जबकि जैफ एटवुड और जो सेल्को को लगता है कि GUID की लागत कोई बड़ी बात नहीं है (जेफ की ब्लॉग पोस्ट, "प्राथमिक कुंजी:आईडी बनाम GUIDs" देखें, और "पहचान बनाम विशिष्ट पहचानकर्ता" शीर्षक वाला यह समाचार समूह धागा), अन्य विशेषज्ञ - अधिक विशेष रूप से इंडेक्स और आर्किटेक्चर विशेषज्ञ जो SQL सर्वर स्पेस पर ध्यान केंद्रित करते हैं - असहमत होते हैं। उदाहरण के लिए, किम्बर्ली ट्रिप ने अपनी पोस्ट में कुछ विवरण दिए हैं, "डिस्क स्पेस सस्ता है - वह बिंदु नहीं है!", जहां वह बताती है कि प्रभाव केवल डिस्क स्थान और विखंडन पर नहीं है, बल्कि अधिक महत्वपूर्ण रूप से सूचकांक आकार और स्मृति पर है। पदचिन्ह।
किम्बर्ली जो कहता है वह वास्तव में सच है - मुझे हर समय GUID के लिए "डिस्क स्थान सस्ता है" औचित्य (उदाहरण के लिए पिछले सप्ताह से) आता है। GUID के लिए अन्य औचित्य हैं, जिसमें डेटाबेस के बाहर अद्वितीय पहचानकर्ता उत्पन्न करने की आवश्यकता शामिल है (और कभी-कभी पंक्ति वास्तव में बनने से पहले), और अलग-अलग वितरित प्रणालियों में अद्वितीय पहचानकर्ताओं की आवश्यकता (और जहां पहचान सीमाएं व्यावहारिक नहीं हैं)। लेकिन मैं वास्तव में इस मिथक को दूर करना चाहता हूं कि GUID की इतनी अधिक लागत नहीं है, क्योंकि वे करते हैं, और आपको अपने निर्णय में इन लागतों को तौलना होगा।
मैंने इस मिशन पर अलग-अलग प्रमुख आकारों के प्रदर्शन का परीक्षण करने के लिए निर्धारित किया है, समान डेटा को समान पंक्तियों में, समान अनुक्रमणिका के साथ, और मोटे तौर पर समान कार्यभार (*सटीक* समान कार्यभार को फिर से खेलना काफी चुनौतीपूर्ण हो सकता है) दिया गया है। मैं न केवल इंडेक्स साइज और इंडेक्स फ्रैगमेंटेशन जैसी बुनियादी चीजों को मापना चाहता था, बल्कि इनका प्रभाव भी रेखा से नीचे है, जैसे:
- बफर पूल के उपयोग पर प्रभाव
- "खराब" पृष्ठ विभाजन की आवृत्ति
- वास्तविक कार्यभार अवधि पर समग्र प्रभाव
- व्यक्तिगत प्रश्नों के औसत रनटाइम पर प्रभाव
- आफ्टर ट्रिगर्स की रनटाइम अवधि पर प्रभाव
- tempdb उपयोग पर प्रभाव
मैं इस डेटा की जांच करने के लिए विभिन्न तकनीकों का उपयोग करूंगा, जिसमें विस्तारित ईवेंट, डिफ़ॉल्ट ट्रेस, tempdb से संबंधित DMV और SQL संतरी प्रदर्शन सलाहकार शामिल हैं।
सेटअप
सबसे पहले, मैंने कुछ अंतर्निहित SQL सर्वर मेटाडेटा का उपयोग करके एक सीड टेबल में डालने के लिए एक लाख ग्राहक बनाए; यह सुनिश्चित करेगा कि "यादृच्छिक" ग्राहकों में प्रत्येक परीक्षण के दौरान समान प्राकृतिक डेटा शामिल होगा।
क्रिएट टेबल dbo.CustomerSeeds(rn INT PRIMARY KEY CCLUSTERED, FirstName NVARCHAR(64), LastName NVARCHAR(64), EMail NVARCHAR(320) NOT NULL UNIQUE, Active BIT); INSERT dbo.CustomerSeeds के साथ (TABLOCKX) (RN, FirstName, LastName, EMail, [Active]) RN =ROW_NUMBER() ओवर (ऑर्डर बाय n), fn, ln, em, aFROM चुनें ( SELECT TOP (1000000) fn, ln , em, a =MAX(a), n =MAX(NEWID ()) से (चुनें fn, ln, em, a, r =ROW_NUMBER() ओवर (उन्हें ऑर्डर के अनुसार विभाजन) से (सेलेक्ट टॉप (2000000) fn =LEFT(o.name, 64), ln =LEFT(c.name, 64), em =LEFT(o.name, LEN(c.name)%5+1) + '.' + LEFT(c. नाम, LEN(o.name)%5+2) + '@' + RIGHT(c.name, LEN(o.name+c.name)%12 + 1) + LEFT(RTRIM(CHECKSUM(NEWID()) ),3) + '.com', a =मामला जब c.name '%y%' पसंद करता है तो 0 ELSE 1 sys.all_objects से समाप्त होता है जैसे कि क्रॉस जॉइन sys.all_columns AS c ORDER BY NEWID() ) AS x ) जहां r =1 ग्रुप बाय fn, ln, em ORDER BY n) AS z ऑर्डर बाय rn;GO SELECT TOP (10) * From dbo.CustomerSeed BY RN;GO
