परिचय
डेटाबेस सर्किलों में यह सामान्य ज्ञान है कि इंडेक्स या तो आवश्यक परिणाम सेट को पूरी तरह से संतुष्ट करके (इंडेक्स को कवर करना) या लुकअप के रूप में कार्य करके क्वेरी प्रदर्शन में सुधार करता है जो आसानी से क्वेरी इंजन को आवश्यक डेटा सेट के सटीक स्थान पर निर्देशित करता है। हालांकि, जैसा कि अनुभवी डीबीए जानते हैं, किसी को भी काम के बोझ की प्रकृति को समझे बिना ओएलटीपी वातावरण में इंडेक्स बनाने के बारे में बहुत उत्साहित नहीं होना चाहिए। SQL सर्वर 2019 इंस्टेंस में क्वेरी स्टोर का उपयोग करना (क्वेरी स्टोर SQL सर्वर 2016 में पेश किया गया था), इंसर्ट पर इंडेक्स के प्रभाव को दिखाना काफी आसान है।
सूचकांक के बिना सम्मिलित करें
हम WideWorldImporters नमूना डेटाबेस को पुनर्स्थापित करके और फिर बिक्री की एक प्रति बनाकर शुरू करते हैं। लिस्टिंग 1 में स्क्रिप्ट का उपयोग कर चालान तालिका। ध्यान दें कि नमूना डेटाबेस में क्वेरी स्टोर पहले से ही रीड-राइट मोड में सक्षम है।
-- Listing 1 Make a Copy Of Invoices SELECT * INTO [SALES].[INVOICES1] FROM [SALES].[INVOICES] WHERE 1=2;
ध्यान दें कि हमारे द्वारा अभी बनाई गई तालिका में कोई अनुक्रमणिका नहीं है। हमारे पास टेबल संरचना है। एक बार हो जाने के बाद, हम नई तालिका में उसके पैरेंट के डेटा का उपयोग करके प्रविष्टि करते हैं जैसा कि लिस्टिंग 2 में दिखाया गया है।
-- Listing 2 Populate Invoices1 -- TRUNCATE TABLE [SALES].[INVOICES1] INSERT INTO [SALES].[INVOICES1] SELECT * FROM [SALES].[INVOICES]; GO 100
