निम्नलिखित एडवेंचरवर्क्स क्वेरी पर विचार करें जो उत्पाद आईडी 421 के लिए इतिहास तालिका लेनदेन आईडी लौटाती है:
SELECT TH.TransactionID FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 421;
क्वेरी ऑप्टिमाइज़र को कार्डिनैलिटी (पंक्ति गणना) अनुमान के साथ एक कुशल निष्पादन योजना शीघ्रता से मिलती है जो बिल्कुल सही है, जैसा कि SQL संतरी योजना एक्सप्लोरर में दिखाया गया है:

अब मान लें कि हम "मेटल प्लेट 2" नामक एडवेंचरवर्क्स उत्पाद के लिए इतिहास लेनदेन आईडी खोजना चाहते हैं। इस क्वेरी को T-SQL में व्यक्त करने के कई तरीके हैं। एक प्राकृतिक सूत्रीकरण है:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); निष्पादन योजना इस प्रकार है:
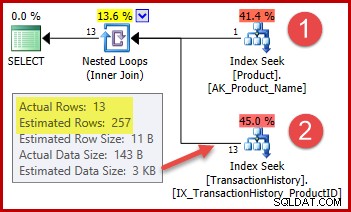
रणनीति है:
- उत्पाद तालिका में दिए गए नाम से उत्पाद आईडी देखें
- इतिहास तालिका में उस उत्पाद आईडी के लिए पंक्तियों का पता लगाएँ
चरण 1 के लिए पंक्तियों की अनुमानित संख्या बिल्कुल सही है क्योंकि उपयोग किए गए सूचकांक को अद्वितीय घोषित किया जाता है और केवल उत्पाद के नाम पर ही कुंजीबद्ध किया जाता है। इसलिए "मेटल प्लेट 2" पर समानता परीक्षण ठीक एक पंक्ति (या शून्य पंक्तियों को वापस करने की गारंटी है यदि हम एक उत्पाद नाम निर्दिष्ट करते हैं जो मौजूद नहीं है)।
चरण दो के लिए हाइलाइट किया गया 257-पंक्ति अनुमान कम सटीक है:वास्तव में केवल 13 पंक्तियों का सामना करना पड़ता है। यह विसंगति इसलिए उत्पन्न होती है क्योंकि अनुकूलक को यह नहीं पता होता है कि "मेटल प्लेट 2" नामक उत्पाद के साथ कौन सी विशेष उत्पाद आईडी संबद्ध है। यह मान को अज्ञात मानता है, औसत घनत्व जानकारी का उपयोग करके कार्डिनैलिटी अनुमान उत्पन्न करता है। गणना नीचे दिखाए गए सांख्यिकी ऑब्जेक्ट के तत्वों का उपयोग करती है:
DBCC SHOW_STATISTICS
(
'Production.TransactionHistory',
'IX_TransactionHistory_ProductID'
)
WITH STAT_HEADER, DENSITY_VECTOR;
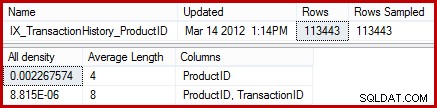
आंकड़े बताते हैं कि तालिका में 441 अद्वितीय उत्पाद आईडी (1 / 0.002267574 =441) के साथ 113443 पंक्तियां हैं। यह मानते हुए कि उत्पाद आईडी में पंक्तियों का वितरण एक समान है, कार्डिनैलिटी का अनुमान उत्पाद आईडी से मेल खाने की अपेक्षा करता है (113443 / 441) =257.24 पंक्तियों का औसत। जैसा कि यह पता चला है, वितरण विशेष रूप से एक समान नहीं है; "मेटल प्लेट 2" उत्पाद के लिए केवल 13 पंक्तियाँ हैं।
