अवलोकन
यह आलेख SQL तालिका (तालिकाओं) से डुप्लिकेट पंक्तियों को हटाने के लिए उपलब्ध दो अलग-अलग तरीकों पर चर्चा करता है जो अक्सर समय के साथ मुश्किल हो जाता है क्योंकि यदि यह समय पर नहीं किया जाता है तो डेटा बढ़ता है।
डुप्लिकेट पंक्तियों की उपस्थिति एक सामान्य समस्या है जिसका SQL डेवलपर्स और परीक्षकों को समय-समय पर सामना करना पड़ता है, हालाँकि, ये डुप्लिकेट पंक्तियाँ कई अलग-अलग श्रेणियों में आती हैं, जिन पर हम इस लेख में चर्चा करने जा रहे हैं।
यह आलेख एक विशिष्ट परिदृश्य पर केंद्रित है, जब डेटाबेस तालिका में डाला गया डेटा डुप्लिकेट रिकॉर्ड की शुरूआत की ओर जाता है और फिर हम डुप्लिकेट को हटाने के तरीकों पर करीब से नज़र डालेंगे और अंत में इन विधियों का उपयोग करके डुप्लिकेट को हटा देंगे।
नमूना डेटा तैयार करना
इससे पहले कि हम डुप्लिकेट को हटाने के लिए उपलब्ध विभिन्न विकल्पों की खोज शुरू करें, इस बिंदु पर एक नमूना डेटाबेस स्थापित करना सार्थक है जो हमें उन स्थितियों को समझने में मदद करेगा जब डुप्लिकेट डेटा सिस्टम में अपना रास्ता बनाता है और इसे मिटाने के लिए उपयोग किए जाने वाले दृष्टिकोण ।
नमूना डेटाबेस सेट करें (UniversityV2)
एक बहुत ही सरल डेटाबेस बनाकर प्रारंभ करें जिसमें केवल एक विद्यार्थी . हो शुरुआत में तालिका।
-- (1) Create UniversityV2 sample database
CREATE DATABASE UniversityV2;
GO
USE UniversityV2
CREATE TABLE [dbo].[Student] (
[StudentId] INT IDENTITY (1, 1) NOT NULL,
[Name] VARCHAR (30) NULL,
[Course] VARCHAR (30) NULL,
[Marks] INT NULL,
[ExamDate] DATETIME2 (7) NULL,
CONSTRAINT [PK_Student] PRIMARY KEY CLUSTERED ([StudentId] ASC)
);
छात्र तालिका भरें
आइए हम विद्यार्थी तालिका में केवल दो रिकॉर्ड जोड़ें:
-- Adding two records to the Student table
SET IDENTITY_INSERT [dbo].[Student] ON
INSERT INTO [dbo].[Student] ([StudentId], [Name], [Course], [Marks], [ExamDate]) VALUES (1, N'Asif', N'Database Management System', 80, N'2016-01-01 00:00:00')
INSERT INTO [dbo].[Student] ([StudentId], [Name], [Course], [Marks], [ExamDate]) VALUES (2, N'Peter', N'Database Management System', 85, N'2016-01-01 00:00:00')
SET IDENTITY_INSERT [dbo].[Student] OFF
डेटा जांच
वह तालिका देखें जिसमें इस समय दो अलग-अलग रिकॉर्ड हैं:
-- View Student table data
SELECT [StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
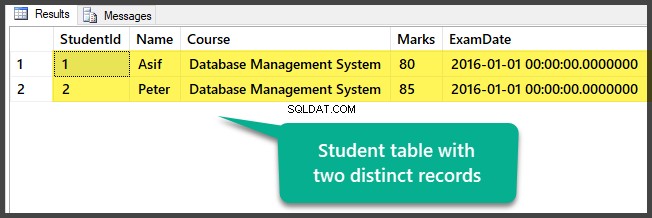
आपने एक टेबल और दो अलग (अलग-अलग) रिकॉर्ड के साथ डेटाबेस सेट करके सैंपल डेटा को सफलतापूर्वक तैयार किया है।
