इस SQL लेख में, हम GROUP BY क्लॉज और SQL में इसका उपयोग करने के तरीके के बारे में जानेंगे। हम WHERE क्लॉज के साथ GROUP BY क्लॉज के इस्तेमाल पर भी चर्चा करेंगे।
ग्रुप बाय क्लॉज क्या है?
ग्रुप बाय क्लॉज एक एसक्यूएल क्लॉज है जिसका इस्तेमाल सेलेक्ट स्टेटमेंट में एसक्यूएल फंक्शंस का इस्तेमाल करते हुए ग्रुप में कॉलम के समान रिकॉर्ड्स को मैनेज करने के लिए किया जाता है।
ग्रुप बाय क्लॉज का सिंटैक्स:
SELECT columnname1, columnname2, columnname3 FROM tablename GROUP BY columnname;हम ग्रुप बाय क्लॉज में टेबल से कई कॉलम का उपयोग कर सकते हैं।
कुछ चरण हैं, हमें सीखना होगा कि SQL क्वेरी में ग्रुप बाय क्लॉज का उपयोग कैसे करें:
1. डेटाबेस नाम के बाद USE कीवर्ड का उपयोग करके डेटाबेस का चयन करके एक नया डेटाबेस बनाएं या मौजूदा डेटाबेस का उपयोग करें।
2. चयनित डेटाबेस के अंदर एक नई तालिका बनाएं, या आप पहले से बनाई गई तालिका का उपयोग कर सकते हैं।
3. यदि तालिका नई बनाई गई है, तो INSERT क्वेरी का उपयोग करके नए बनाए गए डेटाबेस में रिकॉर्ड डालें और GROUP BY क्लॉज के बिना SELECT क्वेरी का उपयोग करके सम्मिलित डेटा देखें।
<मजबूत>4. अब, हम SQL क्वेरी में ग्रुप बाय क्लॉज का उपयोग करने के लिए तैयार हैं।
चरण 1:एक नया डेटाबेस बनाएं या पहले से बनाए गए डेटाबेस का उपयोग करें।
मैंने पहले ही एक डेटाबेस बना लिया है। मैं अपने मौजूदा बनाए गए डेटाबेस नाम, कंपनी का उपयोग करूंगा।
USE Company;
कंपनी डेटाबेस का नाम है।
जिन लोगों ने डेटाबेस नहीं बनाया है, वे डेटाबेस बनाने के लिए नीचे दी गई क्वेरी का पालन करते हैं:
CREATE DATABASE database_name;
डेटाबेस बनाने के बाद, डेटाबेस नाम के बाद USE कीवर्ड का उपयोग करके डेटाबेस का चयन करें।
चरण 2:एक नई तालिका बनाएं या पहले से मौजूद तालिका का उपयोग करें:
मैंने पहले ही एक टेबल बना लिया है। मैं कर्मचारी नाम की मौजूदा तालिका का उपयोग करूंगा।
नई तालिकाएँ बनाने के लिए, नीचे दिए गए CREATE TABLE सिंटैक्स का पालन करें:
CREATE TABLE table_name(
columnname1 datatype(column size),
columnname2 datatype(column size),
columnname3 datatype(column size)
);
चरण 3:INSERT क्वेरी का उपयोग करके नई बनाई गई तालिका में रिकॉर्ड डालें और SELECT क्वेरी का उपयोग करके रिकॉर्ड देखें।
तालिका में नए रिकॉर्ड सम्मिलित करने के लिए निम्न सिंटैक्स का उपयोग करें:
INSERT INTO table_name VALUES(value1, value2, value3);
