इस लेख में, मैं मांग चुनौती के साथ पीटर लार्सन की आकर्षक मिलान आपूर्ति के समाधानों का कवरेज जारी रखता हूं। अपने समाधान भेजने के लिए लुका, कामिल कोस्नो, डैनियल ब्राउन, ब्रायन वॉकर, जो ओबिश, रेनर हॉफमैन, पॉल व्हाइट, चार्ली और पीटर लार्सन को फिर से धन्यवाद।
पिछले महीने मैंने एक क्लासिक विधेय-आधारित अंतराल चौराहे परीक्षण का उपयोग करते हुए, अंतराल चौराहों के आधार पर एक समाधान को कवर किया। मैं उस समाधान का उल्लेख क्लासिक चौराहों . के रूप में करूंगा . क्लासिक अंतराल चौराहों का परिणाम द्विघात स्केलिंग (एन ^ 2) के साथ एक योजना में होता है। मैंने 100K से 400K पंक्तियों तक के नमूना इनपुट के खिलाफ इसके खराब प्रदर्शन का प्रदर्शन किया। 400K-पंक्ति इनपुट के विरुद्ध समाधान को पूरा करने में 931 सेकंड का समय लगा! इस महीने की शुरुआत मैं आपको संक्षेप में पिछले महीने के समाधान की याद दिलाकर करूँगा कि यह इतना खराब क्यों है और इसका प्रदर्शन क्यों है। फिर मैं अंतराल प्रतिच्छेदन परीक्षण में संशोधन के आधार पर एक दृष्टिकोण का परिचय दूंगा। इस दृष्टिकोण का उपयोग लुका, कामिल और संभवतः डैनियल द्वारा भी किया गया था, और यह बेहतर प्रदर्शन और स्केलिंग के साथ समाधान को सक्षम बनाता है। मैं उस समाधान को संशोधित चौराहे . के रूप में संदर्भित करूंगा ।
क्लासिक इंटरसेक्शन टेस्ट की समस्या
आइए पिछले महीने के समाधान के त्वरित अनुस्मारक के साथ शुरुआत करें।
मैंने इनपुट डीबीओ पर निम्नलिखित इंडेक्स का इस्तेमाल किया। नीलामी तालिका मांग और आपूर्ति अंतराल उत्पन्न करने वाले चल रहे योगों की गणना का समर्थन करने के लिए:
-- Index to support solution CREATE UNIQUE NONCLUSTERED INDEX idx_Code_ID_i_Quantity ON dbo.Auctions(Code, ID) INCLUDE(Quantity); -- Enable batch-mode Window Aggregate CREATE NONCLUSTERED COLUMNSTORE INDEX idx_cs ON dbo.Auctions(ID) WHERE ID = -1 AND ID = -2;
निम्नलिखित कोड में क्लासिक अंतराल चौराहों के दृष्टिकोण को लागू करने का पूरा समाधान है:
-- Drop temp tables if exist
SET NOCOUNT ON;
DROP TABLE IF EXISTS #MyPairings, #Demand, #Supply;
GO
WITH D0 AS
-- D0 computes running demand as EndDemand
(
SELECT ID, Quantity,
SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndDemand
FROM dbo.Auctions
WHERE Code = 'D'
),
-- D extracts prev EndDemand as StartDemand, expressing start-end demand as an interval
D AS
(
SELECT ID, Quantity, EndDemand - Quantity AS StartDemand, EndDemand
FROM D0
)
SELECT ID,
CAST(ISNULL(StartDemand, 0.0) AS DECIMAL(19, 6)) AS StartDemand,
CAST(ISNULL(EndDemand, 0.0) AS DECIMAL(19, 6)) AS EndDemand
INTO #Demand
FROM D;
WITH S0 AS
-- S0 computes running supply as EndSupply
(
SELECT ID, Quantity,
SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndSupply
FROM dbo.Auctions
WHERE Code = 'S'
),
-- S extracts prev EndSupply as StartSupply, expressing start-end supply as an interval
S AS
(
SELECT ID, Quantity, EndSupply - Quantity AS StartSupply, EndSupply
FROM S0
)
SELECT ID,
CAST(ISNULL(StartSupply, 0.0) AS DECIMAL(19, 6)) AS StartSupply,
CAST(ISNULL(EndSupply, 0.0) AS DECIMAL(19, 6)) AS EndSupply
INTO #Supply
FROM S;
CREATE UNIQUE CLUSTERED INDEX idx_cl_ES_ID ON #Supply(EndSupply, ID);
-- Trades are the overlapping segments of the intersecting intervals
SELECT
