टी-एसक्यूएल मंगलवार #78 को वेंडी पेस्ट्री द्वारा होस्ट किया जा रहा है, और इस महीने चुनौती बस "कुछ नया सीखना और इसके बारे में ब्लॉग करना है।" SQL सर्वर 2016 में नई सुविधाओं की ओर उनका अस्पष्ट झुकाव है, लेकिन चूंकि मैंने उनमें से कई के बारे में ब्लॉग और प्रस्तुत किया है, इसलिए मैंने सोचा कि मैं पहली बार कुछ और खोजूंगा जिसके बारे में मैं हमेशा उत्सुक रहा हूं।
मैंने कई लोगों को यह कहते हुए देखा है कि कुछ परिदृश्यों के लिए एक ढेर एक संकुल सूचकांक से बेहतर हो सकता है। मैं इससे असहमत नहीं हो सकता। हालांकि, मैंने जो दिलचस्प कारण देखे हैं उनमें से एक यह है कि RID लुकअप की लुकअप की तुलना में तेज़ है। मैं क्लस्टर इंडेक्स का बहुत बड़ा प्रशंसक हूं और ढेर का बहुत बड़ा प्रशंसक नहीं हूं, इसलिए मुझे लगा कि इसके लिए कुछ परीक्षण की आवश्यकता है।
तो, चलिए इसका परीक्षण करते हैं!
मैंने सोचा कि दो तालिकाओं के साथ एक डेटाबेस बनाना अच्छा होगा, सिवाय इसके कि एक के पास एक प्राथमिक प्राथमिक कुंजी थी, और दूसरे के पास एक गैर-संकुल प्राथमिक कुंजी थी। मैं तालिका में कुछ पंक्तियों को लोड करने, लूप में पंक्तियों के एक समूह को अपडेट करने और एक इंडेक्स से चयन करने में समय लगाऊंगा (या तो एक कुंजी या आरआईडी लुकअप को मजबूर करना)।
सिस्टम विनिर्देश
यह प्रश्न अक्सर आता है, इसलिए इस प्रणाली के बारे में महत्वपूर्ण विवरणों को स्पष्ट करने के लिए, मैं एक 8-कोर वीएम पर 32 जीबी रैम के साथ हूं, जो पीसीआई स्टोरेज द्वारा समर्थित है। SQL सर्वर संस्करण 2014 SP1 CU6 है, जिसमें कोई विशेष कॉन्फ़िगरेशन परिवर्तन या ट्रेस फ़्लैग नहीं चल रहा है:
Microsoft SQL सर्वर 2014 (SP1-CU6) (KB3144524) - 12.0.4449.0 (X64)अप्रैल 13 2016 12:41:07
कॉपीराइट (c) Microsoft Corporation
डेवलपर संस्करण (64- बिट) विंडोज एनटी 6.3 पर
डेटाबेस
मैंने किसी भी ऑटोग्रो घटनाओं को परीक्षणों में हस्तक्षेप करने से रोकने के लिए डेटा और लॉग फ़ाइल दोनों में बहुत सारी खाली जगह वाला डेटाबेस बनाया है। लेन-देन लॉग पर प्रभाव को कम करने के लिए मैंने डेटाबेस को सरल पुनर्प्राप्ति पर भी सेट किया है।
