इस लेख में, मैं मांग चुनौती के साथ मिलान आपूर्ति के समाधान तलाशना जारी रखता हूं। आपके समाधान भेजने के लिए लुका, कामिल कोस्नो, डैनियल ब्राउन, ब्रायन वॉकर, जो ओबिश, रेनर हॉफमैन, पॉल व्हाइट, चार्ली, इयान और पीटर लार्सन को धन्यवाद।
पिछले महीने मैंने क्लासिक एक की तुलना में संशोधित अंतराल चौराहों के दृष्टिकोण के आधार पर समाधानों को कवर किया। उन समाधानों में से सबसे तेज़ ने कामिल, लुका और डैनियल के विचारों को संयुक्त किया। इसने दो प्रश्नों को असंबद्ध सारगर्भित विधेय के साथ एकीकृत किया। 400K-पंक्ति इनपुट के मुकाबले समाधान को पूरा करने में 1.34 सेकंड का समय लगा। क्लासिक अंतराल चौराहों के दृष्टिकोण के आधार पर समाधान को देखते हुए यह बहुत जर्जर नहीं है, उसी इनपुट के खिलाफ पूरा करने में 931 सेकंड लगते हैं। यह भी याद रखें कि जो एक शानदार समाधान के साथ आया था जो क्लासिक अंतराल चौराहे के दृष्टिकोण पर निर्भर करता है लेकिन सबसे बड़े अंतराल की लंबाई के आधार पर अंतराल को बाल्टी करके मिलान तर्क को अनुकूलित करता है। उसी 400K-पंक्ति इनपुट के साथ, जो के समाधान को पूरा करने में 0.9 सेकंड का समय लगा। इस समाधान के बारे में मुश्किल बात यह है कि जैसे-जैसे अंतराल की लंबाई बढ़ती है, इसका प्रदर्शन कम होता जाता है।
इस महीने मैं आकर्षक समाधानों का पता लगाता हूं जो कामिल/लुका/डैनियल संशोधित चौराहे समाधान से तेज़ हैं और अंतराल लंबाई के लिए तटस्थ हैं। इस लेख में समाधान ब्रायन वॉकर, इयान, पीटर लार्सन, पॉल व्हाइट और मेरे द्वारा बनाए गए थे।
मैंने इस आलेख में नीलामी इनपुट तालिका के विरुद्ध 100K, 200K, 300K, और 400K पंक्तियों के साथ और निम्न अनुक्रमणिका के साथ सभी समाधानों का परीक्षण किया:
-- Index to support solution CREATE UNIQUE NONCLUSTERED INDEX idx_Code_ID_i_Quantity ON dbo.Auctions(Code, ID) INCLUDE(Quantity); -- Enable batch-mode Window Aggregate CREATE NONCLUSTERED COLUMNSTORE INDEX idx_cs ON dbo.Auctions(ID) WHERE ID = -1 AND ID = -2;
समाधान के पीछे के तर्क का वर्णन करते समय, मैं मानूंगा कि नीलामी तालिका नमूना डेटा के निम्नलिखित छोटे सेट से भरी हुई है:
ID Code Quantity ----------- ---- --------- 1 D 5.000000 2 D 3.000000 3 D 8.000000 5 D 2.000000 6 D 8.000000 7 D 4.000000 8 D 2.000000 1000 S 8.000000 2000 S 6.000000 3000 S 2.000000 4000 S 2.000000 5000 S 4.000000 6000 S 3.000000 7000 S 2.000000
इस नमूना डेटा के लिए वांछित परिणाम निम्नलिखित है:
DemandID SupplyID TradeQuantity ----------- ----------- -------------- 1 1000 5.000000 2 1000 3.000000 3 2000 6.000000 3 3000 2.000000 5 4000 2.000000 6 5000 4.000000 6 6000 3.000000 6 7000 1.000000 7 7000 1.000000
ब्रायन वॉकर सॉल्यूशन
SQL क्वेरी सॉल्यूशंस में आउटर जॉइन का काफी उपयोग किया जाता है, लेकिन अब तक जब आप इनका उपयोग करते हैं, तो आप सिंगल-साइडेड वाले का उपयोग करते हैं। बाहरी जुड़ावों के बारे में पढ़ाते समय, मुझे अक्सर पूर्ण बाहरी जुड़ाव के व्यावहारिक उपयोग के मामलों के उदाहरण पूछने के लिए प्रश्न मिलते हैं, और ऐसे कई नहीं हैं। ब्रायन का समाधान पूर्ण बाहरी जुड़ाव के व्यावहारिक उपयोग के मामले का एक सुंदर उदाहरण है।
ये रहा ब्रायन का पूरा समाधान कोड:
DROP TABLE IF EXISTS #MyPairings;
CREATE TABLE #MyPairings
(
DemandID INT NOT NULL,
SupplyID INT NOT NULL,
TradeQuantity DECIMAL(19,06) NOT NULL
);
WITH D AS
(
SELECT A.ID,
SUM(A.Quantity) OVER (PARTITION BY A.Code
ORDER BY A.ID ROWS UNBOUNDED PRECEDING) AS Running
FROM dbo.Auctions AS A
WHERE A.Code = 'D'
),
S AS
(
SELECT A.ID,
SUM(A.Quantity) OVER (PARTITION BY A.Code
ORDER BY A.ID ROWS UNBOUNDED PRECEDING) AS Running
FROM dbo.Auctions AS A
WHERE A.Code = 'S'
),
W AS
(
SELECT D.ID AS DemandID, S.ID AS SupplyID, ISNULL(D.Running, S.Running) AS Running
FROM D
FULL JOIN S
ON D.Running = S.Running
),
Z AS
(
SELECT
CASE
WHEN W.DemandID IS NOT NULL THEN W.DemandID
ELSE MIN(W.DemandID) OVER (ORDER BY W.Running
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING)
END AS DemandID,
CASE
WHEN W.SupplyID IS NOT NULL THEN W.SupplyID
ELSE MIN(W.SupplyID) OVER (ORDER BY W.Running
