परिचय
SQL सर्वर 2012 में, समूहीकृत (वेक्टर) एकत्रीकरण समानांतर बैच-मोड निष्पादन का उपयोग करने में सक्षम था, लेकिन केवल आंशिक (प्रति-थ्रेड) कुल के लिए। संबद्ध वैश्विक समुच्चय हमेशा पुनर्विभाजन स्ट्रीम . के बाद पंक्ति मोड में चलता है विनिमय।
SQL सर्वर 2014 ने एक हैश मैच एग्रीगेट के भीतर समानांतर बैच-मोड समूहीकृत एकत्रीकरण करने की क्षमता को जोड़ा ऑपरेटर। इसने अनावश्यक पंक्ति-मोड प्रसंस्करण को समाप्त कर दिया, और विनिमय की आवश्यकता को हटा दिया।
SQL सर्वर 2016 ने सीरियल बैच मोड प्रोसेसिंग और एग्रीगेट पुशडाउन की शुरुआत की . जब पुशडाउन सफल होता है, तो एकत्रीकरण कॉलमस्टोर स्कैन . के भीतर किया जाता है ऑपरेटर ही, संभवत:सीधे संपीड़ित डेटा पर काम कर रहा है, और SIMD CPU निर्देशों का लाभ उठा रहा है।
समग्र पुशडाउन के साथ संभव प्रदर्शन सुधार बहुत महत्वपूर्ण हो सकते हैं। दस्तावेज़ीकरण में पुशडाउन प्राप्त करने के लिए आवश्यक कुछ शर्तों को सूचीबद्ध किया गया है, लेकिन ऐसे मामले हैं जहां 'स्थानीय रूप से एकत्रित पंक्तियों' की कमी को केवल उन विवरणों से पूरी तरह से समझाया नहीं जा सकता है।
इस लेख में उन अतिरिक्त कारकों को शामिल किया गया है जो GROUP BY के लिए कुल पुशडाउन को प्रभावित करते हैं केवल क्वेरी . स्केलर एग्रीगेट पुशडाउन (GROUP BY . के बिना एकत्रीकरण क्लॉज), फिल्टर पुशडाउन और एक्सप्रेशन पुशडाउन को भविष्य की पोस्ट में कवर किया जा सकता है।
Columnstore स्टोरेज
कहने वाली पहली बात यह है कि कुल पुशडाउन केवल संपीड़ित डेटा पर लागू होता है, इसलिए डेल्टा स्टोर में पंक्तियाँ पात्र नहीं हैं। इसके अलावा, पुशडाउन इस्तेमाल किए गए संपीड़न के प्रकार पर निर्भर कर सकता है। इसे समझने के लिए, पहले यह समीक्षा करना आवश्यक है कि उच्च स्तर पर कॉलमस्टोर स्टोरेज कैसे काम करता है:
एक संपीड़ित पंक्ति समूह एक स्तंभ खंड . शामिल है प्रत्येक कॉलम के लिए। अपरिष्कृत स्तंभ मान एन्कोडेड . हैं मान . का उपयोग करके 4-बाइट या 8-बाइट पूर्णांक में या शब्दकोश एन्कोडिंग।
मान एन्कोडिंग आधार ऑफसेट और परिमाण संशोधक का उपयोग करके कच्चे मूल्यों का अनुवाद करके भंडारण के लिए आवश्यक बिट्स की संख्या को कम कर सकता है। उदाहरण के लिए, मान {1100, 1200, 1300} को 0.01 के कारक द्वारा पहले स्केलिंग करके {11, 12, 13} देने के लिए (0, 1, 2) के रूप में संग्रहीत किया जा सकता है, फिर 11 पर रिबेस करके {0, 1, 2}.
शब्दकोश एन्कोडिंग डुप्लिकेट मान होने पर उपयोग किया जाता है। इसका उपयोग गैर-संख्यात्मक डेटा के साथ किया जा सकता है। प्रत्येक अद्वितीय मान को एक शब्दकोश में संग्रहीत किया जाता है और एक पूर्णांक आईडी असाइन की जाती है। खंड डेटा तब मूल मानों के बजाय शब्दकोश में आईडी संख्याओं को संदर्भित करता है।
एन्कोडिंग के बाद, खंड डेटा को रन-लेंथ एन्कोडिंग (RLE) और बिट-पैकिंग का उपयोग करके और अधिक संकुचित किया जा सकता है:
आरएलई डेटा और दोहराव की संख्या के साथ दोहराए जाने वाले तत्वों को प्रतिस्थापित करता है, उदाहरण के लिए {1, 1, 1, 1, 2, 2, 2} को {5×1, 3×2} से बदला जा सकता है। आरएलई अंतरिक्ष बचत दोहराए जाने वाले रन की लंबाई के साथ बढ़ती है। छोटे रन प्रतिकूल हो सकते हैं।
बिट-पैकिंग डेटा के बाइनरी रूप को यथासंभव एक सामान्य विंडो में संग्रहीत करता है। उदाहरण के लिए, संख्याएँ {7, 9, 15} बाइनरी (स्पेस के लिए सिंगल-बाइट) पूर्णांकों में {00000111, 00001001, 00001111} के रूप में संग्रहीत हैं। इन बिट्स को एक निश्चित चार-बिट विंडो में पैक करने से स्ट्रीम {011110011111} मिलती है। एक निश्चित विंडो आकार जानने का मतलब है कि एक सीमांकक की कोई आवश्यकता नहीं है।
