एकल विधेय
एकल क्वेरी विधेय द्वारा योग्य पंक्तियों की संख्या का अनुमान लगाना अक्सर सीधा होता है। जब एक विधेय एक स्तंभ और एक अदिश मान के बीच एक सरल तुलना करता है, तो संभावना अच्छी होती है कि कार्डिनैलिटी अनुमानक सांख्यिकी हिस्टोग्राम से एक अच्छी गुणवत्ता का अनुमान प्राप्त करने में सक्षम होंगे। उदाहरण के लिए, निम्नलिखित एडवेंचरवर्क्स क्वेरी 203 पंक्तियों का बिल्कुल सही अनुमान उत्पन्न करती है (यह मानते हुए कि आंकड़ों के निर्माण के बाद से डेटा में कोई बदलाव नहीं किया गया है):
SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.TransactionDate = '20070903';
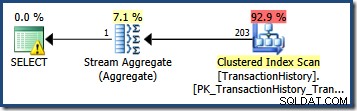
TransactionDate . के लिए सांख्यिकी हिस्टोग्राम को देखते हुए कॉलम, यह देखना स्पष्ट है कि यह अनुमान कहां से आया:
DBCC SHOW_STATISTICS (
'Production.TransactionHistory',
'TransactionDate')
WITH HISTOGRAM;
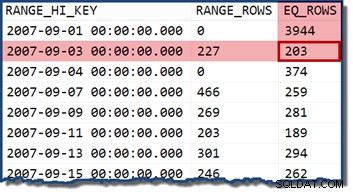
यदि हम हिस्टोग्राम बकेट के भीतर आने वाली तारीख को निर्दिष्ट करने के लिए क्वेरी बदलते हैं, तो कार्डिनैलिटी अनुमानक मान लेता है कि मान समान रूप से वितरित हैं। 2007-09-02 की तारीख का उपयोग करना 227 पंक्तियों का अनुमान उत्पन्न करता है (RANGE_ROWS . से) प्रवेश)। एक दिलचस्प साइड-नोट के रूप में, अनुमान 227 पंक्तियों पर बना रहता है, चाहे हम किसी भी समय भाग को दिनांक मान (TransactionDate) में जोड़ दें। कॉलम एक datetime है डेटा प्रकार)।
अगर हम 2007-09-05 . की तारीख के साथ फिर से क्वेरी का प्रयास करते हैं या 2007-09-06 (दोनों 2007-09-04 . के बीच आते हैं और 2007-09-07 हिस्टोग्राम चरण), कार्डिनैलिटी अनुमानक 466 RANGE_ROWS मानता है दोनों मामलों में 233 पंक्तियों का अनुमान लगाते हुए, दो मानों के बीच समान रूप से विभाजित हैं।
सरल विधेय के लिए कार्डिनैलिटी अनुमान के कई अन्य विवरण हैं, लेकिन पूर्वगामी हमारे वर्तमान उद्देश्यों के लिए एक पुनश्चर्या के रूप में काम करेगा।
एकाधिक विधेय की समस्याएं
जब किसी क्वेरी में एक से अधिक कॉलम विधेय होते हैं, तो कार्डिनैलिटी का अनुमान अधिक कठिन हो जाता है। दो सरल विधेय के साथ निम्नलिखित प्रश्न पर विचार करें (जिनमें से प्रत्येक का अकेले अनुमान लगाना आसान है):
SELECT
COUNT_BIG(*)
FROM Production.TransactionHistory AS TH
WHERE
TH.TransactionID BETWEEN 100000 AND 168412
AND TH.TransactionDate BETWEEN '20070901' AND '20080313'; क्वेरी में मानों की विशिष्ट श्रेणियों को जानबूझकर चुना जाता है ताकि दोनों विधेय बिल्कुल समान पंक्तियों की पहचान करें। हम किसी भी प्रकार के ओवरलैप के परिणामस्वरूप क्वेरी मानों को आसानी से संशोधित कर सकते हैं, जिसमें कोई ओवरलैप नहीं है। अब कल्पना करें कि आप कार्डिनैलिटी अनुमानक हैं:आप इस क्वेरी के लिए कार्डिनैलिटी अनुमान कैसे प्राप्त करेंगे?
