समय-समय पर मैं देखता हूं कि कोई कुंजी के लिए यादृच्छिक संख्या बनाने की आवश्यकता व्यक्त करता है। आमतौर पर यह कुछ प्रकार के सरोगेट CustomerID या UserID बनाने के लिए होता है जो कुछ सीमा के भीतर एक अद्वितीय संख्या होती है, लेकिन क्रमिक रूप से जारी नहीं की जाती है, और इसलिए IDENTITY की तुलना में बहुत कम अनुमान लगाया जा सकता है मूल्य।
NEWID() अनुमान लगाने के मुद्दे को हल करता है, लेकिन प्रदर्शन दंड आमतौर पर एक डील-ब्रेकर होता है, खासकर जब क्लस्टर किया जाता है:पूर्णांक की तुलना में बहुत व्यापक कुंजी, और गैर-अनुक्रमिक मानों के कारण पृष्ठ विभाजित होता है। NEWSEQUENTIALID() पृष्ठ विभाजन समस्या को हल करता है, लेकिन यह अभी भी एक बहुत विस्तृत कुंजी है, और इस मुद्दे को फिर से प्रस्तुत करता है कि आप कुछ स्तर की सटीकता के साथ अगले मान (या हाल ही में जारी किए गए मान) का अनुमान लगा सकते हैं।
परिणामस्वरूप, वे एक ऐसी तकनीक चाहते हैं जो यादृच्छिक और उत्पन्न करे अद्वितीय पूर्णांक। RAND() . जैसी विधियों का उपयोग करके, अपने आप एक यादृच्छिक संख्या उत्पन्न करना मुश्किल नहीं है या CHECKSUM(NEWID()) . समस्या तब आती है जब आपको टकराव का पता लगाना होता है। आइए एक सामान्य दृष्टिकोण पर एक त्वरित नज़र डालें, यह मानते हुए कि हम 1 और 1,000,000 के बीच CustomerID मान चाहते हैं:
DECLARE @rc INT = 0,
@CustomerID INT = ABS(CHECKSUM(NEWID())) % 1000000 + 1;
-- or ABS(CONVERT(INT,CRYPT_GEN_RANDOM(3))) % 1000000 + 1;
-- or CONVERT(INT, RAND() * 1000000) + 1;
WHILE @rc = 0
BEGIN
IF NOT EXISTS (SELECT 1 FROM dbo.Customers WHERE CustomerID = @CustomerID)
BEGIN
INSERT dbo.Customers(CustomerID) SELECT @CustomerID;
SET @rc = 1;
END
ELSE
BEGIN
SELECT @CustomerID = ABS(CHECKSUM(NEWID())) % 1000000 + 1,
@rc = 0;
END
END जैसे-जैसे तालिका बड़ी होती जाती है, न केवल डुप्लिकेट की जाँच करना अधिक महंगा होता जाता है, बल्कि डुप्लिकेट उत्पन्न करने की आपकी संभावना भी बढ़ जाती है। तो तालिका के छोटे होने पर यह दृष्टिकोण ठीक काम करता प्रतीत हो सकता है, लेकिन मुझे संदेह है कि यह समय के साथ अधिक से अधिक चोट पहुंचाएगा।
एक अलग तरीका
मैं सहायक तालिकाओं का बहुत बड़ा प्रशंसक हूं; मैं एक दशक से कैलेंडर तालिकाओं और संख्याओं की तालिकाओं के बारे में सार्वजनिक रूप से लिख रहा हूं, और उनका उपयोग लंबे समय से कर रहा हूं। और यह एक ऐसा मामला है जहां मुझे लगता है कि एक पूर्व-आबादी वाली तालिका वास्तविक काम में आ सकती है। रनटाइम पर रैंडम नंबर जेनरेट करने और संभावित डुप्लीकेट्स से निपटने पर भरोसा क्यों करें, जब आप उन सभी मानों को पहले से पॉप्युलेट कर सकते हैं और जान सकते हैं - 100% निश्चितता के साथ, यदि आप अनधिकृत डीएमएल से अपनी टेबल की रक्षा करते हैं - कि आपके द्वारा चुना गया अगला मान कभी नहीं रहा है पहले इस्तेमाल किया?