एन्कोडिंग और संपीड़न अलग-अलग चरण हैं, इसलिए आरएलई और बिट-पैकिंग कच्चे डेटा के मूल्य-एन्कोडिंग या डिक्शनरी-एन्कोडिंग के परिणाम पर लागू होते हैं। इसके अलावा, एक ही कॉलम सेगमेंट के डेटा में मिश्रण . हो सकता है आरएलई और बिट-पैकिंग संपीड़न का। RLE-संपीड़ित डेटा को शुद्ध . कहा जाता है , और बिट-पैक संपीड़ित डेटा को अशुद्ध . कहा जाता है . एक स्तंभ खंड में शुद्ध और अशुद्ध दोनों डेटा हो सकता है।
स्थान की बचत जो एन्कोडिंग और संपीड़न के माध्यम से प्राप्त की जा सकती है, आदेश देने पर निर्भर हो सकती है। एक पंक्ति समूह के भीतर सभी स्तंभ खंडों को समान रूप से क्रमबद्ध किया जाना चाहिए ताकि SQL सर्वर स्तंभ खंडों से पूरी पंक्तियों को कुशलता से फिर से बना सके। यह जानते हुए कि पंक्ति 123 प्रत्येक स्तंभ खंड में एक ही स्थान (123) पर संग्रहीत है, इसका अर्थ है कि पंक्ति संख्या को संग्रहीत करने की आवश्यकता नहीं है।
इस व्यवस्था का एक नकारात्मक पहलू यह है कि सामान्य सॉर्ट क्रम एक पंक्ति समूह में सभी स्तंभ खंडों के लिए चुना जाना है। एक विशेष क्रम एक कॉलम के लिए बहुत उपयुक्त हो सकता है, लेकिन अन्य कॉलम में महत्वपूर्ण अवसर चूक जाते हैं। यह सबसे स्पष्ट रूप से आरएलई संपीड़न के मामले में है। SQL सर्वर एक अच्छा समग्र संपीड़न परिणाम देने के लिए प्रत्येक पंक्ति समूह में स्तंभों को सॉर्ट करने का एक अच्छा तरीका निर्धारित करने के लिए Vertipaq तकनीक का उपयोग करता है।
SQL सर्वर वर्तमान में केवल RLE का उपयोग करता है एक स्तंभ खंड के भीतर जब न्यूनतम 64 . हो लगातार दोहराए जाने वाले मान। खंड में शेष मान बिट-पैक हैं। जैसा कि नोट किया गया है, कॉलम सेगमेंट में दोहराए जाने वाले मान सन्निहित के रूप में दिखाई देते हैं या नहीं, यह पंक्ति समूह के लिए चुने गए क्रम पर निर्भर करता है।
SQL सर्वर विशेषीकृत SIMD का समर्थन करता है बिट चौड़ाई के लिए 1 से 10 समावेशी, 12, और 21 बिट्स के लिए बिट अनपैकिंग। SQL सर्वर मानक पूर्णांक आकारों का भी उपयोग कर सकता है उदा। 16, 32, और 64 बिट बिट-पैकिंग के साथ। ये नंबर इसलिए चुने गए हैं क्योंकि ये अच्छी तरह से फिट होते हैं 64-बिट इकाई में। उदाहरण के लिए, एक इकाई में तीन 21-बिट सबयूनिट या 5 12-बिट सबयूनिट हो सकते हैं। SQL सर्वर नहीं बिट्स पैक करते समय 64-बिट सीमा पार करें।
जब प्रोसेसर AVX2 निर्देशों का समर्थन करता है तो SIMD 256-बिट रजिस्टर का उपयोग करता है, और SSE4.2 निर्देश उपलब्ध होने पर 128-बिट रजिस्टर करता है। अन्यथा, गैर-SIMD अनपैकिंग का उपयोग किया जा सकता है।
समूहीकृत कुल पुशडाउन शर्तें
हैश मैच एग्रीगेट . के साथ अधिकांश योजनाएं ऑपरेटर सीधे कॉलमस्टोर स्कैन . के ऊपर दस्तावेज़ीकरण में उल्लिखित सामान्य शर्तों के अधीन, ऑपरेटर संभावित रूप से समूहीकृत कुल पुशडाउन के लिए अर्हता प्राप्त करेगा।
समूहीकृत कुल पुशडाउन को रोके बिना कभी-कभी अतिरिक्त फ़िल्टर और भाव भी जोड़े जा सकते हैं। सामान्य नियम यह है कि फ़िल्टर या एक्सप्रेशन भी पुशडाउन में सक्षम होना चाहिए (हालांकि संगत एक्सप्रेशन अभी भी एक अलग कंप्यूट स्केलर में दिखाई दे सकते हैं। ) जैसा कि परिचय में बताया गया है, इन पहलुओं को अलग-अलग लेखों में विस्तार से शामिल किया जा सकता है।
वर्तमान में निष्पादन योजनाओं में यह इंगित करने के लिए कुछ भी नहीं है कि क्या किसी विशेष समुच्चय को आम तौर पर संगत माना जाता था समूहीकृत कुल पुशडाउन के साथ या नहीं। फिर भी, जब योजना आम तौर पर योग्य होती है समूहीकृत कुल पुशडाउन के लिए, पुशडाउन (तेज़) और गैर-पुशडाउन (धीमा) कोड पथ दोनों उपलब्ध कराए गए हैं।
प्रत्येक स्कैन आउटपुट बैच (900 पंक्तियों तक) एक रनटाइम निर्णय . करता है तेज़ और धीमे कोड पथों के बीच। यह लचीलापन पुशडाउन से अधिक से अधिक बैचों को लाभान्वित करने की अनुमति देता है। सबसे खराब स्थिति में, 'आम तौर पर संगत' योजना के बावजूद, कोई भी बैच रनटाइम पर तेज़ पथ का उपयोग नहीं करेगा।