D.ID AS DemandID, S.ID AS SupplyID,
CASE WHEN EndDemand < EndSupply THEN EndDemand ELSE EndSupply END - CASE WHEN StartDemand > StartSupply THEN StartDemand ELSE StartSupply END
AS TradeQuantity
INTO #MyPairings
FROM #Demand AS D
INNER JOIN #Supply AS S WITH (FORCESEEK)
ON D.StartDemand < S.EndSupply AND D.EndDemand > S.StartSupply; पर डी इनर जॉइन #सप्लाई एस विद (फोरसेसीक) की मांग यह कोड मांग और आपूर्ति अंतराल की गणना करके शुरू होता है और उन्हें #Demand और #Supply नामक अस्थायी तालिकाओं में लिखता है। कोड तब #Supply पर एक क्लस्टर इंडेक्स बनाता है, जिसमें EndSupply प्रमुख कुंजी के रूप में होता है ताकि इंटरसेक्शन टेस्ट को यथासंभव बेहतर तरीके से सपोर्ट किया जा सके। अंत में, कोड #सप्लाई और #डिमांड को जोड़ता है, ट्रेडों को इंटरसेक्टिंग अंतराल के ओवरलैपिंग सेगमेंट के रूप में पहचानता है, क्लासिक इंटरवल इंटरसेक्शन टेस्ट के आधार पर निम्नलिखित जॉइन विधेय का उपयोग करता है:
D.StartDemand < S.EndSupply AND D.EndDemand > S.StartSupply
इस समाधान की योजना चित्र 1 में दिखाई गई है।
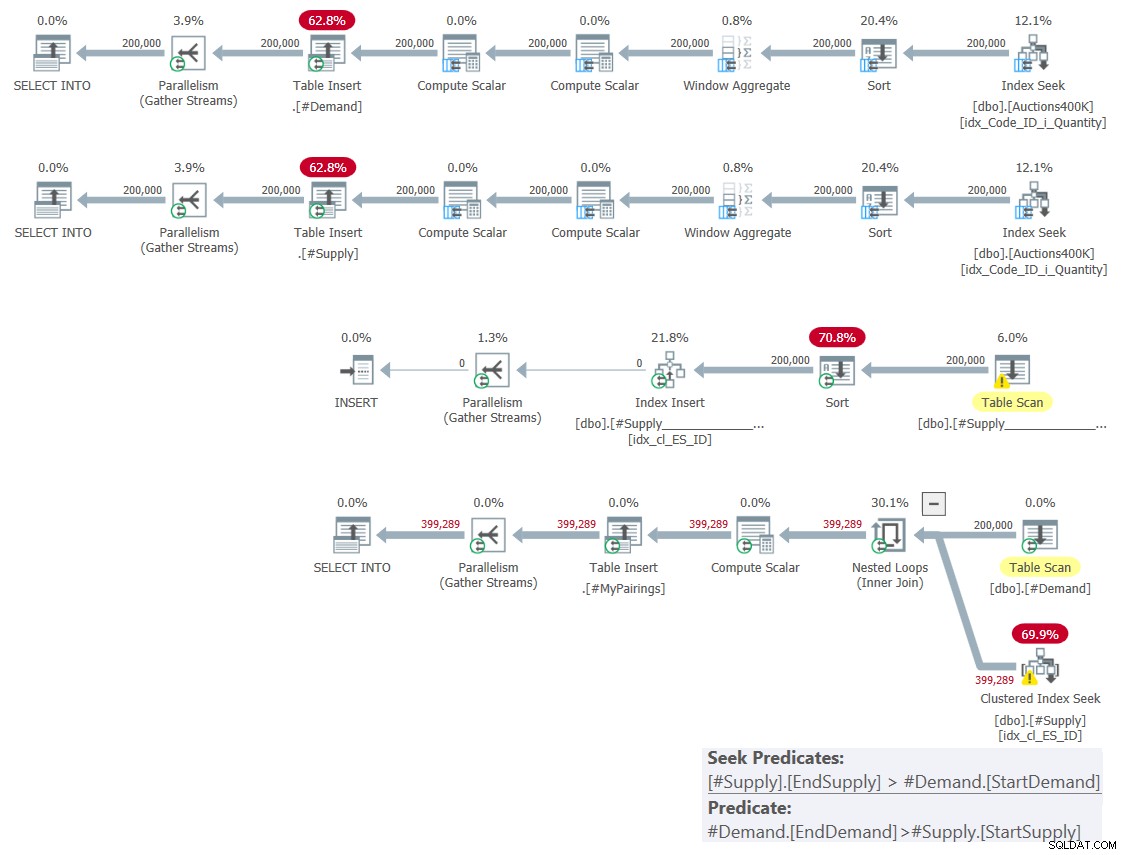 चित्र 1:क्लासिक चौराहों पर आधारित समाधान के लिए क्वेरी योजना
चित्र 1:क्लासिक चौराहों पर आधारित समाधान के लिए क्वेरी योजना
जैसा कि मैंने पिछले महीने समझाया था, इसमें शामिल दो रेंज विधेय में से केवल एक का उपयोग इंडेक्स सीक ऑपरेशन के हिस्से के रूप में एक खोज विधेय के रूप में किया जा सकता है, जबकि दूसरे को अवशिष्ट विधेय के रूप में लागू किया जाना है। आप इसे चित्र 1 में अंतिम क्वेरी के लिए योजना में स्पष्ट रूप से देख सकते हैं। इसलिए मैंने केवल एक टेबल पर एक इंडेक्स बनाने की जहमत उठाई। मैंने FORCESEEK संकेत का उपयोग करके बनाए गए इंडेक्स में एक तलाश के उपयोग को भी मजबूर किया। अन्यथा, ऑप्टिमाइज़र उस इंडेक्स को अनदेखा कर सकता है और इंडेक्स स्पूल ऑपरेटर का उपयोग करके अपना खुद का एक इंडेक्स बना सकता है।
इस योजना में एक तरफ प्रति पंक्ति के बाद से द्विघात जटिलता है-#हमारे मामले में मांग-सूचकांक की तलाश को दूसरी तरफ औसत आधी पंक्तियों तक पहुंचना होगा-#हमारे मामले में आपूर्ति-खोज विधेय के आधार पर, और पहचानें अवशिष्ट विधेय को लागू करके अंतिम मैच।
यदि यह अभी भी आपके लिए स्पष्ट नहीं है कि इस योजना में द्विघात जटिलता क्यों है, तो शायद कार्य का एक दृश्य चित्रण मदद कर सकता है, जैसा कि चित्र 2 में दिखाया गया है।
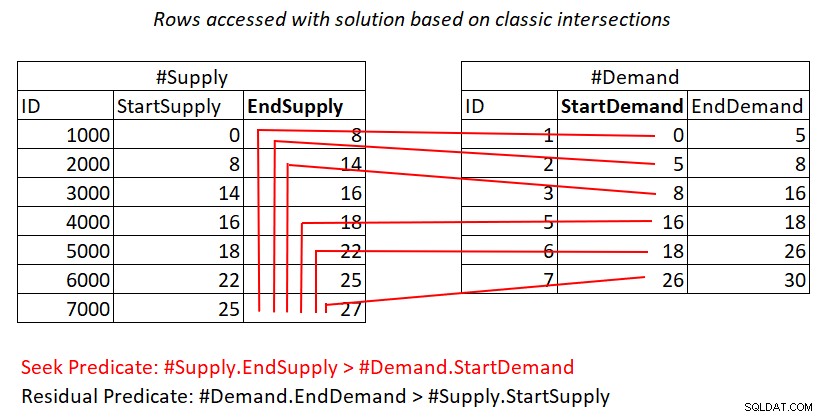 चित्र 2:क्लासिक चौराहों पर आधारित समाधान के साथ कार्य का चित्रण
चित्र 2:क्लासिक चौराहों पर आधारित समाधान के साथ कार्य का चित्रण
यह चित्रण नेस्टेड लूप्स द्वारा अंतिम क्वेरी के लिए योजना में शामिल किए गए कार्य का प्रतिनिधित्व करता है। #Demand हीप जॉइन का बाहरी इनपुट है और #Supply पर क्लस्टर्ड इंडेक्स (EndSupply के साथ प्रमुख कुंजी के रूप में) आंतरिक इनपुट है। लाल रेखाएं # आपूर्ति पर सूचकांक में #Demand में प्रति पंक्ति की गई अनुक्रमणिका खोज गतिविधियों का प्रतिनिधित्व करती हैं और वे पंक्तियाँ जिन्हें वे इंडेक्स लीफ में रेंज स्कैन के हिस्से के रूप में एक्सेस करते हैं। #Demand में अत्यधिक निम्न StartDemand मानों की ओर, रेंज स्कैन को #Supply में सभी पंक्तियों तक पहुंचने की आवश्यकता है। #Demand में अत्यधिक उच्च StartDemand मानों की ओर, रेंज स्कैन को #Supply में लगभग शून्य पंक्तियों तक पहुंचने की आवश्यकता है। औसतन, रेंज स्कैन को मांग में #सप्लाई प्रति पंक्ति में लगभग आधी पंक्तियों तक पहुंचने की आवश्यकता होती है। डी मांग पंक्तियों और एस आपूर्ति पंक्तियों के साथ, एक्सेस की गई पंक्तियों की संख्या डी + डी * एस / 2 है। यह उन खोजों की लागत के अतिरिक्त है जो आपको मिलती-जुलती पंक्तियों तक ले जाती हैं। उदाहरण के लिए, 200,000 मांग पंक्तियों और 200,000 आपूर्ति पंक्तियों के साथ dbo.