पिछले साल, मैंने INSTEAD OF Triggers पर स्विच करके SQL सर्वर दक्षता में सुधार नामक एक टिप पोस्ट की थी।
ट्रिगर के बजाय मैं एक बड़ा कारण पसंद करता हूं, विशेष रूप से उन मामलों में जहां मुझे बहुत सारे व्यावसायिक तर्क उल्लंघन की उम्मीद है, यह सहज लगता है कि किसी कार्रवाई को पूरी तरह से रोकने के लिए, आगे बढ़ने और इसे करने के लिए सस्ता होगा (और इसे लॉग करें!), केवल आपत्तिजनक पंक्तियों को हटाने के लिए ट्रिगर के बाद का उपयोग करने के लिए (या पूरे ऑपरेशन को वापस रोल करें)। उस टिप में दिखाए गए परिणामों ने प्रदर्शित किया कि वास्तव में, यह मामला था - और मुझे संदेह है कि वे ऑपरेशन से प्रभावित अधिक गैर-संकुल सूचकांकों के साथ और भी अधिक स्पष्ट होंगे।
हालाँकि, यह एक धीमी डिस्क पर था, और SQL सर्वर 2014 के शुरुआती CTP पर था। एक नई प्रस्तुति के लिए एक स्लाइड तैयार करने में मैं इस साल ट्रिगर्स पर कर रहा हूँ, मैंने पाया कि SQL सर्वर 2014 के एक और हालिया निर्माण पर - अद्यतन हार्डवेयर के साथ संयुक्त - ट्रिगर के बाद और INSTEAD के बीच प्रदर्शन में समान डेल्टा को प्रदर्शित करना थोड़ा मुश्किल था। इसलिए मैंने यह पता लगाने के लिए निर्धारित किया कि क्यों, हालांकि मुझे तुरंत पता था कि यह एक स्लाइड के लिए जितना मैंने कभी किया है उससे कहीं अधिक काम करने वाला था।
एक बात का मैं उल्लेख करना चाहता हूं कि ट्रिगर tempdb . का उपयोग कर सकते हैं अलग-अलग तरीकों से, और यह इनमें से कुछ अंतरों का कारण हो सकता है। एक ट्रिगर के बाद सम्मिलित और हटाए गए छद्म-तालिकाओं के लिए संस्करण स्टोर का उपयोग करता है, जबकि एक INSTEAD OF ट्रिगर इस डेटा की एक आंतरिक वर्कटेबल में प्रतिलिपि बनाता है। अंतर सूक्ष्म है, लेकिन ध्यान देने योग्य है।
चर
मैं विभिन्न परिदृश्यों का परीक्षण करने जा रहा हूं, जिनमें शामिल हैं:
- तीन अलग-अलग ट्रिगर:
- एक ट्रिगर के बाद जो विफल होने वाली विशिष्ट पंक्तियों को हटा देता है
- एक ट्रिगर के बाद जो किसी भी पंक्ति के विफल होने पर पूरे लेनदेन को वापस ले लेता है
- एक ट्रिगर के बजाय जो केवल पास होने वाली पंक्तियों को सम्मिलित करता है
- विभिन्न पुनर्प्राप्ति मॉडल और स्नैपशॉट अलगाव सेटिंग्स:
- स्नैपशॉट सक्षम के साथ पूर्ण
- स्नैपशॉट के साथ पूर्ण अक्षम
- SNAPSHOT सक्षम के साथ सरल
- SNAPSHOT अक्षम के साथ सरल
- विभिन्न डिस्क लेआउट*:
- एसएसडी पर डेटा, 7200 आरपीएम एचडीडी पर लॉग ऑन करें
- एसएसडी पर डेटा, एसएसडी पर लॉग ऑन करें
- 7200 आरपीएम एचडीडी पर डेटा, एसएसडी पर लॉग ऑन करें
- 7200 आरपीएम एचडीडी पर डेटा, 7200 आरपीएम एचडीडी पर लॉग ऑन करें
- विभिन्न विफलता दर:
- 10%, 25%, और 50% विफलता दर:
- 20,000 पंक्तियों का एकल बैच इंसर्ट
- 2,000 पंक्तियों के 10 बैच
- 200 पंक्तियों के 100 बैच
- 20 पंक्तियों के 1,000 बैच
- 20,000 सिंगलटन इंसर्ट
*
tempdbधीमी, 7200 RPM डिस्क पर एकल डेटा फ़ाइल है। यह जानबूझकर किया गया है औरtempdbके विभिन्न उपयोगों के कारण होने वाली किसी भी बाधा को बढ़ाने के लिए है। . जबtempdb. मैं किसी बिंदु पर इस परीक्षण को फिर से देखने की योजना बना रहा हूं तेज़ SSD पर है। - 10%, 25%, और 50% विफलता दर:
ठीक है, TL;DR पहले ही!