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING)
END AS SupplyID,
W.Running
FROM W
)
INSERT #MyPairings( DemandID, SupplyID, TradeQuantity )
SELECT Z.DemandID, Z.SupplyID,
Z.Running - ISNULL(LAG(Z.Running) OVER (ORDER BY Z.Running), 0.0) AS TradeQuantity
FROM Z
WHERE Z.DemandID IS NOT NULL
AND Z.SupplyID IS NOT NULL; मैंने स्पष्टता के लिए ब्रायन के सीटीई के साथ व्युत्पन्न तालिकाओं के मूल उपयोग को संशोधित किया।
CTE D, D.Running नामक परिणाम कॉलम में कुल मांग मात्रा की गणना करता है, और CTE S, S.Running नामक परिणाम कॉलम में कुल आपूर्ति मात्रा की गणना करता है। CTE W तब D और S के बीच एक पूर्ण बाहरी जुड़ाव करता है, D.Running को S.Running के साथ मिलाता है, और D.Running और S.Running के बीच W.Running के रूप में पहला गैर-NULL लौटाता है। यदि आप रनिंग द्वारा W से सभी पंक्तियों को क्वेरी करते हैं तो आपको यह परिणाम मिलता है:
DemandID SupplyID Running ----------- ----------- ---------- 1 NULL 5.000000 2 1000 8.000000 NULL 2000 14.000000 3 3000 16.000000 5 4000 18.000000 NULL 5000 22.000000 NULL 6000 25.000000 6 NULL 26.000000 NULL 7000 27.000000 7 NULL 30.000000 8 NULL 32.000000
एक विधेय के आधार पर एक पूर्ण बाहरी जुड़ाव का उपयोग करने का विचार जो मांग और आपूर्ति के योग की तुलना करता है, प्रतिभा का एक स्ट्रोक है! इस परिणाम में अधिकांश पंक्तियाँ - हमारे मामले में पहली 9 - कुछ अतिरिक्त संगणनाओं के साथ परिणाम युग्मों का प्रतिनिधित्व करती हैं। किसी एक प्रकार की अनुगामी NULL ID वाली पंक्तियाँ उन प्रविष्टियों का प्रतिनिधित्व करती हैं जिनका मिलान नहीं किया जा सकता है। हमारे मामले में, अंतिम दो पंक्तियाँ मांग प्रविष्टियों का प्रतिनिधित्व करती हैं जिनका आपूर्ति प्रविष्टियों से मिलान नहीं किया जा सकता है। इसलिए, जो कुछ बचा है, वह है डिमांड आईडी, सप्लाईआईडी और ट्रेडक्वांटिटी की गणना करना, और उन प्रविष्टियों को फ़िल्टर करना जिनका मिलान नहीं किया जा सकता है।
लॉजिक जो परिणाम की गणना करता है डिमांडआईडी और सप्लाईआईडी को सीटीई जेड में निम्नानुसार किया जाता है (चलकर डब्ल्यू में ऑर्डर करना):
- डिमांड आईडी:यदि डिमांड आईडी न्यूल नहीं है तो डिमांड आईडी, अन्यथा वर्तमान पंक्ति से शुरू होने वाली न्यूनतम डिमांड आईडी
- आपूर्ति आईडी:यदि आपूर्ति आईडी न्यूल नहीं है तो आपूर्ति आईडी, अन्यथा वर्तमान पंक्ति से शुरू होने वाली न्यूनतम आपूर्ति आईडी
यदि आप Z को क्वेरी करते हैं और चलकर पंक्तियों को क्रमित करते हैं तो आपको यह परिणाम मिलता है:
DemandID SupplyID Running ----------- ----------- ---------- 1 1000 5.000000 2 1000 8.000000 3 2000 14.000000 3 3000 16.000000 5 4000 18.000000 6 5000 22.000000 6 6000 25.000000 6 7000 26.000000 7 7000 27.000000 7 NULL 30.000000 8 NULL 32.000000
बाहरी क्वेरी Z से एक प्रकार की प्रविष्टियों का प्रतिनिधित्व करने वाली पंक्तियों को फ़िल्टर करती है जो कि डिमांडआईडी और सप्लाईआईडी दोनों को सुनिश्चित करके अन्य प्रकार की प्रविष्टियों से मेल नहीं खा सकती हैं। परिणाम युग्मों की व्यापार मात्रा की गणना एलएजी फ़ंक्शन का उपयोग करके वर्तमान रनिंग वैल्यू घटाकर पिछले रनिंग वैल्यू के रूप में की जाती है।
यहां #MyPairings तालिका में लिखा गया है, जो वांछित परिणाम है:
DemandID SupplyID TradeQuantity ----------- ----------- -------------- 1 1000 5.000000 2 1000 3.000000 3 2000 6.000000 3 3000 2.000000 5 4000 2.000000 6 5000 4.000000 6 6000 3.000000 6 7000 1.000000 7 7000 1.000000
इस समाधान की योजना चित्र 1 में दिखाई गई है।
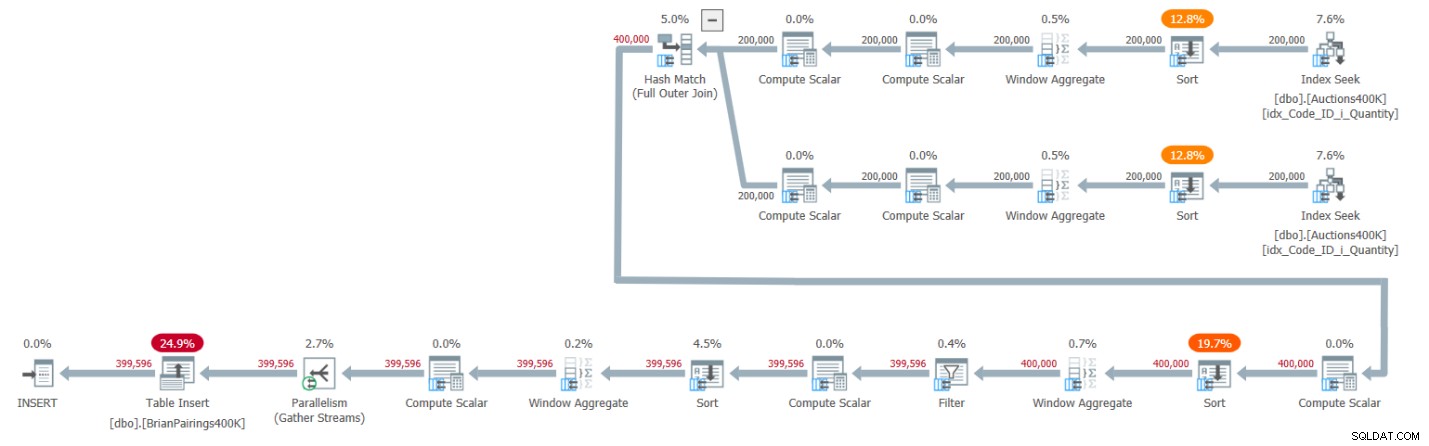 चित्र 1:ब्रायन के समाधान के लिए क्वेरी योजना
चित्र 1:ब्रायन के समाधान के लिए क्वेरी योजना
योजना की शीर्ष दो शाखाएं बैच-मोड विंडो एग्रीगेट ऑपरेटर का उपयोग करके मांग और आपूर्ति के कुल योग की गणना करती हैं, प्रत्येक सहायक सूचकांक से संबंधित प्रविष्टियों को प्राप्त करने के बाद। जैसा कि मैंने श्रृंखला में पहले के लेखों में समझाया था, चूंकि इंडेक्स में पहले से ही पंक्तियों का आदेश दिया गया है जैसे विंडो एग्रीगेट ऑपरेटरों को उनकी आवश्यकता होती है, आपको लगता है कि स्पष्ट सॉर्ट ऑपरेटरों की आवश्यकता नहीं होनी चाहिए। लेकिन SQL सर्वर वर्तमान में समानांतर बैच-मोड विंडो एग्रीगेट ऑपरेटर से पहले समानांतर ऑर्डर-संरक्षण इंडेक्स ऑपरेशन के कुशल संयोजन का समर्थन नहीं करता है, इसलिए परिणामस्वरूप, एक स्पष्ट समानांतर सॉर्ट ऑपरेटर समानांतर विंडो एग्रीगेट ऑपरेटरों में से प्रत्येक से पहले होता है।
