क्या आपने कभी माइक्रोसॉफ्ट या माइक्रोसॉफ्ट पार्टनर से संपर्क किया है और उनके साथ चर्चा की है कि क्लाउड पर जाने के लिए क्या खर्च आएगा? यदि हां, तो आपने Azure SQL डेटाबेस DTU कैलकुलेटर के बारे में सुना होगा, और आपने यह भी पढ़ा होगा कि एंडी मॉलन द्वारा इसे कैसे रिवर्स इंजीनियर किया गया है। DTU कैलकुलेटर एक निःशुल्क टूल है जिसका उपयोग आप अपने सर्वर से प्रदर्शन मीट्रिक अपलोड करने के लिए कर सकते हैं, और यदि आप उस सर्वर को Azure SQL डेटाबेस (या SQL डेटाबेस इलास्टिक पूल में) माइग्रेट करना चाहते हैं, तो उपयुक्त सेवा स्तर निर्धारित करने के लिए डेटा का उपयोग कर सकते हैं।
ऐसा करने के लिए, आपको एक विशिष्ट उत्पादन कार्यभार की अवधि के दौरान या तो शेड्यूल करना होगा या मैन्युअल रूप से एक स्क्रिप्ट (कमांड लाइन या पॉवरशेल, डीटीयू कैलकुलेटर वेबसाइट पर डाउनलोड के लिए उपलब्ध) चलाना होगा।
यदि आप एक बड़े वातावरण का विश्लेषण करने का प्रयास कर रहे हैं, या समय पर विशिष्ट बिंदुओं से डेटा का विश्लेषण करना चाहते हैं, तो यह एक घर का काम बन सकता है। कई मामलों में, कई डीबीए में निगरानी उपकरण का कुछ स्वाद होता है जो पहले से ही उनके लिए प्रदर्शन डेटा कैप्चर कर रहा है। कई मामलों में, यह संभवतः या तो पहले से ही आवश्यक मैट्रिक्स को कैप्चर कर रहा है, या आपको आवश्यक डेटा को कैप्चर करने के लिए आसानी से कॉन्फ़िगर किया जा सकता है। आज, हम यह देखने जा रहे हैं कि SentryOne का लाभ कैसे उठाया जाए ताकि हम DTU कैलकुलेटर को उपयुक्त डेटा प्रदान कर सकें।
शुरू करने के लिए, आइए डीटीयू कैलकुलेटर वेबसाइट पर उपलब्ध कमांड लाइन उपयोगिता और पावरशेल स्क्रिप्ट द्वारा खींची गई जानकारी को देखें; इसमें 4 प्रदर्शन मॉनिटर काउंटर हैं जिन्हें यह कैप्चर करता है:
- प्रोसेसर -% प्रोसेसर समय
- लॉजिकल डिस्क - डिस्क रीड/सेकंड
- लॉजिकल डिस्क - डिस्क राइट/सेकंड
- डेटाबेस - लॉग बाइट्स फ्लश/सेकंड
पहला कदम यह निर्धारित करना है कि क्या ये मीट्रिक पहले से ही SQL संतरी में डेटा संग्रह के हिस्से के रूप में कैप्चर किए गए हैं। खोज के लिए, मैं जेसन हॉल द्वारा इस ब्लॉग पोस्ट को पढ़ने का सुझाव देता हूं, जहां वह बात करता है कि डेटा कैसे निर्धारित किया जाता है और आप इसे कैसे पूछ सकते हैं। मैं यहां इसके प्रत्येक चरण से नहीं जा रहा हूं, लेकिन आपको उस संपूर्ण ब्लॉग श्रृंखला को पढ़ने और बुकमार्क करने के लिए प्रोत्साहित करता हूं।