CREATE TABLE dbo.RandomNumbers1
(
RowID INT,
Value INT, --UNIQUE,
PRIMARY KEY (RowID, Value)
);
;WITH x AS
(
SELECT TOP (1000000) s1.[object_id]
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
ORDER BY s1.[object_id]
)
INSERT dbo.RandomNumbers(RowID, Value)
SELECT
r = ROW_NUMBER() OVER (ORDER BY [object_id]),
n = ROW_NUMBER() OVER (ORDER BY NEWID())
FROM x
ORDER BY r; इस आबादी को (लैपटॉप पर वीएम में) बनाने में 9 सेकंड का समय लगा, और डिस्क पर लगभग 17 एमबी का कब्जा कर लिया। तालिका में डेटा इस तरह दिखता है:
(यदि हम इस बारे में चिंतित थे कि संख्याएँ कैसे पॉप्युलेट हो रही हैं, तो हम मान कॉलम पर एक अद्वितीय बाधा जोड़ सकते हैं, जिससे तालिका 30 एमबी हो जाएगी। यदि हमने पृष्ठ संपीड़न लागू किया होता, तो यह क्रमशः 11 एमबी या 25 एमबी होता। )
मैंने तालिका की एक और प्रतिलिपि बनाई, और इसे समान मानों से भर दिया, ताकि मैं अगला मान प्राप्त करने के दो अलग-अलग तरीकों का परीक्षण कर सकूं:
CREATE TABLE dbo.RandomNumbers2 ( RowID INT, Value INT, -- UNIQUE PRIMARY KEY (RowID, Value) ); INSERT dbo.RandomNumbers2(RowID, Value) SELECT RowID, Value FROM dbo.RandomNumbers1;
अब, जब भी हम एक नया यादृच्छिक संख्या चाहते हैं, हम मौजूदा संख्याओं के ढेर से केवल एक को पॉप कर सकते हैं, और इसे हटा सकते हैं। यह हमें डुप्लिकेट के बारे में चिंता करने से रोकता है, और हमें संख्याओं को खींचने की अनुमति देता है - एक क्लस्टर इंडेक्स का उपयोग करके - जो वास्तव में पहले से ही यादृच्छिक क्रम में हैं। (सख्ती से कहें तो, हमें हटाने . की जरूरत नहीं है संख्याएँ जैसे हम उनका उपयोग करते हैं; हम यह इंगित करने के लिए एक कॉलम जोड़ सकते हैं कि क्या एक मूल्य का उपयोग किया गया है - इससे उस मूल्य को बहाल करना और पुन:उपयोग करना आसान हो जाएगा, जब ग्राहक बाद में हटा दिया जाता है या इस लेनदेन के बाहर कुछ गलत हो जाता है, लेकिन पूरी तरह से बनने से पहले।)
DECLARE @holding TABLE(CustomerID INT);
DELETE TOP (1) dbo.RandomNumbers1
OUTPUT deleted.Value INTO @holding;
INSERT dbo.Customers(CustomerID, ...other columns...)
SELECT CustomerID, ...other params...
FROM @holding;
मैंने इंटरमीडिएट आउटपुट को होल्ड करने के लिए एक टेबल वेरिएबल का उपयोग किया, क्योंकि कंपोजेबल डीएमएल के साथ कई सीमाएँ हैं जो सीधे DELETE से ग्राहक तालिका में सम्मिलित करना असंभव बना सकती हैं। (उदाहरण के लिए, विदेशी कुंजियों की उपस्थिति)। फिर भी, यह स्वीकार करते हुए कि यह हमेशा संभव नहीं होगा, मैं भी इस पद्धति का परीक्षण करना चाहता था:
DELETE TOP (1) dbo.RandomNumbers2 OUTPUT deleted.Value, ...other params... INTO dbo.Customers(CustomerID, ...other columns...);
ध्यान दें कि इनमें से कोई भी समाधान वास्तव में यादृच्छिक क्रम की गारंटी नहीं देता है, खासकर यदि यादृच्छिक संख्या तालिका में अन्य अनुक्रमणिकाएं हैं (जैसे मान कॉलम पर एक अद्वितीय अनुक्रमणिका)। DELETE . के लिए ऑर्डर को परिभाषित करने का कोई तरीका नहीं है TOP का उपयोग कर रहे हैं; दस्तावेज़ीकरण से:
इसलिए, यदि आप रैंडम ऑर्डरिंग की गारंटी देना चाहते हैं, तो आप इसके बजाय कुछ ऐसा कर सकते हैं:
DECLARE @holding TABLE(CustomerID INT);
;WITH x AS
(
SELECT TOP (1) Value
FROM dbo.RandomNumbers2
ORDER BY RowID
)
DELETE x OUTPUT deleted.Value INTO @holding;
INSERT dbo.Customers(CustomerID, ...other columns...)