अब हम कुछ संभावित परिदृश्यों पर चर्चा करने जा रहे हैं जिनमें डुप्लिकेट को पेश किया गया और सरल से लेकर थोड़ी जटिल स्थितियों तक हटा दिया गया।
केस 01:डुप्लीकेट जोड़ना और हटाना
अब हम छात्र तालिका में डुप्लीकेट पंक्ति (पंक्तियों) को पेश करने जा रहे हैं।
पूर्व शर्त
इस मामले में, कहा जाता है कि तालिका में डुप्लिकेट रिकॉर्ड होते हैं यदि किसी छात्र का नाम , पाठ्यक्रम , चिह्न , और परीक्षा तिथि एक से अधिक रिकॉर्ड में मेल खाता है, भले ही विद्यार्थी की आईडी अलग है।
इसलिए, हम मानते हैं कि किसी भी दो छात्रों का नाम, पाठ्यक्रम, अंक और परीक्षा तिथि समान नहीं हो सकती है।
छात्र आसिफ के लिए डुप्लिकेट डेटा जोड़ना
आइए हम जानबूझकर विद्यार्थी:आसिफ . के लिए डुप्लिकेट रिकॉर्ड डालें विद्यार्थी . को तालिका इस प्रकार है:
-- Adding Student Asif duplicate record to the Student table
SET IDENTITY_INSERT [dbo].[Student] ON
INSERT INTO [dbo].[Student] ([StudentId], [Name], [Course], [Marks], [ExamDate]) VALUES (3, N'Asif', N'Database Management System', 80, N'2016-01-01 00:00:00')
SET IDENTITY_INSERT [dbo].[Student] OFF
डुप्लीकेट छात्र डेटा देखें
देखें विद्यार्थी डुप्लिकेट रिकॉर्ड देखने के लिए तालिका:
-- View Student table data
SELECT [StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
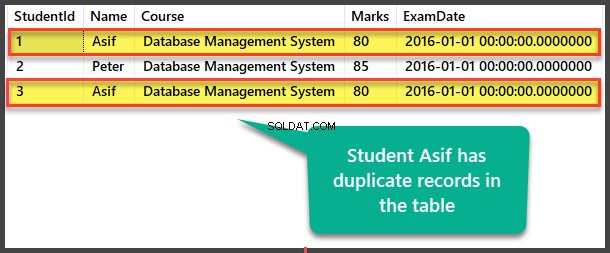
स्व-संदर्भ विधि द्वारा डुप्लिकेट ढूँढना
क्या होगा अगर इस तालिका में हजारों रिकॉर्ड हैं, तो तालिका को देखने से बहुत मदद नहीं मिलेगी।
स्व-संदर्भ विधि में, हम एक ही तालिका में दो संदर्भ लेते हैं और आईडी के अपवाद के साथ कॉलम-बाय-कॉलम मैपिंग का उपयोग करके उन्हें जोड़ते हैं जो दूसरे से कम या अधिक बनाया जाता है।
आइए हम इस तरह दिखने वाले डुप्लिकेट को खोजने के लिए सेल्फ़-रेफ़रेंसिंग विधि को देखें:
USE UniversityV2
-- Self-Referencing method to finding duplicate students having same name, course, marks, exam date
SELECT S1.[StudentId] as S1_StudentId,S2.StudentId as S2_StudentID
,S1.Name AS S1_Name, S2.Name as S2_Name
,S1.Course AS S1_Course, S2.Course as S2_Course
,S1.ExamDate as S1_ExamDate, S2.ExamDate AS S2_ExamDate
FROM [dbo].[Student] S1,[dbo].[Student] S2
WHERE S1.StudentId<S2.StudentId AND
S1.Name=S2.Name
AND
S1.Course=S2.Course
AND
S1.Marks=S2.Marks
AND
S1.ExamDate=S2.ExamDate
उपरोक्त स्क्रिप्ट का आउटपुट हमें केवल डुप्लीकेट रिकॉर्ड दिखाता है:

स्व-संदर्भ विधि-2 द्वारा डुप्लिकेट ढूँढना
स्व-संदर्भ का उपयोग करके डुप्लीकेट खोजने का दूसरा तरीका है INNER JOIN का उपयोग इस प्रकार करना:
-- Self-Referencing method 2 to find duplicate students having same name, course, marks, exam date
SELECT S1.[StudentId] as S1_StudentId,S2.StudentId as S2_StudentID
,S1.Name AS S1_Name, S2.Name as S2_Name
,S1.Course AS S1_Course, S2.Course as S2_Course
,S1.ExamDate as S1_ExamDate, S2.ExamDate AS S2_ExamDate
FROM [dbo].[Student] S1
INNER JOIN
[dbo].[Student] S2
ON S1.Name=S2.Name
AND
S1.Course=S2.Course
AND
S1.Marks=S2.Marks
AND
S1.ExamDate=S2.ExamDate
WHERE S1.StudentId<S2.StudentId

स्व-संदर्भ विधि द्वारा डुप्लिकेट निकालना
हम डुप्लिकेट को उसी विधि का उपयोग करके हटा सकते हैं जिसका उपयोग हम डुप्लिकेट को खोजने के लिए करते थे, इसके सिंटैक्स के अनुरूप DELETE का उपयोग करने के अपवाद के साथ:
USE UniversityV2
-- Removing duplicates by using Self-Referencing method
DELETE S2
FROM [dbo].[Student] S1,
[dbo].[Student] S2
WHERE S1.StudentId < S2.StudentId
AND S1.Name = S2.Name
AND S1.Course = S2.Course
AND S1.Marks = S2.Marks
AND S1.ExamDate = S2.ExamDate
डुप्लिकेट हटाने के बाद डेटा जांच
डुप्लीकेट हटाने के बाद हम जल्दी से रिकॉर्ड की जांच करें:
USE UniversityV2
-- View Student data after duplicates have been removed
SELECT
[StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
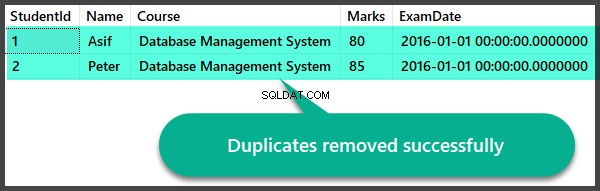
डुप्लीकेट बनाना देखें और डुप्लिकेट्स को संग्रहित प्रक्रिया निकालें
अब जब हम जानते हैं कि हमारी स्क्रिप्ट SQL में डुप्लिकेट पंक्तियों को सफलतापूर्वक ढूंढ और हटा सकती हैं, तो बेहतर होगा कि उपयोग में आसानी के लिए उन्हें देखने और संग्रहीत प्रक्रिया में बदल दिया जाए:
USE UniversityV2;
GO
-- Creating view find duplicate students having same name, course, marks, exam date using Self-Referencing method
CREATE VIEW dbo.Duplicates
AS
SELECT
S1.[StudentId] AS S1_StudentId
,S2.StudentId AS S2_StudentID
,S1.Name AS S1_Name
,S2.Name AS S2_Name
,S1.Course AS S1_Course
,S2.Course AS S2_Course
,S1.ExamDate AS S1_ExamDate
,S2.ExamDate AS S2_ExamDate
FROM [dbo].[Student] S1
,[dbo].[Student] S2
WHERE S1.StudentId < S2.StudentId
AND S1.Name = S2.Name
AND S1.Course = S2.Course
AND S1.Marks = S2.Marks
AND S1.ExamDate = S2.ExamDate
GO
-- Creating stored procedure to removing duplicates by using Self-Referencing method
CREATE PROCEDURE UspRemoveDuplicates
AS
BEGIN
DELETE S2
FROM [dbo].[Student] S1,
[dbo].[Student] S2
WHERE S1.StudentId < S2.StudentId
