केविन क्लाइन (@kekline) और मैंने हाल ही में एक क्वेरी ट्यूनिंग वेबिनार आयोजित किया (ठीक है, एक श्रृंखला में एक, वास्तव में), और जो चीजें सामने आई हैं उनमें से एक है लोगों की प्रवृत्ति किसी भी लापता इंडेक्स को बनाने के लिए जो SQL सर्वर उन्हें बताता है होगा। एक अच्छी बात™ . वे डेटाबेस इंजन ट्यूनिंग एडवाइज़र (डीटीए), लापता इंडेक्स डीएमवी, या प्रबंधन स्टूडियो या प्लान एक्सप्लोरर में प्रदर्शित एक निष्पादन योजना से इन लापता इंडेक्स के बारे में जान सकते हैं (जिनमें से सभी बिल्कुल एक ही जगह से जानकारी रिले करते हैं):
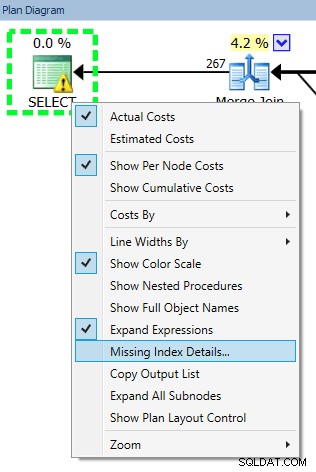
केवल आँख बंद करके इस इंडेक्स को बनाने में समस्या यह है कि SQL सर्वर ने यह निर्णय लिया है कि यह किसी विशेष क्वेरी (या मुट्ठी भर प्रश्नों) के लिए उपयोगी है, लेकिन शेष कार्यभार को पूरी तरह और एकतरफा अनदेखा करता है। जैसा कि हम सभी जानते हैं, इंडेक्स "फ्री" नहीं होते हैं - आप इंडेक्स के लिए कच्चे भंडारण के साथ-साथ डीएमएल संचालन पर आवश्यक रखरखाव दोनों के लिए भुगतान करते हैं। यह बहुत कम समझ में आता है, एक लिखने-भारी कार्यभार में, एक सूचकांक जोड़ने के लिए जो किसी एकल क्वेरी को थोड़ा अधिक कुशल बनाने में मदद करता है, खासकर यदि वह क्वेरी अक्सर नहीं चलती है। इन मामलों में यह बहुत महत्वपूर्ण हो सकता है कि आप अपने समग्र कार्यभार को समझें और अपने प्रश्नों को कुशल बनाने और अनुक्रमणिका रखरखाव के मामले में इसके लिए बहुत अधिक भुगतान न करने के बीच एक अच्छा संतुलन बनाएं।
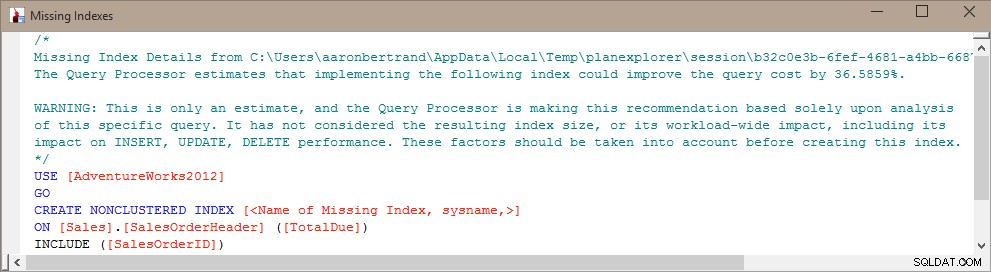
तो मेरे पास एक विचार था कि लापता इंडेक्स डीएमवी, इंडेक्स उपयोग आंकड़े डीएमवी, और क्वेरी योजनाओं के बारे में जानकारी को "मैश अप" करें, यह निर्धारित करने के लिए कि वर्तमान में किस प्रकार का संतुलन मौजूद है और इंडेक्स को समग्र रूप से कैसे जोड़ा जा सकता है।
अनुक्रमणिका अनुपलब्ध
सबसे पहले, हम अनुपलब्ध अनुक्रमणिका पर एक नज़र डाल सकते हैं जो SQL सर्वर वर्तमान में सुझाता है:
SELECT d.[object_id], s = OBJECT_SCHEMA_NAME(d.[object_id]), o = OBJECT_NAME(d.[object_id]), d.equality_columns, d.inequality_columns, d.included_columns, s.unique_compiles, s.user_seeks, s.last_user_seek, s.user_scans, s.last_user_scan INTO #candidates FROM sys.dm_db_missing_index_details AS d INNER JOIN sys.dm_db_missing_index_groups AS g ON d.index_handle = g.index_handle INNER JOIN sys.dm_db_missing_index_group_stats AS s ON g.index_group_handle = s.group_handle WHERE d.database_id = DB_ID() AND OBJECTPROPERTY(d.[object_id], 'IsMsShipped') = 0;
यह तालिका (ओं) और कॉलम (ओं) को दिखाता है जो एक सूचकांक में उपयोगी होते, कितने संकलन/तलाश/स्कैन का उपयोग किया गया होगा, और प्रत्येक संभावित सूचकांक के लिए आखिरी ऐसी घटना कब हुई थी। आप s.avg_total_user_cost . जैसे कॉलम भी शामिल कर सकते हैं और s.avg_user_impact यदि आप प्राथमिकता के लिए उन आंकड़ों का उपयोग करना चाहते हैं।
