ऑटोमोबाइल/कार मरम्मत की दुकान चलाना वास्तव में एक जटिल व्यवसाय है। आपको अपॉइंटमेंट लेने की आवश्यकता होगी जबकि कुछ ग्राहक ड्राइव करेंगे और आप उन्हें घंटों तक इंतजार नहीं करना चाहते हैं। इसके अलावा, आपको कर्मचारियों को व्यवस्थित करने, मरम्मत ट्रैक करने, सामग्री, ग्राहकों को चार्ज करने आदि की आवश्यकता होगी। आपको निश्चित रूप से एक आईटी समाधान और निश्चित रूप से पृष्ठभूमि में एक डेटा मॉडल की आवश्यकता होगी। आज हम ऐसी ही एक मॉडल के बारे में बात करेंगे।
विचार
मैंने पहले ही उल्लेख किया है कि यह व्यवसाय मॉडल वास्तव में जटिल है। इसलिए, मैं सब कुछ कवर करने की कोशिश नहीं करूंगा। मैंने जानबूझकर ट्रैकिंग सामग्री और स्पेयर पार्ट्स को छोड़ दिया है और मॉडल के कुछ हिस्सों को सरल भी किया है। इसका कारण काफी सरल है। अगर मैंने वास्तव में सब कुछ शामिल किया है, तो उचित आकार के लेख के लिए मॉडल बहुत बड़ा होगा। तो चलिए शुरू करते हैं।
डेटा मॉडल
मॉडल में 5 विषय क्षेत्र शामिल हैं:
Repair shops & employeesCustomers & contactsVehiclesServices & offersऔरVisits
हम इन 5 विषय क्षेत्रों में से प्रत्येक का वर्णन उसी क्रम में करेंगे जिस क्रम में उन्हें सूचीबद्ध किया गया था।
अनुभाग 1:मरम्मत की दुकानें और कर्मचारी
पहला विषय क्षेत्र, जिसके साथ हम शुरुआत करेंगे, वह है Repair shops & employees विषय क्षेत्र। यह बिल्कुल स्पष्ट है कि ग्राहकों को ऑफ़र देने से पहले हमें यह जानना होगा कि हमारे पास क्या उपलब्ध है।
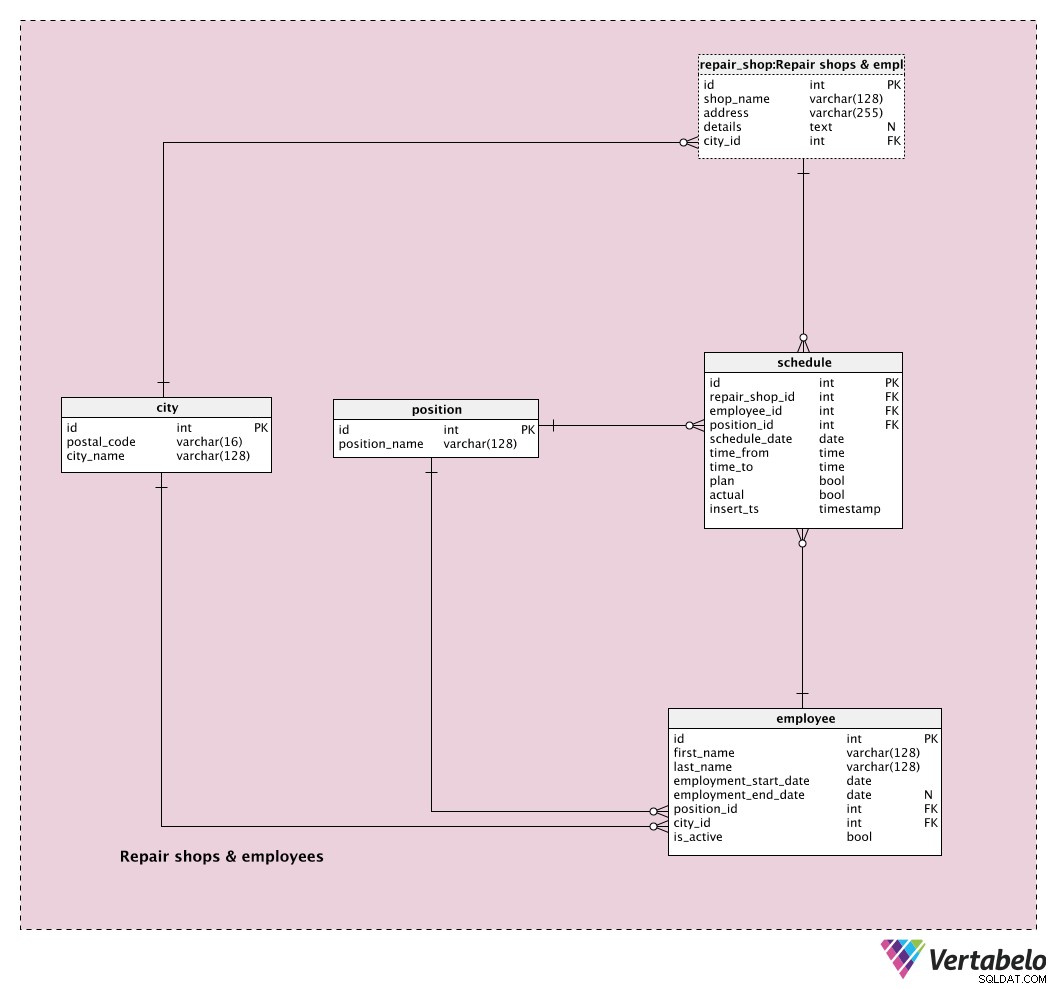
city डिक्शनरी का उपयोग उन सभी अलग-अलग शहरों को स्टोर करने के लिए किया जाता है जहां हमारे पास मरम्मत की दुकानें हैं या हमारे ग्राहक आते हैं। प्रत्येक शहर को postal_code . युग्म द्वारा विशिष्ट रूप से परिभाषित किया गया है - city_name . हम प्रत्येक शहर में केवल एक प्रविष्टि रखने का निर्णय ले सकते हैं, भले ही उस शहर में कई डाक कोड हों। उस स्थिति में, हम उस शहर के लिए केवल "मुख्य" पोस्टल कोड का उपयोग करेंगे। फिर भी, हमारे पास एक ही शहर और अलग-अलग पोस्टल कोड के लिए कई प्रविष्टियां रखने का विकल्प है - यदि हम ऐसा चाहते हैं।
