SQL सर्वर 2005 ने गैर-संकुल अनुक्रमणिका में गैर-कुंजी स्तंभों को शामिल करने की क्षमता जोड़ी। SQL सर्वर 2000 और इससे पहले, एक गैर-संकुल अनुक्रमणिका के लिए, अनुक्रमणिका के लिए परिभाषित सभी स्तंभ कुंजी स्तंभ थे, जिसका अर्थ था कि वे अनुक्रमणिका के प्रत्येक स्तर का हिस्सा थे, जड़ से नीचे पत्ती स्तर तक। जब एक कॉलम को शामिल कॉलम के रूप में परिभाषित किया जाता है, तो यह केवल लीफ लेवल का हिस्सा होता है। पुस्तकें ऑनलाइन शामिल स्तंभों के निम्नलिखित लाभों को नोट करती हैं:
- वे डेटा प्रकार हो सकते हैं जिनकी अनुक्रमणिका कुंजी कॉलम के रूप में अनुमति नहीं है।
- सूचकांक कुंजी स्तंभों की संख्या या अनुक्रमणिका कुंजी आकार की गणना करते समय डेटाबेस इंजन द्वारा उन पर विचार नहीं किया जाता है।
उदाहरण के लिए, एक वर्कर (अधिकतम) कॉलम इंडेक्स कुंजी का हिस्सा नहीं हो सकता है, लेकिन यह एक शामिल कॉलम हो सकता है। इसके अलावा, वह वर्चर (अधिकतम) कॉलम इंडेक्स कुंजी के लिए लगाई गई 900-बाइट (या 16-कॉलम) सीमा के विरुद्ध नहीं गिना जाता है।
दस्तावेज़ीकरण निम्नलिखित प्रदर्शन लाभ को भी नोट करता है:
गैर-कुंजी कॉलम वाला एक इंडेक्स क्वेरी प्रदर्शन में काफी सुधार कर सकता है जब क्वेरी में सभी कॉलम इंडेक्स में कुंजी या नॉनकी कॉलम के रूप में शामिल होते हैं। प्रदर्शन लाभ प्राप्त होते हैं क्योंकि क्वेरी ऑप्टिमाइज़र इंडेक्स के भीतर सभी कॉलम मानों का पता लगा सकता है; तालिका या संकुल अनुक्रमणिका डेटा तक पहुँच नहीं है जिसके परिणामस्वरूप कम डिस्क I/O संचालन होता है।हम यह अनुमान लगा सकते हैं कि चाहे इंडेक्स कॉलम प्रमुख कॉलम हों या नॉनकी कॉलम, हमें प्रदर्शन में सुधार तब मिलता है जब सभी कॉलम इंडेक्स का हिस्सा नहीं होते हैं। लेकिन, क्या दोनों विविधताओं के बीच कोई प्रदर्शन अंतर है?
सेटअप
मैंने AdventuresWork2012 डेटाबेस की एक प्रति स्थापित की और किम्बर्ली ट्रिप के sp_helpindex के संस्करण का उपयोग करके Sales.SalesOrderHeader तालिका के लिए अनुक्रमणिका सत्यापित की:
USE [AdventureWorks2012]; GO EXEC sp_SQLskills_SQL2012_helpindex N'Sales.SalesOrderHeader';

बिक्री के लिए डिफ़ॉल्ट इंडेक्स.SalesOrderHeader
हम परीक्षण के लिए एक सीधी-सीधी क्वेरी के साथ शुरुआत करेंगे जो कई स्तंभों से डेटा पुनर्प्राप्त करती है:
SELECT [CustomerID], [SalesPersonID], [SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[SalesOrderHeader] WHERE [CustomerID] BETWEEN 11000 and 11200;
यदि हम SQL संतरी योजना एक्सप्लोरर का उपयोग करके एडवेंचरवर्क्स2012 डेटाबेस के विरुद्ध इसे निष्पादित करते हैं और योजना और तालिका I/O आउटपुट की जांच करते हैं, तो हम देखते हैं कि हमें 689 तार्किक रीड्स के साथ एक क्लस्टर इंडेक्स स्कैन मिलता है:
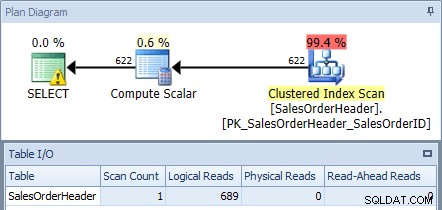
मूल क्वेरी से निष्पादन योजना
(प्रबंधन स्टूडियो में, आप SET STATISTICS IO ON; का उपयोग करके I/O मेट्रिक्स देख सकते हैं। ।)
SELECT में एक चेतावनी चिह्न है, क्योंकि अनुकूलक इस क्वेरी के लिए एक अनुक्रमणिका की अनुशंसा करता है:
USE [AdventureWorks2012]; GO CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [Sales].[SalesOrderHeader] ([CustomerID]) INCLUDE ([OrderDate],[ShipDate],[SalesPersonID],[SubTotal]);
टेस्ट 1
हम सबसे पहले ऑप्टिमाइज़र द्वारा सुझाए गए इंडेक्स (NCI1_included नाम) के साथ-साथ सभी कॉलमों के साथ प्रमुख कॉलम (NCI1 नाम दिया गया) के रूप में बदलाव करेंगे:
CREATE NONCLUSTERED INDEX [NCI1] ON [Sales].[SalesOrderHeader]([CustomerID], [SubTotal], [OrderDate], [ShipDate], [SalesPersonID]); GO CREATE NONCLUSTERED INDEX [NCI1_included] ON [Sales].[SalesOrderHeader]([CustomerID]) INCLUDE ([SubTotal], [OrderDate], [ShipDate], [SalesPersonID]); GO
यदि हम मूल क्वेरी को फिर से चलाते हैं, एक बार इसे NCI1 के साथ संकेत करते हुए, और एक बार इसे NCI1_included के साथ संकेत देते हैं, तो हम मूल के समान एक योजना देखते हैं, लेकिन इस बार तालिका I/ ओ, और समान लागत (दोनों के बारे में 0.006):
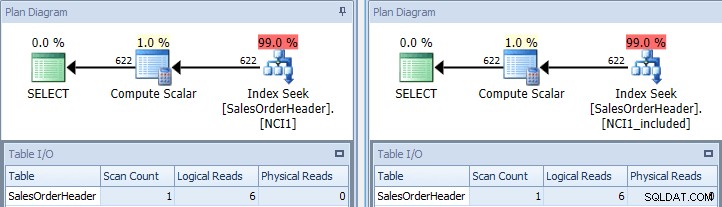
सूचकांक के साथ मूल क्वेरी - बाईं ओर कुंजी, शामिल करें सही
(स्कैन की संख्या अभी भी 1 है क्योंकि इंडेक्स सीक वास्तव में छद्म रूप में एक रेंज स्कैन है।)
अब, AdventureWorks2012 डेटाबेस आकार के संदर्भ में उत्पादन डेटाबेस का प्रतिनिधि नहीं है, और यदि हम प्रत्येक अनुक्रमणिका में पृष्ठों की संख्या को देखते हैं, तो हम देखते हैं कि वे बिल्कुल समान हैं:
SELECT [Table] = N'SalesOrderHeader', [Index_ID] = [ps].[index_id], [Index] = [i].[name], [ps].[used_page_count], [ps].[row_count] FROM [sys].[dm_db_partition_stats] AS [ps] INNER JOIN [sys].[indexes] AS [i] ON [ps].[index_id] = [i].[index_id] AND [ps].[object_id] = [i].[object_id] WHERE [ps].[object_id] = OBJECT_ID(N'Sales.SalesOrderHeader');
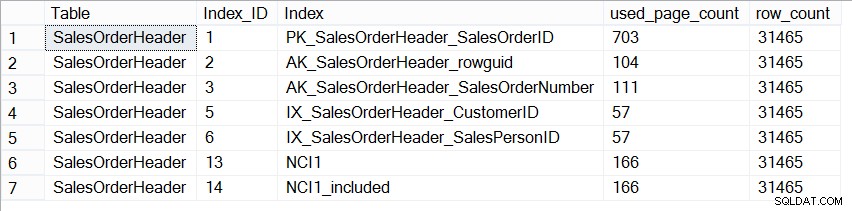
बिक्री पर इंडेक्स का आकार.SalesOrderHeader
यदि हम प्रदर्शन को देख रहे हैं, तो बड़े डेटा सेट के साथ परीक्षण करना आदर्श (और अधिक मज़ेदार) है।
टेस्ट 2
मेरे पास AdventureWorks2012 डेटाबेस की एक प्रति है जिसमें 200 मिलियन से अधिक पंक्तियों (यहां स्क्रिप्ट) के साथ SalesOrderHeader तालिका है, तो चलिए उस डेटाबेस में समान गैर-संकुल अनुक्रमणिका बनाते हैं और प्रश्नों को फिर से चलाते हैं:
USE [AdventureWorks2012_Big]; GO CREATE NONCLUSTERED INDEX [Big_NCI1] ON [Sales].[Big_SalesOrderHeader](CustomerID, SubTotal, OrderDate, ShipDate, SalesPersonID); GO CREATE NONCLUSTERED INDEX [Big_NCI1_included] ON [Sales].[Big_SalesOrderHeader](CustomerID) INCLUDE (SubTotal, OrderDate, ShipDate, SalesPersonID); GO SELECT [CustomerID], [SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1)) WHERE [CustomerID] between 11000 and 11200; SELECT [CustomerID], [SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1_included)) WHERE [CustomerID] between 11000 and 11200;
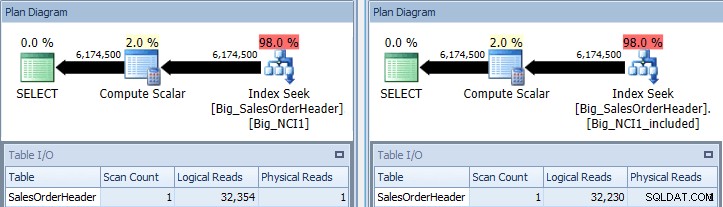
इंडेक्स के साथ मूल क्वेरी Big_NCI1 (l) और Big_NCI1_Included ( आर)
अब हमें कुछ डेटा मिलता है। क्वेरी 6 मिलियन से अधिक पंक्तियों में वापस आती है, और प्रत्येक अनुक्रमणिका की तलाश के लिए केवल 32,000 से अधिक रीड्स की आवश्यकता होती है, और अनुमानित लागत दोनों प्रश्नों के लिए समान है (31.233)। अभी तक कोई प्रदर्शन अंतर नहीं है, और यदि हम इंडेक्स के आकार की जांच करते हैं, तो हम देखते हैं कि शामिल कॉलम वाले इंडेक्स में 5,578 कम पेज हैं:
SELECT [Table] = N'Big_SalesOrderHeader', [Index_ID] = [ps].[index_id], [Index] = [i].[name], [ps].[used_page_count], [ps].[row_count] FROM [sys].[dm_db_partition_stats] AS [ps] INNER JOIN [sys].[indexes] AS [i] ON [ps].[index_id] = [i].[index_id] AND [ps].[object_id] = [i].[object_id] WHERE [ps].[object_id] = OBJECT_ID(N'Sales.Big_SalesOrderHeader');

