गैलेरा में शानदार सुविधाओं में से एक स्वचालित नोड प्रावधान और सदस्यता नियंत्रण है। यदि कोई नोड विफल हो जाता है या संचार खो देता है, तो यह स्वचालित रूप से क्लस्टर से बेदखल हो जाएगा और निष्क्रिय रहेगा। जब तक अधिकांश नोड्स अभी भी संचार कर रहे हैं (गैलेरा इस पीसी को प्राथमिक घटक कहते हैं), इस बात की बहुत अधिक संभावना है कि विफल नोड कनेक्टिविटी वापस आने के बाद स्वचालित रूप से फिर से जुड़ने, पुन:समन्वयित करने और प्रतिकृति को फिर से शुरू करने में सक्षम होगा।
आम तौर पर, सभी गैलेरा नोड्स समान होते हैं। गैलेरा समूह संचार और प्रमाणन-आधारित प्रतिकृति प्लगइन के लिए धन्यवाद, वे एक ही डेटा सेट और मास्टर्स के समान भूमिका रखते हैं, जो एक साथ पढ़ने और लिखने में सक्षम हैं। इसलिए, इस संतुलन के कारण डेटाबेस के दृष्टिकोण से वास्तव में कोई विफलता नहीं है। केवल उस एप्लिकेशन की ओर से जिसे क्लस्टर के विभाजन के दौरान गैर-ऑपरेशनल नोड्स को छोड़ने के लिए फ़ेलओवर की आवश्यकता होगी।
इस ब्लॉग पोस्ट में, हम यह समझने जा रहे हैं कि नेटवर्क विभाजन होने की स्थिति में गैलेरा क्लस्टर नोड और क्लस्टर रिकवरी कैसे करता है। एक साइड नोट के रूप में, हमने कुछ समय पहले इस ब्लॉग पोस्ट में इसी तरह के विषय को शामिल किया है। कोडरशिप ने गैलेरा की पुनर्प्राप्ति अवधारणा को दस्तावेज़ीकरण पृष्ठ, नोड विफलता और पुनर्प्राप्ति में बड़े विवरण में समझाया है।
नोड की विफलता और निष्कासन
पुनर्प्राप्ति को समझने के लिए, हमें यह समझना होगा कि गैलेरा पहले नोड की विफलता और निष्कासन प्रक्रिया का पता कैसे लगाता है। आइए इसे एक नियंत्रित परीक्षण परिदृश्य में रखें ताकि हम निष्कासन प्रक्रिया को बेहतर ढंग से समझ सकें। मान लीजिए कि हमारे पास तीन-नोड वाला गैलेरा क्लस्टर है, जैसा कि नीचे दिखाया गया है:
हमारे गैलेरा प्रदाता विकल्पों को पुनः प्राप्त करने के लिए निम्नलिखित कमांड का उपयोग किया जा सकता है:
mysql> SHOW VARIABLES LIKE 'wsrep_provider_options'\Gयह एक लंबी सूची है, लेकिन प्रक्रिया को समझाने के लिए हमें केवल कुछ मापदंडों पर ध्यान देने की आवश्यकता है:
evs.inactive_check_period = PT0.5S;
evs.inactive_timeout = PT15S;
evs.keepalive_period = PT1S;
evs.suspect_timeout = PT5S;
evs.view_forget_timeout = P1D;
gmcast.peer_timeout = PT3S;सबसे पहले, गैलेरा अवधि का प्रतिनिधित्व करने के लिए आईएसओ 8601 स्वरूपण का पालन करता है। P1D का अर्थ है कि अवधि एक दिन है, जबकि PT15S का अर्थ है कि अवधि 15 सेकंड है (ध्यान दें कि समय निर्दिष्टकर्ता, T, जो समय मान से पहले है)। उदाहरण के लिए यदि कोई evs.view_forget_timeout increase को बढ़ाना चाहता है डेढ़ दिन तक, कोई P1DT12H, या PT36H सेट करेगा।
यह देखते हुए कि सभी होस्ट किसी भी फ़ायरवॉल नियमों के साथ कॉन्फ़िगर नहीं किए गए हैं, हम block_galera.sh नामक निम्न स्क्रिप्ट का उपयोग करते हैं galera2 पर इस नोड के लिए/से नेटवर्क विफलता का अनुकरण करने के लिए:
#!/bin/bash
# block_galera.sh
# galera2, 192.168.55.172
iptables -I INPUT -m tcp -p tcp --dport 4567 -j REJECT
iptables -I INPUT -m tcp -p tcp --dport 3306 -j REJECT
iptables -I OUTPUT -m tcp -p tcp --dport 4567 -j REJECT
iptables -I OUTPUT -m tcp -p tcp --dport 3306 -j REJECT
# print timestamp
dateस्क्रिप्ट को क्रियान्वित करने से, हमें निम्नलिखित आउटपुट मिलते हैं:
$ ./block_galera.sh