नीलामी भरते समय, यह नेस्टेड लूप्स में 200,000 मांग पंक्तियों + 200,000*200,000/2 आपूर्ति पंक्तियों, या 200,000 + 200,000^2/2 =20,000,200,000 पंक्तियों तक पहुँचने में शामिल हो जाता है। यहां आपूर्ति पंक्तियों की बहुत अधिक पुन:स्कैनिंग हो रही है!
यदि आप अंतराल चौराहों के विचार से चिपके रहना चाहते हैं, लेकिन अच्छा प्रदर्शन प्राप्त करना चाहते हैं, तो आपको किए गए काम की मात्रा को कम करने के लिए एक तरीके के साथ आने की जरूरत है।
अपने समाधान में, जो ओबिश ने अधिकतम अंतराल लंबाई के आधार पर अंतराल को बकेट किया। इस तरह वह उन पंक्तियों की संख्या को कम करने में सक्षम था जो जुड़ने के लिए आवश्यक हैं और बैच प्रोसेसिंग पर भरोसा करते हैं। उन्होंने क्लासिक इंटरवल इंटरसेक्शन टेस्ट को अंतिम फिल्टर के रूप में इस्तेमाल किया। जो का समाधान तब तक अच्छा काम करता है जब तक कि अधिकतम अंतराल की लंबाई बहुत अधिक न हो, लेकिन अधिकतम अंतराल की लंबाई बढ़ने पर समाधान का रनटाइम बढ़ता है।
तो, आप और क्या कर सकते हैं…?
संशोधित इंटरसेक्शन टेस्ट
लुका, कामिल, और संभवतः डैनियल (वेबसाइट के स्वरूपण के कारण उनके पोस्ट किए गए समाधान के बारे में एक अस्पष्ट हिस्सा था, इसलिए मुझे अनुमान लगाना पड़ा) एक संशोधित अंतराल चौराहे परीक्षण का उपयोग किया जो अनुक्रमण के बेहतर उपयोग को सक्षम बनाता है।
उनका प्रतिच्छेदन परीक्षण दो विधेय (OR ऑपरेटर द्वारा अलग किए गए विधेय) का एक संयोजन है:
(D.StartDemand >= S.StartSupply AND D.StartDemand < S.EndSupply) OR (S.StartSupply >= D.StartDemand AND S.StartSupply < D.EndDemand)
अंग्रेजी में, या तो मांग प्रारंभ सीमांकक एक समावेशी, अनन्य तरीके से आपूर्ति अंतराल के साथ प्रतिच्छेद करता है (शुरुआत सहित और अंत को छोड़कर); या आपूर्ति प्रारंभ सीमांकक समावेशी, अनन्य तरीके से मांग अंतराल के साथ प्रतिच्छेद करता है। दो विधेय को असंबद्ध बनाने के लिए (ओवरलैपिंग मामले नहीं हैं) अभी भी सभी मामलों को कवर करने में पूर्ण हैं, आप =ऑपरेटर को केवल एक या दूसरे में रख सकते हैं, उदाहरण के लिए:
(D.StartDemand >= S.StartSupply AND D.StartDemand < S.EndSupply) OR (S.StartSupply > D.StartDemand AND S.StartSupply < D.EndDemand)
यह संशोधित अंतराल प्रतिच्छेदन परीक्षण काफी व्यावहारिक है। प्रत्येक भविष्यवाणी संभावित रूप से एक सूचकांक का कुशलता से उपयोग कर सकती है। विधेय 1 पर विचार करें:
D.StartDemand >= S.StartSupply AND D.StartDemand < S.EndSupply ^^^^^^^^^^^^^ ^^^^^^^^^^^^^
यह मानते हुए कि आप #Demand पर StartDemand के साथ एक प्रमुख कुंजी के रूप में एक कवरिंग इंडेक्स बनाते हैं, आप संभावित रूप से चित्र 3 में दिखाए गए कार्य को लागू करने के लिए नेस्टेड लूप्स में शामिल हो सकते हैं।
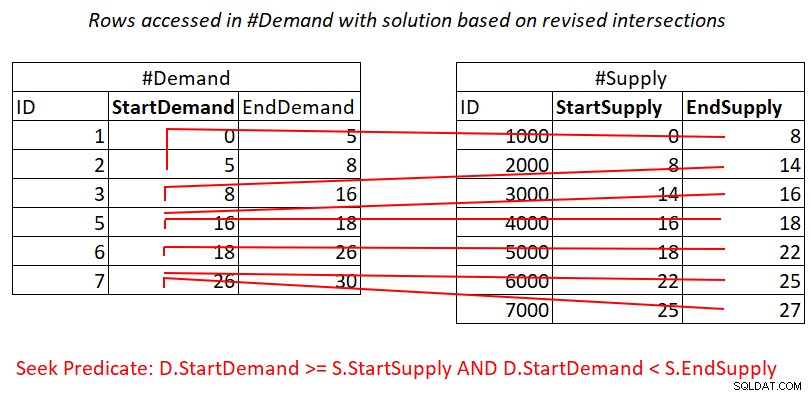
चित्र 3:विधेय को संसाधित करने के लिए आवश्यक सैद्धांतिक कार्य का चित्रण 1
हां, आप अभी भी #सप्लाई में #Demand अनुक्रमणिका प्रति पंक्ति में एक खोज के लिए भुगतान करते हैं, लेकिन अनुक्रमणिका लीफ़ में रेंज स्कैन पंक्तियों के लगभग असंबद्ध उपसमुच्चय तक पहुँचती है। पंक्तियों की कोई पुन:स्कैनिंग नहीं!