निष्पादन योजना 'स्थानीय रूप से एकत्रित पंक्तियों' . के रूप में फास्ट-पाथ पुशडाउन प्रसंस्करण का परिणाम दिखाती है स्कैन से कोई संगत पंक्ति आउटपुट के साथ। स्लो-पाथ बैच हमेशा की तरह कॉलमस्टोर स्कैन से आउटपुट पंक्तियों के रूप में दिखाई देते हैं, जिसमें एकत्रीकरण स्कैन के बजाय एक अलग ऑपरेटर द्वारा किया जाता है।
एक एकल समूहीकृत समुच्चय और स्कैन संयोजन कुछ बैचों को तेज़ पथ पर और कुछ को धीमे पथ पर भेज सकता है, इसलिए स्थानीय रूप से एकत्रित कुछ, लेकिन सभी पंक्तियों को देखना पूरी तरह से संभव है। जब समूहीकृत कुल पुशडाउन सफल होता है, तो स्कैन के प्रत्येक आउटपुट बैच में समूहीकरण कुंजियाँ और योगदान देने वाली पंक्तियों का प्रतिनिधित्व करने वाला एक आंशिक समुच्चय होता है।
विस्तृत जांच
पुशडाउन प्रोसेसिंग का उपयोग किया जा सकता है या नहीं यह निर्धारित करने के लिए कई रनटाइम चेक हैं। हल्के ढंग से प्रलेखित चेकों में से हैं:
- कुल अतिप्रवाह की कोई संभावना नहीं होनी चाहिए ।
- कोई भी अशुद्ध (बिट-पैक) ग्रुपिंग कीज़ 10 बिट से अधिक चौड़ा नहीं होना चाहिए . शुद्ध (RLE एन्कोडेड) ग्रुपिंग कुंजियाँ शून्य की अशुद्ध चौड़ाई वाली मानी जाती हैं, इसलिए ये आमतौर पर कुछ बाधाएँ पेश करती हैं।
- पुशडाउन प्रसंस्करण को सार्थक माना जाना जारी रखना चाहिए , प्रत्येक आउटपुट बैच के अंत में अपडेट किए गए 'लाभ उपाय' का उपयोग करते हुए।
कुल अतिप्रवाह . की संभावना कुल के प्रकार, परिणाम डेटा प्रकार, वर्तमान आंशिक एकत्रीकरण मूल्यों और इनपुट डेटा के बारे में जानकारी के आधार पर प्रत्येक बैच के लिए रूढ़िवादी रूप से मूल्यांकन किया जाता है। उदाहरण के लिए, SQL सर्वर खंड मेटाडेटा से न्यूनतम और अधिकतम मान जानता है जैसा कि DMV sys.column_store_segments में दिखाया गया है . जहां अतिप्रवाह का खतरा होता है, बैच धीमी पथ प्रसंस्करण का उपयोग करेगा। यह ज्यादातर SUM . के लिए एक जोखिम है कुल।
अशुद्ध समूहीकरण कुंजी चौड़ाई . पर प्रतिबंध जोर देने योग्य है। यह केवल GROUP BY . के कॉलम पर लागू होता है क्लॉज जो वास्तव में निष्पादन योजना में समूहीकरण के आधार के रूप में उपयोग किया जाता है। ये सेट हमेशा एक जैसे नहीं होते हैं क्योंकि ऑप्टिमाइज़र के पास अनावश्यक समूहन कॉलम को हटाने, या अन्यथा समुच्चय को फिर से लिखने की स्वतंत्रता होती है, जब तक कि अंतिम क्वेरी परिणाम मूल क्वेरी विनिर्देश से मेल खाने की गारंटी हो। जहां कोई असमानता है, यह निष्पादन योजना में दिखाए गए समूहीकरण स्तंभ हैं जो मायने रखते हैं।
बड़ी कठिनाई यह जानना है कि क्या कोई समूह कॉलम बिट-पैकिंग का उपयोग करके संग्रहीत किया जाता है, और यदि हां, तो किस चौड़ाई का उपयोग किया गया था। यह जानना भी उपयोगी होगा कि RLE का उपयोग करके कितने मान एन्कोड किए गए थे। यह जानकारी column_store_segments . में हो सकती है DMV, लेकिन आज ऐसा नहीं है। जहां तक मुझे पता है, मेटाडेटा से बिट-पैकिंग और आरएलई जानकारी प्राप्त करने के लिए अभी कोई दस्तावेजी तरीका नहीं है। यह हमें गैर-दस्तावेज विकल्पों की तलाश में छोड़ देता है।
RLE और बिट-पैकिंग जानकारी ढूँढना
अनिर्दिष्ट DBCC CSINDEX हमें वह जानकारी दे सकते हैं जो हमें चाहिए। एसएसएमएस संदेश टैब में आउटपुट उत्पन्न करने के लिए इस आदेश के लिए ट्रेस ध्वज 3604 चालू होना चाहिए। हम जिस कॉलम सेगमेंट में रुचि रखते हैं, उसके बारे में जानकारी को देखते हुए, यह कमांड वापस आती है:
- सेगमेंट विशेषताएँ (
column_store_segments. के समान) ) - आरएलई जानकारी
- RLE डेटा में बुकमार्क करें
- बिटपैक जानकारी
अनिर्दिष्ट होने के कारण, कुछ विचित्रताएं हैं (जैसे कि क्लस्टर्ड कॉलमस्टोर के लिए कॉलम आईडी में एक जोड़ना, लेकिन गैर-क्लस्टर्ड कॉलमस्टोर नहीं), और यहां तक कि कुछ छोटी त्रुटियां भी। आपको व्यक्तिगत परीक्षण प्रणाली को छोड़कर किसी भी चीज़ पर इसका उपयोग नहीं करना चाहिए। उम्मीद है, एक दिन इसके बजाय इस डेटा तक पहुँचने के लिए एक समर्थित विधि प्रदान की जाएगी।
