बच्चों की पार्टियों का आयोजन करना कोई आसान काम नहीं है:सब कुछ पूरी तरह से योजनाबद्ध और वितरित किया जाना है। नहीं तो अराजकता हो जाती है। यह वयस्कों पर निर्भर करता है - अधिक विशेष रूप से, पार्टी योजनाकार - सब कुछ का ख्याल रखना और इसे ठीक से करना।
डेटाबेस में सबकुछ व्यवस्थित करने से ऐसा करने का कोई बेहतर तरीका है? हमें ऐसा नहीं लगता!
बच्चों की पार्टियां बहुत भिन्न होती हैं। कुछ सरल हैं, जैसे जन्मदिन की पार्टियां जिनमें सिर्फ निमंत्रण, भोजन (नाश्ता, पेय पदार्थ और एक केक) और शायद बच्चों का मनोरंजन करने के लिए एक जोकर या जादूगर शामिल हैं। अन्य पार्टियां बहुत अधिक जटिल हैं। उन्हें शहर से बाहर यात्रा, सोने की जगह और कई अन्य गतिविधियों की आवश्यकता हो सकती है। पार्टी जितनी जटिल होगी, गलतियों की गुंजाइश उतनी ही कम होगी। जबकि एक मसखरा जो 10 मिनट देर से आता है, कोई बड़ी बात नहीं है, कोई भी ऊब बच्चों के समूह के साथ दो घंटे की देरी से बस का इंतजार नहीं करना चाहता!
आइए देखें कि पार्टी योजनाकारों को संगठित रहने में सहायता के लिए डेटा मॉडल क्या कर सकता है।
हमें अपने डेटा मॉडल में क्या चाहिए?
आइए मान लें कि हम पार्टी नियोजन व्यवसाय चलाते हैं। हमारे पास उन सेवाओं की एक सूची होगी जो हम ग्राहकों को प्रदान करते हैं। ये सेवाएं हमारे द्वारा प्रदान की जा सकती हैं, या हम भागीदारों का उपयोग कर सकते हैं (उदाहरण के लिए हम जोकर को किराए पर लेते हैं)।
हम इन सेवाओं को मिलाते हैं और ग्राहकों को पार्टी पैकेज के रूप में पेश करते हैं। प्रत्येक पैकेज में एक प्रारंभिक और समाप्ति बिंदु, या शेड्यूल होता है। इसमें सिर्फ पार्टी ही नहीं, बल्कि पार्टी बनाना और बाद में सफाई करना शामिल है। हमारे पास कई स्थान भी हो सकते हैं (उदाहरण के लिए एक रेस्तरां में पिज्जा के साथ एक पार्टी शुरू होती है, फिर तैराकी के लिए समुद्र तट पर जाती है)।