Wed Jul 4 16:46:02 UTC 2018रिपोर्ट किए गए टाइमस्टैम्प को क्लस्टर विभाजन की शुरुआत के रूप में माना जा सकता है, जहां हम galera2 खो देते हैं, जबकि galera1 और galera3 अभी भी ऑनलाइन और पहुंच योग्य हैं। इस समय, हमारा गैलेरा क्लस्टर आर्किटेक्चर कुछ इस तरह दिख रहा है:
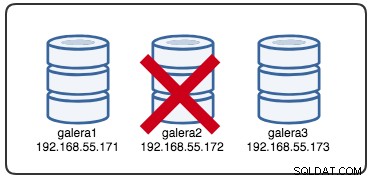
विभाजित नोड परिप्रेक्ष्य से
Galera2 पर, आप MySQL त्रुटि लॉग के अंदर कुछ प्रिंटआउट देखेंगे। आइए उन्हें कई भागों में विभाजित करें। डाउनटाइम लगभग 16:46:02 यूटीसी समय और gmcast.peer_timeout=PT3S के बाद शुरू किया गया था। , निम्न प्रकट होता है:
2018-07-04 16:46:05 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') connection to peer 8b2041d6 with addr tcp://192.168.55.173:4567 timed out, no messages seen in PT3S
2018-07-04 16:46:05 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') turning message relay requesting on, nonlive peers: tcp://192.168.55.173:4567
2018-07-04 16:46:06 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') connection to peer 737422d6 with addr tcp://192.168.55.171:4567 timed out, no messages seen in PT3S
2018-07-04 16:46:06 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 8b2041d6 (tcp://192.168.55.173:4567), attempt 0जैसे-जैसे यह बीतता गया evs.suspect_timeout =PT5S , दोनों नोड्स galera1 और galera3 को galera2 द्वारा मृत घोषित किया गया है:
2018-07-04 16:46:07 140454904243968 [Note] WSREP: evs::proto(62116b35, OPERATIONAL, view_id(REG,62116b35,54)) suspecting node: 8b2041d6
2018-07-04 16:46:07 140454904243968 [Note] WSREP: evs::proto(62116b35, OPERATIONAL, view_id(REG,62116b35,54)) suspected node without join message, declaring inactive
2018-07-04 16:46:07 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 737422d6 (tcp://192.168.55.171:4567), attempt 0
2018-07-04 16:46:08 140454904243968 [Note] WSREP: evs::proto(62116b35, GATHER, view_id(REG,62116b35,54)) suspecting node: 737422d6
2018-07-04 16:46:08 140454904243968 [Note] WSREP: evs::proto(62116b35, GATHER, view_id(REG,62116b35,54)) suspected node without join message, declaring inactiveफिर, गैलेरा वर्तमान क्लस्टर दृश्य और इस नोड की स्थिति को संशोधित करेगा:
2018-07-04 16:46:09 140454904243968 [Note] WSREP: view(view_id(NON_PRIM,62116b35,54) memb {
62116b35,0
} joined {
} left {
} partitioned {
737422d6,0
8b2041d6,0
})
2018-07-04 16:46:09 140454904243968 [Note] WSREP: view(view_id(NON_PRIM,62116b35,55) memb {
62116b35,0
} joined {
} left {
} partitioned {
737422d6,0
8b2041d6,0
})नए क्लस्टर दृश्य के साथ, गैलेरा यह तय करने के लिए कोरम गणना करेगा कि यह नोड प्राथमिक घटक का हिस्सा है या नहीं। यदि नया घटक "प्राथमिक =नहीं" देखता है, तो गैलेरा स्थानीय नोड स्थिति को SYNCED से OPEN में अवनत कर देगा:
2018-07-04 16:46:09 140454288942848 [Note] WSREP: New COMPONENT: primary = no, bootstrap = no, my_idx = 0, memb_num = 1
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Flow-control interval: [16, 16]
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Trying to continue unpaused monitor
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Received NON-PRIMARY.