AND S1.Name = S2.Name
AND S1.Course = S2.Course
AND S1.Marks = S2.Marks
AND S1.ExamDate = S2.ExamDate
END
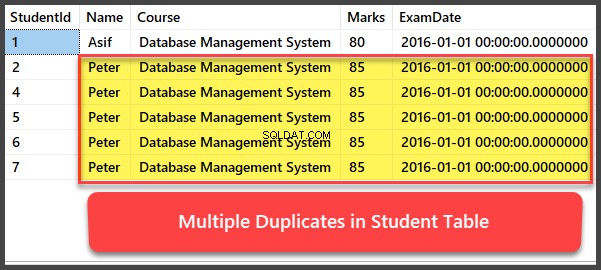
एकाधिक डुप्लिकेट रिकॉर्ड जोड़ना और देखना
आइए अब विद्यार्थी . में चार और रिकॉर्ड जोड़ें तालिका और सभी रिकॉर्ड इस तरह से डुप्लीकेट हैं कि उनका नाम, पाठ्यक्रम, अंक और परीक्षा तिथि समान है:
--Adding multiple duplicates to Student table
INSERT INTO Student (Name,
Course,
Marks,
ExamDate)
VALUES ('Peter', 'Database Management System', 85, '2016-01-01'),
('Peter', 'Database Management System', 85, '2016-01-01'),
('Peter', 'Database Management System', 85, '2016-01-01'),
('Peter', 'Database Management System', 85, '2016-01-01');
-- Viewing Student table after multiple records have been added to Student table
SELECT
[StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
UspRemoveDuplicates प्रक्रिया का उपयोग करके डुप्लिकेट निकालना
USE UniversityV2
-- Removing multiple duplicates
EXEC UspRemoveDuplicates
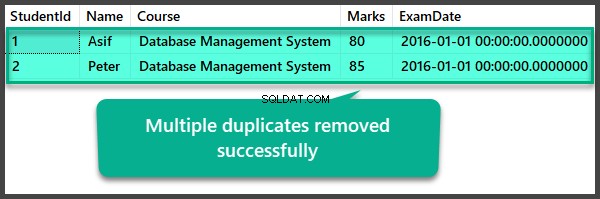
एकाधिक डुप्लिकेट को हटाने के बाद डेटा जांच
USE UniversityV2
--View Student table after multiple duplicates removal
SELECT
[StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
केस 02:समान आईडी वाले डुप्लीकेट जोड़ना और हटाना
अब तक, हमने अलग-अलग आईडी वाले डुप्लीकेट रिकॉर्ड की पहचान की है, लेकिन अगर आईडी समान हैं तो क्या होगा।
उदाहरण के लिए, उस परिदृश्य के बारे में सोचें जिसमें हाल ही में किसी टेक्स्ट या एक्सेल फ़ाइल से कोई तालिका आयात की गई है जिसमें कोई प्राथमिक कुंजी नहीं है।
पूर्व शर्त
इस मामले में, एक तालिका को डुप्लिकेट रिकॉर्ड कहा जाता है यदि सभी कॉलम मान कुछ आईडी कॉलम सहित बिल्कुल समान हैं और प्राथमिक कुंजी गुम है जिससे डुप्लिकेट रिकॉर्ड दर्ज करना आसान हो गया है।
प्राथमिक कुंजी के बिना पाठ्यक्रम तालिका बनाएं
उस परिदृश्य को पुन:उत्पन्न करने के लिए जिसमें प्राथमिक कुंजी की अनुपस्थिति में डुप्लिकेट रिकॉर्ड तालिका में आते हैं, आइए पहले हम एक नया पाठ्यक्रम बनाएं। University2 डेटाबेस में बिना किसी प्राथमिक कुंजी के तालिका निम्नानुसार है:
USE UniversityV2
-- Creating Course table without primary key
CREATE TABLE [dbo].[Course] (
[CourseId] INT NOT NULL,
[Name] VARCHAR (30) NOT NULL,
[Detail] VARCHAR (200) NULL,
);
पाठ्यक्रम तालिका तैयार करें
-- Populating Course table
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail]) VALUES (1, N'T-SQL Programming', N'About T-SQL Programming')