आपका माइलेज भिन्न हो सकता है, लेकिन मेरे सिस्टम पर, इस जनसंख्या ने 86 सेकंड का समय लिया। दस प्रतिनिधि पंक्तियाँ (विस्तार करने के लिए क्लिक करें):
 नमूना ग्राहक
नमूना ग्राहक
इसके बाद, मुझे प्रत्येक उपयोग के मामले के लिए बीज डेटा रखने के लिए तालिकाओं की आवश्यकता थी, कुछ अतिरिक्त अनुक्रमणिका के साथ किसी प्रकार की वास्तविकता का अनुकरण करने के लिए, और मैं बाद में सभी प्रकार के निदान को आसान बनाने के लिए लघु प्रत्ययों के साथ आया:
| डेटा प्रकार | डिफ़ॉल्ट | <थ>संपीड़नकेस सफ़िक्स का उपयोग करें | |
|---|---|---|---|
| INT | पहचान | कोई नहीं | मैं |
| INT | पहचान | पेज + पंक्ति | आईसी |
| बिगिनट | पहचान | कोई नहीं | B |
| बिगिनट | पहचान | पेज + पंक्ति | बीसी |
| UNIQUEIDENTIFIER | NEWID() | कोई नहीं | G |
| UNIQUEIDENTIFIER | NEWID() | पेज + पंक्ति | जीसी |
| UNIQUEIDENTIFIER | NEWSEQUENTIALID() | कोई नहीं | S |
| UNIQUEIDENTIFIER | NEWSEQUENTIALID() | पेज + पंक्ति | Sc |
तालिका 1:मामलों, डेटा प्रकारों और प्रत्ययों का उपयोग करें
सभी आठ तालिकाओं को बताया गया, सभी एक ही टेम्पलेट से उत्पन्न हुई (मैं उपयोग के मामले से मेल खाने के लिए टिप्पणियों को बदल दूंगा, और $use_case$ को बदल दूंगा। उपरोक्त तालिका से उपयुक्त प्रत्यय के साथ):
टेबल डीबीओ बनाएं। ग्राहक_ $ उपयोग_केस $ - आई, आईसी, बी, बीसी, जी, जीसी, एस, एससी (ग्राहक आईडी पूर्ण पहचान नहीं है (1,1), - ग्राहक आईडी पूर्ण पहचान नहीं है (1, 1), --CustomerID UNIQUEIDENTIFIER नॉट न्यूल डिफॉल्ट NEWID(), --CustomerID UNIQUEIDENTIFIER NOT NULL DEFAULT NEWSEQUENTIALID(), FirstName NVARCHAR(64) NOT NULL, LastName NVARCHAR(64) NOT NULL, ईमेल NVARCHAR (320) नॉट न्यूल, एक्टिव BIT NOT NULL DEFAULT 1, बनाया गया DATETIME NOT NULL DEFAULT SYSDATETIME(), अपडेट किया गया DATETIME NULL, CONSTRAINT C_PK_Customers_$use_case$ PRIMARY KEY (CustomerID)) --with (DATA_COMPRESSION =PAGE)GO;CREATE UNIQUE INDEX C_usemail_Customers_$ ON . Customers_$use_case$(EMail) --with (DATA_COMPRESSION =PAGE);GOCREATE INDEX C_Active_Customers_$use_case$ ON dbo.Customers_$use_case$(FirstName, LastName, EMail) WHERE Active =1 --with (DATA_COMPRESSION =PAGE);GOCREATE INDEX C_Name_Customers_$use_case$ ऑन dbo.Customers_$use_case$(LastName, FirstName) INCLUDE (EMail) --with (DATA_COMPRESSION =PAGE);GOएक बार टेबल बन जाने के बाद, मैंने टेबल को पॉप्युलेट करने और ऊपर बताए गए कई मेट्रिक्स को मापने के लिए आगे बढ़े। मैंने यह सुनिश्चित करने के लिए प्रत्येक परीक्षण के बीच में SQL सर्वर सेवा को फिर से शुरू किया कि वे सभी एक ही आधार रेखा से शुरू हो रहे हैं, कि DMV को रीसेट किया जाएगा, आदि।
निर्विरोध निवेशन
मेरा अंतिम लक्ष्य तालिका को 1,000,000 पंक्तियों से भरना था, लेकिन पहले मैं बिना किसी विवाद के कच्चे आवेषण पर डेटा प्रकार और संपीड़न के प्रभाव को देखना चाहता था। मैंने निम्नलिखित क्वेरी उत्पन्न की - जो एक समय में पहले 200,000 संपर्कों, 2000 पंक्तियों के साथ तालिका को पॉप्युलेट करेगा - और इसे प्रत्येक तालिका के विरुद्ध चलाया:
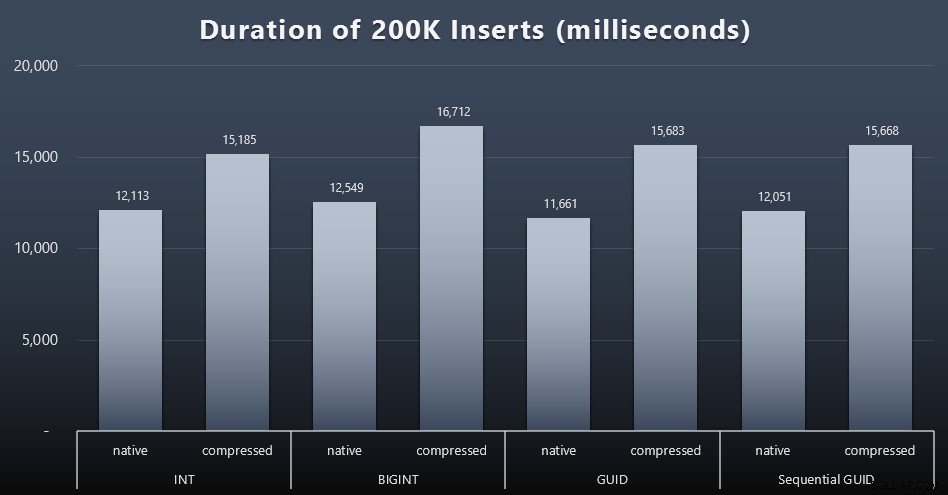
DECLARE @i INT =1;जबकि @i <=100BEGIN INSERT dbo.Customers_$use_case$(FirstName, LastName, ईमेल, एक्टिव) dbo से सक्रिय प्रथम नाम, अंतिम नाम, ईमेल चुनें। 2000 * (@i-1) पंक्तियाँ केवल अगली 2000 पंक्तियाँ प्राप्त करें; SET @i +=1;ENDपरिणाम (विस्तार करने के लिए क्लिक करें):
प्रत्येक मामले में लगभग 12 सेकंड (संपीड़न के बिना) और 16 सेकंड (संपीड़न के साथ) लगे, जिसमें भंडारण मोड में कोई स्पष्ट विजेता नहीं था। संपीड़न का प्रभाव (मुख्य रूप से सीपीयू ओवरहेड पर) काफी सुसंगत है, लेकिन चूंकि यह तेज एसएसडी पर चल रहा है, इसलिए विभिन्न डेटा प्रकारों का I/O प्रभाव नगण्य है। वास्तव में बिगिनट के खिलाफ संपीड़न का सबसे बड़ा प्रभाव प्रतीत होता है (और यह समझ में आता है, क्योंकि 2 अरब से कम का हर एक मूल्य संकुचित होगा)।
अधिक विवादास्पद कार्यभार
आगे मैं देखना चाहता था कि मिश्रित कार्यभार संसाधनों के लिए कैसे प्रतिस्पर्धा करेगा और आम तौर पर प्रत्येक डेटा प्रकार के खिलाफ प्रदर्शन करेगा। इसलिए मैंने इन प्रक्रियाओं को बनाया (
$use_case$. की जगह) और$data_type$प्रत्येक परीक्षण के लिए उपयुक्त):-- एक से अधिक इंडेक्स में डेटा के लिए रैंडम सिंगलटन अपडेटप्रक्रिया बनाएं [डीबीओ]। अद्यतन dbo.Customers_$use_case$ SET LastName =COALESCE(STUFF(LastName, 4, 1, 'x'),'x') जहां CustomerID =@Customers_$use_case$;ENDGO -- पढ़ता है ("पेजिनेशन") - एकाधिक का समर्थन करता है सॉर्ट-- क्वेरी स्टैटिस्टिक्स को अलग से ट्रैक करने के लिए डायनेमिक SQL का उपयोग करें [dbo] बनाएं। [Customers_$use_case$_Page] @PageNumber INT =1, @PageSize INT =100, @sort SYSNAMEASBEGIN SET NOCOUNT ON; DECLARE @sql NVARCHAR(MAX) =N'SELECT CustomerID, FirstName, LastName, ईमेल, एक्टिव, क्रिएटेड, dbo से अपडेट किया गया। ps) पंक्तियाँ फ़ेच अगला @ps केवल पंक्तियाँ;'; EXEC sys.sp_executesql @sql, N'@pn INT, @ps INT', @PageNumber, @PageSize;ENDGOफिर मैंने नौकरियों का निर्माण किया जो उन प्रक्रियाओं को बार-बार कॉल करेगा, थोड़ी देरी के साथ, और साथ ही - शेष 800,000 संपर्कों को पॉप्युलेट करना समाप्त कर देगा। यह स्क्रिप्ट सभी 32 नौकरियों का निर्माण करती है, और आउटपुट को प्रिंट भी करती है जिसका उपयोग बाद में सभी नौकरियों को एक विशिष्ट परीक्षण के लिए एसिंक्रोनस रूप से कॉल करने के लिए किया जा सकता है:
msdb का उपयोग करें; GO DECLARE @typ TABLE(use_case VARCHAR(2), data_type SYSNAME); INSERT @typ(use_case, data_type) VALUES('I', N'INT'), ('Ic',N'INT '), ('बी', एन'बिगिनट'), ('बीसी', एन'बिगिनट'), ('जी', एन'अद्वितीय पहचानकर्ता'), ('जीसी', एन'अद्वितीय पहचानकर्ता'), ('एस ', N'UNIQUEIDENTIFIER'), ('Sc', N'UNIQUEIDENTIFIER'); DECLARE @jobs TABLE(name SYSNAME, cmd NVARCHAR(MAX)); INSERT @jobs(name, cmd) VALUES(N'Random update workload', N'DECLARE @CustomerID $data_type$, @i INT =1; जबकि @i <=500 BEGIN टॉप चुनें (1) @CustomerID =CustomerID फ्रॉम dbo.Customers_$use_case$ ऑर्डर BY NEWID(); EXEC dbo.Customers_$use_case$_RandomUpdate @Customers_$use_case$ =@CustomerID; WAITFOR DELAY ''00:00 :01''; SET @i +=1; END'),( N'Populate Customers', N'SET QUOTED_IDENTIFIER ON; DECLARE @i INT =101; जबकि @i <=500 BEGIN INSERT dbo.Customers_$use_case$ (प्रथम नाम, अंतिम नाम, ईमेल, सक्रिय) प्रथम नाम, अंतिम नाम, ईमेल, डीबीओ से सक्रिय चुनें। आरएन ऑफ़सेट 2000 द्वारा ग्राहक बीज के रूप में सी ऑर्डर करें * (@i-1) पंक्तियाँ केवल अगली 2000 पंक्तियाँ प्राप्त करें; विलंब के लिए प्रतीक्षा करें ''00:00:01''; SET @i +=1; END'),( N'Paging workload 1', N'DECLARE @i INT =1, @sql NVARCHAR(MAX); जबकि @i <=1001 BEGIN -- द्वारा क्रमबद्ध करें CustomerID SET @sql =N ''EXEC dbo.Customers_$use_case$_Page @PageNumber =@i, @sort =N''''CustomerID''''';''; EXEC sys.sp_executesql @sql, N''@i INT'', @i; प्रतीक्षा विलंब ''00:00:01''; सेट @i +=2; END'),( N'Paging workload 2', N'DECLARE @i INT =1, @sql NVARCHAR(MAX); जबकि @i <=1001 BEGIN -- LastName द्वारा क्रमबद्ध करें, FirstName SET @sql =N''EXEC dbo.Customers_$use_case$_Page @PageNumber =@i, @sort =N''''LastName, FirstName''''';''; EXEC sys.sp_executesql @sql, N''@i INT'', @i; प्रतीक्षा विलंब ''00:00:01''; SET @i +=2; END'); DECLARE @n SYSNAME, @c NVARCHAR (MAX); DECLARE c CURSOR LOCAL FAST_FORWARD FORSELECT name =t.use_case + N' ' + j.name, cmd =REPLACE(REPLACE(j.cmd, N'$use_case$', t.use_case), N'$data_type$', t .data_type) @typ AS t CROSS JOIN @jobs AS j से; खुला सी; FETCH c INTO @n, @c; जबकि @@FETCH_STATUS <> -1BEGIN यदि मौजूद है (msdb.dbo.sysjobs से चुनें जहां नाम =@n) EXEC msdb.dbo.sp_delete_job @job_name =@n; END EXEC msdb.dbo.sp_add_job @job_name =@n, @enabled =0, @notify_level_eventlog =0, @category_id =0, @owner_login_name =N'sa'; EXEC msdb.dbo.sp_add_jobstep @job_name =@n, @step_name =@n, @command =@c, @database_name =N'IDs'; EXEC msdb.dbo.sp_add_jobserver @job_name =@n, @server_name =N'(local)'; प्रिंट 'EXEC msdb.dbo.sp_start_job @job_name =N''' + @n + ''';'; FETCH c INTO @n, @c;ENDप्रत्येक मामले में कार्य के समय को मापना तुच्छ था - मैं
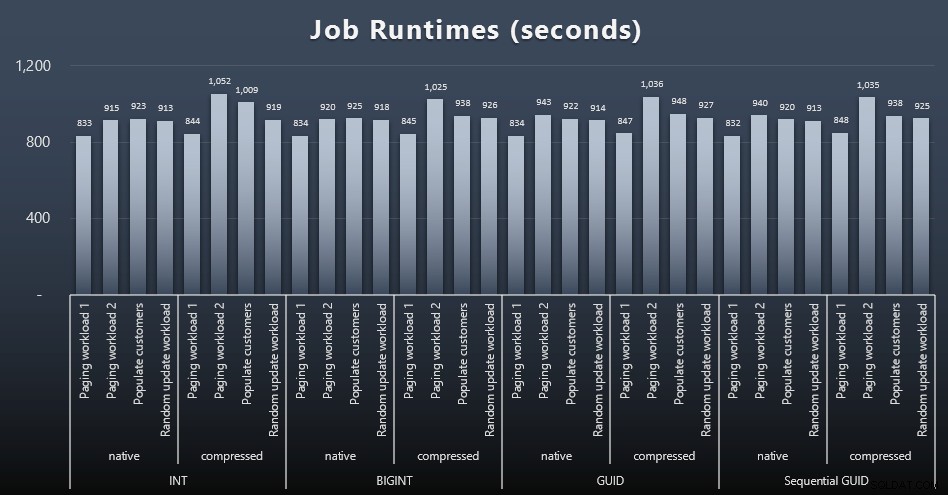
msdb.dbo.sysjobhistoryमें प्रारंभ/समाप्ति तिथियों की जांच कर सकता था या उन्हें SQL संतरी इवेंट मैनेजर से खींचें। यहां परिणाम हैं (विस्तार करने के लिए क्लिक करें):
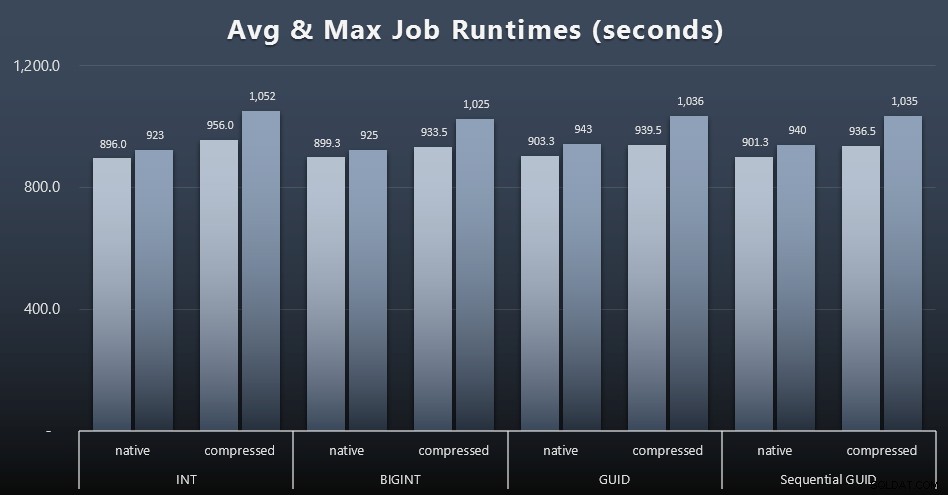
और अगर आप पचाना थोड़ा कम चाहते हैं, तो बस चार नौकरियों में औसत और अधिकतम रनटाइम देखें (विस्तार करने के लिए क्लिक करें):
लेकिन इस दूसरे ग्राफ में भी वास्तव में किसी भी दृष्टिकोण के पक्ष या विपक्ष में एक सम्मोहक मामला बनाने के लिए पर्याप्त भिन्नता नहीं है।
क्वेरी रनटाइम
मैंने
sys.dm_exec_query_stats. से कुछ मेट्रिक्स लिए हैं औरsys.dm_exec_trigger_statsयह निर्धारित करने के लिए कि अलग-अलग प्रश्नों में औसतन कितना समय लग रहा था।
जनसंख्या
पहले 200, 000 ग्राहकों को बहुत जल्दी लोड किया गया - 20 सेकंड से कम - कोई प्रतिस्पर्धी कार्यभार नहीं होने के कारण। एक बार चार नौकरियां एक साथ चल रही थीं, हालांकि, समवर्ती होने के कारण लेखन अवधि पर महत्वपूर्ण प्रभाव पड़ा। शेष 800,000 पंक्तियों को पूरा करने के लिए कम से कम परिमाण के एक क्रम की आवश्यकता होती है, औसतन। यहां प्रत्येक 2,000 ग्राहक प्रविष्टि के औसत के परिणाम दिए गए हैं (विस्तार करने के लिए क्लिक करें):