समस्या पहली ध्वनि की तुलना में कठिन है। डिफ़ॉल्ट रूप से, SQL सर्वर स्वचालित रूप से दोनों विधेय स्तंभों पर एकल-स्तंभ आँकड़े बनाता है। हम मैन्युअल रूप से बहु-स्तंभ आँकड़े भी बना सकते हैं। क्या यह हमें इन विशिष्ट मूल्यों के लिए एक अच्छा अनुमान तैयार करने के लिए पर्याप्त जानकारी देता है? उस अधिक सामान्य मामले के बारे में क्या जहां कोई . हो सकता है ओवरलैप की डिग्री?
दो एकल-स्तंभ सांख्यिकीय वस्तुओं का उपयोग करके, हम पिछले अनुभाग में वर्णित हिस्टोग्राम पद्धति का उपयोग करके प्रत्येक विधेय के लिए आसानी से एक अनुमान प्राप्त कर सकते हैं। उपरोक्त क्वेरी में विशिष्ट मानों के लिए, हिस्टोग्राम दिखाते हैं कि TransactionID श्रेणी 68412.4 . से मेल खाने की उम्मीद है पंक्तियाँ, और TransactionDate रेंज 68,413 . से मेल खाने की उम्मीद है पंक्तियाँ। (यदि हिस्टोग्राम परिपूर्ण होते, तो ये दोनों संख्याएँ बिल्कुल समान होतीं।)
हिस्टोग्राम क्या नहीं कर सकते हमें बताएं कि पंक्तियों के इन दो सेटों में से कितने समान पंक्तियाँ होंगे . हिस्टोग्राम जानकारी के आधार पर हम केवल इतना कह सकते हैं कि हमारा अनुमान शून्य (बिना किसी ओवरलैप के) और 68412.4 पंक्तियों (पूर्ण ओवरलैप) के बीच कहीं होना चाहिए।
बहु-स्तंभ आँकड़े बनाने से इस क्वेरी (या सामान्य रूप से श्रेणी प्रश्नों के लिए) के लिए कोई सहायता नहीं मिलती है। बहु-स्तंभ आंकड़े अभी भी केवल पहले नामित कॉलम पर एक हिस्टोग्राम बनाते हैं, अनिवार्य रूप से स्वचालित रूप से बनाए गए आंकड़ों में से एक से जुड़े हिस्टोग्राम को डुप्लिकेट करते हैं। अतिरिक्त घनत्व बहु-स्तंभ आंकड़ों द्वारा प्रदान की गई जानकारी उन प्रश्नों के लिए औसत-मामले की जानकारी प्रदान करने के लिए उपयोगी हो सकती है जिनमें एकाधिक समानता विधेय शामिल हैं, लेकिन वे यहां हमारे लिए कोई मदद नहीं हैं।
उच्च स्तर के विश्वास के साथ एक अनुमान तैयार करने के लिए, हमें डेटा वितरण के बारे में बेहतर जानकारी प्रदान करने के लिए SQL सर्वर की आवश्यकता होगी - एक बहु-आयामी जैसा कुछ सांख्यिकी हिस्टोग्राम। जहां तक मुझे पता है, कोई भी वाणिज्यिक डेटाबेस इंजन वर्तमान में इस तरह की सुविधा प्रदान नहीं करता है, हालांकि इस विषय पर कई तकनीकी पत्र प्रकाशित किए गए हैं (एक Microsoft अनुसंधान सहित जो SQL Server 2000 के आंतरिक विकास का उपयोग करता है)।
विशेष मूल्य श्रेणियों के लिए डेटा सहसंबंधों और ओवरलैप के बारे में कुछ भी जाने बिना, यह स्पष्ट नहीं है कि हमें अपनी क्वेरी के लिए एक अच्छा अनुमान कैसे तैयार करना चाहिए। तो, SQL सर्वर यहाँ क्या करता है?