विधेय 2 के साथ स्थिति समान है:
S.StartSupply > D.StartDemand AND S.StartSupply < D.EndDemand ^^^^^^^^^^^^^ ^^^^^^^^^^^^^
यह मानते हुए कि आप #Supply पर StartSupply के साथ एक प्रमुख कुंजी के रूप में एक कवरिंग इंडेक्स बनाते हैं, आप संभावित रूप से चित्र 4 में दिखाए गए कार्य को लागू करने के लिए नेस्टेड लूप्स में शामिल हो सकते हैं।
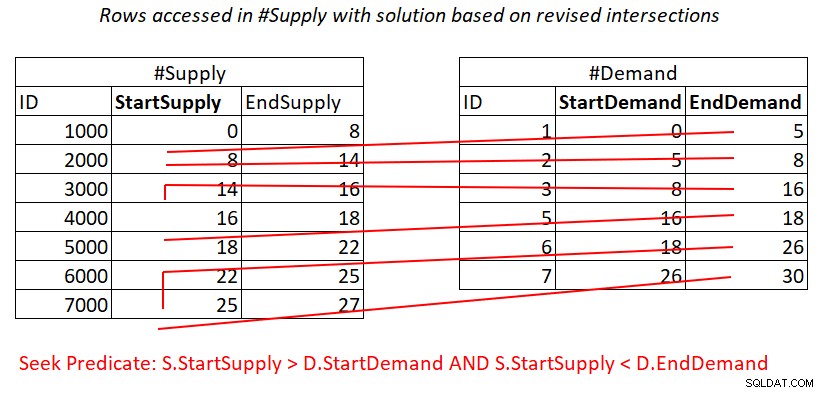
चित्र 4:विधेय को संसाधित करने के लिए आवश्यक सैद्धांतिक कार्य का चित्रण 2
इसके अलावा, यहां आप #Demand में #सप्लाई इंडेक्स प्रति पंक्ति में एक खोज के लिए भुगतान करते हैं, और फिर इंडेक्स लीफ एक्सेस में रेंज स्कैन लगभग पंक्तियों के सबसे अलग उपसमुच्चय तक पहुंचती है। फिर से, पंक्तियों की कोई पुन:स्कैनिंग नहीं!
डी मांग पंक्तियों और एस आपूर्ति पंक्तियों को मानते हुए, कार्य को इस प्रकार वर्णित किया जा सकता है:
Number of index seek operations: D + S Number of rows accessed: 2D + 2S
तो संभावना है, यहां लागत का सबसे बड़ा हिस्सा मांग के साथ शामिल I/O लागत है। लेकिन काम के इस हिस्से में क्लासिक अंतराल चौराहे क्वेरी के द्विघात स्केलिंग की तुलना में रैखिक स्केलिंग है।
बेशक, आपको अस्थायी तालिकाओं पर सूचकांक निर्माण की प्रारंभिक लागत पर विचार करने की आवश्यकता है, जिसमें शामिल छँटाई के कारण n लॉग n स्केलिंग है, लेकिन आप इस हिस्से को दोनों समाधानों के प्रारंभिक भाग के रूप में भुगतान करते हैं।
आइए इस सिद्धांत को व्यवहार में लाने का प्रयास करें। आइए #Demand और #supply अस्थायी तालिकाओं को मांग और आपूर्ति अंतराल (क्लासिक अंतराल चौराहों के समान) के साथ पॉप्युलेट करके और सहायक अनुक्रमणिका बनाकर शुरू करें:
-- Drop temp tables if exist
SET NOCOUNT ON;
DROP TABLE IF EXISTS #MyPairings, #Demand, #Supply;
GO
WITH D0 AS
-- D0 computes running demand as EndDemand
(
SELECT ID, Quantity,
SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndDemand
FROM dbo.Auctions
WHERE Code = 'D'
),
-- D extracts prev EndDemand as StartDemand, expressing start-end demand as an interval
D AS
(
SELECT ID, Quantity, EndDemand - Quantity AS StartDemand, EndDemand
FROM D0
)
SELECT ID,
CAST(ISNULL(StartDemand, 0.0) AS DECIMAL(19, 6)) AS StartDemand,
CAST(ISNULL(EndDemand, 0.0) AS DECIMAL(19, 6)) AS EndDemand
INTO #Demand
FROM D;
WITH S0 AS
-- S0 computes running supply as EndSupply
(
SELECT ID, Quantity,
SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndSupply
FROM dbo.Auctions
WHERE Code = 'S'
),
-- S extracts prev EndSupply as StartSupply, expressing start-end supply as an interval
S AS
(
SELECT ID, Quantity, EndSupply - Quantity AS StartSupply, EndSupply
FROM S0
)