एक तरफ
आप सोच रहे होंगे कि 257-पंक्ति का अनुमान अधिक सटीक होना चाहिए। उदाहरण के लिए, यह देखते हुए कि उत्पाद आईडी और नाम दोनों अद्वितीय होने के लिए बाध्य हैं, SQL सर्वर स्वचालित रूप से इस एक-से-एक संबंध के बारे में जानकारी बनाए रख सकता है। तब उसे पता चलेगा कि "मेटल प्लेट 2" उत्पाद आईडी 479 से संबद्ध है, और उस अंतर्दृष्टि का उपयोग उत्पाद आईडी हिस्टोग्राम का उपयोग करके अधिक सटीक अनुमान उत्पन्न करने के लिए करें:
DBCC SHOW_STATISTICS
(
'Production.TransactionHistory',
'IX_TransactionHistory_ProductID'
)
WITH HISTOGRAM;
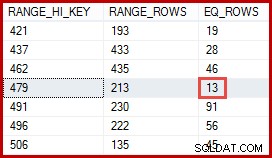
इस तरह से निकाली गई 13 पंक्तियों का अनुमान बिल्कुल सही होता। फिर भी, उपलब्ध सांख्यिकीय जानकारी और कार्डिनैलिटी अनुमान द्वारा लागू सामान्य सरलीकरण मान्यताओं (जैसे समान वितरण) को देखते हुए, 257 पंक्तियों का अनुमान एक अनुचित नहीं था। सटीक अनुमान हमेशा अच्छे होते हैं, लेकिन "उचित" अनुमान भी पूरी तरह से स्वीकार्य होते हैं।
दो प्रश्नों को मिलाना
मान लें कि अब हम सभी लेन-देन इतिहास आईडी देखना चाहते हैं जहां उत्पाद आईडी 421 है या उत्पाद का नाम "धातु प्लेट 2" है। पिछले दो प्रश्नों को संयोजित करने का एक स्वाभाविक तरीका है:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
OR TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); निष्पादन योजना अब थोड़ी अधिक जटिल है, लेकिन इसमें अभी भी एकल-विधेय योजनाओं के पहचानने योग्य तत्व शामिल हैं:
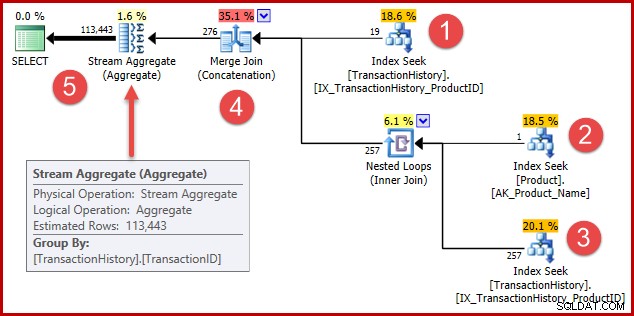
रणनीति है:
- उत्पाद 421 के लिए इतिहास रिकॉर्ड खोजें
- "मेटल प्लेट 2" नाम के उत्पाद के लिए उत्पाद आईडी देखें
- चरण 2 में मिली उत्पाद आईडी के लिए इतिहास रिकॉर्ड खोजें
- चरण 1 और 3 से पंक्तियों को मिलाएं
- किसी भी डुप्लीकेट को हटा दें (क्योंकि उत्पाद 421 "मेटल प्लेट 2" नाम का भी हो सकता है)
चरण 1 से 3 बिल्कुल पहले जैसे ही हैं। उन्हीं कारणों से वही अनुमान तैयार किए जाते हैं। चरण 4 नया है, लेकिन बहुत आसान है:यह 276 पंक्तियों का अनुमान देने के लिए अपेक्षित 257 पंक्तियों के साथ अपेक्षित 19 पंक्तियों को जोड़ता है।
चरण 5 दिलचस्प है। डुप्लीकेट-रिमूवल स्ट्रीम एग्रीगेट में 276 पंक्तियों का अनुमानित इनपुट और 113443 पंक्तियों का अनुमानित आउटपुट है। एक समुच्चय जो प्राप्त होने से अधिक पंक्तियों को आउटपुट करता है वह असंभव लगता है, है ना?
