पुनर्प्राप्ति समय उद्देश्य (आरटीओ) वह समयावधि है जिसके भीतर अस्वीकार्य परिणामों से बचने के लिए किसी सेवा को बहाल किया जाना चाहिए। डेटाबेस विफलता से उबरने में कितना समय लग सकता है, इसकी गणना करके, हम जान सकते हैं कि तैयारी के स्तर की क्या आवश्यकता है। यदि आरटीओ कुछ मिनटों का है, तो विफलता में महत्वपूर्ण निवेश की आवश्यकता है। 36 घंटे के आरटीओ के लिए काफी कम निवेश की आवश्यकता होती है। यही वह जगह है जहां फेलओवर ऑटोमेशन आता है।
हमारे पिछले ब्लॉगों में, हमने MongoDB, MySQL/MariaDB/Percona, PostgreSQL या TimeScaleDB के लिए विफलता पर चर्चा की है। संक्षेप में, "विफलता "कुछ विफलता होने पर भी कार्य करना जारी रखने के लिए एक प्रणाली की क्षमता है। यह सुझाव देता है कि प्राथमिक घटक विफल होने पर सिस्टम के कार्यों को माध्यमिक घटकों द्वारा ग्रहण किया जाता है। विफलता किसी भी उच्च उपलब्धता प्रणाली का एक स्वाभाविक हिस्सा है, और कुछ मामलों में , इसे स्वचालित भी करना पड़ता है। मैनुअल विफलताओं में बहुत अधिक समय लगता है, लेकिन ऐसे मामले हैं जहां स्वचालन अच्छी तरह से काम नहीं करेगा - उदाहरण के लिए एक विभाजित मस्तिष्क के मामले में जहां डेटाबेस प्रतिकृति टूट जाती है और दो 'हिस्सों' को प्रभावी ढंग से अपडेट प्राप्त होते रहते हैं डेटा सेट और असंगति को अलग करने के लिए अग्रणी।
हमने पहले ClusterControl स्वचालित विफलता प्रक्रियाओं के पीछे मार्गदर्शक सिद्धांतों के बारे में लिखा था। जहां संभव हो, स्वचालित विफलता दक्षता प्रदान करती है क्योंकि यह विफलताओं से त्वरित पुनर्प्राप्ति को सक्षम बनाता है। इस ब्लॉग में, हम देखेंगे कि क्लस्टरकंट्रोल का उपयोग करके मास्टर-स्लेव (या प्राथमिक-स्टैंडबाय) प्रतिकृति सेटअप में स्वचालित विफलता कैसे प्राप्त करें।
प्रौद्योगिकी स्टैक आवश्यकताएँ
ओपन सोर्स सॉफ्टवेयर घटकों से एक स्टैक को इकट्ठा किया जा सकता है, और कई विकल्प उपलब्ध हैं - कुछ विफलता विशेषताओं और समाधान के प्रबंधन और रखरखाव के लिए उपलब्ध विशेषज्ञता के स्तर के आधार पर दूसरों की तुलना में अधिक उपयुक्त हैं। हार्डवेयर और नेटवर्किंग भी महत्वपूर्ण पहलू हैं।
सॉफ्टवेयर
ओपन सोर्स इकोसिस्टम में बहुत सारे विकल्प उपलब्ध हैं जिनका उपयोग आप फेलओवर को लागू करने के लिए कर सकते हैं। MySQL के लिए, आप MHA, MMM, Maxscale/MRM, mysqlfailover, या Orchestrator का लाभ उठा सकते हैं। यह पिछला ब्लॉग मैक्सस्केल की तुलना एमएचए से मैक्सस्केल/एमआरएम से करता है। PostgreSQL में repmgr, Patroni, PostgreSQL Automatic Failover (PAF), pglookout, pgPool-II, या stolon है। इन विभिन्न उच्च उपलब्धता विकल्पों को पहले कवर किया गया था। MongoDB में स्वचालित विफलता के समर्थन के साथ प्रतिकृति सेट हैं।