एसक्यूएल सर्वर 7 - 2012
SQL सर्वर के इन संस्करणों में कार्डिनैलिटी अनुमानक आम तौर पर मानता है कि तालिका में विभिन्न विशेषताओं के मान एक दूसरे से पूरी तरह से स्वतंत्र रूप से वितरित किए जाते हैं। यह स्वतंत्रता धारणा शायद ही कभी वास्तविक डेटा का सटीक प्रतिबिंब होता है, लेकिन इसमें सरल गणना करने का लाभ होता है।
और चयनात्मकता
स्वतंत्रता धारणा का उपयोग करते हुए, दो विधेय AND . द्वारा जुड़े हुए हैं (संयोजन . के रूप में जाना जाता है) ) चुनिंदा S1 . के साथ और एस<उप>2 , इसके परिणामस्वरूप संयुक्त चयनात्मकता होती है:
(S1 * S2)
यदि यह शब्द आपके लिए अपरिचित है, चयनात्मकता 0 और 1 के बीच की एक संख्या है, जो विधेय को पार करने वाली तालिका में पंक्तियों के अंश का प्रतिनिधित्व करती है। उदाहरण के लिए, यदि कोई विधेय 100 पंक्तियों की तालिका से 12 पंक्तियों का चयन करता है, तो चयनात्मकता (12/100) =0.12 है।
हमारे उदाहरण में, TransactionHistory तालिका में कुल 113,443 पंक्तियाँ हैं। TransactionID . पर विधेय अनुमानित (हिस्टोग्राम से) 68,412.4 पंक्तियों को अर्हता प्राप्त करने के लिए है, इसलिए चयनात्मकता (68,412.4 / 113,443) या मोटे तौर पर 0.603055 है . TransactionDate पर विधेय इसी तरह (68,413 / 113,443) की चयनात्मकता होने का अनुमान है =मोटे तौर पर 0.603061 ।
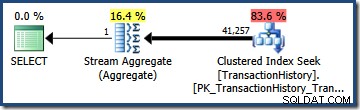
दो चयनों को गुणा करने पर (उपरोक्त सूत्र का उपयोग करके) 0.363679 का संयुक्त चयनात्मकता अनुमान देता है . इस चयनात्मकता को तालिका की कार्डिनैलिटी (113,443) से गुणा करने पर 41,256.8 का अंतिम अनुमान मिलता है पंक्तियाँ:
या चयनात्मकता
OR . द्वारा जुड़े दो विधेय (ए वियोजन ) चुनिंदा S1 . के साथ और एस<उप>2 , की संयुक्त चयनात्मकता में परिणाम:
(S1 + S2) – (S1 * S2)
सूत्र के पीछे अंतर्ज्ञान दो चयनात्मकताओं को जोड़ना है, फिर उनके संयोजन के लिए अनुमान घटाना (पिछले सूत्र का उपयोग करना)। स्पष्ट रूप से हमारे पास दो विधेय हो सकते हैं, प्रत्येक चयनात्मकता 0.8, लेकिन बस उन्हें एक साथ जोड़ने से 1.6 की एक असंभव संयुक्त चयनात्मकता उत्पन्न होगी। स्वतंत्रता की धारणा के बावजूद, हमें यह पहचानना चाहिए कि दो विधेय में ओवरलैप हो सकता है, इसलिए डबल-काउंटिंग से बचने के लिए, संयोजन की अनुमानित चयनात्मकता घटा दी जाती है।
हम OR . का उपयोग करने के लिए अपने चल रहे उदाहरण को आसानी से संशोधित कर सकते हैं :
SELECT COUNT_BIG(*)
FROM Production.TransactionHistory AS TH
WHERE
TH.TransactionID BETWEEN 100000 AND 168412
OR TH.TransactionDate BETWEEN '20070901' AND '20080313';
विधेय चयनों को OR . में प्रतिस्थापित करना सूत्र की संयुक्त चयनात्मकता देता है:
(0.603055 + 0.603061) - (0.603055 * 0.603061) = 0.842437
तालिका में पंक्तियों की संख्या से गुणा करने पर, यह चयनात्मकता हमें 95,568.6 का अंतिम कार्डिनैलिटी अनुमान देती है :