* यदि आप 2014 से पहले के कार्डिनैलिटी अनुमान मॉडल का उपयोग कर रहे हैं तो आपको यहां 102099 पंक्तियों का अनुमान दिखाई देगा।
कार्डिनैलिटी अनुमान बग
हमारे उदाहरण में असंभव स्ट्रीम एग्रीगेट अनुमान कार्डिनैलिटी अनुमान में एक बग के कारण होता है। यह एक दिलचस्प उदाहरण है इसलिए हम इसे थोड़ा विस्तार से देखेंगे।
सबक्वायरी हटाना
आपको यह जानकर आश्चर्य हो सकता है कि SQL सर्वर क्वेरी ऑप्टिमाइज़र सीधे सबक्वेरी के साथ काम नहीं करता है। उन्हें संकलन प्रक्रिया की शुरुआत में तार्किक क्वेरी ट्री से हटा दिया जाता है, और एक समान निर्माण के साथ बदल दिया जाता है जिसे ऑप्टिमाइज़र के साथ काम करने और उसके बारे में तर्क करने के लिए सेट किया जाता है। अनुकूलक के पास कई नियम हैं जो उपश्रेणियों को हटाते हैं। इन्हें निम्नलिखित क्वेरी का उपयोग करके नाम से सूचीबद्ध किया जा सकता है (संदर्भित DMV न्यूनतम रूप से प्रलेखित है, लेकिन समर्थित नहीं है):
SELECT name FROM sys.dm_exec_query_transformation_stats WHERE name LIKE 'RemoveSubq%';
परिणाम (एसक्यूएल सर्वर 2014 पर):
संयुक्त परीक्षण क्वेरी में इतिहास तालिका पर दो विधेय (संबंधपरक शब्दों में "चयन") होते हैं, जो OR से जुड़े होते हैं . इनमें से एक विधेय में एक सबक्वेरी शामिल है। संपूर्ण उपट्री (दोनों विधेय और उपश्रेणी) सूची में पहले नियम ("चयन में उपश्रेणी हटाएं") द्वारा व्यक्तिगत विधेय के संघ में अर्ध-जुड़ने के लिए बदल दिया गया है। हालांकि टी-एसक्यूएल सिंटैक्स का उपयोग करके इस आंतरिक परिवर्तन के परिणाम का प्रतिनिधित्व करना संभव नहीं है, यह होने के बहुत करीब है:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE EXISTS
(
SELECT 1
WHERE TH.ProductID = 421
UNION ALL
SELECT 1
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
AND P.ProductID = TH.ProductID
)
OPTION (QUERYRULEOFF ApplyUAtoUniSJ); यह थोड़ा दुर्भाग्यपूर्ण है कि सबक्वायरी हटाने के बाद आंतरिक पेड़ के मेरे टी-एसक्यूएल अनुमान में एक सबक्वायरी है, लेकिन क्वेरी प्रोसेसर की भाषा में यह नहीं है (यह अर्ध शामिल है)। यदि आप टी-एसक्यूएल समकक्ष पर मेरे प्रयास के बजाय कच्चे आंतरिक रूप को देखना पसंद करते हैं, तो कृपया आश्वस्त रहें कि यह क्षण भर के लिए होगा।
उपरोक्त टी-एसक्यूएल में शामिल अनिर्दिष्ट क्वेरी संकेत आप में से उन लोगों के लिए बाद के परिवर्तन को रोकने के लिए है जो निष्पादन योजना के रूप में परिवर्तित तर्क को देखना चाहते हैं। नीचे दिए गए एनोटेशन परिवर्तन के बाद दो विधेय की स्थिति दिखाते हैं:
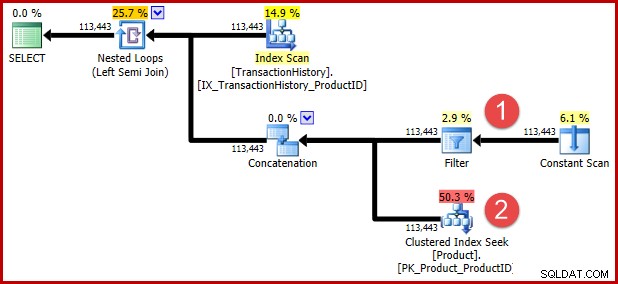
परिवर्तन के पीछे अंतर्ज्ञान यह है कि एक इतिहास पंक्ति योग्य होती है यदि दोनों में से कोई भी विधेय संतुष्ट हो। भले ही आप मेरे अनुमानित टी-एसक्यूएल और निष्पादन योजना चित्रण को कितना उपयोगी पाते हैं, मुझे आशा है कि यह कम से कम उचित रूप से स्पष्ट है कि पुनर्लेखन मूल क्वेरी के समान आवश्यकता को व्यक्त करता है।
मुझे इस बात पर जोर देना चाहिए कि ऑप्टिमाइज़र सचमुच वैकल्पिक टी-एसक्यूएल सिंटैक्स उत्पन्न नहीं करता है या मध्यवर्ती चरणों में पूर्ण निष्पादन योजना तैयार नहीं करता है। ऊपर दिए गए टी-एसक्यूएल और निष्पादन योजना का प्रतिनिधित्व विशुद्ध रूप से समझने में सहायता के लिए है। यदि आप कच्चे विवरण में रुचि रखते हैं, तो रूपांतरित क्वेरी ट्री का वादा किया गया आंतरिक प्रतिनिधित्व (स्पष्टता/स्थान के लिए थोड़ा संपादित) है:
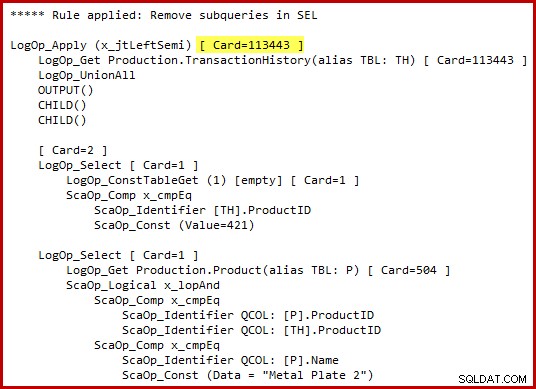
हाइलाइट किए गए लागू सेमी जॉइन कार्डिनैलिटी अनुमान पर ध्यान दें। 2014 कार्डिनैलिटी अनुमानक (पुराने सीई का उपयोग करते हुए 102099 पंक्तियाँ) का उपयोग करते समय यह 113443 पंक्तियाँ हैं। ध्यान रखें कि एडवेंचरवर्क्स इतिहास तालिका में कुल 113443 पंक्तियाँ हैं, इसलिए यह 100% चयनात्मकता (पुराने सीई के लिए 90%) का प्रतिनिधित्व करती है।
हमने पहले देखा था कि इन विधेय में से किसी एक को लागू करने से केवल कुछ ही मैच होते हैं:उत्पाद आईडी 421 के लिए 19 पंक्तियाँ, और "मेटल प्लेट 2" के लिए 13 पंक्तियाँ (अनुमानित 257)। अनुमान है कि वियोजन (OR) दो विधेय में से आधार तालिका में सभी पंक्तियाँ वापस आ जाएँगी जो पूरी तरह से बोनर्स लगती हैं।
बग विवरण
सेमी जॉइन के लिए चयनात्मकता गणना का विवरण केवल SQL सर्वर 2014 में दिखाई देता है जब नए कार्डिनैलिटी अनुमानक का उपयोग (अनियंत्रित) ट्रेस फ्लैग 2363 के साथ किया जाता है। विस्तारित घटनाओं के साथ कुछ ऐसा ही देखना संभव है, लेकिन ट्रेस फ्लैग आउटपुट अधिक सुविधाजनक है यहाँ उपयोग करने के लिए। आउटपुट का प्रासंगिक भाग नीचे दिखाया गया है:
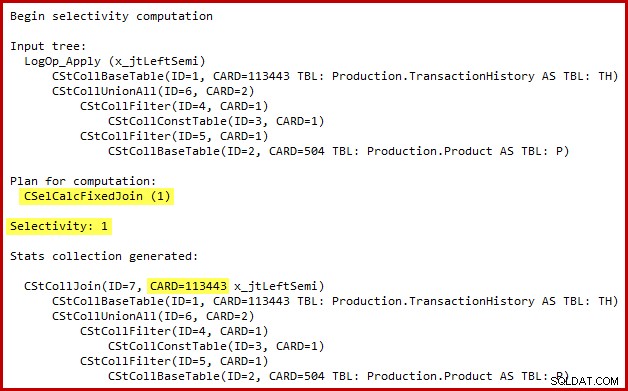
कार्डिनैलिटी अनुमानक 100% चयनात्मकता के साथ फिक्स्ड जॉइन कैलकुलेटर का उपयोग करता है। परिणामस्वरूप, सेमी जॉइन की अनुमानित आउटपुट कार्डिनैलिटी इसके इनपुट के समान है, जिसका अर्थ है कि इतिहास तालिका से सभी 113443 पंक्तियों के योग्य होने की उम्मीद है।