यदि आप केवल परिणाम जानना चाहते हैं, तो नीचे जाएं। बीच में सब कुछ सिर्फ पृष्ठभूमि है और इस बात का स्पष्टीकरण है कि मैंने परीक्षण कैसे स्थापित और चलाया। मैं इस बात से निराश नहीं हूं कि हर किसी को सभी सूक्ष्मताओं में दिलचस्पी नहीं होगी।
परिदृश्य
परीक्षणों के इस विशेष सेट के लिए, वास्तविक जीवन परिदृश्य वह है जहां उपयोगकर्ता स्क्रीन नाम चुनता है, और ट्रिगर को उन मामलों को पकड़ने के लिए डिज़ाइन किया गया है जहां चुना गया नाम कुछ नियमों का उल्लंघन करता है। उदाहरण के लिए, यह "निन्नी-मगिन्स" का कोई रूपांतर नहीं हो सकता (आप निश्चित रूप से यहां अपनी कल्पना का उपयोग कर सकते हैं)।
मैंने 20,000 अद्वितीय उपयोगकर्ता नामों के साथ एक तालिका बनाई:
मॉडल का उपयोग करें; GO - 20,000 अलग, अच्छे नाम; अलग-अलग नामों के साथ (sys.all_columns से नाम चुनें यूनियन sys.all_objects से नाम चुनें) शीर्ष चुनें (20000) नाम डीबीओ में। नाम + 'x' अलग-अलग नामों से यूनियन का चयन नाम + 'y' अलग-अलग नामों से यूनियन चयन नाम + 'z' से अलग_नाम) एएस एक्स; dbo.GoodNamesSource(Name);पर अद्वितीय क्लस्टर इंडेक्स x बनाएं
फिर मैंने एक टेबल बनाया जो मेरे "शरारती नामों" के खिलाफ जांच करने का स्रोत होगा। इस मामले में यह सिर्फ ninny-muggins-00001 है ninny-muggins-10000 . के माध्यम से :
मॉडल का उपयोग करें; टेबल डीबीओ बनाएं। शरारती उपयोगकर्ता नाम (नाम NVARCHAR (255) प्राथमिक कुंजी); जाओ - 10,000 "खराब" नाम डीबीओ डालें। शरारती उपयोगकर्ता नाम (नाम) चुनें एन 'निन्नी-मगिन्स-' + दाएं (एन'0000) ' + RTRIM(n),5) से ( टॉप (10000) n =ROW_NUMBER() ओवर (नाम से ऑर्डर करें) से dbo.GoodNamesSource ) AS x;
मैंने इन तालिकाओं को model . में बनाया है डेटाबेस ताकि हर बार जब मैं एक डेटाबेस बनाऊं, यह स्थानीय रूप से मौजूद हो, और मैं ऊपर सूचीबद्ध परिदृश्य मैट्रिक्स का परीक्षण करने के लिए बहुत सारे डेटाबेस बनाने की योजना बना रहा हूं (बजाय केवल डेटाबेस सेटिंग्स बदलें, लॉग को साफ़ करें, आदि)। कृपया ध्यान दें, यदि आप परीक्षण उद्देश्यों के लिए मॉडल में ऑब्जेक्ट बनाते हैं, तो सुनिश्चित करें कि जब आप कर लें तो आप उन ऑब्जेक्ट्स को हटा दें।
एक तरफ के रूप में, मैं जानबूझकर महत्वपूर्ण उल्लंघनों और अन्य त्रुटि को संभालने जा रहा हूं, जिससे भोली धारणा बनती है कि चुने हुए नाम को विशिष्टता के लिए जांचा जाता है, इससे पहले कि सम्मिलित करने का प्रयास किया जाता है, लेकिन उसी लेनदेन के भीतर (जैसे शरारती नाम तालिका के खिलाफ पहले से जांच की जा सकती थी)।
इसका समर्थन करने के लिए, मैंने model . में निम्नलिखित तीन लगभग समान तालिकाएं भी बनाईं , परीक्षण अलगाव उद्देश्यों के लिए:
मॉडल का उपयोग करें; जाओ - के बाद (रोलबैक) टेबल डीबीओ बनाएं। उपयोगकर्ता नाम_आफ्टर_रोलबैक (उपयोगकर्ता आईडी पहचान (1,1) प्राथमिक कुंजी, नाम NVARCHAR (255) पूर्ण अद्वितीय नहीं, दिनांक बनाया गया दिनांक पूर्ण डिफ़ॉल्ट SYSDATETIME ()); बनाएं INDEX x ON dbo.UserNames_After_Rollback(DateCreated) INCLUDE(Name); - तालिका बनाने के बाद (हटाएं) dbo.UserNames_After_Delete (उपयोगकर्ता आईडी पहचान पहचान (1,1) प्राथमिक कुंजी, नाम NVARCHAR (255) पूर्ण अद्वितीय नहीं, दिनांक बनाया गया दिनांक पूर्ण डिफ़ॉल्ट नहीं SYSDATETIME()); डीबीओ पर इंडेक्स एक्स बनाएं। उपयोगकर्ता नाम_आफ्टर_डिलीट ( दिनांक बनाया गया) शामिल करें (नाम); -- INSTEADCREATE TABLE dbo.UserNames_Instead(UserID INT IDENTITY(1,1) PRIMARY KEY, Name NVARCHAR(255) NOT NULL UNIQUE, DateCreated DATE NOT NULL DEFAULT SYSDATETIME()); क्रिएट इंडेक्स x ऑन dbo.UserNames_Instead(DateCreated) INC. नाम);जाओ
और निम्नलिखित तीन ट्रिगर, प्रत्येक तालिका के लिए एक:
मॉडल का उपयोग करें;जाओ -- AFTER (रोलबैक)ट्रिगर बनाएं dbo.trUserNames_After_RollbackON dbo.UserNames_After_Rollbackबाद में INSERTASBEGIN SET NOCOUNT ON; यदि मौजूद है (जहां मौजूद है, वहां से सम्मिलित से 1 का चयन करें (डीबीओ से चुनें। शरारती उपयोगकर्ता नाम जहां नाम =i.Name)) रोलबैक लेनदेन शुरू करें; ENDENDGO -- AFTER (डिलीट) TRIGGER बनाएं dbo.trUserNames_After_DeleteON dbo.UserNames_After_Delete के बाद INSERTASBEGIN सेट NOCOUNT ON; DELETE d से डाला गया जैसा कि मैं इनर जॉइन dbo.NaughtyUserNames as n ON i.Name =n.Name INNER JOIN dbo.UserNames_After_Delete AS d ON i.UserID =d.UserID;ENDGO - INSTEADCREATE TRIGGER OF dbo.SBN खाता चालू करें; INSERT dbo.UserNames_Instead(Name) चुनें i.नाम से सम्मिलित किया गया जैसा कि मैं मौजूद नहीं हूं (dbo से 1 चुनें। शरारती उपयोगकर्ता नाम जहां नाम =i.Name);ENDGO
आप शायद उपयोगकर्ता को यह सूचित करने के लिए अतिरिक्त हैंडलिंग पर विचार करना चाहेंगे कि उनकी पसंद को वापस ले लिया गया था या अनदेखा कर दिया गया था - लेकिन यह भी सरलता के लिए छोड़ दिया गया है।
परीक्षण सेटअप
मैंने उन तीन विफलता दरों का प्रतिनिधित्व करते हुए नमूना डेटा बनाया, जिनका मैं परीक्षण करना चाहता था, 10 प्रतिशत को 25 और फिर 50 में बदलना, और इन तालिकाओं को भी model में जोड़ना :
मॉडल का उपयोग करें; GO DECLARE @pct INT =10, @cap INT =20000;-- इसे बदलें ---- ^^ से 25 और 50 DECLARE @good INT =@cap - (@cap*(@pct/ 100.0); सेलेक्ट नाम, rn =ROW_NUMBER () ओवर (NEWID द्वारा ऑर्डर ()) dbo.Source10Percent से - इसे ^^ से 25 और 50 में बदलें (सेलेक्ट नेम (सेलेक्ट टॉप (@good) नाम से dbo.GoodNamesSource ऑर्डर द्वारा NEWID ()) एएस जी यूनियन से सभी का चयन नाम (सेलेक्ट टॉप (@cap-@good) नाम डीबीओ से। dbo.Source10Percent(rn) पर अद्वितीय क्लस्टर इंडेक्स बनाएं;-- और यहां भी ------------------^^
