ऑडिट लॉगिंग के लिए डेटाबेस डिजाइन के बारे में सोच रहे हैं? याद रखें कि हेंसल और ग्रेटेल के साथ क्या हुआ था:उन्होंने सोचा था कि ब्रेडक्रंब का एक साधारण निशान छोड़ना उनके कदमों का पता लगाने का एक अच्छा तरीका था।
जब हम एक डेटा मॉडल डिज़ाइन करते हैं, तो हमें इस सिद्धांत को लागू करने के लिए प्रशिक्षित किया जाता है कि अब सब कुछ मौजूद है . उदाहरण के लिए, यदि हम किसी उत्पाद कैटलॉग के लिए कीमतों को संग्रहीत करने के लिए एक स्कीमा डिज़ाइन करते हैं, तो हम सोच सकते हैं कि डेटाबेस को केवल हमें वर्तमान समय में प्रत्येक उत्पाद की कीमत बताने की आवश्यकता है। लेकिन अगर हम जानना चाहते हैं कि क्या कीमतों में संशोधन किया गया था और यदि हां, तो वे संशोधन कब और कैसे हुए, तो हम मुश्किल में पड़ जाएंगे। बेशक, हम डेटाबेस को विशेष रूप से परिवर्तनों का कालानुक्रमिक रिकॉर्ड रखने के लिए डिज़ाइन कर सकते हैं - जिसे आमतौर पर ऑडिट ट्रेल या ऑडिट लॉग के रूप में जाना जाता है।
ऑडिट लॉगिंग एक डेटाबेस को पिछली घटनाओं की 'स्मृति' रखने की अनुमति देता है। मूल्य सूची उदाहरण के साथ जारी रखते हुए, एक उचित ऑडिट लॉग डेटाबेस को हमें यह बताने की अनुमति देगा कि कीमत कब अपडेट की गई थी, अपडेट होने से पहले कीमत क्या थी, इसे किसने और कहां से अपडेट किया था।
डेटाबेस ऑडिट लॉगिंग समाधान
यह बहुत अच्छा होगा यदि डेटाबेस अपने डेटा में होने वाले प्रत्येक परिवर्तन के लिए अपने राज्य का एक स्नैपशॉट रख सके। इस तरह, आप किसी भी समय पर वापस जा सकते हैं और देख सकते हैं कि उस सटीक क्षण में डेटा कैसा था जैसे कि आप किसी फिल्म को रिवाइंड कर रहे थे। लेकिन ऑडिट लॉगिंग उत्पन्न करने का वह तरीका स्पष्ट रूप से असंभव है; परिणामी जानकारी की मात्रा और लॉग उत्पन्न करने में लगने वाला समय बहुत अधिक होगा।
ऑडिट लॉगिंग रणनीतियाँ केवल डेटा के लिए ऑडिट ट्रेल्स उत्पन्न करने पर आधारित होती हैं जिन्हें हटाया या संशोधित किया जा सकता है। परिवर्तनों को वापस लेने, इतिहास तालिका में डेटा को क्वेरी करने, या संदिग्ध गतिविधि को ट्रैक करने के लिए उनमें किसी भी परिवर्तन का ऑडिट किया जाना चाहिए।
कई लोकप्रिय ऑडिट लॉगिंग तकनीकें हैं, लेकिन उनमें से कोई भी हर उद्देश्य की पूर्ति नहीं करता है। सबसे प्रभावी वाले अक्सर महंगे, संसाधन गहन, या प्रदर्शन में गिरावट वाले होते हैं। अन्य संसाधनों के मामले में सस्ते हैं लेकिन या तो अपूर्ण हैं, बनाए रखने के लिए बोझिल हैं, या डिजाइन गुणवत्ता में बलिदान की आवश्यकता है। आप कौन सी रणनीति चुनते हैं, यह आवेदन आवश्यकताओं और प्रदर्शन सीमाओं, संसाधनों और डिजाइन सिद्धांतों पर निर्भर करेगा जिनका आपको सम्मान करना चाहिए।
