्येकanswer_typeअद्वितीय रूप सेanswer_type_name. द्वारा परिभाषित किया गया है और दर्शाता है कि उत्तर कैसे प्रदर्शित होता है। कुछ अपेक्षित प्रकार "खुले", "सूची", "चेकबॉक्स" और "एकाधिक" हैं।ordinal_position- यह मान प्रश्नावली में इस प्रश्न की स्थिति को दर्शाता है। साथ मेंquestionnaire_id, यह इस तालिका की वैकल्पिक कुंजी बनाती है।
सभी पूर्वनिर्धारित उत्तरों की सूची answer टेबल। यदि प्रश्न प्रकार खुला नहीं है (अर्थात व्यक्ति द्वारा पाठ दर्ज नहीं किया जाएगा), तो हमारे पास पूर्वनिर्धारित उत्तरों का एक सेट होगा। प्रत्येक उत्तर के लिए, हम उस प्रश्न को परिभाषित करेंगे जिससे वह संबंधित है (question_id ), answer_text , और ordinal_position उस प्रश्न के भीतर उस उत्तर का। एक बार फिर, एक अद्वितीय जोड़ी - इस बार question_id - ordinal_position – इस तालिका की वैकल्पिक कुंजी बनाता है।
परिणाम
पिछले दो विषय क्षेत्रों में, हमने पोल बनाने और प्रश्न पूछना शुरू करने के लिए आवश्यक सभी चीज़ों को परिभाषित किया है। अब हमें वास्तविक उत्तरों को संग्रहीत करने के लिए डेटा संरचना को परिभाषित करने की आवश्यकता है।
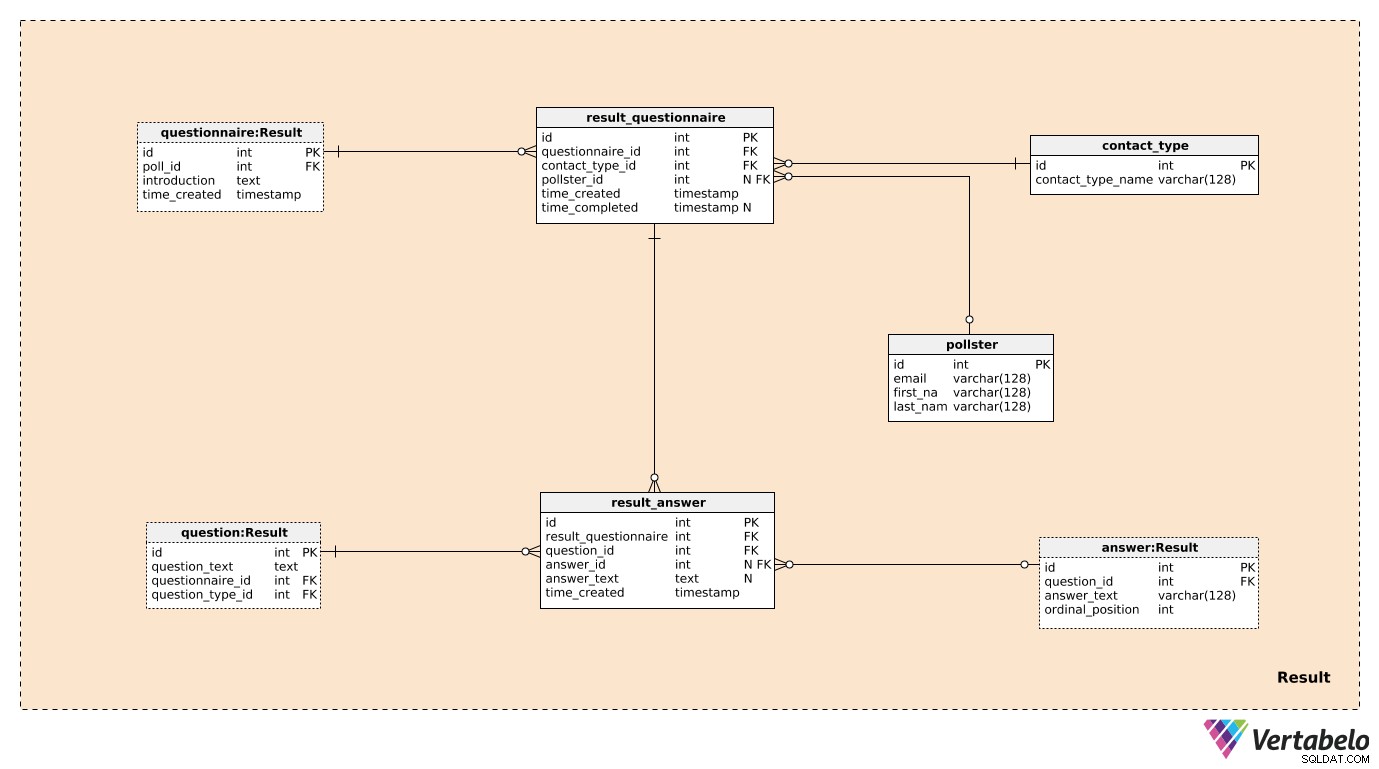
Result विषय क्षेत्र का पहले उल्लेख और वर्णन किया गया था। ये हैं questionnaire , question , और answer . शेष चार तालिकाओं का उपयोग उस चीज़ को संग्रहीत करने के लिए किया जाता है जिसमें हम वास्तव में रुचि रखते हैं।
हम result_questionnaire मतदान में भाग लेने वाले प्रत्येक व्यक्ति के लिए तालिका। questionnaire_id प्रासंगिक मतदान के बारे में सभी जानकारी के साथ esus प्रदान करें। contact_type_id contact_type शब्दकोश। इस तालिका के मान इस व्यक्ति के साथ हमारे इंटरैक्ट करने के तरीके का वर्णन करते हैं। ये मान अद्वितीय रूप से contact_type_name . द्वारा परिभाषित हैं मूल्य और "फ़ोन", "इन-पर्सन", "ईमेल", "वेबफ़ॉर्म", आदि जैसे कुछ हो सकते हैं।
pollster_id विशेषता pollster तालिका, जो यह जानकारी प्रदान करती है कि वास्तविक मतदान किसने किया था। प्रत्येक pollster , हम केवल उनके अद्वितीय ईमेल और उनके first_name . को संगृहीत करेंगे और last_name . time_created विशेषता उस वास्तविक समय को दर्शाती है जब यह रिकॉर्ड बनाया गया था, जबकि time_completed इस सर्वेक्षण के पूरा होने पर सेट किया जाएगा। (उस समय तक, यह NULL रहेगा)।