प्रत्येक तालिका में 20,000 पंक्तियाँ होती हैं, नामों के एक अलग मिश्रण के साथ जो पास और विफल हो जाएगी, और पंक्ति संख्या कॉलम डेटा को अलग-अलग परीक्षणों के लिए अलग-अलग बैच आकारों में विभाजित करना आसान बनाता है, लेकिन सभी परीक्षणों के लिए दोहराने योग्य विफलता दर के साथ।
बेशक हमें नतीजे हासिल करने के लिए जगह चाहिए। मैंने इसके लिए एक अलग डेटाबेस का उपयोग करना चुना, प्रत्येक परीक्षण को कई बार चलाना, बस अवधि को कैप्चर करना।
डेटाबेस कंट्रोल डीबी बनाएं; कंट्रोलडीबी का उपयोग करें; टेबल डीबीओ बनाएं। टेस्ट (टेस्टिड आईएनटी, डिस्कलाउट वचरर (15), रिकवरी मॉडल वर्चर (6), ट्रिगर टाइप वर्चर (14), [स्नैपशॉट] वर्चर (3), विफलता दर आईएनटी, [एसक्यूएल] नवचर (मैक्स)); तालिका बनाएं dbo.TestResults(TestID INT, BatchDescription VARCHAR(15), Duration INT);
मैंने dbo.Tests . को भर दिया है निम्नलिखित स्क्रिप्ट के साथ तालिका, ताकि मैं वर्तमान परीक्षण मापदंडों से मेल खाने के लिए चार डेटाबेस स्थापित करने के लिए विभिन्न भागों को निष्पादित कर सकूं। ध्यान दें कि D:\ एक SSD है, जबकि G:\ एक 7200 RPM डिस्क है:
TRUNCATE TABLE dbo.Tests;TRUNCATE TABLE dbo.TestResults;;डी AS के साथ (VALUES ('DataSSD_LogHDD'), ('DataSSD_LogSSD'), ('DataHDD_LogHDD'), ('DataHDD_LogSSD')) AS d (DiskLayout)), t AS (सेलेक्ट ट्रिगर टाइप (VALUES) से चुनें। 'आफ्टर_डिलीट'), ('आफ्टर_रोलबैक'), ('बजाय')) एएस टी (ट्रिगर टाइप)), एम एएस (सेलेक्ट रिकवरीमॉडल ='फुल' यूनियन ऑल सिलेक्ट 'सिंपल'), एस एएस ( सेलेक्ट आईएस स्नैपशॉट =0 यूनियन ऑल चयन 1), पी एएस (चयन विफलता दर =10 यूनियन सभी चयन 25 यूनियन सभी चयन 50) सम्मिलित करें ControlDB.dbo.Tests (TestID, DiskLayout, RecoveryModel, TriggerType, IsSnapshot, FailureRate, Command) Select TestID =ROW_NUMBER () ओवर (आदेश) द्वारा d.DiskLayout, t.TriggerType, m.RecoveryModel, s.IsSnapshot, p.FailureRate), d.DiskLayout, m.RecoveryModel, t.TriggerType, s.IsSnapshot, p.FailureRate, [sql]=N'SET NOCOUNT पर; डेटाबेस '+ QUOTENAME(d.DiskLayout) + N' ON (name =N''data'', filename =N''' + CASE d.DiskLayout बनाएं जब 'DataSSD_LogHDD' तब N'D:\data\data1.mdf '') लॉग ऑन (नाम =एन''लॉग'', फ़ाइल नाम =एन''जी:\लॉग\डेटा1.एलडीएफ'');'जब 'डेटाएसएसडी_लॉगएसएसडी' तब एन'डी:\डेटा\डेटा2.एमडीएफ'' ) लॉग ऑन (नाम =एन''लॉग'', फ़ाइल नाम =एन''डी:\लॉग\डेटा2.एलडीएफ'');'जब 'डेटाएचडीडी_लॉगएचडीडी' तब एन'जी:\डेटा\डेटा3.