ClusterControl MySQL, MariaDB, PostgreSQL और MongoDB के लिए स्वचालित विफलता कार्यक्षमता प्रदान करता है, जिसे हम और नीचे कवर करेंगे। ध्यान देने योग्य बात यह है कि इसमें टूटे हुए नोड्स या क्लस्टर को स्वचालित रूप से पुनर्प्राप्त करने की कार्यक्षमता भी है।
हार्डवेयर
स्वचालित फ़ेलओवर आमतौर पर एक अलग डेमॉन सर्वर द्वारा किया जाता है जो अपने स्वयं के हार्डवेयर पर सेटअप होता है - डेटाबेस नोड्स से अलग। यह डेटाबेस की स्थिति की निगरानी कर रहा है, और विफलता के मामले में प्रतिक्रिया करने के तरीके के बारे में निर्णय लेने के लिए जानकारी का उपयोग करता है।
कमोडिटी सर्वर ठीक काम कर सकते हैं, जब तक कि सर्वर बड़ी संख्या में उदाहरणों की निगरानी नहीं कर रहा हो। आमतौर पर, प्रसंस्करण के मामले में सिस्टम जांच और स्वास्थ्य विश्लेषण हल्के होते हैं। हालाँकि, यदि आपके पास जाँच करने के लिए बड़ी संख्या में नोड्स हैं, तो बड़े CPU और मेमोरी की आवश्यकता होती है, खासकर जब चेक को कतार में लगाना पड़ता है क्योंकि यह सर्वर से जानकारी को पिंग और एकत्र करने का प्रयास करता है। निगरानी और पर्यवेक्षण किए जा रहे नोड्स कभी-कभी नेटवर्क समस्याओं, उच्च लोड, या बदतर स्थिति में, हार्डवेयर विफलता या कुछ VM होस्ट भ्रष्टाचार के कारण बंद हो सकते हैं। तो सर्वर जो स्वास्थ्य और सिस्टम जांच चलाता है, ऐसे स्टालों का सामना करने में सक्षम होगा, क्योंकि संभावना है कि कतारों का प्रसंस्करण बढ़ सकता है क्योंकि मॉनिटर किए गए प्रत्येक नोड की प्रतिक्रिया में समय लग सकता है जब तक कि यह सत्यापित नहीं हो जाता है कि यह अब उपलब्ध नहीं है या एक टाइमआउट है पहुंच गया है।
क्लाउड-आधारित परिवेशों के लिए, ऐसी सेवाएँ हैं जो स्वचालित विफलता प्रदान करती हैं। उदाहरण के लिए, अमेज़ॅन आरडीएस स्टोरेज को स्टैंडबाय नोड में दोहराने के लिए डीआरबीडी का उपयोग करता है। या अगर आप अपने वॉल्यूम को ईबीएस में स्टोर कर रहे हैं, तो इन्हें कई क्षेत्रों में दोहराया जाता है।
नेटवर्क
स्वचालित फ़ेलओवर सॉफ़्टवेयर अक्सर उन एजेंटों पर निर्भर करता है जो डेटाबेस नोड्स पर सेटअप होते हैं। एजेंट डेटाबेस इंस्टेंस से स्थानीय रूप से जानकारी एकत्र करता है और जब भी अनुरोध किया जाता है, सर्वर को भेजता है।