योजना संचालन
इसके बाद, आइए उन सभी योजनाओं में उपयोग किए गए कार्यों पर एक नज़र डालें, जिन्हें हमने उन ऑब्जेक्ट्स के विरुद्ध कैश किया है जिन्हें हमारे लापता इंडेक्स द्वारा पहचाना गया है।
CREATE TABLE #planops
(
o INT,
i INT,
h VARBINARY(64),
uc INT,
Scan_Ops INT,
Seek_Ops INT,
Update_Ops INT
);
DECLARE @sql NVARCHAR(MAX) = N'';
SELECT @sql += N'
UNION ALL SELECT o,i,h,uc,Scan_Ops,Seek_Ops,Update_Ops
FROM
(
SELECT o = ' + RTRIM([object_id]) + ',
i = ' + RTRIM(index_id) +',
h = pl.plan_handle,
uc = pl.usecounts,
Scan_Ops = p.query_plan.value(''count(//RelOp[@LogicalOp = ''''Index Scan'''''
+ ' or @LogicalOp = ''''Clustered Index Scan'''']/*/'
+ 'Object[@Index=''''' + QUOTENAME(name) + '''''])'', ''int''),
Seek_Ops = p.query_plan.value(''count(//RelOp[@LogicalOp = ''''Index Seek'''''
+ ' or @LogicalOp = ''''Clustered Index Seek'''']/*/'
+ 'Object[@Index=''''' + QUOTENAME(name) + '''''])'', ''int''),
Update_Ops = p.query_plan.value(''count(//Update/Object[@Index='''''
+ QUOTENAME(name) + '''''])'', ''int'')
FROM sys.dm_exec_cached_plans AS pl
CROSS APPLY sys.dm_exec_query_plan(pl.plan_handle) AS p
WHERE p.dbid = DB_ID()
AND p.query_plan IS NOT NULL
) AS x
WHERE Scan_Ops + Seek_Ops + Update_Ops > 0'
FROM sys.indexes AS i
WHERE i.index_id > 0
AND EXISTS (SELECT 1 FROM #candidates WHERE [object_id] = i.[object_id]);
SET @sql = ';WITH xmlnamespaces (DEFAULT '
+ 'N''https://schemas.microsoft.com/sqlserver/2004/07/showplan'')
' + STUFF(@sql, 1, 16, '');
INSERT #planops EXEC sp_executesql @sql; Dba.SE पर एक मित्र, Mikael Eriksson ने निम्नलिखित दो प्रश्नों का सुझाव दिया, जो एक बड़े सिस्टम पर, ऊपर दिए गए XML / UNION क्वेरी की तुलना में बहुत बेहतर प्रदर्शन करेंगे, ताकि आप पहले उनके साथ प्रयोग कर सकें। उनकी अंतिम टिप्पणी यह थी कि उन्होंने "आश्चर्यजनक रूप से नहीं पाया कि कम एक्सएमएल प्रदर्शन के लिए एक अच्छी बात है। :)" वास्तव में।
-- alternative #1
with xmlnamespaces (default 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
insert #planops
select o,i,h,uc,Scan_Ops,Seek_Ops,Update_Ops
from
(
select o = i.object_id,
i = i.index_id,
h = pl.plan_handle,
uc = pl.usecounts,
Scan_Ops = p.query_plan.value('count(//RelOp[@LogicalOp
= ("Index Scan", "Clustered Index Scan")]/*/Object[@Index = sql:column("i2.name")])', 'int'),
Seek_Ops = p.query_plan.value('count(//RelOp[@LogicalOp
= ("Index Seek", "Clustered Index Seek")]/*/Object[@Index = sql:column("i2.name")])', 'int'),
Update_Ops = p.query_plan.value('count(//Update/Object[@Index = sql:column("i2.name")])', 'int')