बिक्री पर इंडेक्स का आकार.Big_SalesOrderHeader
यदि हम इस पर और गहराई से ध्यान दें और dm_dm_index_physical_stats की जाँच करें, तो हम देख सकते हैं कि सूचकांक के मध्यवर्ती स्तरों में अंतर मौजूद है:
SELECT
[ps].[index_id],
[Index] = [i].[name],
[ps].[index_type_desc],
[ps].[index_depth],
[ps].[index_level],
[ps].[page_count],
[ps].[record_count]
FROM [sys].[dm_db_index_physical_stats](DB_ID(),
OBJECT_ID('Sales.Big_SalesOrderHeader'), 5, NULL, 'DETAILED') AS [ps]
INNER JOIN [sys].[indexes] AS [i]
ON [ps].[index_id] = [i].[index_id]
AND [ps].[object_id] = [i].[object_id];
SELECT
[ps].[index_id],
[Index] = [i].[name],
[ps].[index_type_desc],
[ps].[index_depth],
[ps].[index_level],
[ps].[page_count],
[ps].[record_count]
FROM [sys].[dm_db_index_physical_stats](DB_ID(),
OBJECT_ID('Sales.Big_SalesOrderHeader'), 6, NULL, 'DETAILED') AS [ps]
INNER JOIN [sys].[indexes] [i]
ON [ps].[index_id] = [i].[index_id]
AND [ps].[object_id] = [i].[object_id];
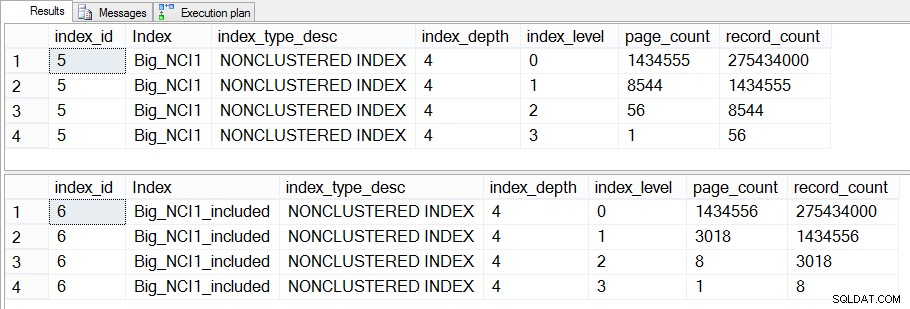
बिक्री पर अनुक्रमणिका का आकार (स्तर-विशिष्ट)। Big_SalesOrderHeader
दो इंडेक्स के मध्यवर्ती स्तरों के बीच का अंतर 43 एमबी है, जो महत्वपूर्ण नहीं हो सकता है, लेकिन शायद मैं डिस्क और मेमोरी दोनों में अंतरिक्ष को बचाने के लिए शामिल कॉलम के साथ इंडेक्स बनाने के इच्छुक हूं। एक क्वेरी के दृष्टिकोण से, हम अभी भी कुंजी में सभी कॉलम वाले इंडेक्स और शामिल कॉलम वाले इंडेक्स के बीच प्रदर्शन में कोई बड़ा बदलाव नहीं देखते हैं।
टेस्ट 3
इस परीक्षण के लिए, आइए क्वेरी को बदलें और [SubTotal] >= 100 के लिए एक फ़िल्टर जोड़ें WHERE क्लॉज के लिए:
SELECT [CustomerID],[SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1)) WHERE CustomerID = 11091 AND [SubTotal] >= 100; SELECT [CustomerID], [SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1_included)) WHERE CustomerID = 11091 AND [SubTotal] >= 100;
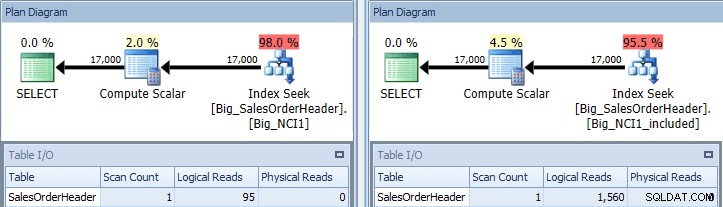
सबटोटल के साथ क्वेरी की एक्ज़ीक्यूशन प्लान दोनों इंडेक्स के खिलाफ विधेय करें