उदाहरण
दिखाने का सबसे अच्छा तरीका DBCC CSINDEX और इस पाठ में अब तक किए गए बिंदुओं को प्रदर्शित करना कुछ उदाहरणों के माध्यम से काम करना है। अनुसरण करने वाली स्क्रिप्ट मानती हैं कि dbo.Numbers . नामक एक तालिका है वर्तमान डेटाबेस में जिसमें 1 से कम से कम 16,384 तक के पूर्णांक हैं। दस लाख पूर्णांकों के साथ इस तालिका का मेरा मानक संस्करण बनाने के लिए यहां एक स्क्रिप्ट है:
IF OBJECT_ID(N'dbo.Numbers', N'U') IS NOT NULL
BEGIN
DROP TABLE dbo.Numbers;
END;
GO
WITH Ten(N) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1
)
SELECT
n = IDENTITY(int, 1, 1)
INTO dbo.Numbers
FROM Ten AS T10
CROSS JOIN Ten AS T100
CROSS JOIN Ten AS T1000
CROSS JOIN Ten AS T10000
CROSS JOIN Ten AS T100000
CROSS JOIN Ten AS T1000000
CROSS JOIN Ten AS T10000000
ORDER BY n
OFFSET 0 ROWS
FETCH FIRST 10 * 1000 * 1000 ROWS ONLY
OPTION
(MAXDOP 1);
GO
ALTER TABLE dbo.Numbers
ADD CONSTRAINT [PK dbo.Numbers n]
PRIMARY KEY CLUSTERED (n)
WITH
(
SORT_IN_TEMPDB = ON,
MAXDOP = 1,
FILLFACTOR = 100
);
सभी उदाहरण एक ही मूल परीक्षण तालिका का उपयोग करते हैं:पहला कॉलम c1 प्रत्येक पंक्ति के लिए एक अद्वितीय संख्या होती है। दूसरा कॉलम c2 अलग-अलग मानों की एक छोटी संख्या के लिए कई डुप्लीकेट से भरा हुआ है।
डेटा आबादी के बाद एक क्लस्टर्ड कॉलमस्टोर इंडेक्स बनाया जाता है ताकि सभी परीक्षण डेटा एक संपीड़ित पंक्ति समूह (कोई डेल्टा स्टोर नहीं) में समाप्त हो जाएं। यह कॉलम c2 . पर b-ट्री क्लस्टर इंडेक्स की जगह बनाया गया है उस कॉलम पर जल्दी से छाँटने की उपयोगिता पर विचार करने के लिए वर्टिपैक एल्गोरिथम को प्रोत्साहित करने के लिए। यह मूल परीक्षण सेटअप है:
USE Sandpit;
GO
DROP TABLE IF EXISTS dbo.Test;
GO
CREATE TABLE dbo.Test
(
c1 integer NOT NULL,
c2 integer NOT NULL
);
GO
DECLARE
@values integer = 512,
@dupes integer = 63;
INSERT dbo.Test
(c1, c2)
SELECT
N.n,
N.n % @values
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND @values * @dupes;
GO
-- Encourage VertiPaq
CREATE CLUSTERED INDEX CCSI ON dbo.Test (c2);
GO
CREATE CLUSTERED COLUMNSTORE INDEX CCSI
ON dbo.Test
WITH (MAXDOP = 1, DROP_EXISTING = ON);
कॉलम c2 . में डालने के लिए अलग-अलग मानों की संख्या के लिए दो चर हैं , और उनमें से प्रत्येक मान के लिए डुप्लीकेट की संख्या।
परीक्षण क्वेरी एक बहुत ही सरल समूहीकृत COUNT_BIG है कॉलम c2 . का उपयोग करके एकत्रीकरण कुंजी के रूप में:
-- The test query
SELECT
T.c2,
numrows = COUNT_BIG(*)
FROM dbo.Test AS T
GROUP BY
T.c2;
Columnstore अनुक्रमणिका जानकारी DBCC CSINDEX . का उपयोग करके प्रदर्शित की जाएगी प्रत्येक परीक्षण क्वेरी निष्पादन के बाद:
DECLARE
@dbname sysname = DB_NAME(),
@objectid integer = OBJECT_ID(N'dbo.Test', N'U');
DECLARE
@rowsetid bigint =
(
SELECT
P.hobt_id
FROM sys.partitions AS P
WHERE
P.[object_id] = @objectid
AND P.index_id = 1
AND P.partition_number = 1
),
@rowgroupid integer = 0,
@columnid integer =
COLUMNPROPERTY(@objectid, N'c2', 'ColumnId') + 1;
DBCC CSINDEX
(
@dbname,
@rowsetid,
@columnid,
@rowgroupid,
1, -- show segment data
2, -- print option
0, -- start bitpack unit (inclusive)
2 -- end bitpack unit (exclusive)
); लेखन के समय उपलब्ध SQL सर्वर के नवीनतम रिलीज़ संस्करण पर परीक्षण चलाए गए:Microsoft SQL Server 2017 RTM-CU13-OD बिल्ड 14.0.3049 विंडोज 10 प्रो पर डेवलपर संस्करण (64-बिट)। SQL सर्वर 2016 के नवीनतम बिल्ड पर भी चीजें ठीक काम करनी चाहिए।
टेस्ट 1:पुशडाउन, 9-बिट अशुद्ध कुंजियां