repair_shop तालिका वह स्थान है जहाँ हम अपनी सभी मरम्मत की दुकानों की सूची संग्रहीत करेंगे। हम उम्मीद कर सकते हैं कि हम किसी बिंदु पर एक से अधिक कार्य करेंगे। प्रत्येक दुकान अपने shop_name . द्वारा विशिष्ट रूप से परिभाषित होती है और उस शहर की आईडी जिससे वह संबंधित है (city_id ) हम दुकान का पता और अतिरिक्त details भी स्टोर करेंगे पाठ्य प्रारूप में यदि कोई हो।
position शब्दकोश का उपयोग अद्वितीय position_names . को स्टोर करने के लिए किया जाता है जो हमारे कर्मचारियों को सौंपा जा सकता है। जबकि अधिकांश पद हमारे मुख्य व्यवसाय से संबंधित होंगे, हमारे पास कुछ ऐसे भी होंगे जो मुख्य व्यवसाय (तकनीकी भूमिका / पद) का हिस्सा नहीं हैं, लेकिन आवश्यक (प्रशासन, बिक्री, आदि) भी हैं।
हमारे सभी कर्मचारियों की सूची employee टेबल। प्रत्येक कर्मचारी के लिए, हम उसका संग्रह करेंगे:
first_name&last_name- कर्मचारी का पहला और अंतिम नाम।employment_start_date&employment_end_date- कंपनी में कर्मचारी की शुरुआत और समाप्ति तिथि। जब तक हम इसे परिभाषित नहीं कर सकते तब तक समाप्ति तिथि में NULL मान होगा।position_id- कंपनी में वर्तमान स्थिति का संदर्भ।city_id- उस शहर का संदर्भ जहां कर्मचारी वर्तमान में रहता है।is_active- एक झंडा यह दर्शाता है कि कर्मचारी वर्तमान में सक्रिय है या नहीं।
इस विषय क्षेत्र में अंतिम तालिका schedule टेबल। इस तालिका में, हम अपने सभी कर्मचारियों के लिए दैनिक स्तर पर सटीक शेड्यूल संग्रहीत करेंगे। हमारे पास एक ही कर्मचारी के लिए एक ही दिन के दौरान कई अंतरालों को संग्रहीत करने का विकल्प भी होगा। इसे प्राप्त करने के लिए, हम निम्नलिखित विशेषताओं का उपयोग करेंगे:
repair_shop_id- संबंधित मरम्मत की दुकान का संदर्भ।employee_id- संबंधित कर्मचारी के लिए एक संदर्भ।position_id- संबंधित स्थिति का संदर्भ, कर्मचारी के पास निर्धारित समय अवधि के दौरान होगा। ज्यादातर मामलों में, यह उसकी वर्तमान स्थिति होगी, लेकिन हमारे पास यहां कुछ अन्य पद सौंपने की सुविधा है।schedule_date- एक तारीख जिससे यह प्रविष्टि संबंधित है।time_from&time_to- यह जोड़ी उस समयावधि को परिभाषित करती है जिससे यह प्रविष्टि संबंधित है।plan- एक झंडा यह दर्शाता है कि क्या यह नियोजित प्रवेश था। प्रवेश की योजना केवल तभी नहीं बनाई जाएगी जब हमने इसे तदर्थ डाला हो।actual- यह ध्वज दर्शाता है कि क्या इस प्रविष्टि का एहसास हुआ था। ध्यान दें कि ज्यादातर मामलों में, फ़्लैग, योजना और वास्तविक दोनों, ट्रू पर सेट होंगे। यह इंगित करेगा कि हमने योजना बनाई और वास्तव में उस योजना को साकार किया।insert_ts- एक टाइमस्टैम्प उस क्षण को दर्शाता है जब यह रिकॉर्ड तालिका में डाला गया था।
संयोजन repair_shop_id - employee_id - schedule_date - time_from इस तालिका की UNIQUE/वैकल्पिक कुंजी बनाता है। नया रिकॉर्ड डालने से पहले, हमें उस नए अंतराल time_from . की भी जांच करनी चाहिए - time_to उसी कर्मचारी और दिनांक के लिए किसी भी मौजूदा अंतराल के साथ ओवरलैप नहीं होता है।
अनुभाग 2:ग्राहक और संपर्क
अब हम मॉडल के ग्राहक-संबंधित भाग में जाने के लिए तैयार हैं।
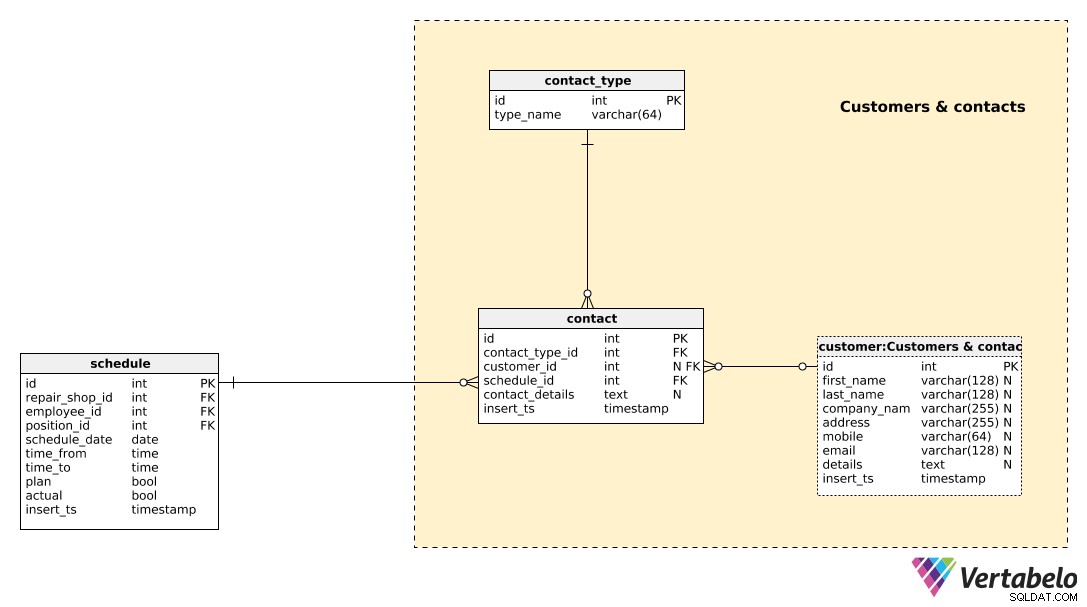
हम customer टेबल। प्रत्येक ग्राहक के लिए, हम स्टोर करेंगे:
first_name&last_name- ग्राहक का पहला और अंतिम नाम, यदि हमारा ग्राहक एक निजी व्यक्ति है।company_name- एक कंपनी का नाम, एक मामले में ग्राहक एक कंपनी है और एक निजी व्यक्ति नहीं है।address- ग्राहक का पता।mobile- ग्राहक का मोबाइल फोन नंबर।email- ग्राहक का ईमेलdetails- सभी अतिरिक्त ग्राहक विवरण, यदि कोई हो, पाठ्य प्रारूप में।insert_ts- एक टाइमस्टैम्प उस क्षण को दर्शाता है जब यह रिकॉर्ड तालिका में डाला गया था।