SELECT CustomerID, ...other params...
FROM @holding; यहां एक और विचार यह है कि, इन परीक्षणों के लिए, ग्राहक तालिका में CustomerID कॉलम पर एक संकुल प्राथमिक कुंजी होती है; जब आप यादृच्छिक मान डालते हैं तो यह निश्चित रूप से पृष्ठ विभाजन की ओर ले जाएगा। वास्तविक दुनिया में, यदि आपके पास यह आवश्यकता होती, तो आप शायद एक अलग कॉलम पर क्लस्टरिंग समाप्त कर देते।
ध्यान दें कि मैंने यहां लेन-देन और त्रुटि प्रबंधन को भी छोड़ दिया है, लेकिन ये भी उत्पादन कोड के लिए एक विचार होना चाहिए।
प्रदर्शन परीक्षण
कुछ यथार्थवादी प्रदर्शन तुलनाओं को आकर्षित करने के लिए, मैंने निम्नलिखित परिदृश्यों (परीक्षण गति, वितरण, और विभिन्न यादृच्छिक तरीकों की टक्कर आवृत्ति, साथ ही यादृच्छिक संख्याओं की पूर्वनिर्धारित तालिका का उपयोग करने की गति) का प्रतिनिधित्व करते हुए पांच संग्रहीत कार्यविधियाँ बनाईं:
CHECKSUM(NEWID())using का उपयोग करके रनटाइम जनरेशनCRYPT_GEN_RANDOM()का उपयोग करके रनटाइम जनरेशनRAND()का उपयोग करके रनटाइम जनरेशन- तालिका चर के साथ पूर्वनिर्धारित संख्या तालिका
- प्रत्यक्ष सम्मिलित के साथ पूर्वनिर्धारित संख्या तालिका
वे अवधि और टक्करों की संख्या को ट्रैक करने के लिए एक लॉगिंग टेबल का उपयोग करते हैं:
CREATE TABLE dbo.CustomerLog ( LogID INT IDENTITY(1,1) PRIMARY KEY, pid INT, collisions INT, duration INT -- microseconds );
प्रक्रियाओं के लिए कोड इस प्रकार है (दिखाने/छिपाने के लिए क्लिक करें):
/* Runtime using CHECKSUM(NEWID()) */
CREATE PROCEDURE [dbo].[AddCustomer_Runtime_Checksum]
AS
BEGIN
SET NOCOUNT ON;
DECLARE
@start DATETIME2(7) = SYSDATETIME(),
@duration INT,
@CustomerID INT = ABS(CHECKSUM(NEWID())) % 1000000 + 1,
@collisions INT = 0,
@rc INT = 0;
WHILE @rc = 0
BEGIN
IF NOT EXISTS
(
SELECT 1 FROM dbo.Customers_Runtime_Checksum