तालिका से रिकॉर्ड देखने के लिए निम्न सिंटैक्स का उपयोग करें:
SELECT * FROM table_name;
निम्न क्वेरी कर्मचारियों के रिकॉर्ड प्रदर्शित करेगी:
SELECT * FROM Employees;
उपरोक्त SELECT क्वेरी का आउटपुट है:
| कर्मचारी | FIRST_NAME | LAST_NAME | वेतन | शहर | विभाग | मैनेजरिड |
| 1001 | वैभवी | मिश्रा | 65500 | पुणे | ओरेकल | 1 |
| 1002 | वैभव | शर्मा | 60000 | नोएडा | सी# | 5 |
| 1003 | निखिल | वाणी | 50500 | जयपुर | FMW | 2 |
| 2001 | प्राची | शर्मा | 55500 | चंडीगढ़ | ओरेकल | 1 |
| 2002 | भावेश | जैन | 65500 | पुणे | FMW | 2 |
| 2003 | रुचिका | जैन | 50000 | मुंबई | सी# | 5 |
| 3001 | प्रानोटी | शेंडे | 55500 | पुणे | जावा | 3 |
| 3002 | अनुजा | WANRE | 50500 | जयपुर | FMW | 2 |
| 3003 | दीपम | जौहारी | 58500 | मुंबई | जावा | 3 |
| 4001 | राजेश | GOUD | 60500 | मुंबई | परीक्षण | 4 |
| 4002 | अश्विनी | बगत | 54500 | नोएडा | जावा | 3 |
| 4003 | रुचिका | अग्रवाल | 60000 | दिल्ली | ओरेकल | 1 |
| 5001 | ARCHIT | शर्मा | 55500 | दिल्ली | परीक्षण | 4 |
| 5002 | संकेट | चौहान | 70000 | हैदराबाद | जावा | 3 |
| 5003 | रोशन | NEHTE | 48500 | चंडीगढ़ | सी# | 5 |
| 6001 | राहुल | निकम | 54500 | बैंगलोर | परीक्षण | 4 |
| 6002 | आतिश | जाधव | 60500 | बैंगलोर | सी# | 5 |
| 6003 | निकिता | इंगले | 65000 | हैदराबाद | ओरेकल | 1 |
चरण 4:हम प्रश्नों में ग्रुप बाय क्लॉज का उपयोग करने के लिए तैयार हैं
अब हम उदाहरणों की मदद से ग्रुप बाय क्लॉज में गहराई से उतरेंगे
उदाहरण 1: कर्मचारी रिकॉर्ड समूह को शहर के अनुसार प्रदर्शित करने के लिए एक प्रश्न लिखें।
SELECT * FROM EMPLOYEES GROUP BY CITY;
उपरोक्त क्वेरी कर्मचारियों के रिकॉर्ड प्रदर्शित करती है जहां एक ही शहर के एक कर्मचारी को एक समूह माना जाएगा। उदाहरण के लिए, यदि तालिका में 10 कर्मचारी रिकॉर्ड हैं जहां 3 पुणे शहर से हैं, 3 मुंबई शहर से हैं, 2 हैदराबाद और बैंगलोर से हैं, तो उपरोक्त क्वेरी पुणे शहर के कर्मचारी मुंबई शहर के कर्मचारी को एक रिकॉर्ड के रूप में समूहित करेगी, और इसी तरह आगे ।
उपरोक्त क्वेरी का आउटपुट:
| कर्मचारी | FIRST_NAME | LAST_NAME | वेतन | शहर | विभाग | मैनेजरिड |
| 6001 | राहुल | निकम | 54500 | बैंगलोर | परीक्षण | 4 |
| 2001 | प्राची | शर्मा | 55500 | चंडीगढ़ | ओरेकल | 1 |
| 4003 | रुचिका | अग्रवाल | 60000 | दिल्ली | ओरेकल | 1 |