इस तालिका में अधिकांश विशेषताएँ अशक्त हैं क्योंकि हमारे पास शायद उनमें से कुछ और कुछ नहीं होंगी (first_name &last_name बनाम company_name ) दूसरों को बाहर करें।
हमें प्रत्येक ग्राहक के साथ किए गए सभी संपर्कों को ट्रैक करना होगा। ऐसा करने के लिए, हम दो तालिकाओं का उपयोग करेंगे। पहला, contact_type तालिका, एक साधारण शब्दकोश है जिसमें केवल UNIQUE type_name . है मूल्य।
वास्तविक संपर्क डेटा contact टेबल। हम उस संपर्क के प्रकार के संदर्भ संग्रहीत करेंगे (contact_type_id ), जिस ग्राहक से हमारा संपर्क था (customer_id ), एक कर्मचारी जिसने वह संपर्क किया (schedule_id ), और संपर्क विवरण और उस समय को भी संग्रहीत करता है जब यह रिकॉर्ड तालिका में डाला गया था (insert_ts )।
अनुभाग 3:वाहन
हमारे संसाधनों और ग्राहकों को जानने के बाद, हमें उन वाहनों को स्टोर करना होगा जिनके साथ हम काम करेंगे। डेटा पर नज़र रखने और आंतरिक रिपोर्ट बनाने के अलावा, अधिकांश देशों में हमें नियामक एजेंसियों, बीमा कंपनियों, पुलिस के लिए भी रिपोर्ट बनाने की आवश्यकता होगी।
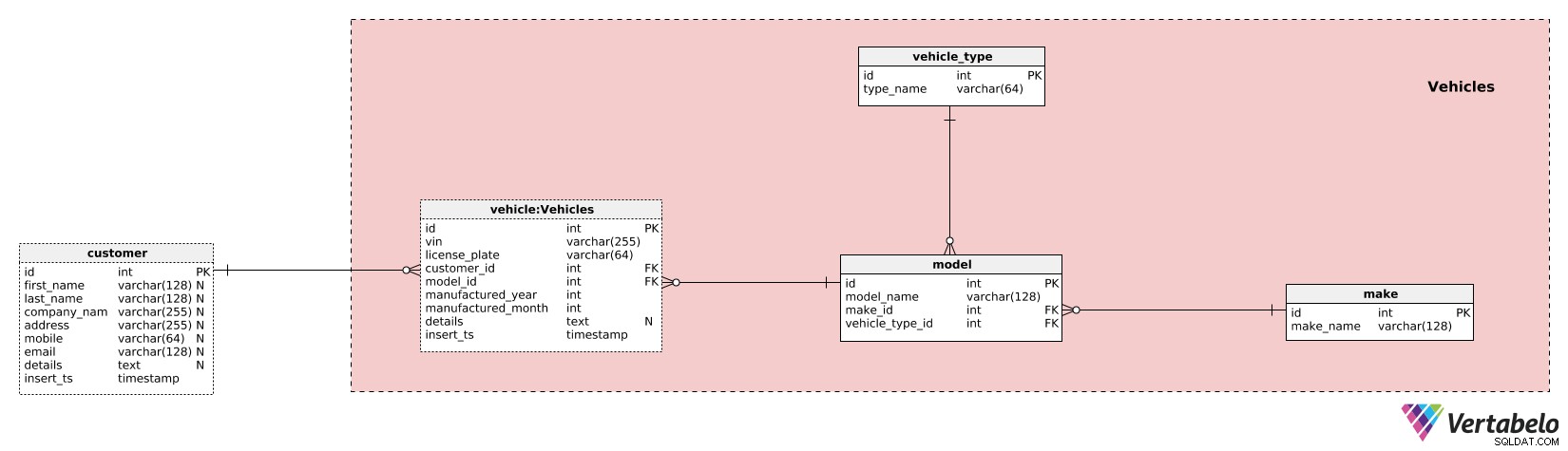
सबसे पहले, हम अपने वाहनों के मॉडल को परिभाषित करेंगे। हम इसे प्राप्त करने के लिए 3 तालिकाओं का उपयोग करेंगे। make शब्दकोश, हम अद्वितीय make_names . की सूची देंगे सभी कार/वाहन निर्माताओं/निर्माणों के लिए। इसके अलावा, हमें वाहन के प्रकारों को जानना होगा, इसलिए हम केवल एक अद्वितीय मान विशेषता के साथ एक और शब्दकोश का उपयोग करेंगे - type_name . इस्तेमाल किया गया 3 शब्दकोश model शब्दकोश। इसमें उन सभी मॉडलों की सूची होगी जो हमारे दरवाजे से आए थे। प्रत्येक मॉडल के लिए, हम अद्वितीय संयोजन को परिभाषित करेंगे model_name - make_id - vechicle_type_id .