एमडीएफ'') लॉग इन करें ON (name =N''log'', filename =N''G:\log\data3.ldf'');'जब 'DataHDD_LogSSD' तब N'G:\data\data4.mdf'') लॉग ऑन करें ( नाम =एन''लॉग'', फाइलनाम =एन''डी:\लॉग\डेटा4.एलडीएफ'');' END+ 'EXEC sp_executesql N''ALTER DATABASE' + QUOTENAME(d.DiskLayout) + 'SET RECOVERY' + m.RecoveryModel + ';'';'+ Case जब s.IsSnapshot =1 तब 'EXEC sp_executesql N''ALTER DATABASE ' + QUOTENAME(d.DiskLayout) + ' ALLOW_SNAPSHOT_ISOLATION ON;''; EXEC sp_executesql N''ALTER DATABASE' + QUOTENAME(d.DiskLayout) + 'SET READ_COMMITTED_SNAPSHOT ON;'';' ELSE '' END+ ' DECLARE @d DATETIME2(7), @i INT, @LoopID INT, @loops INT, @perloop INT; DECLARE c CURSOR LOCAL FAST_FORWARD फॉर सेलेक्ट लूपिड, लूप्स, परलूप फ्रॉम dbo.Loops; खुला सी; FETCH c INTO @LoopID, @loops, @perloop; जबकि @@FETCH_STATUS <> -1BEGIN EXEC sp_executesql N''TRUNCATE TABLE' + QUOTENAME(d.DiskLayout) + '.dbo.UserNames_' + t.TriggerType + ';''; @d =SYSDATETIME (), @i =1 चुनें; जबकि @i <=@loops INSERT '+ QUOTENAME(d.DiskLayout) + '.dbo.UserNames_' + t.TriggerType + '(Name) से नाम चुनें' + QUOTENAME(d.DiskLayout) + '.dbo से शुरू करें। .स्रोत' + आरटीआरआईएम (पी.विफलता दर) + 'प्रतिशत जहां आरएन> (@i-1)*@perloop और rn <=@i*@perloop; अंत प्रयास शुरू करें कैच सेट @TestID =@TestID; अंत कैच सेट @i +=1; END INSERT ControlDB.dbo.TestResults(TestID, LoopID, Duration) चुनें @TestID, @LoopID, DATEDIFF(MILLISECOND, @d, SYSDATETIME ()); FETCH c INTO @LoopID, @loops, @perloop;END CLOSE c;DEALLOCATE c; ड्रॉप डेटाबेस '+ QUOTENAME(d.DiskLayout) +';'FROM d, t, m, s, p; - निहित क्रॉस जॉइन! जैसा मैं कहता हूं वैसा करो, जैसा मैं करता हूं वैसा नहीं! :-) तब सभी परीक्षणों को कई बार चलाना आसान था:
कंट्रोलडीबी का उपयोग करें;जाओ सेट करें चालू करें; DECLARE @TestID INT, @Command NVARCHAR(MAX), @msg VARCHAR(32); DECLARE d CURSOR LOCAL FAST_FORWARD सेलेक्ट टेस्टिड के लिए, ControlDB.dbo.Tests से कमांड TestID द्वारा ऑर्डर करें; खुला घ; FETCH d INTO @TestID, @Command; जबकि @@FETCH_STATUS <> -1BEGIN SET @msg ='प्रारंभ' + RTRIM(@TestID); RAISERROR(@msg, 0, 1) NOWAIT के साथ; EXEC sp_executesql @Command, N'@TestID INT', @TestID; SET @msg ='समाप्त' + RTRIM(@TestID); RAISERROR(@msg, 0, 1) NOWAIT के साथ; FETCH d INTO @TestID, @Command;END CLOSE d;DEALLOCATE d; जाओ 10
मेरे सिस्टम पर इसमें करीब 6 घंटे लगे, इसलिए इसे बिना किसी रुकावट के चलने देने के लिए तैयार रहें। साथ ही, सुनिश्चित करें कि आपके पास model . के विरुद्ध कोई सक्रिय कनेक्शन या क्वेरी विंडो नहीं खुली है डेटाबेस, अन्यथा आपको यह त्रुटि तब मिल सकती है जब स्क्रिप्ट डेटाबेस बनाने का प्रयास करती है:
डेटाबेस 'मॉडल' पर विशेष लॉक प्राप्त नहीं कर सका। बाद में कार्रवाई का पुन:प्रयास करें।
परिणाम
देखने के लिए कई डेटा बिंदु हैं (और डेटा प्राप्त करने के लिए उपयोग किए जाने वाले सभी प्रश्नों को परिशिष्ट में संदर्भित किया गया है)। ध्यान रखें कि यहां दर्शाई गई प्रत्येक औसत अवधि 10 से अधिक परीक्षणों की है और गंतव्य तालिका में कुल 100,000 पंक्तियों को सम्मिलित कर रही है।
ग्राफ़ 1 - समग्र समुच्चय
पहला ग्राफ़ आइसोलेशन में अलग-अलग वैरिएबल के लिए समग्र समुच्चय (औसत अवधि) दिखाता है (इसलिए *सभी* परीक्षण एक AFTER ट्रिगर का उपयोग करते हैं जो हटाता है, *सभी* परीक्षण एक AFTER ट्रिगर का उपयोग करके जो वापस रोल करता है, आदि)।
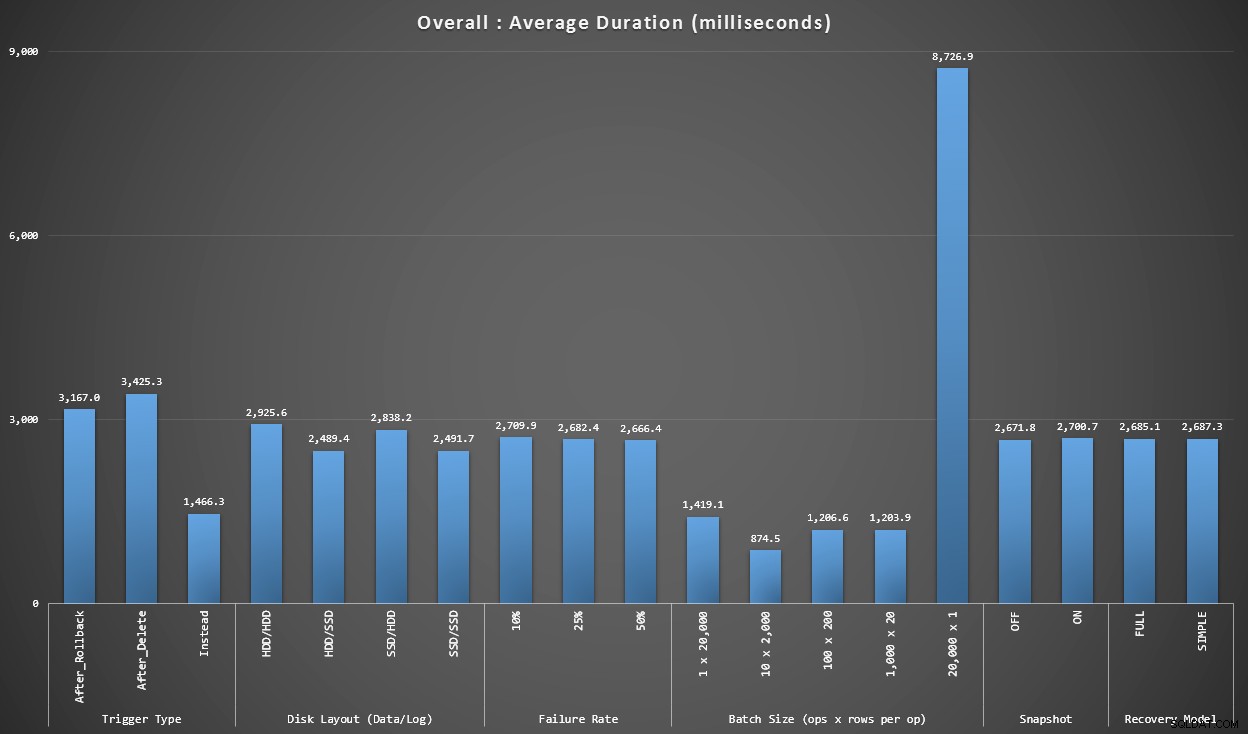
औसत अवधि, मिलीसेकंड में, अलगाव में प्रत्येक चर के लिए
कुछ चीजें तुरंत हमारे सामने आती हैं:
- यहां INSTEAD OF ट्रिगर दोनों AFTER ट्रिगर से दोगुना तेज है।
- SSD पर ट्रांजेक्शन लॉग होने से थोड़ा फर्क पड़ा। डेटा फ़ाइल का स्थान बहुत कम है।
- 20,000 सिंगलटन इंसर्ट का बैच किसी भी अन्य बैच वितरण की तुलना में 7-8x धीमा था।
- 20,000 पंक्तियों का एकल बैच इंसर्ट किसी भी गैर-सिंगलटन वितरण की तुलना में धीमा था।
- विफलता दर, स्नैपशॉट अलगाव और पुनर्प्राप्ति मॉडल का प्रदर्शन पर बहुत कम प्रभाव पड़ा है।
ग्राफ 2 - कुल मिलाकर सर्वश्रेष्ठ 10
जब प्रत्येक चर पर विचार किया जाता है तो यह ग्राफ़ सबसे तेज़ 10 परिणाम दिखाता है। ये सभी ट्रिगर्स के बजाय हैं जहां पंक्तियों का सबसे बड़ा प्रतिशत विफल (50%) होता है। आश्चर्यजनक रूप से, सबसे तेज़ (हालांकि बहुत अधिक नहीं) के पास एक ही एचडीडी (एसएसडी नहीं) पर डेटा और लॉग दोनों थे। यहां डिस्क लेआउट और पुनर्प्राप्ति मॉडल का मिश्रण है, लेकिन सभी 10 में स्नैपशॉट आइसोलेशन सक्षम था, और शीर्ष 7 परिणामों में सभी 10 x 2,000 पंक्ति बैच आकार शामिल थे।
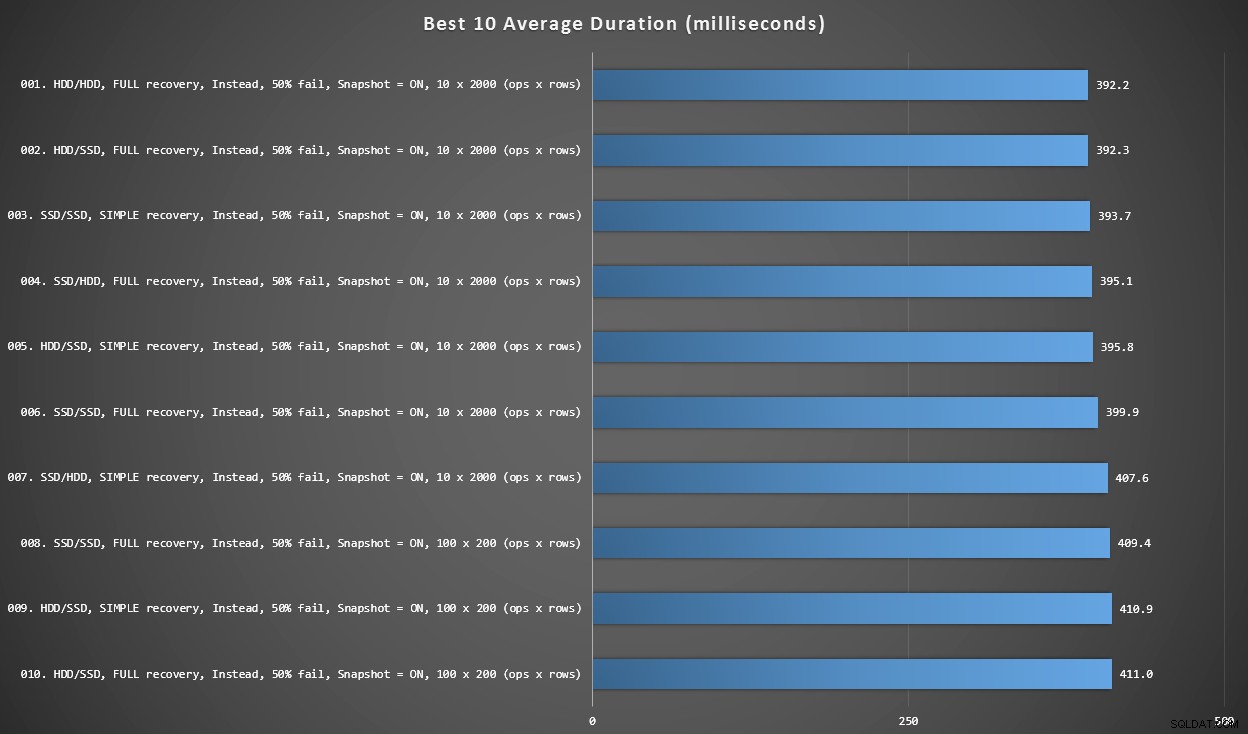
प्रत्येक चर को ध्यान में रखते हुए मिलीसेकंड में सर्वश्रेष्ठ 10 अवधियां
ट्रिगर के बाद सबसे तेज़ - 100 x 200 पंक्ति बैच आकार में 10% विफलता दर वाला रोलबैक संस्करण - #144 (806 एमएस) की स्थिति में आया।
ग्राफ 3 - कुल मिलाकर सबसे खराब 10
जब प्रत्येक चर पर विचार किया जाता है तो यह ग्राफ सबसे धीमे 10 परिणाम दिखाता है; सभी वेरिएंट के बाद हैं, सभी में 20,000 सिंगलटन इंसर्ट शामिल हैं, और सभी के पास डेटा है और एक ही धीमी एचडीडी पर लॉग इन है।
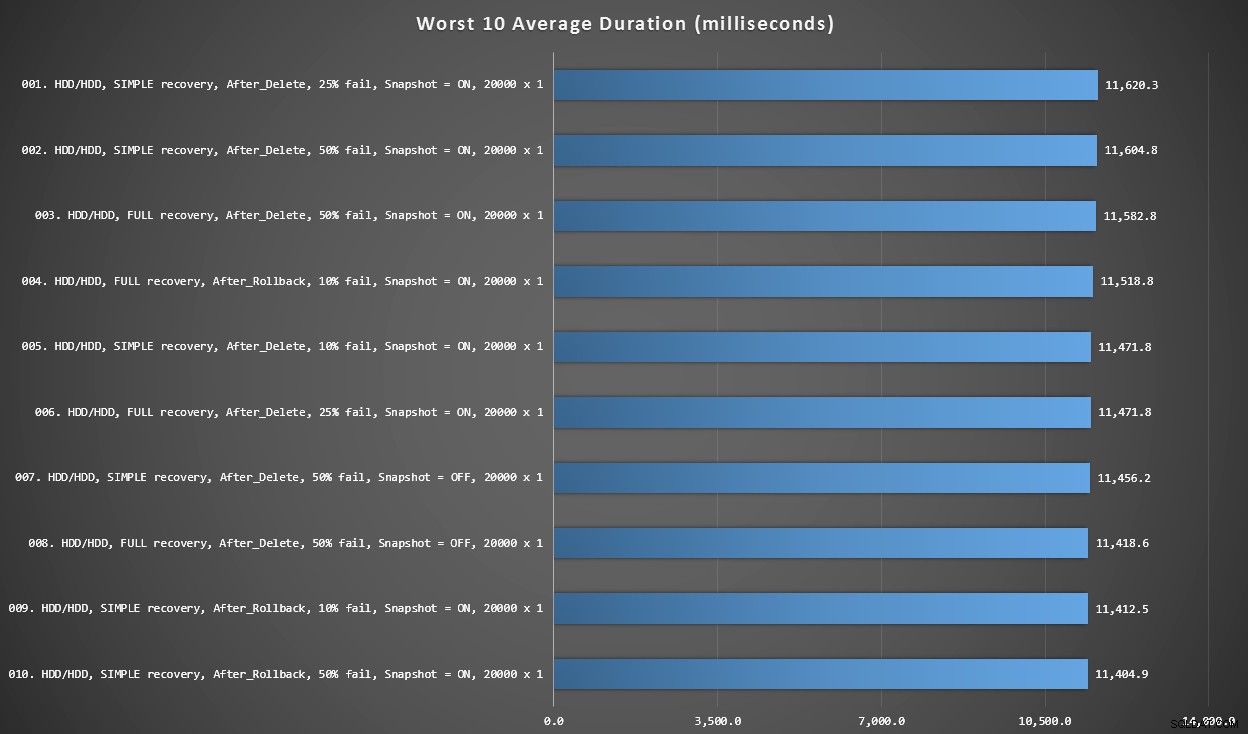
मिलीसेकंड में सबसे खराब 10 अवधियां, प्रत्येक चर को ध्यान में रखते हुए