WHERE CustomerID = @CustomerID
)
BEGIN
INSERT dbo.Customers_Runtime_Checksum(CustomerID) SELECT @CustomerID;
SET @rc = 1;
END
ELSE
BEGIN
SELECT
@CustomerID = ABS(CHECKSUM(NEWID())) % 1000000 + 1,
@collisions += 1,
@rc = 0;
END
END
SELECT @duration = DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME()));
INSERT dbo.CustomerLog(pid, collisions, duration) SELECT 1, @collisions, @duration;
END
GO
/* runtime using CRYPT_GEN_RANDOM() */
CREATE PROCEDURE [dbo].[AddCustomer_Runtime_CryptGen]
AS
BEGIN
SET NOCOUNT ON;
DECLARE
@start DATETIME2(7) = SYSDATETIME(),
@duration INT,
@CustomerID INT = ABS(CONVERT(INT,CRYPT_GEN_RANDOM(3))) % 1000000 + 1,
@collisions INT = 0,
@rc INT = 0;
WHILE @rc = 0
BEGIN
IF NOT EXISTS
(
SELECT 1 FROM dbo.Customers_Runtime_CryptGen
WHERE CustomerID = @CustomerID
)
BEGIN
INSERT dbo.Customers_Runtime_CryptGen(CustomerID) SELECT @CustomerID;
SET @rc = 1;
END
ELSE
BEGIN
SELECT
@CustomerID = ABS(CONVERT(INT,CRYPT_GEN_RANDOM(3))) % 1000000 + 1,
@collisions += 1,
@rc = 0;
END
END
SELECT @duration = DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME()));
INSERT dbo.CustomerLog(pid, collisions, duration) SELECT 2, @collisions, @duration;
END
GO
/* runtime using RAND() */
CREATE PROCEDURE [dbo].[AddCustomer_Runtime_Rand]
AS
BEGIN
SET NOCOUNT ON;
DECLARE
@start DATETIME2(7) = SYSDATETIME(),
@duration INT,
@CustomerID INT = CONVERT(INT, RAND() * 1000000) + 1,
@collisions INT = 0,
@rc INT = 0;
WHILE @rc = 0
BEGIN
IF NOT EXISTS
(
SELECT 1 FROM dbo.Customers_Runtime_Rand
WHERE CustomerID = @CustomerID
)
BEGIN
INSERT dbo.Customers_Runtime_Rand(CustomerID) SELECT @CustomerID;
SET @rc = 1;
END
ELSE
BEGIN
SELECT