बग की सटीक प्रकृति यह है कि सेमी जॉइन सेलेक्टिविटी कंप्यूटेशन इनपुट ट्री में एक यूनियन से परे स्थित किसी भी विधेय को याद करता है। नीचे दिए गए उदाहरण में, सेमी जॉइन पर विधेय की कमी का अर्थ यह माना जाता है कि प्रत्येक पंक्ति योग्य होगी; यह संघनन (सभी संघ) के नीचे विधेय के प्रभाव की उपेक्षा करता है।
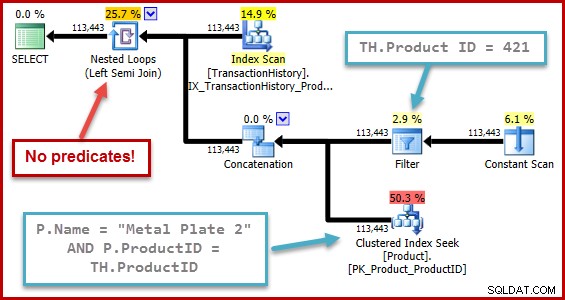
यह व्यवहार तब और अधिक आश्चर्यजनक होता है जब आप मानते हैं कि चयनात्मकता गणना एक पेड़ के प्रतिनिधित्व पर काम कर रही है जिसे ऑप्टिमाइज़र ने स्वयं उत्पन्न किया है (पेड़ का आकार और विधेय की स्थिति सबक्वेरी को हटाने का परिणाम है)।
2014 से पहले के कार्डिनैलिटी अनुमानक के साथ एक समान समस्या होती है, लेकिन इसके बजाय अंतिम अनुमान अनुमानित सेमी जॉइन इनपुट के 90% पर तय किया जाता है (उलटा निश्चित 10% विधेय अनुमान से संबंधित मनोरंजक कारणों के लिए जो प्राप्त करने के लिए बहुत अधिक मोड़ है में)।
उदाहरण
जैसा कि ऊपर उल्लेख किया गया है, यह बग तब प्रकट होता है जब एक संघ से परे स्थित संबंधित विधेय के साथ अर्ध जुड़ाव के लिए अनुमान लगाया जाता है। क्वेरी ऑप्टिमाइज़ेशन के दौरान यह आंतरिक व्यवस्था होती है या नहीं, यह मूल T-SQL सिंटैक्स और आंतरिक ऑप्टिमाइज़ेशन ऑपरेशन के सटीक अनुक्रम पर निर्भर करता है। निम्नलिखित उदाहरण कुछ ऐसे मामले दिखाते हैं जहां बग होता है और नहीं होता है:
उदाहरण 1
इस पहले उदाहरण में परीक्षण क्वेरी में एक मामूली बदलाव शामिल है:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = (SELECT 421) -- The only change
OR TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); अनुमानित निष्पादन योजना है:
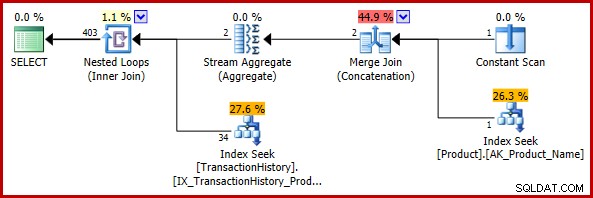
403 पंक्तियों का अंतिम अनुमान नेस्टेड लूप्स के इनपुट अनुमानों के साथ असंगत है, लेकिन यह अभी भी एक उचित है (जिस अर्थ में पहले चर्चा की गई थी)। यदि बग का सामना किया गया था, तो अंतिम अनुमान 113443 पंक्तियाँ (या 2014 से पहले CE मॉडल का उपयोग करते समय 102099 पंक्तियाँ) होंगी।
उदाहरण 2
यदि आप इस बग से बचने के लिए अपनी सभी निरंतर तुलनाओं को तुच्छ उपश्रेणियों के रूप में जल्दी से लिखने और फिर से लिखने वाले थे, तो देखें कि क्या होता है यदि हम एक और तुच्छ परिवर्तन करते हैं, इस बार दूसरे विधेय में समानता परीक्षण को IN के साथ बदलते हैं। क्वेरी का अर्थ अपरिवर्तित रहता है:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = (SELECT 421) -- Change 1