मॉडल में अंतिम तालिका result_answer टेबल। जैसा कि इसके नाम से पता चलता है, यह वह जगह है जहां हम सर्वेक्षणकर्ताओं से प्राप्त वास्तविक प्रतिक्रियाओं को संग्रहीत करेंगे। इस तालिका में प्रत्येक रिकॉर्ड के लिए, हमारे पास होगा:
result_questionnaire_id- प्रासंगिक प्रश्नावली का संदर्भ।question_id- इस प्रतिक्रिया द्वारा उत्तर दिए गए प्रश्न को दर्शाने वाला एक संदर्भ।answer_id- उस उत्तर का संदर्भ जिसका उपयोग इस प्रश्न का उत्तर देने के लिए किया गया था। जब प्रश्न "खुला" प्रकार का हो तो इस विशेषता में एक NULL मान होगा (क्योंकि इसमें से चुनने के लिए कोई पूर्वनिर्धारित उत्तर नहीं थे)।answer_text- इस प्रश्न का उत्तर देने के लिए डाला गया पाठ। इस विशेषता में एक मान होगा जब प्रश्न "खुला" था; अन्य सभी मामलों में, यह NULL होगा।time_created- वास्तविक समय जब यह उत्तर हमारे सिस्टम में डाला गया था।
संभावित सुधार
अब तक, हमने कवर किया है कि हम पोल डेटा कैसे स्टोर कर सकते हैं। हमने चर्चा नहीं की है कि मतदान बंद होने के बाद हम डेटा के साथ क्या करेंगे। हम उम्मीद कर सकते हैं कि हमें भविष्य में पुराने डेटा की आवश्यकता नहीं होगी, कम से कम हमारे परिचालन डेटाबेस में तो नहीं। इसलिए, हम दो काम कर सकते हैं:
- परिचालन डेटाबेस में एक अलग तालिका में मतदान सारांश संग्रहीत करें। अगर हम यह देखना चाहते हैं कि इसी तरह के सर्वेक्षण के साथ क्या हुआ है तो यह ऐसी जानकारी हमारे पास रखेगा।
- सभी पोल डेटा को एक बैकअप डेटाबेस में संग्रहीत करें जिसकी संरचना परिचालन डेटाबेस के समान है। यह हमें जरूरत पड़ने पर विवरणों तक पहुंचने की अनुमति देगा।
हम मतदान परिणामों को संग्रहीत करने के लिए एक डेटा वेयरहाउस भी बना सकते हैं, लेकिन यह आवश्यक नहीं होगा यदि हम पहले से ही दो बुलेट बिंदुओं में वर्णित कार्य कर चुके हों।
आप हमारे जनमत सर्वेक्षण डेटा मॉडल के बारे में क्या सोचते हैं?
हम इस बारे में आपकी राय जानना चाहेंगे कि जनमत सर्वेक्षण डेटा मॉडल को बेहतर बनाने के लिए हम क्या बदल सकते हैं। क्या आपके पास उद्योग का अनुभव है? क्या आपको लगता है कि हमने कुछ याद किया? क्या आप कुछ जोड़ेंगे या हटाएंगे? आपकी राय सुनने के लिए उत्सुक हैं।