इस ऑपरेशन के दौरान, क्वेरी स्टोर क्वेरी की निष्पादन योजना को कैप्चर करता है। चित्र 1 संक्षेप में दिखाता है कि हुड के नीचे क्या हो रहा है। बाएं से दाएं पढ़ने पर, हम देखते हैं कि SQL सर्वर प्लान आईडी 563 का उपयोग करके इन्सर्ट को निष्पादित करता है - डेटा लाने के लिए सोर्स टेबल की प्राइमरी की पर एक इंडेक्स स्कैन और फिर डेस्टिनेशन टेबल पर एक टेबल इंसर्ट। (बाएं से दाएं पढ़ना)। ध्यान दें कि इस मामले में, लागत का बड़ा हिस्सा टेबल इंसर्ट पर है - 99% क्वेरी लागत का।
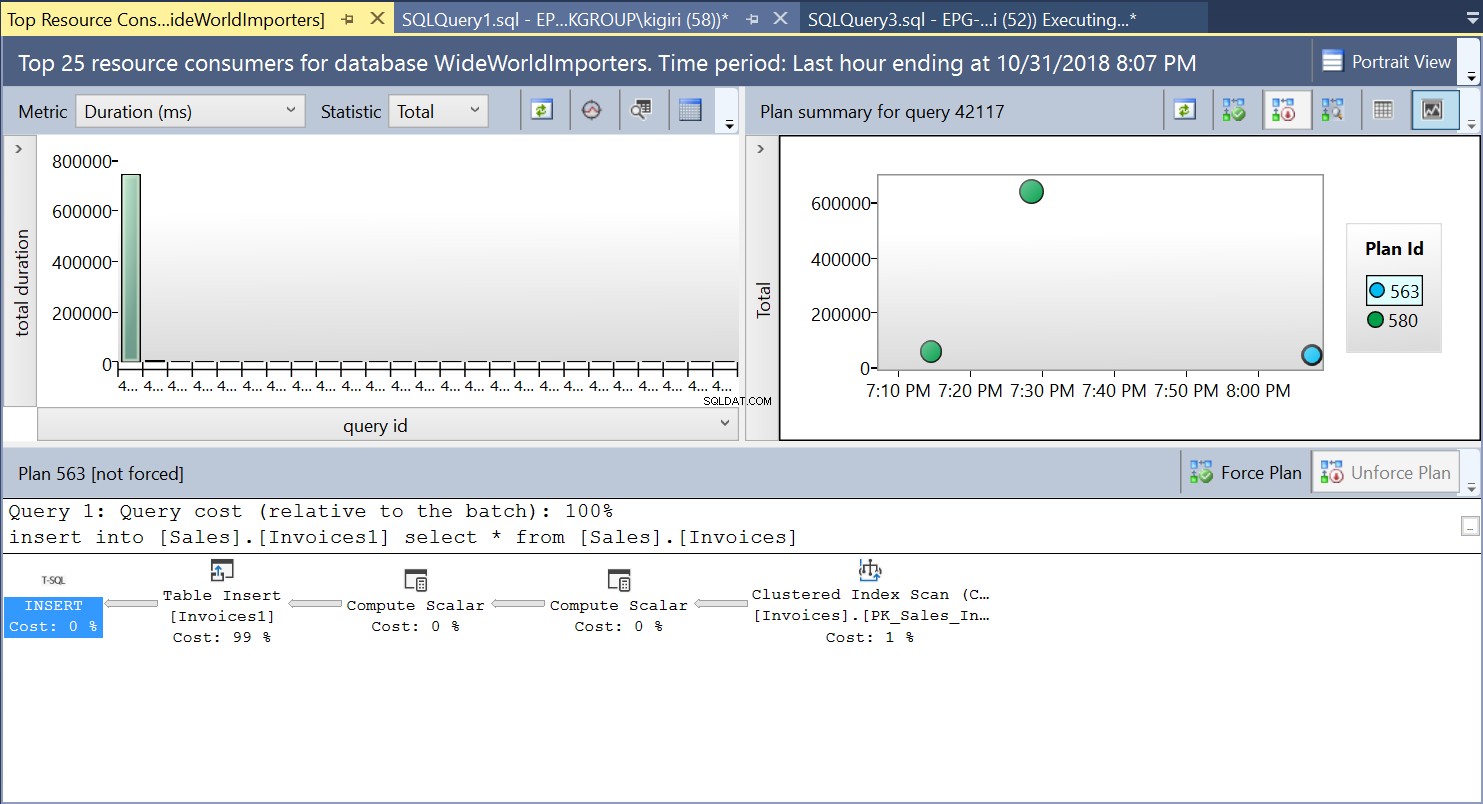
चित्र 1 निष्पादन योजना 563
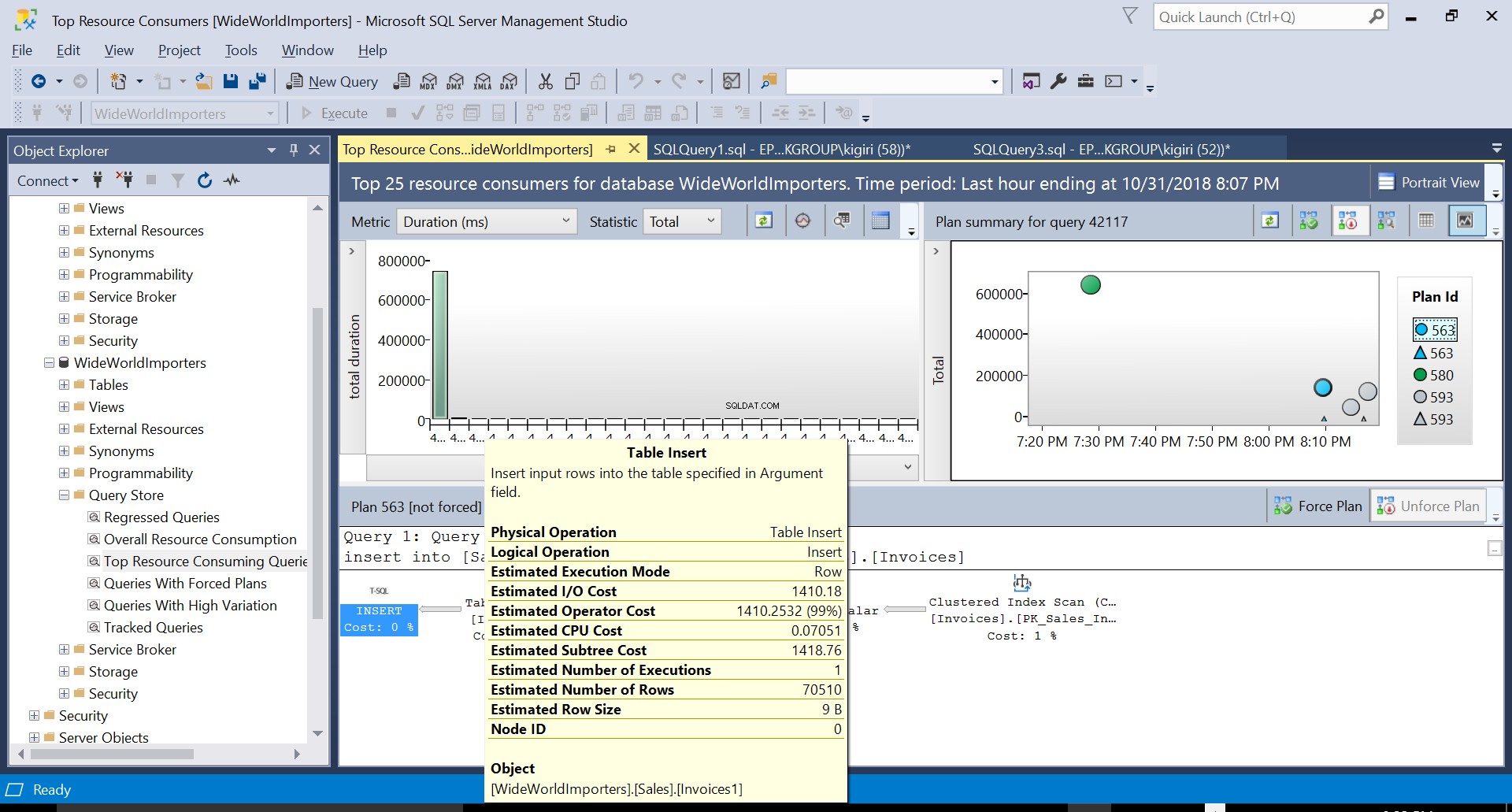
चित्र 2 गंतव्य पर तालिका सम्मिलित करें
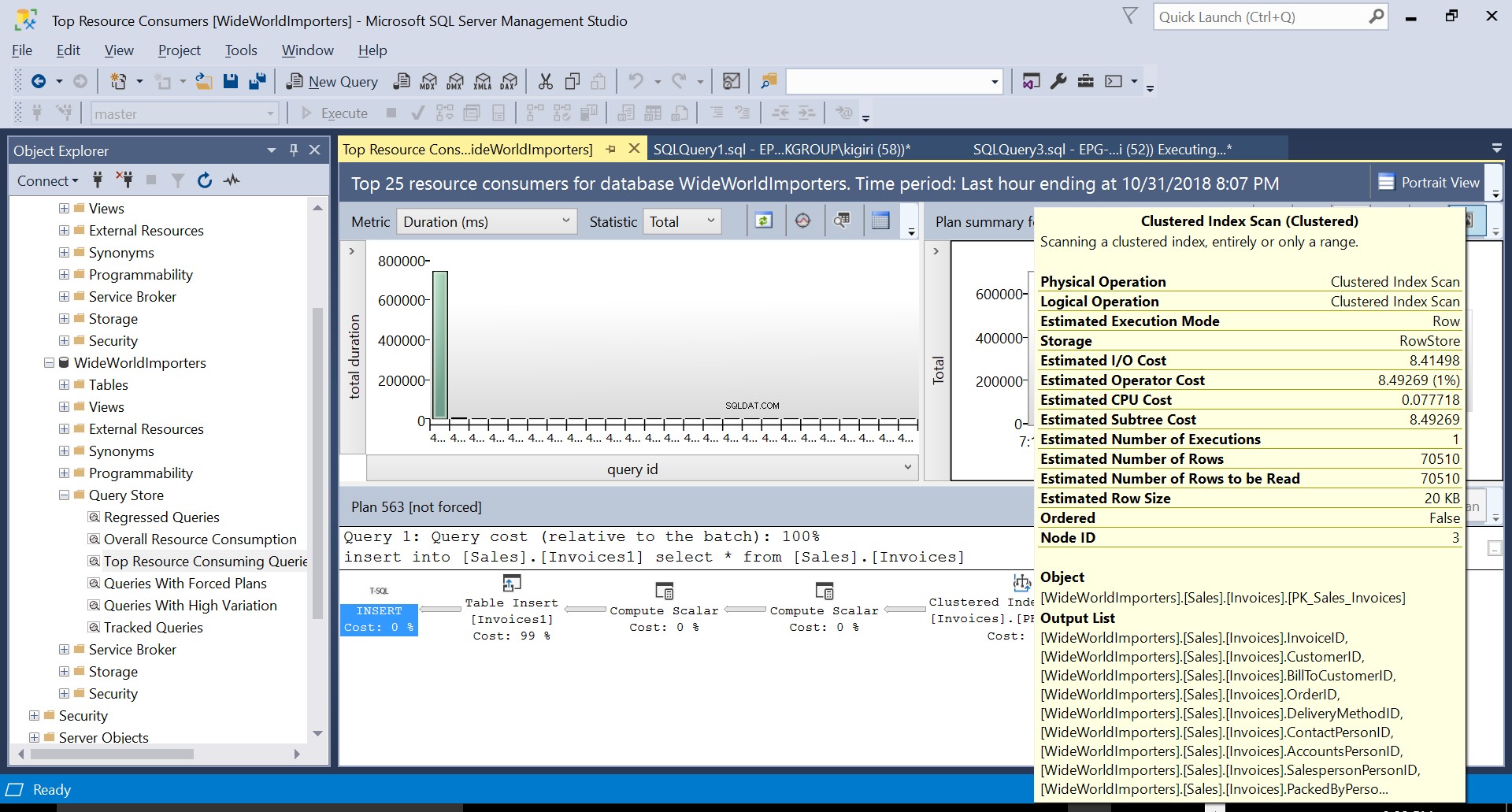
अंजीर। 3 स्रोत तालिका पर क्लस्टर्ड इंडेक्स स्कैन