जब मैंने SentryOne डेटाबेस को देखा, तो मैंने पाया कि 4 में से 3 काउंटर पहले से ही डिफ़ॉल्ट रूप से कैप्चर किए जा रहे थे। केवल एक जो गायब था वह था [Database – Log Bytes Flushed/sec] , इसलिए मुझे इसे चालू करने में सक्षम होने की आवश्यकता थी। जस्टिन रान्डेल का एक और ब्लॉग पोस्ट था जो बताता है कि यह कैसे करना है।
संक्षेप में, आप [PerformanceAnalysisCounter] . को क्वेरी कर सकते हैं टेबल।
चयन आईडी, प्रदर्शन विश्लेषण काउंटर श्रेणी आईडी, प्रदर्शन विश्लेषण नमूना अंतराल आईडी, काउंटर रिसोर्सनाम, काउंटरनाम डीबीओ से।आप देखेंगे कि डिफ़ॉल्ट रूप से
[PerformanceAnalysisSampleIntervalID]0 पर सेट है - इसका मतलब है कि यह अक्षम है। इसे सक्षम करने के लिए आपको निम्न आदेश चलाने की आवश्यकता होगी। आपके द्वारा अभी-अभी चलाई गई SELECT क्वेरी से ID को खींचें और इस अद्यतन में इसका उपयोग करें:UPDATE dbo.PerformanceAnalysisCounter SET PerformanceAnalysisSampleIntervalID =1 जहां आईडी =166;अपडेट चलाने के बाद, आपको इस लक्ष्य के लिए प्रासंगिक SentryOne निगरानी सेवा (सेवाओं) को पुनरारंभ करना होगा, ताकि नया काउंटर डेटा एकत्र किया जा सके।
ध्यान दें कि मैंने
[PerformanceAnalysisSampleIntervalID]. सेट किया है 1 तक ताकि डेटा हर 10 सेकंड में कैप्चर किया जा सके, हालांकि, आप कम सटीकता की कीमत पर एकत्रित डेटा के आकार को कम करने के लिए इस डेटा को कम बार कैप्चर कर सकते हैं। देखें[PerformanceAnalysisSampleInterval]उन मानों की सूची के लिए तालिका जिनका आप उपयोग कर सकते हैं।डेटा के तुरंत तालिकाओं में प्रवाहित होने की अपेक्षा न करें; इस प्रणाली के माध्यम से अपना रास्ता बनाने में समय लगेगा। आप निम्न क्वेरी के साथ जनसंख्या की जांच कर सकते हैं:
सेलेक्ट टॉप (100) * dbo.PerformanceAnalysisDatabaseCounter से जहां PerformanceAnalysisCounterID =166;एक बार जब आप पुष्टि कर लेते हैं कि डेटा दिखाई दे रहा है, तो आपके पास डीटीयू कैलकुलेटर द्वारा आवश्यक प्रत्येक मीट्रिक के लिए डेटा होना चाहिए, हालांकि आप इसे तब तक निकालने के लिए इंतजार करना चाहेंगे जब तक आपके पास पूर्ण कार्यभार या व्यावसायिक चक्र से प्रतिनिधि नमूना न हो।
यदि आप जेसन के ब्लॉग पोस्ट के माध्यम से पढ़ते हैं, तो आप देखेंगे कि डेटा विभिन्न रोलअप तालिकाओं में संग्रहीत है, और इनमें से प्रत्येक रोलअप तालिका में अलग-अलग अवधारण दर हैं। यदि मैं समय के साथ कार्यभार का विश्लेषण कर रहा हूं, तो इनमें से कई मेरी अपेक्षा से कम हैं। हालांकि इन्हें बदलना संभव हो सकता है, लेकिन यह सबसे बुद्धिमानी नहीं हो सकती है। क्योंकि जो मैं आपको दिखा रहा हूं वह असमर्थित है, हो सकता है कि आप SentryOne सेटिंग्स के साथ बहुत अधिक छेड़छाड़ करने से बचना चाहें क्योंकि इससे प्रदर्शन, विकास या दोनों पर नकारात्मक प्रभाव पड़ सकता है।
इसकी भरपाई करने के लिए, मैंने एक स्क्रिप्ट बनाई जो मुझे विभिन्न रोलअप तालिकाओं के लिए आवश्यक डेटा निकालने की अनुमति देती है और उस डेटा को अपने स्थान पर संग्रहीत करती है, ताकि मैं अपने स्वयं के प्रतिधारण को नियंत्रित कर सकूं और SentryOne कार्यक्षमता में हस्तक्षेप न कर सकूं।
तालिका:dbo.AzureDatabaseDTUData
मैंने
[AzureDatabaseDTUData]. नामक एक तालिका बनाई है और इसे SentryOne डेटाबेस में संग्रहीत किया। मेरे द्वारा बनाई गई प्रक्रिया स्वचालित रूप से इस तालिका को उत्पन्न करेगी यदि यह मौजूद नहीं है, इसलिए इसे मैन्युअल रूप से करने की कोई आवश्यकता नहीं है जब तक कि आप इसे संग्रहीत नहीं करना चाहते हैं। आप चाहें तो इसे एक अलग डेटाबेस में स्टोर कर सकते हैं, ऐसा करने के लिए आपको बस स्क्रिप्ट को संपादित करना होगा। तालिका इस तरह दिखती है:टेबल डीबीओ बनाएं। AzureDatabaseDTUdata (आईडी बिगिंट पहचान (1,1) शून्य नहीं है, डिवाइस आईडी छोटा नहीं है, [टाइमस्टैम्प] डेटाटाइम शून्य नहीं है, काउंटरनाम nvarchar (256) शून्य नहीं है, [मान] फ्लोट शून्य नहीं है, इंस्टेंसनाम nvarchar ( 256) शून्य नहीं, CONSTRAINT PK_AzureDatabaseDTUडेटा प्राथमिक कुंजी (आईडी));प्रक्रिया:dbo.Custom_CollectDTUDataForDevice