| 5002 | संकेट | चौहान | 70000 | हैदराबाद | जावा | 3 |
| 1003 | निखिल | वाणी | 50500 | जयपुर | FMW | 2 |
| 2003 | रुचिका | जैन | 50000 | मुंबई | C# | 5 |
| 1002 | वैभव | शर्मा | 60000 | नोएडा | सी# | 5 |
| 1001 | वैभवी | मिश्रा | 65500 | पुणे | ओरेकल | 1 |
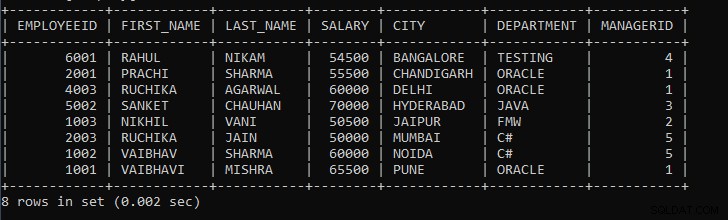
जैसा कि हम देख सकते हैं कि कर्मचारियों के रिकॉर्ड शहर के अनुसार समूहीकृत होते हैं, और रिकॉर्ड डिफ़ॉल्ट रूप से आरोही क्रम में प्रदर्शित होते हैं।
उदाहरण 2: वेतन के आधार पर कर्मचारियों के रिकॉर्ड समूह को अवरोही क्रम में प्रदर्शित करने के लिए एक प्रश्न लिखें।
SELECT * FROM EMPLOYEES GROUP BY SALARY DESC;
उपरोक्त क्वेरी कर्मचारियों के रिकॉर्ड प्रदर्शित करती है जहां समान वेतन वाले कर्मचारियों को एक समूह माना जाएगा, और रिकॉर्ड अवरोही क्रम में प्रदर्शित होंगे।
उपरोक्त क्वेरी का आउटपुट:
| कर्मचारी | FIRST_NAME | LAST_NAME | वेतन | शहर | विभाग | मैनेजरिड |
| 5002 | संकेट | चौहान | 70000 | हैदराबाद | जावा | 3 |
| 1001 | वैभवी | मिश्रा | 65500 | पुणे | ओरेकल | 1 |
| 6003 | निकिता | इंगले | 65000 | हैदराबाद | ओरेकल | 1 |
| 4001 | राजेश | GOUD | 60500 | मुंबई | परीक्षण | 4 |
| 1002 | वैभव | शर्मा | 60000 | नोएडा | सी# | 5 |
| 3003 | दीपम | जौहारी | 58500 | मुंबई | जावा | 3 |
| 2001 | प्राची | शर्मा | 55500 | चंडीगढ़ | ओरेकल | 1 |
| 4002 | अश्विनी | बगत | 54500 | नोएडा | जावा | 3 |
| 1003 | निखिल | वाणी | 50500 | जयपुर | FMW | 2 |
| 2003 | रुचिका | जैन | 50000 | मुंबई | C# | 5 |
| 5003 | रोशन | NEHTE | 48500 | चंडीगढ़ | सी# | 5 |
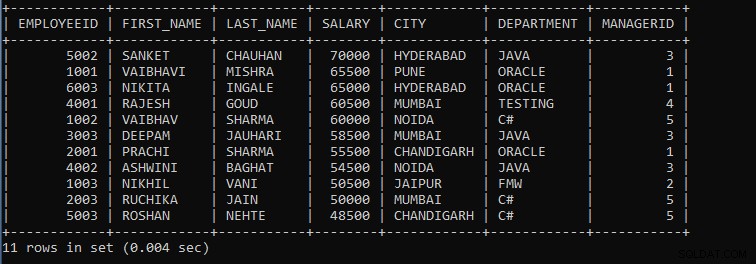
जैसा कि हम देख सकते हैं, कर्मचारियों के रिकॉर्ड वेतन के आधार पर समूहित होते हैं, और रिकॉर्ड अवरोही क्रम में प्रदर्शित होते हैं, जैसा कि हम अंत में वर्णन करते हैं।
उदाहरण 3: कर्मचारियों के रिकॉर्ड समूह को वेतन और शहर के आधार पर प्रदर्शित करने के लिए एक प्रश्न लिखें।
SELECT * FROM EMPLOYEES GROUP BY SALARY, CITY;
उपरोक्त क्वेरी कर्मचारियों के रिकॉर्ड प्रदर्शित करती है जहां समान वेतन और शहर वाले कर्मचारियों को एक समूह माना जाएगा।
उदाहरण के लिए, मान लें कि तालिका में 10 कर्मचारी रिकॉर्ड थे। 10 कर्मचारियों में से 2 कर्मचारियों का वेतन और शहर अन्य दो कर्मचारियों के साथ मेल खाता है और बाकी छह कर्मचारियों का वेतन और शहर बेजोड़ है तो 6 कर्मचारियों को 6 अलग-अलग समूह माना जाएगा, और 2 कर्मचारी जो अन्य 2 कर्मचारियों के साथ मेल खाते हैं, उन्हें एक समूह माना जाएगा . संक्षेप में, 8 समूह बनाए जाएंगे।
