परिचय
- कुछ विशिष्ट नियम हैं जिनका डेटाबेस ऑब्जेक्ट बनाते समय पालन करने की आवश्यकता होती है। एक डेटाबेस के प्रदर्शन को बेहतर बनाने के लिए, एक प्राथमिक कुंजी, क्लस्टर्ड और गैर-क्लस्टर इंडेक्स, और बाधाओं को एक टेबल पर असाइन किया जाना चाहिए। हालांकि हम इन सभी नियमों का पालन करते हैं, फिर भी तालिका में डुप्लिकेट पंक्तियां हो सकती हैं।
- डेटाबेस कुंजियों का उपयोग करना हमेशा एक अच्छा अभ्यास है। डेटाबेस कुंजियों का उपयोग करने से तालिका में डुप्लिकेट रिकॉर्ड प्राप्त करने की संभावना कम हो जाएगी। लेकिन यदि किसी तालिका में डुप्लिकेट रिकॉर्ड पहले से मौजूद हैं, तो ऐसे विशिष्ट तरीके हैं जिनका उपयोग इन डुप्लिकेट रिकॉर्ड को निकालने के लिए किया जाता है।
डुप्लिकेट पंक्तियों को हटाने के तरीके
- ज्वाइन हटाएं का उपयोग करें डुप्लिकेट पंक्तियों को हटाने के लिए कथन
DELETE JOIN स्टेटमेंट MySQL में दिया गया है जो टेबल से डुप्लीकेट रो को हटाने में मदद करता है।
"स्टूडेंटडीबी" नाम के एक डेटाबेस पर विचार करें। हम इसमें एक टेबल स्टूडेंट बनाएंगे।
mysql> USE studentdb;
Database changed
mysql> CREATE TABLE student (Stud_ID INT, Stud_Name VARCHAR(20), Stud_City VARCHAR(20), Stud_email VARCHAR(255), Stud_Age INT);
Query OK, 0 rows affected (0.15 sec)
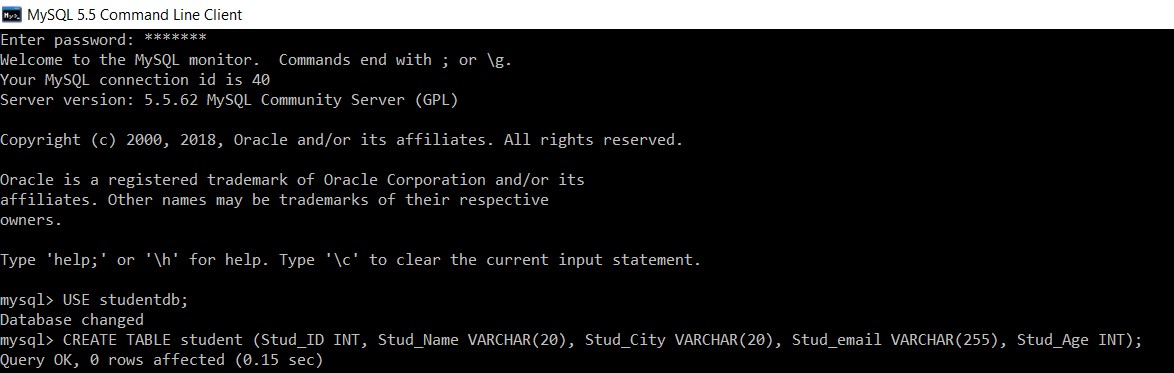
हमने 'studentdb' डेटाबेस में सफलतापूर्वक 'छात्र' तालिका बना ली है।
अब, हम छात्र तालिका में डेटा सम्मिलित करने के लिए निम्नलिखित प्रश्न लिखेंगे।
mysql> INSERT INTO student VALUES (1, "Ankit", "Nagpur", "example@sqldat.com", 32);
Query OK, 1 row affected (0.08 sec)
mysql> INSERT INTO student VALUES (2, "Soham", "Nanded", "example@sqldat.com", 35);
Query OK, 1 row affected (0.08 sec)
mysql> INSERT INTO student VALUES (3, "Soham", "Nanded", "example@sqldat.com", 26);
Query OK, 1 row affected (0.04 sec)
mysql> INSERT INTO student VALUES (4, "Ravi", "Chandigarh", "example@sqldat.com", 19);
Query OK, 1 row affected (0.09 sec)
mysql> INSERT INTO student VALUES (5, "Ravi", "Chandigarh", "example@sqldat.com", 19);
Query OK, 1 row affected (0.09 sec)
mysql> INSERT INTO student VALUES (6, "Shyam", "Dehradun", "example@sqldat.com", 22);
Query OK, 1 row affected (0.09 sec)