अनुक्रमणिका के साथ सम्मिलित करें
फिर हम लिस्टिंग 3 में डीडीएल का उपयोग करके गंतव्य तालिका पर एक इंडेक्स बनाते हैं। जब हम गंतव्य तालिका को छोटा करने के बाद लिस्टिंग 2 में कथन दोहराते हैं, तो हम थोड़ा अलग निष्पादन योजना देखते हैं (चित्र 4 में दिखाया गया प्लान आईडी 593)। हम अभी भी टेबल इंसर्ट देखते हैं लेकिन यह केवल 58% का योगदान देता है क्वेरी की लागत के लिए। निष्पादन की गतिशीलता एक प्रकार की शुरूआत और एक इंडेक्स इंसर्ट के साथ थोड़ी तिरछी हो जाती है। अनिवार्य रूप से जो हो रहा है वह यह है कि SQL सर्वर को अनुक्रमणिका पर संबंधित पंक्तियों को प्रस्तुत करना चाहिए क्योंकि तालिका में नए रिकॉर्ड पेश किए जाते हैं।
-- LISTING 3 Create Index on Destination Table CREATE NONCLUSTERED INDEX [IX_Sales_Invoices_ConfirmedDeliveryTime] ON [Sales].[Invoices1] ( [ConfirmedDeliveryTime] ASC ) INCLUDE ( [ConfirmedReceivedBy]) WITH (PAD_INDEX = OFF , STATISTICS_NORECOMPUTE = OFF , SORT_IN_TEMPDB = OFF , DROP_EXISTING = OFF , ONLINE = OFF , ALLOW_ROW_LOCKS = ON , ALLOW_PAGE_LOCKS = ON) ON [USERDATA] GO
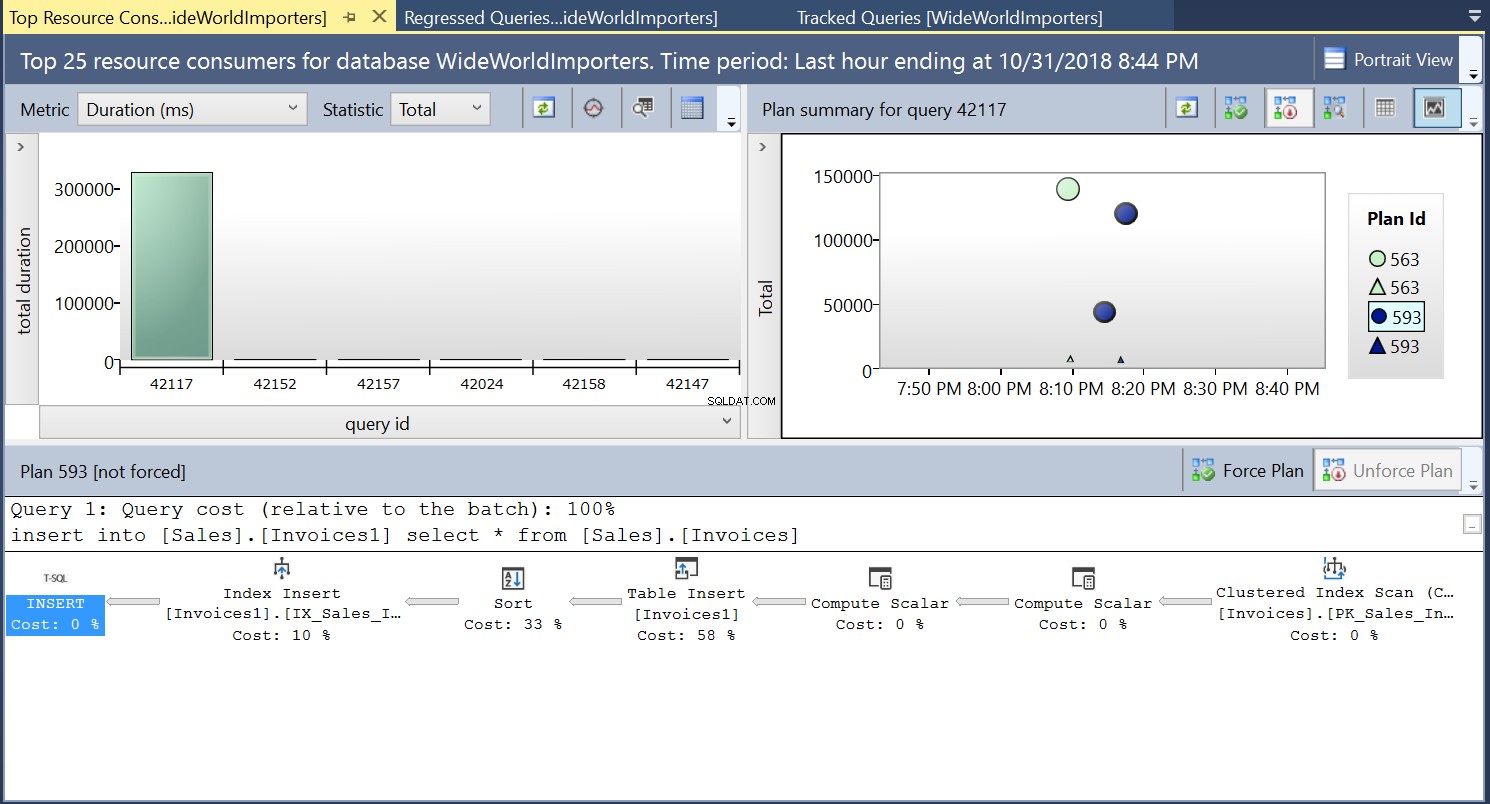
चित्र 4 निष्पादन योजना 593
और गहराई से देख रहे हैं
हम दोनों योजनाओं के विवरण की जांच कर सकते हैं और देख सकते हैं कि ये नए कारक कथन के निष्पादन समय को कैसे बढ़ाते हैं। योजना 593 विवरण की औसत अवधि में अतिरिक्त 300ms या तो जोड़ता है। उत्पादन वातावरण में भारी कार्यभार के तहत, यह अंतर महत्वपूर्ण हो सकता है।