यह परीक्षण परीक्षण डेटा जनसंख्या स्क्रिप्ट का ठीक उसी तरह उपयोग करता है जैसा कि ऊपर लिखा गया है, 32,256 पंक्तियों वाली तालिका का निर्माण करता है। कॉलम c1 इसमें 1 से 32,256 तक की संख्याएँ होती हैं।
कॉलम c2 इसमें 512 अलग-अलग मान . हैं 0 से 511 तक समावेशी। c2 . में प्रत्येक मान 63 बार दोहराया गया , लेकिन c1 . में देखे जाने पर वे सन्निहित ब्लॉक के रूप में प्रकट नहीं होते हैं गण; वे 0 से 511 तक के मानों के माध्यम से 63 बार साइकिल चलाते हैं।
पूर्वगामी चर्चा को देखते हुए, हम उम्मीद करते हैं कि SQL सर्वर c2 . को स्टोर करेगा कॉलम डेटा का उपयोग कर:
- शब्दकोश एन्कोडिंग चूंकि डुप्लीकेट मानों की एक बड़ी संख्या है।
- कोई आरएलई नहीं . प्रति मान डुप्लिकेट (63) की संख्या RLE के लिए आवश्यक 64 की सीमा तक नहीं पहुंचती है।
- बिट-पैकिंग आकार 9 . 512 विशिष्ट शब्दकोश प्रविष्टियाँ 9 बिट्स (2 ^ 9 =512) में बिल्कुल फिट होंगी। प्रत्येक 64-बिट इकाई में अधिकतम सात 9-बिट सबयूनिट होंगे।
DBCC CSINDEX . का उपयोग करके यह सब सही होने की पुष्टि की गई है क्वेरी:
सेगमेंट विशेषताएं आउटपुट का अनुभाग शब्दकोश एन्कोडिंग shows दिखाता है (टाइप 2; encodingType . के लिए मान sys.column_store_segments . पर दस्तावेज़ के रूप में हैं )।
संस्करण =1 एन्कोडिंग टाइप =2 हैनल =0
बेसआईडी =-1 परिमाण =-1.000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =511
NullValue =-1 OnDiskSize =37944 रोकाउंट =32256
RLE अनुभाग कोई RLE डेटा नहीं दिखाता है , बिट-पैक क्षेत्र के लिए केवल एक सूचक, और शून्य मान के लिए एक खाली प्रविष्टि:
आरएलई हैडर:
लोब प्रकार =3 RLE सरणी गणना (मूल इकाइयों के संदर्भ में) =2
RLE सरणी प्रविष्टि आकार =8
RLE डेटा:
इंडेक्स =0 बिटपैक ऐरे इंडेक्स =0 काउंट =32256
इंडेक्स =1 वैल्यू =0 काउंट =0
बिटपैक डेटा हैडर अनुभाग बिटपैक आकार 9 . दिखाता है और उपयोग की गई 4,608 बिटपैक इकाइयां:
बिटपैक डेटा हैडर:
बिटपैक एंट्री साइज =9 बिटपैक यूनिट काउंट =4608 बिटपैक मिनीआईडी =3
बिटपैक डेटासाइज =36864
बिटपैक डेटा अनुभाग DBCC CSINDEX के लिए अंतिम दो पैरामीटर द्वारा अनुरोधित पहले दो बिटपैक इकाइयों में संग्रहीत मान दिखाता है आज्ञा। याद रखें कि प्रत्येक 64-बिट इकाई में 9 बिट्स (7 x 9 =63 बिट्स) के 7 सबयूनिट (संख्या 0 से 6) हो सकते हैं। कुल मिलाकर 4,608 इकाइयों में 4,608 * 7 =32,256 पंक्तियाँ हैं:
यूनिट 0 सबयूनिट 0 =383
यूनिट 0 सबयूनिट 1 =255
यूनिट 0 सबयूनिट 2 =127
यूनिट 0 सबयूनिट 3 =510
यूनिट 0 सबयूनिट 4 =381
यूनिट 0 सबयूनिट 5 =253
यूनिट 0 सबयूनिट 6 =125
यूनिट 1 सबयूनिट 0 =508
यूनिट 1 सबयूनिट 1 =379
यूनिट 1 सबयूनिट 2 =251
यूनिट 1 सबयूनिट 3 =123
यूनिट 1 सबयूनिट 4 =506
यूनिट 1 सबयूनिट 5 =377
यूनिट 1 सबयूनिट 6 =249
चूँकि ग्रुपिंग कुंजियाँ बिट-पैकिंग . का उपयोग करती हैं 10 से कम या उसके बराबर के आकार के साथ , हम उम्मीद करते हैं समूहीकृत कुल पुशडाउन यहाँ काम करने के लिए। वास्तव में, निष्पादन योजना से पता चलता है कि सभी पंक्तियों को स्थानीय रूप से Columnstore अनुक्रमणिका स्कैन . पर एकत्रित किया गया था ऑपरेटर:

योजना xml में ActualLocallyAggregatedRows="32256" . शामिल है अनुक्रमणिका स्कैन के लिए रनटाइम जानकारी में।
टेस्ट 2:कोई पुशडाउन नहीं, 12-बिट अशुद्ध कुंजियां
यह परीक्षण @values . को बदल देता है @dupes . रखते हुए 1025 पर पैरामीटर 63 पर। यह 64,575 पंक्तियों की एक तालिका देता है, जिसमें 1,025 अलग-अलग मान . हैं कॉलम में c2 0 से 1024 तक चल रहा है। c2 . में प्रत्येक मान 63 बार दोहराया गया ।
SQL सर्वर c2 को स्टोर करता है कॉलम डेटा का उपयोग कर:
- शब्दकोश एन्कोडिंग चूंकि डुप्लीकेट मानों की एक बड़ी संख्या है।