यह संग्रहीत प्रक्रिया है जिसका उपयोग आप एक समय में सभी डीटीयू-विशिष्ट डेटा खींचने के लिए कर सकते हैं (बशर्ते आप पर्याप्त समय के लिए लॉग बाइट्स काउंटर एकत्र कर रहे हों), या इसे समय-समय पर एकत्रित डेटा में जोड़ने के लिए शेड्यूल करें आप डीटीयू कैलकुलेटर को आउटपुट जमा करने के लिए तैयार हैं। उपरोक्त तालिका की तरह, सेंट्रीऑन डेटाबेस में प्रक्रिया बनाई गई है, लेकिन आप इसे आसानी से कहीं और बना सकते हैं, ऑब्जेक्ट संदर्भों में केवल तीन या चार-भाग के नाम जोड़ें। प्रक्रिया का इंटरफ़ेस इस प्रकार है:
CREATE PROCEDURE [डीबीओ]। @ProcessorCounterID smallint =1858, -- प्रोसेसर (डिफ़ॉल्ट) @DiskReadCounterID smallint =64, -- डिस्क रीड/सेक (डिस्ककाउंटर) @DiskWritesCounterID smallint =67, -- डिस्क राइट्स/सेकंड (डिस्ककाउंटर) @LogBytesFlushCounterID smallint =166, -- लॉग बाइट्स फ्लश/सेकंड (डेटाबेस काउंटर) AS...नोट :पूरी प्रक्रिया थोड़ी लंबी है, इसलिए यह इस पोस्ट से जुड़ी हुई है (dbo.Custom_CollectDTUDataForDevice.sql_.zip)।
कुछ पैरामीटर हैं जिनका आप उपयोग कर सकते हैं। प्रत्येक का एक डिफ़ॉल्ट मान होता है, इसलिए यदि आप डिफ़ॉल्ट मानों के साथ ठीक हैं तो आपको उन्हें निर्दिष्ट करने की आवश्यकता नहीं है।
- @DeviceID - यह आपको निर्दिष्ट करने की अनुमति देता है कि क्या आप किसी विशिष्ट SQL सर्वर या सब कुछ के लिए डेटा एकत्र करना चाहते हैं। डिफ़ॉल्ट -1 है, जिसका अर्थ है कि सभी देखे गए SQL सर्वर की प्रतिलिपि बनाएँ। यदि आप केवल एक विशिष्ट उदाहरण के लिए जानकारी निर्यात करना चाहते हैं, तो
DeviceIDखोजें[dbo].[Device]तालिका, और उस मान को पास करें। आप केवल एक@DeviceIDपास कर सकते हैं एक समय में, इसलिए यदि आप सर्वर के एक सेट से गुजरना चाहते हैं, तो आप प्रक्रिया को कई बार कॉल कर सकते हैं, या आप उपकरणों के एक सेट का समर्थन करने के लिए प्रक्रिया को संशोधित कर सकते हैं। - @DaysToPurge - यह उस उम्र का प्रतिनिधित्व करता है जिस पर आप डेटा हटाना चाहते हैं। डिफ़ॉल्ट 14 दिन है, जिसका अर्थ है कि आप केवल 14 दिन पुराना डेटा प्राप्त करेंगे, और आपकी कस्टम तालिका में 14 दिनों से अधिक पुराना कोई भी डेटा हटा दिया जाएगा।