हम इस विषय क्षेत्र का वर्णन vehicle टेबल। इस विषय क्षेत्र में "वास्तविक" डेटा वाली यह एकमात्र तालिका है। हम इस तालिका का उपयोग निम्नलिखित विवरणों को संग्रहीत करने के लिए करेंगे:
vin- एक वाहन पहचान संख्या, जो इस वाहन को विशिष्ट रूप से परिभाषित करती है।license_plate- एक मौजूदा लाइसेंस प्लेट नंबर।customer_id- यह वाहन जिस ग्राहक का है उसका संदर्भ। यदि वाहन का मालिक बदल जाता है, तो हम इसे एक नए रिकॉर्ड के रूप में सम्मिलित करेंगे, लेकिन हमें पता चलेगा कि यह वही वाहन है जो सीरियल नंबर के आधार पर है।model_id- मॉडल डिक्शनरी का संदर्भ।manufactured_year&manufactured_month- उस वर्ष और महीने को इंगित करें जब इस वाहन का उत्पादन किया गया था।details- टेक्स्ट के प्रारूप में सभी अतिरिक्त विवरण।insert_ts- एक टाइमस्टैम्प उस क्षण को दर्शाता है जब यह रिकॉर्ड तालिका में डाला गया था।
अनुभाग 4:सेवाएं और ऑफ़र
हम अगला बड़ा कदम उठाने के लिए तैयार हैं। हमें यह परिभाषित करने की आवश्यकता है कि हम अपने (संभावित) ग्राहकों को क्या पेशकश करते हैं। ये एकल कार्य या कार्यों का एक समूह हो सकता है - सेवाएं।
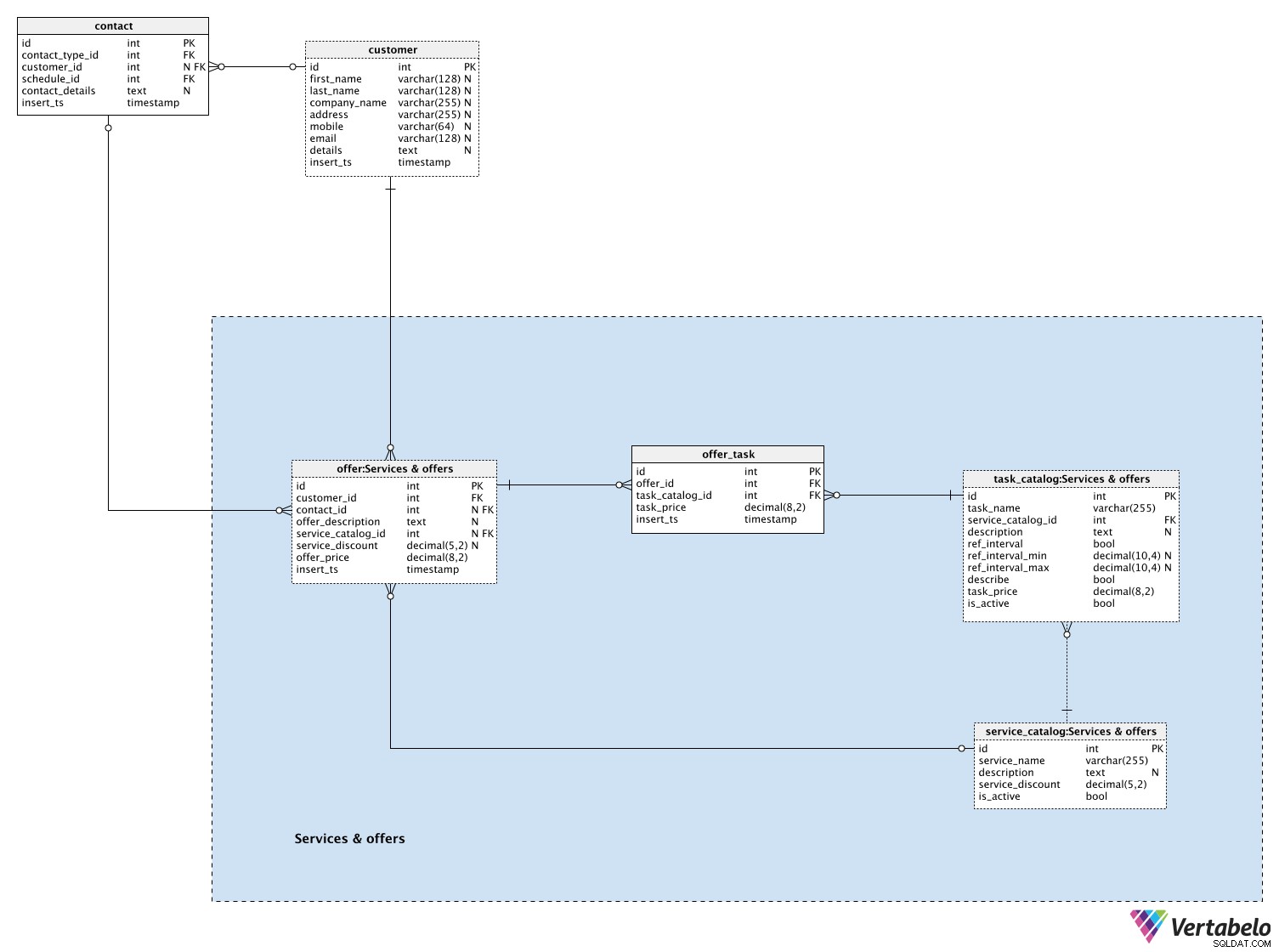
सभी सेवाओं की सूची service_catalog शब्दकोश। प्रत्येक सेवा में कुछ कार्य होते हैं और इसे इसके service_name . द्वारा विशिष्ट रूप से परिभाषित किया जाता है . नाम के अलावा, हम एक विवरण भी संग्रहीत करेंगे, यदि हमारे पास कोई है, तो service_discount का प्रतिशत और is_active झंडा। सेवा छूट का उपयोग इस सेवा में शामिल सभी कार्यों के लिए किया जाएगा।
अगला, हम कार्यों को परिभाषित करेंगे। कार्य हमारी सेवाओं का हिस्सा हैं। वे मूल क्रिया हैं जिन्हें अकेले किया जा सकता है। प्रत्येक कार्य को task_catalog तालिका:
task_name&service_catalog_id- एक नाम जिसका उपयोग हम इस कार्य और इससे संबंधित सेवा का वर्णन करने के लिए करेंगे। यह विशेषता जोड़ी तालिका की अद्वितीय कुंजी बनाती है।details- अतिरिक्त पाठ विवरण, यदि कोई हो, इस कार्य का वर्णन करने के लिए उपयोग किया जाता है।ref_interval- एक ध्वज यह दर्शाता है कि क्या हम इस कार्य के लिए अंतराल को मापेंगे।ref_interval_min&ref_interval_max- संदर्भ श्रेणी की न्यूनतम और अधिकतम सीमा।describe- एक ध्वज यह दर्शाता है कि क्या हमें इस कार्य के लिए एक पाठ्य टिप्पणी जोड़नी चाहिए।task_price- इस कार्य के लिए सेवा छूट के बिना वर्तमान मूल्य।is_active- एक ध्वज यह दर्शाता है कि कार्य वर्तमान में सक्रिय है (हमारे प्रस्ताव में) या नहीं।
ग्राहकों से संपर्क करने के बाद, हम उन्हें ऑफ़र देंगे. ऑफ़र अपने सभी कार्यों या कार्यों के एक सेट के साथ एक पूर्ण सेवा हो सकती है। सभी ऑफ़र offer टेबल। प्रत्येक ऑफ़र के लिए, हम स्टोर करेंगे:
customer_id- संबंधित ग्राहक की एक आईडी।contact_id- संबंधित संपर्क की एक आईडी, यदि कोई हो। पिछले संपर्कों के परिणामस्वरूप कितने ऑफ़र आए, यह निर्धारित करने के लिए यह महत्वपूर्ण जानकारी हो सकती है।offer_description- इस ऑफ़र का एक अतिरिक्त पाठ्य विवरण।service_catalog_id- हमारे द्वारा ग्राहक को दी गई सेवा की एक आईडी। यदि हमने उसे पूर्ण सेवा की पेशकश नहीं की है, लेकिन एक या अधिक कार्य जो सेवा का हिस्सा नहीं हैं, तो यह आईडी NULL हो सकती है।service_discount- फिलहाल सर्विस डिस्काउंट ऑफर बनाया गया था। यदि ऑफ़र सेवा से संबंधित नहीं है तो इस मान में NULL होगा।offer_price- उस प्रस्ताव की अंतिम कीमत। इसकी गणना सेवा छूट को घटाकर सभी कार्यों के योग के रूप में की जा सकती है।insert_ts- एक टाइमस्टैम्प उस क्षण को दर्शाता है जब यह रिकॉर्ड तालिका में डाला गया था।