mysql> INSERT INTO student VALUES (7, "Manthan", "Ambala", "example@sqldat.com", 24);
Query OK, 1 row affected (0.08 sec)
mysql> INSERT INTO student VALUES (8, "Neeraj", "Noida", "example@sqldat.com", 25);
Query OK, 1 row affected (0.04 sec)
mysql> INSERT INTO student VALUES (9, "Anand", "Kashmir", "example@sqldat.com", 20);
Query OK, 1 row affected (0.07 sec)
mysql> INSERT INTO student VALUES (10, "Raju", "Shimla", "example@sqldat.com", 29);
Query OK, 1 row affected (0.13 sec)
mysql> INSERT INTO student VALUES (11, "Raju", "Shimla", "example@sqldat.com", 29);
Query OK, 1 row affected (0.08 sec)
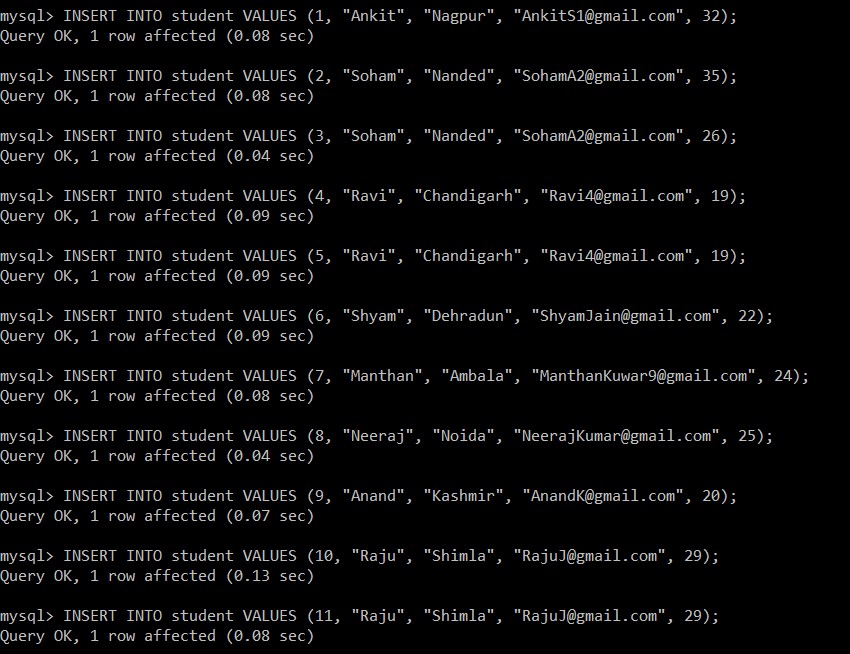
अब, हम छात्र तालिका से सभी रिकॉर्ड प्राप्त करेंगे। हम निम्नलिखित सभी उदाहरणों के लिए इस तालिका और डेटाबेस पर विचार करेंगे।
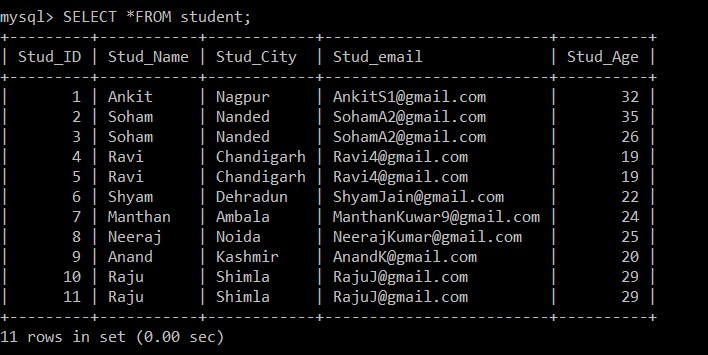
mysql> SELECT *FROM student;
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 1 | Ankit | Nagpur | example@sqldat.com | 32 |
| 2 | Soham | Nanded | example@sqldat.com | 35 |
| 3 | Soham | Nanded | example@sqldat.com | 26 |
| 4 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 5 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 6 | Shyam | Dehradun | example@sqldat.com | 22 |
| 7 | Manthan | Ambala | example@sqldat.com | 24 |
| 8 | Neeraj | Noida | example@sqldat.com | 25 |
| 9 | Anand | Kashmir | example@sqldat.com | 20 |
| 10 | Raju | Shimla | example@sqldat.com | 29 |
| 11 | Raju | Shimla | example@sqldat.com | 29 |
+---------+-----------+------------+-------------------------+----------+
11 rows in set (0.00 sec)
उदाहरण 1:
छात्र तालिका से डुप्लिकेट पंक्तियों को हटाने के लिए शामिल हों का उपयोग करके एक क्वेरी लिखें बयान।
mysql> DELETE s1 FROM student s1 INNER JOIN student s2 WHERE s1.Stud_ID < s2.Stud_ID AND s1.Stud_email = s2.Stud_email;हमने इनर जॉइन के साथ DELETE क्वेरी का उपयोग किया है। INNER JOIN को एक ही टेबल पर लागू करने के लिए, हमने दो उदाहरण s1 और s2 बनाए हैं। फिर, WHERE क्लॉज की मदद से, हमने छात्र तालिका में डुप्लिकेट पंक्तियों का पता लगाने के लिए दो शर्तों की जाँच की है। यदि दो अलग-अलग रिकॉर्ड में ईमेल आईडी समान है और छात्र आईडी अलग है, तो इसे WHERE क्लॉज शर्त के अनुसार डुप्लिकेट रिकॉर्ड के रूप में माना जाएगा।