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Shifting SYNCED -> OPEN (TO: 2753699)क्लस्टर दृश्य और नोड स्थिति में नवीनतम परिवर्तन के साथ, गैलेरा बेदखली के बाद के क्लस्टर दृश्य और वैश्विक स्थिति को निम्नानुसार लौटाता है:
2018-07-04 16:46:09 140454222194432 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:2753699, view# -1: non-Primary, number of nodes: 1, my index: 0, protocol version 3
2018-07-04 16:46:09 140454222194432 [Note] WSREP: wsrep_notify_cmd is not defined, skipping notification.आप देख सकते हैं कि इस अवधि के दौरान galera2 की निम्न वैश्विक स्थिति बदल गई है:
mysql> SELECT * FROM information_schema.global_status WHERE variable_name IN ('WSREP_CLUSTER_STATUS','WSREP_LOCAL_STATE_COMMENT','WSREP_CLUSTER_SIZE','WSREP_EVS_DELAYED','WSREP_READY');
+---------------------------+-----------------------------------------------------------------------------------------------------------------------------------+
| VARIABLE_NAME | VARIABLE_VALUE |
+---------------------------+-----------------------------------------------------------------------------------------------------------------------------------+
| WSREP_CLUSTER_SIZE | 1 |
| WSREP_CLUSTER_STATUS | non-Primary |
| WSREP_EVS_DELAYED | 737422d6-7db3-11e8-a2a2-bbe98913baf0:tcp://192.168.55.171:4567:1,8b2041d6-7f62-11e8-87d5-12a76678131f:tcp://192.168.55.173:4567:2 |
| WSREP_LOCAL_STATE_COMMENT | Initialized |
| WSREP_READY | OFF |
+---------------------------+-----------------------------------------------------------------------------------------------------------------------------------+इस बिंदु पर, galera2 पर MySQL/MariaDB सर्वर अभी भी पहुंच योग्य है (डेटाबेस 3306 पर और गैलेरा 4567 पर सुन रहा है) और आप MySQL सिस्टम तालिकाओं को क्वेरी कर सकते हैं और डेटाबेस और तालिकाओं को सूचीबद्ध कर सकते हैं। हालाँकि जब आप गैर-सिस्टम तालिकाओं में कूदते हैं और इस तरह की एक साधारण क्वेरी बनाते हैं:
mysql> SELECT * FROM sbtest1;
ERROR 1047 (08S01): WSREP has not yet prepared node for application useजैसा कि wsrep_ready द्वारा रिपोर्ट किया गया है, आपको तुरंत एक त्रुटि मिलेगी जो इंगित करती है कि WSREP लोड हो गया है लेकिन इस नोड द्वारा उपयोग के लिए तैयार नहीं है। स्थिति। यह नोड के प्राथमिक घटक से अपना कनेक्शन खोने के कारण है और यह गैर-परिचालन स्थिति में प्रवेश करता है (स्थानीय नोड स्थिति को SYNCED से OPEN में बदल दिया गया था)। जब तक आप wsrep_dirty_reads=ON सेट नहीं करते हैं, तब तक गैर-कार्यशील स्थिति में नोड्स से पढ़े गए डेटा को बासी माना जाता है पढ़ने की अनुमति देने के लिए, हालांकि गैलेरा अभी भी डेटाबेस को संशोधित या अद्यतन करने वाले किसी भी आदेश को अस्वीकार कर देता है।
अंत में, गैलेरा पृष्ठभूमि में अन्य सदस्यों को असीमित रूप से सुनता और पुनः कनेक्ट करता रहेगा:
2018-07-04 16:47:12 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 8b2041d6 (tcp://192.168.55.173:4567), attempt 30
2018-07-04 16:47:13 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 737422d6 (tcp://192.168.55.171:4567), attempt 30
2018-07-04 16:48:20 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 8b2041d6 (tcp://192.168.55.173:4567), attempt 60
2018-07-04 16:48:22 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 737422d6 (tcp://192.168.55.171:4567), attempt 60नेटवर्क समस्या के दौरान विभाजित नोड के लिए गैलेरा समूह संचार द्वारा निष्कासन प्रक्रिया प्रवाह को नीचे संक्षेप में प्रस्तुत किया जा सकता है:
- gmcast.peer_timeout के बाद क्लस्टर से डिस्कनेक्ट हो जाता है ।
- evs.suspect_timeout के बाद अन्य नोड्स पर संदेह करता है ।
- नया क्लस्टर दृश्य पुनर्प्राप्त करता है।
- नोड की स्थिति निर्धारित करने के लिए कोरम गणना करता है।
- नोड को SYNCED से OPEN में अवनत करता है।
- पृष्ठभूमि में प्राथमिक घटक (अन्य गैलेरा नोड्स) से पुन:कनेक्ट करने का प्रयास।
प्राथमिक घटक परिप्रेक्ष्य से
gmcast.peer_timeout=PT3S के बाद क्रमशः galera1 और galera3 पर , निम्नलिखित MySQL त्रुटि लॉग में प्रकट होता है:
2018-07-04 16:46:05 139955510687488 [Note] WSREP: (8b2041d6, 'tcp://0.0.0.0:4567') turning message relay requesting on, nonlive peers: tcp://192.168.55.172:4567
2018-07-04 16:46:06 139955510687488 [Note] WSREP: (8b2041d6, 'tcp://0.0.0.0:4567') reconnecting to 62116b35 (tcp://192.168.55.172:4567), attempt 0इसके बीत जाने के बाद evs.suspect_timeout =PT5S , galera2 को galera3 (और galera1) द्वारा मृत घोषित किया गया है:
2018-07-04 16:46:10 139955510687488 [Note] WSREP: evs::proto(8b2041d6, OPERATIONAL, view_id(REG,62116b35,54)) suspecting node: 62116b35
2018-07-04 16:46:10 139955510687488 [Note] WSREP: evs::proto(8b2041d6, OPERATIONAL, view_id(REG,62116b35,54)) suspected node without join message, declaring inactiveगैलेरा यह जांचता है कि क्या अन्य नोड galera3 पर समूह संचार का जवाब देते हैं, यह पाता है कि galera1 प्राथमिक और स्थिर स्थिति में है:
2018-07-04 16:46:11 139955510687488 [Note] WSREP: declaring 737422d6 at tcp://192.168.55.171:4567 stable
2018-07-04 16:46:11 139955510687488 [Note] WSREP: Node 737422d6 state primगैलेरा इस नोड के क्लस्टर दृश्य को संशोधित करता है (galera3):
2018-07-04 16:46:11 139955510687488 [Note] WSREP: view(view_id(PRIM,737422d6,55) memb {
737422d6,0
8b2041d6,0
} joined {
} left {
} partitioned {
62116b35,0
})
2018-07-04 16:46:11 139955510687488 [Note] WSREP: save pc into diskगैलेरा तब प्राथमिक घटक से विभाजित नोड को हटा देता है:
2018-07-04 16:46:11 139955510687488 [Note] WSREP: forgetting 62116b35 (tcp://192.168.55.172:4567)नया प्राथमिक घटक अब दो नोड्स, galera1 और galera3 से मिलकर बना है:
2018-07-04 16:46:11 139955502294784 [Note] WSREP: New COMPONENT: primary = yes, bootstrap = no, my_idx = 1, memb_num = 2प्राथमिक घटक नए क्लस्टर दृश्य और वैश्विक स्थिति पर सहमत होने के लिए एक दूसरे के बीच राज्य का आदान-प्रदान करेगा:
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: Waiting for state UUID.
