इन-मेमोरी ओएलटीपी (जिसे पहले "हेकाटन" के नाम से जाना जाता था) और यह कैसे बहुत विशिष्ट, उच्च मात्रा वाले वर्कलोड में मदद कर सकता है, के बारे में बहुत सारी चर्चाएं हुई हैं। एक अलग बातचीत के बीच, मैंने CREATE TYPE . में कुछ नोटिस किया SQL सर्वर 2014 के लिए प्रलेखन जिसने मुझे यह सोचने पर मजबूर कर दिया कि अधिक सामान्य उपयोग का मामला हो सकता है:

क्रिएट टाइप डॉक्युमेंटेशन में अपेक्षाकृत शांत और अनहेल्ड एडिशन
सिंटैक्स आरेख के आधार पर, ऐसा लगता है कि टेबल-वैल्यू पैरामीटर (टीवीपी) को मेमोरी-ऑप्टिमाइज़ किया जा सकता है, जैसे स्थायी टेबल कर सकते हैं। और इसके साथ ही पहिए तुरंत मुड़ने लगे।
एक चीज जिसके लिए मैंने टीवीपी का उपयोग किया है, वह है ग्राहकों को टी-एसक्यूएल या सीएलआर में महंगी स्ट्रिंग-विभाजन विधियों को खत्म करने में मदद करना (पिछली पोस्ट में पृष्ठभूमि यहां, यहां और यहां देखें)। मेरे परीक्षणों में, एक नियमित टीवीपी का उपयोग करके सीएलआर या टी-एसक्यूएल विभाजन कार्यों का उपयोग करके एक महत्वपूर्ण मार्जिन (25-50%) द्वारा समकक्ष पैटर्न से बेहतर प्रदर्शन किया गया। मैंने तार्किक रूप से सोचा:क्या स्मृति-अनुकूलित टीवीपी से कोई प्रदर्शन लाभ होगा?
सामान्य रूप से इन-मेमोरी ओएलटीपी के बारे में कुछ आशंकाएं हैं, क्योंकि कई सीमाएं और फीचर अंतराल हैं, आपको मेमोरी-अनुकूलित डेटा के लिए एक अलग फ़ाइल समूह की आवश्यकता है, आपको संपूर्ण टेबल को मेमोरी-अनुकूलित करने की आवश्यकता है, और सबसे अच्छा लाभ आम तौर पर है मूल रूप से संकलित संग्रहीत कार्यविधियाँ (जिनकी अपनी सीमाएँ हैं) बनाकर भी हासिल की जाती हैं। जैसा कि मैं प्रदर्शित करूंगा, मान लें कि आपके टेबल प्रकार में सरल डेटा संरचनाएं हैं (उदाहरण के लिए पूर्णांक या स्ट्रिंग के सेट का प्रतिनिधित्व करते हुए), इस तकनीक का उपयोग केवल टीवीपी के लिए कुछ को समाप्त करता है इन मुद्दों में से।
परीक्षा
यदि आप स्थायी, स्मृति-अनुकूलित तालिकाएँ नहीं बनाने जा रहे हैं, तब भी आपको स्मृति-अनुकूलित फ़ाइल समूह की आवश्यकता होगी। तो चलिए उपयुक्त संरचना के साथ एक नया डेटाबेस बनाते हैं:
CREATE DATABASE xtp; GO ALTER DATABASE xtp ADD FILEGROUP xtp CONTAINS MEMORY_OPTIMIZED_DATA; GO ALTER DATABASE xtp ADD FILE (name='xtpmod', filename='c:\...\xtp.mod') TO FILEGROUP xtp; GO ALTER DATABASE xtp SET MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT = ON; GOसेट करें
अब, हम एक नियमित तालिका प्रकार बना सकते हैं, जैसा कि हम आज करेंगे, और एक गैर-संकुल हैश इंडेक्स के साथ एक मेमोरी-अनुकूलित तालिका प्रकार और एक बकेट काउंट जिसे मैंने हवा से निकाला है (मेमोरी आवश्यकताओं और बकेट काउंट की गणना के बारे में अधिक जानकारी में असली दुनिया यहाँ):
USE xtp; GO CREATE TYPE dbo.ClassicTVP AS TABLE ( Item INT PRIMARY KEY ); CREATE TYPE dbo.InMemoryTVP AS TABLE ( Item INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 256) ) WITH (MEMORY_OPTIMIZED = ON);
यदि आप इसे किसी ऐसे डेटाबेस में आज़माते हैं जिसमें स्मृति-अनुकूलित फ़ाइल समूह नहीं है, तो आपको यह त्रुटि संदेश प्राप्त होगा, ठीक वैसे ही जैसे आप एक सामान्य स्मृति-अनुकूलित तालिका बनाने का प्रयास करते हैं:
संदेश 41337, स्तर 16, राज्य 0, पंक्ति 9MEMORY_OPTIMIZED_DATA फ़ाइल समूह मौजूद नहीं है या खाली है। किसी डेटाबेस के लिए स्मृति अनुकूलित तालिकाएँ तब तक नहीं बनाई जा सकतीं जब तक कि उसमें एक MEMORY_OPTIMIZED_DATA फ़ाइल समूह न हो जो खाली न हो।
एक नियमित, गैर-स्मृति-अनुकूलित तालिका के विरुद्ध एक क्वेरी का परीक्षण करने के लिए, मैंने SELECT INTO का उपयोग करके, AdventureWorks2012 नमूना डेटाबेस से कुछ डेटा को एक नई तालिका में खींच लिया। उन सभी अजीब बाधाओं, अनुक्रमित और विस्तारित गुणों को अनदेखा करने के लिए, फिर कॉलम पर एक क्लस्टर इंडेक्स बनाया जो मुझे पता था कि मैं (ProductID) पर खोज करूँगा ):
SELECT * INTO dbo.Products FROM AdventureWorks2012.Production.Product; -- 504 rows CREATE UNIQUE CLUSTERED INDEX p ON dbo.Products(ProductID);