परीक्षण की सबसे धीमी INSTEAD स्थिति #97 में, 5,680 ms पर थी - एक 20,000 सिंगलटन इंसर्ट परीक्षण जहां 10% विफल हो जाते हैं। यह देखना भी दिलचस्प है कि 20,000 सिंगलटन इंसर्ट बैच आकार का उपयोग करते हुए ट्रिगर के बाद एक भी बेहतर प्रदर्शन नहीं किया - वास्तव में 96 वां सबसे खराब परिणाम एक AFTER (डिलीट) परीक्षण था जो 10,219 एमएस पर आया था - अगले सबसे धीमे परिणाम से लगभग दोगुना।
ग्राफ 4 - लॉग डिस्क प्रकार, सिंगलटन इंसर्ट्स
ऊपर दिए गए ग्राफ़ हमें सबसे बड़े दर्द बिंदुओं का एक मोटा विचार देते हैं, लेकिन वे या तो बहुत अधिक ज़ूम इन हैं या पर्याप्त रूप से ज़ूम नहीं किए गए हैं। यह ग्राफ़ वास्तविकता के आधार पर डेटा को फ़िल्टर करता है:ज्यादातर मामलों में इस प्रकार का ऑपरेशन सिंगलटन इंसर्ट होने वाला है। मैंने सोचा था कि मैं इसे विफलता दर और लॉग के प्रकार के डिस्क के आधार पर तोड़ दूंगा, लेकिन केवल उन पंक्तियों को देखें जहां बैच 20,000 व्यक्तिगत आवेषण से बना है।
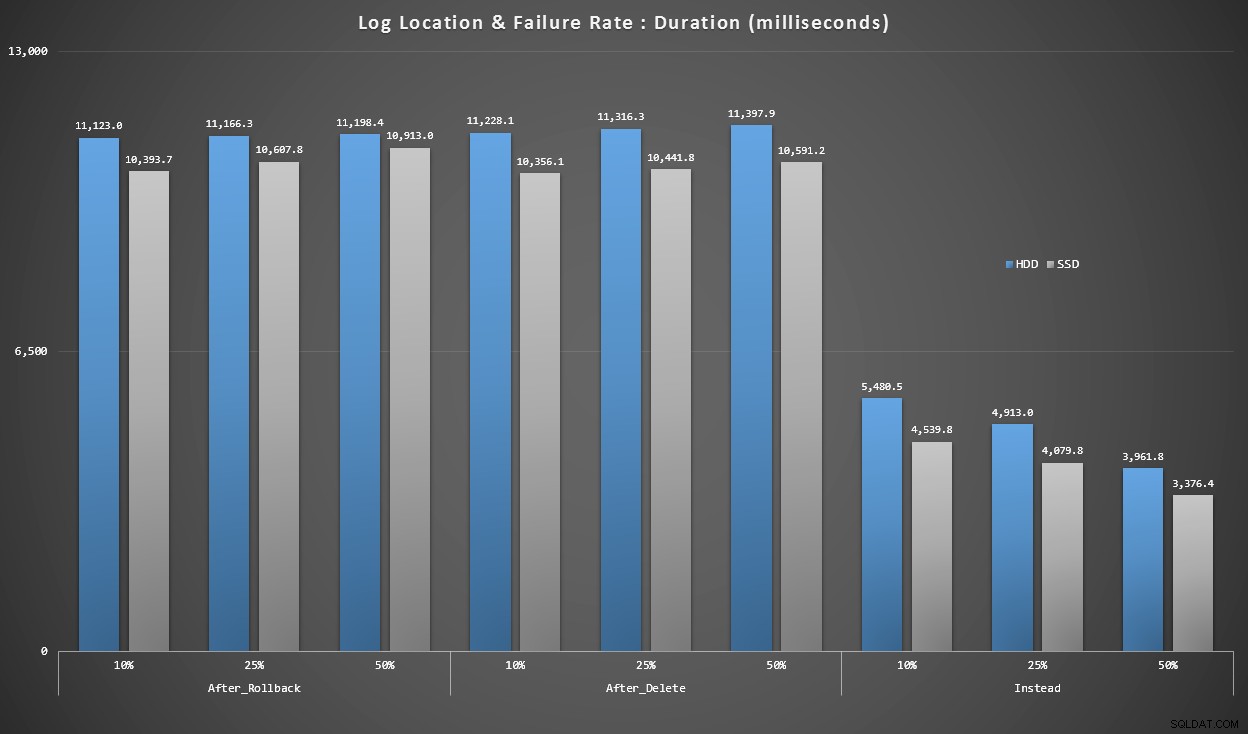
अवधि, मिलीसेकंड में, विफलता दर और लॉग स्थान के आधार पर समूहीकृत, 20,000 व्यक्तिगत प्रविष्टियों के लिए
यहां हम देखते हैं कि सभी AFTER 10-11 सेकंड रेंज (लॉग लोकेशन के आधार पर) में औसत ट्रिगर करते हैं, जबकि सभी INSTEAD OF ट्रिगर्स 6 सेकंड के निशान से काफी नीचे हैं।
निष्कर्ष
अब तक, मुझे यह स्पष्ट लगता है कि ज्यादातर मामलों में INSTEAD OF ट्रिगर एक विजेता है - कुछ मामलों में दूसरों की तुलना में अधिक (उदाहरण के लिए, जैसे-जैसे विफलता दर बढ़ती है)। अन्य कारक, जैसे कि पुनर्प्राप्ति मॉडल, का समग्र प्रदर्शन पर बहुत कम प्रभाव पड़ता है।
यदि आपके पास डेटा को कैसे तोड़ना है, इसके बारे में अन्य विचार हैं, या डेटा की एक प्रति अपने स्वयं के स्लाइसिंग और डाइसिंग करने के लिए चाहते हैं, तो कृपया मुझे बताएं। यदि आप इस परिवेश को स्थापित करने में सहायता चाहते हैं ताकि आप अपने स्वयं के परीक्षण चला सकें, तो मैं इसमें भी सहायता कर सकता हूं।
हालांकि इस परीक्षण से पता चलता है कि ट्रिगर्स के बजाय निश्चित रूप से विचार करने योग्य हैं, यह पूरी कहानी नहीं है। मैंने सचमुच इन ट्रिगर्स को उस तर्क का उपयोग करके एक साथ थप्पड़ मारा जो मुझे लगा कि प्रत्येक परिदृश्य के लिए सबसे अधिक समझ में आता है, लेकिन ट्रिगर कोड - किसी भी टी-एसक्यूएल कथन की तरह - इष्टतम योजनाओं के लिए ट्यून किया जा सकता है। एक अनुवर्ती पोस्ट में, मैं एक संभावित अनुकूलन पर एक नज़र डालूँगा जो AFTER ट्रिगर को अधिक प्रतिस्पर्धी बना सकता है।
परिशिष्ट
परिणाम अनुभाग के लिए उपयोग की जाने वाली क्वेरी:
ग्राफ़ 1 - समग्र समुच्चय