नेटवर्क आवश्यकताओं के संदर्भ में, सुनिश्चित करें कि आपके पास अच्छी बैंडविड्थ और एक स्थिर नेटवर्क कनेक्शन है। जाँच को बार-बार करने की आवश्यकता होती है, और अस्थिर नेटवर्क के कारण दिल की धड़कन छूटने से फ़ेलओवर सॉफ़्टवेयर हो सकता है (गलत तरीके से) यह पता लगाने के लिए कि एक नोड नीचे है।
ClusterControl को डेटाबेस नोड्स पर स्थापित किसी एजेंट की आवश्यकता नहीं है, क्योंकि यह नियमित अंतराल पर प्रत्येक डेटाबेस नोड में SSH करेगा और कई जाँच करेगा।
ClusterControl के साथ स्वचालित विफलता
ClusterControl मैनुअल के साथ-साथ स्वचालित विफलताओं को करने की क्षमता प्रदान करता है। आइए देखें कि यह कैसे किया जा सकता है।
ClusterControl में विफलता को स्वचालित या नहीं होने के लिए कॉन्फ़िगर किया जा सकता है। यदि आप मैन्युअल रूप से विफलता का ख्याल रखना पसंद करते हैं, तो आप स्वचालित क्लस्टर पुनर्प्राप्ति को अक्षम कर सकते हैं। मैन्युअल फ़ेलओवर करते समय, आप क्लस्टर → टोपोलॉजी . पर जा सकते हैं क्लस्टर कंट्रोल में। नीचे स्क्रीनशॉट देखें:
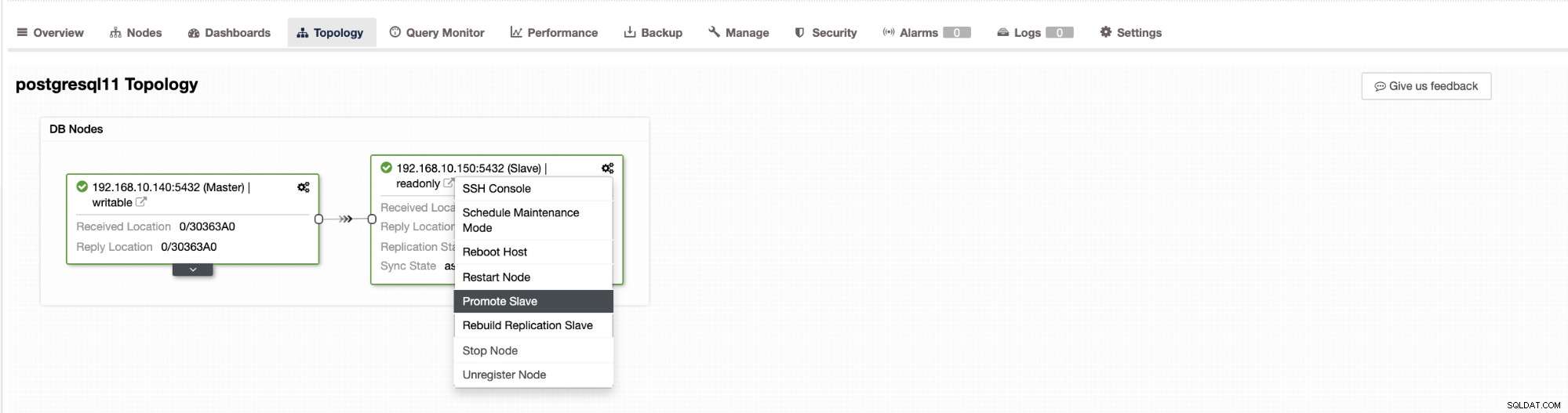
डिफ़ॉल्ट रूप से, क्लस्टर पुनर्प्राप्ति सक्षम है और स्वचालित विफलता का उपयोग किया जाता है। UI में परिवर्तन करने के बाद, रनटाइम कॉन्फ़िगरेशन बदल जाता है। यदि आप चाहते हैं कि सेटिंग नियंत्रक के पुनरारंभ होने से बचे, तो सुनिश्चित करें कि आप cmon कॉन्फ़िगरेशन में भी परिवर्तन करते हैं, अर्थात /etc/cmon.d/cmon_

MySQL/MariaDB/Percona सर्वर में, ClusterControl द्वारा स्वचालित विफलता शुरू की जाती है जब यह पता लगाता है कि read_only के साथ कोई होस्ट नहीं है। ध्वज अक्षम। ऐसा इसलिए हो सकता है क्योंकि मास्टर (जिसमें केवल पढ़ने के लिए . है) 0 पर सेट है) उपलब्ध नहीं है या इसे किसी उपयोगकर्ता या किसी बाहरी सॉफ़्टवेयर द्वारा ट्रिगर किया जा सकता है जिसने मास्टर पर इस ध्वज को बदल दिया है। यदि आप डेटाबेस नोड्स में मैन्युअल परिवर्तन करते हैं या आपके पास सॉफ़्टवेयर है जो read_only सेटिंग्स के साथ खराब हो सकता है, तो आपको स्वचालित विफलता को अक्षम करना चाहिए। ClusterControl के स्वचालित फ़ेलओवर का प्रयास केवल एक बार किया जाता है, इसलिए, विफल फ़ेलओवर के बाद बाद में फ़ेलओवर नहीं किया जाएगा - तब तक नहीं जब तक कि cmon पुनरारंभ नहीं हो जाता।