अन्य चार पैरामीटर फ्यूचर-प्रूफिंग के लिए हैं, यदि काउंटर आईडी के लिए सेंट्रीऑन एनम कभी भी बदलता है।
स्क्रिप्ट पर कुछ नोट्स:
- जब डेटा खींचा जाता है, तो यह काटे गए मिनट से अधिकतम मूल्य लेता है और उसे निर्यात करता है। इसका मतलब है कि एक मान प्रति मीट्रिक प्रति मिनट है, लेकिन यह अधिकतम कैप्चर किया गया मान है। यह महत्वपूर्ण है क्योंकि जिस तरह से डेटा को डीटीयू कैलकुलेटर में प्रस्तुत करने की आवश्यकता होती है।
- पहली बार जब आप निर्यात चलाते हैं, तो इसमें थोड़ा अधिक समय लग सकता है। ऐसा इसलिए है क्योंकि यह आपके पैरामीटर मानों के आधार पर सभी डेटा को खींच सकता है। प्रत्येक अतिरिक्त रन, निकाला गया एकमात्र डेटा वही है जो पिछले रन के बाद से नया है, इसलिए यह बहुत तेज़ होना चाहिए।
- आपको इस प्रक्रिया को एक समय सारिणी पर चलाने के लिए शेड्यूल करना होगा जो SentryOne पर्ज प्रक्रिया से आगे रहता है। मैंने जो किया है, वह रात में चलने के लिए एक SQL एजेंट जॉब बनाया है जो रात से पहले के सभी नए डेटा एकत्र करता है।
- चूंकि सेंट्रीऑन में शुद्ध करने की प्रक्रिया मीट्रिक के आधार पर भिन्न हो सकती है, आप अपनी कॉपी में पंक्तियों के साथ समाप्त हो सकते हैं जिसमें एक समय अवधि के लिए सभी 4 काउंटर शामिल नहीं हैं। हो सकता है कि आप अपने डेटा का विश्लेषण केवल उस समय से शुरू करना चाहें जब से आप अपनी निष्कर्षण प्रक्रिया शुरू करते हैं।
- मैंने प्रत्येक काउंटर के लिए रोलअप तालिका निर्धारित करने के लिए मौजूदा SentryOne प्रक्रियाओं से कोड के एक ब्लॉक का उपयोग किया। मैं तालिकाओं के वर्तमान नामों को हार्ड-कोड कर सकता था, हालांकि, SentryOne पद्धति का उपयोग करके, यह अंतर्निहित रोलअप प्रक्रियाओं में किसी भी परिवर्तन के साथ संगत होना चाहिए।
एक बार जब आपका डेटा एक स्टैंडअलोन तालिका में ले जाया जा रहा है, तो आप इसे डीटीयू कैलकुलेटर की अपेक्षा के रूप में बदलने के लिए एक PIVOT क्वेरी का उपयोग कर सकते हैं।
प्रक्रिया:dbo.Custom_ExportDataForDTUकैलकुलेटर
मैंने डेटा को CSV प्रारूप में निकालने के लिए एक और प्रक्रिया बनाई। इस प्रक्रिया के लिए कोड भी संलग्न है (dbo.Custom_ExportDataForDTUCalculator.sql_.zip)।
तीन पैरामीटर हैं:
- @DeviceID - आपके द्वारा एकत्रित किए जा रहे उपकरणों में से एक के अनुरूप छोटा और जिसे आप कैलकुलेटर में जमा करना चाहते हैं।
- @BeginTime - स्थानीय समय में प्रारंभ समय का प्रतिनिधित्व करने वाला डेटाटाइम; उदाहरण के लिए,
'2018-12-04 05:47:00.000'. प्रक्रिया यूटीसी में तब्दील हो जाएगी। यदि छोड़ा गया है, तो यह तालिका में सबसे पहले के मान से एकत्रित होगा। - @एंडटाइम - स्थानीय समय में फिर से अंत समय का प्रतिनिधित्व करने वाला डेटाटाइम; उदाहरण के लिए,
'2018-12-06 12:54:00.000'. यदि छोड़ा गया है, तो यह तालिका में नवीनतम मान तक एकत्रित हो जाएगा।
एक उदाहरण निष्पादन, SQLInstanceA . के लिए एकत्रित सभी डेटा प्राप्त करने के लिए 4 दिसंबर को सुबह 5:47 बजे और 6 दिसंबर को दोपहर 12:54 बजे के बीच।
EXEC SentryOne.dbo.custom_ExportDataForDTUCalculator @DeviceID =12, @BeginTime ='2018-12-04 05:47:00.000', @EndTime ='2018-12-06 12:54:00.000';
डेटा को CSV फ़ाइल में निर्यात करने की आवश्यकता होगी। डेटा के बारे में ही चिंतित न हों; मैंने सुनिश्चित किया कि परिणाम आउटपुट हों ताकि सीएसवी फ़ाइल में आपके सर्वर के बारे में कोई पहचान संबंधी जानकारी न हो, केवल दिनांक और मीट्रिक।
यदि आप SSMS में क्वेरी चलाते हैं, तो आप राइट-क्लिक कर सकते हैं और परिणाम निर्यात कर सकते हैं; हालांकि, आपके पास यहां सीमित विकल्प हैं और आपको डीटीयू कैलकुलेटर द्वारा अपेक्षित प्रारूप प्राप्त करने के लिए आउटपुट में हेरफेर करना होगा। (बेझिझक कोशिश करें और अगर आपको ऐसा करने का कोई तरीका मिल जाए तो मुझे बताएं।)
मैं केवल SSMS में बेक किए गए निर्यात विज़ार्ड का उपयोग करने की सलाह देता हूं। डेटाबेस पर राइट-क्लिक करें और टास्क -> एक्सपोर्ट डेटा पर जाएं। अपने डेटा स्रोत के लिए "एसक्यूएल सर्वर नेटिव क्लाइंट" का उपयोग करें और इसे अपने सेंट्रीऑन डेटाबेस (या जहां भी आपके पास संग्रहीत डेटा की प्रतिलिपि है) पर इंगित करें। अपने गंतव्य के लिए, आप "फ्लैट फ़ाइल गंतव्य" का चयन करना चाहेंगे। किसी स्थान पर ब्राउज़ करें, फ़ाइल को एक नाम दें, और फ़ाइल को CSV के रूप में सहेजें।
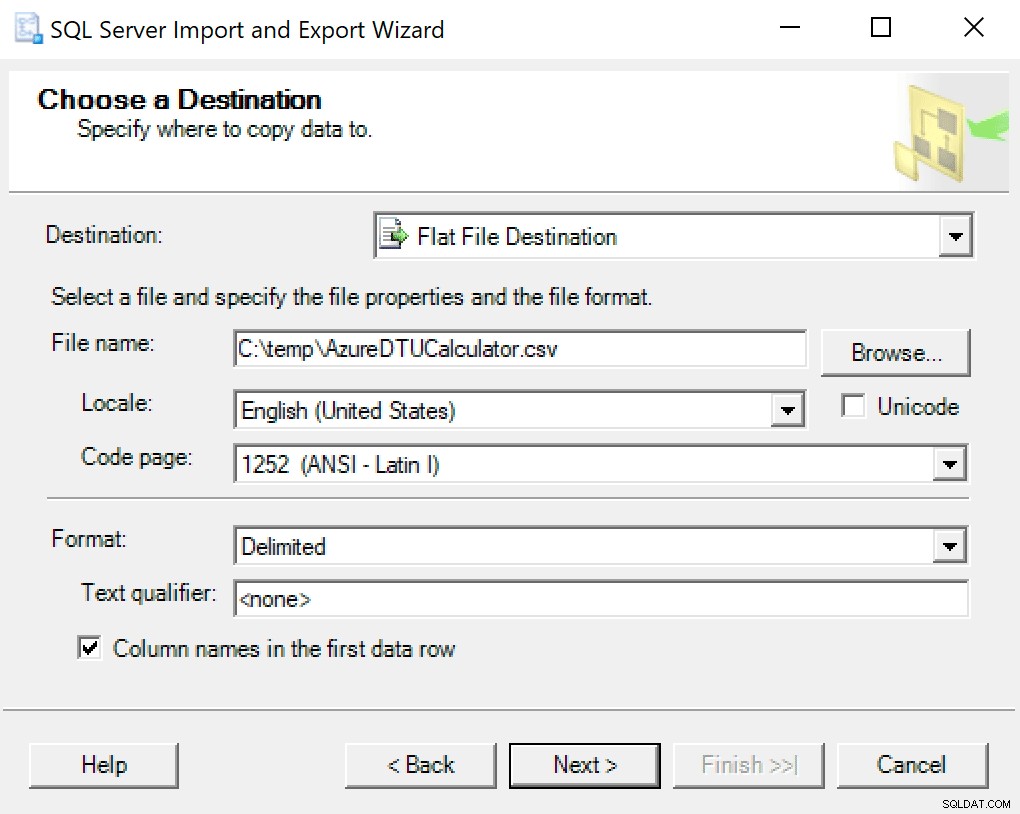