उपरोक्त क्वेरी का आउटपुट:
| कर्मचारी | FIRST_NAME | LAST_NAME | वेतन | शहर | विभाग | मैनेजरिड |
| 5003 | रोशन | NEHTE | 48500 | चंडीगढ़ | सी# | 5 |
| 2003 | रुचिका | जैन | 50000 | मुंबई | सी# | 5 |
| 1003 | निखिल | वाणी | 50500 | जयपुर | FMW | 2 |
| 6001 | राहुल | निकम | 54500 | बैंगलोर | परीक्षण | 4 |
| 4002 | अश्विनी | बगत | 54500 | नोएडा | जावा | 3 |
| 2001 | प्राची | शर्मा | 55500 | चंडीगढ़ | ओरेकल | 1 |
| 5001 | ARCHIT | शर्मा | 55500 | दिल्ली | परीक्षण | 4 |
| 3001 | प्रानोटी | शेंडे | 55500 | पुणे | जावा | 3 |
| 3003 | दीपम | जौहारी | 58500 | मुंबई | जावा | 3 |
| 4003 | रुचिका | अग्रवाल | 60000 | दिल्ली | ओरेकल | 1 |
| 1002 | वैभव | शर्मा | 60000 | नोएडा | सी# | 5 |
| 6002 | आतिश | जाधव | 60500 | बैंगलोर | सी# | 5 |
| 4001 | राजेश | GOUD | 60500 | मुंबई | परीक्षण | 4 |
| 6003 | निकिता | इंगले | 65000 | हैदराबाद | ओरेकल | 1 |
| 1001 | वैभवी | मिश्रा | 65500 | पुणे | ओरेकल | 1 |
| 5002 | संकेट | चौहान | 70000 | हैदराबाद | जावा | 3 |
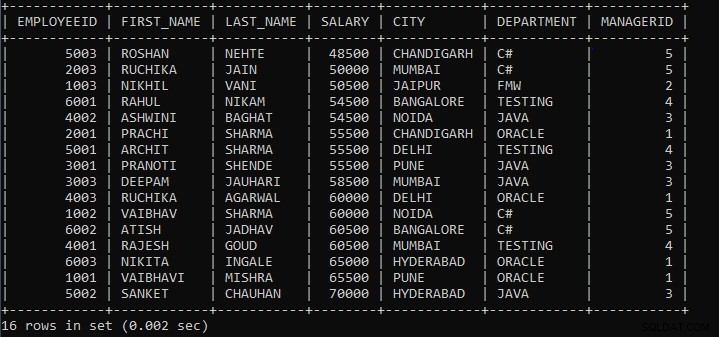
जैसा कि हम देख सकते हैं, कर्मचारियों के रिकॉर्ड वेतन और शहर के आधार पर समूहीकृत होते हैं, और रिकॉर्ड डिफ़ॉल्ट रूप से आरोही क्रम में प्रदर्शित होते हैं।
उदाहरण 4: शहर और विभाग द्वारा कर्मचारियों के रिकॉर्ड प्रदर्शित करने के लिए एक प्रश्न लिखें।
SELECT * FROM EMPLOYEES GROUP BY CITY, DEPARTMENT;
उपरोक्त क्वेरी कर्मचारियों के रिकॉर्ड प्रदर्शित करती है जहां कर्मचारी एक ही शहर में हैं, और विभाग को एक समूह माना जाएगा।
उपरोक्त क्वेरी का आउटपुट:
| कर्मचारी | FIRST_NAME | LAST_NAME | वेतन | शहर | विभाग | मैनेजरिड |
| 6002 | आतिश | जाधव | 60500 | बैंगलोर | सी# | 5 |
| 6001 | राहुल | निकम | 54500 | बैंगलोर | परीक्षण | 4 |
| 5003 | रोशन | NEHTE | 48500 | चंडीगढ़ | सी# | 5 |
| 2001 | प्राची | शर्मा | 55500 | चंडीगढ़ | ओरेकल | 1 |
| 4003 | रुचिका | अग्रवाल | 60000 | दिल्ली | ओरेकल | 1 |
| 5001 | ARCHIT | शर्मा | 55500 | दिल्ली | परीक्षण | 4 |
| 5002 | संकेट | चौहान | 70000 | हैदराबाद | जावा | 3 |
| 6003 | निकिता | इंगले | 65000 | हैदराबाद | ओरेकल | 1 |
| 1003 | निखिल | वाणी | 50500 | जयपुर | FMW | 2 |