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail]) VALUES (2, N'Tabular Data Modeling', N'This is about Tabular Data Modeling')
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail]) VALUES (3, N'Analysis Services Fundamentals', N'This is about Analysis Services Fundamentals')
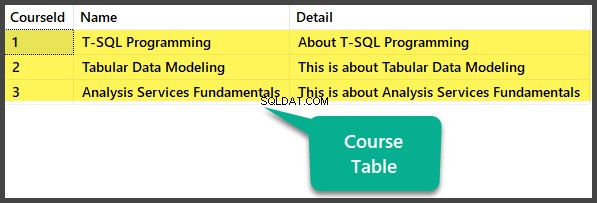
डेटा जांच
देखें पाठ्यक्रम तालिका:
USE UniversityV2
-- Viewing Course table
SELECT CourseId
,Name
,Detail FROM dbo.Course
पाठ्यक्रम तालिका में डुप्लिकेट डेटा जोड़ना
अब डुप्लीकेट को पाठ्यक्रम . में डालें तालिका:
USE UniversityV2
-- Inserting duplicate records in Course table
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail])
VALUES (1, N'T-SQL Programming', N'About T-SQL Programming')
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail])
VALUES (1, N'T-SQL Programming', N'About T-SQL Programming')
डुप्लिकेट कोर्स डेटा देखें
तालिका देखने के लिए सभी स्तंभों का चयन करें:
USE UniversityV2
-- Viewing duplicate data in Course table
SELECT CourseId
,Name
,Detail FROM dbo.Course

एग्रीगेट विधि द्वारा डुप्लीकेट ढूँढना
हम कुल गणना (*) फ़ंक्शन का उपयोग करके सभी पंक्तियों को गिनने के साथ-साथ सभी स्तंभों का चयन करने के बाद सभी स्तंभों को एक से अधिक के साथ समूहीकृत करके समग्र विधि का उपयोग करके सटीक डुप्लिकेट प्राप्त कर सकते हैं:
-- Finding duplicates using Aggregate method
SELECT <column1>,<column2>,<column3>…
,COUNT(*) AS Total_Records
FROM <Table>
GROUP BY <column1>,<column2>,<column3>…
HAVING COUNT(*)>1
इसे निम्नानुसार लागू किया जा सकता है:
USE UniversityV2
-- Finding duplicates using Aggregate method
SELECT
c.CourseId
,c.Name
,c.Detail
,COUNT(*) AS Duplicate_Records
FROM dbo.Course c
GROUP BY c.CourseId
,c.Name
,c.Detail
HAVING COUNT(*) > 1
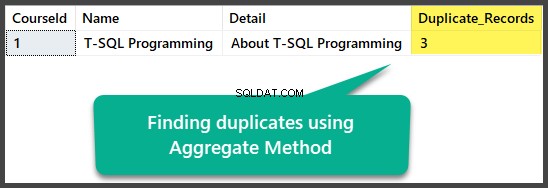
कुल विधि द्वारा डुप्लिकेट निकालना
आइए हम इस प्रकार समग्र विधि का उपयोग करके डुप्लिकेट को हटा दें:
USE UniversityV2
-- Removing duplicates using Aggregate method
-- (1) Finding duplicates and put them into a new table (CourseNew) as a single row
SELECT
c.CourseId
,c.Name
,c.Detail
,COUNT(*) AS Duplicate_Records INTO CourseNew
FROM dbo.Course c
GROUP BY c.CourseId
,c.Name
,c.Detail
HAVING COUNT(*) > 1
-- (2) Rename Course (which contains duplicates) as Course_OLD
EXEC sys.sp_rename @objname = N'Course'