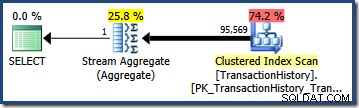
न तो अनुमान (41,257 AND . के लिए सवाल; 95,569 OR . के लिए query) विशेष रूप से अच्छा है क्योंकि दोनों एक मॉडलिंग धारणा पर आधारित हैं जो डेटा वितरण से बहुत अच्छी तरह मेल नहीं खाती है। दोनों प्रश्न वास्तव में 68,413 return लौटाते हैं पंक्तियाँ (क्योंकि विधेय बिल्कुल समान पंक्तियों की पहचान करते हैं)।
ट्रेस फ्लैग 4137 - न्यूनतम चयनात्मकता
SQL Server 2008 (R1) से 2012 तक के लिए, Microsoft ने एक फिक्स जारी किया है जो AND के लिए चयनात्मकता की गणना करने के तरीके को बदल देता है। केस (संयोजक विधेय) केवल। उस लिंक के नॉलेज बेस आलेख में बहुत सारे विवरण नहीं हैं, लेकिन यह पता चला है कि फिक्स उपयोग किए गए चयनात्मकता सूत्र को बदल देता है। अलग-अलग चयनात्मकताओं को गुणा करने के बजाय, संयोजक विधेय के लिए कार्डिनैलिटी अनुमान अब अकेले सबसे कम चयनात्मकता का उपयोग करता है।
बदले हुए व्यवहार को सक्रिय करने के लिए समर्थित ट्रेस फ्लैग 4137 की आवश्यकता है। एक अलग नॉलेज बेस आलेख दस्तावेज करता है कि यह ट्रेस ध्वज QUERYTRACEON के माध्यम से प्रति-क्वेरी उपयोग के लिए भी समर्थित है संकेत:
SELECT COUNT_BIG(*)
FROM Production.TransactionHistory AS TH
WHERE
TH.TransactionID BETWEEN 100000 AND 168412
AND TH.TransactionDate BETWEEN '20070901' AND '20080313'
OPTION (QUERYTRACEON 4137); इस ध्वज के सक्रिय होने के साथ, कार्डिनैलिटी अनुमान दो विधेय की न्यूनतम चयनात्मकता का उपयोग करता है, जिसके परिणामस्वरूप 68,412.4 का अनुमान होता है पंक्तियाँ:
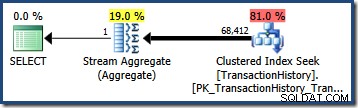
यह हमारी क्वेरी के लिए बिल्कुल सही होता है क्योंकि हमारे परीक्षण विधेय बिल्कुल सहसंबद्ध हैं (और आधार हिस्टोग्राम से प्राप्त अनुमान भी बहुत अच्छे हैं)।
विधेय के लिए वास्तविक डेटा के साथ इस तरह पूरी तरह से सहसंबद्ध होना यथोचित रूप से दुर्लभ है, लेकिन ट्रेस ध्वज फिर भी कुछ मामलों में मदद कर सकता है। ध्यान दें कि न्यूनतम चयनात्मकता व्यवहार सभी संयोजन पर लागू होगा (AND ) क्वेरी में विधेय करता है; व्यवहार को अधिक विस्तृत स्तर पर निर्दिष्ट करने का कोई तरीका नहीं है।
डिसजंक्टिव (OR .) का अनुमान लगाने के लिए कोई संगत ट्रेस फ़्लैग नहीं है ) न्यूनतम चयनात्मकता का उपयोग करके भविष्यवाणी करता है।
एसक्यूएल सर्वर 2014
SQL सर्वर 2014 में चयनात्मकता गणना पिछले संस्करणों के समान व्यवहार करती है (और ट्रेस फ़्लैग 4137 पहले की तरह काम करता है) यदि डेटाबेस संगतता स्तर 120 से कम सेट है, या यदि ट्रेस फ़्लैग 9481 सक्रिय है। डेटाबेस संगतता स्तर सेट करना आधिकारिक है SQL सर्वर 2014 में पूर्व-2014 कार्डिनैलिटी अनुमानक का उपयोग करने का तरीका। ट्रेस ध्वज 9481 लेखन के समय वही काम करने के लिए प्रभावी है, और QUERYTRACEON के साथ भी काम करता है। , हालांकि ऐसा करने के लिए इसका दस्तावेजीकरण नहीं किया गया है। इस ध्वज का RTM व्यवहार क्या होगा, यह जानने का कोई तरीका नहीं है।