CREATE DATABASE HeapVsCIX ON ( name = N'HeapVsCIX_data', filename = N'C:\...\HeapCIX.mdf', size = 100MB, filegrowth = 10MB ) LOG ON ( name = N'HeapVsCIX_log', filename = 'C:\...\HeapCIX.ldf', size = 100MB, filegrowth = 10MB ); GO ALTER DATABASE HeapVsCIX SET RECOVERY SIMPLE;
टेबल्स
जैसा कि मैंने कहा, दो टेबल, केवल अंतर यह है कि प्राथमिक कुंजी क्लस्टर की गई है या नहीं।
CREATE TABLE dbo.ObjectHeap ( ObjectID int PRIMARY KEY NONCLUSTERED, Name sysname, SchemaID int, ModuleDefinition nvarchar(max) ); CREATE INDEX oh_name ON dbo.ObjectHeap(Name) INCLUDE(SchemaID); CREATE TABLE dbo.ObjectCIX ( ObjectID INT PRIMARY KEY CLUSTERED, Name sysname, SchemaID int, ModuleDefinition nvarchar(max) ); CREATE INDEX oc_name ON dbo.ObjectCIX(Name) INCLUDE(SchemaID);
रनटाइम कैप्चर करने के लिए एक टेबल
मैं सीपीयू और उस सब की निगरानी कर सकता था, लेकिन वास्तव में जिज्ञासा लगभग हमेशा रनटाइम के आसपास होती है। इसलिए मैंने प्रत्येक परीक्षण के रनटाइम को कैप्चर करने के लिए एक लॉगिंग टेबल बनाई:
CREATE TABLE dbo.Timings ( Test varchar(32) NOT NULL, StartTime datetime2 NOT NULL DEFAULT SYSUTCDATETIME(), EndTime datetime2 );
इन्सर्ट टेस्ट
तो, 2,000 पंक्तियों को 100 बार डालने में कितना समय लगता है? मैं sys.all_objects . से कुछ बहुत ही बुनियादी डेटा ले रहा हूं , और किसी भी प्रक्रिया, कार्य, आदि के लिए परिभाषा को साथ लाना:
INSERT dbo.Timings(Test) VALUES('Inserting Heap');
GO
TRUNCATE TABLE dbo.ObjectHeap;
INSERT dbo.ObjectHeap(ObjectID, Name, SchemaID, ModuleDefinition)
SELECT TOP (2000) [object_id], name, [schema_id], OBJECT_DEFINITION([object_id])
FROM sys.all_objects ORDER BY [object_id];
GO 100
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
GO
-- CIX:
INSERT dbo.Timings(Test) VALUES('Inserting CIX');