from sys.indexes as i
cross apply (select quotename(i.name) as name) as i2
cross apply sys.dm_exec_cached_plans as pl
cross apply sys.dm_exec_query_plan(pl.plan_handle) AS p
where exists (select 1 from #candidates as c where c.[object_id] = i.[object_id])
and p.query_plan.exist('//Object[@Index = sql:column("i2.name")]') = 1
and p.[dbid] = db_id()
and i.index_id > 0
) as T
where Scan_Ops + Seek_Ops + Update_Ops > 0;
-- alternative #2
with xmlnamespaces (default 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
insert #planops
select o = coalesce(T1.o, T2.o),
i = coalesce(T1.i, T2.i),
h = coalesce(T1.h, T2.h),
uc = coalesce(T1.uc, T2.uc),
Scan_Ops = isnull(T1.Scan_Ops, 0),
Seek_Ops = isnull(T1.Seek_Ops, 0),
Update_Ops = isnull(T2.Update_Ops, 0)
from
(
select o = i.object_id,
i = i.index_id,
h = t.plan_handle,
uc = t.usecounts,
Scan_Ops = sum(case when t.LogicalOp in ('Index Scan', 'Clustered Index Scan') then 1 else 0 end),
Seek_Ops = sum(case when t.LogicalOp in ('Index Seek', 'Clustered Index Seek') then 1 else 0 end)
from (
select
r.n.value('@LogicalOp', 'varchar(100)') as LogicalOp,
o.n.value('@Index', 'sysname') as IndexName,
pl.plan_handle,
pl.usecounts
from sys.dm_exec_cached_plans as pl
cross apply sys.dm_exec_query_plan(pl.plan_handle) AS p
cross apply p.query_plan.nodes('//RelOp') as r(n)
cross apply r.n.nodes('*/Object') as o(n)
where p.dbid = db_id()
and p.query_plan is not null
) as t
inner join sys.indexes as i
on t.IndexName = quotename(i.name)
where t.LogicalOp in ('Index Scan', 'Clustered Index Scan', 'Index Seek', 'Clustered Index Seek')
and exists (select 1 from #candidates as c where c.object_id = i.object_id)
group by i.object_id,
i.index_id,
t.plan_handle,
t.usecounts
) as T1
full outer join
(
select o = i.object_id,
i = i.index_id,
h = t.plan_handle,
uc = t.usecounts,
Update_Ops = count(*)
from (
select
o.n.value('@Index', 'sysname') as IndexName,
pl.plan_handle,
pl.usecounts
from sys.dm_exec_cached_plans as pl
cross apply sys.dm_exec_query_plan(pl.plan_handle) AS p
cross apply p.query_plan.nodes('//Update') as r(n)
cross apply r.n.nodes('Object') as o(n)
where p.dbid = db_id()
and p.query_plan is not null
) as t
inner join sys.indexes as i
on t.IndexName = quotename(i.name)
where exists
(
select 1 from #candidates as c where c.[object_id] = i.[object_id]
)
and i.index_id > 0
group by i.object_id,
i.index_id,
t.plan_handle,
t.usecounts
) as T2
on T1.o = T2.o and
T1.i = T2.i and
T1.h = T2.h and
T1.uc = T2.uc;