RTRIM(l.loops) + 'x' + RTRIM(l.perloop), AVG(r.Duration*1.0) से dbo.TestResults चुनें r INNER JOIN dbo.Loops AS l ON r.LoopID =l. लूपिड ग्रुप बाय आरटीआरआईएम(l.loops) + 'x' + RTRIM(l.perloop); dbo से t.IsSnapshot, AVG (अवधि * 1.0) चुनें। इनर जॉइन dbo के रूप में टेस्ट परिणाम। tr.TestID =t.TestID समूह द्वारा t.Is स्नैपशॉट के रूप में परीक्षण; t.RecoveryModel, AVG (अवधि * 1.0) से dbo.TestResults को tr INNER JOIN dbo से चुनें। tr.TestID =t.TestID GROUP BY t.RecoveryModel; dbo.TestResults से t.DiskLayout, AVG (अवधि*1.0) चुनें। dbo से t.TriggerType, AVG (अवधि * 1.0) चुनें। इनर जॉइन dbo के रूप में टेस्ट परिणाम। tr.TestID =t.TestID ग्रुप द्वारा t.TriggerType; dbo.TestResults से t.FailureRate, AVG (अवधि*1.0) चुनें।ग्राफ 2 और 3 - सर्वश्रेष्ठ और सबसे खराब 10
; src AS के साथ (डिस्कलेआउट, रिकवरीमॉडल, ट्रिगर टाइप, फेल्योररेट, IsSnapshot, बैच =RTRIM(l.loops) + 'x' + RTRIM(l.perloop), Duration =AVG(Duration*1.0) from dbo. टेस्ट इनर जॉइन dbo.TestResults as tr ON tr.TestID =t.TestID INNER JOIN dbo.Loops as l ON tr.LoopID =l. LoopID GROUP by DiskLayout, RecoveryModel, TriggerType, FailureRate, IsSnapshot, RTRIM (I.Snapshot, RTRIM) ) + 'x' + RTRIM (l.perloop)), agg AS (चुनें लेबल =जगह (बदलें (डिस्कलाउट, 'डेटा', ''), '_ लॉग', '/') + ',' + रिकवरीमॉडल + ' पुनर्प्राप्ति, '+ ट्रिगर टाइप +', '+ आरटीआरआईएम (विफलता दर) +'% विफल' + ', स्नैपशॉट =' + केस स्नैपशॉट जब 1 फिर 'चालू' और 'बंद' अंत + ',' + बैच + '(ऑप्स x पंक्तियाँ)', best10 =ROW_NUMBER () ओवर (अवधि के अनुसार ऑर्डर), सबसे खराब 10 =ROW_NUMBER () ओवर (अवधि डीईएससी द्वारा ऑर्डर), स्रोत से अवधि) जीआरपी चुनें, लेबल, अवधि से चुनें (शीर्ष चुनें (20) जीआरपी ='सर्वश्रेष्ठ ', लेबल =राइट ('0' + आरटीआरआईएम (बेस्ट 10), 2) + '।' + लेबल, अवधि एजीजी से जहां सबसे अच्छा 10 <=10 सर्वश्रेष्ठ 10 डीईएससी यूनियन द्वारा ऑर्डर करें सभी चुनें टॉप (20) जीआरपी ='सबसे खराब', लेबल =राइट ('0' + आरटीआरआईएम (सबसे खराब 10), 2) + '। ' + लेबल, एजीजी से अवधि जहां सबसे खराब10 <=10 सबसे खराब 10 डीईएससी द्वारा आदेश) जीआरपी द्वारा आदेश के अनुसार;ग्राफ 4 - लॉग डिस्क प्रकार, सिंगलटन इंसर्ट्स
; एक्स एएस के साथ (ट्रिगर टाइप, विफलता दर, लॉगलोकेशन =राइट (डिस्कलाउट, 3), अवधि =एवीजी (अवधि * 1.0) डीबीओ से। टेस्ट परिणाम टीआर इनर जॉइन डीबीओ के रूप में। टेस्ट के रूप में टी पर टेस्ट। टेस्टिड =टी। टेस्टिड इनर जॉइन dbo.Loops as l ON l.LoopID =tr.LoopID जहां l.loops =20000 ग्रुप बाय राइट (डिस्कलाउट, 3), विफलता दर, ट्रिगर टाइप) ट्रिगर टाइप, विफलता दर, एचडीडी अवधि =MAX (केस जब लॉगलोकेशन ='एचडीडी ' तब अवधि END), SSDDuration =MAX (केस जब LogLocation ='SSD' तब अवधि END) X GROUP BY TriggerType, FailureRateORDER by TriggerType, FailureRate;