| 2003 | रुचिका | जैन | 50000 | मुंबई | सी# | 5 |
| 3003 | दीपम | जौहारी | 58500 | मुंबई | जावा | 3 |
| 4001 | राजेश | GOUD | 60500 | मुंबई | परीक्षण | 4 |
| 1002 | वैभव | शर्मा | 60000 | नोएडा | सी# | 5 |
| 4002 | अश्विनी | बगत | 54500 | नोएडा | जावा | 3 |
| 2002 | भावेश | जैन | 65500 | पुणे | FMW | 2 |
| 3001 | प्रानोटी | शेंडे | 55500 | पुणे | जावा | 3 |
| 1001 | वैभवी | मिश्रा | 65500 | पुणे | ओरेकल | 1 |
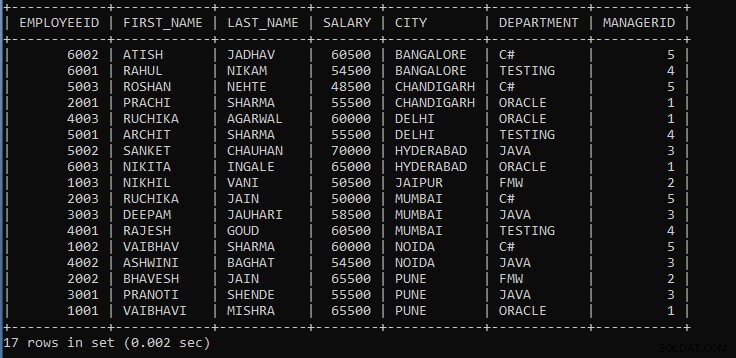
जैसा कि हम देख सकते हैं, कर्मचारियों के रिकॉर्ड शहर और विभाग द्वारा समूहीकृत किए जाते हैं, और रिकॉर्ड डिफ़ॉल्ट रूप से आरोही क्रम में प्रदर्शित होते हैं।
उदाहरण 5: कर्मचारियों की तालिका से प्रत्येक विभाग में कर्मचारियों की सूची गिनने के लिए एक प्रश्न लिखें।
SELECT DEPARTMENT, COUNT(DEPARTMENT) FROM EMPLOYEES GROUP BY DEPARTMENT;उपरोक्त क्वेरी विभाग द्वारा प्रत्येक विभाग समूह में कर्मचारियों की संख्या प्रदर्शित करती है। जैसे छह कर्मचारी मानव संसाधन विभाग में काम करते हैं, पांच दूसरे विभाग में काम करते हैं।
उपरोक्त क्वेरी का आउटपुट:
| विभाग | COUNT(DEPARTMENT) |
| सी# | 4 |
| FMW | 3 |
| जावा | 4 |
| ओरेकल | 4 |
| परीक्षण | 3 |
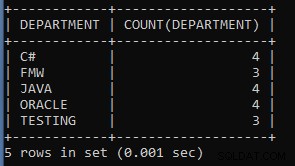
जैसा कि हम देख सकते हैं, चार कर्मचारी C# विभाग में काम करते हैं, तीन FMW विभाग में काम करते हैं, आदि।
उदाहरण 6: कर्मचारियों की तालिका से प्रत्येक शहर के कर्मचारियों की सूची गिनने के लिए एक प्रश्न लिखें।
SELECT CITY, COUNT(CITY) FROM EMPLOYEES GROUP BY CITY;
उपरोक्त क्वेरी शहर के अनुसार प्रत्येक शहर समूह में कर्मचारियों की संख्या प्रदर्शित करती है। जैसे तीन कर्मचारी पुणे शहर से काम करते हैं, चार दूसरे शहर से काम करते हैं, इत्यादि।
उपरोक्त क्वेरी का आउटपुट:
| शहर | COUNT(CITY) |
| बैंगलोर | 2 |
| चंडीगढ़ | 2 |
| दिल्ली | 2 |
| हैदराबाद | 2 |
| जयपुर | 2 |
| मुंबई | 3 |
| नोएडा | 2 |
| पुणे | 3 |
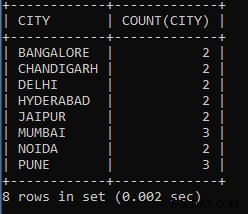
जैसा कि हम देख सकते हैं, दो कर्मचारी बैंगलोर शहर से काम करते हैं, तीन मुंबई शहर से काम करते हैं, और इसी तरह।
उदाहरण 7: शहर के अनुसार कर्मचारी वेतन समूह के योग के लिए एक प्रश्न लिखें।
SELECT CITY, SUM(SALARY) AS SALARY FROM EMPLOYEES GROUP BY CITY;उपरोक्त का उपयोग कर्मचारियों के वेतन को शहर के नाम से समूहित करने के लिए किया जाता है। उदाहरण के लिए, एक ही शहर के कर्मचारियों के लिए, उनका वेतन योग और एक समूह माना जाएगा। हमने वेतन जोड़ने के लिए वेतन कॉलम के बाद कुल योग फ़ंक्शन का उपयोग किया।