अब #planops . में तालिका में आपके पास plan_handle . के लिए मानों का एक समूह है ताकि आप उन वस्तुओं के खिलाफ खेल में प्रत्येक व्यक्तिगत योजना की जांच कर सकें और जांच कर सकें जिन्हें कुछ उपयोगी सूचकांक की कमी के रूप में पहचाना गया है। हम अभी इसके लिए इसका उपयोग नहीं करने जा रहे हैं, लेकिन आप इसके साथ आसानी से क्रॉस-रेफरेंस कर सकते हैं:
SELECT OBJECT_SCHEMA_NAME(po.o), OBJECT_NAME(po.o), po.uc,po.Scan_Ops,po.Seek_Ops,po.Update_Ops, p.query_plan FROM #planops AS po CROSS APPLY sys.dm_exec_query_plan(po.h) AS p;
अब आप किसी भी आउटपुट प्लान पर क्लिक करके देख सकते हैं कि वे वर्तमान में आपकी वस्तुओं के विरुद्ध क्या कर रहे हैं। ध्यान दें कि कुछ योजनाएँ दोहराई जाएंगी, क्योंकि एक योजना में एक से अधिक ऑपरेटर हो सकते हैं जो एक ही टेबल पर अलग-अलग इंडेक्स का संदर्भ देते हैं।
सूचकांक उपयोग आँकड़े
इसके बाद, आइए इंडेक्स उपयोग के आंकड़ों पर एक नज़र डालते हैं, ताकि हम देख सकें कि वर्तमान में हमारी उम्मीदवार तालिका (और, विशेष रूप से, अपडेट) के विरुद्ध कितनी वास्तविक गतिविधि चल रही है।
SELECT [object_id], index_id, user_seeks, user_scans, user_lookups, user_updates INTO #indexusage FROM sys.dm_db_index_usage_stats AS s WHERE database_id = DB_ID() AND EXISTS (SELECT 1 FROM #candidates WHERE [object_id] = s.[object_id]);
यदि कैश में बहुत कम या कोई योजना किसी विशेष इंडेक्स के लिए अपडेट नहीं दिखाती है, तो चिंतित न हों, भले ही इंडेक्स उपयोग के आंकड़े बताते हैं कि उन इंडेक्स को अपडेट किया गया है। इसका सीधा सा मतलब है कि अद्यतन योजनाएं वर्तमान में कैश में नहीं हैं, जो कई कारणों से हो सकती हैं - उदाहरण के लिए, यह एक बहुत ही पढ़ा-लिखा कार्यभार हो सकता है और वे वृद्ध हो चुके हैं, या वे सभी एकल हैं- उपयोग करें और optimize for ad hoc workloads सक्षम है।
सब को एक साथ रखना
निम्नलिखित क्वेरी आपको दिखाएगी, प्रत्येक सुझाए गए लापता इंडेक्स के लिए, एक इंडेक्स ने पढ़ने में मदद की हो सकती है, मौजूदा इंडेक्स के खिलाफ वर्तमान में कैप्चर किए गए लिखने और पढ़ने की संख्या, उनका अनुपात, संबंधित योजनाओं की संख्या वह वस्तु, और उन योजनाओं के लिए उपयोग की कुल संख्या मायने रखती है:
;WITH x AS
(
SELECT
c.[object_id],
potential_read_ops = SUM(c.user_seeks + c.user_scans),
[write_ops] = SUM(iu.user_updates),
[read_ops] = SUM(iu.user_scans + iu.user_seeks + iu.user_lookups),
[write:read ratio] = CONVERT(DECIMAL(18,2), SUM(iu.user_updates)*1.0 /
SUM(iu.user_scans + iu.user_seeks + iu.user_lookups)),
current_plan_count = po.h,
current_plan_use_count = po.uc
FROM
#candidates AS c
LEFT OUTER JOIN
#indexusage AS iu
ON c.[object_id] = iu.[object_id]
LEFT OUTER JOIN
(
SELECT o, h = COUNT(h), uc = SUM(uc)
FROM #planops GROUP BY o
) AS po
ON c.[object_id] = po.o
GROUP BY c.[object_id], po.h, po.uc
)
SELECT [object] = QUOTENAME(c.s) + '.' + QUOTENAME(c.o),