यदि नया कार्डिनैलिटी एस्टीमेटर सक्रिय है, तो SQL Server 2014 कंजंक्टिव और डिसजंक्टिव विधेय के संयोजन के लिए एक अलग डिफ़ॉल्ट फॉर्मूला का उपयोग करता है। हालांकि अनिर्दिष्ट, संयोजनों के लिए चयनात्मकता सूत्र अब कई बार खोजा और प्रलेखित किया गया है। पहला जो मुझे याद है वह इस पुर्तगाली ब्लॉग पोस्ट में है और अनुवर्ती भाग दो कुछ हफ़्ते बाद जारी किया गया है। संक्षेप में, संयोजन विधेय के लिए 2014 का दृष्टिकोण घातीय बैकऑफ़: का उपयोग करना है कार्डिनैलिटी सी के साथ एक तालिका दी गई है, और चयनकर्ताओं की भविष्यवाणी करें एस1 , एस<उप>2 , एस<उप>3 ... एस<उप>एन , जहां एस1 सबसे चयनात्मक और Sn . है कम से कम:
Estimate = C * S1 * SQRT(S2) * SQRT(SQRT(S3)) * SQRT(SQRT(SQRT(S4))) …
अनुमान की गणना सबसे चयनात्मक विधेय को तालिका कार्डिनैलिटी से गुणा करके, अगले सबसे चयनात्मक विधेय के वर्गमूल से गुणा करके की जाती है, और इसी तरह प्रत्येक नई चयनात्मकता एक अतिरिक्त वर्गमूल प्राप्त करती है।
यह याद करते हुए कि चयनात्मकता 0 और 1 के बीच की संख्या है, यह स्पष्ट है कि वर्गमूल लगाने से संख्या 1 के करीब पहुंच जाती है। इसका प्रभाव अंतिम अनुमान में सभी विधेय को ध्यान में रखना है, लेकिन कम चयनात्मक विधेय के प्रभाव को कम करना है। घातीय रूप से। स्वतंत्रता धारणा . की तुलना में इस विचार के लिए तर्कसंगत रूप से अधिक तर्क है , लेकिन यह अभी भी एक निश्चित सूत्र है - यह डेटा सहसंबंध की वास्तविक डिग्री के आधार पर नहीं बदलता है।
2014 का कार्डिनैलिटी अनुमानक दोनों . के लिए घातांकीय बैकऑफ़ फ़ॉर्मूला का उपयोग करता है संयोजन और असंबद्ध विधेय, हालांकि असंबद्ध में प्रयुक्त सूत्र (OR ) मामला अभी तक दर्ज नहीं किया गया है (आधिकारिक तौर पर या अन्यथा)।
SQL सर्वर 2014 चयनात्मकता ट्रेस फ़्लैग्स
ट्रेस फ्लैग 4137 (न्यूनतम चयनात्मकता का उपयोग करने के लिए) नहीं . करता है SQL सर्वर 2014 में काम करते हैं, यदि किसी क्वेरी को संकलित करते समय नए कार्डिनैलिटी अनुमानक का उपयोग किया जाता है। इसके बजाय, एक नया ट्रेस फ़्लैग है 9471 . जब यह फ़्लैग सक्रिय होता है, तो न्यूनतम चयनात्मकता का उपयोग एकाधिक संयोजक और असंबद्ध का अनुमान लगाने के लिए किया जाता है भविष्यवाणी करता है। यह 4137 व्यवहार से एक बदलाव है, जो केवल संयोजन विधेय को प्रभावित करता है।
इसी तरह, ट्रेस फ्लैग 9472 स्वतंत्रता . मानने के लिए निर्दिष्ट किया जा सकता है कई विधेय के लिए, जैसा कि पिछले संस्करणों ने किया था। यह फ़्लैग 9481 से अलग है (2014 से पहले के कार्डिनैलिटी एस्टीमेटर का उपयोग करने के लिए) क्योंकि 9472 के तहत नए कार्डिनैलिटी एस्टिमेटर का अभी भी उपयोग किया जाएगा, एकाधिक विधेय के लिए केवल चयनात्मकता सूत्र प्रभावित होता है।