पूर्ण बाहरी जुड़ाव को संभालने के लिए योजना बैच-मोड हैश जॉइन का उपयोग करती है। यह योजना दो अतिरिक्त बैच-मोड विंडो एग्रीगेट ऑपरेटरों का भी उपयोग करती है, जो स्पष्ट सॉर्ट ऑपरेटरों से पहले मिन और एलएजी विंडो फ़ंक्शन की गणना करने के लिए करते हैं।
यह काफी कारगर योजना है!
इस समाधान के लिए मुझे 100K से 400K पंक्तियों तक के इनपुट आकारों के विरुद्ध सेकंड में रन टाइम मिला है:
100K: 0.368 200K: 0.845 300K: 1.255 400K: 1.315
इत्ज़िक का समाधान
चुनौती का अगला समाधान इसे हल करने के मेरे प्रयासों में से एक है। यहां संपूर्ण समाधान कोड दिया गया है:
DROP TABLE IF EXISTS #MyPairings;
WITH C1 AS
(
SELECT *,
SUM(Quantity)
OVER(PARTITION BY Code
ORDER BY ID
ROWS UNBOUNDED PRECEDING) AS SumQty
FROM dbo.Auctions
),
C2 AS
(
SELECT *,
SUM(Quantity * CASE Code WHEN 'D' THEN -1 WHEN 'S' THEN 1 END)
OVER(ORDER BY SumQty, Code
ROWS UNBOUNDED PRECEDING) AS StockLevel,
LAG(SumQty, 1, 0.0) OVER(ORDER BY SumQty, Code) AS PrevSumQty,
MAX(CASE WHEN Code = 'D' THEN ID END)
OVER(ORDER BY SumQty, Code
ROWS UNBOUNDED PRECEDING) AS PrevDemandID,
MAX(CASE WHEN Code = 'S' THEN ID END)
OVER(ORDER BY SumQty, Code
ROWS UNBOUNDED PRECEDING) AS PrevSupplyID,
MIN(CASE WHEN Code = 'D' THEN ID END)
OVER(ORDER BY SumQty, Code
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS NextDemandID,
MIN(CASE WHEN Code = 'S' THEN ID END)
OVER(ORDER BY SumQty, Code
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS NextSupplyID
FROM C1
),
C3 AS
(
SELECT *,
CASE Code
WHEN 'D' THEN ID
WHEN 'S' THEN
CASE WHEN StockLevel > 0 THEN NextDemandID ELSE PrevDemandID END
END AS DemandID,
CASE Code
WHEN 'S' THEN ID
WHEN 'D' THEN
CASE WHEN StockLevel <= 0 THEN NextSupplyID ELSE PrevSupplyID END
END AS SupplyID,
SumQty - PrevSumQty AS TradeQuantity
FROM C2
)
SELECT DemandID, SupplyID, TradeQuantity
INTO #MyPairings
FROM C3
WHERE TradeQuantity > 0.0
AND DemandID IS NOT NULL
AND SupplyID IS NOT NULL; CTE C1 नीलामी तालिका से पूछताछ करता है और कुल मांग और आपूर्ति मात्रा की गणना करने के लिए एक विंडो फ़ंक्शन का उपयोग करता है, परिणाम कॉलम SumQty को कॉल करता है।
CTE C2 C1 को क्वेरी करता है, और SumQty और कोड ऑर्डरिंग के आधार पर विंडो फ़ंक्शंस का उपयोग करके कई विशेषताओं की गणना करता है:
- स्टॉक स्तर:प्रत्येक प्रविष्टि को संसाधित करने के बाद वर्तमान स्टॉक स्तर। इसकी गणना मात्राओं की मांग करने के लिए एक ऋणात्मक चिह्न और मात्राओं की आपूर्ति के लिए एक सकारात्मक संकेत और वर्तमान प्रविष्टि तक और उन मात्राओं को जोड़कर की जाती है।
- PrevSumQty:पिछली पंक्ति का SumQty मान।
- PrevDemandID:अंतिम गैर-शून्य मांग आईडी।
- PrevSupplyID:अंतिम गैर-नल आपूर्ति आईडी।
- NextDemandID:अगला गैर-शून्य मांग आईडी।
- NextSupplyID:अगला नॉन-नल सप्लाई आईडी।
यहाँ SumQty और कोड द्वारा आदेशित C2 की सामग्री है:
ID Code Quantity SumQty StockLevel PrevSumQty PrevDemandID PrevSupplyID NextDemandID NextSupplyID ----- ---- --------- ---------- ----------- ----------- ------------ ------------ ------------ ------------ 1 D 5.000000 5.000000 -5.000000 0.000000 1 NULL 1 1000 2 D 3.000000 8.000000 -8.000000 5.000000 2 NULL 2 1000 1000 S 8.000000 8.000000 0.000000 8.000000 2 1000 3 1000 2000 S 6.000000 14.000000 6.000000 8.000000 2 2000 3 2000 3 D 8.000000 16.000000 -2.000000 14.000000 3 2000 3 3000 3000 S 2.000000 16.000000 0.000000 16.000000 3 3000 5 3000 5 D 2.000000 18.000000 -2.000000 16.000000 5 3000 5 4000 4000 S 2.000000 18.000000 0.000000 18.000000 5 4000 6 4000 5000 S 4.000000 22.000000 4.000000 18.000000 5 5000 6 5000 6000 S 3.000000 25.000000 7.000000 22.000000 5 6000 6 6000 6 D 8.000000 26.000000 -1.000000 25.000000 6 6000 6 7000 7000 S 2.000000 27.000000 1.000000 26.000000 6 7000 7 7000 7 D 4.000000 30.000000 -3.000000 27.000000 7 7000 7 NULL 8 D 2.000000 32.000000 -5.000000 30.000000 8 7000 8 NULL