दोनों मामलों में सिर्फ एक बार इंसर्ट स्टेटमेंट को निष्पादित करते समय सांख्यिकी IO को चालू करना - गंतव्य तालिका पर अनुक्रमणिका के साथ और गंतव्य तालिका पर अनुक्रमणिका के बिना - यह भी दर्शाता है कि अनुक्रमणिका के साथ तालिका में पंक्तियों को सम्मिलित करते समय तार्किक IO के संदर्भ में अधिक कार्य किया जाता है।
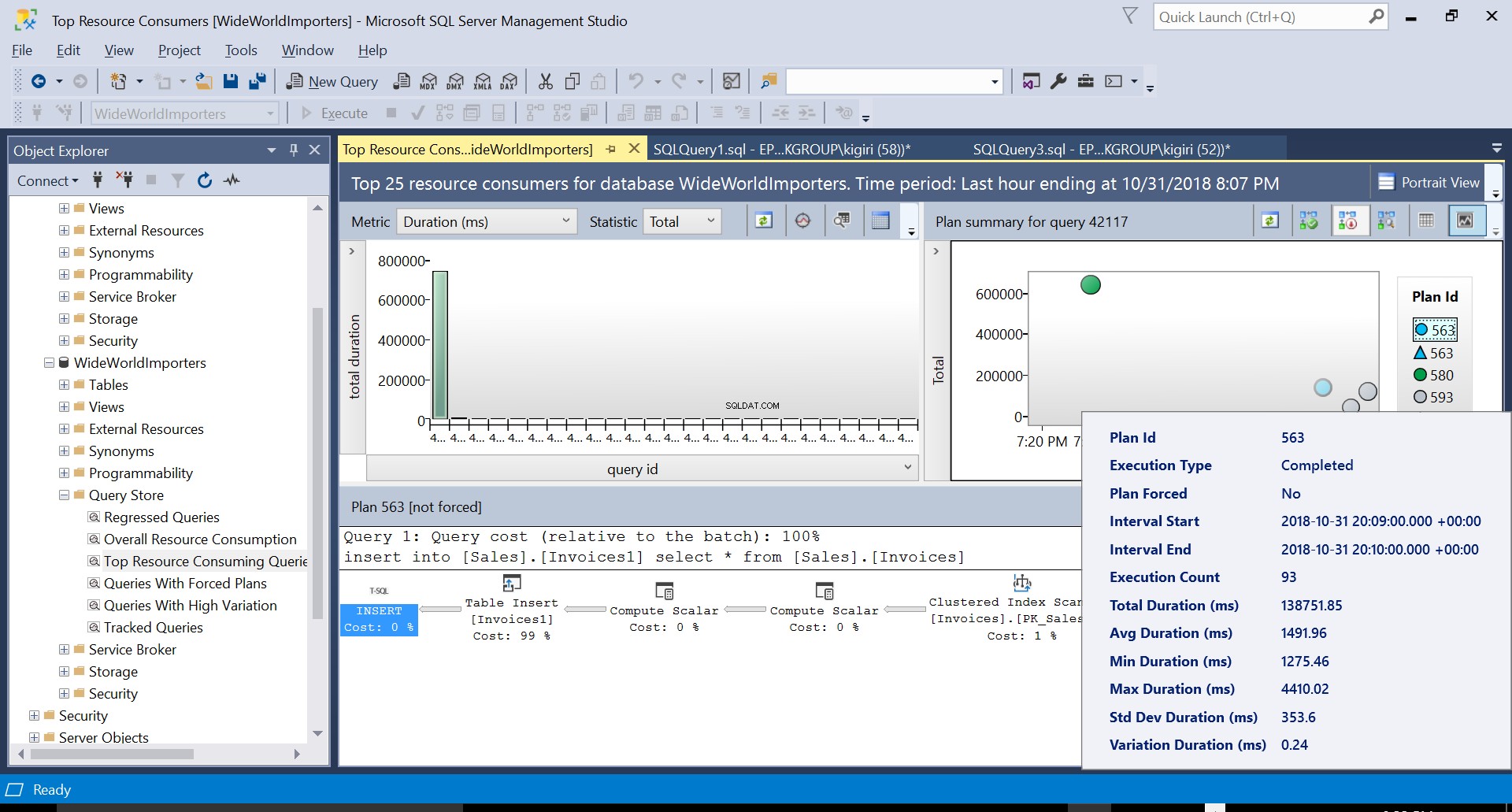
चित्र 5 निष्पादन योजना 563 का विवरण
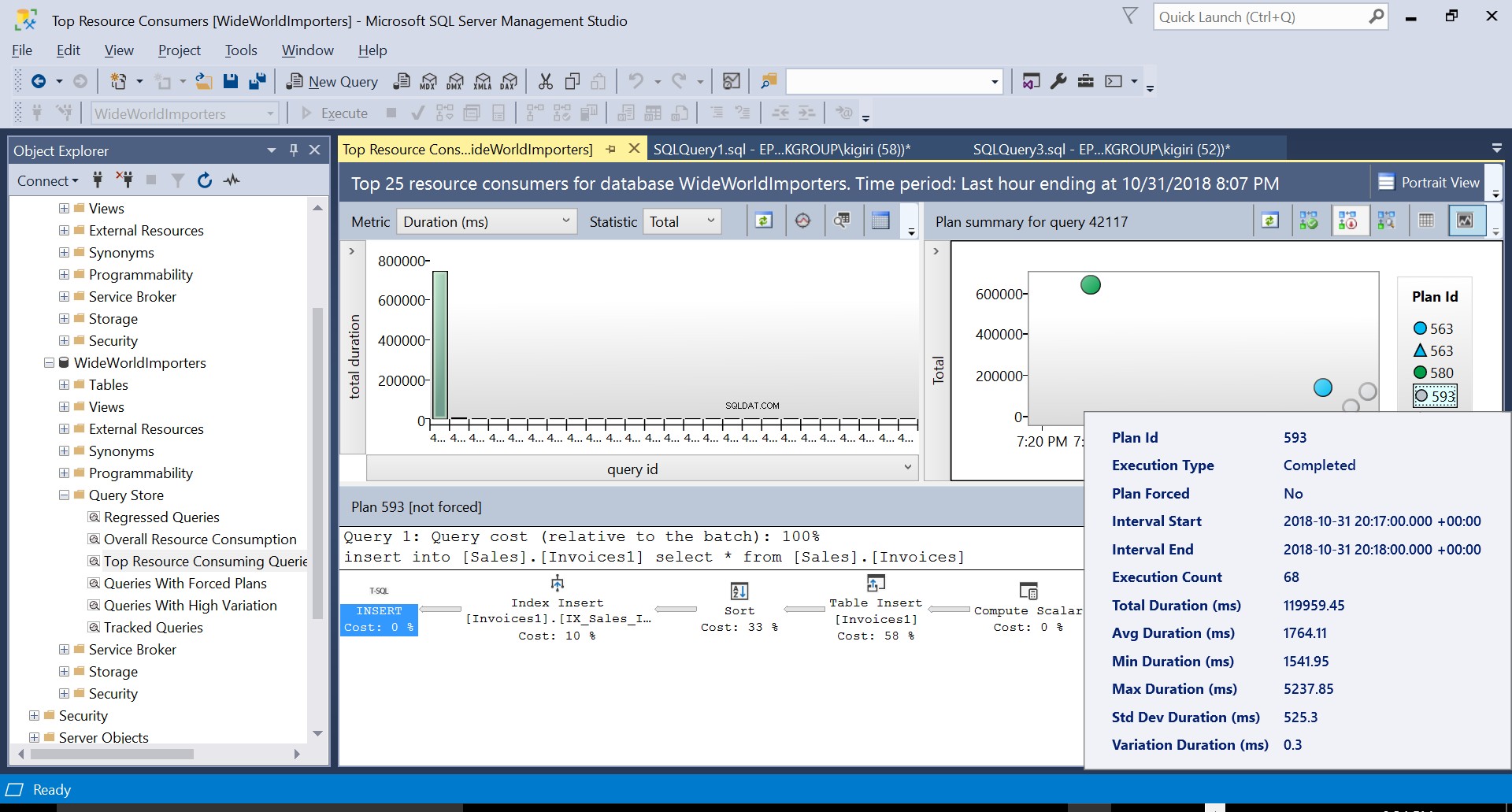
चित्र 4 निष्पादन योजना 593 का विवरण
कोई अनुक्रमणिका नहीं:सांख्यिकी IO के साथ आउटपुट चालू:
तालिका 'चालान1'। स्कैन काउंट 0, लॉजिकल रीड्स 78372 , फिजिकल रीड्स 0, रीड-फॉरवर्ड रीड्स 0, लोब लॉजिकल रीड्स 0, लोब फिजिकल रीड्स 0, लोब रीड-फॉरवर्ड रीड्स 0.