2018-07-04 16:46:11 139955510687488 [Note] WSREP: (8b2041d6, 'tcp://0.0.0.0:4567') turning message relay requesting off
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: sent state msg: b3d38100-7f66-11e8-8e70-8e3bf680c993
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: got state msg: b3d38100-7f66-11e8-8e70-8e3bf680c993 from 0 (192.168.55.171)
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: got state msg: b3d38100-7f66-11e8-8e70-8e3bf680c993 from 1 (192.168.55.173)गैलेरा ऑनलाइन सदस्यों के बीच स्टेट एक्सचेंज के कोरम की गणना और सत्यापन करता है:
2018-07-04 16:46:11 139955502294784 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 27,
members = 2/2 (joined/total),
act_id = 2753703,
last_appl. = 2753606,
protocols = 0/8/3 (gcs/repl/appl),
group UUID = 55238f52-41ee-11e8-852f-3316bdb654bc
2018-07-04 16:46:11 139955502294784 [Note] WSREP: Flow-control interval: [23, 23]
2018-07-04 16:46:11 139955502294784 [Note] WSREP: Trying to continue unpaused monitorgalera2 निष्कासन के बाद Galera नए क्लस्टर दृश्य और वैश्विक स्थिति को अपडेट करता है:
2018-07-04 16:46:11 139955214169856 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:2753703, view# 28: Primary, number of nodes: 2, my index: 1, protocol version 3
2018-07-04 16:46:11 139955214169856 [Note] WSREP: wsrep_notify_cmd is not defined, skipping notification.
2018-07-04 16:46:11 139955214169856 [Note] WSREP: REPL Protocols: 8 (3, 2)
2018-07-04 16:46:11 139955214169856 [Note] WSREP: Assign initial position for certification: 2753703, protocol version: 3
2018-07-04 16:46:11 139956691814144 [Note] WSREP: Service thread queue flushed.
Clean up the partitioned node (galera2) from the active list:
2018-07-04 16:46:14 139955510687488 [Note] WSREP: cleaning up 62116b35 (tcp://192.168.55.172:4567)इस समय, galera1 और galera3 दोनों समान वैश्विक स्थिति की रिपोर्ट करेंगे:
mysql> SELECT * FROM information_schema.global_status WHERE variable_name IN ('WSREP_CLUSTER_STATUS','WSREP_LOCAL_STATE_COMMENT','WSREP_CLUSTER_SIZE','WSREP_EVS_DELAYED','WSREP_READY');
+---------------------------+------------------------------------------------------------------+
| VARIABLE_NAME | VARIABLE_VALUE |
+---------------------------+------------------------------------------------------------------+
| WSREP_CLUSTER_SIZE | 2 |
| WSREP_CLUSTER_STATUS | Primary |
| WSREP_EVS_DELAYED | 1491abd9-7f6d-11e8-8930-e269b03673d8:tcp://192.168.55.172:4567:1 |
| WSREP_LOCAL_STATE_COMMENT | Synced |
| WSREP_READY | ON |
+---------------------------+------------------------------------------------------------------+वे समस्याग्रस्त सदस्य को wsrep_evs_delayed . में सूचीबद्ध करते हैं स्थिति। चूंकि स्थानीय स्थिति "समन्वयित" है, ये नोड्स चालू हैं और आप क्लाइंट कनेक्शन को galera2 से उनमें से किसी पर भी रीडायरेक्ट कर सकते हैं। यदि यह चरण असुविधाजनक है, तो क्लाइंट से कनेक्शन समापन बिंदु को सरल बनाने के लिए डेटाबेस के सामने बैठे लोड बैलेंसर का उपयोग करने पर विचार करें।
नोड रिकवरी और ज्वाइनिंग
एक विभाजित गैलेरा नोड प्राथमिक घटक के साथ असीम रूप से संबंध स्थापित करने का प्रयास करता रहेगा। आइए galera2 पर iptables नियमों को फ्लश करें ताकि इसे शेष नोड्स के साथ जोड़ा जा सके:
# on galera2
$ iptables -Fएक बार जब नोड किसी एक नोड से जुड़ने में सक्षम हो जाता है, तो गैलेरा समूह संचार को स्वचालित रूप से फिर से स्थापित करना शुरू कर देगा:
2018-07-09 10:46:34 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') connection established to 8b2041d6 tcp://192.168.55.173:4567
2018-07-09 10:46:34 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') connection established to 737422d6 tcp://192.168.55.171:4567
2018-07-09 10:46:34 140075962705664 [Note] WSREP: declaring 737422d6 at tcp://192.168.55.171:4567 stable
2018-07-09 10:46:34 140075962705664 [Note] WSREP: declaring 8b2041d6 at tcp://192.168.55.173:4567 stableनोड galera2 तब प्राथमिक घटक में से एक से कनेक्ट होगा (इस मामले में galera1, नोड आईडी 737422d6 है) वर्तमान क्लस्टर दृश्य और नोड्स स्थिति प्राप्त करने के लिए:
2018-07-09 10:46:34 140075962705664 [Note] WSREP: Node 737422d6 state prim
2018-07-09 10:46:34 140075962705664 [Note] WSREP: view(view_id(PRIM,1491abd9,142) memb {
1491abd9,0
737422d6,0
8b2041d6,0
} joined {
} left {
} partitioned {
})
2018-07-09 10:46:34 140075962705664 [Note] WSREP: save pc into diskगैलेरा फिर बाकी सदस्यों के साथ राज्य विनिमय करेगा जो प्राथमिक घटक बना सकते हैं:
2018-07-09 10:46:34 140075954312960 [Note] WSREP: New COMPONENT: primary = yes, bootstrap = no, my_idx = 0, memb_num = 3
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE_EXCHANGE: sent state UUID: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: sent state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: got state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f from 0 (192.168.55.172)
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: got state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f from 1 (192.168.55.171)
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: got state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f from 2 (192.168.55.173)स्टेट एक्सचेंज galera2 को कोरम की गणना करने और निम्नलिखित परिणाम देने की अनुमति देता है:
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 71,
members = 2/3 (joined/total),
act_id = 2836958,
last_appl. = 0,
protocols = 0/8/3 (gcs/repl/appl),
group UUID = 55238f52-41ee-11e8-852f-3316bdb654bcगैलेरा तब प्राथमिक घटक से नोड कनेक्शन शुरू करने और स्थापित करने के लिए स्थानीय नोड स्थिति को OPEN से PRIMARY तक बढ़ावा देगा:
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Flow-control interval: [28, 28]
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Trying to continue unpaused monitor
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Shifting OPEN -> PRIMARY (TO: 2836958)जैसा कि उपरोक्त पंक्ति द्वारा बताया गया है, गैलेरा इस अंतर की गणना करता है कि नोड क्लस्टर से कितनी दूर है। इस नोड को 2761994 से राइटसेट संख्या 2836958 तक पहुंचने के लिए राज्य हस्तांतरण की आवश्यकता है:
2018-07-09 10:46:34 140075929970432 [Note] WSREP: State transfer required:
Group state: 55238f52-41ee-11e8-852f-3316bdb654bc:2836958
Local state: 55238f52-41ee-11e8-852f-3316bdb654bc:2761994
2018-07-09 10:46:34 140075929970432 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:2836958, view# 72: Primary, number of nodes:
3, my index: 0, protocol version 3
2018-07-09 10:46:34 140075929970432 [Warning] WSREP: Gap in state sequence. Need state transfer.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: wsrep_notify_cmd is not defined, skipping notification.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: REPL Protocols: 8 (3, 2)
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Assign initial position for certification: 2836958, protocol version: 3गैलेरा इस नोड पर पोर्ट 4568 पर आईएसटी श्रोता तैयार करता है और क्लस्टर में किसी भी सिंक किए गए नोड को दाता बनने के लिए कहता है। इस मामले में, गैलेरा स्वचालित रूप से galera3 (192.168.55.173) चुनता है, या यह wsrep_sst_donor के अंतर्गत सूची से किसी दाता को भी चुन सकता है (यदि परिभाषित है) सिंकिंग ऑपरेशन के लिए:
2018-07-09 10:46:34 140075996276480 [Note] WSREP: Service thread queue flushed.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: IST receiver addr using tcp://192.168.55.172:4568
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Prepared IST receiver, listening at: tcp://192.168.55.172:4568
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Member 0.0 (192.168.55.172) requested state transfer from '*any*'. Selected 2.0 (192.168.55.173)(SYNCED) as donor.इसके बाद यह स्थानीय नोड स्थिति को प्राथमिक से जॉइनर में बदल देगा। इस स्तर पर, galera2 को राज्य हस्तांतरण अनुरोध के साथ प्रदान किया जाता है और राइट-सेट को कैश करना शुरू कर देता है:
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Shifting PRIMARY -> JOINER (TO: 2836958)
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Requesting state transfer: success, donor: 2
2018-07-09 10:46:34 140075929970432 [Note] WSREP: GCache history reset: 55238f52-41ee-11e8-852f-3316bdb654bc:2761994 -> 55238f52-41ee-11e8-852f-3316bdb654bc:2836958
2018-07-09 10:46:34 140075929970432 [Note] WSREP: GCache DEBUG: RingBuffer::seqno_reset(): full resetNode galera2 को चयनित दाता के gcache (galera3) से लापता राइटसेट मिलना शुरू हो जाता है:
2018-07-09 10:46:34 140075954312960 [Note] WSREP: 2.0 (192.168.55.173): State transfer to 0.0 (192.168.55.172) complete.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Receiving IST: 74964 writesets, seqnos 2761994-2836958
2018-07-09 10:46:34 140075593627392 [Note] WSREP: Receiving IST... 0.0% ( 0/74964 events) complete.