CTE C3 कुछ अतिरिक्त पंक्तियों को हटाने से पहले C2 को क्वेरी करता है और परिणाम युग्मों की डिमांडआईडी, सप्लाईआईडी और ट्रेडक्वांटिटी की गणना करता है।
परिणाम C3.DemandID कॉलम की गणना इस प्रकार की जाती है:
- यदि वर्तमान प्रविष्टि एक मांग प्रविष्टि है, तो डिमांड आईडी लौटाएं।
- यदि वर्तमान प्रविष्टि एक आपूर्ति प्रविष्टि है और वर्तमान स्टॉक स्तर सकारात्मक है, तो NextDemandID लौटाएं।
- यदि वर्तमान प्रविष्टि एक आपूर्ति प्रविष्टि है और वर्तमान स्टॉक स्तर गैर-धनात्मक है, तो PrevDemandID लौटाएं।
परिणाम C3.SupplyID कॉलम की गणना इस प्रकार की जाती है:
- यदि वर्तमान प्रविष्टि एक आपूर्ति प्रविष्टि है, तो आपूर्ति आईडी लौटाएं।
- यदि वर्तमान प्रविष्टि एक मांग प्रविष्टि है और वर्तमान स्टॉक स्तर गैर-सकारात्मक है, तो NextSupplyID लौटाएं।
- यदि वर्तमान प्रविष्टि एक मांग प्रविष्टि है और वर्तमान स्टॉक स्तर सकारात्मक है, तो PrevSupplyID लौटाएं।
परिणाम TradeQuantity की गणना वर्तमान पंक्ति की SumQty घटा PrevSumQty के रूप में की जाती है।
C3 से परिणाम के लिए प्रासंगिक कॉलम की सामग्री यहां दी गई है:
DemandID SupplyID TradeQuantity ----------- ----------- -------------- 1 1000 5.000000 2 1000 3.000000 2 1000 0.000000 3 2000 6.000000 3 3000 2.000000 3 3000 0.000000 5 4000 2.000000 5 4000 0.000000 6 5000 4.000000 6 6000 3.000000 6 7000 1.000000 7 7000 1.000000 7 NULL 3.000000 8 NULL 2.000000
बाहरी क्वेरी के लिए जो करना बाकी है, वह है C3 से अतिरिक्त पंक्तियों को फ़िल्टर करना। इनमें दो मामले शामिल हैं:
- जब दोनों प्रकार के रनिंग योग समान होते हैं, तो आपूर्ति प्रविष्टि में शून्य ट्रेडिंग मात्रा होती है। याद रखें कि ऑर्डरिंग SumQty और कोड पर आधारित है, इसलिए जब रनिंग टोटल समान होते हैं, तो सप्लाई एंट्री से पहले डिमांड एंट्री दिखाई देती है।
- एक प्रकार की पिछली प्रविष्टियाँ जिनका दूसरे प्रकार की प्रविष्टियों से मिलान नहीं किया जा सकता है। ऐसी प्रविष्टियाँ C3 में पंक्तियों द्वारा दर्शायी जाती हैं जहाँ या तो डिमांडआईडी NULL है या सप्लाईआईडी NULL है।
इस समाधान की योजना चित्र 2 में दिखाई गई है।
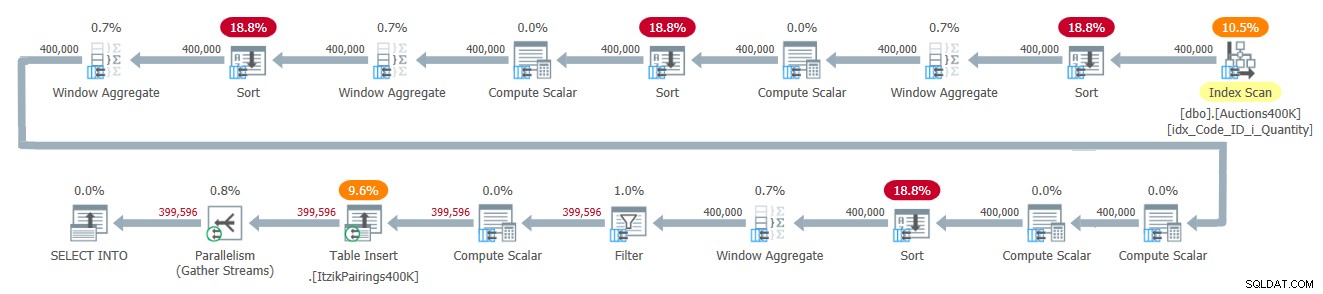 चित्र 2:इट्ज़िक के समाधान के लिए क्वेरी योजना
चित्र 2:इट्ज़िक के समाधान के लिए क्वेरी योजना
योजना इनपुट डेटा पर एक पास लागू करती है और विभिन्न विंडो गणनाओं को संभालने के लिए चार बैच-मोड विंडो एग्रीगेट ऑपरेटरों का उपयोग करती है। सभी विंडो एग्रीगेट ऑपरेटरों से पहले स्पष्ट सॉर्ट ऑपरेटर होते हैं, हालांकि उनमें से केवल दो ही यहां अपरिहार्य हैं। अन्य दो को समानांतर बैच-मोड विंडो एग्रीगेट ऑपरेटर के वर्तमान कार्यान्वयन के साथ करना है, जो समानांतर ऑर्डर-संरक्षण इनपुट पर भरोसा नहीं कर सकता है। यह देखने का एक आसान तरीका है कि इस कारण से कौन से सॉर्ट ऑपरेटर हैं, एक सीरियल प्लान को मजबूर करना और यह देखना है कि कौन से सॉर्ट ऑपरेटर गायब हो जाते हैं। जब मैं इस समाधान के साथ एक सीरियल प्लान लागू करता हूं, तो पहले और तीसरे सॉर्ट ऑपरेटर गायब हो जाते हैं।
इस समाधान के लिए मुझे जो रन समय सेकंड में मिला है वह यहां दिया गया है:
100K: 0.246 200K: 0.427 300K: 0.616 400K: 0.841>
इयान का समाधान
इयान का समाधान छोटा और कुशल है। यहां संपूर्ण समाधान कोड दिया गया है:
DROP TABLE IF EXISTS #MyPairings;
WITH A AS (
SELECT *,
SUM(Quantity) OVER (PARTITION BY Code
ORDER BY ID
ROWS UNBOUNDED PRECEDING) AS CumulativeQuantity
FROM dbo.Auctions
), B AS (
SELECT CumulativeQuantity,
CumulativeQuantity
- LAG(CumulativeQuantity, 1, 0)
OVER (ORDER BY CumulativeQuantity) AS TradeQuantity,
MAX(CASE WHEN Code = 'D' THEN ID END) AS DemandID,
MAX(CASE WHEN Code = 'S' THEN ID END) AS SupplyID
FROM A
GROUP BY CumulativeQuantity, ID/ID -- bogus grouping to improve row estimate
-- (rows count of Auctions instead of 2 rows)
), C AS (
-- fill in NULLs with next supply / demand
-- FIRST_VALUE(ID) IGNORE NULLS OVER ...