तालिका 'चालान'। स्कैन गिनती 1, तार्किक 11400 पढ़ता है, फिजिकल रीड्स 0, रीड-फॉरवर्ड रीड्स 0, लोब लॉजिकल रीड्स 0, लोब फिजिकल रीड्स 0, लोब रीड-फॉरवर्ड रीड्स 0.
(70510 पंक्तियाँ प्रभावित)
सूचकांक:सांख्यिकी IO के साथ आउटपुट चालू:
तालिका 'चालान1'। स्कैन गिनती 0, तार्किक 81119 पढ़ता है , फिजिकल रीड्स 0, रीड-फॉरवर्ड रीड्स 0, लोब लॉजिकल रीड्स 0, लोब फिजिकल रीड्स 0, लोब रीड-फॉरवर्ड रीड्स 0.
तालिका 'कार्यस्थल'। स्कैन काउंट 0, लॉजिकल रीड्स 0, फिजिकल रीड्स 0, रीड-फॉरवर्ड रीड्स 0, लोब लॉजिकल रीड्स 0, लोब फिजिकल रीड्स 0, लोब रीड-फॉरवर्ड रीड्स 0।
तालिका 'चालान'। स्कैन गिनती 1, तार्किक 11400 पढ़ता है , फिजिकल रीड्स 0, रीड-फॉरवर्ड रीड्स 0, लोब लॉजिकल रीड्स 0, लोब फिजिकल रीड्स 0, लोब रीड-फॉरवर्ड रीड्स 0.