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Member 2.0 (192.168.55.173) synced with group.
2018-07-09 10:46:34 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') connection established to 737422d6 tcp://192.168.55.171:4567
2018-07-09 10:46:41 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') turning message relay requesting off
2018-07-09 10:46:44 140075593627392 [Note] WSREP: Receiving IST... 36.0% (27008/74964 events) complete.
2018-07-09 10:46:54 140075593627392 [Note] WSREP: Receiving IST... 71.6% (53696/74964 events) complete.
2018-07-09 10:47:02 140075593627392 [Note] WSREP: Receiving IST...100.0% (74964/74964 events) complete.
2018-07-09 10:47:02 140075929970432 [Note] WSREP: IST received: 55238f52-41ee-11e8-852f-3316bdb654bc:2836958
2018-07-09 10:47:02 140075954312960 [Note] WSREP: 0.0 (192.168.55.172): State transfer from 2.0 (192.168.55.173) complete.एक बार सभी लापता राइटसेट प्राप्त हो जाने और लागू होने के बाद, गैलेरा galera2 को seqno 2837012 तक JOINED के रूप में प्रचारित करेगा:
2018-07-09 10:47:02 140075954312960 [Note] WSREP: Shifting JOINER -> JOINED (TO: 2837012)
2018-07-09 10:47:02 140075954312960 [Note] WSREP: Member 0.0 (192.168.55.172) synced with group.नोड अपनी दास कतार में किसी भी कैश्ड राइटसेट को लागू करता है और क्लस्टर के साथ पकड़ने को समाप्त करता है। इसकी दास कतार अब खाली है। गैलेरा galera2 को SYNCED में बढ़ावा देगा, यह दर्शाता है कि नोड अब चालू है और ग्राहकों की सेवा के लिए तैयार है:
2018-07-09 10:47:02 140075954312960 [Note] WSREP: Shifting JOINED -> SYNCED (TO: 2837012)
2018-07-09 10:47:02 140076605892352 [Note] WSREP: Synchronized with group, ready for connectionsइस बिंदु पर, सभी नोड्स वापस चालू हो गए हैं। आप galera2 पर निम्नलिखित कथनों का उपयोग करके सत्यापित कर सकते हैं:
mysql> SELECT * FROM information_schema.global_status WHERE variable_name IN ('WSREP_CLUSTER_STATUS','WSREP_LOCAL_STATE_COMMENT','WSREP_CLUSTER_SIZE','WSREP_EVS_DELAYED','WSREP_READY');
+---------------------------+----------------+
| VARIABLE_NAME | VARIABLE_VALUE |
+---------------------------+----------------+
| WSREP_CLUSTER_SIZE | 3 |
| WSREP_CLUSTER_STATUS | Primary |
| WSREP_EVS_DELAYED | |
| WSREP_LOCAL_STATE_COMMENT | Synced |
| WSREP_READY | ON |
+---------------------------+----------------+wsrep_cluster_size 3 के रूप में रिपोर्ट किया गया है और क्लस्टर स्थिति प्राथमिक है, यह दर्शाता है कि galera2 प्राथमिक घटक का हिस्सा है। wsrep_evs_delayed को भी साफ़ कर दिया गया है और स्थानीय राज्य अब समन्वयित हो गया है।
नेटवर्क समस्या के दौरान विभाजित नोड के लिए पुनर्प्राप्ति प्रक्रिया प्रवाह को नीचे संक्षेप में प्रस्तुत किया जा सकता है:
- अन्य नोड्स में समूह संचार को फिर से स्थापित करता है।
- एक प्राथमिक घटक से क्लस्टर दृश्य प्राप्त करता है।