इस विषय क्षेत्र में अंतिम तालिका offer_task टेबल। प्रत्येक ऑफ़र के लिए, भले ही हमने पूर्ण सेवा की पेशकश की हो या नहीं, हम सभी कार्यों के सेट को संग्रहीत करेंगे। हमें निम्नलिखित विवरण संग्रहीत करने की आवश्यकता है:
offer_id- संबंधित ऑफ़र की एक आईडी.task_catalog_id- संबंधित कार्य की एक आईडी। साथ मेंoffer_id, यह इस तालिका की अद्वितीय/वैकल्पिक कुंजी बनाता हैtask_price- उस कार्य का वर्तमान मूल्य जिस समय यह रिकॉर्ड डाला गया था।insert_ts- एक टाइमस्टैम्प उस क्षण को दर्शाता है जब यह रिकॉर्ड तालिका में डाला गया था।
अनुभाग 5:विज़िट
हमारे मॉडल में अंतिम विषय क्षेत्र का उपयोग हमारी मरम्मत की दुकान पर वास्तविक ग्राहक यात्राओं को संग्रहीत करने के लिए किया जाता है। हालांकि यह जटिल लगता है, हमारे यहां केवल 2 नई टेबल हैं, visit और visit_task ।
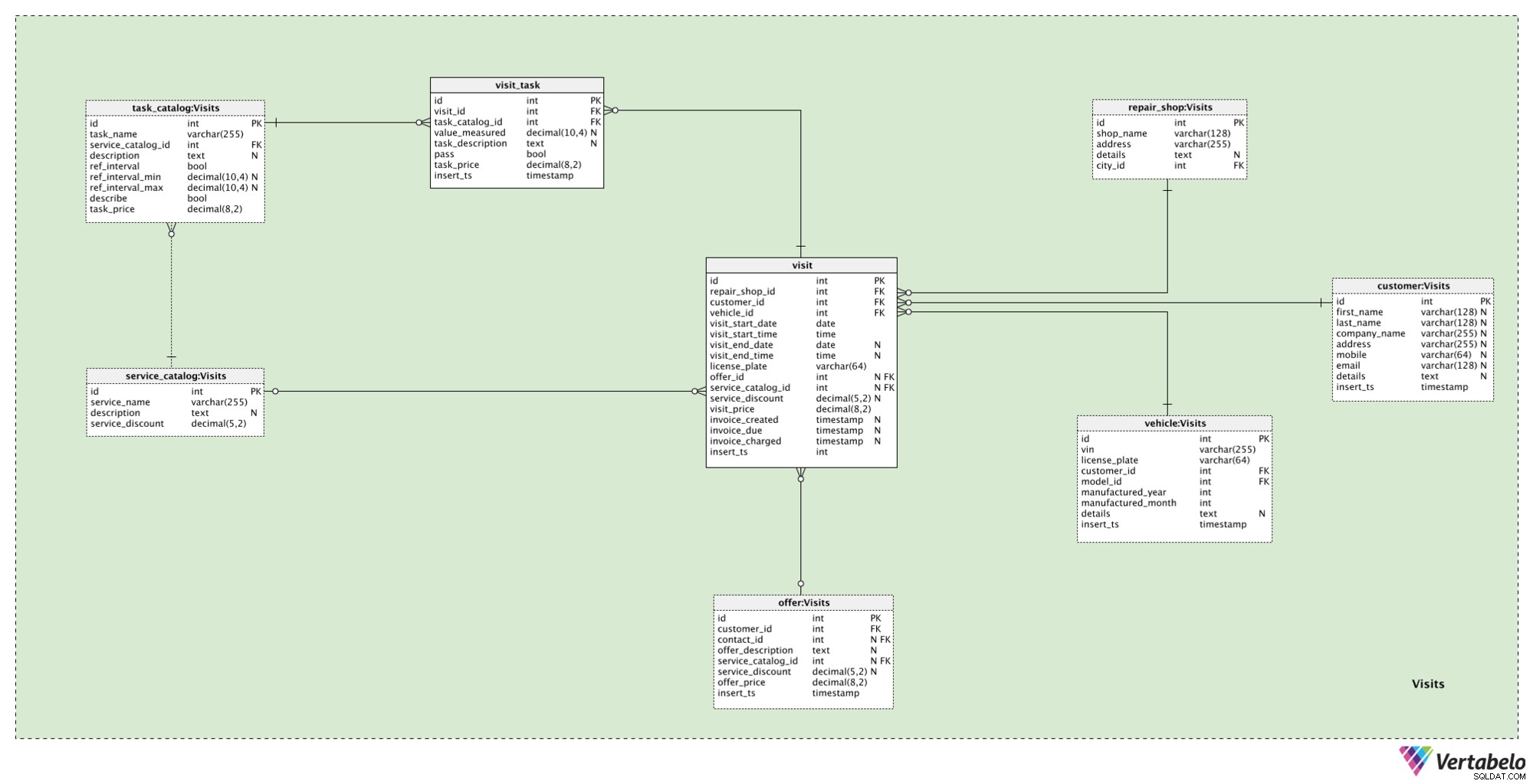
जब ग्राहक हमारे प्रस्ताव के लिए सहमत होता है या बस हमारी दुकान में आता है, तो हम उसे visit . ऐसी प्रत्येक घटना के लिए, हम निम्नलिखित विवरण संग्रहीत करेंगे:
repair_shop_id- संबंधित मरम्मत की दुकान का संदर्भ।customer_id- जिस ग्राहक से यह मुलाकात हुई है उसका संदर्भ।vehicle_id- इस यात्रा से संबंधित वाहन का एक संदर्भ।visit_start_date- विज़िट की आरंभ तिथि (योजनाबद्ध)।visit_start_time- विज़िट का प्रारंभ समय (योजनाबद्ध)।visit_end_date- एक विज़िट प्रारंभ तिथि (वास्तविक)। यह मान तब सेट किया जाएगा जब विज़िट वास्तव में समाप्त होगी।visit_end_time- एक यात्रा प्रारंभ समय (वास्तविक)। यह मान तब सेट किया जाएगा जब विज़िट वास्तव में समाप्त होगी।license_plate- एक लाइसेंस प्लेट नंबर जिस वक्त विजिट हुआ था। ध्यान दें, कि समय के दौरान लाइसेंस प्लेट बदल जाती हैं।