SELECT ID,
CAST(ISNULL(StartSupply, 0.0) AS DECIMAL(19, 6)) AS StartSupply,
CAST(ISNULL(EndSupply, 0.0) AS DECIMAL(19, 6)) AS EndSupply
INTO #Supply
FROM S;
-- Indexing
CREATE UNIQUE CLUSTERED INDEX idx_cl_SD_ID ON #Demand(StartDemand, ID);
CREATE UNIQUE CLUSTERED INDEX idx_cl_SS_ID ON #Supply(StartSupply, ID); अस्थायी तालिकाओं को भरने और अनुक्रमणिका बनाने की योजना चित्र 5 में दिखाई गई है।
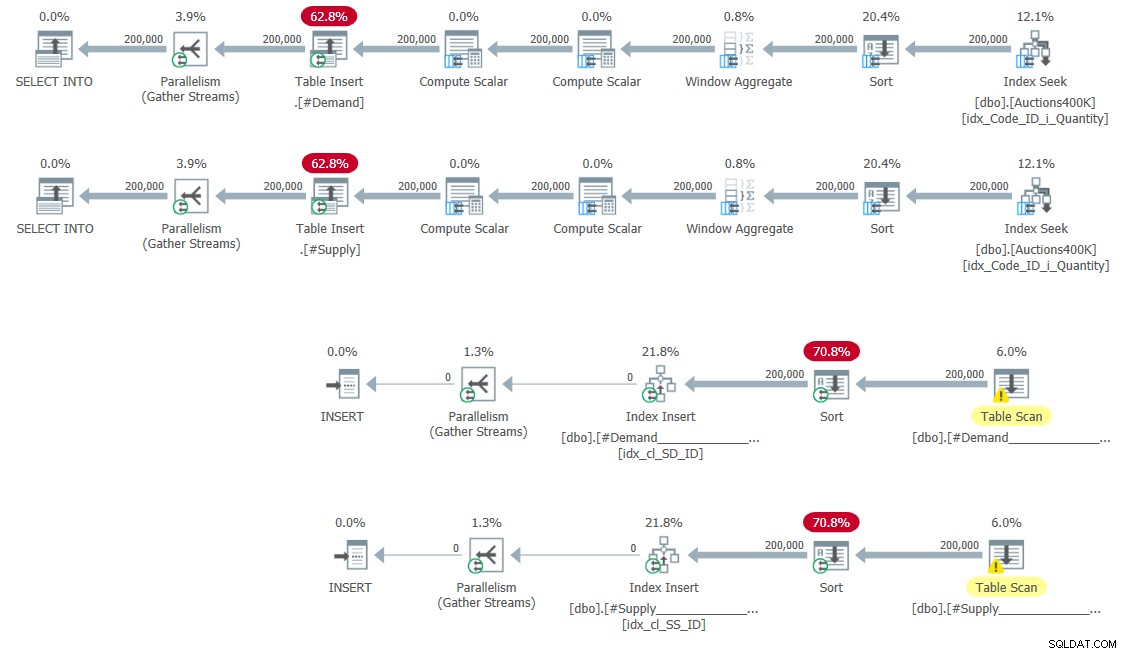
चित्र 5:अस्थायी तालिकाओं को भरने और बनाने के लिए क्वेरी योजनाएं अनुक्रमणिका
यहाँ कोई आश्चर्य की बात नहीं है।
अब अंतिम प्रश्न पर। आप दो विधेय के पूर्वोक्त संयोजन के साथ एकल क्वेरी का उपयोग करने के लिए ललचा सकते हैं, जैसे:
SELECT
D.ID AS DemandID, S.ID AS SupplyID,
CASE WHEN EndDemand < EndSupply THEN EndDemand ELSE EndSupply END - CASE WHEN StartDemand > StartSupply THEN StartDemand ELSE StartSupply END
AS TradeQuantity
INTO #MyPairings
FROM #Demand AS D
INNER JOIN #Supply AS S
ON (D.StartDemand >= S.StartSupply AND D.StartDemand < S.EndSupply) OR (S.StartSupply > D.StartDemand AND S.StartSupply < D.EndDemand); इस क्वेरी की योजना चित्र 6 में दिखाई गई है।
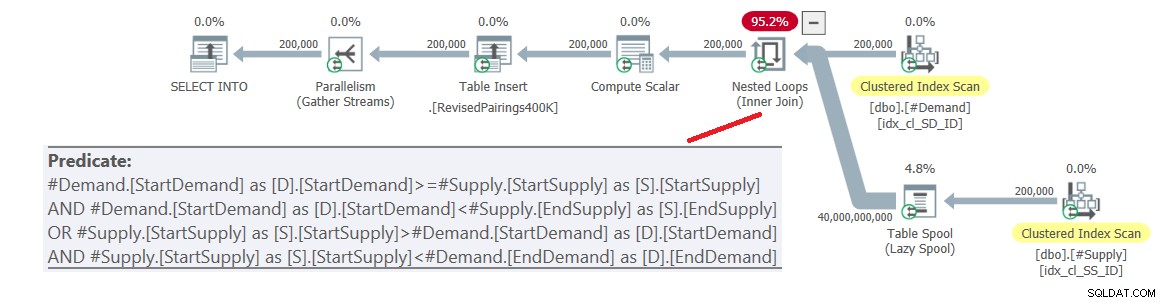
चित्र 6:संशोधित चौराहे का उपयोग करके अंतिम क्वेरी के लिए क्वेरी योजना परीक्षण करें, 1 प्रयास करें
समस्या यह है कि अनुकूलक यह नहीं जानता कि इस तर्क को दो अलग-अलग गतिविधियों में कैसे विभाजित किया जाए, प्रत्येक एक अलग विधेय को संभालता है और संबंधित सूचकांक का कुशलता से उपयोग करता है। तो, यह दोनों पक्षों के एक पूर्ण कार्टेशियन उत्पाद के साथ समाप्त होता है, सभी विधेय को अवशिष्ट विधेय के रूप में लागू करता है। 200,000 मांग पंक्तियों और 200,000 आपूर्ति पंक्तियों के साथ, जॉइन 40,000,000,000 पंक्तियों को संसाधित करता है।
लुका, कामिल और संभवतः डैनियल द्वारा उपयोग की जाने वाली अंतर्दृष्टिपूर्ण चाल तर्क को दो प्रश्नों में तोड़ना था, उनके परिणामों को एकीकृत करना था। यहीं पर दो असंबद्ध विधेय का उपयोग करना महत्वपूर्ण हो जाता है! डुप्लिकेट की तलाश की अनावश्यक लागत से बचने के लिए, आप UNION के बजाय UNION ALL ऑपरेटर का उपयोग कर सकते हैं। इस दृष्टिकोण को लागू करने वाली क्वेरी यहां दी गई है:
SELECT
D.ID AS DemandID, S.ID AS SupplyID,
CASE WHEN EndDemand < EndSupply THEN EndDemand ELSE EndSupply END - CASE WHEN StartDemand > StartSupply THEN StartDemand ELSE StartSupply END
AS TradeQuantity
INTO #MyPairings
FROM #Demand AS D
INNER JOIN #Supply AS S
ON D.StartDemand >= S.StartSupply AND D.StartDemand < S.EndSupply
UNION ALL
SELECT
D.ID AS DemandID, S.ID AS SupplyID,