- कोई आरएलई नहीं . प्रति मान डुप्लिकेट (63) की संख्या RLE के लिए आवश्यक 64 की सीमा तक नहीं पहुंचती है।
- 12 आकार के साथ थोड़ा सा पैक किया हुआ . 1,025 विशिष्ट शब्दकोश प्रविष्टियां 10 बिट्स (2^10 =1,024) में बिल्कुल फिट नहीं होंगी। वे 11 बिट्स में फिट होंगे लेकिन SQL सर्वर पहले बताए गए बिट-पैकिंग आकार का समर्थन नहीं करता है। अगला सबसे छोटा आकार 12 बिट है। बिट-पैकिंग के लिए हार्ड बॉर्डर वाली 64-बिट इकाइयों का उपयोग करते हुए, 12-बिट सबयूनिट्स की तुलना में 64 बिट्स में 11-बिट सबयूनिट फिट नहीं हो सकते। किसी भी तरह से, 5 सबयूनिट 64-बिट इकाई में फ़िट होंगे।
DBCC CSINDEX आउटपुट उपरोक्त विश्लेषण की पुष्टि करता है:
संस्करण =1 एन्कोडिंग प्रकार =2 हैनल्स =0
BaseId =-1 परिमाण =-1.000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =1024
NullValue =-1 OnDiskSize =104400 रोकाउंट =64575
आरएलई हैडर:
लोब प्रकार =3 RLE सरणी गणना (मूल इकाइयों के संदर्भ में) =2
RLE सरणी प्रविष्टि आकार =8
आरएलई डेटा:
इंडेक्स =0 बिटपैक ऐरे इंडेक्स =0 काउंट =64575
इंडेक्स =1 वैल्यू =0 काउंट =0
बिटपैक डेटा हैडर:
बिटपैक एंट्री साइज =12 बिटपैक यूनिट काउंट =12915 बिटपैक मिनीआईडी =3
बिटपैक डेटासाइज =103320
बिटपैक डेटा:
यूनिट 0 सबयूनिट 0 =767
यूनिट 0 सबयूनिट 1 =510
यूनिट 0 सबयूनिट 2 =254
यूनिट 0 सबयूनिट 3 =1021
यूनिट 0 सबयूनिट 4 =765
यूनिट 1 सबयूनिट 0 =507
यूनिट 1 सबयूनिट 1 =250
यूनिट 1 सबयूनिट 2 =1019
यूनिट 1 सबयूनिट 3 =761
यूनिट 1 सबयूनिट 4 =505
चूंकि अशुद्ध समूहीकरण कुंजियों का आकार 10 से अधिक . होता है , हम उम्मीद करते हैं समूहीकृत कुल पुशडाउन काम नहीं करना है यहाँ। इसकी पुष्टि निष्पादन योजना से होती है जो स्थानीय रूप से एकत्रित शून्य पंक्तियों को दिखाती है कॉलमस्टोर इंडेक्स स्कैन . पर ऑपरेटर:
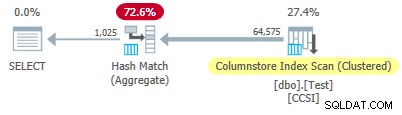
Columnstore Index Scan . द्वारा सभी 64,575 पंक्तियाँ (बैच में) उत्सर्जित होती हैं और बैच मोड में हैश मैच एग्रीगेट . द्वारा एकत्रित किया गया ऑपरेटर। ActualLocallyAggregatedRows अनुक्रमणिका स्कैन के लिए xml योजना रनटाइम जानकारी से विशेषता अनुपलब्ध है।
टेस्ट 3:पुशडाउन, प्योर कीज़
यह परीक्षण @dupes . को बदल देता है RLE को अनुमति देने के लिए पैरामीटर 63 से 64 तक। @values पैरामीटर को 16,384 में बदल दिया गया है (पंक्तियों की कुल संख्या के लिए अधिकतम अभी भी एक पंक्ति समूह में फिट होने के लिए)। @values . के लिए चुनी गई सटीक संख्या महत्वपूर्ण नहीं है - बिंदु प्रत्येक अद्वितीय मूल्य के 64 डुप्लिकेट उत्पन्न करना है ताकि आरएलई का उपयोग किया जा सके।
SQL सर्वर c2 को स्टोर करता है कॉलम डेटा का उपयोग कर:
- शब्दकोश एन्कोडिंग दोहराए गए मानों के कारण।
- आरएलई. प्रत्येक विशिष्ट मान के लिए उपयोग किया जाता है क्योंकि प्रत्येक 64 की सीमा को पूरा करता है।
- कोई भी डेटा पैक नहीं है . यदि कोई हो, तो वह आकार 16 का उपयोग करेगा। आकार 12 पर्याप्त बड़ा नहीं है (2^12 =4,096 अलग-अलग मान) और आकार 21 बेकार होगा। 16,384 विशिष्ट मान 14 बिट्स में फ़िट होंगे लेकिन, पहले की तरह, इनमें से कोई भी 16-बिट सबयूनिट्स की तुलना में 64-बिट इकाई में फ़िट नहीं हो सकता।
DBCC CSINDEX आउटपुट उपरोक्त की पुष्टि करता है (केवल कुछ आरएलई प्रविष्टियां और स्पेस कारणों से दिखाए गए बुकमार्क):
संस्करण =1 एन्कोडिंग प्रकार =2 हैनल =0
बेसआईडी =-1 परिमाण =-1.000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =16383
NullValue =-1 OnDiskSize =131648 रोकाउंट =1048576
आरएलई हैडर:
लोब प्रकार =3 RLE सरणी गणना (मूल इकाइयों के संदर्भ में) =16385
RLE सरणी प्रविष्टि आकार =8
आरएलई डेटा:
इंडेक्स =0 वैल्यू =3 काउंट =64
इंडेक्स =1 वैल्यू =1538 काउंट =64
इंडेक्स =2 वैल्यू =3072 काउंट =64
इंडेक्स =3 वैल्यू =4608 काउंट =64