हमें कर्मचारियों के साथ गतिविधियों को जोड़ने, पार्टियों की प्रगति को ट्रैक करने और हमारी सेवाओं के लिए शुल्क लेने की भी आवश्यकता होगी। आइए देखें कि यह कैसे किया जाता है।
बच्चों की पार्टी डेटा मॉडल
हमारे बच्चों के पार्टी डेटा मॉडल में चार विषय क्षेत्र शामिल हैं:
Countries & citiesPartners & servicesEmployees & rolesParty
हम प्रत्येक विषय क्षेत्र को उसी क्रम में प्रस्तुत करेंगे जिस क्रम में वह सूचीबद्ध है।
अनुभाग 1:देश और शहर
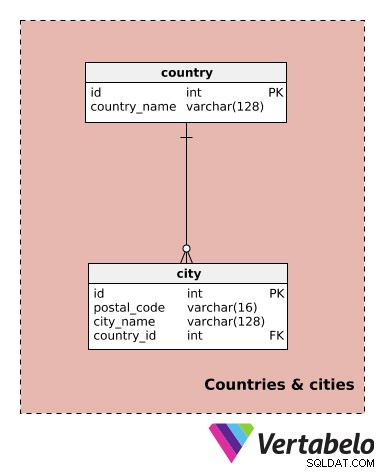
इस विषय क्षेत्र में केवल दो टेबल हैं। वे इस मॉडल के लिए विशिष्ट नहीं हैं, लेकिन हम उनका उपयोग अन्य विषय क्षेत्रों में करेंगे।
हम कई शहरों में और शायद कई देशों में भी काम करने की उम्मीद कर सकते हैं। इसलिए, हमें विभिन्न शहरों को संदर्भित करने की आवश्यकता होगी। यह हमें ट्रैक करने में मदद करेगा कि पार्टियां कहां स्थित हैं और यह भी कि हम प्रत्येक स्थान पर कौन सी सेवाएं प्रदान करते हैं।
country शब्दकोश में केवल UNIQUE country_name शामिल है मूल्य। प्रत्येक city , हम postal_code . के UNIQUE संयोजन को संग्रहित करेंगे - city_name - country_id ।
अनुभाग 2:भागीदार और सेवाएं
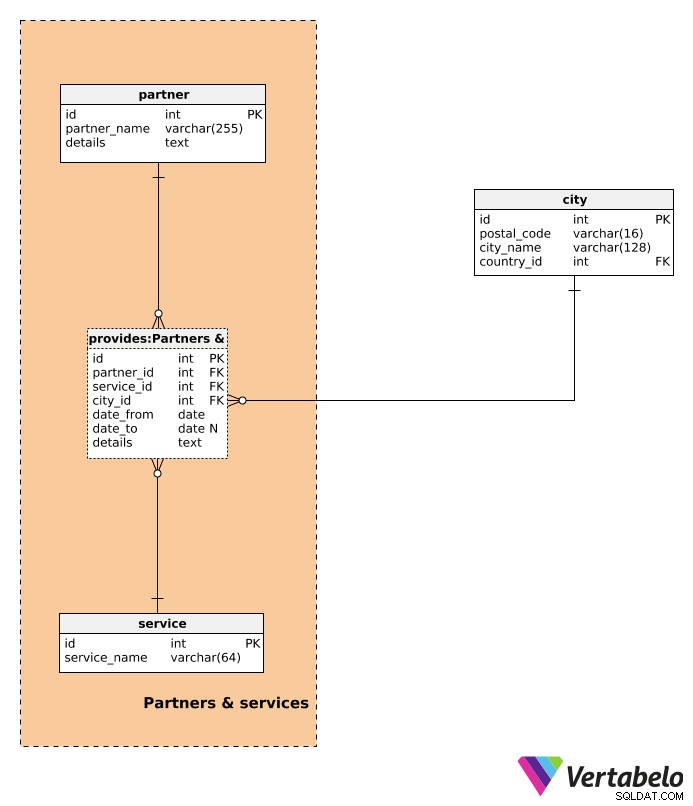
इसके बाद, हम अपने ग्राहकों के लिए प्रदान की जाने वाली सेवाओं के बारे में विस्तार से बताते हैं।
सभी संभावित सेवाओं की सूची service शब्दकोश। इसमें केवल UNIQUE service_name है विशेषता।
इस डेटा मॉडल में, सभी सेवाएं भागीदारों द्वारा प्रदान की जाती हैं। यहां तक कि जब हमारी कंपनी वास्तव में सेवा प्रदान करती है, तब भी हम इसे एक partner सेवा (और हम भागीदार हैं)। पार्टनर डिक्शनरी उन सभी पार्टनर्स को स्टोर करेगी, जिनके साथ हम काम करते हैं, जिनमें हम भी शामिल हैं। प्रत्येक पार्टनर के लिए, हम एक UNIQUE partner_name . स्टोर करेंगे . details विशेषता एक असंरचित या संरचित प्रारूप का उपयोग करके उस भागीदार से संबंधित किसी भी अतिरिक्त विवरण को संग्रहीत करती है (उदाहरण के लिए पूर्वनिर्धारित विभाजक द्वारा अलग किए गए नाम-मूल्य जोड़े का उपयोग करना)।