अब हम I/O (95 रीड बनाम 1,560), लागत (0.848 बनाम 1.55), और क्वेरी प्लान में एक सूक्ष्म लेकिन उल्लेखनीय अंतर देखते हैं। कुंजी में सभी स्तंभों के साथ अनुक्रमणिका का उपयोग करते समय, खोज विधेय CustomerID और SubTotal है:
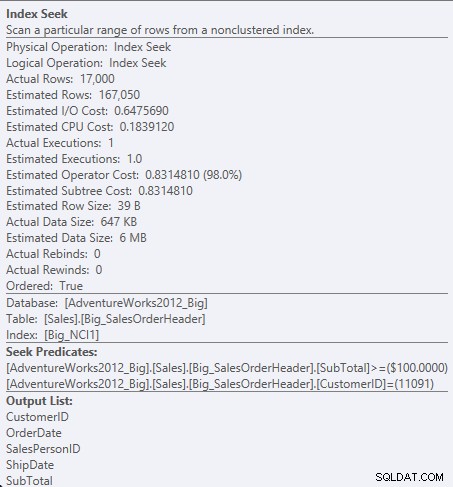
NCI1 के विरुद्ध विधेय की तलाश करें
क्योंकि सबटोटल इंडेक्स की में दूसरा कॉलम है, डेटा को ऑर्डर किया जाता है और सबटोटल इंडेक्स के मध्यवर्ती स्तरों में मौजूद होता है। इंजन 11091 के ग्राहक आईडी और 100 से अधिक या उसके बराबर सबटोटल के साथ सीधे पहले रिकॉर्ड की तलाश करने में सक्षम है, और तब तक इंडेक्स के माध्यम से पढ़ा जाता है जब तक कि ग्राहक आईडी 11091 के लिए कोई और रिकॉर्ड मौजूद न हो।
शामिल कॉलम वाले इंडेक्स के लिए, सबटोटल केवल इंडेक्स के लीफ लेवल में मौजूद होता है, इसलिए CustomerID सीक प्रेडिकेट है, और सबटोटल एक अवशिष्ट विधेय है (सिर्फ स्क्रीन शॉट में प्रेडिकेट के रूप में सूचीबद्ध):
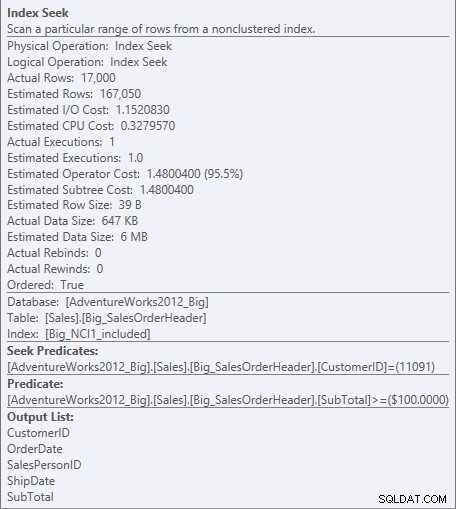
NCI1_included के विरुद्ध विधेय और अवशिष्ट विधेय की तलाश करें
इंजन सीधे पहले रिकॉर्ड की तलाश कर सकता है जहां CustomerID 11091 है, लेकिन फिर उसे प्रत्येक को देखना होगा यह देखने के लिए CustomerID 11091 के लिए रिकॉर्ड करें कि क्या SubTotal 100 या अधिक है, क्योंकि डेटा CustomerID और SalesOrderID (क्लस्टरिंग कुंजी) द्वारा ऑर्डर किया गया है।
टेस्ट 4
हम अपनी क्वेरी के एक और रूपांतर की कोशिश करेंगे, और इस बार हम एक ORDER BY:
जोड़ेंगे।SELECT [CustomerID],[SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1)) WHERE CustomerID = 11091 ORDER BY [SubTotal]; SELECT [CustomerID],[SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1_included)) WHERE CustomerID = 11091 ORDER BY [SubTotal];
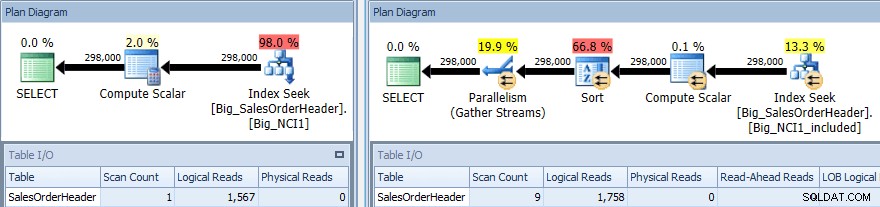
दोनों अनुक्रमितों के विरुद्ध SORT के साथ क्वेरी की निष्पादन योजना
फिर से हमारे पास I/O में बदलाव (हालांकि बहुत मामूली), लागत में बदलाव (1.5 बनाम 9.3), और योजना के आकार में बहुत बड़ा बदलाव है; हम बड़ी संख्या में स्कैन (1 बनाम 9) भी देखते हैं। क्वेरी के लिए डेटा को सबटोटल द्वारा क्रमबद्ध करने की आवश्यकता होती है; जब SubTotal अनुक्रमणिका कुंजी का हिस्सा होता है तो इसे सॉर्ट किया जाता है, इसलिए जब CustomerID 11091 के रिकॉर्ड पुनर्प्राप्त किए जाते हैं, तो वे पहले से ही अनुरोधित क्रम में होते हैं।