-- would be better, but this will work because the IDs are in CumulativeQuantity order
SELECT
MIN(DemandID) OVER (ORDER BY CumulativeQuantity
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS DemandID,
MIN(SupplyID) OVER (ORDER BY CumulativeQuantity
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS SupplyID,
TradeQuantity
FROM B
)
SELECT DemandID, SupplyID, TradeQuantity
INTO #MyPairings
FROM C
WHERE SupplyID IS NOT NULL -- trim unfulfilled demands
AND DemandID IS NOT NULL; -- trim unused supplies सीटीई ए में कोड नीलामी तालिका से पूछताछ करता है और परिणाम कॉलम संचयी मात्रा का नामकरण, विंडो फ़ंक्शन का उपयोग करके कुल मांग और आपूर्ति मात्रा की गणना करता है।
सीटीई बी में कोड सीटीई ए से पूछताछ करता है, और पंक्तियों को संचयी मात्रा के आधार पर समूहित करता है। यह समूह मांग और आपूर्ति के योग के आधार पर ब्रायन के बाहरी जुड़ाव के समान प्रभाव प्राप्त करता है। इयान ने अनुमान के तहत समूह की मूल कार्डिनैलिटी को बेहतर बनाने के लिए ग्रुपिंग सेट में डमी एक्सप्रेशन आईडी/आईडी भी जोड़ा। मेरी मशीन पर, इसके परिणामस्वरूप सीरियल के बजाय समानांतर योजना का उपयोग किया गया।
चयन सूची में, कोड MAX एग्रीगेट और CASE एक्सप्रेशन का उपयोग करके समूह में संबंधित प्रविष्टि प्रकार की आईडी प्राप्त करके डिमांडआईडी और सप्लाईआईडी की गणना करता है। यदि समूह में आईडी मौजूद नहीं है, तो परिणाम NULL है। कोड, ट्रेडक्वांटिटी नामक एक परिणाम कॉलम की गणना वर्तमान संचयी मात्रा को घटाकर पिछले वाले के रूप में करता है, जिसे LAG विंडो फ़ंक्शन का उपयोग करके पुनर्प्राप्त किया जाता है।
यहाँ बी की सामग्री है:
CumulativeQuantity TradeQuantity DemandId SupplyId ------------------- -------------- --------- --------- 5.000000 5.000000 1 NULL 8.000000 3.000000 2 1000 14.000000 6.000000 NULL 2000 16.000000 2.000000 3 3000 18.000000 2.000000 5 4000 22.000000 4.000000 NULL 5000 25.000000 3.000000 NULL 6000 26.000000 1.000000 6 NULL 27.000000 1.000000 NULL 7000 30.000000 3.000000 7 NULL 32.000000 2.000000 8 NULL
सीटीई सी में कोड तब सीटीई बी से पूछताछ करता है और अगली गैर-शून्य मांग और आपूर्ति आईडी के साथ न्यूल मांग और आपूर्ति आईडी भरता है, मिन विंडो फ़ंक्शन का उपयोग करके वर्तमान पंक्ति और असीमित निम्नलिखित के बीच फ्रेम के साथ।
यहाँ C की सामग्री है:
DemandID SupplyID TradeQuantity --------- --------- -------------- 1 1000 5.000000 2 1000 3.000000 3 2000 6.000000 3 3000 2.000000 5 4000 2.000000 6 5000 4.000000 6 6000 3.000000 6 7000 1.000000 7 7000 1.000000 7 NULL 3.000000 8 NULL 2.000000
सी के खिलाफ बाहरी क्वेरी द्वारा संभाला गया अंतिम चरण एक प्रकार की प्रविष्टियों को हटाना है जो अन्य प्रकार की प्रविष्टियों से मेल नहीं खा सकते हैं। यह उन पंक्तियों को फ़िल्टर करके किया जाता है जहां या तो सप्लाईआईडी न्यूल है या डिमांडआईडी न्यूल है।
इस समाधान की योजना चित्र 3 में दिखाई गई है।
 चित्र 3:इयान के समाधान के लिए क्वेरी योजना
चित्र 3:इयान के समाधान के लिए क्वेरी योजना
यह योजना इनपुट डेटा का एक स्कैन करती है और विभिन्न विंडो फ़ंक्शंस की गणना करने के लिए तीन समानांतर बैच-मोड विंडो एग्रीगेट ऑपरेटरों का उपयोग करती है, जो सभी समानांतर सॉर्ट ऑपरेटरों से पहले होती हैं। उनमें से दो अपरिहार्य हैं क्योंकि आप एक सीरियल प्लान को मजबूर करके सत्यापित कर सकते हैं। यह योजना सीटीई बी में समूहीकरण और एकत्रीकरण को संभालने के लिए हैश एग्रीगेट ऑपरेटर का भी उपयोग करती है।
इस समाधान के लिए मुझे जो रन समय सेकंड में मिला है वह यहां दिया गया है:
100K: 0.214 200K: 0.363 300K: 0.546 400K: 0.701