@CustomerID = CONVERT(INT, RAND() * 1000000) + 1,
@collisions += 1,
@rc = 0;
END
END
SELECT @duration = DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME()));
INSERT dbo.CustomerLog(pid, collisions, duration) SELECT 3, @collisions, @duration;
END
GO
/* pre-defined using a table variable */
CREATE PROCEDURE [dbo].[AddCustomer_Predefined_TableVariable]
AS
BEGIN
SET NOCOUNT ON;
DECLARE @start DATETIME2(7) = SYSDATETIME(), @duration INT;
DECLARE @holding TABLE(CustomerID INT);
DELETE TOP (1) dbo.RandomNumbers1
OUTPUT deleted.Value INTO @holding;
INSERT dbo.Customers_Predefined_TableVariable(CustomerID)
SELECT CustomerID FROM @holding;
SELECT @duration = DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME()));
INSERT dbo.CustomerLog(pid, duration) SELECT 4, @duration;
END
GO
/* pre-defined using a direct insert */
CREATE PROCEDURE [dbo].[AddCustomer_Predefined_Direct]
AS
BEGIN
SET NOCOUNT ON;
DECLARE @start DATETIME2(7) = SYSDATETIME(), @duration INT;
DELETE TOP (1) dbo.RandomNumbers2
OUTPUT deleted.Value INTO dbo.Customers_Predefined_Direct;
SELECT @duration = DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME()));
INSERT dbo.CustomerLog(pid, duration) SELECT 5, @duration;
END
GO और इसका परीक्षण करने के लिए, मैं प्रत्येक संग्रहीत कार्यविधि को 1,000,000 बार चलाऊंगा:
EXEC dbo.AddCustomer_Runtime_Checksum; EXEC dbo.AddCustomer_Runtime_CryptGen; EXEC dbo.AddCustomer_Runtime_Rand; EXEC dbo.AddCustomer_Predefined_TableVariable; EXEC dbo.AddCustomer_Predefined_Direct; GO 1000000