PostgreSQL के लिए, ClusterControl हमारे डेटाबेस के संस्करण के आधार पर इस उद्देश्य के लिए pg_current_xlog_location (PostgreSQL 9+) या pg_current_wal_lsn (PostgreSQL 10+) का उपयोग करते हुए सबसे उन्नत स्लेव को चुनेगा। कुछ सामान्य गलतियों से बचने के लिए, ClusterControl फ़ेलओवर प्रक्रिया पर कई जाँच भी करता है। एक उदाहरण यह है कि यदि हम अपने पुराने असफल मास्टर को पुनर्प्राप्त करने का प्रबंधन करते हैं, तो यह "नहीं . होगा " क्लस्टर में स्वचालित रूप से पुन:प्रस्तुत किया जाएगा, न तो एक मास्टर के रूप में और न ही एक दास के रूप में। हमें इसे मैन्युअल रूप से करने की आवश्यकता है। यह उस मामले में डेटा हानि या असंगति की संभावना से बच जाएगा जब हमारे दास (जिसे हमने बढ़ावा दिया था) उस समय विलंबित था विफलता के बारे में। हो सकता है कि हम समस्या को प्रतिकृति सेटअप में फिर से पेश करने से पहले उसका विस्तार से विश्लेषण करना चाहें, इसलिए हम नैदानिक जानकारी को संरक्षित करना चाहेंगे।
साथ ही, यदि फ़ेलओवर विफल हो जाता है, तो कोई और प्रयास नहीं किया जाता है (यह पोस्टग्रेएसक्यूएल और माईएसक्यूएल-आधारित क्लस्टर दोनों पर लागू होता है), समस्या का विश्लेषण करने और संबंधित कार्यों को करने के लिए मैन्युअल हस्तक्षेप की आवश्यकता होती है। यह उस स्थिति से बचने के लिए है जहां ClusterControl, जो स्वचालित विफलता को संभालता है, अगले दास और अगले दास को बढ़ावा देने का प्रयास करता है। कोई समस्या हो सकती है, और हम एकाधिक विफलताओं का प्रयास करके चीजों को और खराब नहीं करना चाहते हैं।
ClusterControl उन सर्वरों के एक सेट की श्वेतसूची और ब्लैकलिस्टिंग की पेशकश करता है जिन्हें आप फ़ेलओवर में भाग लेना चाहते हैं, या उम्मीदवार के रूप में बाहर करना चाहते हैं।
MySQL-प्रकार के क्लस्टर के लिए, ClusterControl दासों की एक सूची बनाता है जिसे मास्टर के रूप में पदोन्नत किया जा सकता है। अधिकांश समय, इसमें टोपोलॉजी में सभी दास शामिल होंगे लेकिन उपयोगकर्ता का इस पर कुछ अतिरिक्त नियंत्रण होता है। सीमोन कॉन्फ़िगरेशन में आप दो चर सेट कर सकते हैं:
replication_failover_whitelistऔर
replication_failover_blacklistकॉन्फ़िगरेशन चर प्रतिकृति_फेलओवर_व्हाइटलिस्ट के लिए, इसमें आईपी या दासों के होस्टनामों की एक सूची है, जिन्हें संभावित मास्टर उम्मीदवारों के रूप में उपयोग किया जाना चाहिए। यदि यह चर सेट किया गया है, तो केवल उन होस्ट पर विचार किया जाएगा। परिवर्तनीय प्रतिकृति_फेलओवर_ब्लैकलिस्ट के लिए, इसमें उन मेजबानों की सूची होती है जिन्हें कभी भी मास्टर उम्मीदवार नहीं माना जाएगा। आप इसका उपयोग उन दासों को सूचीबद्ध करने के लिए कर सकते हैं जिनका उपयोग बैकअप या विश्लेषणात्मक प्रश्नों के लिए किया जाता है। यदि हार्डवेयर दासों के बीच भिन्न होता है, तो आप यहां उन दासों को रखना चाहेंगे जो धीमे हार्डवेयर का उपयोग करते हैं।