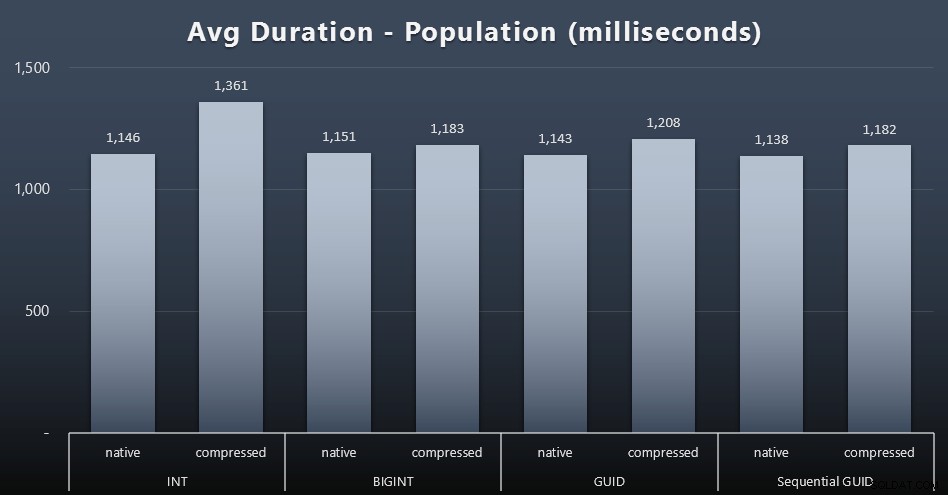
हम यहां देखते हैं कि एक आईएनटी को संपीड़ित करना ही एकमात्र वास्तविक बाहरी था - मेरे पास उस पर कुछ सिद्धांत हैं, लेकिन अभी तक कुछ भी निर्णायक नहीं है।
पेजिंग वर्कलोड
पेजिंग प्रश्नों के औसत रनटाइम भी मेरे परीक्षण की तुलना में समवर्ती से काफी प्रभावित हुए हैं जो अलगाव में चलते हैं। यहां परिणाम हैं (विस्तार करने के लिए क्लिक करें):
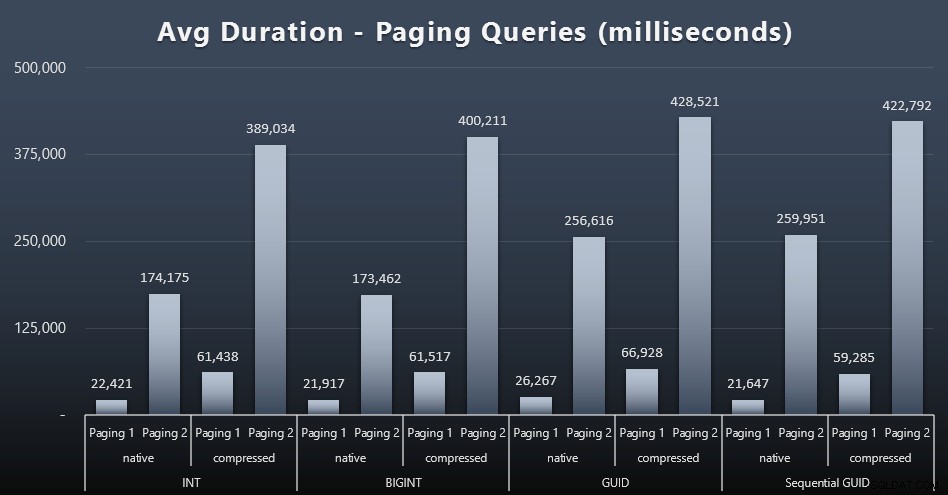
(पेजिंग 1 =ग्राहक आईडी द्वारा आदेश, पेजिंग 2 =अंतिम नाम, प्रथम नाम द्वारा आदेश।)
हम देखते हैं कि पेजिंग 1 (ग्राहक आईडी द्वारा ऑर्डर) और पेजिंग 2 (नामों के अनुसार ऑर्डर) दोनों के लिए, संपीड़न (~ 700% तक) के कारण रन टाइम पर महत्वपूर्ण प्रभाव पड़ता है। दोनों GUID इस दौड़ में सबसे धीमे घोड़े प्रतीत होते हैं, जिनमें NEWID() सबसे खराब प्रदर्शन करते हैं।
कार्यभार अपडेट करें
सिंगलटन अपडेट भारी संगामिति के तहत भी काफी तेज थे, लेकिन संपीड़न के कारण अभी भी कुछ ध्यान देने योग्य अंतर थे, और यहां तक कि डेटा प्रकारों में कुछ आश्चर्यजनक अंतर भी थे (विस्तार करने के लिए क्लिक करें):
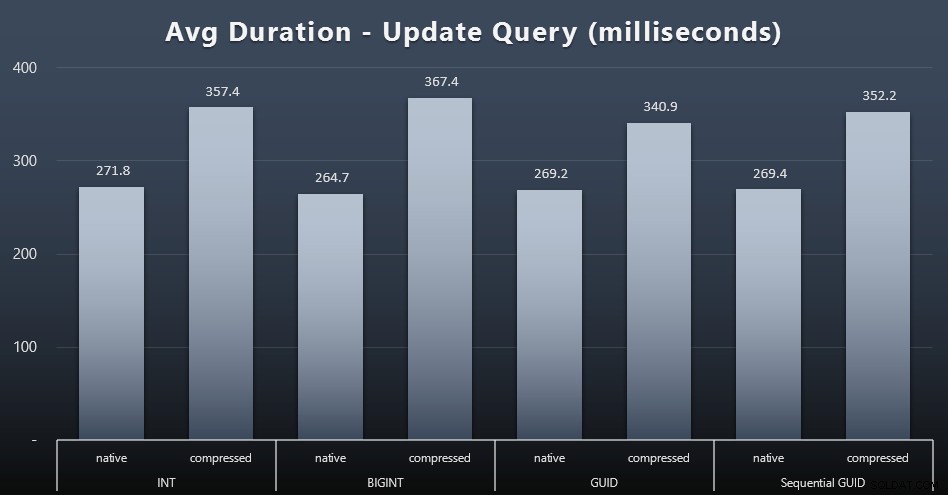
सबसे विशेष रूप से, GUID मानों वाली पंक्तियों के अपडेट वास्तव में तेज़ थे INT/BIGINT वाले अद्यतनों की तुलना में, जब संपीड़न उपयोग में था। स्थानीय भंडारण के साथ, अंतर कम ध्यान देने योग्य थे (लेकिन INT अभी भी वहां हारे हुए थे)।
ट्रिगर आंकड़े
प्रत्येक मामले में साधारण ट्रिगर के लिए औसत और अधिकतम रनटाइम यहां दिए गए हैं (विस्तार करने के लिए क्लिक करें):
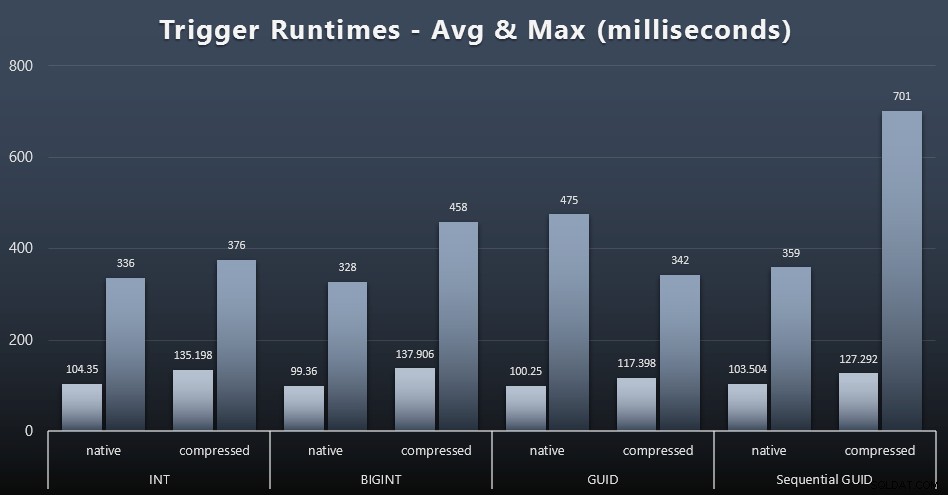
ऐसा लगता है कि डेटा प्रकार पसंद की तुलना में संपीड़न का यहां बहुत बड़ा प्रभाव पड़ता है (हालांकि यह अधिक स्पष्ट होगा यदि मेरे कुछ अपडेट वर्कलोड ने केवल सिंगल-पंक्ति खोजों को शामिल करने के बजाय कई पंक्तियों को अपडेट किया हो)। अनुक्रमिक GUID के लिए अधिकतम स्पष्ट रूप से किसी प्रकार का एक बाहरी है जिसकी मैंने जांच नहीं की (आप बता सकते हैं कि यह औसत अभी भी बोर्ड भर में होने के आधार पर महत्वहीन है)।
इन क्वेरीज़ का क्या इंतज़ार था?
प्रत्येक कार्यभार के बाद, मैंने सिस्टम पर शीर्ष प्रतीक्षाओं पर भी एक नज़र डाली, स्पष्ट कतार/टाइमर प्रतीक्षा (जैसा कि पॉल रान्डल द्वारा वर्णित है), और निगरानी सॉफ़्टवेयर से अप्रासंगिक गतिविधि (जैसे TRACEWRITE) को फेंक दिया। ) यहाँ प्रत्येक मामले में शीर्ष 3 प्रतीक्षाएँ थीं (विस्तार करने के लिए क्लिक करें):
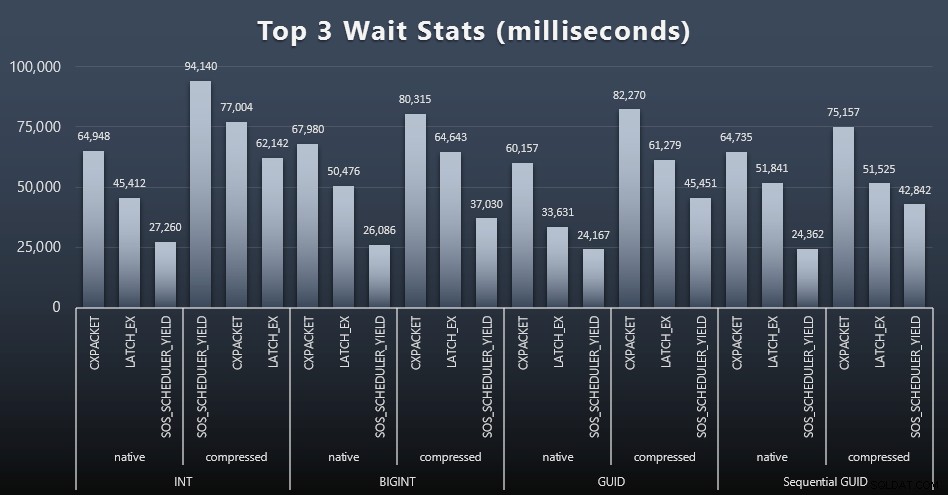
ज्यादातर मामलों में, प्रतीक्षा CXPACKET, फिर LATCH_EX, फिर SOS_SCHEDULER_YIELD थी। पूर्णांक और संपीड़न से जुड़े उपयोग के मामले में, हालांकि, SOS_SCHEDULER_YIELD ने कब्जा कर लिया, जिसका अर्थ है कि पूर्णांक को संपीड़ित करने के लिए एल्गोरिदम में कुछ अक्षमता (जो कि बिगिनट्स को आईएनटी में निचोड़ने के लिए उपयोग किए जाने वाले एल्गोरिदम से पूरी तरह से असंबंधित हो सकती है)। मैंने इसकी और जांच नहीं की, न ही मुझे प्रति व्यक्ति क्वेरी के लिए प्रतीक्षा ट्रैकिंग का औचित्य मिला।
डिस्क स्थान / विखंडन