offer_id- संबंधित ऑफ़र की एक आईडी, यदि कोई हो।service_catalog_id- संबंधित सेवा की एक आईडी, यदि कोई हो।service_discount- जिस समय यह रिकॉर्ड जोड़ा गया था उस समय छूट की एक प्रतिशत राशि और अगर हम एक पूर्ण सेवा प्रदान करते हैं।visit_price- उस विज़िट के लिए ग्राहक को कुल कीमत चुकानी होगी।invoice_created- एक टाइमस्टैम्प जब चालान बनाया गया था।invoice_due- एक टाइमस्टैम्प जब चालान देय हो गया।invoice_charged- एक टाइमस्टैम्प जब चालान का शुल्क लिया गया था।insert_ts- एक टाइमस्टैम्प उस क्षण को दर्शाता है जब यह रिकॉर्ड तालिका में डाला गया था।
हमारे मॉडल में अंतिम तालिका है visit_task टेबल। यह उन सभी कार्यों को संग्रहीत करने का स्थान है जो वास्तव में उस यात्रा का हिस्सा थे। यहां प्रत्येक रिकॉर्ड के लिए, हम निम्नलिखित मान संग्रहीत करेंगे:
visit_id- उस मुलाकात का एक संदर्भ।task_catalog_id- संबंधित कार्य का संदर्भvalue_measured- एक मान जिसे इस कार्य के दौरान मापा गया था, यदि कार्य को मापन की आवश्यकता है।task_description- उस कार्य से संबंधित विवरण यदि कार्य के लिए विवरण की आवश्यकता हो।pass- एक ध्वज यह दर्शाता है कि यह कार्य अपेक्षित अंतराल में था या नहीं।task_price- इस तालिका में फिलहाल उस कार्य का वास्तविक मूल्य डाला गया है।insert_ts- एक टाइमस्टैम्प उस क्षण को दर्शाता है जब यह रिकॉर्ड तालिका में डाला गया था।
जबकि यह मॉडल काफी सरल है, इसमें सभी आवश्यक तत्व शामिल हैं, जिसके लिए आपको इसके चारों ओर एक संपूर्ण मॉडल बनाने की आवश्यकता होगी। जिन भागों में सुधार की आवश्यकता है, वे निश्चित रूप से उपयोग की जाने वाली सामग्री और भुगतान प्रसंस्करण हैं। क्या आप इस मॉडल में कुछ और जोड़ेंगे?