(70510 पंक्तियाँ प्रभावित)
अतिरिक्त जानकारी
Microsoft और अन्य स्रोत अनुक्रमणिका उत्पादन परिवेश की जांच करने और ऐसी स्थितियों की पहचान करने के लिए स्क्रिप्ट प्रदान करते हैं जैसे:
- अनावश्यक अनुक्रमणिका - अनुक्रमित जो दोहराए गए हैं
- अनुक्रमणिका अनुपलब्ध - इंडेक्स जो कार्यभार के आधार पर प्रदर्शन में सुधार कर सकते हैं
- ढेर - बिना संकुल अनुक्रमणिका वाली तालिकाएँ
- अति-अनुक्रमित तालिकाएं - स्तंभों की तुलना में अधिक अनुक्रमणिका वाली तालिकाएँ
- सूचकांक उपयोग - अनुक्रमित पर खोज, स्कैन और खोज की संख्या
आइटम 2, 3, और 5 पढ़ने के संबंध में प्रदर्शन प्रभाव से अधिक संबंधित हैं, जबकि आइटम 1 और 4 लेखन के संबंध में प्रदर्शन प्रभाव से संबंधित हैं। लिस्टिंग 4 और 5 इन सार्वजनिक रूप से उपलब्ध प्रश्नों के दो उदाहरण हैं।
-- LISTING 4 Check Redundant Indexes
;WITH INDEXCOLUMNS AS(
SELECT DISTINCT
SCHEMA_NAME (O.SCHEMA_ID) AS 'SCHEMANAME'
, OBJECT_NAME(O.OBJECT_ID) AS TABLENAME
,I.NAME AS INDEXNAME, O.OBJECT_ID,I.INDEX_ID,I.TYPE
,(SELECT CASE KEY_ORDINAL WHEN 0 THEN NULL ELSE '['+COL_NAME(K.OBJECT_ID,COLUMN_ID) +']' END AS [DATA()]
FROM SYS.INDEX_COLUMNS AS K WHERE K.OBJECT_ID = I.OBJECT_ID AND K.INDEX_ID = I.INDEX_ID
ORDER BY KEY_ORDINAL, COLUMN_ID FOR XML PATH('')) AS COLS
FROM SYS.INDEXES AS I INNER JOIN SYS.OBJECTS O ON I.OBJECT_ID =O.OBJECT_ID
INNER JOIN SYS.INDEX_COLUMNS IC ON IC.OBJECT_ID =I.OBJECT_ID AND IC.INDEX_ID =I.INDEX_ID
INNER JOIN SYS.COLUMNS C ON C.OBJECT_ID = IC.OBJECT_ID AND C.COLUMN_ID = IC.COLUMN_ID
WHERE I.OBJECT_ID IN (SELECT OBJECT_ID FROM SYS.OBJECTS WHERE TYPE ='U') AND I.INDEX_ID <>0 AND I.TYPE <>3 AND I.TYPE <>6
GROUP BY O.SCHEMA_ID,O.OBJECT_ID,I.OBJECT_ID,I.NAME,I.INDEX_ID,I.TYPE
)
SELECT
IC1.SCHEMANAME,IC1.TABLENAME,IC1.INDEXNAME,IC1.COLS AS INDEXCOLS,IC2.INDEXNAME AS REDUNDANTINDEXNAME, IC2.COLS AS REDUNDANTINDEXCOLS
FROM INDEXCOLUMNS IC1
JOIN INDEXCOLUMNS IC2 ON IC1.OBJECT_ID = IC2.OBJECT_ID
AND IC1.INDEX_ID <> IC2.INDEX_ID
AND IC1.COLS <> IC2.COLS
AND IC2.COLS LIKE REPLACE(IC1.COLS,'[','[[]') + ' %'
ORDER BY 1,2,3,5;
-- LISTING 5 Check Indexes Usage
SELECT O.NAME AS TABLE_NAME
, I.NAME AS INDEX_NAME
, S.USER_SEEKS
, S.USER_SCANS
, S.USER_LOOKUPS
, S.USER_UPDATES
FROM SYS.DM_DB_INDEX_USAGE_STATS S
INNER JOIN SYS.INDEXES I
ON I.INDEX_ID=S.INDEX_ID
AND S.OBJECT_ID = I.OBJECT_ID
INNER JOIN SYS.OBJECTS O
ON S.OBJECT_ID = O.OBJECT_ID
INNER JOIN SYS.SCHEMAS C
ON O.SCHEMA_ID = C.SCHEMA_ID;
निष्कर्ष
हमने क्वेरी स्टोर का उपयोग करके दिखाया है कि एक इंडेक्स के साथ अतिरिक्त कार्यभार एक नमूना सम्मिलन विवरण की निष्पादन योजना में पेश कर सकता है। उत्पादन में, अत्यधिक और अनावश्यक अनुक्रमणिका प्रदर्शन पर नकारात्मक प्रभाव डाल सकते हैं, विशेष रूप से OLTP वर्कलोड के लिए बनाए गए डेटाबेस में। इंडेक्स की जांच करने और यह निर्धारित करने के लिए कि क्या वे वास्तव में मदद कर रहे हैं या प्रदर्शन को नुकसान पहुंचा रहे हैं, उपलब्ध स्क्रिप्ट और टूल का उपयोग करना महत्वपूर्ण है।
उपयोगी टूल:
डीबीफोर्ज इंडेक्स मैनेजर - एसक्यूएल इंडेक्स की स्थिति का विश्लेषण करने और इंडेक्स विखंडन के साथ मुद्दों को ठीक करने के लिए आसान एसएसएमएस ऐड-इन।