जबकि मैं इस बात से सहमत हूं कि यह डिस्क स्थान के बारे में नहीं है, यह अभी भी एक मीट्रिक प्रस्तुत करने लायक है। यहां तक कि इस बहुत ही सरल मामले में जहां केवल एक तालिका है और कुंजी अन्य सभी संबंधित तालिकाओं में मौजूद नहीं है (जो निश्चित रूप से वास्तविक अनुप्रयोग में मौजूद होगी), अंतर महत्वपूर्ण है। आइए सबसे पहले reserved को देखें sp_spaceused . से कॉलम (विस्तार करने के लिए क्लिक करें):
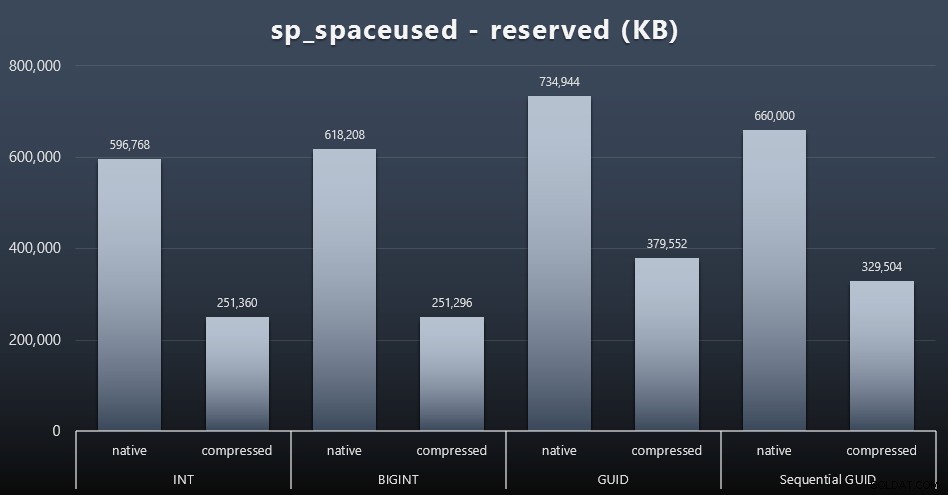
यहाँ, BIGINT ने INT की तुलना में केवल थोड़ी अधिक जगह ली, और GUID (जैसा कि अपेक्षित था) ने एक बड़ी छलांग लगाई। अनुक्रमिक GUID में उपयोग की जाने वाली जगह में कम महत्वपूर्ण वृद्धि हुई, और पारंपरिक GUID की तुलना में बहुत बेहतर संकुचित हुई। फिर, यहाँ कोई आश्चर्य की बात नहीं है - एक GUID एक संख्या से बड़ा है, पूर्ण विराम। अब, GUID के समर्थक यह तर्क दे सकते हैं कि डिस्क स्थान के संदर्भ में आप जो कीमत अदा करते हैं, वह इतनी अधिक नहीं है (बिना कंप्रेशन के BIGINT पर 18%), कंप्रेशन के साथ लगभग 50%)। लेकिन याद रखें कि यह 1 मिलियन पंक्तियों की एकल तालिका है। कल्पना करें कि जब आपके पास 10 मिलियन ग्राहक होंगे और उनमें से कई के पास 10, 30, या 500 ऑर्डर होंगे तो यह कैसे एक्सट्रपलेशन होगा - उन चाबियों को एक दर्जन अन्य तालिकाओं में दोहराया जा सकता है, और प्रत्येक पंक्ति में समान अतिरिक्त स्थान ले सकते हैं।
जब मैंने प्रत्येक कार्यभार के बाद विखंडन को देखा (याद रखें, कोई अनुक्रमणिका रखरखाव नहीं किया जा रहा है) इस क्वेरी का उपयोग करके:
सेलेक्ट index_id, FROM sys.dm_db_index_physical_stats (DB_ID(), OBJECT_ID('dbo.Customers_$use_case$'), -1, 0, 'DETAILED'); बहुत कम दिलचस्प दृश्यों के लिए किए गए परिणाम; सभी गैर-संकुल सूचकांक 99% से अधिक खंडित थे। क्लस्टर किए गए इंडेक्स, हालांकि, या तो बहुत अधिक खंडित थे, या बिल्कुल भी खंडित नहीं थे (विस्तार करने के लिए क्लिक करें):
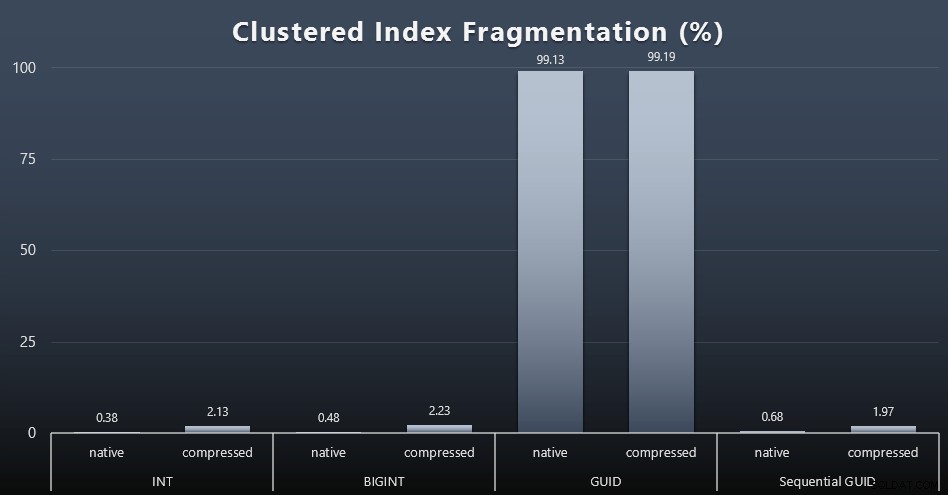
जब हम एसएसडी के बारे में बात कर रहे होते हैं तो विखंडन एक और मीट्रिक होता है, जिसका अर्थ अक्सर बहुत कम होता है, लेकिन सभी को समान रूप से नोट करना महत्वपूर्ण है, क्योंकि सभी सिस्टम I/O पैटर्न पर विखंडन के प्रभाव से अनजान होने का आनंद नहीं उठा सकते हैं। मेरा मानना है कि गैर-अनुक्रमिक GUID का उपयोग करते हुए, अधिक I/O-बाउंड सिस्टम पर, अकेले इस विखंडन का प्रभाव इस परीक्षण में अधिकांश अन्य मीट्रिक पर अत्यधिक बढ़ जाएगा।
बफर पूल उपयोग
यह वह जगह है जहाँ आपकी तालिकाओं द्वारा उपयोग की जाने वाली डिस्क स्थान की मात्रा के बारे में विवेकपूर्ण होना वास्तव में भुगतान करता है - आपकी तालिकाएँ जितनी बड़ी होंगी, वे बफर पूल में उतनी ही अधिक जगह लेंगे। बफर पूल के अंदर और बाहर डेटा ले जाना महंगा है, और फिर से, यह एक बहुत ही सरल मामला है जहां परीक्षण अलगाव में चलाए गए थे और उदाहरण के लिए कीमती स्मृति के लिए प्रतिस्पर्धा करने वाले अन्य एप्लिकेशन और डेटाबेस नहीं थे।
यह प्रत्येक कार्यभार के अंत में निम्नलिखित क्वेरी का एक सरल उपाय है:
sys.dm_os_memory_broker_clerks से कुल_केबी चुनें जहां क्लर्क_नाम =एन'बफ़र पूल';
परिणाम (विस्तार करने के लिए क्लिक करें):
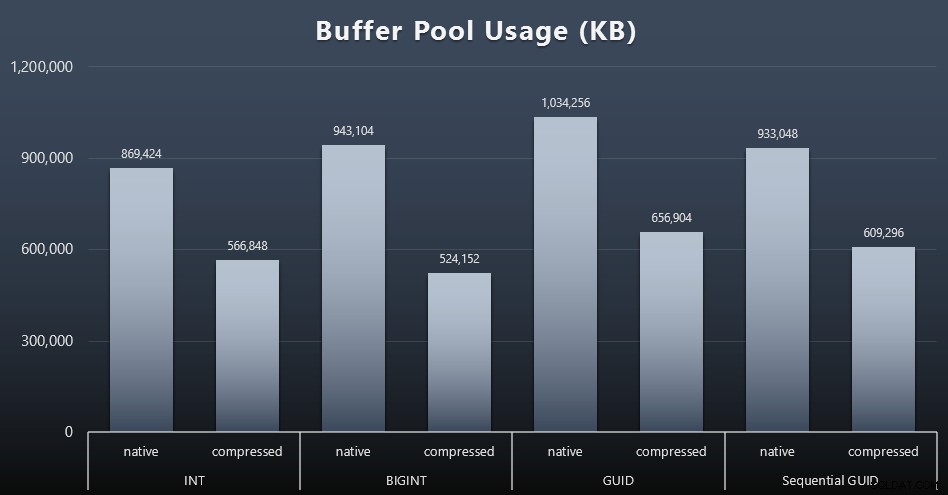