आउट-ऑफ़-द-बॉक्स लॉगिंग समाधान
ये ऑडिट लॉगिंग समाधान डेटाबेस को भेजे गए सभी कमांड को इंटरसेप्ट करके और एक अलग रिपॉजिटरी में परिवर्तन लॉग उत्पन्न करके काम करते हैं। ऐसे प्रोग्राम उपयोगकर्ता के कार्यों को ट्रैक करने के लिए कई कॉन्फ़िगरेशन और रिपोर्टिंग विकल्प प्रदान करते हैं। वे डेटाबेस को भेजे गए सभी कार्यों और प्रश्नों को लॉग कर सकते हैं, तब भी जब वे उच्चतम विशेषाधिकार वाले उपयोगकर्ताओं से आते हैं। इन उपकरणों को प्रदर्शन प्रभाव को कम करने के लिए अनुकूलित किया गया है, लेकिन यह अक्सर एक मौद्रिक लागत पर आता है।
यदि आप अत्यधिक संवेदनशील जानकारी (जैसे मेडिकल रिकॉर्ड) को संभाल रहे हैं, तो समर्पित ऑडिट ट्रेल समाधानों की कीमत को उचित ठहराया जा सकता है, जहां डेटा के किसी भी परिवर्तन को पूरी तरह से मॉनिटर और ऑडिट करने योग्य होना चाहिए और ऑडिट ट्रेल अपरिवर्तनीय होना चाहिए। लेकिन जब ऑडिट ट्रेल की आवश्यकताएं उतनी सख्त नहीं होती हैं, तो एक समर्पित लॉगिंग समाधान की लागत अत्यधिक हो सकती है।
रिलेशनल डेटाबेस सिस्टम (RDBMS) द्वारा पेश किए गए नेटिव मॉनिटरिंग टूल का उपयोग ऑडिट ट्रेल्स उत्पन्न करने के लिए भी किया जा सकता है। अनुकूलन विकल्प फ़िल्टर करने की अनुमति देते हैं कि कौन सी घटनाओं को रिकॉर्ड किया गया है, ताकि अनावश्यक जानकारी उत्पन्न न हो या डेटाबेस इंजन को लॉगिंग संचालन के साथ अधिभारित न किया जाए जो बाद में उपयोग नहीं किया जाएगा। इस तरह से उत्पन्न लॉग टेबल पर निष्पादित संचालन की विस्तृत ट्रैकिंग की अनुमति देते हैं। हालांकि, वे इतिहास तालिकाओं को क्वेरी करने के लिए उपयोगी नहीं हैं, क्योंकि वे केवल घटनाओं को रिकॉर्ड करते हैं।
ऑडिट ट्रेल को बनाए रखने का सबसे किफायती विकल्प ऑडिट लॉगिंग के लिए अपने डेटाबेस को विशेष रूप से डिज़ाइन करना है। यह तकनीक लॉग टेबल पर आधारित होती है जो डेटाबेस को अपडेट करने वाले एप्लिकेशन के लिए विशिष्ट ट्रिगर्स या तंत्र द्वारा पॉप्युलेट होती है। ऑडिट लॉगिंग डेटाबेस डिज़ाइन के लिए कोई सार्वभौमिक रूप से स्वीकृत दृष्टिकोण नहीं है, लेकिन कई सामान्य रूप से उपयोग की जाने वाली रणनीतियाँ हैं, जिनमें से प्रत्येक के अपने फायदे और नुकसान हैं।
डेटाबेस ऑडिट लॉगिंग डिजाइन तकनीक
ऑडिट लॉगिंग इन प्लेस के लिए रो वर्जनिंग