आउटपुट:
Query OK, 3 rows affected (0.20 sec)उपरोक्त क्वेरी के परिणाम बताते हैं कि छात्र तालिका में तीन डुप्लिकेट रिकॉर्ड मौजूद हैं।

हम हटाए गए डुप्लिकेट रिकॉर्ड को खोजने के लिए SELECT क्वेरी का उपयोग करेंगे।
mysql> SELECT *FROM student;
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 1 | Ankit | Nagpur | example@sqldat.com | 32 |
| 3 | Soham | Nanded | example@sqldat.com | 26 |
| 5 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 6 | Shyam | Dehradun | example@sqldat.com | 22 |
| 7 | Manthan | Ambala | example@sqldat.com | 24 |
| 8 | Neeraj | Noida | example@sqldat.com | 25 |
| 9 | Anand | Kashmir | example@sqldat.com | 20 |
| 11 | Raju | Shimla | example@sqldat.com | 29 |
+---------+-----------+------------+-------------------------+----------+
8 rows in set (0.00 sec)
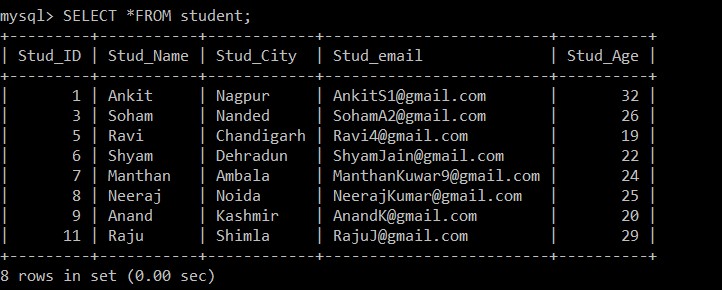
अब, केवल 8 रिकॉर्ड हैं जो छात्र तालिका में मौजूद हैं क्योंकि वर्तमान में चयनित तालिका से तीन डुप्लिकेट रिकॉर्ड हटा दिए गए हैं। निम्नलिखित शर्त के अनुसार:
s1.Stud_ID < s2.Stud_ID AND s1.Stud_email = s2.Stud_email;यदि किन्हीं दो अभिलेखों की ईमेल आईडी समान हैं, तो चूंकि छात्र आईडी के बीच कम से कम चिह्न का उपयोग किया जाता है, केवल अधिक कर्मचारी आईडी वाले रिकॉर्ड को रखा जाएगा, और अन्य डुप्लिकेट रिकॉर्ड को दो रिकॉर्ड के बीच हटा दिया जाएगा।
उदाहरण 2:
कम कर्मचारी आईडी के साथ डुप्लीकेट रिकॉर्ड रखते हुए और दूसरे को हटाते समय डिलीट जॉइन स्टेटमेंट का उपयोग करके छात्र तालिका से डुप्लिकेट पंक्तियों को हटाने के लिए एक प्रश्न लिखें।
mysql> DELETE s1 FROM student s1 INNER JOIN student s2 WHERE s1.Stud_ID > s2.Stud_ID AND s1.Stud_email = s2.Stud_email;हमने इनर जॉइन के साथ DELETE क्वेरी का उपयोग किया है। INNER JOIN को एक ही टेबल पर लागू करने के लिए, हमने दो उदाहरण s1 और s2 बनाए हैं। फिर, WHERE क्लॉज की मदद से, हमने छात्र तालिका में डुप्लिकेट पंक्तियों का पता लगाने के लिए दो शर्तों की जाँच की है। यदि दो अलग-अलग रिकॉर्ड में मौजूद ईमेल आईडी समान है और छात्र आईडी अलग है, तो इसे WHERE क्लॉज शर्त के अनुसार डुप्लिकेट रिकॉर्ड माना जाएगा।
आउटपुट:
Query OK, 3 rows affected (0.09 sec)उपरोक्त क्वेरी के परिणाम बताते हैं कि छात्र तालिका में तीन डुप्लिकेट रिकॉर्ड मौजूद हैं।

हम हटाए गए डुप्लिकेट रिकॉर्ड को खोजने के लिए SELECT क्वेरी का उपयोग करेंगे।
mysql> SELECT *FROM student;
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 1 | Ankit | Nagpur | example@sqldat.com | 32 |
| 2 | Soham | Nanded | example@sqldat.com | 35 |
| 4 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 6 | Shyam | Dehradun | example@sqldat.com | 22 |
| 7 | Manthan | Ambala | example@sqldat.com | 24 |
| 8 | Neeraj | Noida | example@sqldat.com | 25 |
| 9 | Anand | Kashmir | example@sqldat.com | 20 |
| 10 | Raju | Shimla | example@sqldat.com | 29 |
+---------+-----------+------------+-------------------------+----------+
8 rows in set (0.00 sec)
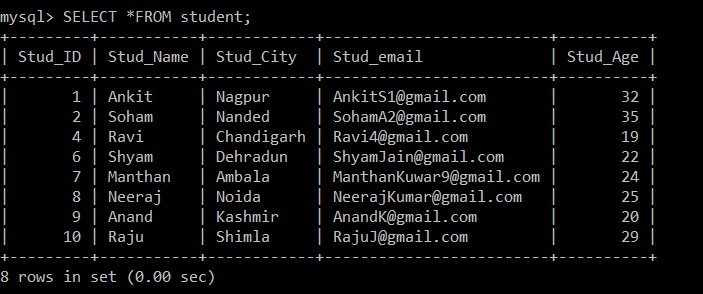
अब, केवल 8 रिकॉर्ड हैं जो छात्र तालिका में मौजूद हैं क्योंकि वर्तमान में चयनित तालिका से तीन डुप्लिकेट रिकॉर्ड हटा दिए गए हैं। निम्नलिखित शर्त के अनुसार:
s1.Stud_ID > s2.Stud_ID AND s1.Stud_email = s2.Stud_email;यदि किन्हीं दो अभिलेखों की ईमेल आईडी समान हैं क्योंकि छात्र आईडी के बीच चिह्न से अधिक का उपयोग किया जाता है, तो केवल कम कर्मचारी आईडी वाला रिकॉर्ड रखा जाएगा, और दो रिकॉर्ड के बीच अन्य डुप्लिकेट रिकॉर्ड हटा दिए जाएंगे।
- डुप्लीकेट पंक्तियों को हटाने के लिए मध्यवर्ती तालिका का उपयोग
मध्यवर्ती तालिका की सहायता से डुप्लिकेट पंक्तियों को हटाते समय निम्नलिखित चरणों का पालन किया जाना चाहिए।
- एक नई तालिका बनाई जानी चाहिए, जो वास्तविक तालिका के समान होगी।
- वास्तविक तालिका से नई बनाई गई तालिका में अलग-अलग पंक्तियां जोड़ें।
- वास्तविक तालिका को छोड़ दें और वास्तविक तालिका के समान नाम वाली नई तालिका का नाम बदलें।
उदाहरण:
इंटरमीडिएट टेबल का उपयोग करके छात्र तालिका से डुप्लिकेट रिकॉर्ड को हटाने के लिए एक प्रश्न लिखें।
चरण 1:
सबसे पहले, हम एक मध्यवर्ती तालिका बनाएंगे जो कर्मचारी तालिका के समान होगी।
mysql> CREATE TABLE temp_student LIKE student;
Query OK, 0 rows affected (0.14 sec)

यहां, 'कर्मचारी' मूल तालिका है और 'temp_student' मध्यवर्ती तालिका है।
चरण 2:
अब, हम छात्र तालिका से केवल अद्वितीय रिकॉर्ड प्राप्त करेंगे और सभी प्राप्त किए गए रिकॉर्ड को temp_student तालिका में सम्मिलित करेंगे।