कोड पृष्ठ को अकेला छोड़ने का ध्यान रखें; कुछ त्रुटियाँ लौटा सकते हैं। मुझे पता है कि 1252 ठीक काम करता है। शेष मान डिफ़ॉल्ट के रूप में छोड़ देते हैं।
अगली स्क्रीन पर, विकल्प चुनें स्थानांतरण के लिए डेटा निर्दिष्ट करने के लिए एक प्रश्न लिखें ।
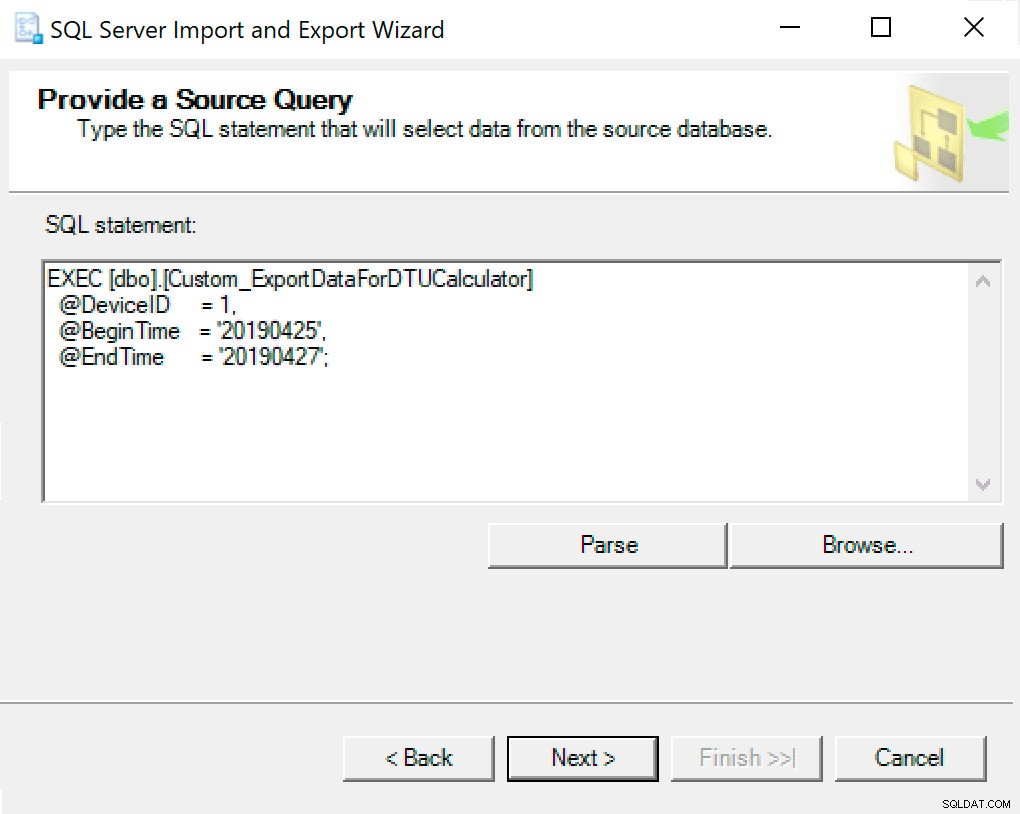
अगली विंडो में, अपने पैरामीटर सेट के साथ प्रक्रिया कॉल को कॉपी करें। अगला हिट करें।
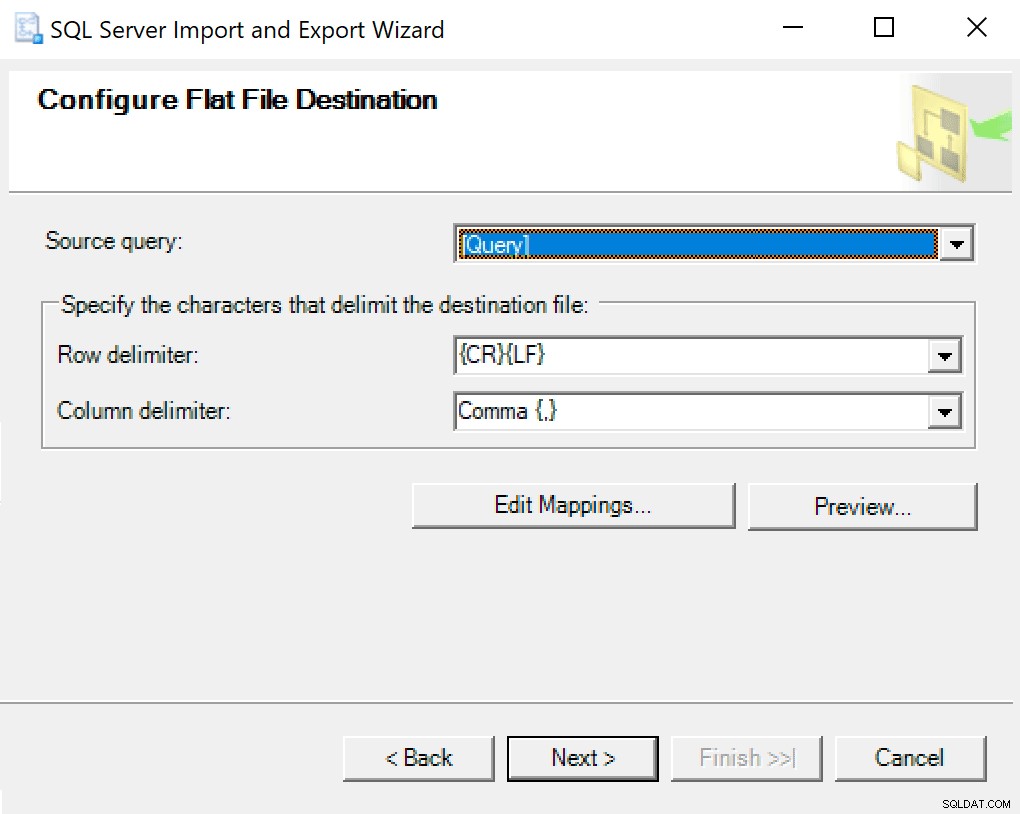
जब आप कॉन्फिगर फ्लैट फाइल डेस्टिनेशन पर पहुंचते हैं, तो मैं विकल्पों को डिफ़ॉल्ट के रूप में छोड़ देता हूं। आपके अलग होने की स्थिति में यहां एक स्क्रीनशॉट है:
अगला मारो और तुरंत भागो। एक फ़ाइल बनाई जाएगी जिसका उपयोग आप अंतिम चरण में करेंगे।
ध्यान दें :आप इसके लिए उपयोग करने के लिए एक एसएसआईएस पैकेज बना सकते हैं और फिर अपने पैरामीटर मानों को एसएसआईएस पैकेज में पास कर सकते हैं यदि आप इसे बहुत कुछ करने जा रहे हैं। यह आपको हर बार विज़ार्ड से गुजरने से रोकेगा।
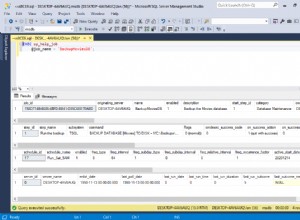
उस स्थान पर नेविगेट करें जहां आपने फ़ाइल सहेजी है और सत्यापित करें कि यह वहां है। जब आप इसे खोलते हैं, तो यह कुछ इस तरह दिखना चाहिए:
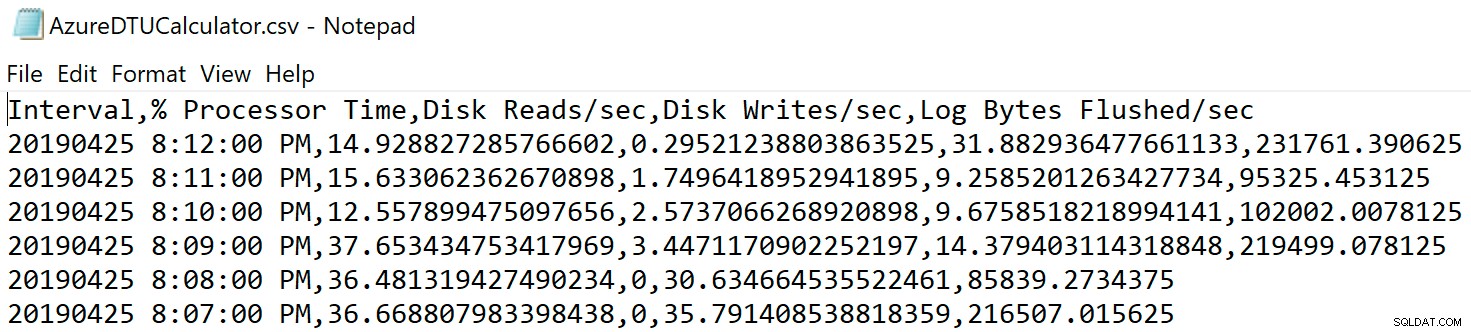
डीटीयू कैलकुलेटर वेब साइट खोलें, और उस हिस्से तक स्क्रॉल करें जो कहता है, "सीएसवी फ़ाइल अपलोड करें और गणना करें।" सर्वर के पास मौजूद कोर की संख्या दर्ज करें, CSV फ़ाइल अपलोड करें और गणना करें पर क्लिक करें। आपको इस तरह के परिणामों का एक सेट मिलेगा (ज़ूम करने के लिए किसी भी छवि पर क्लिक करें):
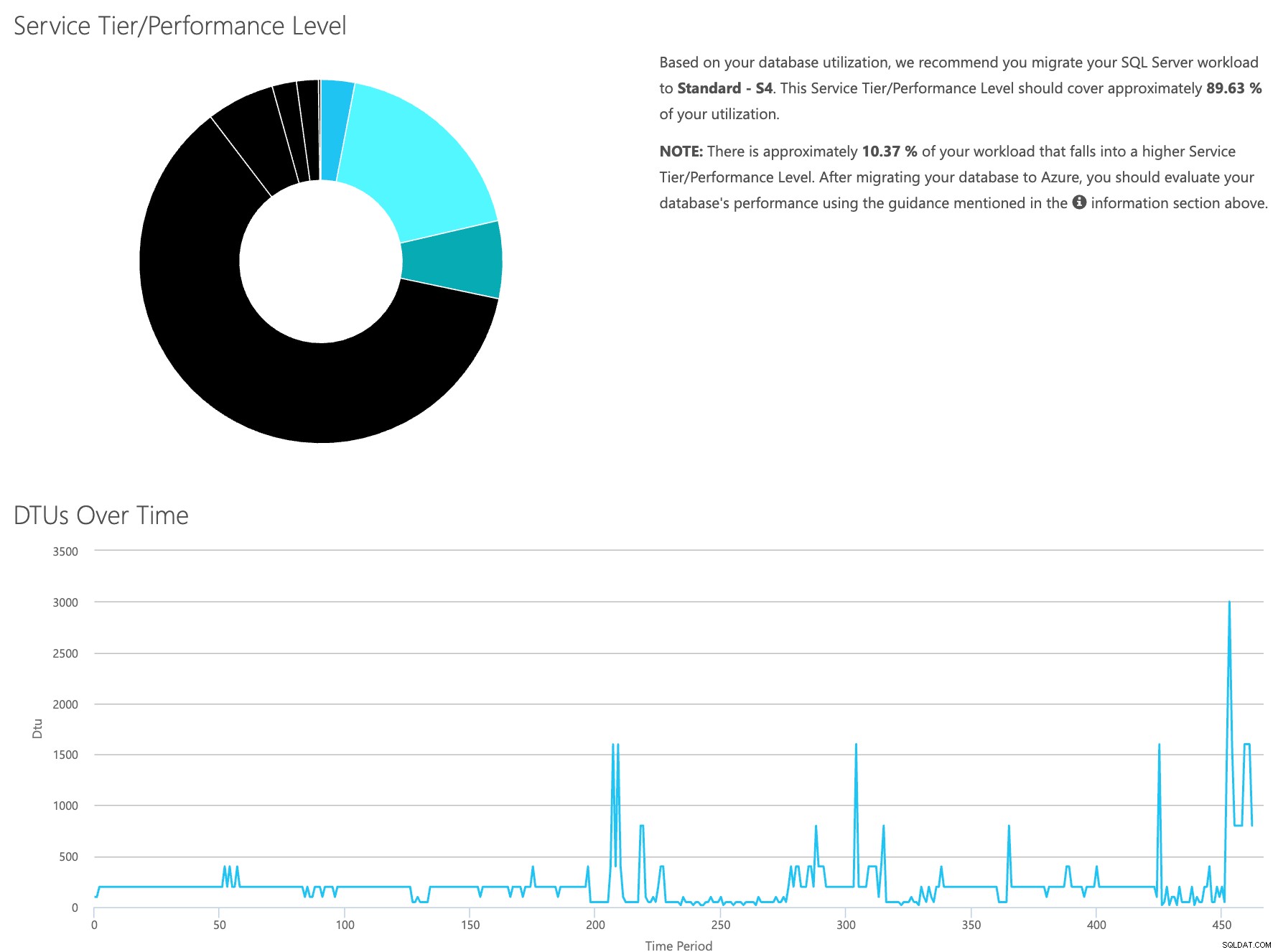
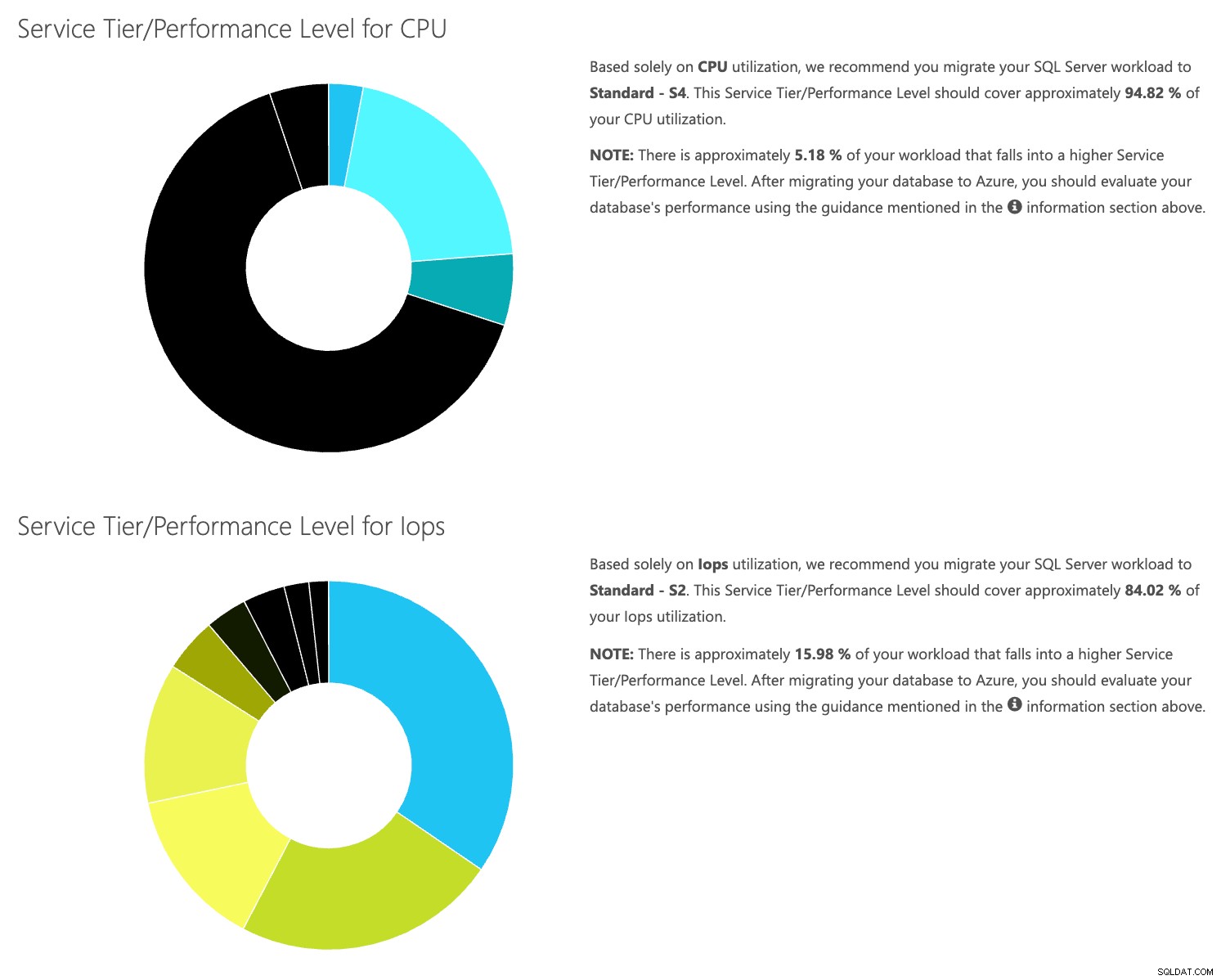
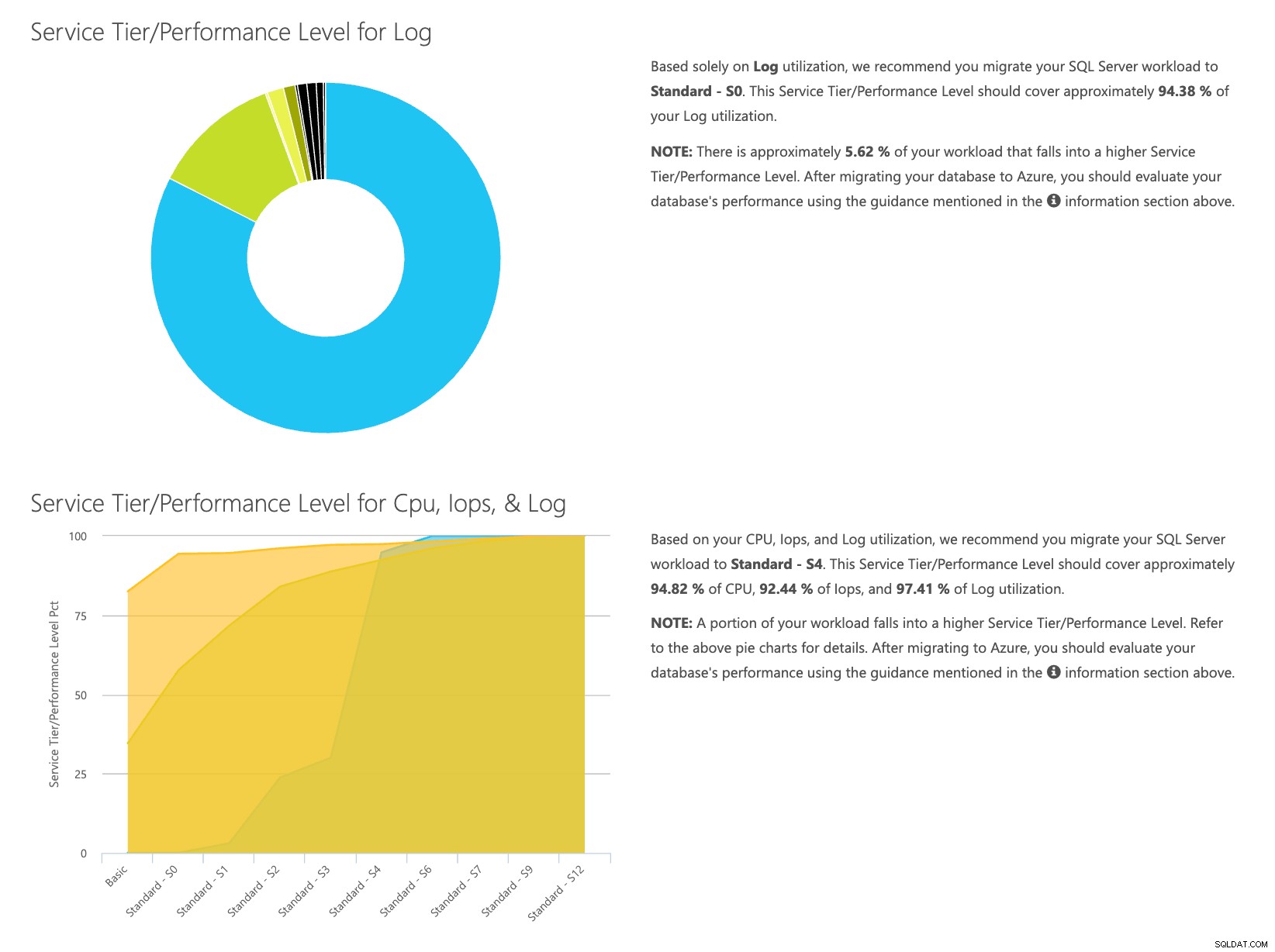
चूंकि आपके पास डेटा अलग से संग्रहीत किया जा रहा है, आप अलग-अलग समय से वर्कलोड का विश्लेषण कर सकते हैं, और आप इसे किसी भी सर्वर के लिए मैन्युअल रूप से चलाने के लिए \ शेड्यूल कमांड उपयोगिता \ powershell स्क्रिप्ट के बिना कर सकते हैं, जिसे आप पहले से ही SentryOne का उपयोग मॉनिटर करने के लिए कर रहे हैं।
चरणों को संक्षेप में बताने के लिए, यहां बताया गया है कि क्या करने की आवश्यकता है:
- [डेटाबेस - लॉग बाइट्स फ्लश/सेकंड] काउंटर सक्षम करें, और सत्यापित करें कि डेटा एकत्र किया जा रहा है
- SentryOne टेबल से डेटा को अपनी टेबल में कॉपी करें (और जहां उपयुक्त हो उसे शेड्यूल करें)।
- DTU कैलकुलेटर के लिए नई तालिका से डेटा को सही प्रारूप में निर्यात करें
- DTU कैलकुलेटर में CSV अपलोड करें
किसी भी सर्वर/उदाहरण के लिए आप क्लाउड में माइग्रेट करने पर विचार कर रहे हैं, और यह कि आप वर्तमान में SQL संतरी के साथ निगरानी कर रहे हैं, यह अनुमान लगाने का एक अपेक्षाकृत दर्द रहित तरीका है कि आपको किस प्रकार के सर्विस टियर की आवश्यकता होगी और इसकी लागत कितनी होगी। एक बार जब यह वहां हो तो आपको अभी भी इसकी निगरानी करने की आवश्यकता होगी; उसके लिए, SentryOne DB संतरी देखें।
लेखक के बारे में
 डस्टिन डोर्सी वर्तमान में LifePoint Health के लिए प्रबंध डेटाबेस इंजीनियर हैं, जिसमें वे प्रबंधन और इंजीनियरिंग समाधानों के लिए जिम्मेदार टीम का नेतृत्व करते हैं। 90 अस्पतालों के लिए डेटाबेस प्रौद्योगिकियों में। वह 2008 से एक प्रशासन, वास्तुकला, विकास और बीआई क्षमता में मुख्य रूप से स्वास्थ्य सेवा में SQL सर्वर के साथ काम कर रहा है और उसका समर्थन कर रहा है। वह रोज़मर्रा के डीबीए को प्रभावित करने वाली समस्याओं को हल करने के तरीके खोजने के बारे में भावुक है और इसे दूसरों के साथ साझा करना पसंद करता है। उन्हें SQL कम्युनिटी इवेंट्स में बोलते हुए, साथ ही DustinDorsey.com पर ब्लॉगिंग करते हुए पाया जा सकता है।
डस्टिन डोर्सी वर्तमान में LifePoint Health के लिए प्रबंध डेटाबेस इंजीनियर हैं, जिसमें वे प्रबंधन और इंजीनियरिंग समाधानों के लिए जिम्मेदार टीम का नेतृत्व करते हैं। 90 अस्पतालों के लिए डेटाबेस प्रौद्योगिकियों में। वह 2008 से एक प्रशासन, वास्तुकला, विकास और बीआई क्षमता में मुख्य रूप से स्वास्थ्य सेवा में SQL सर्वर के साथ काम कर रहा है और उसका समर्थन कर रहा है। वह रोज़मर्रा के डीबीए को प्रभावित करने वाली समस्याओं को हल करने के तरीके खोजने के बारे में भावुक है और इसे दूसरों के साथ साझा करना पसंद करता है। उन्हें SQL कम्युनिटी इवेंट्स में बोलते हुए, साथ ही DustinDorsey.com पर ब्लॉगिंग करते हुए पाया जा सकता है।