आश्चर्य की बात नहीं है, यादृच्छिक संख्याओं की पूर्वनिर्धारित तालिका का उपयोग करने के तरीकों में * परीक्षण की शुरुआत में * थोड़ा अधिक समय लगा, क्योंकि उन्हें हर बार I/O पढ़ना और लिखना दोनों करना पड़ता था। यह ध्यान में रखते हुए कि ये संख्याएं माइक्रोसेकंड . में हैं , यहां प्रत्येक प्रक्रिया के लिए अलग-अलग अंतरालों पर औसत अवधियां दी गई हैं (औसतन पहले 10,000 निष्पादन, मध्य 10,000 निष्पादन, अंतिम 10,000 निष्पादन, और अंतिम 1,000 निष्पादन):
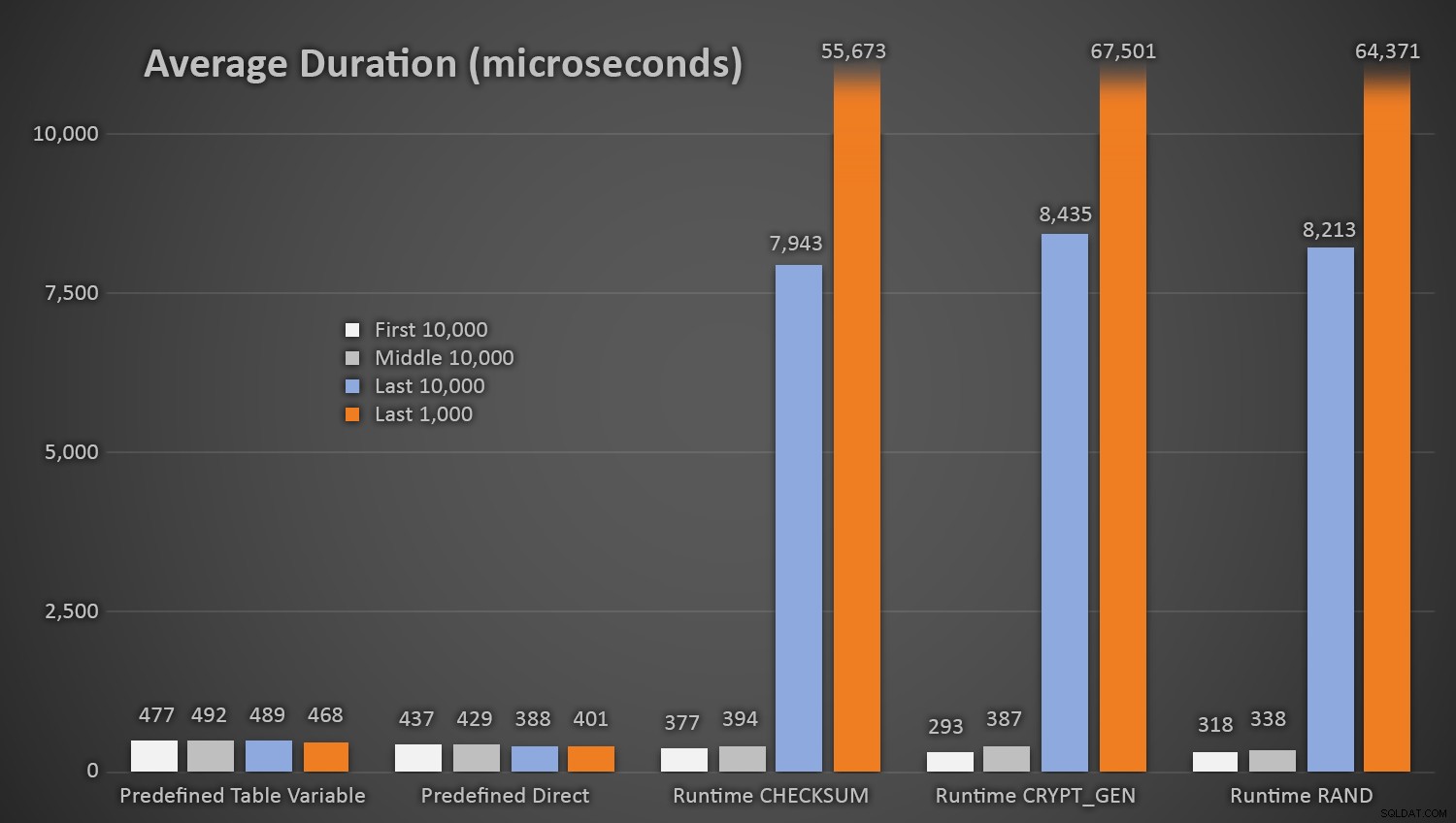
विभिन्न दृष्टिकोणों का उपयोग करके यादृच्छिक पीढ़ी की औसत अवधि (माइक्रोसेकंड में)
जब ग्राहक तालिका में कुछ पंक्तियाँ होती हैं, तो यह सभी विधियों के लिए अच्छी तरह से काम करता है, लेकिन जैसे-जैसे तालिका बड़ी और बड़ी होती जाती है, रनटाइम विधियों का उपयोग करके मौजूदा डेटा के विरुद्ध नई यादृच्छिक संख्या की जाँच करने की लागत काफी बढ़ जाती है, दोनों में वृद्धि के कारण I /ओ और इसलिए भी कि टकराव की संख्या बढ़ जाती है (आपको फिर से प्रयास करने के लिए मजबूर करना)। औसत अवधि की तुलना करें जब टक्कर की निम्न श्रेणियों में गणना की जाती है (और याद रखें कि यह पैटर्न केवल रनटाइम विधियों को प्रभावित करता है):
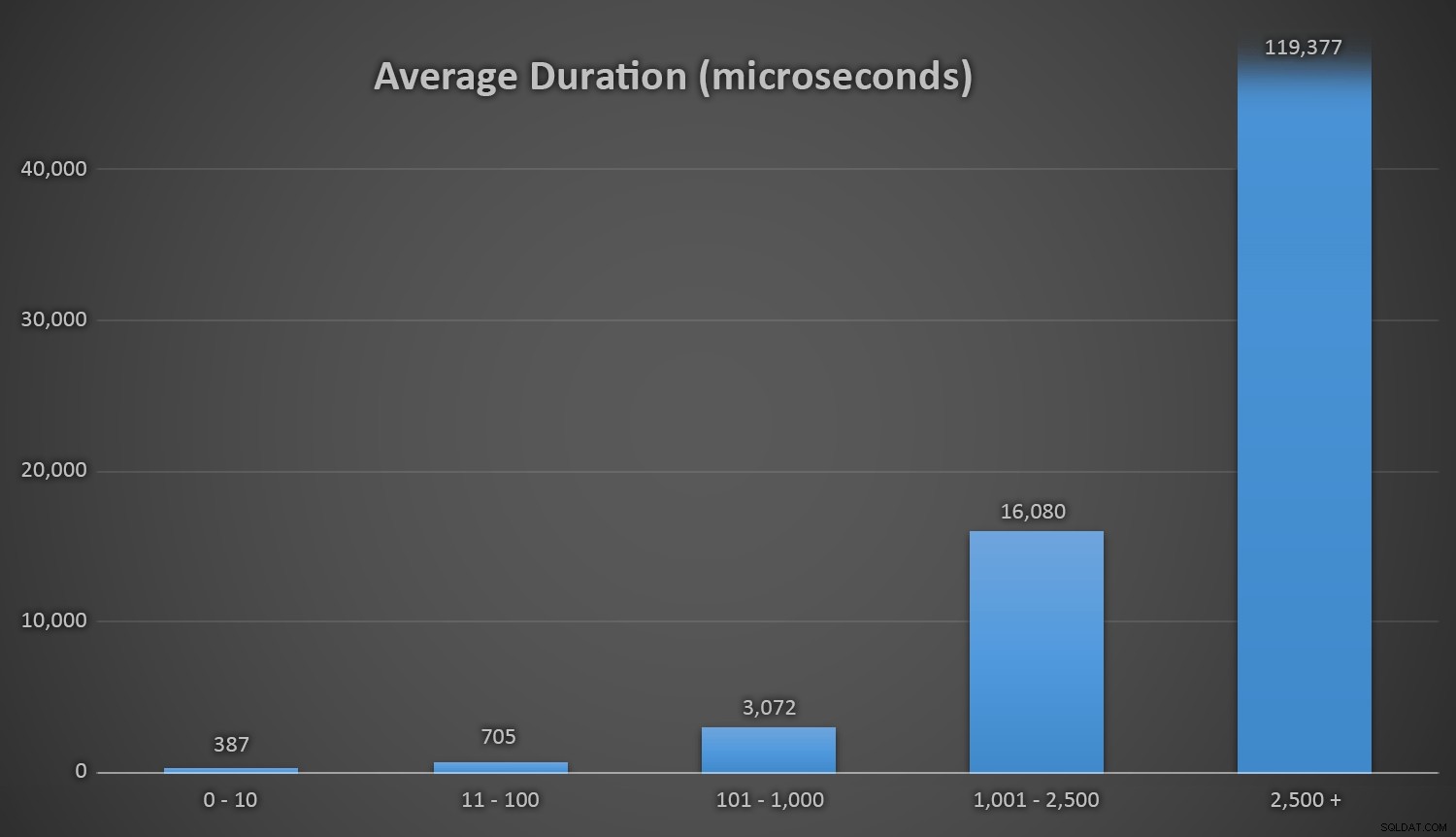
संघर्षों की विभिन्न श्रेणियों के दौरान औसत अवधि (माइक्रोसेकंड में) उन्हें>
मेरी इच्छा है कि टकराव की गणना के खिलाफ अवधि ग्राफ करने का एक आसान तरीका था। मैं आपको इस जानकारी के साथ छोड़ दूँगा:पिछले तीन इंसर्ट पर, निम्नलिखित रनटाइम विधियों को इतने प्रयास करने पड़े, इससे पहले कि वे अंततः उस अंतिम अद्वितीय आईडी पर ठोकर खाएँ, जिसकी वे तलाश कर रहे थे, और इसमें कितना समय लगा:
| टकरावों की संख्या | अवधि (माइक्रोसेकंड) | ||
|---|---|---|---|
| CHECKSUM(NEWID()) | तीसरी से अंतिम पंक्ति | 63,545 | 639,358 |
| दूसरी से अंतिम पंक्ति | 164,807 | 1,605,695 | |
| अंतिम पंक्ति | 30,630 | 296,207 | |
| CRYPT_GEN_RANDOM() | तीसरी से अंतिम पंक्ति | 219,766 | 2,229,166 |
| दूसरी से अंतिम पंक्ति | 255,463 | 2,681,468 | |