प्रतिकृति_फेलओवर_व्हाइटलिस्ट को प्राथमिकता दी जाती है, जिसका अर्थ है कि यदि प्रतिकृति_फेलओवर_व्हाइटलिस्ट सेट है, तो प्रतिकृति_फेलओवर_ब्लैकलिस्ट को अनदेखा कर दिया जाता है।
एक बार दासों की सूची जिन्हें मास्टर के रूप में पदोन्नत किया जा सकता है, क्लस्टरकंट्रोल अपने राज्य की तुलना करना शुरू कर देता है, जो सबसे अद्यतित दास की तलाश में है। यहां, मारियाडीबी और माईएसक्यूएल-आधारित सेटअप की हैंडलिंग अलग-अलग है। मारियाडीबी सेटअप के लिए, क्लस्टरकंट्रोल एक दास को चुनता है जिसमें उपलब्ध सभी दासों की सबसे कम प्रतिकृति अंतराल है। MySQL सेटअप के लिए, ClusterControl ऐसे दास को भी चुनता है लेकिन फिर यह अतिरिक्त, लापता लेनदेन की जांच करता है जिसे कुछ शेष दासों पर निष्पादित किया जा सकता था। यदि ऐसा कोई लेन-देन पाया जाता है, तो ClusterControl सभी लापता लेनदेन को पुनः प्राप्त करने के लिए उस होस्ट से मास्टर उम्मीदवार को हटा देता है। आप इस प्रक्रिया को छोड़ सकते हैं और अपने CMON कॉन्फ़िगरेशन में वेरिएबल प्रतिकृति_स्किप_apply_missing_txs सेट करके सबसे उन्नत स्लेव का उपयोग कर सकते हैं:
उदा.
replication_skip_apply_missing_txs=1चर के साथ अधिक जानकारी के लिए हमारे दस्तावेज़ यहाँ देखें।
चेतावनी यह है कि आपको इसे केवल तभी सेट करना चाहिए जब आप जानते हों कि आप क्या कर रहे हैं, क्योंकि गलत लेनदेन हो सकते हैं। इनके कारण प्रतिकृति टूट सकती है, साथ ही पूरे क्लस्टर में डेटा असंगति हो सकती है। यदि गलत लेन-देन अतीत में हुआ है, तो यह अब बाइनरी लॉग में उपलब्ध नहीं हो सकता है। उस स्थिति में, प्रतिकृति टूट जाएगी क्योंकि दास लापता डेटा को पुनः प्राप्त करने में सक्षम नहीं होंगे। इसलिए, क्लस्टरकंट्रोल, डिफ़ॉल्ट रूप से, मास्टर उम्मीदवार को मास्टर बनने के लिए बढ़ावा देने से पहले किसी भी गलत लेनदेन की जांच करता है। यदि ऐसी समस्या का पता चलता है, तो मास्टर स्विच निरस्त कर दिया जाता है और ClusterControl उपयोगकर्ता को समस्या को मैन्युअल रूप से ठीक करने देता है।
यदि आप 100% निश्चित होना चाहते हैं कि कुछ मुद्दों का पता चलने पर भी ClusterControl एक नए मास्टर को बढ़ावा देगा, तो आप प्रतिकृति_स्टॉप_ऑन_एरर चर का उपयोग करके ऐसा कर सकते हैं। नीचे देखें:
उदा.