जब SubTotal एक सम्मिलित कॉलम के रूप में मौजूद होता है, तो CustomerID 11091 के रिकॉर्ड को उपयोगकर्ता को वापस करने से पहले सॉर्ट किया जाना चाहिए, इसलिए ऑप्टिमाइज़र क्वेरी में सॉर्ट ऑपरेटर को इंटरजेक्ट करता है। नतीजतन, क्वेरी जो इंडेक्स Big_NCI1_included का उपयोग करती है, वह 29,312 KB के मेमोरी ग्रांट का अनुरोध (और दिया जाता है), जो उल्लेखनीय है (और योजना के गुणों में पाया जाता है)।
सारांश
हम जिस मूल प्रश्न का उत्तर देना चाहते थे, वह यह था कि क्या हम एक प्रदर्शन अंतर देखेंगे जब कोई क्वेरी कुंजी में सभी स्तंभों के साथ सूचकांक का उपयोग करती है, बनाम सूचकांक जिसमें अधिकांश कॉलम लीफ स्तर में शामिल होते हैं। हमारे परीक्षणों के पहले सेट में कोई अंतर नहीं था, लेकिन हमारे तीसरे और चौथे परीक्षण में था। यह अंततः क्वेरी पर निर्भर करता है। हमने केवल दो भिन्नताओं को देखा - एक के पास एक अतिरिक्त विधेय था, दूसरे के पास एक ORDER BY था - कई और मौजूद हैं।
डेवलपर्स और डीबीए को यह समझने की जरूरत है कि एक इंडेक्स में कॉलम शामिल करने के कुछ बेहतरीन फायदे हैं, लेकिन वे हमेशा इंडेक्स के समान प्रदर्शन नहीं करेंगे, जिसमें कुंजी में सभी कॉलम होते हैं। यह उन स्तंभों को स्थानांतरित करने के लिए आकर्षक हो सकता है जो विधेय का हिस्सा नहीं हैं और कुंजी से जुड़ते हैं, और बस उन्हें शामिल करते हैं, ताकि सूचकांक के समग्र आकार को कम किया जा सके। हालाँकि, कुछ मामलों में इसके लिए क्वेरी निष्पादन के लिए अधिक संसाधनों की आवश्यकता होती है और यह प्रदर्शन को ख़राब कर सकता है। गिरावट नगण्य हो सकती है; यह नहीं हो सकता है ... जब तक आप परीक्षण नहीं करेंगे तब तक आपको पता नहीं चलेगा। इसलिए, एक इंडेक्स को डिजाइन करते समय, प्रमुख के बाद कॉलम के बारे में सोचना महत्वपूर्ण है - और समझें कि क्या उन्हें कुंजी का हिस्सा बनने की आवश्यकता है (उदाहरण के लिए डेटा को ऑर्डर करने से लाभ मिलेगा) या यदि वे अपने उद्देश्य को शामिल कर सकते हैं स्तंभ।
जैसा कि SQL सर्वर में अनुक्रमण के साथ विशिष्ट है, आपको सर्वोत्तम रणनीति निर्धारित करने के लिए अपनी अनुक्रमणिका के साथ अपने प्रश्नों का परीक्षण करना होगा। यह एक कला और विज्ञान बना हुआ है - जितना संभव हो उतने प्रश्नों को संतुष्ट करने के लिए न्यूनतम संख्या में अनुक्रमणिका खोजने का प्रयास कर रहा है।