| अंतिम पंक्ति | 136,342 | 1,434,725 | |
| RAND() | तीसरी से अंतिम पंक्ति | 129,764 | 1,215,994 |
| दूसरी से अंतिम पंक्ति | 220,195 | 2,088,992 | |
| अंतिम पंक्ति | 440,765 | 4,161,925 |
अत्यधिक अवधि और पंक्ति के अंत के निकट टकराव
यह ध्यान रखना दिलचस्प है कि अंतिम पंक्ति हमेशा वह नहीं होती है जो सबसे अधिक संख्या में टकराव उत्पन्न करती है, इसलिए 999,000+ मानों का उपयोग करने से बहुत पहले यह एक वास्तविक समस्या हो सकती है।
एक और विचार
जब RandomNumbers तालिका कुछ पंक्तियों से नीचे आने लगती है, तो आप किसी प्रकार की चेतावनी या अधिसूचना सेट करने पर विचार कर सकते हैं (जिस बिंदु पर आप तालिका को 1,000,001 – 2,000,000 से एक नए सेट के साथ फिर से पॉप्युलेट कर सकते हैं, उदाहरण के लिए)। आपको कुछ ऐसा ही करना होगा यदि आप फ़्लाई पर यादृच्छिक संख्याएँ उत्पन्न कर रहे थे - यदि आप इसे 1 - 1,000,000 की सीमा के भीतर रखते हैं, तो आपको एक बार एक अलग श्रेणी से संख्याएँ उत्पन्न करने के लिए कोड बदलना होगा। उन सभी मूल्यों का उपयोग किया है।
यदि आप रनटाइम विधि पर यादृच्छिक संख्या का उपयोग कर रहे हैं, तो आप पूल के आकार को लगातार बदलकर इस स्थिति से बच सकते हैं जिससे आप एक यादृच्छिक संख्या खींचते हैं (जो कि टकराव की संख्या को स्थिर और काफी कम करना चाहिए)। उदाहरण के लिए, इसके बजाय:
DECLARE @CustomerID INT = ABS(CHECKSUM(NEWID())) % 1000000 + 1;
आप तालिका में पहले से मौजूद पंक्तियों की संख्या के आधार पर पूल को आधार बना सकते हैं:
DECLARE @total INT = 1000000 + ISNULL(
(SELECT SUM(row_count) FROM sys.dm_db_partition_stats
WHERE [object_id] = OBJECT_ID('dbo.Customers') AND index_id = 1),0);
अब आपकी एकमात्र वास्तविक चिंता यह है कि जब आप INT . के लिए ऊपरी सीमा पर पहुंचते हैं …
नोट:मैंने हाल ही में MSSQLTips.com पर इस बारे में एक टिप भी लिखी है।