c.equality_columns,
c.inequality_columns,
c.included_columns,
x.potential_read_ops,
x.write_ops,
x.read_ops,
x.[write:read ratio],
x.current_plan_count,
x.current_plan_use_count
FROM #candidates AS c
INNER JOIN x
ON c.[object_id] = x.[object_id]
ORDER BY x.[write:read ratio];
यदि आपका लिखना:इन इंडेक्स में पढ़ने का अनुपात पहले से ही> 1 (या> 10!) है, तो मुझे लगता है कि यह एक इंडेक्स बनाने से पहले रुकने का कारण देता है जो केवल इस अनुपात को बढ़ा सकता है। potential_read_ops . की संख्या हालाँकि, दिखाया गया है कि संख्या बड़ी होने पर इसकी भरपाई हो सकती है। अगर potential_read_ops संख्या बहुत कम है, आप शायद अन्य मेट्रिक्स की जांच करने की जहमत उठाने से पहले अनुशंसा को पूरी तरह से अनदेखा करना चाहते हैं - ताकि आप एक WHERE जोड़ सकें उन सिफारिशों में से कुछ को फ़िल्टर करने के लिए खंड।
कुछ नोट्स:
- ये पढ़ने और लिखने के कार्य हैं, न कि व्यक्तिगत रूप से मापे गए 8K पृष्ठों के पढ़ने और लिखने के लिए।
- अनुपात और तुलना काफी हद तक शैक्षिक हैं; यह बहुत अच्छी तरह से मामला हो सकता है कि 10,000,000 लेखन संचालन सभी एक ही पंक्ति को प्रभावित करते हैं, जबकि 10 पढ़ने के संचालन का काफी अधिक प्रभाव हो सकता था। यह केवल एक मोटे दिशानिर्देश के रूप में है और यह मानता है कि पढ़ने और लिखने के कार्यों का भार लगभग समान है।
- आप इनमें से कुछ प्रश्नों पर मामूली भिन्नताओं का उपयोग यह पता लगाने के लिए भी कर सकते हैं - अनुपलब्ध अनुक्रमणिका के बाहर SQL सर्वर अनुशंसा कर रहा है - आपके कितने वर्तमान अनुक्रमणिका बेकार हैं। इस ऑनलाइन के बारे में बहुत सारे विचार हैं, जिसमें पॉल रान्डल (@PaulRandal) की यह पोस्ट भी शामिल है।
मुझे आशा है कि इससे आपके सिस्टम के व्यवहार में अधिक अंतर्दृष्टि प्राप्त करने के लिए कुछ विचार मिलते हैं इससे पहले कि आप एक इंडेक्स जोड़ने का निर्णय लें जिसे किसी टूल ने आपको बनाने के लिए कहा था। मैं इसे एक बड़े प्रश्न के रूप में बना सकता था, लेकिन मुझे लगता है कि अगर आप चाहें तो अलग-अलग हिस्से आपको जांच के लिए कुछ खरगोश छेद देंगे।
अन्य नोट
आप वर्तमान आकार मेट्रिक्स, तालिका की चौड़ाई, और वर्तमान पंक्तियों की संख्या (साथ ही भविष्य के विकास के बारे में किसी भी पूर्वानुमान) को पकड़ने के लिए इसे विस्तारित करना चाह सकते हैं; यह आपको एक अच्छा विचार दे सकता है कि एक नया सूचकांक कितना स्थान लेगा, जो आपके पर्यावरण के आधार पर चिंता का विषय हो सकता है। मैं भविष्य की पोस्ट में इसका इलाज कर सकता हूं।
बेशक, आपको यह ध्यान रखना होगा कि ये मेट्रिक्स केवल उतने ही उपयोगी हैं जितना कि आपका अपटाइम तय करता है। फिर से शुरू होने के बाद डीएमवी को हटा दिया जाता है (और कभी-कभी अन्य, कम विघटनकारी परिदृश्यों में), इसलिए यदि आपको लगता है कि यह जानकारी लंबे समय तक उपयोगी होगी, तो समय-समय पर स्नैपशॉट लेना कुछ ऐसा हो सकता है जिस पर आप विचार करना चाहते हैं।