इंडेक्स =4 वैल्यू =6142 काउंट =64
…
इंडेक्स =16381 वैल्यू =8954 काउंट =64
इंडेक्स =16382 वैल्यू =10489 काउंट =64
इंडेक्स =16383 वैल्यू =12025 काउंट =64
इंडेक्स =16384 वैल्यू =0 काउंट =0
बुकमार्क हैडर:
बुकमार्क संख्या =65 बुकमार्क दूरी =16384 बुकमार्क आकार =520
बुकमार्क डेटा:
स्थिति =0 सूचकांक =64
स्थिति =512 सूचकांक =16448
स्थिति =1024 सूचकांक =32832
…
स्थिति =31744 सूचकांक =1015872
स्थिति =32256 सूचकांक =1032256
स्थिति =32768 सूचकांक =1048577
बिटपैक डेटा हैडर:
बिटपैक एंट्री साइज =16 बिटपैक यूनिट काउंट =0 बिटपैक मिनीआईडी =3
बिटपैक डेटासाइज =0
चूंकि समूहीकरण कुंजियाँ शुद्ध हैं (आरएलई का उपयोग किया जाता है), समूहीकृत कुल पुशडाउन यहाँ अपेक्षित है। निष्पादन योजना स्थानीय रूप से एकत्रित सभी पंक्तियों . को दिखा कर इसकी पुष्टि करती है कॉलमस्टोर इंडेक्स स्कैन . पर ऑपरेटर:
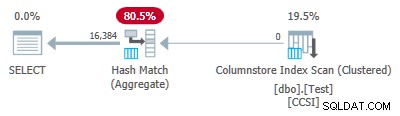
योजना xml में ActualLocallyAggregatedRows="1048576" . शामिल है अनुक्रमणिका स्कैन के लिए रनटाइम जानकारी में।
टेस्ट 4:10-बिट अशुद्ध कुंजियां
यह परीक्षण @values . सेट करता है से 1024 और @dupes 63 तक, 64,512 पंक्तियों की एक तालिका देते हुए, 1,024 अलग-अलग मानों . के साथ कॉलम में c2 0 से 1,023 तक के मानों के साथ। c2 . में प्रत्येक मान 63 बार दोहराया गया ।
सबसे महत्वपूर्ण , बी-ट्री क्लस्टर इंडेक्स अब कॉलम c1 . पर बनाया गया है कॉलम के बजाय c2 . क्लस्टर्ड कॉलमस्टोर अभी भी बी-ट्री क्लस्टर्ड इंडेक्स को बदल देता है। यह स्क्रिप्ट का बदला हुआ हिस्सा है:
-- Note column c1 now! CREATE CLUSTERED INDEX CCSI ON dbo.Test (c1); GO CREATE CLUSTERED COLUMNSTORE INDEX CCSI ON dbo.Test WITH (MAXDOP = 1, DROP_EXISTING = ON);
SQL सर्वर c2 को स्टोर करता है कॉलम डेटा का उपयोग कर:
- शब्दकोश एन्कोडिंग डुप्लिकेट के कारण।
- कोई आरएलई नहीं . प्रति मान डुप्लिकेट (63) की संख्या RLE के लिए आवश्यक 64 की सीमा तक नहीं पहुंचती है।
- 10 आकार के साथ बिट-पैकिंग . 1,024 विशिष्ट शब्दकोश प्रविष्टियां 10 बिट्स (2^10 =1,024) में बिल्कुल फिट होती हैं। प्रत्येक 64-बिट इकाई में 10 बिट्स के छह सबयूनिट संग्रहीत किए जा सकते हैं।
DBCC CSINDEX आउटपुट है:
संस्करण =1 एन्कोडिंग टाइप =2 हैनल्स =0
BaseId =-1 परिमाण =-1.000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =1023
NullValue =-1 OnDiskSize =87096 रोकाउंट =64512
आरएलई हैडर:
लोब प्रकार =3 RLE सरणी गणना (मूल इकाइयों के संदर्भ में) =2
RLE सरणी प्रविष्टि आकार =8
आरएलई डेटा:
इंडेक्स =0 बिटपैक ऐरे इंडेक्स =0 काउंट =64512
इंडेक्स =1 वैल्यू =0 काउंट =0
बिटपैक डेटा हैडर:
बिटपैक एंट्री साइज =10 बिटपैक यूनिट काउंट =10752 बिटपैक मिनीआईडी =3
बिटपैक डेटासाइज =86016
बिटपैक डेटा:
यूनिट 0 सबयूनिट 0 =766
यूनिट 0 सबयूनिट 1 =509
यूनिट 0 सबयूनिट 2 =254
यूनिट 0 सबयूनिट 3 =1020
यूनिट 0 सबयूनिट 4 =764
यूनिट 0 सबयूनिट 5 =506
यूनिट 1 सबयूनिट 0 =250
यूनिट 1 सबयूनिट 1 =1018
यूनिट 1 सबयूनिट 2 =760
यूनिट 1 सबयूनिट 3 =504
यूनिट 1 सबयूनिट 4 =247
यूनिट 1 सबयूनिट 5 =1014
चूंकि अशुद्ध ग्रुपिंग कुंजियाँ 10 से कम या उसके बराबर आकार का उपयोग करती हैं, हम उम्मीद करेंगे ग्रुपेड एग्रीगेट पुशडाउन यहाँ काम करने के लिए। लेकिन ऐसा नहीं होता है . निष्पादन योजना से पता चलता है कि 64,512 पंक्तियों में से 54,612 को हैश मैच एग्रीगेट पर एकत्रित किया गया था। ऑपरेटर:
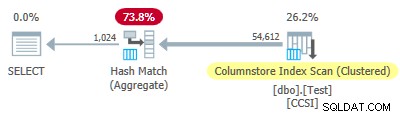
योजना xml में ActualLocallyAggregatedRows="9900" . शामिल है अनुक्रमणिका स्कैन के लिए रनटाइम जानकारी में। इसका अर्थ है समूहीकृत कुल पुशडाउन 9,900 पंक्तियों के लिए उपयोग किया गया था, लेकिन अन्य 54,612 के लिए उपयोग नहीं किया गया था!