हालांकि इस ग्राफ़ का अधिकांश भाग आश्चर्यजनक नहीं है - GUID BIGINT से अधिक स्थान लेता है, INT से BIGINT अधिक - मुझे यह दिलचस्प लगा कि एक अनुक्रमिक GUID ने संपीड़न के बिना भी, BIGINT की तुलना में कम जगह ली। कवर के तहत यहां किस तरह की दक्षता हो रही है, यह निर्धारित करने के लिए मैंने कुछ पृष्ठ-स्तरीय फोरेंसिक करने के लिए एक नोट बनाया है।
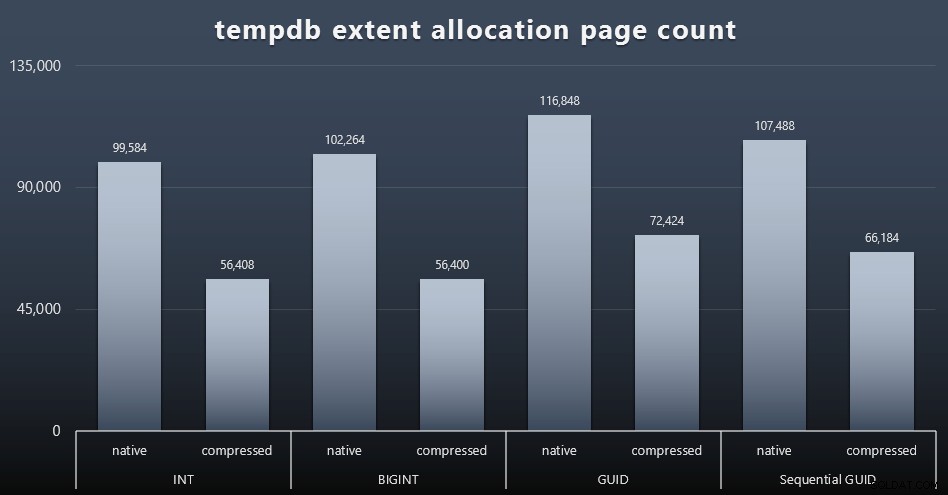
tempdb उपयोग
मुझे यकीन नहीं है कि मैं यहां क्या उम्मीद कर रहा था, लेकिन प्रत्येक कार्यभार के बाद, मैंने तीन tempdb-संबंधित अंतरिक्ष उपयोग DMV, sys.dm_db_file|session|task_space_usage की सामग्री एकत्र की। . डेटा प्रकार के आधार पर केवल एक ही अस्थिरता दिखा रहा था sys.dm_db_file_space_usage का extent_allocation_page_count . इससे पता चलता है कि - कम से कम मेरे कॉन्फ़िगरेशन और इस विशिष्ट कार्यभार में - GUIDs tempdb को थोड़ी अधिक गहन कसरत के माध्यम से रखेंगे (विस्तार करने के लिए क्लिक करें):
"खराब" पृष्ठ विभाजन
जिन चीजों को मैं मापना चाहता था उनमें से एक पृष्ठ विभाजन पर प्रभाव था - सामान्य पृष्ठ विभाजन नहीं (जब आप एक नया पृष्ठ जोड़ते हैं) लेकिन जब आपको वास्तव में अधिक पंक्तियों के लिए जगह बनाने के लिए पृष्ठों के बीच डेटा स्थानांतरित करना होता है। जोनाथन केहैयस ने अपने ब्लॉग पोस्ट में इस बारे में और अधिक गहराई से बात की, "एसक्यूएल सर्वर 2012 एक्सटेंडेड इवेंट्स में ट्रैकिंग प्रॉब्लम पेज स्प्लिट्स - नो रियली दिस टाइम!", जो डेटा को कैप्चर करने के लिए इस्तेमाल किए गए एक्सटेंडेड इवेंट्स सेशन का आधार भी प्रदान करता है: सर्वर पर
ईवेंट सत्र बनाएं [बैडपेजस्प्लिट्स] ईवेंट जोड़ें sqlserver.transaction_log (जहां ऑपरेशन =11 और डेटाबेस_आईडी =10) लक्ष्य पैकेज जोड़ें। हिस्टोग्राम (सेट फ़िल्टरिंग_इवेंट_नाम ='sqlserver.transaction_log', source_type =0, स्रोत ='id' );GOALTER EVENT SESSION [BadPageSplits] सर्वर स्टेट पर =START;GO
और जिस क्वेरी से मैं इसे प्लॉट करता था:
सेलेक्ट t.name, SUM(tab.split_count)FROM (चुनें n.value('(value)[1]', 'bigint') AS alloc_unit_id, n.value('(@count)[1]' , 'bigint') एएस स्प्लिट_काउंट से (सेलेक्ट कास्ट (एक्सएमएल के रूप में टारगेट_डेटा) टारगेट_डेटा sys.dm_xe_sessions के रूप में इनर जॉइन sys.dm_xe_session_targets एएस टी ऑन एस.एड्रेस =टी.ईवेंट_सेशन_नाम ='बैज पेज। ='हिस्टोग्राम' ) AS x क्रॉस लागू करें target_data.nodes('HistogramTarget/Slot') q(n) के रूप में) tabINNER के रूप में sys.allocation_units AS au पर tab.alloc_unit_id =au.allocation_unit_idINNER sys.partitions के रूप में शामिल हों। कंटेनर_आईडी =p.partition_idINNER sys.tables को p.object_id =t.[object_id]GROUP by t.name; के रूप में शामिल करें और यहां परिणाम हैं (विस्तार करने के लिए क्लिक करें):
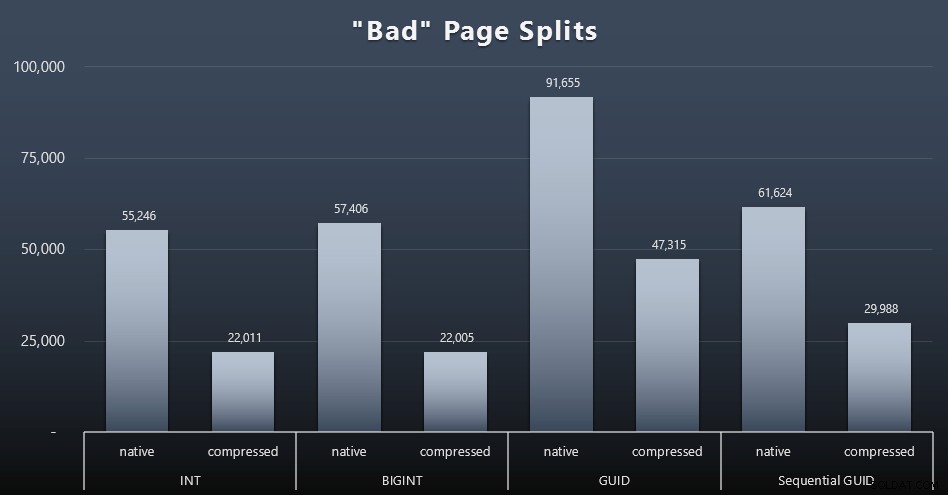
हालांकि मैंने पहले ही नोट कर लिया है कि मेरे परिदृश्य में (जहां मैं तेज एसएसडी पर चल रहा हूं) I/O गतिविधि में निर्विवाद अंतर सीधे समग्र रन टाइम को प्रभावित नहीं करता है, यह अभी भी एक मीट्रिक है जिस पर आप विचार करना चाहेंगे - खासकर यदि आपके पास SSD नहीं है या यदि आपका कार्यभार पहले से ही I/O-बाध्य है।
निष्कर्ष