किसी तालिका के लिए ऑडिट ट्रेल को बनाए रखने का एक तरीका एक फ़ील्ड जोड़ना है जो प्रत्येक रिकॉर्ड की संस्करण संख्या को इंगित करता है। तालिका में सम्मिलन प्रारंभिक संस्करण संख्या के साथ सहेजे जाते हैं। कोई भी संशोधन या विलोपन वास्तव में सम्मिलन संचालन बन जाता है, जहां अद्यतन डेटा के साथ नए रिकॉर्ड उत्पन्न होते हैं और संस्करण संख्या एक से बढ़ जाती है। आप इस ऑडिट लॉगिंग इन प्लेस डिज़ाइन का एक उदाहरण नीचे देख सकते हैं:
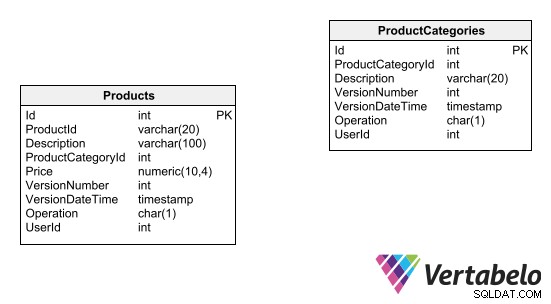
नोट:एम्बेडेड पंक्ति संस्करण के साथ तालिका डिज़ाइन को विदेशी कुंजी संबंधों से नहीं जोड़ा जा सकता है।
संस्करण संख्या के अतिरिक्त, रिकॉर्ड में किए गए प्रत्येक परिवर्तन के मूल और कारण को निर्धारित करने के लिए तालिका में कुछ अतिरिक्त फ़ील्ड जोड़े जाने चाहिए:
- दिनांक/समय जब परिवर्तन दर्ज किया गया था।
- उपयोगकर्ता और एप्लिकेशन।
- कार्य किया गया (सम्मिलित करें, अपडेट करें, हटाएं), आदि। ऑडिट ट्रेल प्रभावी होने के लिए, तालिका को केवल सम्मिलन का समर्थन करना चाहिए (अद्यतन और हटाने की अनुमति नहीं दी जानी चाहिए)। तालिका को भी आवश्यक रूप से एक सरोगेट प्राथमिक कुंजी की आवश्यकता होती है, क्योंकि फ़ील्ड का कोई अन्य संयोजन दोहराव के अधीन होगा।
क्वेरी के माध्यम से अद्यतन तालिका डेटा तक पहुँचने के लिए, आपको एक ऐसा दृश्य बनाना होगा जो प्रत्येक रिकॉर्ड का केवल नवीनतम संस्करण लौटाए। फिर, आपको सभी प्रश्नों में तालिका के नाम को दृश्य के नाम से बदलना होगा, सिवाय उन प्रश्नों के जो विशेष रूप से अभिलेखों के कालक्रम को देखने के लिए अभिप्रेत हैं।
इस संस्करण विकल्प का लाभ यह है कि ऑडिट ट्रेल उत्पन्न करने के लिए अतिरिक्त तालिकाओं का उपयोग करने की आवश्यकता नहीं है। साथ ही, लेखापरीक्षित तालिकाओं में केवल कुछ फ़ील्ड जोड़े जाते हैं। लेकिन इसका एक बड़ा नुकसान है:यह आपको कुछ सबसे सामान्य डेटाबेस डिज़ाइन त्रुटियों को बनाने के लिए मजबूर करेगा। इनमें संदर्भात्मक अखंडता या प्राकृतिक प्राथमिक कुंजियों का उपयोग नहीं करना शामिल है, जब ऐसा करना आवश्यक हो, जिससे इकाई-संबंध आरेख डिजाइन के मूल सिद्धांतों को लागू करना असंभव हो जाता है। आप डेटाबेस डिज़ाइन त्रुटियों पर इन उपयोगी संसाधनों पर जा सकते हैं, इसलिए आपको चेतावनी दी जाएगी कि किन अन्य प्रथाओं से बचना चाहिए।
छाया टेबल
एक अन्य ऑडिट ट्रेल विकल्प प्रत्येक तालिका के लिए एक छाया तालिका उत्पन्न करना है जिसे ऑडिट करने की आवश्यकता है। शैडो टेबल में वही फ़ील्ड होते हैं जो टेबल वे ऑडिट करते हैं, साथ ही विशिष्ट ऑडिट फ़ील्ड (वही जो पंक्ति संस्करण तकनीक के लिए उल्लिखित हैं)।
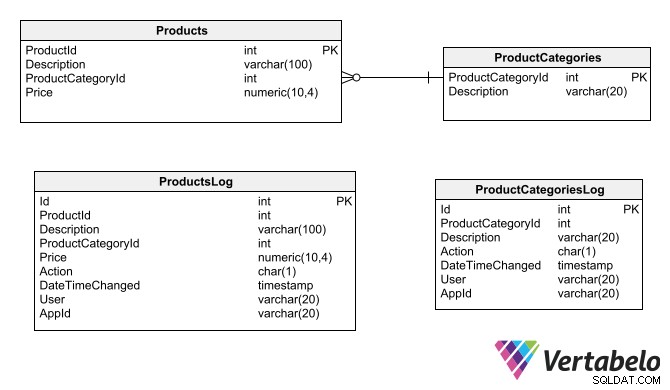