- प्राथमिक घटक के साथ राज्य विनिमय करता है और कोरम की गणना करता है।
- स्थानीय नोड स्थिति को OPEN से PRIMARY में बदलता है।
- स्थानीय नोड और क्लस्टर के बीच अंतर की गणना करता है।
- स्थानीय नोड स्थिति को प्राथमिक से जॉइनर में बदलता है।
- पोर्ट 4568 पर IST श्रोता/रिसीवर तैयार करता है।
- आईएसटी के माध्यम से राज्य हस्तांतरण का अनुरोध करता है और एक दाता चुनता है।
- चुने हुए डोनर के gcache से लापता राइटसेट प्राप्त करना और लागू करना शुरू करता है।
- स्थानीय नोड स्थिति को JOINER से JOINED में बदलता है।
- दास कतार में कैश्ड राइटसेट को लागू करके क्लस्टर के साथ जुड़ता है।
- स्थानीय नोड स्थिति को JOINED से SYNCED में बदलता है।
क्लस्टर विफलता
यदि कोई प्राथमिक घटक (पीसी) उपलब्ध नहीं है, तो गैलेरा क्लस्टर को विफल माना जाता है। एक समान तीन-नोड वाले गैलेरा क्लस्टर पर विचार करें जैसा कि नीचे दिए गए चित्र में दिखाया गया है:
यदि सभी नोड्स या अधिकांश नोड्स ऑनलाइन हैं तो क्लस्टर को चालू माना जाता है। ऑनलाइन का मतलब है कि वे गैलेरा के प्रतिकृति यातायात या समूह संचार के माध्यम से एक-दूसरे को देखने में सक्षम हैं। यदि नोड से कोई ट्रैफ़िक नहीं आ रहा है, तो क्लस्टर समय पर प्रतिक्रिया के लिए नोड के लिए एक दिल की धड़कन बीकन भेजेगा। अन्यथा, नोड की प्रतिक्रिया के अनुसार इसे विलंब या संदिग्ध सूची में डाल दिया जाएगा।
यदि कोई नोड नीचे चला जाता है, मान लें कि नोड सी, क्लस्टर चालू रहेगा क्योंकि नोड ए और बी अभी भी प्राथमिक घटक बनाने के लिए 3 में से 2 वोटों के साथ कोरम में हैं। आपको ए और बी पर निम्न क्लस्टर स्थिति मिलनी चाहिए:
mysql> SHOW STATUS LIKE 'wsrep_cluster_status';
+----------------------+---------+
| Variable_name | Value |
+----------------------+---------+
| wsrep_cluster_status | Primary |
+----------------------+---------+यदि मान लें कि एक प्राथमिक स्विच कपट चला गया, जैसा कि निम्नलिखित आरेख में दिखाया गया है:
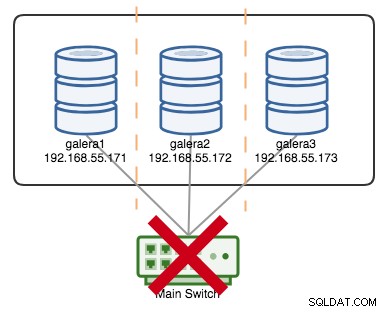
इस बिंदु पर, प्रत्येक नोड एक-दूसरे से संचार खो देता है, और क्लस्टर स्थिति को सभी नोड्स पर गैर-प्राथमिक के रूप में रिपोर्ट किया जाएगा (जैसा कि पिछले मामले में galera2 के साथ हुआ था)। प्रत्येक नोड कोरम की गणना करेगा और यह पता लगाएगा कि यह अल्पसंख्यक है (3 में से 1 वोट) इस प्रकार कोरम खो देता है, जिसका अर्थ है कि कोई प्राथमिक घटक नहीं बनता है और परिणामस्वरूप सभी नोड्स किसी भी डेटा की सेवा से इनकार करते हैं। इसे क्लस्टर विफलता माना जाता है।
एक बार नेटवर्क समस्या हल हो जाने के बाद, गैलेरा स्वचालित रूप से सदस्यों के बीच संचार को फिर से स्थापित करेगा, नोड के राज्यों का आदान-प्रदान करेगा और नोड राज्य, यूयूआईडी और सेकनोस की तुलना करके प्राथमिक घटक में सुधार की संभावना निर्धारित करेगा। यदि संभावना है, तो गैलेरा प्राथमिक घटकों को मर्ज कर देगा जैसा कि निम्नलिखित पंक्तियों में दिखाया गया है:
2018-06-27 0:16:57 140203784476416 [Note] WSREP: New COMPONENT: primary = yes, bootstrap = no, my_idx = 2, memb_num = 3
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: Waiting for state UUID.