लेखन के समय न तो 9471 और न ही 9472 का दस्तावेजीकरण किया गया है (हालांकि वे आरटीएम पर हो सकते हैं)।
यह देखने का एक सुविधाजनक तरीका है कि SQL सर्वर 2014 (नए कार्डिनैलिटी अनुमानक सक्रिय के साथ) में कौन सी चयनात्मकता धारणा का उपयोग किया जा रहा है, ट्रेस फ़्लैग 2363 के दौरान उत्पन्न चयनात्मकता गणना डिबग आउटपुट की जांच करना है। और 3604 सक्रिय हैं। देखने के लिए अनुभाग चयनकर्ता कैलकुलेटर से संबंधित है जो फ़िल्टर को जोड़ता है, जहां आप निम्न में से एक देखेंगे, जिसके आधार पर किस धारणा का उपयोग किया जा रहा है:
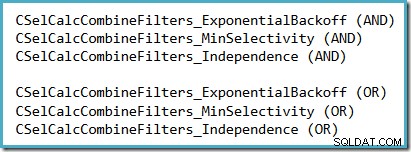
कोई वास्तविक संभावना नहीं है कि 2363 का दस्तावेजीकरण या समर्थन किया जाएगा।
अंतिम विचार
घातीय बैकऑफ़, न्यूनतम चयनात्मकता या स्वतंत्रता के बारे में कुछ भी जादू नहीं है। प्रत्येक दृष्टिकोण एक (बेहद) सरलीकृत धारणा का प्रतिनिधित्व करता है जो किसी विशेष क्वेरी या डेटा वितरण के लिए स्वीकार्य अनुमान उत्पन्न कर सकता है या नहीं भी कर सकता है।
कुछ मामलों में, घातीय बैकऑफ़ स्वतंत्रता . के दो चरम सीमाओं के बीच एक समझौते का प्रतिनिधित्व करता है और न्यूनतम चयनात्मकता . फिर भी, यह महत्वपूर्ण है कि उससे अनुचित अपेक्षाएँ न रखें। जब तक कई विधेय (उचित प्रदर्शन विशेषताओं के साथ) के लिए चयनात्मकता का अनुमान लगाने के लिए एक अधिक सटीक तरीका नहीं मिल जाता है, तब तक मॉडल की सीमाओं के बारे में पता होना और तदनुसार (संभावित) अनुमान त्रुटियों पर ध्यान देना महत्वपूर्ण है।
विभिन्न ट्रेस झंडे कुछ नियंत्रण प्रदान करते हैं जिस पर धारणा का उपयोग किया जाता है, लेकिन स्थिति एकदम सही नहीं है। एक बात के लिए, सबसे अच्छी ग्रैन्युलैरिटी जिस पर एक ध्वज लगाया जा सकता है, वह एक ही प्रश्न है - अनुमान व्यवहार को विधेय स्तर पर निर्दिष्ट नहीं किया जा सकता है। यदि आपके पास कोई प्रश्न है जहां कुछ विधेय सहसंबद्ध हैं और अन्य स्वतंत्र हैं, तो ट्रेस फ़्लैग एक तरह से या किसी अन्य तरीके से क्वेरी को फिर से तैयार किए बिना आपकी बहुत मदद नहीं कर सकते हैं। समान रूप से, एक समस्यात्मक क्वेरी में विधेय सहसंबंध हो सकते हैं जो उपलब्ध विकल्पों में से किसी के द्वारा अच्छी तरह से तैयार नहीं किए गए हैं।
ट्रेस फ़्लैग के तदर्थ उपयोग के लिए DBCC TRACEON . जैसी ही अनुमतियों की आवश्यकता होती है - अर्थात् sysadmin . व्यक्तिगत परीक्षण के लिए यह शायद ठीक है, लेकिन उत्पादन के लिए QUERYTRACEON का उपयोग करके एक योजना मार्गदर्शिका का उपयोग करें संकेत एक बेहतर विकल्प है। योजना मार्गदर्शिका के साथ, क्वेरी को निष्पादित करने के लिए किसी अतिरिक्त अनुमति की आवश्यकता नहीं होती है (हालांकि निश्चित रूप से योजना मार्गदर्शिका बनाने के लिए उन्नत अनुमतियों की आवश्यकता होती है)।