OR TH.ProductID IN -- Change 2
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); बग वापस आता है:
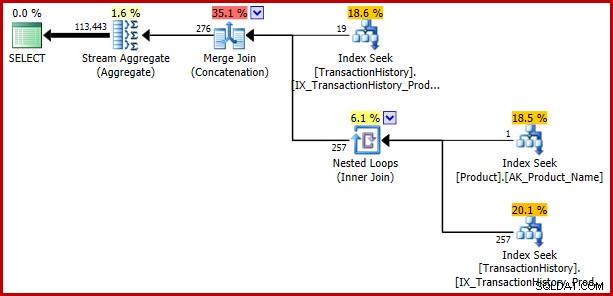
उदाहरण 3
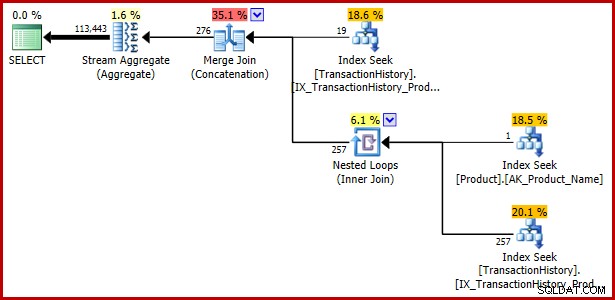
यद्यपि यह आलेख अब तक एक उपश्रेणी वाले एक असंगत विधेय पर केंद्रित है, निम्न उदाहरण से पता चलता है कि EXISTS और UNION ALL का उपयोग करके व्यक्त समान क्वेरी विनिर्देश भी असुरक्षित है:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE EXISTS
(
SELECT 1
WHERE TH.ProductID = 421
UNION ALL
SELECT 1
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
AND P.ProductID = TH.ProductID
); निष्पादन योजना:
उदाहरण 4
टी-एसक्यूएल में समान तार्किक क्वेरी को व्यक्त करने के दो और तरीके यहां दिए गए हैं:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
UNION
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
);
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
UNION
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
JOIN Production.Product AS P
ON P.ProductID = TH.ProductID
AND P.Name = N'Metal Plate 2'; कोई भी क्वेरी बग का सामना नहीं करती है, और दोनों एक ही निष्पादन योजना तैयार करते हैं:
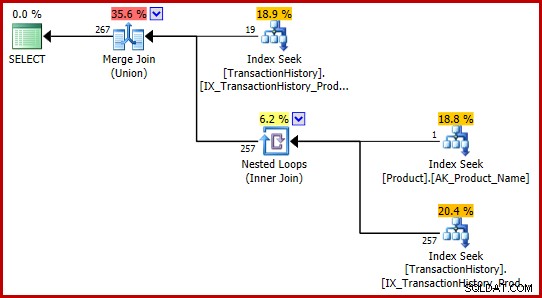
ये टी-एसक्यूएल फॉर्मूलेशन पूरी तरह से संगत (और उचित) अनुमानों के साथ निष्पादन योजना तैयार करने के लिए होते हैं।
उदाहरण 5
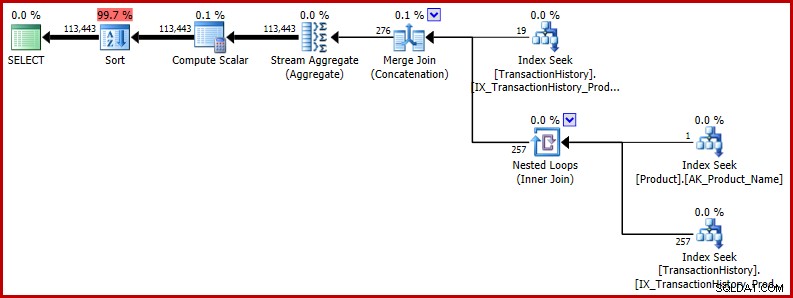
आप सोच रहे होंगे कि क्या गलत अनुमान महत्वपूर्ण है। अब तक प्रस्तुत मामलों में, यह कम से कम सीधे तौर पर तो नहीं है। समस्याएँ तब उत्पन्न होती हैं जब बग एक बड़ी क्वेरी में होता है, और गलत अनुमान ऑप्टिमाइज़र के निर्णयों को कहीं और प्रभावित करता है। एक न्यूनतम-विस्तारित उदाहरण के रूप में, हमारी परीक्षण क्वेरी के परिणामों को एक यादृच्छिक क्रम में वापस करने पर विचार करें:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
OR TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
)
ORDER BY NEWID(); -- New निष्पादन योजना से पता चलता है कि गलत अनुमान बाद के संचालन को प्रभावित करता है। उदाहरण के लिए, यह इस प्रकार के लिए आरक्षित स्मृति अनुदान का आधार है:
यदि आप इस बग के संभावित प्रभाव का अधिक वास्तविक-विश्व उदाहरण देखना चाहते हैं, तो SQLPerformance.com प्रश्नोत्तर साइट, answer.SQLPerformance.com.