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: sent state msg: 5885911b-795c-11e8-8683-931c85442c7e
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: got state msg: 5885911b-795c-11e8-8683-931c85442c7e from 0 (192.168.55.171)
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: got state msg: 5885911b-795c-11e8-8683-931c85442c7e from 1 (192.168.55.172)
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: got state msg: 5885911b-795c-11e8-8683-931c85442c7e from 2 (192.168.55.173)
2018-06-27 0:16:57 140203784476416 [Warning] WSREP: Quorum: No node with complete state:
Version : 4
Flags : 0x3
Protocols : 0 / 8 / 3
State : NON-PRIMARY
Desync count : 0
Prim state : SYNCED
Prim UUID : 5224a024-791b-11e8-a0ac-8bc6118b0f96
Prim seqno : 5
First seqno : 112714
Last seqno : 112725
Prim JOINED : 3
State UUID : 5885911b-795c-11e8-8683-931c85442c7e
Group UUID : 55238f52-41ee-11e8-852f-3316bdb654bc
Name : '192.168.55.171'
Incoming addr: '192.168.55.171:3306'
Version : 4
Flags : 0x2
Protocols : 0 / 8 / 3
State : NON-PRIMARY
Desync count : 0
Prim state : SYNCED
Prim UUID : 5224a024-791b-11e8-a0ac-8bc6118b0f96
Prim seqno : 5
First seqno : 112714
Last seqno : 112725
Prim JOINED : 3
State UUID : 5885911b-795c-11e8-8683-931c85442c7e
Group UUID : 55238f52-41ee-11e8-852f-3316bdb654bc
Name : '192.168.55.172'
Incoming addr: '192.168.55.172:3306'
Version : 4
Flags : 0x2
Protocols : 0 / 8 / 3
State : NON-PRIMARY
Desync count : 0
Prim state : SYNCED
Prim UUID : 5224a024-791b-11e8-a0ac-8bc6118b0f96
Prim seqno : 5
First seqno : 112714
Last seqno : 112725
Prim JOINED : 3
State UUID : 5885911b-795c-11e8-8683-931c85442c7e
Group UUID : 55238f52-41ee-11e8-852f-3316bdb654bc
Name : '192.168.55.173'
Incoming addr: '192.168.55.173:3306'
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Full re-merge of primary 5224a024-791b-11e8-a0ac-8bc6118b0f96 found: 3 of 3.
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 5,
members = 3/3 (joined/total),
act_id = 112725,
last_appl. = 112722,
protocols = 0/8/3 (gcs/repl/appl),
group UUID = 55238f52-41ee-11e8-852f-3316bdb654bc
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Flow-control interval: [28, 28]
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Trying to continue unpaused monitor
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Restored state OPEN -> SYNCED (112725)
2018-06-27 0:16:57 140202564110080 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:112725, view# 6: Primary, number of nodes: 3, my index: 2, protocol version 3A good indicator to know if the re-bootstrapping process is OK is by looking at the following line in the error log:
[Note] WSREP: Synchronized with group, ready for connectionsClusterControl Auto Recovery
ClusterControl comes with node and cluster automatic recovery features, because it oversees and understands the state of all nodes in the cluster. Automatic recovery is by default enabled if the cluster is deployed using ClusterControl. To enable or disable the cluster, simply clicking on the power icon in the summary bar as shown below:

Green icon means automatic recovery is turned on, while red is the opposite. You can monitor the recovery progress from the Activity -> Jobs dialog, like in this case, galera2 was totally inaccessible due to firewall blocking, thus forcing ClusterControl to report the following:
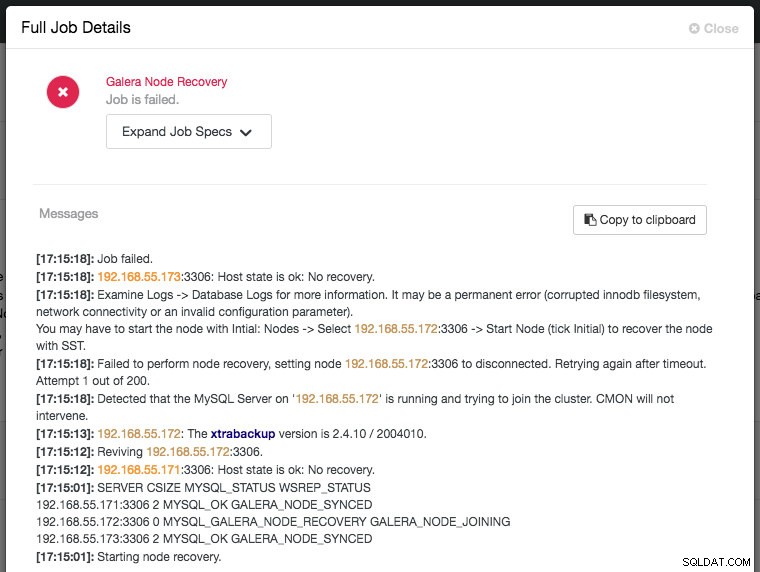
The recovery process will only be commencing after a graceful timeout (30 seconds) to give Galera node a chance to recover itself beforehand. If ClusterControl fails to recover a node or cluster, it will first pull all MySQL error logs from all accessible nodes and will raise the necessary alarms to notify the user via email or by pushing critical events to the third-party integration modules like PagerDuty, VictorOps or Slack. Manual intervention is then required. For Galera Cluster, ClusterControl will keep on trying to recover the failure until you mark the node as under maintenance, or disable the automatic recovery feature.
ClusterControl's automatic recovery is one of most favorite features as voted by our users. It helps you to take the necessary actions quickly, with a complete report on what has been attempted and recommendation steps to troubleshoot further on the issue. For users with support subscriptions, you can look for extra hands by escalating this issue to our technical support team for assistance.
निष्कर्ष
Galera automatic node recovery and membership control are neat features to simplify the cluster management, improve the database reliability and reduce the risk of human error, as commonly haunting other open-source database replication technology like MySQL Replication, Group Replication and PostgreSQL Streaming/Logical Replication.