पीटर लार्सन सॉल्यूशन
पीटर लार्सन का समाधान आश्चर्यजनक रूप से छोटा, मीठा और अत्यधिक कुशल है। ये रहा पीटर का पूरा समाधान कोड:
DROP TABLE IF EXISTS #MyPairings;
WITH cteSource(ID, Code, RunningQuantity)
AS
(
SELECT ID, Code,
SUM(Quantity) OVER (PARTITION BY Code ORDER BY ID) AS RunningQuantity
FROM dbo.Auctions
)
SELECT DemandID, SupplyID, TradeQuantity
INTO #MyPairings
FROM (
SELECT
MIN(CASE WHEN Code = 'D' THEN ID ELSE 2147483648 END)
OVER (ORDER BY RunningQuantity, Code
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS DemandID,
MIN(CASE WHEN Code = 'S' THEN ID ELSE 2147483648 END)
OVER (ORDER BY RunningQuantity, Code
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS SupplyID,
RunningQuantity
- COALESCE(LAG(RunningQuantity) OVER (ORDER BY RunningQuantity, Code), 0.0)
AS TradeQuantity
FROM cteSource
) AS d
WHERE DemandID < 2147483648
AND SupplyID < 2147483648
AND TradeQuantity > 0.0; सीटीई सीटीईसोर्स नीलामी तालिका से पूछताछ करता है और कुल मांग और आपूर्ति मात्रा की गणना करने के लिए विंडो फ़ंक्शन का उपयोग करता है, परिणाम कॉलम रनिंगक्वांटिटी को कॉल करता है।
व्युत्पन्न तालिका d को परिभाषित करने वाला कोड cteSource को क्वेरी करता है और कुछ अतिरिक्त पंक्तियों को हटाने से पहले परिणाम युग्मों की डिमांड आईडी, सप्लाईआईडी और ट्रेडक्वांटिटी की गणना करता है। उन गणनाओं में उपयोग किए जाने वाले सभी विंडो फ़ंक्शन रनिंगक्वांटिटी और कोड ऑर्डरिंग पर आधारित होते हैं।
परिणाम कॉलम d.DemandID की गणना वर्तमान या 2147483648 से शुरू होने वाली न्यूनतम मांग आईडी के रूप में की जाती है यदि कोई नहीं मिलता है।
परिणाम कॉलम d.SupplyID की गणना वर्तमान या 2147483648 से शुरू होने वाली न्यूनतम आपूर्ति आईडी के रूप में की जाती है यदि कोई नहीं मिलता है।
परिणाम TradeQuantity की गणना वर्तमान पंक्ति के RunQuantity मान से पिछली पंक्ति के RunQuantity मान को घटाकर की जाती है।
यहाँ घ की सामग्री है:
DemandID SupplyID TradeQuantity --------- ----------- -------------- 1 1000 5.000000 2 1000 3.000000 3 1000 0.000000 3 2000 6.000000 3 3000 2.000000 5 3000 0.000000 5 4000 2.000000 6 4000 0.000000 6 5000 4.000000 6 6000 3.000000 6 7000 1.000000 7 7000 1.000000 7 2147483648 3.000000 8 2147483648 2.000000
बाहरी क्वेरी के लिए क्या करना बाकी है, d से अतिरिक्त पंक्तियों को फ़िल्टर करना। वे ऐसे मामले हैं जहां ट्रेडिंग मात्रा शून्य है, या एक प्रकार की प्रविष्टियां जिनका दूसरे प्रकार की प्रविष्टियों से मिलान नहीं किया जा सकता है (आईडी 2147483648 के साथ)।
इस समाधान की योजना चित्र 4 में दिखाई गई है।
 चित्र 4:पीटर के समाधान के लिए प्रश्न योजना
चित्र 4:पीटर के समाधान के लिए प्रश्न योजना
इयान की योजना की तरह, पीटर की योजना इनपुट डेटा के एक स्कैन पर निर्भर करती है और विभिन्न विंडो फ़ंक्शंस की गणना करने के लिए तीन समानांतर बैच-मोड विंडो एग्रीगेट ऑपरेटरों का उपयोग करती है, जो सभी समानांतर सॉर्ट ऑपरेटरों से पहले होती हैं। उनमें से दो अपरिहार्य हैं क्योंकि आप एक सीरियल प्लान को मजबूर करके सत्यापित कर सकते हैं। पीटर की योजना में, इयान की योजना की तरह समूहीकृत कुल ऑपरेटर की कोई आवश्यकता नहीं है।
पीटर की महत्वपूर्ण अंतर्दृष्टि जिसने इतने छोटे समाधान की अनुमति दी, वह यह अहसास था कि किसी भी प्रकार की प्रासंगिक प्रविष्टि के लिए, दूसरे प्रकार की मिलान आईडी हमेशा बाद में दिखाई देगी (रनिंगक्वांटिटी और कोड ऑर्डरिंग के आधार पर)। पीटर के समाधान को देखने के बाद, यह निश्चित रूप से लगा कि मैंने अपने अंदर की चीजों को जटिल कर दिया है!