आगे मैंने चार संग्रहीत कार्यविधियाँ बनाईं:प्रत्येक तालिका प्रकार के लिए दो; प्रत्येक EXISTS . का उपयोग कर रहा है और JOIN दृष्टिकोण (मैं आमतौर पर दोनों की जांच करना पसंद करता हूं, भले ही मैं EXISTS . पसंद करता हूं; बाद में आप देखेंगे कि मैं अपने परीक्षण को केवल EXISTS . तक सीमित क्यों नहीं रखना चाहता था ) इस मामले में मैं केवल एक चर के लिए एक मनमानी पंक्ति निर्दिष्ट करता हूं, ताकि मैं परिणाम और अन्य आउटपुट और ओवरहेड से निपटने के बिना उच्च निष्पादन गणनाओं का निरीक्षण कर सकूं:
-- Old-school TVP using EXISTS:
CREATE PROCEDURE dbo.ClassicTVP_Exists
@Classic dbo.ClassicTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @name NVARCHAR(50);
SELECT @name = p.Name
FROM dbo.Products AS p
WHERE EXISTS
(
SELECT 1 FROM @Classic AS t
WHERE t.Item = p.ProductID
);
END
GO
-- In-Memory TVP using EXISTS:
CREATE PROCEDURE dbo.InMemoryTVP_Exists
@InMemory dbo.InMemoryTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @name NVARCHAR(50);
SELECT @name = p.Name
FROM dbo.Products AS p
WHERE EXISTS
(
SELECT 1 FROM @InMemory AS t
WHERE t.Item = p.ProductID
);
END
GO
-- Old-school TVP using a JOIN:
CREATE PROCEDURE dbo.ClassicTVP_Join
@Classic dbo.ClassicTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @name NVARCHAR(50);
SELECT @name = p.Name
FROM dbo.Products AS p
INNER JOIN @Classic AS t
ON t.Item = p.ProductID;
END
GO
-- In-Memory TVP using a JOIN:
CREATE PROCEDURE dbo.InMemoryTVP_Join
@InMemory dbo.InMemoryTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @name NVARCHAR(50);
SELECT @name = p.Name
FROM dbo.Products AS p
INNER JOIN @InMemory AS t
ON t.Item = p.ProductID;
END
GO पर @InMemory के रूप में शामिल हों
इसके बाद, मुझे उस प्रकार की क्वेरी का अनुकरण करने की आवश्यकता थी जो आम तौर पर इस प्रकार की तालिका के विरुद्ध आती है और पहले स्थान पर एक टीवीपी या समान पैटर्न की आवश्यकता होती है। उत्पादों की सूची वाले ड्रॉप-डाउन या चेकबॉक्स के सेट के साथ एक फॉर्म की कल्पना करें, और उपयोगकर्ता 20 या 50 या 200 का चयन कर सकता है, जिसकी वे तुलना करना चाहते हैं, सूची, आपके पास क्या है। मान एक अच्छे सन्निहित सेट में नहीं होने जा रहे हैं; वे आम तौर पर सभी जगह बिखरे हुए होंगे (यदि यह अनुमानित रूप से सन्निहित सीमा थी, तो क्वेरी बहुत आसान होगी:प्रारंभ और समाप्ति मान)। इसलिए मैंने तालिका से एक मनमाना 20 मान चुना (नीचे रहने की कोशिश कर रहा है, कहते हैं, तालिका आकार का 5%), यादृच्छिक रूप से आदेश दिया। पुन:प्रयोज्य VALUES build बनाने का एक आसान तरीका इस तरह का खंड इस प्रकार है:
DECLARE @x VARCHAR(4000) = '';
SELECT TOP (20) @x += '(' + RTRIM(ProductID) + '),'
FROM dbo.Products ORDER BY NEWID();
SELECT @x; परिणाम (आपके लगभग निश्चित रूप से भिन्न होंगे):
(725),(524),(357),(405),(477),(821),(323),(526),(952),(473),(442),(450),(735) ),(441),(409),(454),(780),(966),(988),(512),
सीधे INSERT...SELECT . के विपरीत , इससे हमारे टीवीपी को समान मूल्यों और परीक्षण के कई पुनरावृत्तियों के साथ बार-बार पॉप्युलेट करने के लिए उस आउटपुट को पुन:प्रयोज्य कथन में हेरफेर करना काफी आसान हो जाता है:
SET NOCOUNT ON; DECLARE @ClassicTVP dbo.ClassicTVP; DECLARE @InMemoryTVP dbo.InMemoryTVP; INSERT @ClassicTVP(Item) VALUES (725),(524),(357),(405),(477),(821),(323),(526),(952),(473), (442),(450),(735),(441),(409),(454),(780),(966),(988),(512); INSERT @InMemoryTVP(Item) VALUES (725),(524),(357),(405),(477),(821),(323),(526),(952),(473), (442),(450),(735),(441),(409),(454),(780),(966),(988),(512); EXEC dbo.ClassicTVP_Exists @Classic = @ClassicTVP; EXEC dbo.InMemoryTVP_Exists @InMemory = @InMemoryTVP; EXEC dbo.ClassicTVP_Join @Classic = @ClassicTVP; EXEC dbo.InMemoryTVP_Join @InMemory = @InMemoryTVP;
यदि हम SQL संतरी प्लान एक्सप्लोरर का उपयोग करके इस बैच को चलाते हैं, तो परिणामी योजनाएं एक बड़ा अंतर दिखाती हैं:इन-मेमोरी TVP एक नेस्टेड लूप जॉइन का उपयोग करने में सक्षम है और 20 सिंगल-पंक्ति क्लस्टर इंडेक्स चाहता है, बनाम एक मर्ज फेड 502 पंक्तियों से जुड़ता है क्लासिक टीवीपी के लिए क्लस्टर्ड इंडेक्स स्कैन। और इस मामले में, EXISTS और JOIN ने समान योजनाएँ प्राप्त कीं। यह बहुत अधिक संख्या में मूल्यों के साथ टिप दे सकता है, लेकिन आइए इस धारणा के साथ जारी रखें कि मानों की संख्या तालिका आकार के 5% से कम होगी:
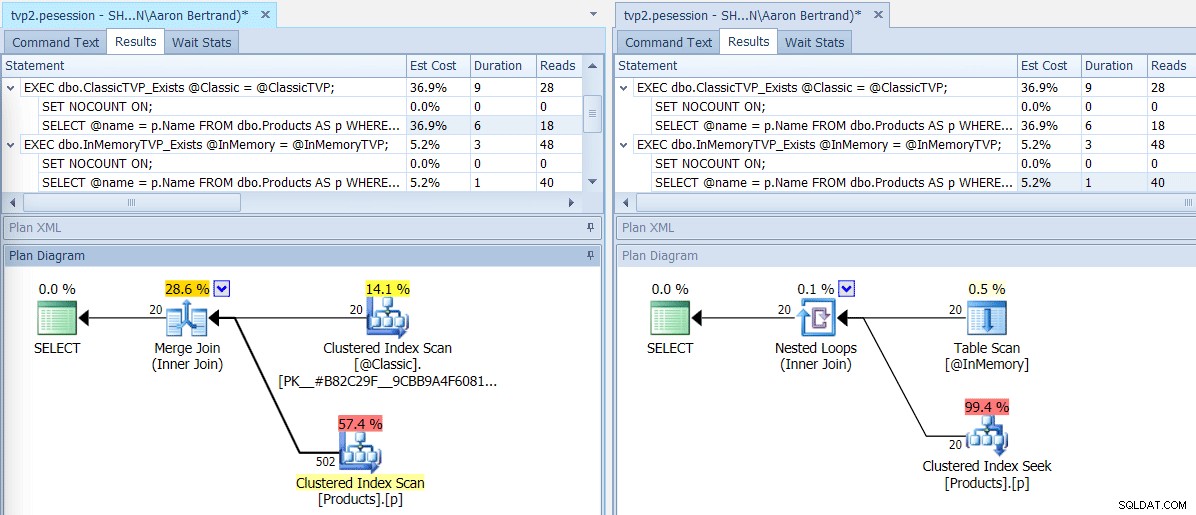 क्लासिक और इन-मेमोरी टीवीपी के लिए योजनाएं
क्लासिक और इन-मेमोरी टीवीपी के लिए योजनाएं
 स्कैन/सीक ऑपरेटरों के लिए टूलटिप्स, प्रमुख अंतरों को हाइलाइट करना - बाईं ओर क्लासिक, इन- मेमोरी दाईं ओर
स्कैन/सीक ऑपरेटरों के लिए टूलटिप्स, प्रमुख अंतरों को हाइलाइट करना - बाईं ओर क्लासिक, इन- मेमोरी दाईं ओर
अब इसका क्या मतलब है पैमाने पर? आइए किसी भी शोप्लान संग्रह को बंद करें, और प्रत्येक प्रक्रिया को 100,000 बार चलाने के लिए परीक्षण स्क्रिप्ट को थोड़ा बदलें, संचयी रनटाइम को मैन्युअल रूप से कैप्चर करें:
DECLARE @i TINYINT = 1, @j INT = 1;
WHILE @i <= 4
BEGIN
SELECT SYSDATETIME();
WHILE @j <= 100000
BEGIN
IF @i = 1
BEGIN
EXEC dbo.ClassicTVP_Exists @Classic = @ClassicTVP;
END
IF @i = 2
BEGIN
EXEC dbo.InMemoryTVP_Exists @InMemory = @InMemoryTVP;
END
IF @i = 3
BEGIN
EXEC dbo.ClassicTVP_Join @Classic = @ClassicTVP;
END
IF @i = 4
BEGIN
EXEC dbo.InMemoryTVP_Join @InMemory = @InMemoryTVP;
END
SET @j += 1;
END
SELECT @i += 1, @j = 1;
END
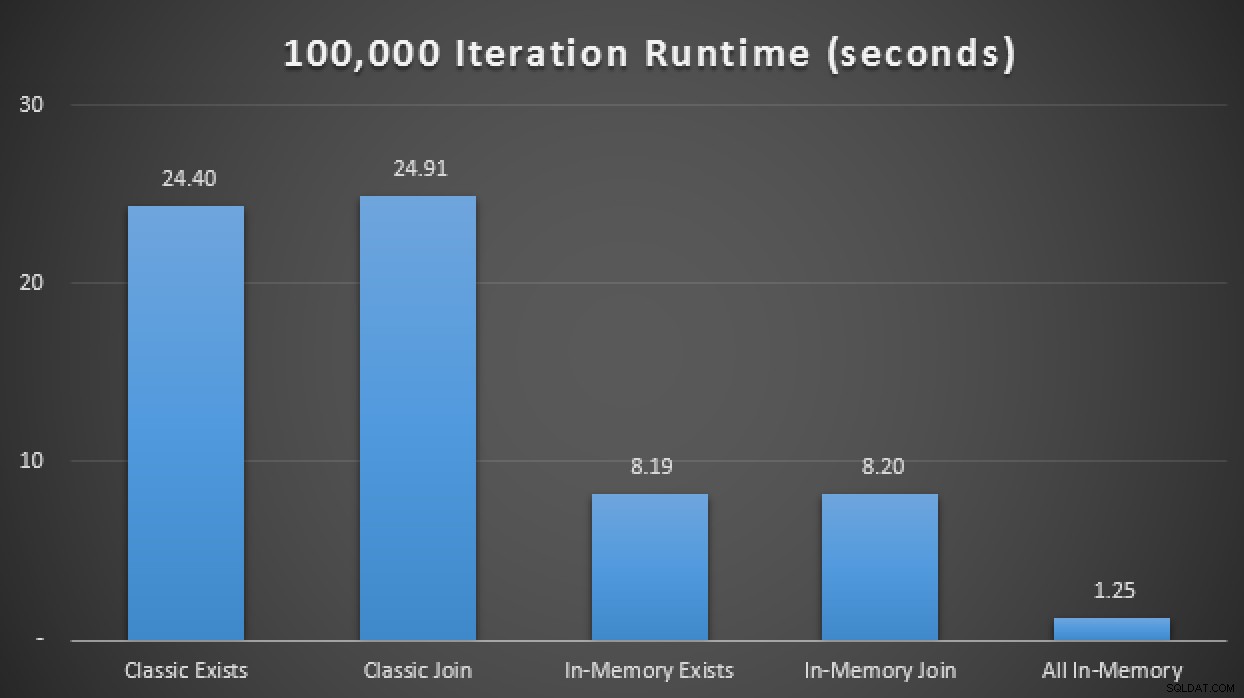
SELECT SYSDATETIME(); परिणामों में, औसतन 10 रन से अधिक, हम देखते हैं कि, इस सीमित परीक्षण मामले में, कम से कम, स्मृति-अनुकूलित तालिका प्रकार का उपयोग करने से OLTP (रनटाइम अवधि) में सबसे महत्वपूर्ण प्रदर्शन मीट्रिक पर लगभग 3 गुना सुधार प्राप्त हुआ:
इन-मेमोरी टीवीपी के साथ 3X सुधार दिखाने वाले रनटाइम परिणाम उन्हें>
इन-मेमोरी + इन-मेमोरी + इन-मेमोरी:इन-मेमोरी इंसेप्शन
अब जब हमने देखा है कि हम अपने नियमित तालिका प्रकार को स्मृति-अनुकूलित तालिका प्रकार में बदलकर क्या कर सकते हैं, आइए देखें कि जब हम ट्राइफेक्टा लागू करते हैं तो हम इसी क्वेरी पैटर्न से किसी और प्रदर्शन को निचोड़ सकते हैं:एक इन-मेमोरी तालिका, मूल रूप से संकलित स्मृति-अनुकूलित संग्रहीत कार्यविधि का उपयोग करते हुए, जो एक इन-मेमोरी तालिका तालिका को तालिका-मूल्यवान पैरामीटर के रूप में स्वीकार करती है।