provides तालिका इस खंड की अंतिम और सबसे महत्वपूर्ण तालिका है। प्रत्येक रिकॉर्ड के लिए, हम स्टोर करेंगे:
partner_id-partnerजो एक सेवा प्रदान करता है।service_id-serviceयह भागीदार प्रदान करता है।city_id- संदर्भcityजहां यह सेवा उस भागीदार द्वारा प्रदान की जाती है।date_from- वह तारीख जब पार्टनर ने उस सेवा की पेशकश शुरू की।date_to- वह तारीख जब पार्टनर ने वह सेवा देना बंद कर दिया। यह मान NULL हो सकता है यदि वह सेवा-साझेदार संबंध अभी भी जारी है।details- उस सेवा से संबंधित सभी अतिरिक्त विवरण, जैसे सेवा विवरण, मूल्य, आदि। हम उम्मीद कर सकते हैं कि सभी विवरण की-वैल्यू जोड़े का उपयोग करते हुए एक संरचित पाठ प्रारूप में होंगे।
partner_id . का संयोजन - service_id - city_id - date_from इस तालिका में UNIQUE कुंजी बनाता है। जब हम एक नया रिकॉर्ड दर्ज करते हैं, तो हमें यह जांचना चाहिए कि यह किसी भी मौजूदा रिकॉर्ड के साथ ओवरलैप नहीं होता है।
अनुभाग 3:कर्मचारी और भूमिकाएं
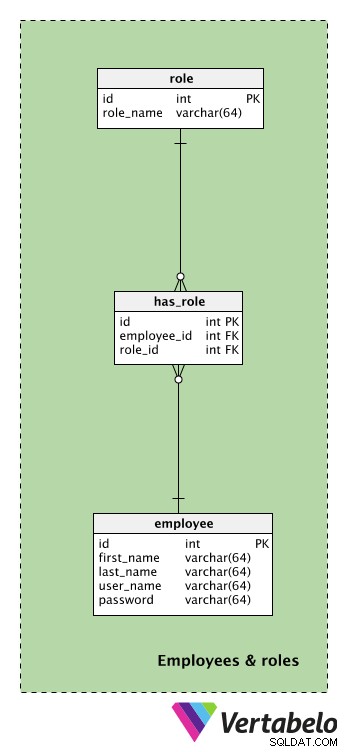
इससे पहले कि हम अपने मॉडल के केंद्रीय और सबसे महत्वपूर्ण हिस्से पर जाएं, हमें अपने कर्मचारियों और उनकी भूमिकाओं से संबंधित तालिकाओं को देखना होगा।
इस विषय क्षेत्र में केंद्रीय तालिका employee टेबल। प्रत्येक कर्मचारी के लिए, हम उनका first_name स्टोर करेंगे , last_name , user_name और password . वे हमारे एप्लिकेशन तक पहुंचने के लिए इन अंतिम दो विशेषताओं का उपयोग करेंगे।