छाया तालिकाएं उन्हीं फ़ील्ड को दोहराती हैं, जिनका वे ऑडिट करते हैं, साथ ही ऑडिटिंग उद्देश्यों के लिए विशिष्ट फ़ील्ड।
शैडो टेबल में ऑडिट ट्रेल्स जेनरेट करने के लिए, सबसे सुरक्षित विकल्प इंसर्ट बनाना, अपडेट करना और ट्रिगर हटाना है, ताकि मूल तालिका में प्रत्येक प्रभावित रिकॉर्ड के लिए ऑडिट टेबल में एक रिकॉर्ड बनाया जा सके। ट्रिगर्स के पास उन सभी ऑडिट सूचनाओं तक पहुंच होनी चाहिए, जिन्हें आपको शैडो टेबल में रिकॉर्ड करने की आवश्यकता है। आपको डेटा प्राप्त करने के लिए डेटाबेस इंजन की विशिष्ट कार्यक्षमता का उपयोग करना होगा जैसे कि वर्तमान तिथि और समय, लॉग उपयोगकर्ता, एप्लिकेशन का नाम, और स्थान (नेटवर्क पता या कंप्यूटर का नाम) जहां ऑपरेशन शुरू हुआ था।
यदि ट्रिगर्स का उपयोग करना एक विकल्प नहीं है, तो ऑडिट ट्रेल्स उत्पन्न करने के लिए तर्क को एप्लिकेशन स्टैक का हिस्सा होना चाहिए, आदर्श रूप से डेटा दृढ़ता परत से ठीक पहले स्थित एक परत में, ताकि यह डेटाबेस की ओर निर्देशित सभी कार्यों को रोक सके।
इस प्रकार की लॉग तालिका को केवल रिकॉर्ड प्रविष्टि की अनुमति देनी चाहिए; यदि वे संशोधन या हटाने की अनुमति देते हैं, तो ऑडिट ट्रेल अपने कार्य को पूरा नहीं करेगा। तालिकाओं को सरोगेट प्राथमिक कुंजियों का भी उपयोग करना चाहिए, क्योंकि मूल तालिकाओं की निर्भरता और संबंध उन पर लागू नहीं किए जा सकते हैं।
यदि जिस तालिका के लिए आपने ऑडिट ट्रेल बनाया है उसमें टेबल हैं जिन पर यह निर्भर करता है, तो उनके पास संबंधित शैडो टेबल भी होनी चाहिए। ऐसा इसलिए है ताकि अन्य तालिकाओं में परिवर्तन किए जाने पर ऑडिट ट्रेल अनाथ न हो।
शैडो टेबल उनकी सादगी के कारण सुविधाजनक हैं और क्योंकि वे डेटा मॉडल की अखंडता को प्रभावित नहीं करते हैं; ऑडिट ट्रेल्स अलग-अलग टेबल में रहते हैं और क्वेरी करना आसान होता है। दोष यह है कि योजना लचीली नहीं है:मुख्य तालिका की संरचना में कोई भी परिवर्तन संबंधित छाया तालिका में परिलक्षित होना चाहिए, जिससे मॉडल को बनाए रखना मुश्किल हो जाता है। इसके अलावा, यदि ऑडिट लॉगिंग को बड़ी संख्या में तालिकाओं पर लागू करने की आवश्यकता है, तो छाया तालिकाओं की संख्या भी अधिक होगी, जिससे स्कीमा रखरखाव और भी कठिन हो जाएगा।
ऑडिट लॉगिंग के लिए सामान्य तालिकाएं
तीसरा विकल्प ऑडिट लॉग के लिए जेनेरिक टेबल बनाना है। ऐसी तालिकाएँ स्कीमा में किसी अन्य तालिका को लॉग करने की अनुमति देती हैं। इस तकनीक के लिए केवल दो तालिकाओं की आवश्यकता है:
एक शीर्षलेख तालिका जो रिकॉर्ड करती है:
- परिवर्तन की तिथि और समय।
- तालिका का नाम।
- प्रभावित पंक्ति की कुंजी.