हालांकि इन परीक्षणों ने मेरी आंखों को थोड़ा चौड़ा कर दिया है कि लंबे समय से चलने वाली धारणाओं को और अधिक आधुनिक हार्डवेयर द्वारा बदल दिया गया है, मैं अभी भी डिस्क या मेमोरी में जगह बर्बाद करने के खिलाफ काफी कट्टर हूं। जबकि मैंने कुछ संतुलन प्रदर्शित करने और GUID को चमकने देने की कोशिश की, INT/BIGINT से UNIQUEIDENTIFIER के किसी भी रूप में स्विच करने का समर्थन करने के लिए प्रदर्शन के दृष्टिकोण से यहां बहुत कम है - जब तक कि आपको अन्य कम मूर्त कारणों के लिए इसकी आवश्यकता न हो (जैसे कि कुंजी बनाना) एप्लिकेशन या अलग-अलग प्रणालियों में अद्वितीय कुंजी मान बनाए रखना)। एक त्वरित सारांश, यह दर्शाता है कि कई मेट्रिक्स में NEWID() सबसे खराब विकल्प है जहां पर्याप्त अंतर था (और उनमें से अधिकतर मामलों में, NEWSEQUENTIALID() एक करीबी दूसरा था)):
| मीट्रिक | हारने वाले को साफ़ करें? |
|---|---|
| निर्विरोध निवेशन | – ड्रा करें – |
| समवर्ती कार्यभार | – ड्रा करें – |
| व्यक्तिगत प्रश्न – जनसंख्या | INT (संपीड़ित) |
| व्यक्तिगत क्वेरी - पेजिंग | NEWID() / NEWSEQUENTIALID() |
| व्यक्तिगत प्रश्न - अपडेट करें | INT (मूल) / BIGINT (संपीड़ित) |
| व्यक्तिगत प्रश्न - ट्रिगर के बाद | – ड्रा करें – |
| डिस्क स्थान | NEWID() |
| संकुल अनुक्रमणिका विखंडन | NEWID() |
| बफर पूल उपयोग | NEWID() |
| tempdb उपयोग | NEWID() |
| "खराब" पृष्ठ विभाजन | NEWID() |
तालिका 2:सबसे ज्यादा हारने वाले
बेझिझक इन चीजों को अपने लिए परखें; यदि आप उन्हें अपने वातावरण में चलाना चाहते हैं तो मैं अपनी स्क्रिप्ट का पूरा सेट इकट्ठा कर सकता हूं। इस पूरी पोस्ट का संक्षिप्त उद्देश्य काफी सरल है:डिस्क स्थान पर अनुमानित प्रभाव से अलग विचार करने के लिए कई महत्वपूर्ण मीट्रिक हैं, इसलिए इसे किसी भी दिशा में तर्क के रूप में अकेले उपयोग नहीं किया जाना चाहिए।
अब, मैं नहीं चाहता कि इस सोच की रेखा को चाबियों तक ही सीमित रखा जाए। जब भी कोई डेटा प्रकार का चुनाव किया जा रहा हो तो इस बारे में वास्तव में सोचा जाना चाहिए। मुझे datetime दिखाई दे रहा है अक्सर चुना जा रहा है, उदाहरण के लिए, जब केवल एक date या smalldatetime ज़रूरी है। लेन-देन की तालिकाओं पर, यह भी बहुत सारे व्यर्थ डिस्क स्थान को उत्पन्न कर सकता है, और यह इन कुछ अन्य संसाधनों के लिए भी नीचे जाता है।
भविष्य के परीक्षण में मैं एक बहुत बड़ी तालिका (> 2 अरब पंक्तियों) के परिणामों की तुलना करना चाहता हूं। मैं पहचान बीज को -2 बिलियन पर सेट करके, ~ 4 बिलियन पंक्तियों की अनुमति देकर आईएनटी के साथ अनुकरण कर सकता हूं। और मैं चाहता हूं कि वर्कलोड और डिस्क स्पेस/मेमोरी फुटप्रिंट तुलना में एक से अधिक टेबल शामिल हों, क्योंकि एक पतली कुंजी के फायदों में से एक यह है कि जब उस कुंजी को दर्जनों संबंधित तालिकाओं में दर्शाया जाता है। मैं ऑटोग्रो घटनाओं के लिए निगरानी कर रहा था, लेकिन कोई भी नहीं था, क्योंकि विकास को समायोजित करने के लिए डेटाबेस काफी बड़ा था, और मैंने मौजूदा लॉग फ़ाइल के अंदर वास्तविक लॉग उपयोग को मापने के लिए नहीं सोचा था, इसलिए मैं परीक्षण करना चाहता हूं फिर से लॉग आकार और ऑटोग्रोथ के लिए डिफ़ॉल्ट के साथ, और इस बार DBCC SQLPERF(LOGSPACE); को मापना . समय के पुनर्निर्माण के लिए भी दिलचस्प होगा और उन परिचालनों के परिणामस्वरूप लॉग उपयोग को भी मापें। अंत में, मैं मैकेनिकल हार्ड डिस्क के साथ सर्वर ढूंढकर I/O को अधिक प्रासंगिक कारक बनाना चाहता हूं - मुझे पता है कि वहां बहुत कुछ है, लेकिन कुछ दुकानों में वे बहुत दुर्लभ हैं।