सबसे पहले, हमें टेबल की एक नई कॉपी बनाने की जरूरत है, और इसे हमारे द्वारा पहले से बनाई गई स्थानीय टेबल से पॉप्युलेट करना होगा:
CREATE TABLE dbo.Products_InMemory ( ProductID INT NOT NULL, Name NVARCHAR(50) NOT NULL, ProductNumber NVARCHAR(25) NOT NULL, MakeFlag BIT NOT NULL, FinishedGoodsFlag BIT NULL, Color NVARCHAR(15) NULL, SafetyStockLevel SMALLINT NOT NULL, ReorderPoint SMALLINT NOT NULL, StandardCost MONEY NOT NULL, ListPrice MONEY NOT NULL, [Size] NVARCHAR(5) NULL, SizeUnitMeasureCode NCHAR(3) NULL, WeightUnitMeasureCode NCHAR(3) NULL, [Weight] DECIMAL(8, 2) NULL, DaysToManufacture INT NOT NULL, ProductLine NCHAR(2) NULL, [Class] NCHAR(2) NULL, Style NCHAR(2) NULL, ProductSubcategoryID INT NULL, ProductModelID INT NULL, SellStartDate DATETIME NOT NULL, SellEndDate DATETIME NULL, DiscontinuedDate DATETIME NULL, rowguid UNIQUEIDENTIFIER NULL, ModifiedDate DATETIME NULL, PRIMARY KEY NONCLUSTERED HASH (ProductID) WITH (BUCKET_COUNT = 256) ) WITH ( MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA ); INSERT dbo.Products_InMemory SELECT * FROM dbo.Products;
इसके बाद, हम एक स्थानीय रूप से संकलित संग्रहीत कार्यविधि बनाते हैं जो हमारे मौजूदा मेमोरी-अनुकूलित तालिका प्रकार को TVP के रूप में लेती है:
CREATE PROCEDURE dbo.InMemoryProcedure
@InMemory dbo.InMemoryTVP READONLY
WITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS OWNER
AS
BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english');
DECLARE @Name NVARCHAR(50);
SELECT @Name = Name
FROM dbo.Products_InMemory AS p
INNER JOIN @InMemory AS t
ON t.Item = p.ProductID;
END
GO चेतावनियों की एक जोड़ी। हम मूल रूप से संकलित संग्रहीत कार्यविधि के पैरामीटर के रूप में एक नियमित, गैर-स्मृति-अनुकूलित तालिका प्रकार का उपयोग नहीं कर सकते हैं। अगर हम कोशिश करते हैं, तो हमें मिलता है:
Msg 41323, स्तर 16, राज्य 1, प्रक्रिया InMemoryProcedureतालिका प्रकार 'dbo.ClassicTVP' एक स्मृति अनुकूलित तालिका प्रकार नहीं है और इसे मूल रूप से संकलित संग्रहीत कार्यविधि में उपयोग नहीं किया जा सकता है।