प्रतिक्रिया तंत्र
SQL सर्वर ने समूहीकृत कुल पुशडाउन का उपयोग करके प्रारंभ किया इस निष्पादन के लिए क्योंकि अशुद्ध समूहीकरण कुंजियाँ 10-बिट्स-या-कम मानदंडों को पूरा करती हैं। यह कुल 11 बैचों (प्रत्येक 900 पंक्तियों में से =9,900 पंक्तियों की कुल) के लिए चली। उस समय, समूहीकृत कुल पुशडाउन . की प्रभावशीलता को मापने वाला एक फ़ीडबैक तंत्र फैसला किया कि यह काम नहीं कर रहा था, और इसे बंद कर दिया . शेष बैच सभी पुशडाउन अक्षम के साथ संसाधित किए गए थे।
फीडबैक अनिवार्य रूप से उत्पादित समूहों की संख्या के विरुद्ध एकत्रित पंक्तियों की संख्या की तुलना करता है। यह 100 के मान से शुरू होता है और प्रत्येक पुशडाउन आउटपुट बैच के अंत में समायोजित किया जाता है। यदि मान 10 या उससे कम हो जाता है, तो वर्तमान समूह संचालन के लिए पुशडाउन अक्षम कर दिया जाता है।
पुश-डाउन एकत्रीकरण प्रयास कितनी बुरी तरह चल रहा है, इस पर निर्भर करते हुए 'पुशडाउन लाभ उपाय' को कम या ज्यादा किया जाता है। यदि आउटपुट बैच में औसतन प्रति ग्रुपिंग कुंजी 8 से कम पंक्तियाँ हैं, तो वर्तमान लाभ मूल्य 22% कम हो जाता है। यदि 8 से अधिक लेकिन 16 से कम हैं, तो मीट्रिक 11% कम हो जाती है।
दूसरी ओर, यदि चीजें सुधरती हैं, और आउटपुट बैच के लिए प्रति समूह कुंजी 16 या अधिक पंक्तियाँ बाद में सामने आती हैं, तो मीट्रिक को 100 पर रीसेट कर दिया जाता है, और इसे समायोजित करना जारी रहता है क्योंकि स्कैन द्वारा आंशिक कुल बैच तैयार किए जाते हैं।
कॉलम c1 पर मूल बी-ट्री क्लस्टर इंडेक्स के कारण इस परीक्षण में डेटा पुशडाउन के लिए विशेष रूप से अनुपयोगी क्रम में प्रस्तुत किया गया था। . जब इस तरह प्रस्तुत किया जाता है, तो कॉलम c2 . में मान 0 से शुरू करते हैं और 1 से बढ़ते हैं जब तक कि वे 1,023 तक नहीं पहुंच जाते, फिर वे फिर से चक्र शुरू करते हैं। 1,023 अलग-अलग मान यह सुनिश्चित करने के लिए पर्याप्त से अधिक हैं कि प्रत्येक 900-पंक्ति आउटपुट बैच में प्रत्येक कुंजी के लिए केवल एक आंशिक रूप से एकत्रित पंक्ति होती है। यह सुखी राज्य नहीं है।
यदि 63 के बजाय प्रति मूल्य 64 डुप्लिकेट होते, तो SQL सर्वर c2 द्वारा सॉर्ट करने पर विचार करता कॉलमस्टोर इंडेक्स का निर्माण करते समय, और इसलिए आरएलई संपीड़न का उत्पादन किया। वैसे भी, 22% जुर्माना हर बैच के बाद शुरू होता है। 100 से शुरू होकर और उसी राउंड-अप पूर्णांक अंकगणित का उपयोग करते हुए, मीट्रिक मानों का क्रम इस प्रकार है:
-- @metric := FLOOR(@metric * 0.78 + 0.5); -- 100, 78, 61, 48, 37, 29, 23, 18, 14, 11, *9*
ग्यारहवां बैच मीट्रिक को घटाकर 10 या उससे कम कर देता है, और पुशडाउन अक्षम कर दिया जाता है। 900 पंक्तियों के 11 बैच निष्पादन योजना में दिखाई गई 9,900 स्थानीय रूप से एकत्रित पंक्तियों के लिए जिम्मेदार हैं।
900 अलग-अलग मानों वाली वेरिएशन
परीक्षण 4 में 901 अलग-अलग मानों के साथ समान व्यवहार देखा जा सकता है, यह मानते हुए कि पंक्तियों को उसी अनुपयोगी क्रम में प्रस्तुत किया जाता है।
@values को बदलना 900 के पैरामीटर के साथ बाकी सब कुछ समान रखते हुए निष्पादन योजना पर एक नाटकीय प्रभाव पड़ता है:
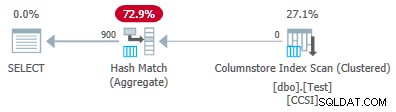
अब सभी 900 समूहों को स्कैन में एकत्र किया गया है! Xml योजना गुण ActualLocallyAggregatedRows="56700" . दिखाते हैं . ऐसा इसलिए है क्योंकि समूहीकृत कुल पुशडाउन एक बैच में 900 समूहीकरण कुंजियाँ और आंशिक समुच्चय बनाए रखता है। यह कभी भी एक नए कुंजी मान का सामना नहीं करता है जो बैच में नहीं है, इसलिए एक नया आउटपुट बैच शुरू करने का कोई कारण नहीं है।
Only ever producing one batch means the feedback mechanism never gets chance to reduce the “pushdown benefit measure” to the point where grouped aggregate pushdown is disabled. It never would anyway, since the pushdown is very successful — 56,700 rows for 900 grouping keys is 63 per key, well above the threshold for benefit measure reduction.
Extended Event
There is very little information available in execution plans to help determine why grouped aggregation pushdown was either not tried, or was not successful. There is, however, an Extended Event named query_execution_dynamic_push_down_statistics in the execution category of the Analytic channel.
It provides the following Event Fields:
rows_not_pushed_down_due_to_encoding
Description:Number of rows not pushed to scan because of the the total encoded key length.
This identifies impure data over the 10-bit limit as shown in test 2.
rows_not_pushed_down_due_to_possible_overflow
Description:Number of rows not pushed to scan because of a possible overflow
rows_not_pushed_down_due_to_pushdown_disabled
Description:Number of rows not pushed to scan (only) because dynamic pushdown was disabled
This occurs when the pushdown benefit measure drops below 10 as described in test 4.
rows_pushed_down_in_thread
Description:Number of locally aggregated rows in thread
This corresponds with the value for ‘locally aggregated rows’ shown in execution plans.
नोट: No event is recorded if grouped aggregation pushdown is specifically disabled using trace flag 9373. All types of pushdown to a nonclustered columnstore index can be specifically disabled with trace flag 9386. All types of pushdown activity can be disabled with trace flag 9354.