CASE WHEN EndDemand < EndSupply THEN EndDemand ELSE EndSupply END - CASE WHEN StartDemand > StartSupply THEN StartDemand ELSE StartSupply END
AS TradeQuantity
FROM #Demand AS D
INNER JOIN #Supply AS S
ON S.StartSupply > D.StartDemand AND S.StartSupply < D.EndDemand; इस क्वेरी की योजना चित्र 7 में दिखाई गई है।
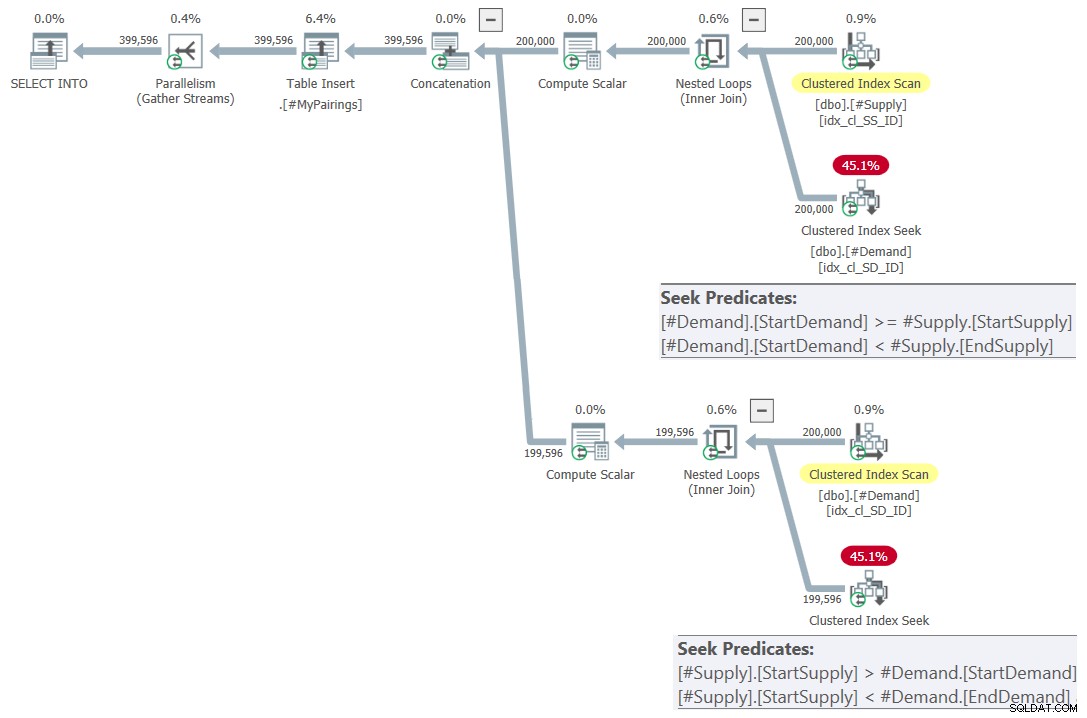
चित्र 7:संशोधित चौराहे का उपयोग करके अंतिम क्वेरी के लिए क्वेरी योजना परीक्षण करें, 2 प्रयास करें
यह सिर्फ सुंदर है! है न? और क्योंकि यह बहुत सुंदर है, यहां शुरुआत से संपूर्ण समाधान है, जिसमें अस्थायी तालिकाओं का निर्माण, अनुक्रमण, और अंतिम क्वेरी शामिल है:
-- Drop temp tables if exist
SET NOCOUNT ON;
DROP TABLE IF EXISTS #MyPairings, #Demand, #Supply;
GO
WITH D0 AS
-- D0 computes running demand as EndDemand
(
SELECT ID, Quantity,
SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndDemand
FROM dbo.Auctions
WHERE Code = 'D'
),
-- D extracts prev EndDemand as StartDemand, expressing start-end demand as an interval
D AS
(
SELECT ID, Quantity, EndDemand - Quantity AS StartDemand, EndDemand
FROM D0
)
SELECT ID,
CAST(ISNULL(StartDemand, 0.0) AS DECIMAL(19, 6)) AS StartDemand,
CAST(ISNULL(EndDemand, 0.0) AS DECIMAL(19, 6)) AS EndDemand
INTO #Demand
FROM D;
WITH S0 AS
-- S0 computes running supply as EndSupply
(
SELECT ID, Quantity,
SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndSupply
FROM dbo.Auctions
WHERE Code = 'S'
),
-- S extracts prev EndSupply as StartSupply, expressing start-end supply as an interval
S AS
(
SELECT ID, Quantity, EndSupply - Quantity AS StartSupply, EndSupply
FROM S0
)
SELECT ID,
CAST(ISNULL(StartSupply, 0.0) AS DECIMAL(19, 6)) AS StartSupply,
CAST(ISNULL(EndSupply, 0.0) AS DECIMAL(19, 6)) AS EndSupply
INTO #Supply
FROM S;
-- Indexing
CREATE UNIQUE CLUSTERED INDEX idx_cl_SD_ID ON #Demand(StartDemand, ID);
CREATE UNIQUE CLUSTERED INDEX idx_cl_SS_ID ON #Supply(StartSupply, ID);
-- Trades are the overlapping segments of the intersecting intervals
SELECT
D.ID AS DemandID, S.ID AS SupplyID,
CASE WHEN EndDemand < EndSupply THEN EndDemand ELSE EndSupply END - CASE WHEN StartDemand > StartSupply THEN StartDemand ELSE StartSupply END
AS TradeQuantity
INTO #MyPairings
FROM #Demand AS D
INNER JOIN #Supply AS S
ON D.StartDemand >= S.StartSupply AND D.StartDemand < S.EndSupply
UNION ALL
SELECT
D.ID AS DemandID, S.ID AS SupplyID,
CASE WHEN EndDemand < EndSupply THEN EndDemand ELSE EndSupply END - CASE WHEN StartDemand > StartSupply THEN StartDemand ELSE StartSupply END