साथ ही, हम EXISTS . का उपयोग नहीं कर सकते यहाँ या तो पैटर्न; जब हम कोशिश करते हैं, हमें मिलता है:
उपश्रेणियाँ (किसी अन्य क्वेरी के अंदर नेस्टेड क्वेरी) स्थानीय रूप से संकलित संग्रहीत कार्यविधियों के साथ समर्थित नहीं हैं।
इन-मेमोरी ओएलटीपी और मूल रूप से संकलित संग्रहीत प्रक्रियाओं के साथ कई अन्य चेतावनी और सीमाएं हैं, मैं बस कुछ चीजें साझा करना चाहता हूं जो स्पष्ट रूप से परीक्षण से गायब हो सकती हैं।
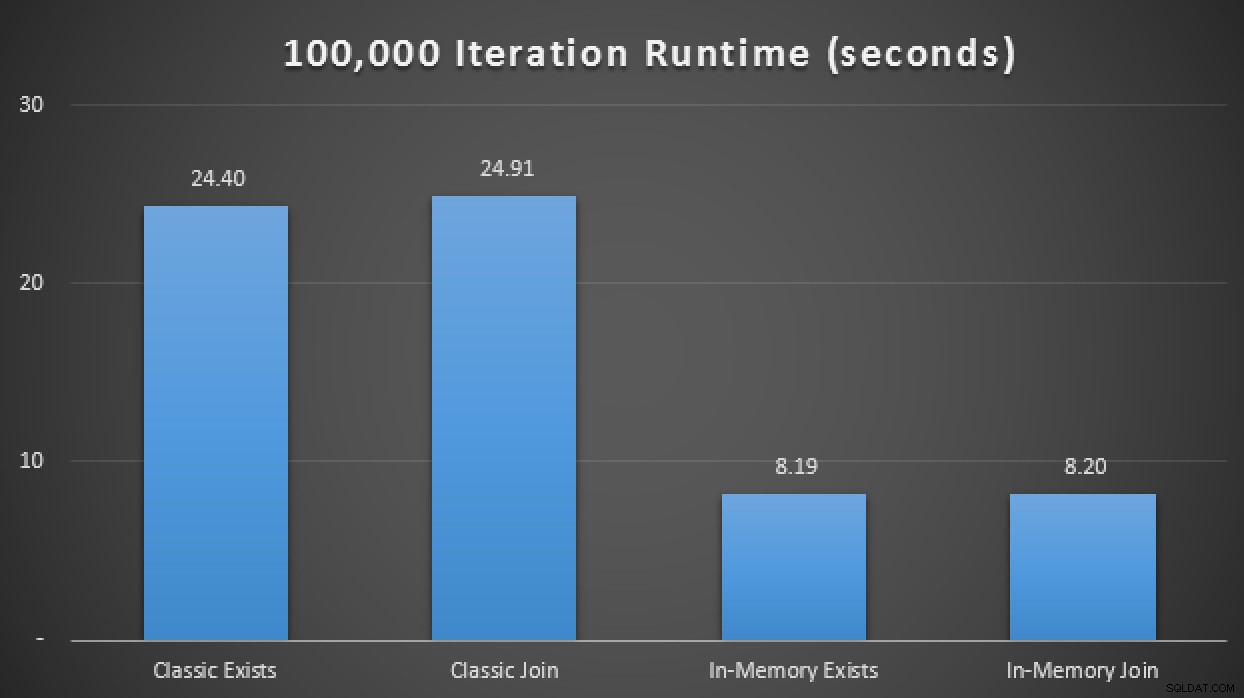
इसलिए उपरोक्त परीक्षण मैट्रिक्स में इस नई मूल रूप से संकलित संग्रहीत प्रक्रिया को जोड़ते हुए, मैंने पाया कि - फिर से, औसतन 10 रन से अधिक - इसने केवल 1.25 सेकंड में 100,000 पुनरावृत्तियों को निष्पादित किया। यह नियमित टीवीपी की तुलना में लगभग 20X सुधार और पारंपरिक तालिकाओं और प्रक्रियाओं का उपयोग करते हुए इन-मेमोरी टीवीपी पर 6-7X सुधार दर्शाता है:
इन-मेमोरी के साथ 20X तक सुधार दिखाने वाले रनटाइम परिणाम
निष्कर्ष
यदि आप अभी टीवीपी का उपयोग कर रहे हैं, या आप ऐसे पैटर्न का उपयोग कर रहे हैं जिन्हें टीवीपी द्वारा प्रतिस्थापित किया जा सकता है, तो आपको निश्चित रूप से अपनी परीक्षण योजनाओं में मेमोरी-अनुकूलित टीवीपी जोड़ने पर विचार करना चाहिए, लेकिन यह ध्यान में रखते हुए कि आप अपने परिदृश्य में समान सुधार नहीं देख सकते हैं। (और, ज़ाहिर है, यह ध्यान में रखते हुए कि टीवीपी में सामान्य रूप से बहुत सी चेतावनी और सीमाएं हैं, और वे सभी परिदृश्यों के लिए उपयुक्त नहीं हैं। एरलैंड सोमरस्कोग के पास आज के टीवीपी के बारे में एक अच्छा लेख है।)
वास्तव में आप देख सकते हैं कि वॉल्यूम और समवर्ती के निचले सिरे पर, कोई अंतर नहीं है - लेकिन कृपया यथार्थवादी पैमाने पर परीक्षण करें। यह एक एकल एसएसडी वाले आधुनिक लैपटॉप पर एक बहुत ही सरल और आकस्मिक परीक्षण था, लेकिन जब आप वास्तविक मात्रा और/या स्पिनी मैकेनिकल डिस्क के बारे में बात कर रहे हैं, तो इन प्रदर्शन विशेषताओं में बहुत अधिक वजन हो सकता है। बड़े डेटा आकारों पर कुछ प्रदर्शनों के साथ अनुवर्ती कार्रवाई हो रही है।