इस समाधान के लिए मुझे मिले कुछ सेकंड में रन टाइम यहां दिया गया है:
100K: 0.197 200K: 0.412 300K: 0.558 400K: 0.696
पॉल व्हाइट का समाधान
हमारा अंतिम समाधान पॉल व्हाइट द्वारा बनाया गया था। यहां संपूर्ण समाधान कोड दिया गया है:
DROP TABLE IF EXISTS #MyPairings;
CREATE TABLE #MyPairings
(
DemandID integer NOT NULL,
SupplyID integer NOT NULL,
TradeQuantity decimal(19, 6) NOT NULL
);
GO
INSERT #MyPairings
WITH (TABLOCK)
(
DemandID,
SupplyID,
TradeQuantity
)
SELECT
Q3.DemandID,
Q3.SupplyID,
Q3.TradeQuantity
FROM
(
SELECT
Q2.DemandID,
Q2.SupplyID,
TradeQuantity =
-- Interval overlap
CASE
WHEN Q2.Code = 'S' THEN
CASE
WHEN Q2.CumDemand >= Q2.IntEnd THEN Q2.IntLength
WHEN Q2.CumDemand > Q2.IntStart THEN Q2.CumDemand - Q2.IntStart
ELSE 0.0
END
WHEN Q2.Code = 'D' THEN
CASE
WHEN Q2.CumSupply >= Q2.IntEnd THEN Q2.IntLength
WHEN Q2.CumSupply > Q2.IntStart THEN Q2.CumSupply - Q2.IntStart
ELSE 0.0
END
END
FROM
(
SELECT
Q1.Code,
Q1.IntStart,
Q1.IntEnd,
Q1.IntLength,
DemandID = MAX(IIF(Q1.Code = 'D', Q1.ID, 0)) OVER (
ORDER BY Q1.IntStart, Q1.ID
ROWS UNBOUNDED PRECEDING),
SupplyID = MAX(IIF(Q1.Code = 'S', Q1.ID, 0)) OVER (
ORDER BY Q1.IntStart, Q1.ID
ROWS UNBOUNDED PRECEDING),
CumSupply = SUM(IIF(Q1.Code = 'S', Q1.IntLength, 0)) OVER (
ORDER BY Q1.IntStart, Q1.ID
ROWS UNBOUNDED PRECEDING),
CumDemand = SUM(IIF(Q1.Code = 'D', Q1.IntLength, 0)) OVER (
ORDER BY Q1.IntStart, Q1.ID
ROWS UNBOUNDED PRECEDING)
FROM
(
-- Demand intervals
SELECT
A.ID,
A.Code,
IntStart = SUM(A.Quantity) OVER (
ORDER BY A.ID
ROWS UNBOUNDED PRECEDING) - A.Quantity,
IntEnd = SUM(A.Quantity) OVER (
ORDER BY A.ID
ROWS UNBOUNDED PRECEDING),
IntLength = A.Quantity
FROM dbo.Auctions AS A
WHERE
A.Code = 'D'
UNION ALL
-- Supply intervals
SELECT
A.ID,
A.Code,
IntStart = SUM(A.Quantity) OVER (
ORDER BY A.ID
ROWS UNBOUNDED PRECEDING) - A.Quantity,
IntEnd = SUM(A.Quantity) OVER (
ORDER BY A.ID
ROWS UNBOUNDED PRECEDING),
IntLength = A.Quantity
FROM dbo.Auctions AS A
WHERE
A.Code = 'S'
) AS Q1
) AS Q2
) AS Q3
WHERE
Q3.TradeQuantity > 0; व्युत्पन्न तालिका Q1 को परिभाषित करने वाला कोड चल रहे योग के आधार पर मांग और आपूर्ति अंतराल की गणना करने के लिए दो अलग-अलग प्रश्नों का उपयोग करता है और दोनों को एकीकृत करता है। प्रत्येक अंतराल के लिए, कोड इसकी शुरुआत (IntStart), अंत (IntEnd), और लंबाई (IntLength) की गणना करता है। IntStart और ID द्वारा आदेशित Q1 की सामग्री यहां दी गई है:
ID Code IntStart IntEnd IntLength ----- ---- ---------- ---------- ---------- 1 D 0.000000 5.000000 5.000000 1000 S 0.000000 8.000000 8.000000 2 D 5.000000 8.000000 3.000000 3 D 8.000000 16.000000 8.000000 2000 S 8.000000 14.000000 6.000000 3000 S 14.000000 16.000000 2.000000 5 D 16.000000 18.000000 2.000000 4000 S 16.000000 18.000000 2.000000 6 D 18.000000 26.000000 8.000000 5000 S 18.000000 22.000000 4.000000 6000 S 22.000000 25.000000 3.000000 7000 S 25.000000 27.000000 2.000000 7 D 26.000000 30.000000 4.000000 8 D 30.000000 32.000000 2.000000
व्युत्पन्न तालिका Q2 को परिभाषित करने वाला कोड Q1 को क्वेरी करता है और परिणाम कॉलम की गणना करता है जिसे डिमांडआईडी, सप्लाईआईडी, कम सप्लाई और कमडेमैंड कहा जाता है। इस कोड द्वारा उपयोग किए जाने वाले सभी विंडो फ़ंक्शन इंटस्टार्ट और आईडी ऑर्डरिंग और फ्रेम ROWS UNBOUNDED PRECEDING (वर्तमान तक सभी पंक्तियाँ) पर आधारित हैं।
डिमांड आईडी वर्तमान पंक्ति तक अधिकतम मांग आईडी है, या 0 यदि कोई मौजूद नहीं है।
आपूर्ति आईडी वर्तमान पंक्ति तक अधिकतम आपूर्ति आईडी है, या 0 यदि कोई मौजूद नहीं है।
CumSupply वर्तमान पंक्ति तक संचयी आपूर्ति मात्रा (आपूर्ति अंतराल लंबाई) है।
CumDemand वर्तमान पंक्ति तक संचयी मांग मात्रा (मांग अंतराल लंबाई) है।
Q2 की सामग्री यहां दी गई है:
Code IntStart IntEnd IntLength DemandID SupplyID CumSupply CumDemand ---- ---------- ---------- ---------- --------- --------- ---------- ---------- D 0.000000 5.000000 5.000000 1 0 0.000000 5.000000 S 0.000000 8.000000 8.000000 1 1000 8.000000 5.000000 D 5.000000 8.000000 3.000000 2 1000 8.000000 8.000000 D 8.000000 16.000000 8.000000 3 1000 8.000000 16.000000 S 8.000000 14.000000 6.000000 3 2000 14.000000 16.000000 S 14.000000 16.000000 2.000000 3 3000 16.000000 16.000000 D 16.000000 18.000000 2.000000 5 3000 16.000000 18.000000 S 16.000000 18.000000 2.000000 5 4000 18.000000 18.000000 D 18.000000 26.000000 8.000000 6 4000 18.000000 26.000000 S 18.000000 22.000000 4.000000 6 5000 22.000000 26.000000 S 22.000000 25.000000 3.000000 6 6000 25.000000 26.000000 S 25.000000 27.000000 2.000000 6 7000 27.000000 26.000000 D 26.000000 30.000000 4.000000 7 7000 27.000000 30.000000 D 30.000000 32.000000 2.000000 8 7000 27.000000 32.000000
Q2 already has the final result pairings’ correct DemandID and SupplyID values. The code defining the derived table Q3 queries Q2 and computes the result pairings’ TradeQuantity values as the overlapping segments of the demand and supply intervals. Finally, the outer query against Q3 filters only the relevant pairings where TradeQuantity is positive.
The plan for this solution is shown in Figure 5.