AS TradeQuantity
FROM #Demand AS D
INNER JOIN #Supply AS S
ON S.StartSupply > D.StartDemand AND S.StartSupply < D.EndDemand; जैसा कि पहले उल्लेख किया गया है, मैं इस समाधान को संशोधित चौराहे . के रूप में संदर्भित करूंगा ।
कामिल का समाधान
लुका, कामिल और डैनियल के समाधानों के बीच, कामिल सबसे तेज़ था। पेश है कामिल का पूरा समाधान:
SET NOCOUNT ON;
DROP TABLE IF EXISTS #supply, #demand;
GO
CREATE TABLE #demand
(
DemandID INT NOT NULL,
DemandQuantity DECIMAL(19, 6) NOT NULL,
QuantityFromDemand DECIMAL(19, 6) NOT NULL,
QuantityToDemand DECIMAL(19, 6) NOT NULL
);
CREATE TABLE #supply
(
SupplyID INT NOT NULL,
QuantityFromSupply DECIMAL(19, 6) NOT NULL,
QuantityToSupply DECIMAL(19,6) NOT NULL
);
WITH demand AS
(
SELECT
a.ID AS DemandID,
a.Quantity AS DemandQuantity,
SUM(a.Quantity) OVER(ORDER BY ID ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
- a.Quantity AS QuantityFromDemand,
SUM(a.Quantity) OVER(ORDER BY ID ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
AS QuantityToDemand
FROM dbo.Auctions AS a WHERE Code = 'D'
)
INSERT INTO #demand
(
DemandID,
DemandQuantity,
QuantityFromDemand,
QuantityToDemand
)
SELECT
d.DemandID,
d.DemandQuantity,
d.QuantityFromDemand,
d.QuantityToDemand
FROM demand AS d;
WITH supply AS
(
SELECT
a.ID AS SupplyID,
SUM(a.Quantity) OVER(ORDER BY ID ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
- a.Quantity AS QuantityFromSupply,
SUM(a.Quantity) OVER(ORDER BY ID ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
AS QuantityToSupply
FROM dbo.Auctions AS a WHERE Code = 'S'
)
INSERT INTO #supply
(
SupplyID,
QuantityFromSupply,
QuantityToSupply
)
SELECT
s.SupplyID,
s.QuantityFromSupply,
s.QuantityToSupply
FROM supply AS s;
CREATE UNIQUE INDEX ix_1 ON #demand(QuantityFromDemand)
INCLUDE(DemandID, DemandQuantity, QuantityToDemand);
CREATE UNIQUE INDEX ix_1 ON #supply(QuantityFromSupply)
INCLUDE(SupplyID, QuantityToSupply);
CREATE NONCLUSTERED COLUMNSTORE INDEX nci ON #demand(DemandID)
WHERE DemandID is null;
DROP TABLE IF EXISTS #myPairings;
CREATE TABLE #myPairings
(
DemandID INT NOT NULL,
SupplyID INT NOT NULL,
TradeQuantity DECIMAL(19, 6) NOT NULL
);
INSERT INTO #myPairings(DemandID, SupplyID, TradeQuantity)
SELECT
d.DemandID,
s.SupplyID,
d.DemandQuantity
- CASE WHEN d.QuantityFromDemand < s.QuantityFromSupply
THEN s.QuantityFromSupply - d.QuantityFromDemand ELSE 0 end
- CASE WHEN s.QuantityToSupply < d.QuantityToDemand