सभी संभावित भूमिकाओं की सूची role शब्दकोश। प्रत्येक भूमिका को उसके role_name . द्वारा विशिष्ट रूप से परिभाषित किया जाता है . भूमिकाएँ उन कार्यों से संबंधित होती हैं जो प्रत्येक कर्मचारी पार्टी के दौरान करता है। इसलिए, हम यहां "पार्टी प्रबंधक" या "सहायक" जैसे मूल्यों की अपेक्षा कर सकते हैं।
has_role टेबल। employee_id - role_id जोड़ी उस समय प्रत्येक कर्मचारी की सक्रिय भूमिकाओं को दर्शाएगी।
अनुभाग 4:पार्टी
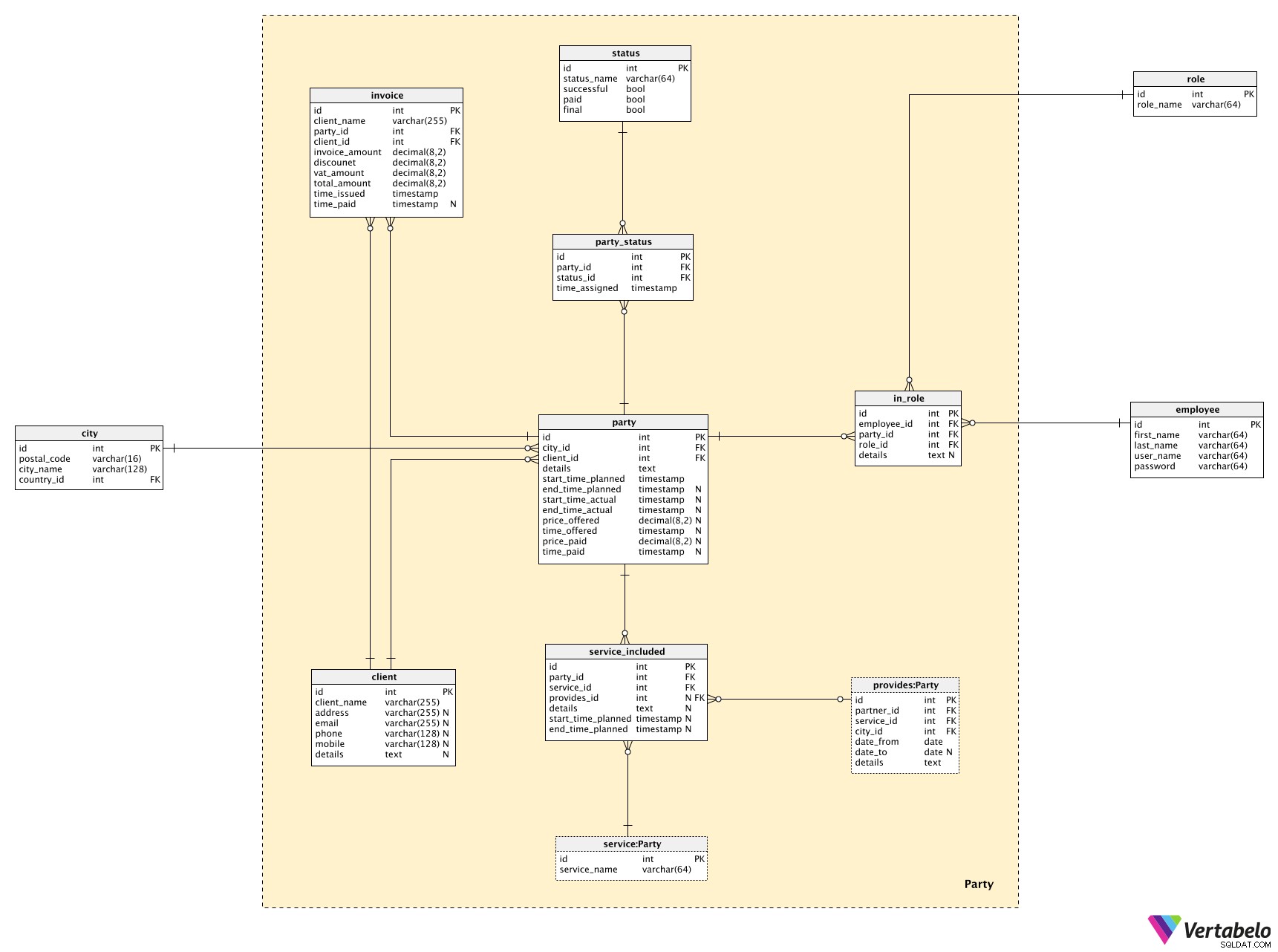
Party विषय क्षेत्र इस मॉडल का मध्य भाग है। हम इसका उपयोग अन्य विषय क्षेत्रों से तालिकाओं को जोड़ने के लिए करेंगे, और हमारे पास यहां कुछ नई जानकारी भी होगी।
यहां केंद्रीय तालिका है Party टेबल। प्रत्येक पार्टी के लिए, हम स्टोर करेंगे:
city_id-cityजहां पार्टी होगी।client_id-clientइस पार्टी के लिए आयोजित किया जाता है।details- पार्टी का विस्तृत पाठ विवरण।start_time_plannedऔरend_time_planned- हमने इस पार्टी के लिए सेटअप और सफाई सहित समय निर्धारित किया है।start_time_actualऔरend_time_actual- पार्टी (और इससे संबंधित सेवाओं) का वास्तविक समय।price_offered- इस क्लाइंट के लिए इस पार्टी को आयोजित करने के लिए हमने जो कीमत उद्धृत की है।time_offered- जब प्रस्ताव दिया गया था।price_paid- इस पार्टी के लिए क्लाइंट द्वारा भुगतान की गई वास्तविक राशि।time_paid- जब भुगतान किया गया था।
प्रत्येक पक्ष एक ग्राहक से संबंधित होता है। हम पहले ही client तालिका, लेकिन अब हम देखेंगे कि वहां क्या संग्रहीत है। मैं केवल बुनियादी डेटा के साथ गया था:client_name , संपर्क विवरण (address , email , phone , mobile ), और पाठ्य प्रारूप में कोई अतिरिक्त विवरण।
प्रत्येक पार्टी के पास इससे जुड़ी सेवाओं की एक सूची भी होगी। वह सूची service_included टेबल। प्रत्येक रिकॉर्ड के लिए, हमें आवश्यकता होगी:
party_id- संदर्भ संबंधितParty।service_id- संदर्भserviceपार्टी में शामिल।provides_id- संदर्भproviderउस सेवा का, साथ ही सेवा का भी। यह विशेषता NULL हो सकती है, क्योंकि जब हम विशिष्ट प्रदाता का चयन करेंगे तो हम इसे अपडेट करेंगे।details- उस पार्टी में उस सेवा से संबंधित कोई भी अतिरिक्त पाठ्य विवरण।start_time_plannedऔरend_time_planned- पार्टी के दौरान सेवा प्रदान करने के लिए नियोजित समय।
हमें प्रत्येक पार्टी की प्रगति को भी ट्रैक करना होगा। हम ऐसा करने के लिए दो तालिकाओं का उपयोग करेंगे।
status तालिका उन सभी संभावित स्थितियों को सूचीबद्ध करेगी जो किसी पार्टी को सौंपी जा सकती हैं। प्रत्येक रिकॉर्ड के लिए, हम एक UNIQUE status_name . स्टोर करेंगे और तीन झंडे:
successful- क्या सब ठीक हो गया? या हमारी सेवाओं में कोई समस्या थी?paid- क्या पार्टी को भुगतान किया गया है?final- क्या यह इस पार्टी की अंतिम स्थिति है?
हम party_status टेबल। प्रत्येक रिकॉर्ड के लिए, हम party और service टेबल और timestamp जब यह स्थिति असाइन की गई थी।
हमारे मॉडल में अंतिम तालिका invoice टेबल। यह इस मॉडल के लिए विशिष्ट नहीं है, लेकिन हमें इनवॉइस को स्टोर करने के लिए एक बुनियादी संरचना की आवश्यकता है। प्रत्येक चालान के लिए, हम रिकॉर्ड करेंगे:
client_name- चालान जारी करने के समय ग्राहक का नाम।party_id-Partyइस चालान से संबंधित।client_id-clientचालान किया जा रहा है।invoice_amount,discount,vat_amount,total_amount- चालान का वित्तीय विवरण।time_issued- जब यह चालान जारी किया गया था या डेटाबेस में जोड़ा गया था।time_paid- जब इस चालान का भुगतान किया गया था।
आप इस डेटा मॉडल के साथ क्या करेंगे?
यह मॉडल बहुत सीधा है, लेकिन मुझे लगता है कि हम इसे बेहतर बनाने के कई तरीके देख सकते हैं। आप क्या बदलाव प्रस्तावित करेंगे? क्या ऐसा कुछ है जिसे हम अलग तरीके से व्यवस्थित कर सकते हैं? हो सकता है कि हमें किसी सुविधा को जोड़ने या हटाने की आवश्यकता हो। कृपया हमें टिप्पणियों में बताएं।