replication_stop_on_error=0इस चर को अपनी सीमोन कॉन्फ़िगरेशन फ़ाइल में सेट करें। जैसा कि पहले उल्लेख किया गया है, यह प्रतिकृति के साथ समस्या पैदा कर सकता है क्योंकि दास एक बाइनरी लॉग इवेंट के लिए पूछना शुरू कर सकते हैं जो अब उपलब्ध नहीं है। ऐसे मामलों को संभालने के लिए हमने दास पुनर्निर्माण के लिए प्रयोगात्मक समर्थन जोड़ा। यदि आप चर सेट करते हैं
replication_auto_rebuild_slave=1सीमोन कॉन्फ़िगरेशन में और यदि आपके दास को MySQL में निम्न त्रुटि के साथ नीचे के रूप में चिह्नित किया गया है:
Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'ClusterControl मास्टर के डेटा का उपयोग करके दास के पुनर्निर्माण का प्रयास करेगा। ऐसी सेटिंग हमेशा उपयुक्त नहीं हो सकती है क्योंकि पुनर्निर्माण प्रक्रिया मास्टर पर बढ़े हुए भार को प्रेरित करेगी। यह भी हो सकता है कि आपका डेटासेट बहुत बड़ा हो और नियमित पुनर्निर्माण कोई विकल्प न हो - इसलिए यह व्यवहार डिफ़ॉल्ट रूप से अक्षम होता है।
एक बार जब हम यह सुनिश्चित कर लेते हैं कि कोई गलत लेन-देन मौजूद नहीं है और हम जाने के लिए अच्छे हैं, तब भी एक और समस्या है जिसे हमें किसी तरह संभालने की आवश्यकता है - ऐसा हो सकता है कि सभी दास स्वामी से पिछड़ रहे हों।
जैसा कि आप शायद जानते हैं, MySQL में प्रतिकृति एक सरल तरीके से काम करती है। मास्टर स्टोर बाइनरी लॉग में लिखता है। दास का I / O धागा मास्टर से जुड़ता है और किसी भी बाइनरी लॉग इवेंट को खींचता है जो गायब है। यह फिर उन्हें रिले लॉग के रूप में संग्रहीत करता है। SQL थ्रेड उन्हें पार्स करता है और ईवेंट लागू करता है। स्लेव लैग एक ऐसी स्थिति है जिसमें SQL थ्रेड (या थ्रेड्स) घटनाओं की संख्या का सामना नहीं कर सकता है, और जैसे ही वे I/O थ्रेड द्वारा मास्टर से खींचे जाते हैं, उन्हें लागू करने में असमर्थ होते हैं। ऐसी स्थिति हो सकती है इससे कोई फर्क नहीं पड़ता कि आप किस प्रकार की प्रतिकृति का उपयोग कर रहे हैं। यहां तक कि अगर आप अर्ध-सिंक प्रतिकृति का उपयोग करते हैं, तो यह केवल गारंटी दे सकता है कि मास्टर की सभी घटनाओं को रिले लॉग में दासों में से एक पर संग्रहीत किया जाता है। यह उन घटनाओं को दास पर लागू करने के बारे में कुछ नहीं कहता है।
यहां समस्या यह है कि, यदि दास को मास्टर के रूप में पदोन्नत किया जाता है, तो रिले लॉग मिटा दिए जाएंगे। यदि कोई दास पिछड़ रहा है और उसने सभी लेन-देन लागू नहीं किए हैं, तो वह डेटा खो देगा - रिले लॉग से अभी तक लागू नहीं किए गए ईवेंट हमेशा के लिए खो जाएंगे।
इस स्थिति को हल करने का कोई एक आकार-फिट-सभी तरीका नहीं है। ClusterControl उपयोगकर्ताओं को सुरक्षित डिफ़ॉल्ट बनाए रखते हुए इसे कैसे किया जाना चाहिए, इस पर नियंत्रण देता है। यह निम्न सेटिंग का उपयोग करके cmon कॉन्फ़िगरेशन में किया जाता है:
replication_failover_wait_to_apply_timeout=-1डिफ़ॉल्ट रूप से यह '-1' का मान लेता है, जिसका अर्थ है कि यदि कोई मास्टर उम्मीदवार पिछड़ रहा है तो फ़ेलओवर तुरंत नहीं होगा, इसलिए जब तक उम्मीदवार पकड़ा नहीं जाता है, तब तक यह हमेशा के लिए प्रतीक्षा करने के लिए तैयार है। ClusterControl इसके रिले लॉग से सभी लापता लेनदेन को लागू करने के लिए अनिश्चित काल तक प्रतीक्षा करेगा। यह सुरक्षित है, लेकिन, अगर किसी कारण से, सबसे अद्यतित दास बुरी तरह पिछड़ रहा है, तो विफलता को पूरा होने में घंटों लग सकते हैं। स्पेक्ट्रम के दूसरी तरफ इसे '0' पर सेट कर रहा है - इसका मतलब है कि विफलता तुरंत होती है, भले ही मास्टर उम्मीदवार पिछड़ रहा हो या नहीं। आप बीच में भी जा सकते हैं और इसे कुछ मूल्य पर सेट कर सकते हैं। यह सेकंड में एक समय सेट करेगा, उदाहरण के लिए 30 सेकंड इसलिए वेरिएबल को इस पर सेट करें,
replication_failover_wait_to_apply_timeout=30जब> 0 पर सेट किया जाता है, तो ClusterControl एक मास्टर उम्मीदवार के लिए उसके रिले लॉग से लापता लेनदेन को लागू करने के लिए प्रतीक्षा करेगा जब तक कि मूल्य पूरा नहीं हो जाता (जो कि उदाहरण में 30 सेकंड है)। विफलता निर्धारित समय के बाद होती है या जब मास्टर उम्मीदवार प्रतिकृति पर पकड़ लेगा, जो भी पहले हो। यह एक अच्छा विकल्प हो सकता है यदि आपके आवेदन में डाउनटाइम के संबंध में विशिष्ट आवश्यकताएं हैं और आपको थोड़े समय के भीतर एक नए मास्टर का चुनाव करना है।
PostgreSQL और MySQL में स्वचालित विफलता के साथ ClusterControl कैसे काम करता है, इस बारे में अधिक जानकारी के लिए, हमारे पिछले ब्लॉगों को चेकआउट करें जिसका शीर्षक "PostgreSQL प्रतिकृति 101 के लिए विफलता" और "MySQL प्रतिकृति का स्वचालित विफलता - ClusterControl 1.4 में नया" है।
निष्कर्ष
स्वचालित विफलता एक मूल्यवान विशेषता है, विशेष रूप से उन व्यवसायों के लिए जिन्हें न्यूनतम डाउनटाइम के साथ 24/7 संचालन की आवश्यकता होती है। व्यवसाय को यह परिभाषित करना चाहिए कि अनियोजित आउटेज के दौरान स्वचालन प्रक्रिया पर कितना नियंत्रण दिया जाता है। ClusterControl जैसा उच्च उपलब्धता समाधान फ़ेलओवर प्रोसेसिंग में अनुकूलन योग्य स्तर की सहभागिता प्रदान करता है। कुछ संगठनों के लिए, स्वचालित फ़ेलओवर एक विकल्प नहीं हो सकता है, भले ही फ़ेलओवर के दौरान उपयोगकर्ता इंटरैक्शन समय खा सकता है और आरटीओ को प्रभावित कर सकता है। धारणा यह है कि यदि स्वचालित विफलता सही ढंग से काम नहीं करती है या इससे भी बदतर है, तो यह बहुत जोखिम भरा है, इसके परिणामस्वरूप डेटा गड़बड़ हो जाता है और आंशिक रूप से गायब हो जाता है (हालांकि कोई यह तर्क दे सकता है कि एक मानव भी इसी तरह के परिणामों के लिए विनाशकारी गलतियां कर सकता है)। जो लोग अपने डेटाबेस पर करीबी नियंत्रण रखना पसंद करते हैं, वे स्वचालित विफलता को छोड़ना और इसके बजाय मैन्युअल प्रक्रिया का उपयोग करना चुन सकते हैं। इस तरह की प्रक्रिया में अधिक समय लगता है, लेकिन यह एक अनुभवी व्यवस्थापक को सिस्टम की स्थिति का आकलन करने और जो हुआ उसके आधार पर सुधारात्मक कार्रवाई करने की अनुमति देता है।