THEN d.QuantityToDemand - s.QuantityToSupply ELSE 0 END AS TradeQuantity
FROM #demand AS d
INNER JOIN #supply AS s
ON (d.QuantityFromDemand < s.QuantityToSupply
AND s.QuantityFromSupply <= d.QuantityFromDemand)
UNION ALL
SELECT
d.DemandID,
s.SupplyID,
d.DemandQuantity
- CASE WHEN d.QuantityFromDemand < s.QuantityFromSupply
THEN s.QuantityFromSupply - d.QuantityFromDemand ELSE 0 END
- CASE WHEN s.QuantityToSupply < d.QuantityToDemand
THEN d.QuantityToDemand - s.QuantityToSupply ELSE 0 END AS TradeQuantity
FROM #supply AS s
INNER JOIN #demand AS d
ON (s.QuantityFromSupply < d.QuantityToDemand
AND d.QuantityFromDemand < s.QuantityFromSupply); जैसा कि आप देख सकते हैं, यह मेरे द्वारा कवर किए गए संशोधित चौराहों के समाधान के बहुत करीब है।
कामिल के समाधान में अंतिम प्रश्न की योजना चित्र 8 में दिखाई गई है।
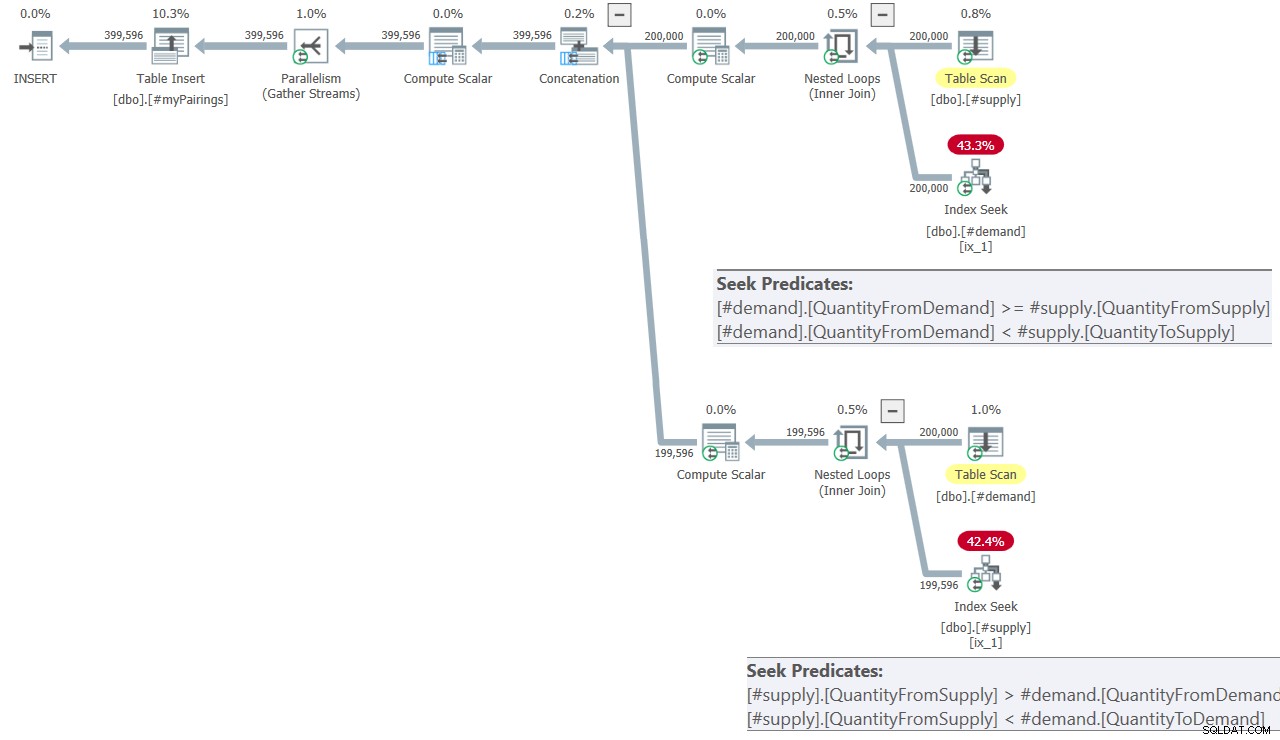
चित्र 8:कामिल के समाधान में अंतिम प्रश्न के लिए प्रश्न योजना
यह योजना पहले चित्र 7 में दिखाए गए के समान ही दिखती है।
प्रदर्शन परीक्षण
याद रखें कि क्लासिक चौराहों के समाधान को 400K पंक्तियों के साथ एक इनपुट के मुकाबले पूरा करने में 931 सेकंड का समय लगा। वह 15 मिनट है! यह कर्सर समाधान की तुलना में बहुत अधिक खराब है, जिसे उसी इनपुट के विरुद्ध पूरा करने में लगभग 12 सेकंड का समय लगा। चित्र 9 में इस आलेख में चर्चा किए गए नए समाधानों सहित प्रदर्शन संख्याएं हैं।
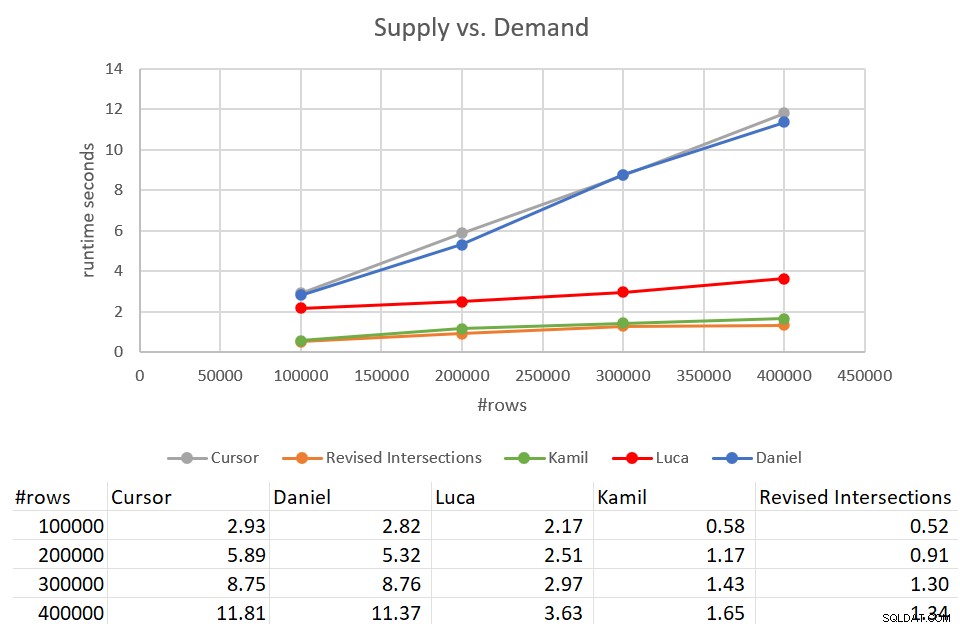
चित्र 9:प्रदर्शन परीक्षण
जैसा कि आप देख सकते हैं, कामिल के समाधान और इसी तरह के संशोधित चौराहे समाधान को 400K-पंक्ति इनपुट के मुकाबले पूरा करने में लगभग 1.5 सेकंड का समय लगा। मूल कर्सर-आधारित समाधान की तुलना में यह एक बहुत अच्छा सुधार है। इन समाधानों का मुख्य दोष I/O लागत है। सीक प्रति पंक्ति के साथ, 400K-पंक्ति इनपुट के लिए, ये समाधान 1.35M से अधिक रीड्स करते हैं। लेकिन अच्छा रन टाइम और आपको मिलने वाले स्केलिंग को देखते हुए इसे पूरी तरह से स्वीकार्य लागत भी माना जा सकता है।
आगे क्या है?
मिलान आपूर्ति बनाम मांग चुनौती को हल करने का हमारा पहला प्रयास क्लासिक अंतराल चौराहे परीक्षण पर निर्भर था और द्विघात स्केलिंग के साथ खराब प्रदर्शन करने वाली योजना मिली। कर्सर-आधारित समाधान से भी बदतर। लुका, कामिल और डैनियल की अंतर्दृष्टि के आधार पर, एक संशोधित अंतराल चौराहे परीक्षण का उपयोग करते हुए, हमारा दूसरा प्रयास एक महत्वपूर्ण सुधार था जो अनुक्रमण का कुशलतापूर्वक उपयोग करता है और कर्सर-आधारित समाधान से बेहतर प्रदर्शन करता है। हालांकि, इस समाधान में एक महत्वपूर्ण I/O लागत शामिल है। अगले महीने मैं अतिरिक्त समाधान तलाशना जारी रखूंगा।
[ यहां जाएं:मूल चुनौती | समाधान:भाग 1 | भाग 2 | भाग 3 ]