GO
TRUNCATE TABLE dbo.ObjectCIX;
INSERT dbo.ObjectCIX(ObjectID, Name, SchemaID, ModuleDefinition)
SELECT TOP (2000) [object_id], name, [schema_id], OBJECT_DEFINITION([object_id])
FROM sys.all_objects ORDER BY [object_id];
GO 100
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL; अपडेट टेस्ट
अद्यतन परीक्षण के लिए, मैं बस एक बहुत ही पंक्ति-दर-पंक्ति फैशन में एक क्लस्टर इंडेक्स बनाम ढेर में लिखने की गति का परीक्षण करना चाहता था। इसलिए मैंने 200 यादृच्छिक पंक्तियों को एक #temp तालिका में डाल दिया, फिर उसके चारों ओर एक कर्सर बनाया (#temp तालिका केवल यह सुनिश्चित करती है कि समान 200 पंक्तियों को तालिका के दोनों संस्करणों में अपडेट किया जाता है, जो शायद अधिक है)।
CREATE TABLE #IdsToUpdate(ObjectID int PRIMARY KEY CLUSTERED);
INSERT #IdsToUpdate(ObjectID)
SELECT TOP (200) ObjectID
FROM dbo.ObjectCIX ORDER BY NEWID();
GO
INSERT dbo.Timings(Test) VALUES('Updating Heap');
GO
-- update speed - update 200 rows 1,000 times
DECLARE @id int;
DECLARE c CURSOR LOCAL FORWARD_ONLY
FOR SELECT ObjectID FROM #IdsToUpdate;
OPEN c; FETCH c INTO @id;
WHILE @@FETCH_STATUS <> -1
BEGIN
UPDATE dbo.ObjectHeap SET Name = REPLACE(Name,'s','u') WHERE ObjectID = @id;
FETCH c INTO @id;
END
CLOSE c; DEALLOCATE c;
GO 1000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
GO
INSERT dbo.Timings(Test) VALUES('Updating CIX');
GO
DECLARE @id int;
DECLARE c CURSOR LOCAL FORWARD_ONLY
FOR SELECT ObjectID FROM #IdsToUpdate;
OPEN c; FETCH c INTO @id;
WHILE @@FETCH_STATUS <> -1
BEGIN
UPDATE dbo.ObjectCIX SET Name = REPLACE(Name,'s','u') WHERE ObjectID = @id;
FETCH c INTO @id;
END
CLOSE c; DEALLOCATE c;
GO 1000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL; चुनें परीक्षण