,@newname = N'Course_OLD'
-- (3) Rename CourseNew (which contains no duplicates) as Course
EXEC sys.sp_rename @objname = N'CourseNew'
,@newname = N'Course'
-- (4) Insert original distinct records into Course table from Course_OLD table
INSERT INTO Course (CourseId, Name, Detail)
SELECT
co.CourseId
,co.Name
,co.Detail
FROM Course_OLD co
WHERE co.CourseId <> (SELECT
c.CourseId
FROM Course c)
ORDER BY CO.CourseId
-- (4) Data check
SELECT
cn.CourseId
,cn.Name
,cn.Detail
FROM Course cn
-- Clean up
-- (5) You can drop the Course_OLD table afterwards
-- (6) You can remove Duplicate_Records column from Course table afterwards
डेटा जांच
विश्वविद्यालय का उपयोग करेंV2
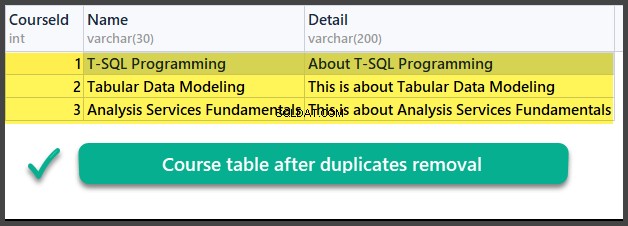
इसलिए, हमने सफलतापूर्वक सीखा है कि दो अलग-अलग परिदृश्यों के आधार पर दो अलग-अलग तरीकों का उपयोग करके डेटाबेस तालिका से डुप्लिकेट को कैसे हटाया जाए।
करने के लिए चीज़ें
अब आप डेटाबेस तालिका को आसानी से पहचान सकते हैं और डुप्लिकेट मान से मुक्त कर सकते हैं।
1. UspRemoveDuplicatesByAggregate . बनाने का प्रयास करें ऊपर वर्णित विधि के आधार पर संग्रहीत कार्यविधि और संग्रहीत कार्यविधि को कॉल करके डुप्लिकेट निकालें
2. ऊपर बनाई गई संग्रहीत प्रक्रिया को संशोधित करने का प्रयास करें (UspRemoveDuplicatesByAggregates) और इस आलेख में उल्लिखित क्लीन अप युक्तियों को लागू करें।
DROP TABLE CourseNew
-- (5) You can drop the Course_OLD table afterwards
-- (6) You can remove Duplicate_Records column from Course table afterwards
3. क्या आप सुनिश्चित हो सकते हैं कि UspRemoveDuplicatesByAggregate डुप्लिकेट को हटाने के बाद भी संग्रहीत प्रक्रिया को जितनी बार संभव हो निष्पादित किया जा सकता है, यह दिखाने के लिए कि प्रक्रिया पहले स्थान पर बनी हुई है?
4. कृपया मेरा पिछला लेख जंप टू स्टार्ट टेस्ट-ड्रिवेन डेटाबेस डेवलपमेंट (टीडीडीडी) - भाग 1 देखें और SQLDevBlog डेटाबेस टेबल में डुप्लिकेट डालने का प्रयास करें, उसके बाद इस टिप में उल्लिखित दोनों विधियों का उपयोग करके डुप्लिकेट को हटाने का प्रयास करें।
5. कृपया एक और नमूना डेटाबेस बनाने का प्रयास करें कर्मचारियों का नमूना मेरे पिछले लेख आर्ट ऑफ़ आइसोलेटिंग डिपेंडेंसीज़ एंड डेटा इन डेटाबेस यूनिट टेस्टिंग का जिक्र करते हुए और टेबल में डुप्लिकेट डालें और इस टिप से सीखी गई दोनों विधियों का उपयोग करके उन्हें हटाने का प्रयास करें।
उपयोगी टूल:
SQL सर्वर के लिए dbForge डेटा तुलना - बड़े डेटा के साथ काम करने में सक्षम शक्तिशाली SQL तुलना उपकरण।