- उपयोगकर्ता डेटा।
- प्रदर्शन का प्रकार।
एक विवरण तालिका जो रिकॉर्ड करती है:
- प्रत्येक प्रभावित क्षेत्र के नाम।
- संशोधन से पहले फ़ील्ड मान।
- संशोधन के बाद फ़ील्ड मान। (यदि आवश्यक हो तो आप इसे छोड़ सकते हैं, क्योंकि इसे ऑडिट ट्रेल में निम्नलिखित रिकॉर्ड या ऑडिट की गई तालिका में संबंधित रिकॉर्ड से परामर्श करके प्राप्त किया जा सकता है।)
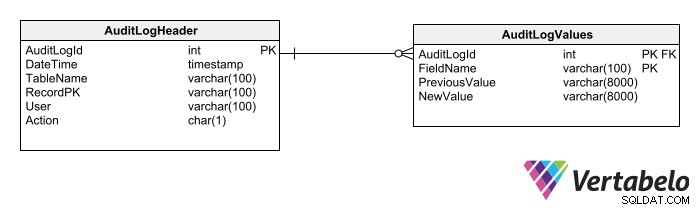
जेनेरिक ऑडिट लॉग टेबल का उपयोग ऑडिट किए जा सकने वाले डेटा के प्रकारों को सीमित करता है।
इस ऑडिट लॉगिंग रणनीति का लाभ यह है कि इसमें ऊपर उल्लिखित दो के अलावा किसी अन्य तालिका की आवश्यकता नहीं है। साथ ही, इसमें केवल उन फ़ील्ड के लिए रिकॉर्ड संग्रहीत किए जाते हैं जो किसी ऑपरेशन से प्रभावित होते हैं। इसका मतलब है कि जब केवल एक फ़ील्ड को संशोधित किया जाता है, तो तालिका की पूरी पंक्ति को दोहराने की कोई आवश्यकता नहीं होती है। इसके अलावा, यह तकनीक आपको बड़ी संख्या में अतिरिक्त तालिकाओं के साथ स्कीमा को अव्यवस्थित किए बिना - जितनी चाहें उतनी तालिकाओं का लॉग रखने की अनुमति देती है।
नुकसान यह है कि मूल्यों को संग्रहीत करने वाले फ़ील्ड एक ही प्रकार के होने चाहिए - और टेबल के सबसे बड़े फ़ील्ड को भी स्टोर करने के लिए पर्याप्त चौड़ा होना चाहिए जिसके लिए आप ऑडिट लॉग बनाना चाहते हैं। VARCHAR-प्रकार के फ़ील्ड का उपयोग करना सबसे आम है जो बड़ी संख्या में वर्णों को स्वीकार करते हैं।
यदि, उदाहरण के लिए, आपको 8,000 वर्णों की एक VARCHAR फ़ील्ड वाली तालिका के लिए ऑडिट लॉग जेनरेट करने की आवश्यकता है, तो ऑडिट तालिका में मानों को संग्रहीत करने वाले फ़ील्ड में 8,000 वर्ण भी होने चाहिए। यह सच है भले ही आप उस क्षेत्र में केवल एक पूर्णांक संग्रहीत करते हैं। दूसरी ओर, यदि आपकी तालिका में जटिल डेटा प्रकार के फ़ील्ड हैं, जैसे कि चित्र, बाइनरी डेटा, BLOB, आदि, तो आपको उनकी सामग्री को क्रमबद्ध करने की आवश्यकता होगी ताकि उन्हें लॉग टेबल के VARCHAR फ़ील्ड में संग्रहीत किया जा सके।
अपना डेटाबेस ऑडिट लॉग डिज़ाइन बुद्धिमानी से चुनें
हमने ऑडिट लॉगिंग उत्पन्न करने के लिए कई विकल्प देखे हैं, लेकिन उनमें से कोई भी वास्तव में इष्टतम नहीं है। आपको एक लॉगिंग रणनीति अपनानी चाहिए जो आपके डेटाबेस के प्रदर्शन को महत्वपूर्ण रूप से प्रभावित नहीं करती है, इसे अत्यधिक विकसित नहीं करती है, और आपकी ट्रेसिबिलिटी आवश्यकताओं को पूरा कर सकती है। यदि आप केवल कुछ तालिकाओं के लिए लॉग स्टोर करना चाहते हैं, तो शैडो टेबल सबसे सुविधाजनक विकल्प हो सकता है। यदि आप चाहते हैं कि किसी तालिका को लॉग करने का लचीलापन हो, तो सामान्य लॉगिंग तालिकाएं सर्वोत्तम हो सकती हैं।
क्या आपने अपने डेटाबेस के लिए ऑडिट लॉग रखने का कोई अन्य तरीका खोजा है? इसे नीचे टिप्पणी अनुभाग में साझा करें - आपके साथी डेटाबेस डिजाइनर बहुत आभारी होंगे!