mysql> INSERT INTO temp_student SELECT *FROM student GROUP BY Stud_email;
Query OK, 8 rows affected (0.12 sec)
Records: 8 Duplicates: 0 Warnings: 0

यहां, छात्र तालिका से अलग-अलग रिकॉर्ड्स को temp_student में डालने से पहले, सभी डुप्लिकेट रिकॉर्ड्स को Stud_email द्वारा फ़िल्टर किया जाता है। फिर, केवल विशिष्ट ईमेल आईडी वाले रिकॉर्ड्स को temp_student में डाला गया है।
चरण 3:
फिर, हम छात्र तालिका को हटा देंगे और तालिका का नाम बदलकर छात्र तालिका कर देंगे।
mysql> DROP TABLE student;
Query OK, 0 rows affected (0.08 sec)
mysql> ALTER TABLE temp_student RENAME TO student;
Query OK, 0 rows affected (0.08 sec)
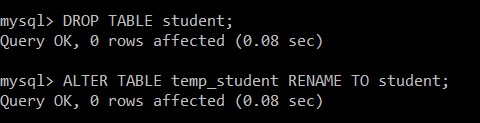
छात्र तालिका को सफलतापूर्वक हटा दिया गया है, और temp_student का नाम बदलकर छात्र तालिका कर दिया गया है, जिसमें केवल अद्वितीय रिकॉर्ड हैं।
फिर, हमें यह सत्यापित करने की आवश्यकता है कि छात्र तालिका में अब केवल अद्वितीय रिकॉर्ड हैं। इसे सत्यापित करने के लिए, हमने छात्र तालिका में निहित डेटा को देखने के लिए SELECT क्वेरी का उपयोग किया है।
mysql> SELECT *FROM student;आउटपुट:
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 9 | Anand | Kashmir | example@sqldat.com | 20 |
| 1 | Ankit | Nagpur | example@sqldat.com | 32 |
| 7 | Manthan | Ambala | example@sqldat.com | 24 |
| 8 | Neeraj | Noida | example@sqldat.com | 25 |
| 10 | Raju | Shimla | example@sqldat.com | 29 |
| 4 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 6 | Shyam | Dehradun | example@sqldat.com | 22 |
| 2 | Soham | Nanded | example@sqldat.com | 35 |
+---------+-----------+------------+-------------------------+----------+
8 rows in set (0.00 sec)
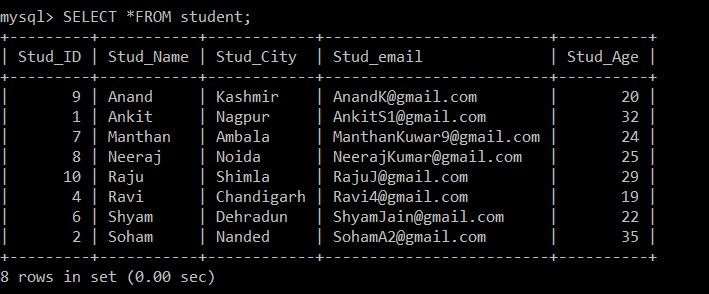
अब, केवल 8 रिकॉर्ड हैं जो छात्र तालिका में मौजूद हैं क्योंकि वर्तमान में चयनित तालिका से तीन डुप्लिकेट रिकॉर्ड हटा दिए गए हैं। चरण 2 में, मूल तालिका से अलग-अलग रिकॉर्ड लाने और उन्हें एक मध्यवर्ती तालिका में डालने के दौरान, स्टड_ईमेल पर ग्रुप बाय क्लॉज का उपयोग किया गया था, इसलिए सभी रिकॉर्ड छात्रों के ईमेल आईडी के आधार पर डाले गए थे। यहां, केवल कम कर्मचारी आईडी वाला रिकॉर्ड डिफ़ॉल्ट रूप से डुप्लिकेट रिकॉर्ड के बीच रखा जाता है, और दूसरा हटा दिया जाता है।