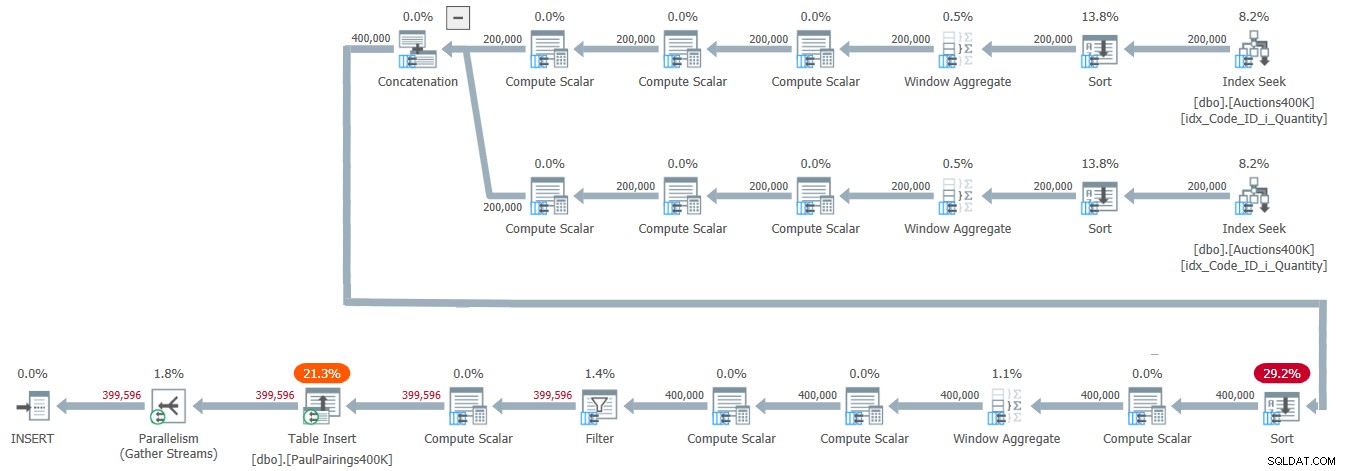 Figure 5:Query plan for Paul’s solution
Figure 5:Query plan for Paul’s solution
The top two branches of the plan are responsible for computing the demand and supply intervals. Both rely on Index Seek operators to get the relevant rows based on index order, and then use parallel batch-mode Window Aggregate operators, preceded by Sort operators that theoretically could have been avoided. The plan concatenates the two inputs, sorts the rows by IntStart and ID to support the subsequent remaining Window Aggregate operator. Only this Sort operator is unavoidable in this plan. The rest of the plan handles the needed scalar computations and the final filter. That’s a very efficient plan!
Here are the run times in seconds I got for this solution:
100K: 0.187 200K: 0.331 300K: 0.369 400K: 0.425
These numbers are pretty impressive!
Performance Comparison
Figure 6 has a performance comparison between all solutions covered in this article.
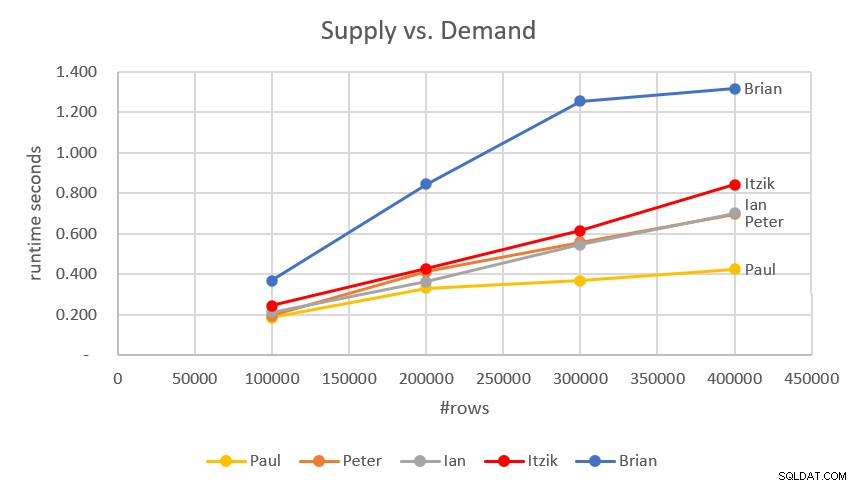 Figure 6:Performance comparison
Figure 6:Performance comparison
At this point, we can add the fastest solutions I covered in previous articles. Those are Joe’s and Kamil/Luca/Daniel’s solutions. The complete comparison is shown in Figure 7.
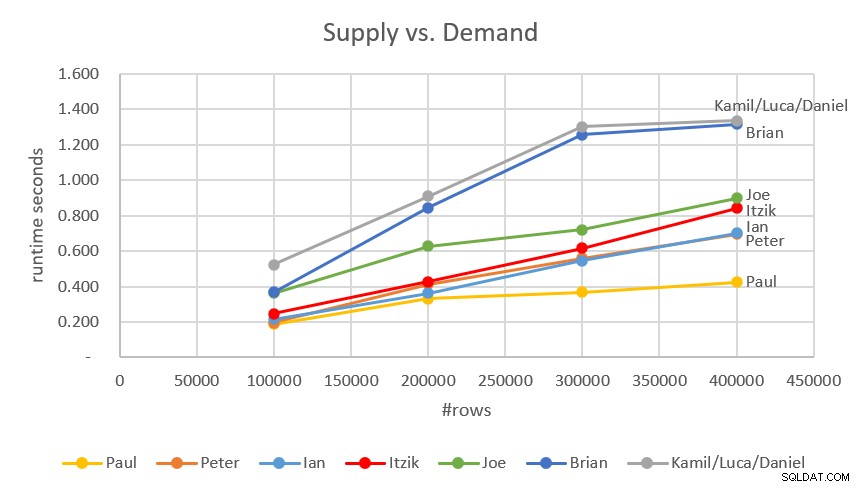 Figure 7:Performance comparison including earlier solutions
Figure 7:Performance comparison including earlier solutions
These are all impressively fast solutions, with the fastest being Paul’s and Peter’s.
निष्कर्ष
When I originally introduced Peter’s puzzle, I showed a straightforward cursor-based solution that took 11.81 seconds to complete against a 400K-row input. The challenge was to come up with an efficient set-based solution. It’s so inspiring to see all the solutions people sent. I always learn so much from such puzzles both from my own attempts and by analyzing others’ solutions. It’s impressive to see several sub-second solutions, with Paul’s being less than half a second!
It's great to have multiple efficient techniques to handle such a classic need of matching supply with demand. Well done everyone!
[ Jump to:Original challenge | Solutions:Part 1 | Part 2 | Part 3 ]