उपरोक्त क्वेरी का आउटपुट:
| शहर | वेतन |
| बैंगलोर | 115000 |
| चंडीगढ़ | 104000 |
| दिल्ली | 115500 |
| हैदराबाद | 135000 |
| जयपुर | 101000 |
| मुंबई | 169000 |
| नोएडा | 114500 |
| पुणे | 186500 |
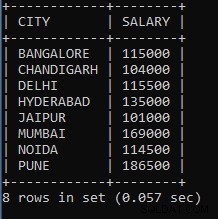
जैसा कि हम देख सकते हैं, बैंगलोर शहर का वेतन 115000 है, चंडीगढ़ शहर का वेतन 104000 है जो विभिन्न कर्मचारी वेतन के अतिरिक्त है, लेकिन शहर से, प्रत्येक शहर के लिए एक ही दृष्टिकोण का उपयोग किया जाता है।
उदाहरण 8: प्रत्येक विभाग से न्यूनतम वेतन खोजने के लिए एक प्रश्न लिखें।
SELECT DEPARTMENT, MIN(SALARY) FROM EMPLOYEES GROUP BY DEPARTMENT;उपरोक्त क्वेरी का उपयोग प्रत्येक विभाग से कर्मचारी के न्यूनतम वेतन का पता लगाने के लिए किया जाता है। जावा विभाग के कर्मचारियों में से एक का वेतन 54500 है, जो पूरे जावा विभाग में सबसे कम है। वही 48500 C# विभाग में कर्मचारी को दिया जाने वाला सबसे कम वेतन है।
उपरोक्त क्वेरी का आउटपुट:
| विभाग | मिनट(वेतन) |
| सी# | 48500 |
| FMW | 50500 |
| जावा | 54500 |
| ओरेकल | 55500 |
| परीक्षण | 54500 |
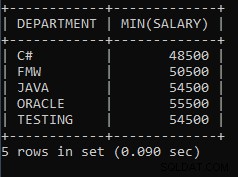
जैसा कि हम देख सकते हैं, FMW विभाग में कर्मचारियों में से किसी एक को दिया जाने वाला न्यूनतम वेतन 50500 है, ORACLE विभाग के किसी एक कर्मचारी को दिया जाने वाला न्यूनतम वेतन 55500 है।
उदाहरण 9: प्रत्येक शहर से न्यूनतम वेतन खोजने के लिए एक प्रश्न लिखें।
SELECT CITY, MAX(SALARY) FROM EMPLOYEES GROUP BY CITY;उपरोक्त क्वेरी का उपयोग प्रत्येक शहर से अधिकतम वेतन खोजने के लिए किया जाता है। पुणे शहर के कर्मचारियों में से एक का वेतन 65500 है जो पूरे पुणे शहर में सबसे अधिक है, वही 60500 मुंबई शहर में कर्मचारी को दिया जाने वाला उच्चतम वेतन है।
उपरोक्त क्वेरी का आउटपुट:
| शहर | अधिकतम(वेतन) |
| बैंगलोर | 60500 |
| चंडीगढ़ | 55500 |
| दिल्ली | 60000 |
| हैदराबाद | 70000 |
| जयपुर | 50500 |
| मुंबई | 60500 |
| नोएडा | 60000 |
| पुणे | 65500 |
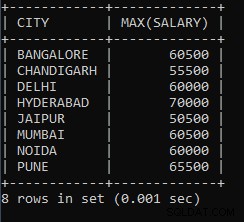
जैसा कि हम देख सकते हैं, जयपुर शहर में 50500 कर्मचारियों में से एक को दिया जाने वाला उच्चतम वेतन है, 55500 चंडीगढ़ शहर में कर्मचारियों में से एक को दिया जाने वाला उच्चतम वेतन है।