पर रिचर्ड मैनसेल के इस हालिया प्रश्न पर एक नज़र डालें।सारांश और अंतिम विचार
यह बग तब ट्रिगर होता है जब ऑप्टिमाइज़र विशिष्ट परिस्थितियों में सेमी जॉइन के लिए कार्डिनैलिटी अनुमान करता है। कई कारणों से पता लगाना और काम करना एक चुनौतीपूर्ण बग है:
- सेमी जॉइन को निर्दिष्ट करने के लिए कोई स्पष्ट टी-एसक्यूएल सिंटैक्स नहीं है, इसलिए पहले से यह जानना मुश्किल है कि क्या कोई विशेष क्वेरी इस बग के लिए असुरक्षित होगी।
- ऑप्टिमाइज़र कई तरह की परिस्थितियों में सेमी जॉइन का परिचय दे सकता है, जिनमें से सभी स्पष्ट सेमी जॉइन उम्मीदवार नहीं हैं।
- समस्याग्रस्त सेमी जॉइन अक्सर बाद के ऑप्टिमाइज़र गतिविधि द्वारा किसी और चीज़ में बदल दिया जाता है, इसलिए हम अंतिम निष्पादन योजना में सेमी जॉइन ऑपरेशन होने पर भी भरोसा नहीं कर सकते हैं।
- अजीब दिखने वाला हर कार्डिनैलिटी अनुमान इस बग के कारण नहीं होता है। वास्तव में, इस प्रकार के कई उदाहरण सामान्य अनुकूलक संचालन के अपेक्षित और हानिरहित दुष्प्रभाव हैं।
- गलत सेमी जॉइन चयनात्मकता अनुमान हमेशा इसके इनपुट का 90% या 100% होगा, लेकिन यह आमतौर पर योजना में उपयोग की गई तालिका की कार्डिनैलिटी के अनुरूप नहीं होगा। इसके अलावा, गणना में उपयोग की जाने वाली सेमी जॉइन इनपुट कार्डिनैलिटी अंतिम निष्पादन योजना में भी दिखाई नहीं दे सकती है।
- टी-एसक्यूएल में समान तार्किक क्वेरी को व्यक्त करने के लिए आमतौर पर कई तरीके हैं। इनमें से कुछ बग को ट्रिगर करेंगे, जबकि अन्य नहीं करेंगे।
ये विचार इस बग का पता लगाने या उसके आसपास काम करने के लिए व्यावहारिक सलाह देना मुश्किल बनाते हैं। "अपमानजनक" अनुमानों के लिए निष्पादन योजनाओं की जांच करना निश्चित रूप से सार्थक है, और प्रदर्शन के साथ प्रश्नों की जांच करना जो अपेक्षा से बहुत खराब है, लेकिन इन दोनों में ऐसे कारण हो सकते हैं जो इस बग से संबंधित नहीं हैं। उस ने कहा, यह विशेष रूप से प्रश्नों की जांच करने लायक है जिसमें भविष्यवाणियों और एक सबक्वायरी का संयोजन शामिल है। जैसा कि इस लेख में दिए गए उदाहरणों से पता चलता है, बग का सामना करने का यही एकमात्र तरीका नहीं है, लेकिन मैं उम्मीद करता हूं कि यह एक सामान्य तरीका होगा।
यदि आप SQL सर्वर 2014 चलाने के लिए पर्याप्त भाग्यशाली हैं, तो नए कार्डिनैलिटी अनुमानक सक्षम होने के साथ, आप अर्ध जुड़ाव पर निश्चित 100% चयनात्मकता अनुमान के लिए ट्रेस फ्लैग 2363 आउटपुट को मैन्युअल रूप से चेक करके बग की पुष्टि करने में सक्षम हो सकते हैं, लेकिन यह है शायद ही सुविधाजनक। आप स्वाभाविक रूप से एक उत्पादन प्रणाली पर अनिर्दिष्ट ट्रेस फ़्लैग का उपयोग नहीं करना चाहेंगे।
इस समस्या के लिए User Voice बग रिपोर्ट यहां पाई जा सकती है। कृपया वोट करें और टिप्पणी करें कि क्या आप इस मुद्दे की जांच (और संभवतः तय) देखना चाहते हैं।