तो, ऊपर आपने देखा कि मैंने Name . के साथ एक इंडेक्स बनाया है प्रत्येक तालिका में मुख्य स्तंभ के रूप में; पंक्तियों की एक महत्वपूर्ण राशि के लिए लुकअप करने की लागत का मूल्यांकन करने के लिए, मैंने एक क्वेरी लिखी जो आउटपुट को एक चर (नेटवर्क I/O और क्लाइंट रेंडरिंग समय को समाप्त) को असाइन करती है, लेकिन इंडेक्स के उपयोग को मजबूर करती है:
INSERT dbo.Timings(Test) VALUES('Forcing RID Lookup');
GO
DECLARE @x nvarchar(max);
SELECT @x = ModuleDefinition FROM dbo.ObjectHeap WITH (INDEX(oh_name)) WHERE Name LIKE N'S%';
GO 10000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
GO
INSERT dbo.Timings(Test) VALUES('Forcing Key Lookup');
GO
DECLARE @x nvarchar(max);
SELECT @x = ModuleDefinition FROM dbo.ObjectCIX WITH (INDEX(oc_name)) WHERE Name LIKE N'S%';
GO 10000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL; इसके लिए मैं परीक्षा परिणामों को समेटने से पहले योजनाओं के कुछ दिलचस्प पहलुओं को दिखाना चाहता था। उन्हें अलग-अलग आमने-सामने चलाने से ये तुलनात्मक मेट्रिक्स मिलते हैं:

किसी एक कथन के लिए अवधि का कोई महत्व नहीं है, लेकिन उन कथनों को देखें। यदि आप धीमे संग्रहण पर हैं, तो यह एक बड़ा अंतर है जो आपको छोटे पैमाने पर और/या अपने स्थानीय विकास SSD पर नहीं दिखाई देगा।
और फिर SQL सेंट्री प्लान एक्सप्लोरर का उपयोग करते हुए दो अलग-अलग लुकअप दिखाने वाली योजनाएं:

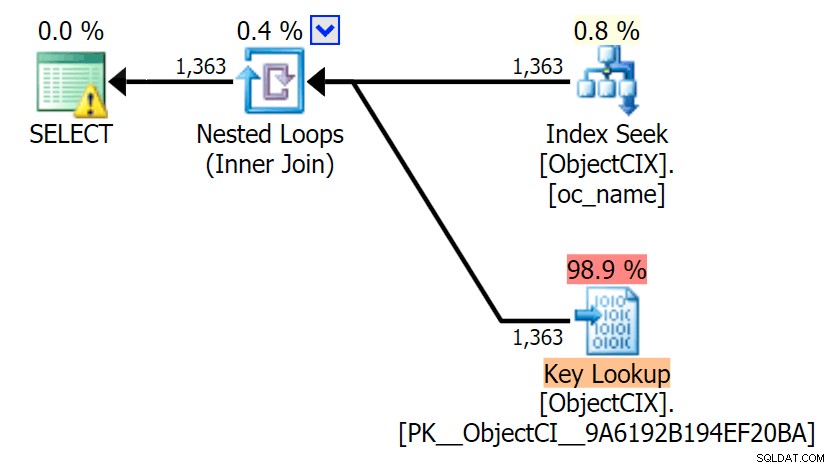
योजनाएं लगभग समान दिखती हैं, और जब तक आप सांख्यिकी I/O कैप्चर नहीं कर रहे थे, तब तक आपको SSMS में पढ़ने में अंतर दिखाई नहीं दे सकता है। यहां तक कि दो लुकअप के लिए अनुमानित I/O लागत समान थी - की लुकअप के लिए 1.69, और RID लुकअप के लिए 1.59। (दोनों योजनाओं में चेतावनी आइकन एक लापता कवरिंग इंडेक्स के लिए है।)
यह ध्यान रखना दिलचस्प है कि यदि हम एक लुकअप के लिए बाध्य नहीं करते हैं और SQL सर्वर को यह तय करने की अनुमति देते हैं कि क्या करना है, तो यह दोनों मामलों में एक मानक स्कैन चुनता है - कोई अनुपलब्ध अनुक्रमणिका चेतावनी नहीं है, और देखें कि रीड्स कितने करीब हैं:

अनुकूलक जानता है कि इस मामले में खोज + लुकअप की तुलना में एक स्कैन बहुत सस्ता होगा। मैंने केवल प्रभाव के लिए परिवर्तनीय असाइनमेंट के लिए एक एलओबी कॉलम चुना, लेकिन परिणाम गैर-एलओबी कॉलम का उपयोग करने के समान थे।
परीक्षा परिणाम
टाइमिंग टेबल के साथ, मैं आसानी से कई बार परीक्षण चलाने में सक्षम था (मैंने एक दर्जन परीक्षण चलाए) और फिर निम्न क्वेरी के साथ परीक्षणों के लिए औसत के साथ आया:
SELECT Test, Avg_Duration = AVG(1.0*DATEDIFF(MILLISECOND, StartTime, EndTime)) FROM dbo.Timings GROUP BY Test;
एक साधारण बार चार्ट दिखाता है कि वे कैसे तुलना करते हैं:
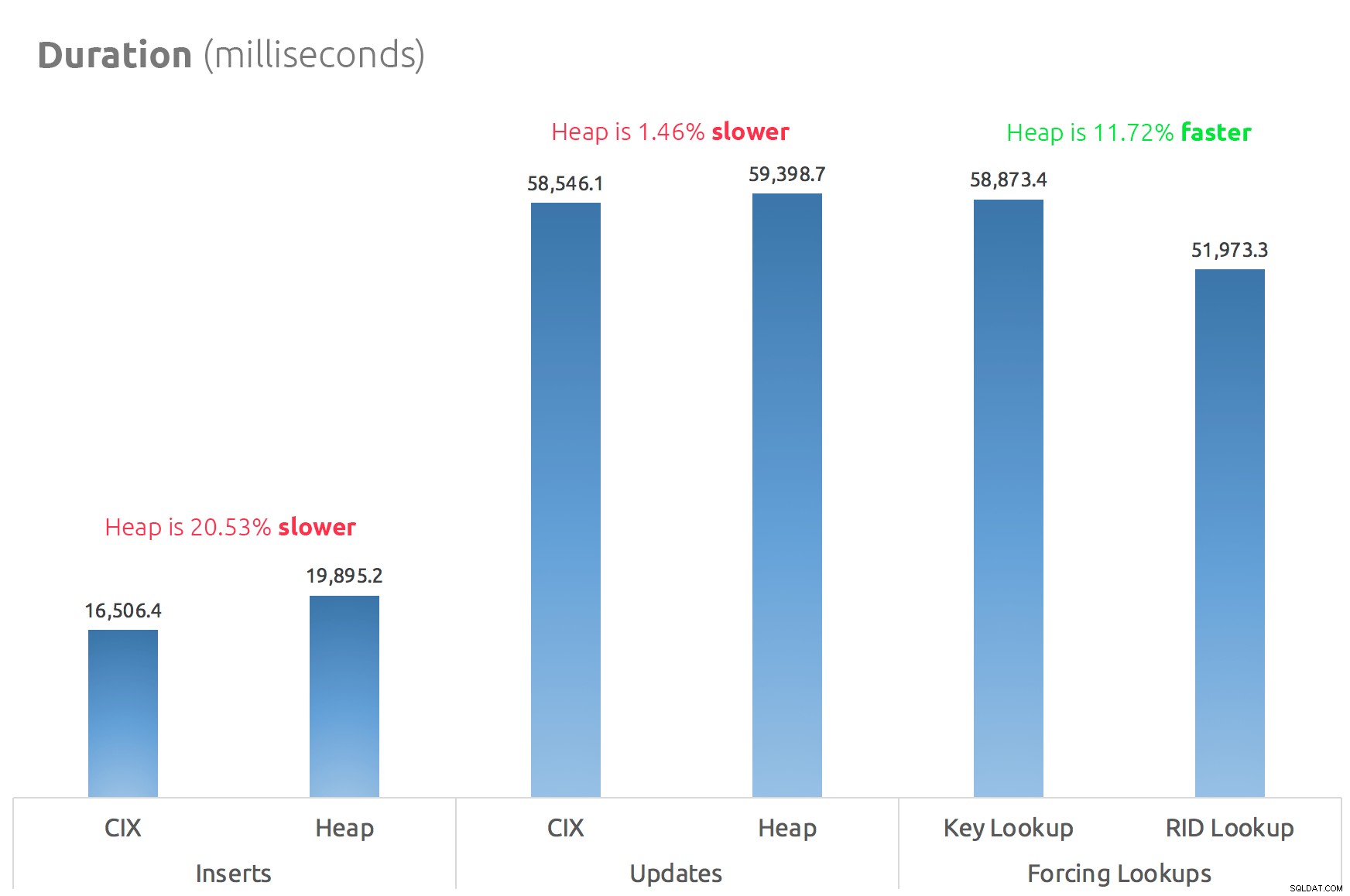
निष्कर्ष
तो, अफवाहें सच हैं:इस मामले में कम से कम, एक आरआईडी लुकअप एक कुंजी लुकअप की तुलना में काफी तेज है। सीधे फ़ाइल पर जाना:पृष्ठ:स्लॉट बी-ट्री का अनुसरण करने की तुलना में I/O के संदर्भ में स्पष्ट रूप से अधिक कुशल है (और यदि आप आधुनिक भंडारण पर नहीं हैं, तो डेल्टा अधिक ध्यान देने योग्य हो सकता है)।
आप इसका लाभ उठाना चाहते हैं, और ढेर के अन्य सभी पहलुओं को साथ लाना चाहते हैं, यह आपके कार्यभार पर निर्भर करेगा - लेखन कार्यों के लिए ढेर थोड़ा अधिक महंगा है। लेकिन यह नहीं है निश्चित - यह तालिका संरचना, अनुक्रमणिका और पहुंच पैटर्न के आधार पर बहुत भिन्न हो सकता है।
मैंने यहां बहुत ही सरल चीजों का परीक्षण किया है, और यदि आप इसके बारे में बाड़ पर हैं, तो मैं अत्यधिक अनुशंसा करता हूं कि आप अपने हार्डवेयर पर अपने वास्तविक कार्यभार का परीक्षण करें और अपने लिए तुलना करें (और उसी कार्यभार का परीक्षण करना न भूलें जहां कवरिंग इंडेक्स मौजूद हैं; यदि आप केवल लुकअप को पूरी तरह से समाप्त कर सकते हैं तो आप शायद बेहतर समग्र प्रदर्शन प्राप्त करेंगे)। आपके लिए महत्वपूर्ण सभी मीट्रिक को मापना सुनिश्चित करें; सिर्फ इसलिए कि मैं अवधि पर ध्यान केंद्रित करता हूं इसका मतलब यह नहीं है कि आपको इसकी सबसे अधिक देखभाल करने की आवश्यकता है। :-)